基于DeepLabv3+的鳴笛監測系統定位誤差檢測*
2022-10-25 08:25:56鄭慧峰姚潤廣朱勤豐
傳感技術學報 2022年8期
周 云,鄭慧峰,姚潤廣,朱勤豐
(中國計量大學計量測試工程學院,浙江 杭州 310018)
鳴笛監測系統是基于傳聲器陣列的聲源定位技術在交通執法方面的應用。 傳聲器陣列中心集成的小型攝像機抓拍光學圖像,與聲源識別定位系統計算的聲壓云圖(偽彩圖)疊加,以聲相云圖的方式直觀地將鳴笛聲與鳴笛車輛相對應[1-3]。 隨著文明城市建設和智能化交通管理的進一步深入,越來越多的城市在特定路口安裝了鳴笛監測系統以協助交通部門取證執法[4]。
1996 年,Silverman 和Brandstein[5]首次將傳聲器陣列應用于噪聲源的定位。 隨后波音公司的Asano F、Asoh H 等[6]通過大型麥克風陣列實現波音777 在滑行中的噪聲點監測分析。 丹麥的B&K、荷蘭的Microflown 等單位[7]先后提出了“聲學照相機”這一概念,將聲場重建結果與光學照片合成,實現了聲場可視化。 為進一步研究基于傳聲器陣列的聲源定位系統,Barsikow B 等[8]通過改變傳聲器陣列的形狀,如水平、垂直線性、十字和X 形等來研究噪聲源的定位效果。 文獻[9]提出修正陣列中各傳聲器與標準傳聲器之間的幅值比和相位差,從而提高傳聲器陣列的定位精度。 文獻[10]設計了一種七元傳聲器陣列,并研究了陣列參數水平偏角、仰角等對定位誤差的影響。 以上方法是從傳聲器及其陣列設計上對聲源定位系統的定位誤差進行研究。 鳴笛監測系統作為聲源定位系統的分支,暫無統一的衡量標準或檢定規程對其進行計量校準。 生產廠家提供的傳統定位誤差檢測方法有兩種:一是采用偏差標記框,在不同位置測試被檢系統的定位中心是否位于框內,僅能夠定性判斷系統合格與否。 二是利用圖像處理技術在聲相云圖上提取目標,與實際位置對比得到定位誤差[11],一定程度上提高了檢測效率和精度,但難以提取復雜背景環境中的目標對象。
