基于TextRNN 與TextCNN 的情感分類對比研究
2022-10-21 14:01:38付甜甜劉海忠
科學技術創新 2022年30期
付甜甜,劉海忠*
(蘭州交通大學 數理學院,甘肅 蘭州 730070)
引言
情感分類是根據人們對特定的對象或實體發布的觀點、意見、態度等進行信息提取的計算性研究過程[1],屬于文本分類的子問題。情感分類在輿情分析方面、產品及服務方面,能夠輔助網絡環境的監控和產品服務的改進。情感分類的研究方法主要有基于情感詞典的方法、基于機器學習的方法和基于深度學習的方法[2]。由于情感詞典和機器學習需要構建詞典和龐大的特征工程,因而深度學習算法在情感分類中變得十分流行。
深度學習算法以低維連續的詞向量來表示文本,解決了數據稀疏問題和特征構建的復雜問題。Moraes等[3]對支持向量機SVM和人工神經網絡ANN 進行了文檔分類的對比實驗,結果表明ANN 的分類準確率比SVM要高。Kim[4]提出了使用文本卷積神經網絡(Text Convolutional Neural Networks,TextCNN) 進行句子級情感分類,發現TextCNN 能夠快速高效地完成文本分類任務。Liu 等[5]基于文本循環神經網絡(Text Recurrent Neural Network,TextRNN)提出三種不同的信息共享機制來對文本數據進行建模。梁軍等[6]討論了在中文微博情感分類任務上使用深度學習算法的可行性。同時情感分類算法也在通過對預訓練模型微調或融入注意力機制等方式[7]進行改進,而情感分類的融合算法大多建立在CNN,RNN 等模型上。主層算法的選擇一定要依照任務特點和數據特征來構建,本研究對比CNN 和RNN 兩個典型算法的表現來為主體算法的選用提供參考。
1 模型介紹
1.1 TextRNN
TextRNN 是用RNN 來處理文本分類問題。RNN能夠順序地讀取文本序列數據,具有一定的記憶能力。本研究RNN 模型選用雙向長短時記憶網絡BiLSTM來進行實驗。LSTM是RNN 的變體,它通過控制遺忘門、輸入門和輸出門三個門結構及細胞單元狀態來控制數據信息的加工,可以避免梯度消失問題。BiLSTM擁有更大的感受野,雙向提取語義關聯信息以獲得高層特征表示。在建模時,一組向量分別作為正向和反向LSTM的輸入:
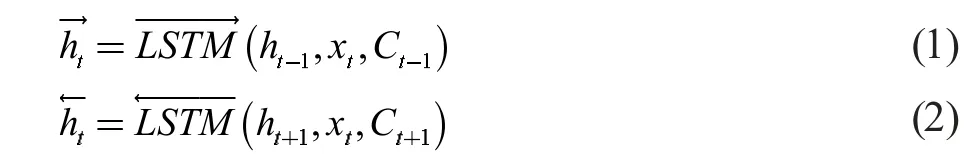
連接正反方向LSTM處理后的序列輸出,BiLSTM在t 時刻的輸出則表示為:

TextRNN 模型結構見圖1,單詞先通過嵌入層轉化為特征詞向量,然后使用BiLSTM 對序列張量進行信息提取。將BiLSTM 的最初時間步和最后時間步的隱藏單元連結,作為特征序列的表征傳輸到全連接層再進行分類。

圖1 TextRNN 結構
1.2 TextCNN
CNN 提取特征信息時可以把文本數據理解為一維圖像,卷積核在文本表示矩陣上上下滑動來進行特征提取。句子向量化得到矩陣V(wi),采用Fk=k*d 維卷積核與其進行卷積計算

ci表示經過一次卷積計算得到的局部特征值,滑動一輪后得到一個完整的局部特征向量C。為了降低向量維度,卷積后還要進行池化操作。
TextCNN 模型結構見圖2,先將單個文本序列輸入轉換為詞向量矩陣輸出,然后定義多個尺度的卷積核,分別執行卷積操作。在所有輸出通道上執行時序最大池化,將所有池化后的特征向量匯聚連結為新的特征向量,最后放入全連接層進行分類。
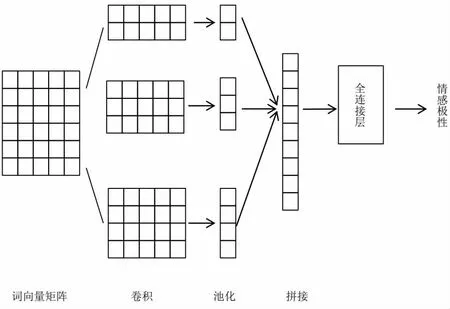
圖2 TextCNN 結構
2 數據說明及處理
本研究實驗使用IMDB 數據集,包含來自互聯網電影數據庫的50 000 條評論數據,情感類別為positive 和negative,按照1:1 劃分為訓練集與測試集。首先對數據中的標點符號和無用字符進行清洗,隨后進行分詞操作并過濾掉出現頻率少于5 次的單詞,然后創建一個屬于訓練集的詞典。由于評論長短不一,通過截斷和填充將每條評論的長度都控制在500 個單詞,分詞后進行向量化。使用斯坦福的Glove 預訓練詞向量來做嵌入,包含了400 000 個單詞的嵌入向量,在訓練期間不更新詞向量。
3 實驗與分析
3.1 參數設置
TextRNN 是一個具有一層嵌入層、兩層隱藏層和一層全連接層的雙向神經網絡。隱藏單元數設為100,學習率設為0.01,batch_size 為64,epoch 為5。
TextCNN 使用兩個嵌入層,其中一個是可訓練權重,另一個是固定權重;三個卷積層,卷積核大小分別為[3,4,5],每個卷積核的數量為100,通道數為100,步長為1,使用RELU 激活函數;池化層采用時序最大池化,后面接上全連接層。dropout 設置為0.5,學習率設為0.001,batch_size 為64 ,epoch 為5。
3.2 機器學習對比模型
利用機器學習的邏輯回歸模型LR、支持向量機模型SVM 和樸素貝葉斯模型NB 對實驗數據進行分類,結果見表1。本研究實驗均采用分類準確率來評估分類效果。可以看出在IMDB 數據集上三個算法的測試結果并不是很理想,其中SVM的分類準確率只有51.12%,LR 和NB 可以達到75%左右。

