基于基原效用差異的黃連品質辯識光譜化學表征模型構建
2022-10-21 06:44:46齊路明董繼晶馬云桐
中草藥 2022年20期
關鍵詞:模型
黃 玲,齊路明,王 科,李 娜,董繼晶,馬云桐*
基于基原效用差異的黃連品質辯識光譜化學表征模型構建
黃 玲1,齊路明2,王 科3,李 娜1,董繼晶1,馬云桐1*
1. 成都中醫藥大學藥學院,四川 成都 611137 2. 成都中醫藥大學養生康復學院,四川 成都 611137 3. 成都工業學院大數據與人工智能學院,四川 成都 611730
中藥多基原物種間的效用差異性受到歷代醫家的高度重視,聯用傅里葉變換近紅外光譜(fourier transform near infrared spectroscopy,FT-NIR)和傅里葉變換中紅外光譜(fourier transform mid-infrared spectroscopy,FT-MIR)技術,考察光譜化學表征技術應用于多基原黃連共有物質基礎測定和品質辨識的可行性。以黃連的4種基原(黃連、三角葉黃連、峨眉野連和云南黃連)的共有物質基礎小檗堿、黃連堿、木蘭花堿、非洲防己堿和巴馬汀為研究對象,基于光譜矩陣的優化和特征學習算法,串聯近紅外和中紅外光譜特征構建偏最小二乘回歸(partial least squares regression,PLSR)和支持向量回歸(support vector regression,SVR)光譜化學表征模型以測定藥材中共有活性成分的含量,辨識其品質差異。SVR模型對小檗堿的測定效果最優,剩余預測偏差(residual predictive deviation,RPD)值高達4.842,模型對黃連堿、巴馬汀和木蘭花堿含量的預測RPD值均大于2;PCA結果表明所建立的模型能有效鑒別多基原黃連共有成分含量的差異,為其品質辨識提供依據。多元光譜技術串聯應用可有效表征多基原黃連藥材中共有成分的含量差異,提高多基原中藥品質辨識的效率。
黃連;三角葉黃連;峨眉野連;云南黃連;紅外光譜技術;偏最小二乘回歸;支持向量回歸;光譜化學表征模型;小檗堿;黃連堿;木蘭花堿;非洲防己堿;巴馬汀
黃連為黃連Franch.、三角葉黃連C. Y. Cheng et Hsial、云南黃連Wall.、峨眉野連C. Y. Cheng等黃連屬植物的干燥根莖。依據古代典籍記載,雖然這些資源均可當作黃連藥材使用,但其具體生物效用有較大差異。如《唐本草》記載:“黃連,蜀道者粗大,味極濃苦,療渴為最;江東者節如連珠,療痢大善”,指出川產黃連具有較好的治療糖尿病的效果,而長江以東的黃連則更善于抑菌止痢。目前相關研究已經提供有力的證據,指出導致不同基原黃連藥材效用差異的主要原因表現為其共有物質基礎的含量差異[1-2]。結合課題組前期研究,次生代謝產物類型的相似性是不同基原黃連屬植物根莖可作為同一中藥使用的基礎,也是其均可用于治療糖尿病、阿爾茨海默癥等疾病的重要原因。原小檗堿類生物堿為黃連藥材的主要化學成分群,包括小檗堿、黃連堿、木蘭花堿、巴馬汀和非洲防己堿等[3-4],這些活性成分的含量差異正是多基原黃連效用同中有異的主要原因。對該類化學成分的含量進行有效表征,可明確不同來源黃連藥材共有物質基礎的差異,為其品質差異鑒別提供有效的證據,并且對于該藥材資源的合理利用具有積極的意義。
針對中藥復雜體系中物質基礎成分的快速測定,科研工作者已經進行了許多有益探索。其中,光譜技術表現出巨大的潛力。相對而言,該技術操作簡單,無需樣品試劑損耗,且能夠全面展示樣品中的代謝成分信息,是一種綠色環保的測定方法。但是中藥的光譜信息變量復雜,易于受到外界因素干擾,如何從復雜的光譜變量矩陣中提取目標變量是阻礙其進一步應用的關鍵問題。目前,多種化學計量學的方法已經應用于光譜數據的優化,以求簡化高維的變量矩陣并提高其可用性。例如多種優化去噪、特征學習和信息融合的算法,都是提升光譜技術應用潛力的有效方法[5-7]。通常而言,一套完整的光譜矩陣分析流程十分復雜,包括預處理、異常值診斷、特征學習和數學模型構建等多個步驟,且需要進行嚴格的優化。迄今,光譜化學表征技術在多基原黃連藥材共有化學成分測定及其品質差異的辨識上的應用相對較少。