語義分割算法將圖像中不同類型的對象進行語義信息標注,可在復雜背景中識別出不同對象。 完全卷積網絡(Fully Convolutional Network,FCN)[12]的提出,促進了深度學習語義分割模型的迅速發展,基于編碼器- 解碼器結構的U-net、 SegNet 和DeepLab 系列網絡被廣泛應用于醫學圖像處理、空間機器人、自動駕駛等領域[13]。 其中DeepLabv3+網絡將深度可分離卷積添加到空洞空間金字塔池化(Atrous Spatial Pyramid Pooling,ASPP)和解碼器模塊中,提高了網絡的運行速率和魯棒性,達到了目前最佳的分割效果。
本文以DeepLabv3+網絡為基礎,增加通道注意力機制模塊,并結合幾何推導法提出了一種基于改進DeepLabv3+網絡的鳴笛監測系統定位誤差檢測方法。 將聲源定位結果分為橫向定位誤差與縱向定位誤差兩個指標,在室外道路上對動靜態定位誤差檢測方法進行實驗驗證。
1 定位誤差檢測原理
1.1 橫向定位誤差和縱向定位誤差定義
定位誤差定義為鳴笛監測系統標記的偽彩圖中心位置與鳴笛聲源中心位置平行于路面的誤差,此誤差包括垂直于車輛行進方向的誤差及平行于車輛行進方向的誤差,分別為橫向定位誤差和縱向定位誤差,如圖1 所示。
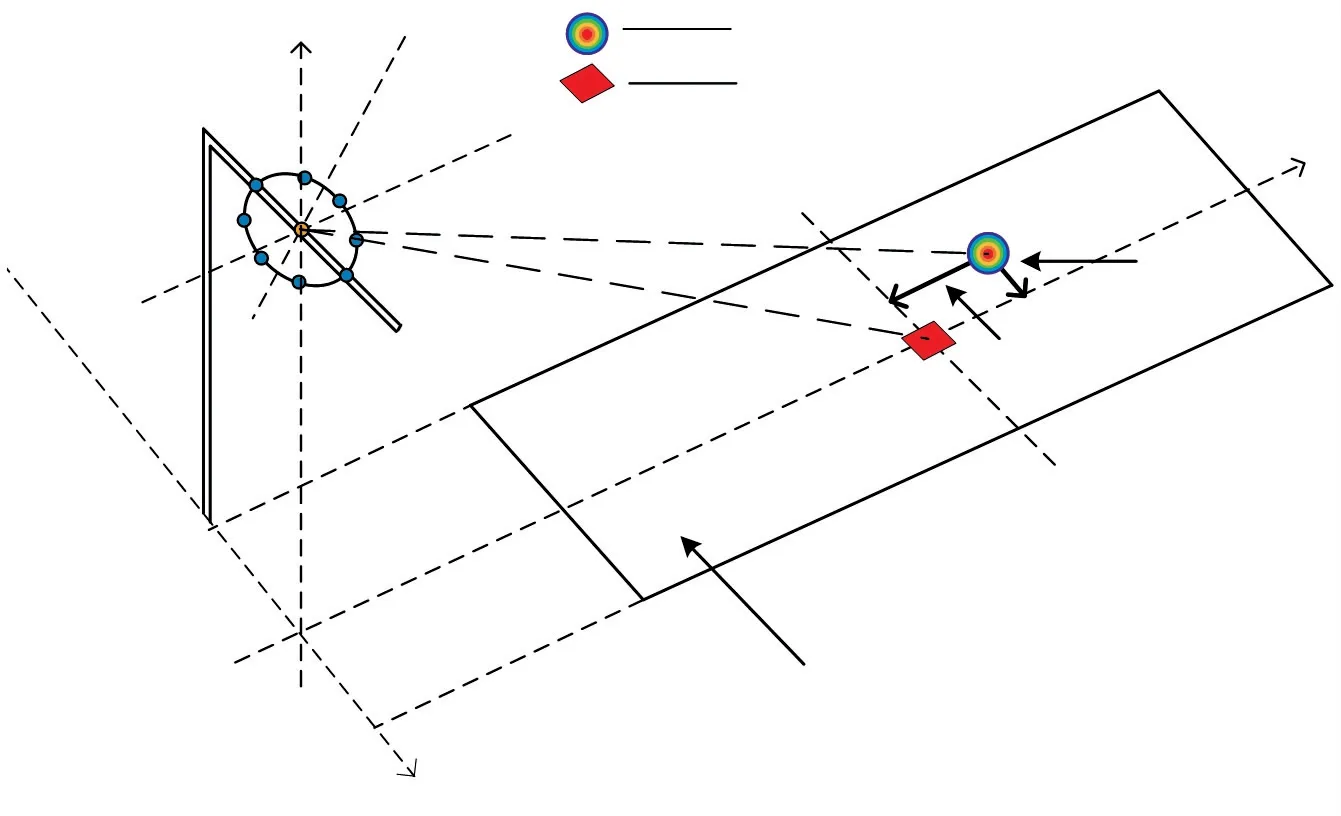
圖1 定位誤差示意圖
如圖1 所示,以鳴笛監測系統的攝像頭到路面的豎直投影點為原點Ow,道路的橫向方向為x軸,縱向方向為y軸,建立直角坐標系Owxwyw,S(X0,Y0)為鳴笛聲源的實際位置坐標,P(X1,Y1)為偽彩圖中心位置的世界坐標。 則鳴笛監測系統的橫向定位誤差定義為:

縱向定位誤差定義為:

2020 年中國計量科學研究院等單位起草的《機動車鳴笛監測系統檢定規程》送審稿中規定:鳴笛監測系統對聲源的橫向定位誤差不應超過0.6 m,縱向定位誤差不應超過1.5 m。
1.2 定位誤差檢測步驟
對鳴笛監測系統生成的聲相云圖進行算法處理,計算其Err(x)和Err(y),主要分為兩個步驟:一是運用訓練好的網絡模型預測聲相云圖,對鳴笛聲源與偽彩圖進行識別分割,獲取兩者的預測像素點所占區域,采用加權平均的方法分別將像素橫縱坐標累加求均值,得到鳴笛聲源和偽彩圖的中心像素坐標。 二是結合相機參數和鳴笛監測系統的安裝參數,通過幾何關系將聲相云圖中的像素坐標換算為對應的世界坐標,進而通過式(1)、式(2)計算Err(x)及Err(y)。 檢測方法的流程如圖2 所示。
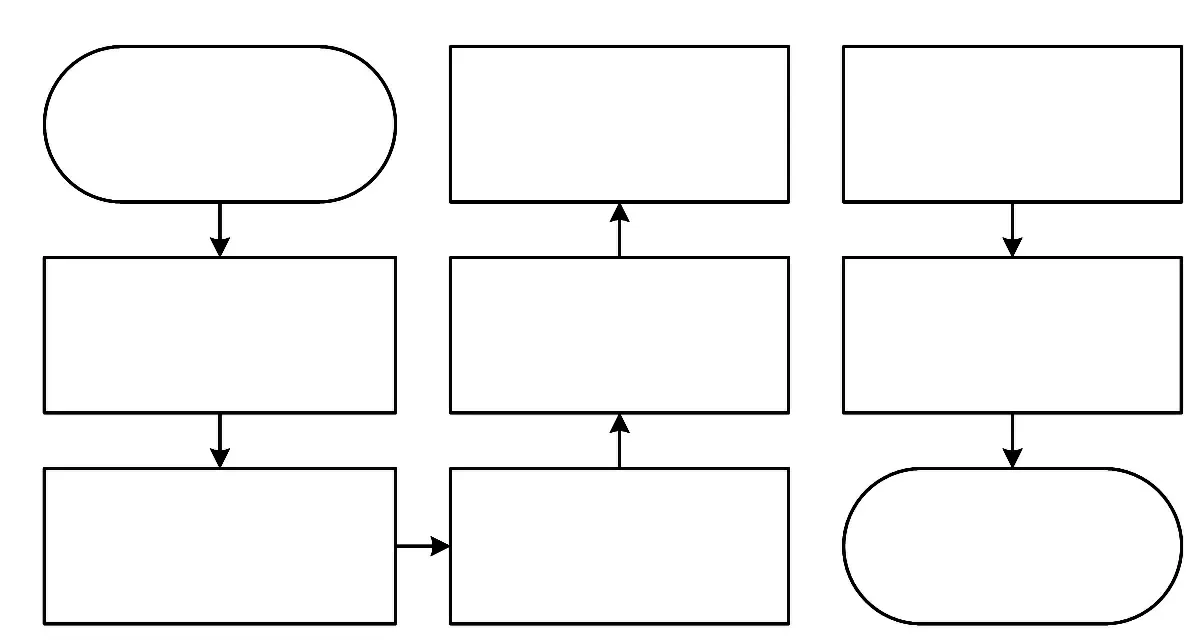
圖2 檢測方法流程圖
2 基于DeepLabv3+的定位誤差檢測
2.1 改進的DeepLabv3+網絡結構
DeepLabv3+在DeepLabv3 的基礎上添加一個解碼器模塊,使網絡沿對象邊緣的分割效果有明顯的提升。 并在編碼器部分引入了空洞卷積,加大感受野,豐富了每個卷積的輸出信息[14-15]。 然而,在模型分割過程中,DeepLabv3+對目標區域及特征沒有側重學習,容易漏檢感興趣的區域,而聲相云圖中鳴笛聲源與偽彩圖所占的像素范圍極為接近,不易分割。 因此,本文在主干特征提取網絡和ASPP 模塊之間添加了通道注意力機制模塊[16]。 該模塊可對特征圖中的不同通道賦予不同的權重,增加通道間的差異,并通過全局最大池化和全連接層等獲取相應通道的權值特征,提高特征提取精度。 