基于聚類和隨機森林回歸的超大型建筑能耗負荷預測模型研究
2022-10-18 03:35:44葉從周,肖朋林,秦俊等
綠色建筑 2022年5期
我國隨著節能減排工作的推進,碳達峰和碳中和概念的提出,對公共建筑能耗約束和能效等級提出了更高的要求,低碳城區與綠色建筑的建設進程將以更快的速度推進。超高層超大型建筑是城市能耗大戶,為了實現低碳目標,在其建設與運行過程中,將會使用更多類型的分布式能源,這使得多種能源的調度與控制,尤其是對于空調的控制,將成為一大難題。
根據《2020 年上海市國家機關辦公建筑和大型公共建筑能耗監測及分析報告》,主要類型建筑 2020 年分項用電占比來看,照明與插座用電、空調用電為主要用電分項,各類型建筑這兩項之和均超過 70%。在超高層超大型建筑中,空調用電也是主要耗能之一。所以通過預測供暖空調負荷,指導冷熱源的優化運行,從而提高空調運行效率,能夠有效節約能源、降低運行成本。
本文主要研究如何通過混合多種機器學習算法,包括聚類與回歸算法等,提高建筑能耗預測建模準確性和有效性,并對能耗預測的實際應用提供幫助。
1 能耗預測模型研究現狀
目前,能耗預測主要有 2 種方式,即物理模擬和數據驅動。數據驅動建模是本文研究的重點。數據驅動,一般指的是將收集到的建筑數據作為輸入,對應的歷史能耗數據作為輸出,訓練得到能耗預測模型[1]。數據驅動建模的方式主要有回歸模型、時間序列模型、機器學習算法模型等[2]。其中,機器學習算法在建筑能耗建模的應用主要包括支持向量機(SVM)、人工神經網絡(ANN)、決策樹和其他統計算法[3]。如肖冉等[4]提出一種基于支持向量機的辦公建筑逐時能耗預測方法,并引入了網格搜索方法優化模型超參數,體現了建筑的運行波動。楊麗娜等[5]提出一種結合神經網絡(artificial neural network)和GRU的網絡模型(ANNGRU)來預測數據中心能耗,具有很高的精度。
除了在不同算法上有各種研究以外,針對不同的建筑類型以及不同的時間粒度也有各類研究。如周芮錦等[6]基于時間序列分析,將建筑逐月能耗的 4 個主要影響因子:逐月積溫值、逐月相對濕度平均值、逐月工作日天數及逐月非工作日天數引入建筑能耗預測模型,對逐月數據進行預測。高英博等[7]利用 LSTM 模型對上海某酒店建筑逐時能耗數據進行預測,并以此為依據對能耗數據進行異常識別。