基于此,本研究結合課題組前期研究中的高效液相色譜數據[8],選擇多基原黃連藥材中主要共有化學成分小檗堿、黃連堿、木蘭花堿、非洲防己堿和巴馬汀,考察光譜化學表征技術應用于多基原黃連共有活性成分測定和品質辨識的可行性。應用傅里葉變換近紅外光譜(fourier transform near infrared spectroscopy,FT-NIR)和傅里葉變換中紅外光譜(fourier transform mid-infrared spectroscopy,FT-MIR)技術采集不同基原黃連藥材的光譜信息,結合化學計量學算法,構建一套完整的光譜矩陣分析流程。偏最小二乘回歸(partial least squares regression,PLSR)和支持向量回歸(support vector regression,SVR)算法被用來建立該藥材的光譜化學含量的表征模型,考察其與高效液相色譜數據的相關性,探討紅外光譜應用于該類化學成分快速測定和差異辨識的可行性,為多基原黃連藥材的品質辨識提供依據。
1 材料與儀器
1.1 樣品
所用黃連藥材來源于4種黃連屬植物,經成都中醫藥大學馬云桐教授鑒定,分別為黃連Franch.、三角葉黃連C. Y. Cheng et Hsial、峨眉野連C. Y. Cheng和云南黃連Wall.。前3種植物采集于四川省洪雅縣黑山村人工種植基地,云南黃連采集于云南省福貢縣匹河鄉人工種植基地,采集樣品均為5年生植物。在其藥材采收期收集并參照產地加工方法,取其根莖部位,洗凈后60 ℃烘干,保存在陰涼干燥處。得到4種黃連藥材分別稱為味連、雅連、野連和云連。
1.2 儀器與試劑
PerkinElmer傅里葉近紅外和中紅外光譜儀(美國珀金埃爾默儀器有限公司),DFT-50A型手提式高速粉碎機(林大機械有限公司,浙江溫嶺),電子天平(賽多利斯科學儀器有限公司,北京),LC-20A型高效液相色譜儀(日本島津公司)。對照品小檗堿(批號110713-201814)購自于中國食品藥品檢定研究院,木蘭花堿(批號CHB180205)、非洲防己堿(批號CHB180712)、黃連堿(批號CHB180629)和巴馬汀(批號CHB180226)購于成都克洛瑪試劑公司,質量分數均≥98%。
2 方法
2.1 樣品檢測
稱取適量樣品,均勻放置于樣品杯中,應用傅里葉近紅外和中紅外光譜儀,分別采集FT-NIR和FT-MIR光譜特征。針對每一個樣品,檢測區間分別設定為10 000~4000 cm?1和4000~500 cm?1,儀器分辨率均為4 cm?1,信號累積64次。在樣品測定之前,首先測定空氣中水和二氧化碳引起的背景信號,并將其從樣品吸收峰中自動刪除。每一個樣品重復測定3次,平均光譜用于后續分析。色譜數據的測定參考課題組前期的研究成果[8]。
2.2 光譜數據分析流程
2.2.1 4種光譜預處理算法應用于原始光譜優化 平滑算法(11點),去除噪音信號[9];多元散射校正和標準正態變量,消除光散射影響[10];導數算法,減小基線漂移并增強樣品特征信息[11]。
2.2.2 異常值診斷 采用基于PLSR的Hotelling T2[12]檢驗診斷數據分布。首先基于和矩陣建立PLSR模型,根據T2值來甄別數據集中的異常值。當樣本的T2值高于99%置信區間,該樣本被設定為異常樣本并刪除。
2.2.3 數據標準化 光譜和色譜數據含有不同的量綱,將兩者數據標準化到同一數量級,能夠提升模型的收斂速度和增加準確性,因此將數據縮減至[-1,1]之間[13]。
2.2.4 光譜特征數據篩選與評價 紅外光譜數據變量復雜,代表樣品全面的化學信息,也會產生大量的無關信號,不僅增加模型運行時間,還會降低模型的準確性和推廣性。運用4種特征學習機器算法對光譜變量的重要性進行排序,分別是遞歸式特征消除(recursive feature elimination,RFE)[14]、Boruta算法[15]、變量投影重要性算法(variable importance in projection,VIP)[16]和基尼指數(gini coefficient,GINI)[17],應用十折交叉驗證評價特征變量數目。
2.2.5 特征信息融合:特征級數據融合是一種中等水平的融合策略,將來源于不同傳感器的特征信息加以綜合,可以產生比單一信息源更精確、更完全、更可靠的估計和判斷[18]。本研究將來源于FT-NIR和FT-MIR光譜的特征變量進行信息融合,進一步提高多基原黃連藥材共有化學成分表征模型的準確性和有效性。
2.3 光譜化學表征模型
首先應用PLSR[19]算法建立5種共有化學成分的光譜化學表征模型。該方法依據最大協方差原則,計算復雜矩陣中變量()和()之間的關系。該方法的優點是可以很好地克服多元共線性問題,將復雜的數據矩陣降維為若干互不相關的潛在因子(latent variable,LV)。LV的數目是PLSR的重要參數,基于交叉驗證結果確定該參數,建立光譜化學表征模型。