另外,本文需要分割的類別僅有聲源、偽彩圖及背景三種,故將主干網絡由傳統的Xception 更換為MobileNetV2,兩者均使用深度可分離卷積,而MobileNetV2 大大減少了參數量[17],并且使用ReLU6 激活函數保證網絡結構的數值分辨力,改進的DeepLabv3+網絡結構如圖3 所示。
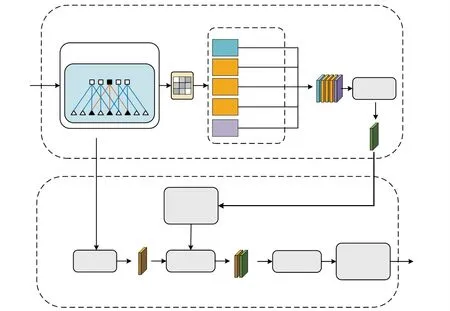
圖3 改進DeepLabv3+網絡
2.2 網絡訓練及其評價指標
將鳴笛監測系統在不同情況下抓拍的聲相云圖作為數據集(圖4),分辨率均為640×480。 選取500張圖片,使用LabelMe 軟件將其整理為VOC 格式。隨機選取數據集中350 張圖片用作訓練集,75 張用作驗證集,75 張用作測試集。

圖4 數據集中的聲相云圖
本文在深度學習框架Keras 環境下完成網絡的訓練和測試,編程語言為python3.6,使用Intel(R)Core(TM)i7-8700 處理器,NVIDIA GeForce RTX 2060 顯 卡, 在 Windows10 操 作 系 統 下 運 用CUDA10.0 與cuDNN7.4 加速改進DeepLabv3+網絡訓練。 模型收斂后,調用生成的權重文件對測試集圖片進行測試,對測試圖片中的目標物體進行劃分并用不同顏色標記,圖5 為實際測試效果。

圖5 改進DeepLabv3+算法的定位結果
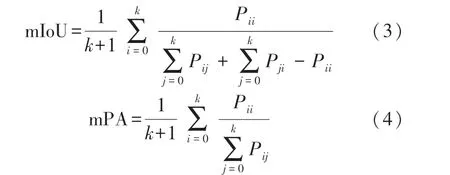
本文使用平均交并比(Mean Intersection over Union,mIoU)和平均像素精度(Mean Pixel Accuracy,mPA)作為模型的性能評價指標,具體公式如下:式中:k表示像素分類類別,Pii表示屬于i類被預測為i類的像素總數,Pij表示屬于i類被誤判為j類的像素數量,Pji表示屬于j類被誤判為i類的像素數量。 式(3)得到各類別預測值與真實值之間重合度的均值,式(4)得到各類別被正確分類的像素數量所占比例的均值。