以上種種在建筑能耗領域目前已得到廣泛的研究,通過結合建筑運行數據和天氣數據,預測建筑未來的能耗數據,有一定的預測準確性。但是,許多算法當建筑處于運行模式切換時,預測的準確性會下降,同時對于不同維度的數據需要做多步預處理和超參設置,而在超大型建筑中,往往存在不同區域的空調設備運行模式不同,造成了工程化的復雜性。本文為了解決該問題進行了以下幾個試驗。
2 基于隨機森林回歸的能耗預測模型
隨機森林回歸是一種基于決策樹的集成學習算法。其核心思想是一個由多顆隨機生成的決策樹組成的森林,每一個數據輸入后,由各個不相關的決策樹做分類或者回歸,并投票決定該數據該如何分類或者回歸。
隨機森林回歸主要用到的決策樹算法是 C A R T (classification and regression tree)算法。單獨的決策樹算法往往會在訓練數據上表現良好,但在訓練數據和實際應用中效果很差,其由于過擬合的缺點,使得模型不具有普遍性和工程上的應用能力。
為了彌補決策樹的不足,隨機森林引入了隨機采樣的概念,即在森林中的決策樹在訓練中得到的數據都是全局樣本中的一部分,從而避免了過擬合,并且可以通過算法本身進行特征選擇,不需要對數據進行規范化,相比于 SVM、ANN 等算法,工程化更簡單,容易并行化,處理更大量的數據。
選取溫度、濕度、是否為工作日以及小時點和相同工作狀態下前一天同一時間點的能耗值作為輸入變量,該時間點的能耗值作為輸出變量,并對比不同的超參構建模型,試驗不同大小和深度的隨機森林對能耗預測模型的影響。
試驗設置決策樹深度分別為n=3、5 以及 7,對比不同超參數下,評估參數的值。評估參數選取R2與 mse(均方誤差)。R2是用來評價預測值與真實值的擬合程度好壞,越接近 1 表示擬合度越高;均方誤差 mse 是預測值與真實值之差的平方和的平均值,值越小代表預測值與真實值差距越小。
同時將連續的能耗數據分段截取一部分作為訓練數據,另外一部分作為測試數據,比例為 7∶3。
評估參數選取R2與 mse,測試樣本整體R2與 mse 見表 1 。
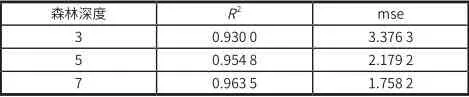