SVR[20]屬于基于支持向量機算法的關聯模型。依據結構風險最小化理論,構建最優分類面,以允許學習模型達到全局最優。對于線性不可分的數據集,該算法將數據映射到更高維的特征平面,以求得線性可分。核函數的引入是解決這個問題的關鍵,徑向基核函數可以有效地簡化計算的復雜性,提供更加滿意的準確度[21]。懲罰系數(penalty coefficient,c)和高斯核函數(gaussian kernel coefficient,g)是SVR模型中2個重要的參數。前者用于權衡算法的復雜性和偏差的關聯,后者為核函數的設置參數。通常情況下,2個參數的調節需要借助于調參算法。本研究選擇遺傳算法(genetic algorithm,GA)、粒子群優化算法(particle swarm optimization,PSO)和網格搜索算法(grid search,GS)調整SVR模型的參數,以求建立最佳光譜化學表征模型。
對于2種模型,主要評價參數為校正系數(correction coefficient,2)接近于1表明模型效果好;校正集均方根誤差(root mean square error of estimation,RMSEE)和預測集均方根誤差(root mean square error of prediction,RMSEP)分別用來評價校正集和驗證集結果的偏差;交叉驗證均方根誤差(root mean square error of cross validation,RMSCV)基于交叉驗證算法,用來估計回歸模型的推廣能力[22]。為保證模型的穩健性和防止模型過擬合,應用Kennard-Stone算法[23]將樣品數據分為訓練集和驗證集,前者用于構建化學表征模型,后者用于測試模型的推廣能力。剩余預測偏差(residual predictive deviation,RPD)是一個評價化學表征模型效果的常用參數,通常情況下,該值越高則表明模型的效果越好。當其超過2時,表明模型的預測效果較好[24]。
3 結果與分析
3.1 標準數據可視化結果
課題組前期研究結果表明,小檗堿、黃連堿、木蘭花堿、非洲防己堿和巴馬汀是不同基原黃連藥材的共有成分,也是其主要的物質基礎[3, 8]。依據高效液相色譜的測定,這5種化學成分的標準含量結果如圖1所示。
3.2 紅外光譜數據預處理結果
主要包括光譜數據優化、異常值篩選和數據標準化3個步驟。FT-NIR最好的預處理算法分別為二階導數、二階導數、不做處理、二階導數結合多元散射校正和一階導數;FT-MIR最好的預處理算法分別為二階導數、二階導數、二階導數、一階導數結合多元散射校正和一階導數結合標準正態變量,處理后的紅外指紋圖譜如圖2所示。以PLSR模型輸出結果為評價指標,對于黃連堿、木蘭花堿、小檗堿、非洲防己堿和巴馬汀的測定,FT-NIR和FT-MIR結果如表1和表2所示。
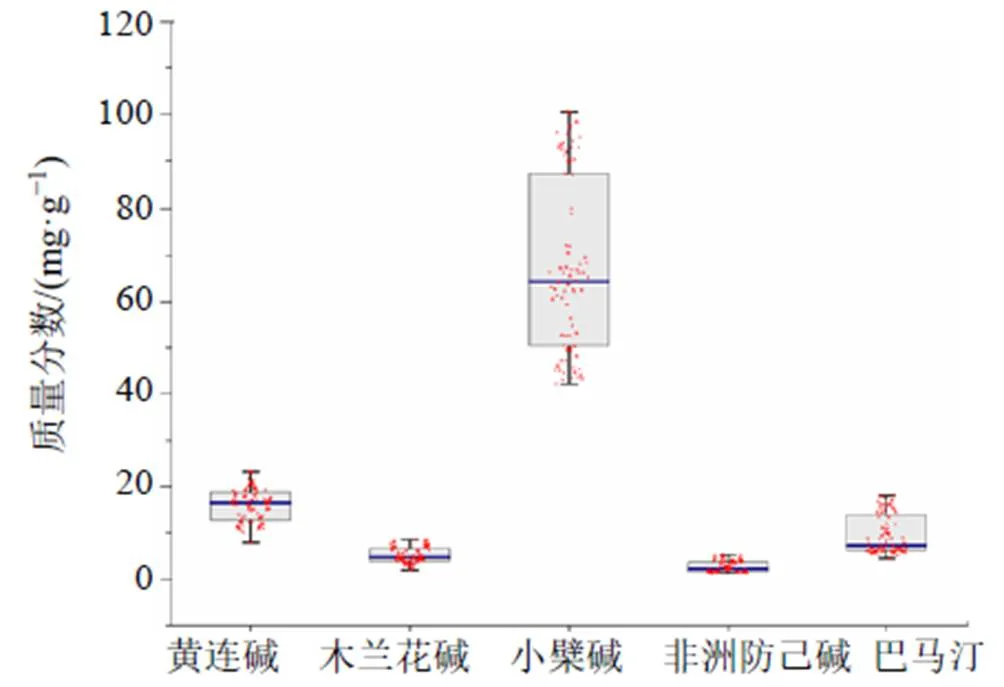
圖1 多基原黃連中5種共有成分的含量可視化
采用Hotelling T2檢驗監測離群點,結果如圖3所示。以T2 Crit(99%)為標準,分別從FT-NIR_黃連堿、FT-MIR_黃連堿、FT-NIR_小檗堿、FT-MIR_小檗堿、FT-NIR_巴馬汀、FT-MIR_巴馬汀、FT-NIR_非洲防己堿、FT-MIR_非洲防己堿、FT-NIR_木蘭花堿和FT-MIR_木蘭花堿的數據矩陣中檢測到0、1、3、0、3、0、2、0、1、0個離群點,分別有3個味連和野連的樣品。刪除異常值數據,對光譜數據進行歸一化處理。
3.3 特征選擇及評價
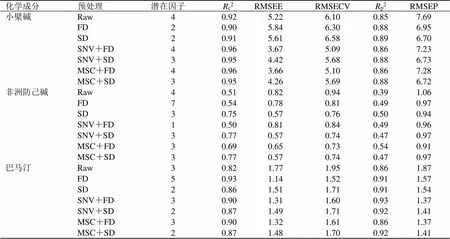
不同基原黃連藥材中5種物質基礎化學成分的數據矩陣均含有大量的信息,包括有效變量、無效變量和噪音變量。特征學習是獲取目標特征,去除無效信息的關鍵方法。本研究應用4種特征學習算法(RFE、BORUTA、VIP和GINI)對以上光譜數據集進行特征排序。按照固定的間隔,以重復3次交叉驗證計算的RMSE誤差為基準來篩選最優變量,以選擇出與黃連堿、小檗堿、巴馬汀、非洲防己堿、木蘭花堿成分關聯性強的特征變量,結果如表3所示。如表3所示,無論是近紅外還是中紅外光譜的數據矩陣,RFE和BORUTA算法都表現出較好的特征采集能力。其中RFE的模型值為0.074~0.131,針對FT-MIR_黃連堿、FT-MIR_小檗堿、FT-NIR_巴馬汀、FT-MIR_非洲防己堿和FT-NIR_木蘭花堿數據集,誤差率較低;BORUTA的模型RMSE值為0.077~0.130,針對FT-MIR_黃連堿、FT-MIR_小檗堿、FT-MIR_巴馬汀、FT-MIR_非洲防己堿和FT-MIR_木蘭花堿數據集,誤差率較低。對于VIP和GINI 2種特征選擇算法,其誤差率較高,評價效果較差。