將測試集的圖片輸入DeepLabv3+和增加注意力機制的改進DeepLabv3+網絡模型,并計算其mIoU 和mPA,結果如表1 所示。
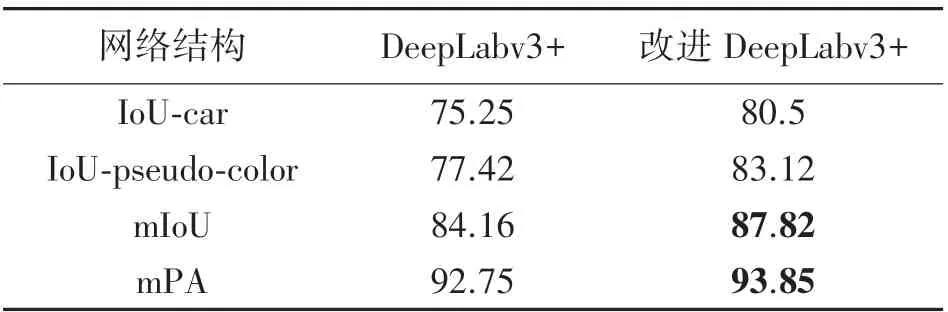
表1 改進前后性能對比 單位:%
改進DeepLabv3+算法較原始DeepLabv3+算法有更優秀的表現,mIoU 為87.82%,mPA 為93.85%。在各個類別的分割精度方面,改進DeepLabv3+算法對偽彩圖的分割效果最優,IoU 可達83.12%,提升了5.7%。
2.3 坐標系轉換方法
鳴笛監測系統安裝好后,其相機參數(水平視場角β、垂直視場角θ)、安裝參數(俯仰角α、安裝高度H)可測量標定獲得,如圖6 所示。
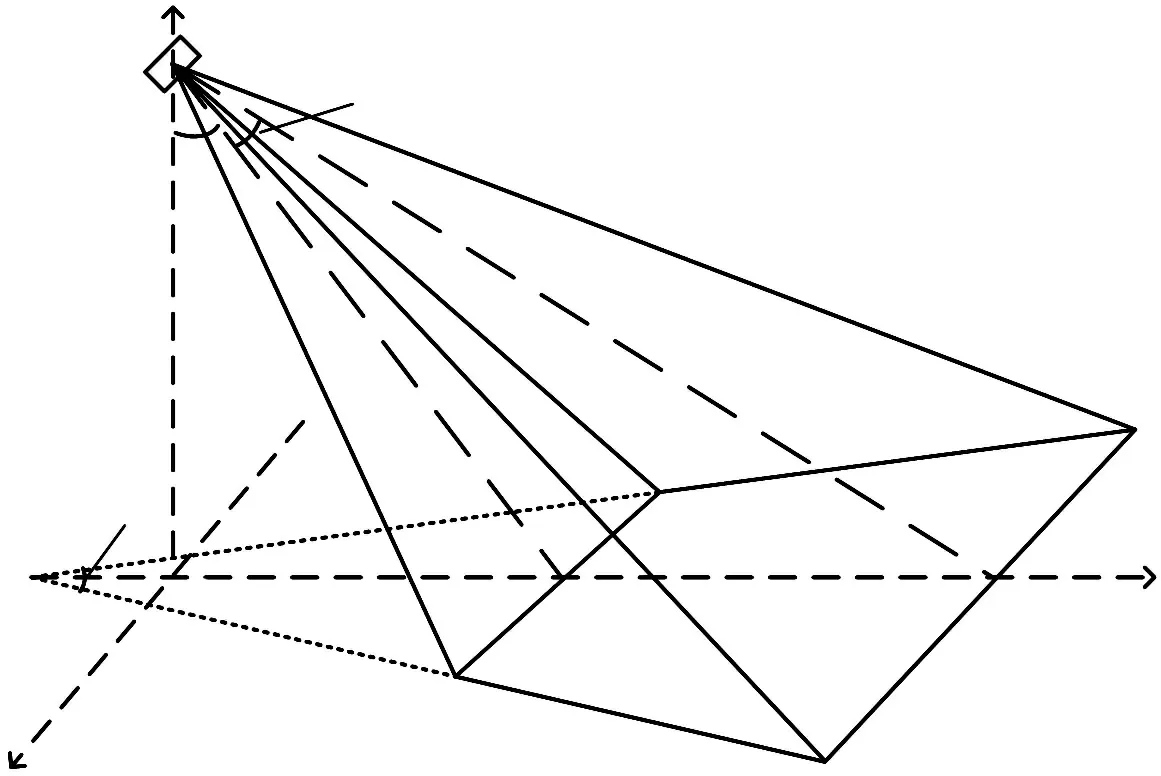
圖6 鳴笛監測系統參數示意圖
通過幾何推導法,得到像素坐標與世界坐標的映射關系[18],可將聲相云圖中的像素坐標轉換為世界坐標系下平行路面的坐標,以偽彩圖中心坐標為例,原理如圖7 所示。
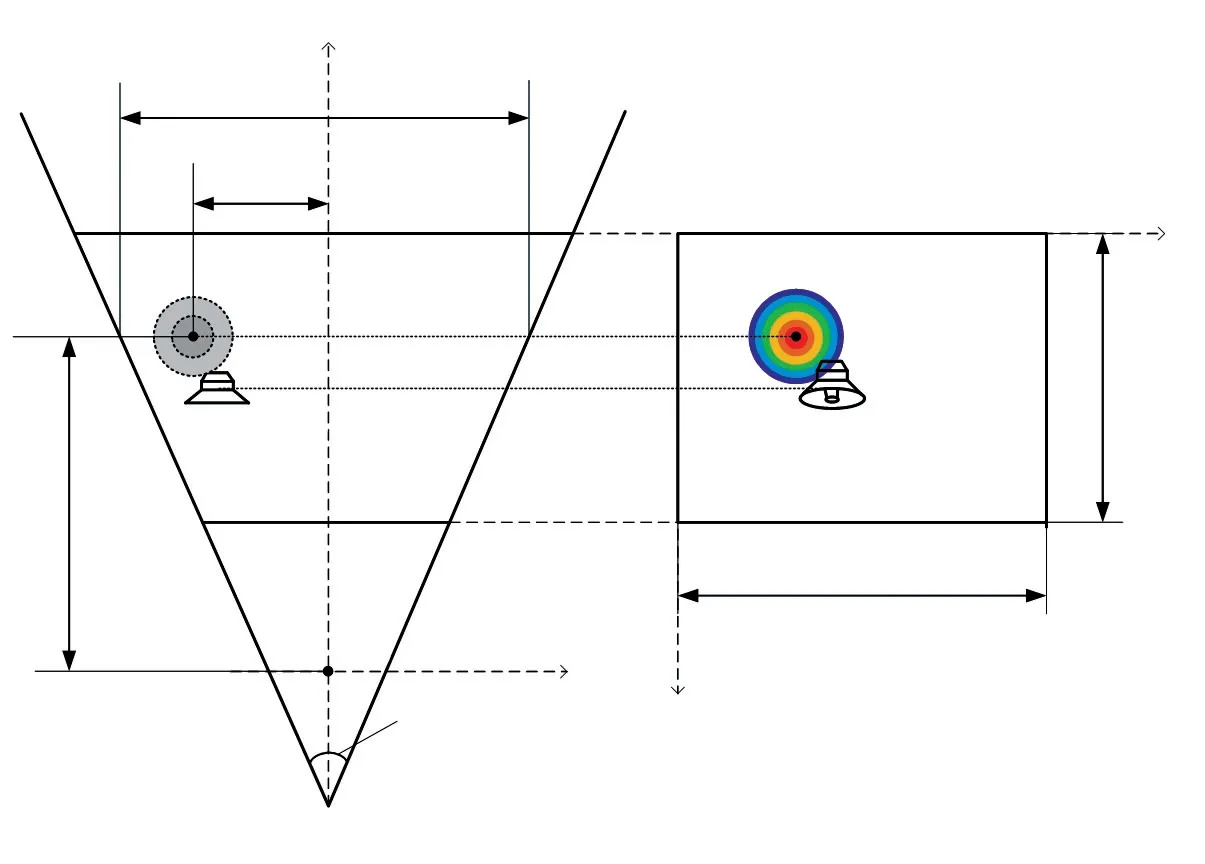
圖7 幾何轉換原理
已知鳴笛監測系統的安裝參數和相機參數后,根據攝像頭的垂直視場角θ設定步進小角度Δθ,可表示為:
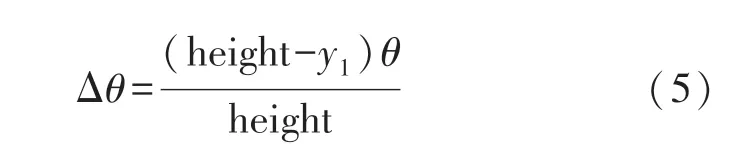
式中:height 為聲相云圖的像素高度,y1為聲相云圖
中偽彩圖中心的縱坐標值。 由此可得到Owxwyw坐標系中的偽彩圖中心縱坐標為:
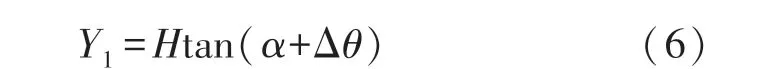
定義Xmax為鳴笛監測系統在距離Y1處對應的實際水平視野寬度,如圖7(a)所示,其計算方式為:
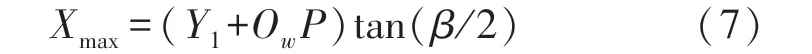
式中:OwP可根據相似三角形經簡單運算后求得,則Owxwyw坐標系中的偽彩圖中心橫坐標為:
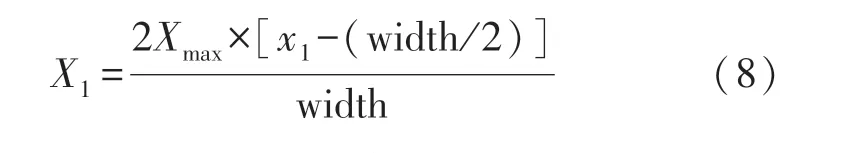
式中:width 為聲相云圖的像素寬度,x1為聲相云圖中目標點的橫坐標值。 綜上,偽彩圖中心像素坐標P(x1,y1)得以轉換為對應的世界坐標P(X1,Y1)。此外,在實際應用場景中,鳴笛聲源往往距離地面有一定的高度,此時需要通過相似三角形原理計算出鳴笛聲源高度為h時的偽彩圖中心的世界坐標P(X′,Y′)。

3 鳴笛聲定位實驗結果與分析
為研究鳴笛監測系統在實際使用過程中的定位性能,設計鳴笛聲源分別在固定位置及運動狀態下開展實驗。 實驗系統如圖8(a)、8(b)所示,包括鳴笛監測系統、鳴笛聲源、聲源支架、工具車和計算機等。 聲源頻率為3.18 kHz。
3.1 靜態定位實驗
在室外道路上,將鳴笛監測系統安裝于6.5 m的支撐桿上,在鳴笛監測系統的視野范圍內設置12個位置,如圖8(c)所示。 將鳴笛聲源固定于高0.6 m 的支撐架上,模擬汽車喇叭的高度,分別放置在各個位置上,依次鳴笛獲取定位數據。
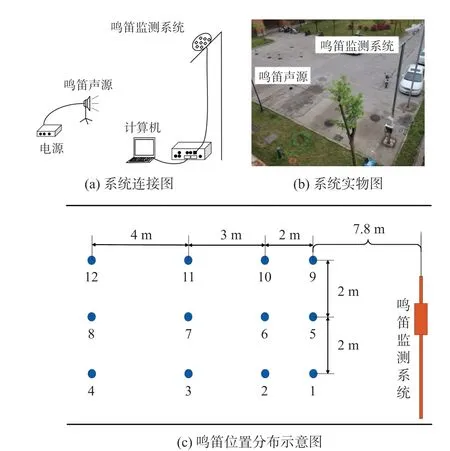
圖8 定位誤差檢測實驗
將聲相云圖送入改進DeepLabv3+模型進行預測,獲得圖像中鳴笛聲源和偽彩圖所占的像素位置,再分別求取中心坐標,最后根據幾何推導法轉換為世界坐標,計算鳴笛監測系統的Err(x)及Err(y)。將本文方法計算所得的結果與實際定位誤差對比,結果如圖9 所示。