表1 機器學習模型準確率
3.3 對比模型說明
LSTM:含雙層隱藏狀態的單向網絡,其余參數設置與TextRNN 相同。
TextCNN_1:由卷積核大小為3*3 的3 個同類型卷積核構成,其余設置與TextCNN 完全相同。
TextCNN_2:由卷積核大小為4*4 的3 個同類型卷積核構成。
TextCNN_3:由卷積核大小為5*5 的3 個同類型卷積核構成。
3.4 實驗結果與分析
與機器學習相比,深度學習算法不僅特征構建更為簡單,分類準確率也會有大幅提升。下面結合表格數據來進行詳細分析。在預訓練詞向量維度分別為50和100 時,各模型分類準確率見表2。
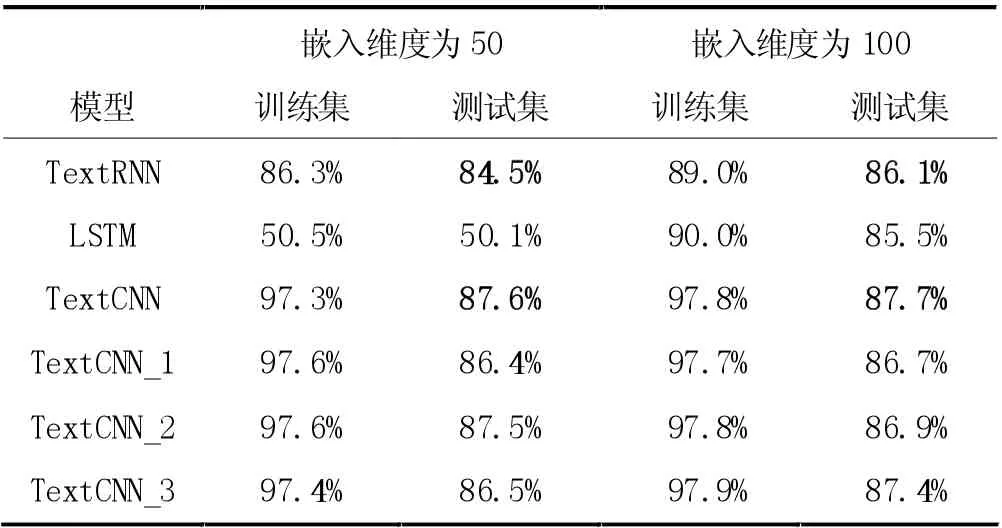
表2 各算法分類準確率
當詞嵌入維度為50 時,TextRNN 在測試集上的分類準確率為84.5%,而LSTM只有50.1%。TextCNN的分類準確率為87.6%,比TextRNN 高出3.1%。使用同類型卷積核的三個TextCNN 模型分類準確率分別為86.4%、87.5%、86.5%,結果相差不大,但準確率都要比RNN 高。
在詞嵌入維度為100 時,發生顯著變化的是LSTM,分類準確率提升了35.4%,達到了85.5%,而TextRNN 的分類準確率達到了86.1%,比單向算法的準確率高0.6%。TextCNN 的準確率達到87.7%,較三個使用同類型卷積核的TextCNN 要高一些,同樣CNN的整體表現結果比RNN 要好。
實驗結果表明,當詞嵌入維度從50 維增加到100維時,所有模型在訓練集和測試集的準確率都有所上升,說明嵌入維度是影響分類結果的一個重要因素。同時TextRNN、TextCNN 的分類結果比機器學習的最好結果高出10%左右。
4 結論
本研究在介紹TextRNN 與TextCNN 模型的基礎上,分別對文本進行特征提取及分類。在本研究所使用的數據集上,TextCNN 擁有更高的分類準確率和穩健性,TextRNN 采用雙向提取時表現結果也不錯。結合各自的特點來講,由于TextCNN 通過多尺度的卷積核組合進行特征提取,比起使用同類型卷積核的提取限制,對局部特征的提取更為精準細致。而RNN 更擅長處理長序列數據,獲取更大范圍的上下文信息。情感分類任務進行算法選擇時,短文本可以選取多尺度卷積核組合的TextCNN,長文本選擇雙向提取的TextRNN 會取得相對較高的準確率。
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中國生殖健康(2020年5期)2021-01-18 02:59:48
北極光(2019年12期)2020-01-18 06:22:10
小太陽畫報(2019年10期)2019-11-04 02:57:59
制造技術與機床(2019年10期)2019-10-26 02:48:08
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
電子制作(2018年18期)2018-11-14 01:48:06
中國生殖健康(2018年5期)2018-11-06 07:15:40
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