圖2 預處理后的光譜指紋圖譜
表1 FT-NIR光譜優化后結果
Table 1 Results of FT-NIR after optimization
化學成分預處理潛在因子Rc2RMSEERMSECVRp2RMSEP 黃連堿Raw70.851.461.940.612.16 FD20.781.651.840.651.93 SD40.980.581.460.661.86 SNV+FD20.790.371.360.592.14 SNV+SD50.990.371.360.651.89 MSC+FD20.791.621.800.582.15 MSC+FD20.791.651.840.651.89 木蘭花堿Raw30.451.221.610.491.33 FD80.980.240.930.641.08 SD20.810.711.100.790.91 SNV+FD10.511.131.210.551.25 SNV+SD20.810.711.090.800.92 MSC+FD10.511.131.120.551.24 MSC+SD20.810.711.090.800.92 小檗堿Raw60.886.457.790.926.13 FD20.837.458.080.877.54 SD20.934.726.840.926.69 SNV+FD20.876.627.160.906.96 SNV+SD20.944.526.490.936.65 MSC+FD20.876.607.150.906.97 MSC+SD20.944.516.480.936.67 非洲防己堿Raw60.560.851.030.241.16 FD70.950.290.680.181.23 SD40.950.280.760.261.03 SNV+FD20.540.840.980.251.05 SNV+SD40.940.300.680.261.03 MSC+FD20.540.840.980.251.04 MSC+SD60.990.100.660.291.00 巴馬汀Raw90.941.152.020.881.77 FD80.990.481.240.881.47 SD40.990.501.440.821.72 SNV+FD70.980.601.260.861.52 SNV+SD40.990.481.320.841.60 MSC+FD70.980.601.260.861.52 MSC+SD40.990.481.320.841.60
Raw、FD、SD、SNV、MSC分別代表不做處理、一階導數、二階導數、多元正態變量、多元散射校正,所有數據均經過平滑處理。c2和p2分別代表校正集和驗證集的決定系數
Raw, FD, SD, SNV and MSC respectively represent the spectral pre-processing algorithms of unprocessed, first derivative, second derivative, standard normal variate and multiplicative scatter correction. All data applied with a smoothing step.2and2represent the coefficient of determination for calibration and the coefficient of determination for prediction respectively
表2 FT-MIR光譜優化后結果
Table 2 Results of FT-MIR after optimization
化學成分預處理潛在因子Rc2RMSEERMSECVRp2RMSEP 黃連堿Raw40.781.661.830.661.98 FD20.751.781.890.671.94 SD20.791.631.870.691.87 SNV+FD20.791.621.800.652.01 SNV+SD20.801.571.840.691.88 MSC+FD20.791.621.800.652.01 MSC+SD20.801.561.840.691.88 木蘭花堿Raw30.750.801.030.611.16 FD20.730.830.930.531.29 SD10.710.841.010.790.91 SNV+FD10.720.830.910.491.33 SNV+SD10.720.830.950.471.35 MSC+FD10.720.830.910.491.33 MSC+SD10.720.830.950.471.35