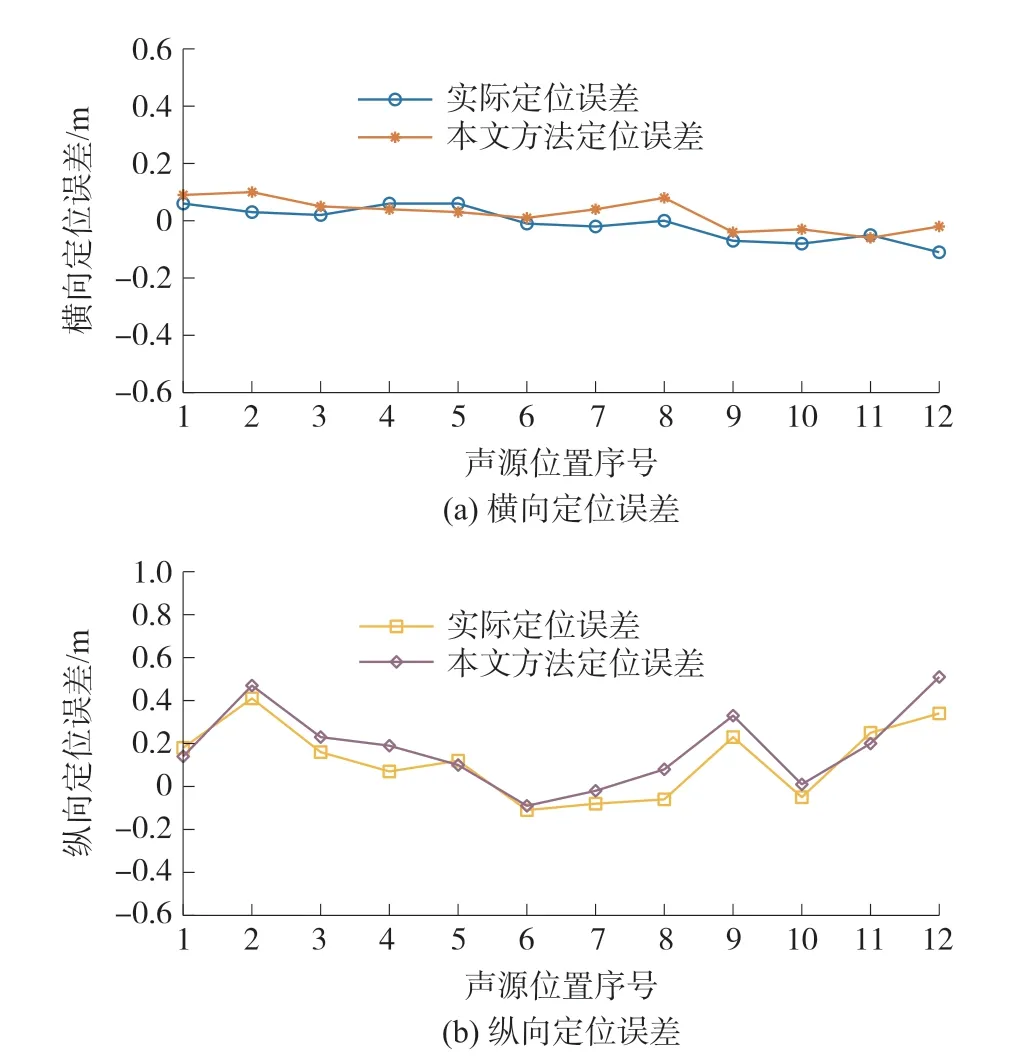
圖9 本文方法與實際靜態定位誤差對比
由圖9 可知,本文方法求得的定位誤差與實際定位誤差對比差異較小,兩者Err(x)的差值和Err(y)的差值均在12 號位置處最大,分別為0.09 m和0.17 m。 在距離鳴笛監測系統7.8 m ~16.8 m,橫向寬度4 m 的范圍內,本文方法能夠滿足聲源定位誤差檢測精度要求。
3.2 動態定位實驗
為檢測鳴笛監測系統的動態定位誤差,使用工具車搭載鳴笛聲源以30 km/h 的速度面向鳴笛監測系統運動,在經過上述12 個位置點(圖8(c))的同時控制鳴笛聲源工作,觸發鳴笛監測系統對其進行抓拍,保存聲成像視頻,提取對應幀圖像后運用本文方法計算每個位置點的動態定位誤差,與實際的定位誤差比較,結果如圖10 所示。
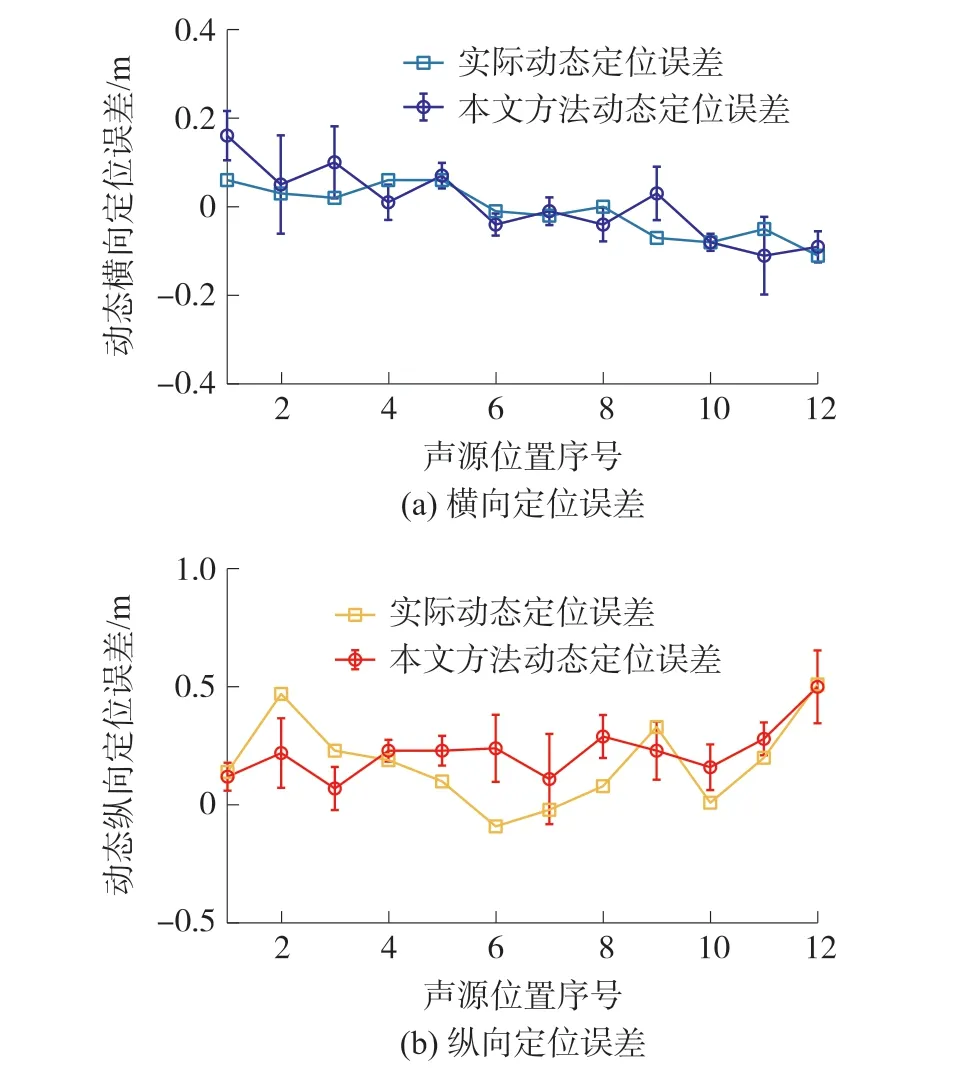
圖10 本文方法與實際動態定位誤差對比
圖10 中將本文方法計算的動態定位誤差求取平均值和標準差,作誤差棒圖。 與實際定位誤差對比,本文方法對動態橫向定位誤差檢測結果與真實值的差值最大為0.1 m,標準差為0.05 m;對動態縱向定位誤差檢測結果與真實值的差值最大為0.35 m,標準差為0.14 m,本文方法能夠滿足現場檢測要求且具有一定的穩定性。
為進一步研究鳴笛監測系統對于不同運動方向聲源的抓拍能力,在圖8(c)的5 號~8 號位置點處,分別使鳴笛聲源以10 km/h、20 km/h 以及30 km/h的速度相對鳴笛監測系統做運動,經本文方法計算Err(x)及Err(y),將結果進行對比,如圖11 所示。