表1 預測值與真實值的擬合度及均方誤差
由試驗結果可知,隨機森林越復雜,預測效果越佳。然而,仔細觀察換季時的預測準確性,當數據處于不同季度之間時,誤差較大。
季度交錯時間段內的預測準確率明顯下降。當決策樹深度為 7 時,取 8 月、9 月數據計算R2與 mse 值,分別為 0.898 6 和 2.849 0,與整體相比,下降了 0.065 與 62%,有明顯差距。
考慮原因,不同季度的相同時間段能耗消耗規律不同,當處于同一模型下訓練時,隨機森林無法及時分辨不同的空調運行模式,為此需要引入聚類對不同季度的能耗曲線進行分類和建模。
3 基于聚類的能耗曲線建模
聚類算法在建筑能耗建模中的應用主要指的是時間序列聚類,時間序列聚類在建筑節能領域的主要應用有 3 種:識別時間序列數據中的動態變化、預測與推薦以及模式識別。在建筑用能建模領域,基于時間序列聚類分析的主要研究有:建筑用能的模式識別、需求側管理、建筑用能預測、建筑用能異常數據檢測。
K-means 聚類作為最著名的聚類算法之一,在時間序列領域應用廣泛。其原理為通過將數據分為K個簇中,使得簇內的各個數據到中心點的距離差平方和最小。在能耗數據的聚類中計算距離的方式,在本研究中主要采用歐幾里得距離,K值設置為 6,理由如下。
(1)空調用電受季節因素的影響較大,可以分為過渡季,供熱季,供冷季,同時工作日和節假日時的空調運行同樣有很大的區分。所以,試驗中將K設置為 6,即(過渡季,供熱季,供冷季)×(工作日,節假日)。
(2)超大型建筑空調能耗時序數據與空調設備的啟停時間有著強相關性。因此,在計算相似性時需要考慮建筑能耗曲線在相同時間點的實際物理意義,計算各條由 24 個點/d 組成的能耗曲線相互之間相似度,得到每個簇的中心,使得簇心曲線上的每個點有其實際的物理意義,為設備運行策略優化提供統計學意義上的支撐。
研究中混合了 K-means 和 DBSCAN 2 個聚類算法,對能耗曲線進行清洗以及分類。試驗中,將某電表一整年的小時總能耗數據劃分為一個 365×24 的矩陣,以天為單位,一天 24 h 組成一條時間序列曲線;通過混合多種聚類算法清洗數據,剔除異常曲線;將清洗后數據進行二次聚類。聚類結果如圖1 所示。