續表2
化學成分預處理潛在因子Rc2RMSEERMSECVRp2RMSEP 小檗堿Raw40.925.226.100.857.69 FD20.905.846.300.886.95 SD20.915.616.580.896.70 SNV+FD40.963.675.090.867.23 SNV+SD30.954.425.680.886.73 MSC+FD40.963.665.100.867.28 MSC+SD30.954.265.690.886.72 非洲防己堿Raw40.510.820.940.391.06 FD70.540.780.810.490.97 SD30.750.570.760.500.94 SNV+FD10.500.810.840.490.96 SNV+SD30.770.570.740.470.97 MSC+FD30.690.650.730.540.91 MSC+SD30.770.570.740.470.97 巴馬汀Raw30.821.771.950.861.87 FD50.931.141.520.911.57 SD20.861.511.710.911.54 SNV+FD30.901.311.600.931.37 SNV+SD20.871.491.710.921.41 MSC+FD30.901.321.610.861.37 MSC+SD20.871.481.700.921.41
Raw、FD、SD、SNV、MSC分別代表不做處理、一階導數、二階導數、多元正態變量、多元散射校正,所有數據均經過平滑處理。c2和p2分別代表校正集和驗證集的決定系數
Raw, FD, SD, SNV and MSC respectively represent the spectral pre-processing algorithms of unprocessed, first derivative, second derivative, standard normal variate and multiplicative scatter correction. All data applied with a smoothing step.2and2represent the coefficient of determination for calibration and the coefficient of determination for prediction respectively
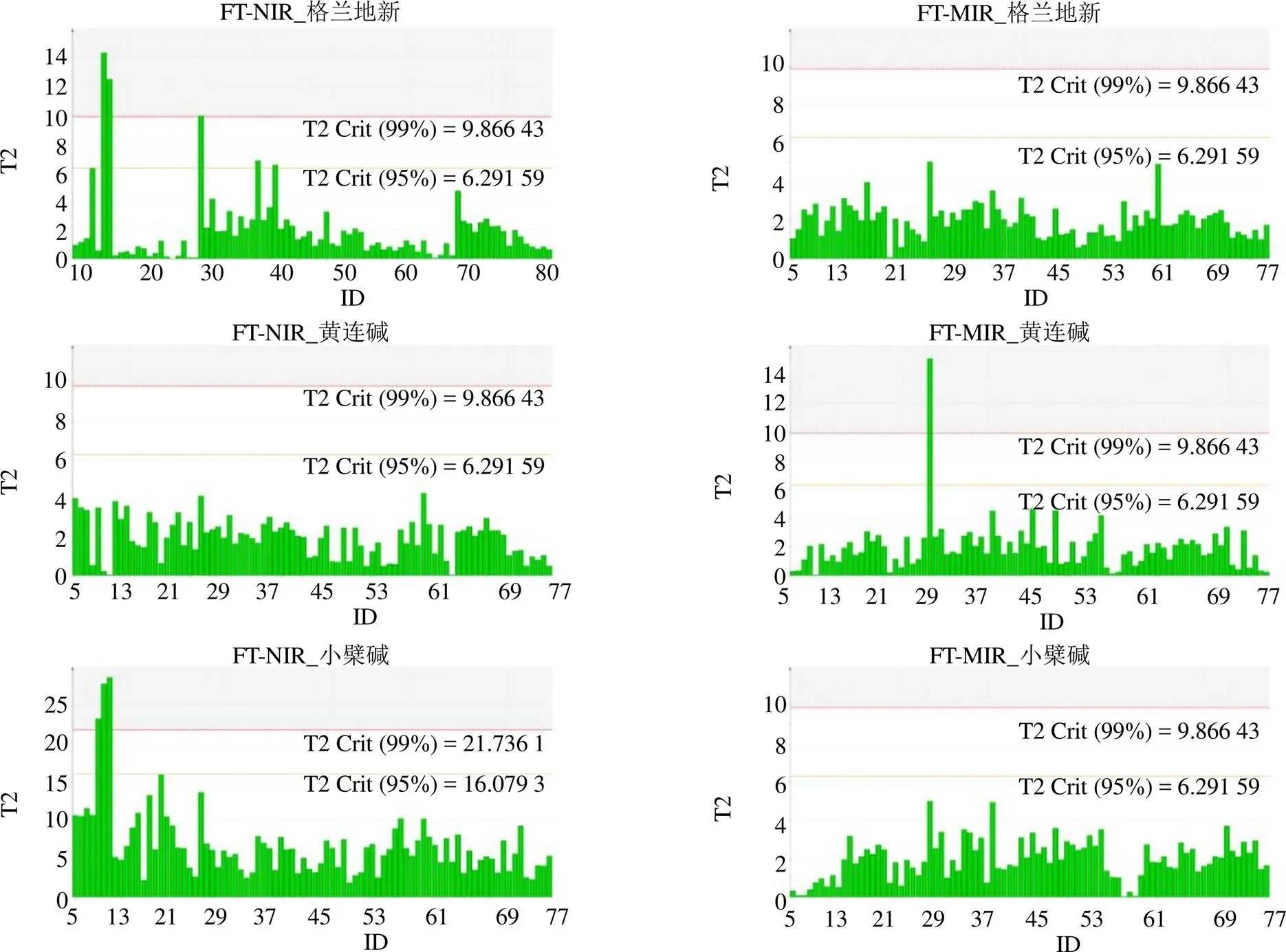
圖3 不同數據集異常值診斷結果
表3 不同變量采集模型誤差率
Table 3 RMSE based on different feature selection models
成分紅外光譜RFEBORUTAVIPGINI 黃連堿FT-NIR0.099±0.0310.104±0.0330.108±0.0370.102±0.029 FT-MIR0.088±0.0320.092±0.0300.112±0.0360.094±0.031 小檗堿FT-NIR0.123±0.0500.130±0.0480.133±0.0500.123±0.049 FT-MIR0.074±0.0270.077±0.0260.083±0.0260.077±0.022 巴馬汀FT-NIR0.105±0.0390.106±0.0440.115±0.0480.135±0.041 FT-MIR0.092±0.0320.091±0.0400.102±0.0410.116±0.038 非洲防己堿FT-NIR0.131±0.0360.126±0.0370.194±0.0380.185±0.036 FT-MIR0.119±0.0330.122±0.0340.203±0.0340.190±0.042 木蘭花堿FT-NIR0.114±0.0340.120±0.0390.132±0.0380.181±0.031 FT-MIR0.119±0.0390.118±0.0410.123±0.0460.161±0.045
特征變量的數目也在一定程度上反應出特征學習模型的效率,其結果見圖4。針對FT-NIR和FT-MIR數據集,RFE和BORUTA在變量數目的輸出中具有明顯的優勢,其中BORUTA算法的效果較好;VIP和GINI 2種特征選擇算法的效率較低。由圖可見,BORUTA算法基本可以將不同的數據集的變量數目縮減至50以內,同時保持較低的誤差率。