由圖11 可知,在不同的運動方向下,Err(x)的差異最大值為0.12 m。 Err(y)差異較大,具體表現為聲源靠近鳴笛監測系統時的Err(y)為聲源遠離時的21%~67%,且不同方向的定位誤差結果不同,聲源靠近鳴笛監測系統時,定位距離比實際距離大,聲源遠離時比實際距離小。 這是由于聲源置于工具車前部,遠離鳴笛監測系統鳴笛時,聲波經過車體一系列吸收、反射后被傳聲器陣列接收,影響定位性能。
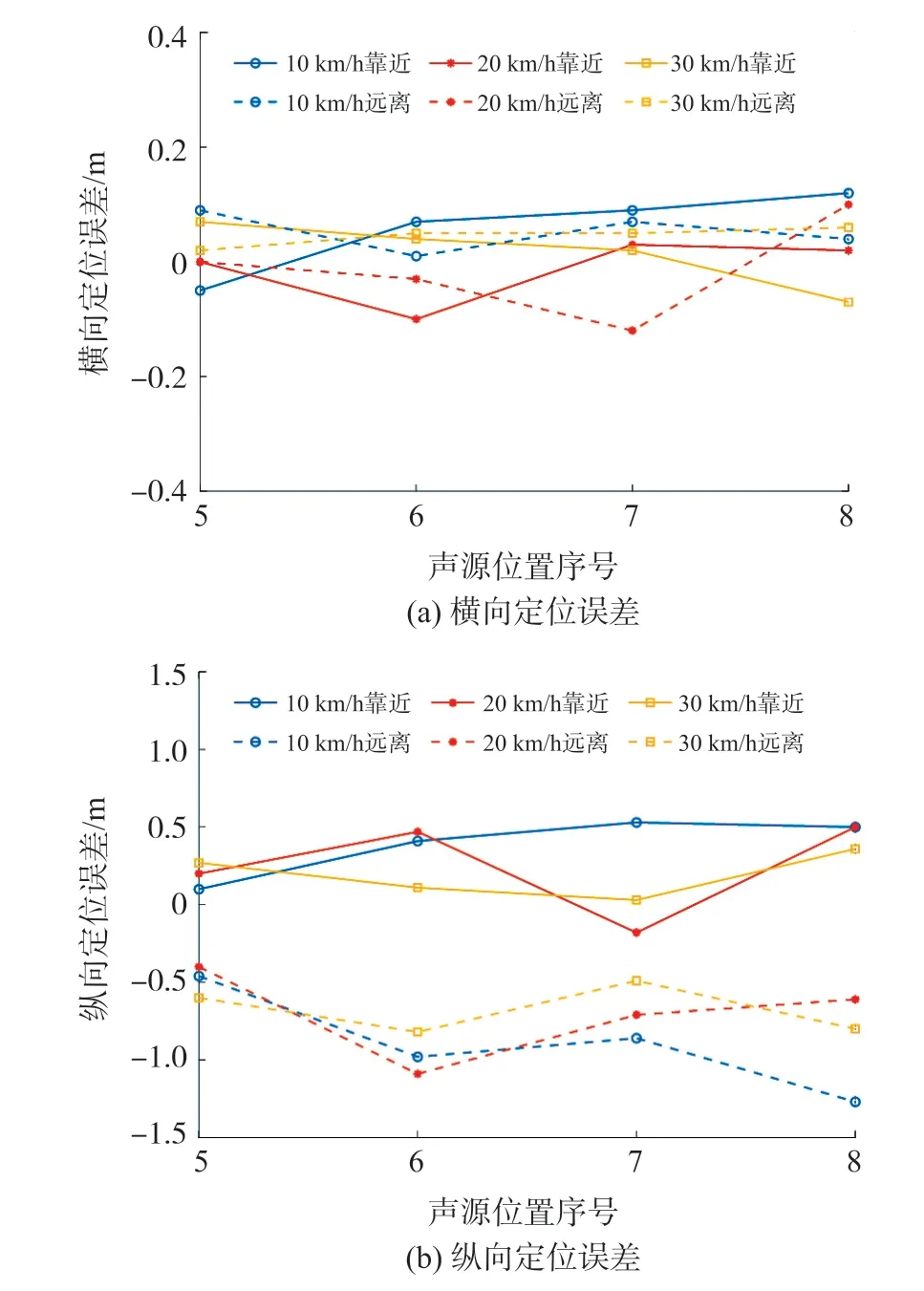
圖11 不同運動方向定位誤差對比
4 結語
本文將語義分割算法應用到聲相云圖中聲源和偽彩圖的識別定位,并結合幾何關系推導演算,提出了一種基于改進DeepLabv3+的定位誤差檢測方法。實驗結果表明,改進DeepLabv3+網絡對聲相云圖的背景有更強的抗干擾能力,運用本文方法對鳴笛監測系統進行定位誤差檢測,在聲源固定的情況下,與真實值的最大誤差為0.17 m。 對動態定位誤差檢測的最大引入誤差為0.35 m,能夠滿足鳴笛監測系統定位誤差檢測精度要求。
本文對鳴笛監測系統的動靜態定位誤差進行研究,而空間分辨力等其他參數,涉及多個聲源同時鳴笛的情況,將在后續的研究工作中開展。
猜你喜歡
工業設計(2022年8期)2022-09-09 07:43:20
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
軍民兩用技術與產品(2021年10期)2021-03-16 06:05:30
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
北京測繪(2020年12期)2020-12-29 01:33:58
裝備制造技術(2019年12期)2019-12-25 03:06:46
中國洗滌用品工業(2019年4期)2019-05-11 09:27:34