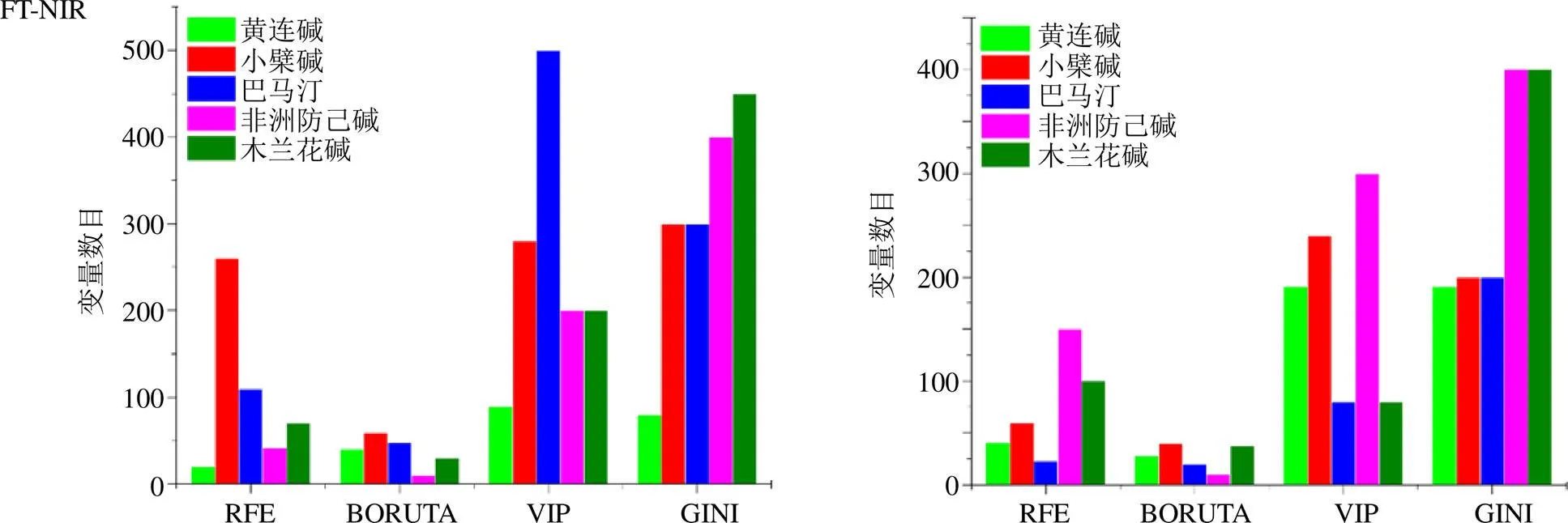
圖4 不同特征篩選后變量數目
結合誤差率和變量數目2個指標綜合考慮,對于FT-NIR_黃連堿、FT-MIR_黃連堿和FT-NIR_木蘭花堿3個數據集,選擇RFE特征學習算法進行變量采集,簡化光譜矩陣數據。其余數據集選擇BORUTA特征學習模型對其進行優化。經過數據預處理和變量篩選兩個階段,FT-NIR_黃連堿、FT-MIR_黃連堿、FT-NIR_小檗堿、FT-MIR_小檗堿、FT-NIR_巴馬汀、FT-MIR_巴馬汀、FT-NIR_非洲防己堿、FT-MIR_非洲防己堿、FT-NIR_木蘭花堿和FT-MIR_木蘭花堿數據集的變量數目分別被縮減為83×20、83×40、81×59、81×40、81×48、81×23、82×10、82×10、83×70和83×38。
3.4 光譜化學表征模型的建立
基于以上步驟,本研究進一步基于特征級信息融合算法,獲得不同基原黃連藥材中黃連堿、小檗堿、巴馬汀、非洲防己堿和木蘭花堿的相關特征數據集,其大小分別為83×60、81×99、81×71、82×20和83×108。相較于原始數據,光譜變量的數量明顯降低,可以有效增加模型的速度和準確性,同時增強其推廣能力。
應用以上特征數據集,以高效液相色譜結果作為標準數據,分別建立2種化學計量學相關模型,以考察其預測結果和真實數據的相關性,證實模型的推廣能力。PLSR分析結果見表4,相對于標準數據,小檗堿的PLSR模型的預測效果最優。該模型將數據集縮減至4個LV,其RMSEE、RMSECV、2、RMSEP和RPD分別是0.075、0.097、0.928、0.096和3.734。對于非洲防己堿的含量預測,PLSR模型的效果較差,其RMSEE、RSECV、R2、RMSEP和RPD分別是0.140、0.170、0.580、0.205和1.570。根據光譜化學表征模型的預測RPD值,表明PLSR模型對于黃連堿、小檗堿、巴馬汀和木蘭花堿的預測都取得較好效果。
SVR模型的結果如表5所示,調參流程如圖5所示。相對于PLSR,SVR模型可以更好地處理非線性的數據,對于某些成分取得了更好的預測效果。特別是對于小檗堿含量的預測,選擇PSO調參算法,模型的預測效果取得了較大的提升,其RSECV、R、RMSEP和RPD分別為0.094、0.957、0.075和4.842;其主要參數和分別是17.238和0.010。另外針對于非洲防己堿和木蘭花堿2個成分,SVR模型的效果也優于PLSR;GA和GS兩種調參的方法獲得了更優的參數值,其和分別是64.343、0.058和2.297、0.005。但是針對于黃連堿和巴馬汀2個成分,SVR模型的預測效果弱于PLSR相關模型。根據所建立的最優紅外光譜化學表征模型,對未知樣品中5種物質基礎成分的含量進行預測。樣品預測值和真實值之間的關系見圖6,兩者之間趨勢接近,進一步證明了模型的有效性和推廣能力。應用主成分分析的方法對預測結果進行分類,結果見圖7。如圖所示,味連、雅連、野連和云連樣品的界限明顯,可以很明顯地被鑒別開。經過光譜優化和特征學習流程,光譜化學表征模型能成功預測不同基原黃連樣品中主要共有物質基礎的含量,可以有效對不同基原的黃連藥材進行品質辨識。
表4 PLSR光譜化學表征模型的結果
Table 4 PLSR results of spectrochemical characterization model
化學成分LVRMSEERMSECVR2RMSEPRPD 黃連堿30.0920.1110.8620.1622.003 小檗堿40.0750.0970.9280.0973.734 巴馬汀50.0800.1240.8830.1152.917 非洲防己堿30.1400.1700.5800.2051.570 木蘭花堿40.0790.1080.7670.1322.051
表5 光譜化學表征模型的SVR結果
Table 5 SVR results of spectrochemical characterization model
化學成分方法cgRMSECVR2RMSEPRPD 黃連堿GA2.2660.4730.1100.8620.1861.741 PSO1.3720.0100.1160.8310.1671.941 GS1.3200.4350.1060.8640.1851.753 小檗堿GA0.3370.0910.0870.9500.0894.034 PSO17.2380.0100.0940.9570.0754.842 GS0.7580.0270.0880.9510.0794.558 巴馬汀GA0.4760.0150.1020.9230.1282.638 PSO14.1490.0100.1160.9000.1612.094 GS2.2970.0050.0990.9150.1262.664 非洲防己堿GA64.3430.0580.1670.7260.1701.892 PSO3.0390.0100.1840.6060.2021.587 GS1.3200.0820.1740.7120.1821.768 木蘭花堿GA9.9710.0320.1140.7630.1342.030 PSO2.9300.0100.1270.7920.1272.138 GS2.2970.0050.1230.8230.1162.344
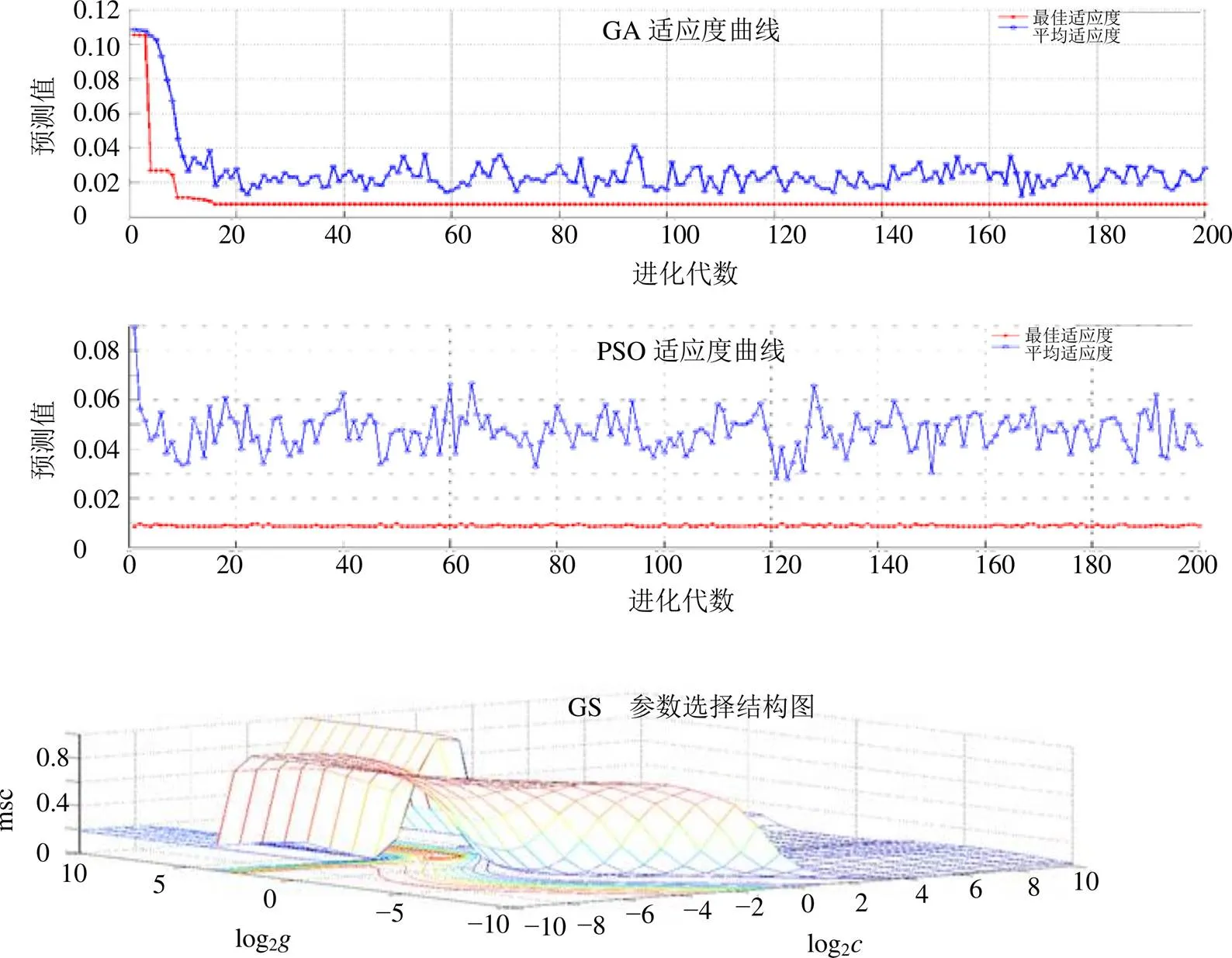
圖5 GA、PSO和GS調參流程(以小檗堿數據集為例)
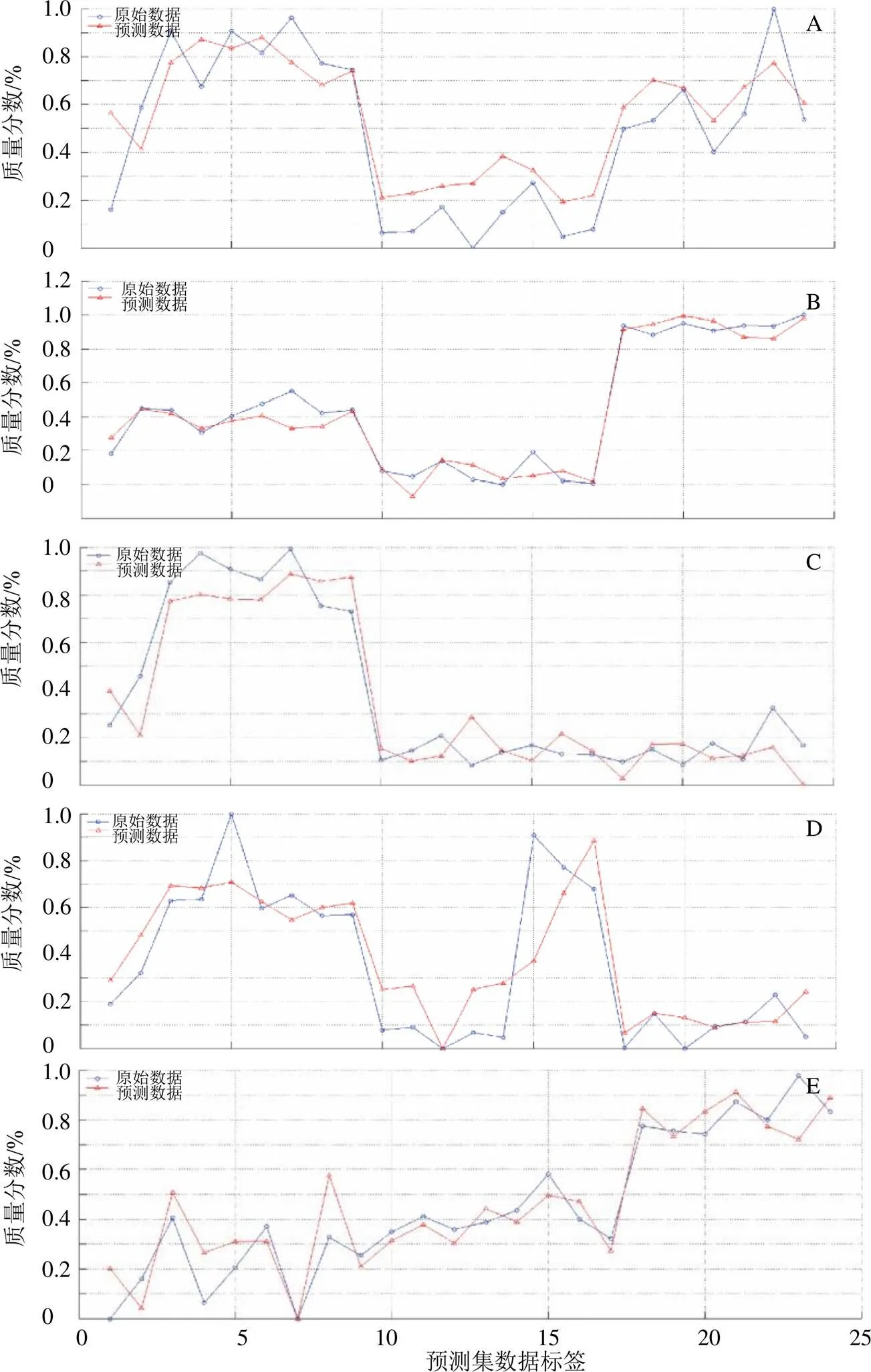
A-黃連堿 B-小檗堿 C-巴馬汀 D-非洲防己堿 E-木蘭花堿
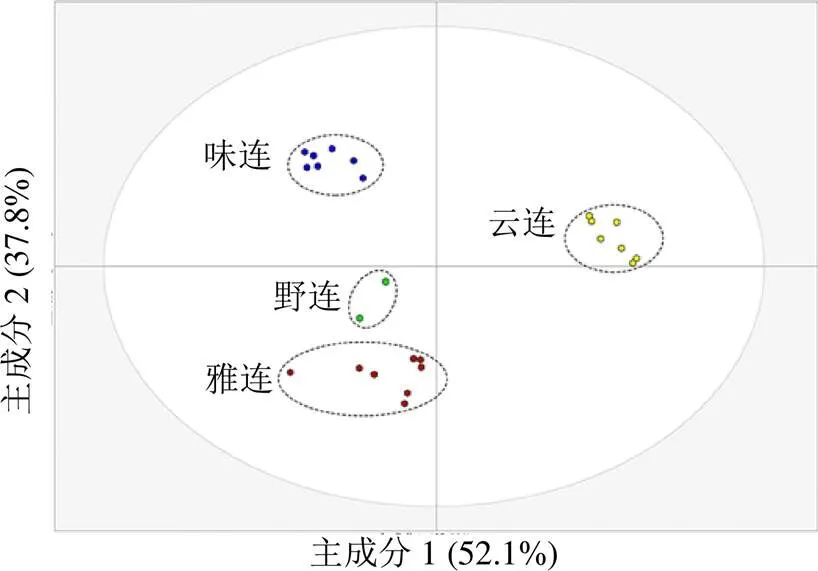
圖7 基于最優光譜化學表征模型的PCA結果
4 討論
多基原中藥自古以來就是中藥體系構成的重要部分,一方面保障了中醫臨床的有藥可用,另一方面又給臨床實現精準治療提供依據。但是對于多基原品種,其基原的等效性一直是歷代醫家的主要研究內容,而其效用差異研究較少。因此,如何依據多基原中藥的效用差異制定合理的品質評價標準,是該類藥材實現臨床合理用藥、有效資源配置環節中亟需解決的問題。本研究以典型的多基原藥材黃連為研究對象,結合課題組前期研究中得到的“共有成分的含量差異是其效用差異的主要原因”這一結論,選擇黃連堿、小檗堿、巴馬汀、非洲防己堿和木蘭花堿為指標,應用無損綠色的光譜技術構建其含量表征模型,考察該技術應用于多基原黃連藥材品質辨識的可行性。
中藥的化學成分復雜,光譜變量眾多且難以辨識。本研究在前人工作的基礎上[25-27],建立了一套完整的光譜矩陣分析流程:主要包括光譜信號優化、異常值診斷、數據標準化、特征學習與評價、光譜化學表征模型等步驟。結果顯示,光譜預處理可以明顯降低噪音信號,提高光譜數據質量;特征學習算法可有效從復雜數據矩陣中提取出和目標成分有關的光譜特征。其中RFE和BORUTA模型可以將3000多個黃連樣品光譜變量降維到100個內,同時能保證較高的正確率。這兩種方法在中藥領域應用較少,將來可以有效地應用到中藥復雜問題的解決之中。
基于主要的FT-NIR和FT-MIR變量特征,分別建立黃連中五種共有物質基礎化學成分的PLSR和SVR光譜化學表征模型。其中小檗堿的預測效果最好,其RPD值高達4.842;黃連堿、巴馬汀和木蘭花堿的數學模型的RPD值均高于2,取得了滿意的效果。非洲防己堿的光譜化學表征模型的RPD值為1.892,其預測效果有待于進一步提高。對比PLSR和SVR光譜化學表征模型,SVR的效果更優,可能與處理非線性問題的能力有關。
將未知樣品代入最優模型之中,結果顯示五種化學成分含量的真實值和預測值相關性較高,證明模型的可靠性和推廣性。應用PCA分析最優模型的預測結果,散點圖可以將不同基原黃連藥材有效鑒別,表明所建立的光譜化學表征模型能夠對該類藥材的品質進行辨識,有進一步應用于該藥材效用評價的潛力,為多基原中藥的品質辨識提供一個無損、綠色和快速的方案。
利益沖突 所有作者均聲明不存在利益沖突
[1] Li J X, Yan D, Ma L N,. A quality evaluation strategy for Rhizoma coptidis from a variety of different sources using chromatographic fingerprinting combined with biological fingerprinting [J]., 2013, 58(33): 4092-4100.
[2] 劉睿穎, 任瑤瑤, 張思遠, 等. 味連與雅連改善2型糖尿病大鼠糖及脂代謝紊亂的研究 [J]. 華西藥學雜志, 2018, 33(4): 368-372.
[3] Chen Y, Qi L M, Zhong F R,. Integrated metabolomics and ligand fishing approaches to screen the hypoglycemic ingredients from fourmedicines [J]., 2021, 192: 113655.
[4] Zhang H M, Guo Y N, Meng L W,. Rapid screening and characterization of acetylcholinesterase inhibitors from Yinhuang oral liquid using ultrafiltration-liquid chromatography-electrospray ionization tandem mass spectrometry [J]., 2018, 14(54): 248-252.
[5] Zhang G W, Peng S L, Cao S Y,. A fast progressive spectrum denoising combined with partial least squares algorithm and its application in online Fourier transform infrared quantitative analysis [J]., 2019, 1074: 62-68.
[6] Shamshirband S, Petkovi? D, Javidnia H,. Sensor data fusion by support vector regression methodology—A comparative study [J]., 2015, 15(2): 850-854.
[7] Sun W J, Zhang X, Zhang Z Y,. Data fusion of near-infrared and mid-infrared spectra for identification of rhubarb [J]., 2017, 171: 72-79.
[8] Zhong F R, Shen C, Qi L M,. A multi-level strategy based on metabolic and molecular genetic approaches for the characterization of differentmedicines using HPLC-UV and RAD-seq techniques [J]., 2018, 23(12): E3090.
[9] Yang Y H, Pan T, Zhang J. Global optimization of Norris derivative filtering with application for near-infrared analysis of serum urea nitrogen [J]., 2019, 10(5): 143-152.
[10] Dhanoa M S, Lister S J, Sanderson R,. The link between multiplicative scatter correction (MSC) and standard normal variate (SNV) transformations of NIR spectra [J]., 1994, 2(1): 43-47.
[11] Roy I G. On computing first and second order derivative spectra [J]., 2015, 295: 307-321.
[12] Mahmoud S, Lotfi A, Langensiepen C. User activities outliers detection; integration of statistical and computational intelligence techniques [J]., 2016, 32(1): 49-71.
[13] Shalabi L A, Shaaban Z. Normalization as a preprocessing engine for data mining and the approach of preference matrix. International Conference on Dependability of Computer Systems [C]. 2006: 207-214.
[14] Granitto P M, Furlanello C, Biasioli F,. Recursive feature elimination with random forest for PTR-MS analysis of agroindustrial products [J]., 2006, 83(2): 83-90.
[15] Kursa M B, Rudnicki W R. Feature selection with the Boruta Package [J]., 2010, 36(11): 1-13.
[16] Mehmood T, Liland K H, Snipen L,. A review of variable selection methods in Partial Least Squares Regression[J]., 2012, 118: 62-69.
[17] Singh S R, Murthy H A, Gonsalves T A. Feature selection for text classification based on gini coefficient of inequality [J][J]. 2010, 26: 76-85.
[18] Biancolillo A, Bucci R, Magrì A L,. Data-fusion for multiplatform characterization of an Italian craft beer aimed at its authentication [J]., 2014, 820: 23-31.
[19] Cheng J H, Sun D W. Partial least squares regression (PLSR) applied to NIR and HSI spectral data modeling to predict chemical properties of fish muscle [J]., 2017, 9(1): 36-49.
[20] Drucker H, Surges C J C, Kaufman L,. Support vector regression machines [J]., 1997: 155-161.
[21] Chen Q S, Zhao J W, Fang C H,. Feasibility study on identification of green, black and Oolong teas using near-infrared reflectance spectroscopy based on support vector machine (SVM) [J]., 2007, 66(3): 568-574.
[22] Qi L M, Zhang J, Zuo Z T,. Determination of iridoids inby infrared spectroscopy and multivariate analysis [J]., 2017, 50(2): 389-401.
[23] Kennard R W, Stone L A. Computer aided design of experiments [J]., 2012, 11(1): 137-148.
[24] Chang C W, Laird D A, Mausbach M J,. Near-infrared reflectance spectroscopy-principal components regression analyses of soil properties [J]., 2001, 65(2): 480-490.
[25] Pei Y F, Zuo Z T, Zhang Q Z,. Data fusion of Fourier transform mid-infrared (MIR) and near-infrared (NIR) spectroscopies to identify geographical origin of wildvar.[J]., 2019, 24(14): E2559.
[26] Wang Y, Zuo Z T, Shen T,. Authentication ofspecies using near-infrared and ultraviolet-visible spectroscopy with chemometrics and data fusion [J]., 2018, 51(17): 2792-2821.
[27] Li Y, Zhang J, Li T,. Geographical traceability of wild Boletus edulis based on data fusion of FT-MIR and ICP-AES coupled with data mining methods (SVM) [J]., 2017, 177: 20-27.
Construction of spectrochemical characterization model for quality identification based on utility difference of multi-source
HUANG Ling1, QI Lu-ming2, WANG Ke3, LI Na1, DONG Ji-jing1, MA Yun-tong1
1. School of Pharmacy, Chengdu University of Traditional Chinese Medicine, Chengdu 611137, China 2. School of Rehabilitation and Health Preservation, Chengdu University of Traditional Chinese Medicine, Chengdu 611137, China 3. School of Big Data and Artifical Intelligence, Chengdu Technological University, Chengdu 611730, China
The difference in the utility of the multi-source species of traditional Chinese medicine has been paid great attention by the doctors in the past dynasties. In this study, FT-NIR and FT-MIR technologies were combined to investigate the feasibility of applying spectrochemical characterization techniques to the determination and quality identification of the common material basis of multi-source Huanglian ().Taking the common material basis of four, coptisine, magnoflorine, berberine, columbamine, and palmatine as the research objects, optimization and feature learning algorithms based on spectral matrix, combining near-infrared and mid-infrared spectroscopy characteristics to construct PLSR and SVR spectrochemical characterization models to determine the content of common active ingredients in medicinal materials and identify their quality differences.The SVR model had the best effect on the determination of berberine, with anvalue of 4.842. The predictedvalues of the model for berberine, palmatine and magnoflorine content were all higher than 2; PCA results showed that the model could effectively identify the differences in the common components of multi-source, and provide a basis for its quality identification.The serial application of multiple spectrum technology can effectively characterize the difference in the content of the common components of the multi-based original, and improve the efficiency of quality identification of the multi-based original Chinese medicine.
Franch.;C. Y. Cheng et Hsial;C. Y. Cheng;Wall.; infrared spectroscopy; partial least squares regression; support vector regression; spectrochemical characterization model; berberine; coptisine; magnoflorine; columbamine; palmatine
R286.2
A
0253 - 2670(2022)20 - 6343 - 11
10.7501/j.issn.0253-2670.2022.20.005
2022-03-09
國家重要野生植物種質資源共享平臺
黃 玲(1994—),女,在讀碩士研究生,研究方向為中藥品種、品質與資源開發研究。Tel: 18482134481 E-mail: huangling0108@163.com
馬云桐(1963—),男,博士生導師,教授,研究方向為中藥品種、品質與資源開發研究。E-mail: mayuntong06@163.com
[責任編輯 時圣明]
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