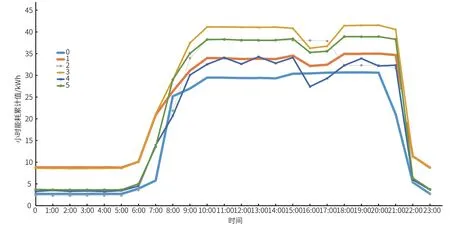
圖1 某空調回路聚類簇中心曲線
從表2 統計結果可知,表2 的運行結果與季度相關性高,而與是否為工作日、節假日相關性低。為了能夠更好區分出空調運行的能耗規律,將能耗數據按照工作日、節假日重新聚類,得出結果如圖2 所示。

表2 各類別天數所處月份及所處工作日雙休日天數統計表 單位:d
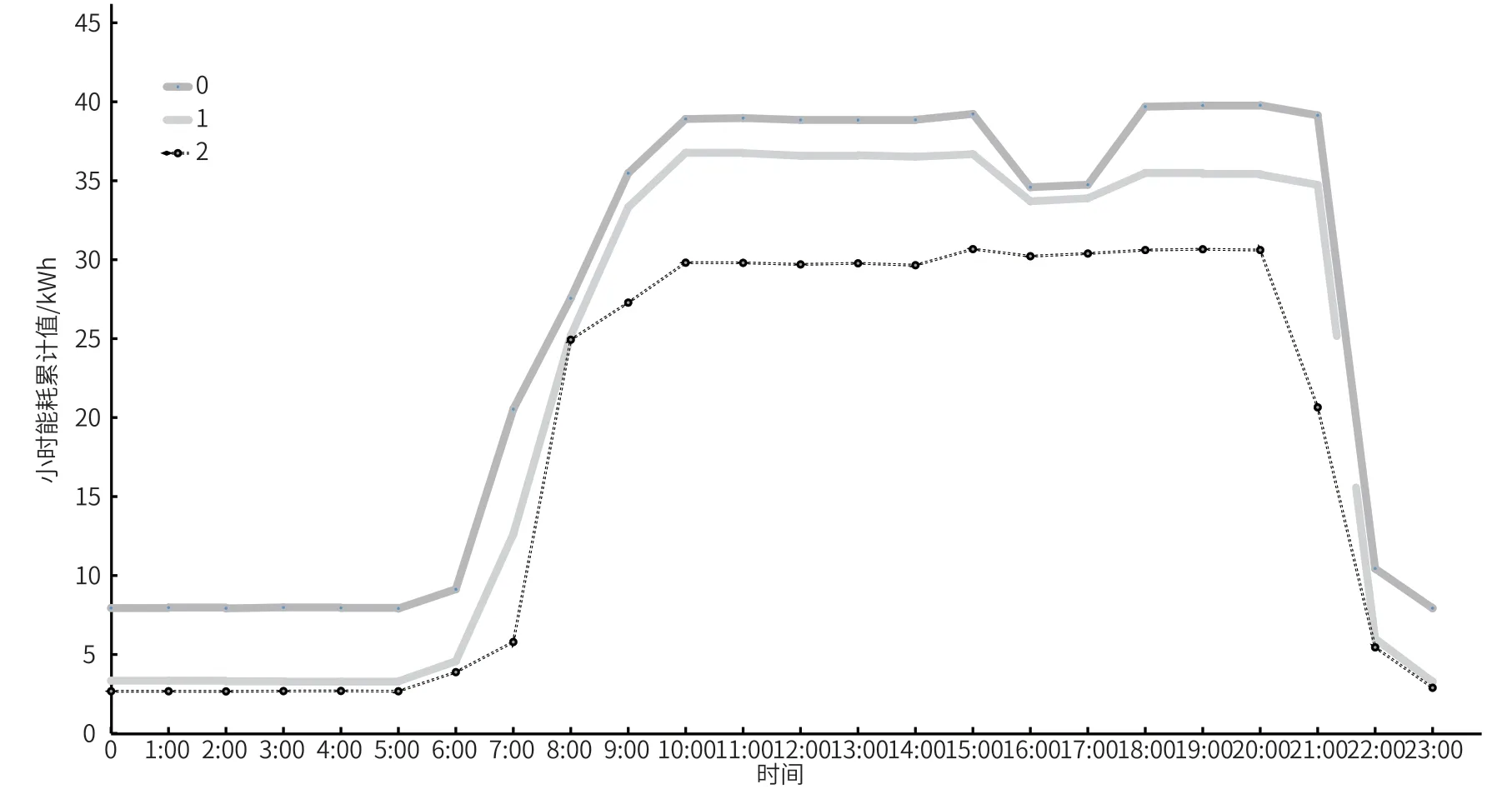
圖2 某空調回路工作日、節假日聚類簇中心曲線
從統計結果表3,可以發現每一類簇中心曲線都分別代表了過渡季、制冷季和供熱季在 0:00-6:00 時的非工作時間段以及 6:00-18:00 時的工作時間段上用能規律。由此可知該空調在不同季度大致的用能規律,并以此為根據對不同季度的能耗數據進行分類。

表3 工作日各類別天數所處月份及所處工作日雙休日天數統計表 單位:d
4 混合聚類與隨機森林回歸的能耗預測模型
混合 K-means 聚類與隨機森林回歸兩種算法,該思想主要針對超大型建筑不同區域和季節運行規律區別很大,需要針對不同時間段和用能區域來進行建模的困難,找到不同區域和時間段建模的理論依據。
經過以上聚類算法對能耗數據處理的試驗,可以得知聚類算法能夠對不同季度的能耗數據進行分類,并在分類之后可以統計各個分類的所處于的季節及相關時間段,從而找到不同區域的空調設備切換啟停時間和運行模式的時間節點,以此作為劃分預測模型的分割點,即不同區域空調設備該依據哪個時間段作為一種運行模式的訓練數據,形成預測模型,并在一年中不同區域空調設備在不同季節中何時采用何種預測模型進行預測的理論依據。
首先嘗試對該樓宇不同區域的空調設備能耗進行建模。試驗結果見表4。
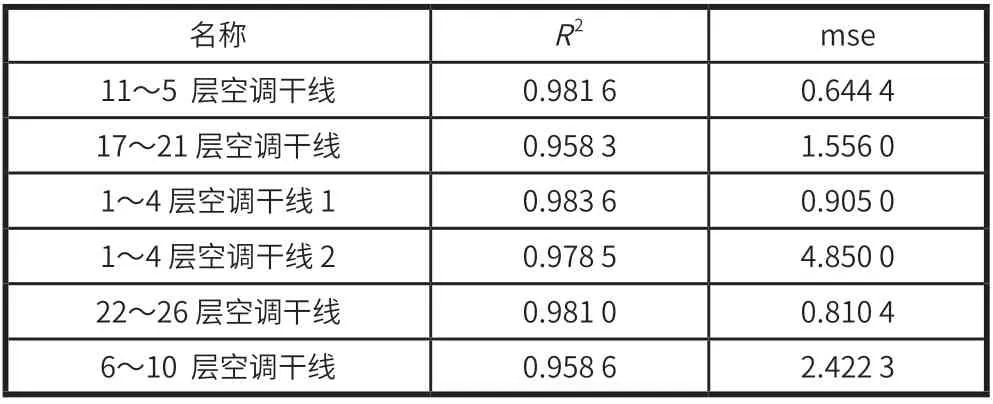
表4 不同區域的空調設備能耗預測值與真實值的擬合度及均方誤差
由試驗可知,即使設置相同超參,不同區域空調設備能耗數據對隨機森林回歸的性能依然表現良好,具有普適性,且不需要做任何的預處理。
之后,對某電表一整年的小時總能耗數據進行聚類,然后統計其各類曲線在各月分布情況,發現其空調運行模式切換主要在工作日 8月底9月初,符合之前試驗準確率下降的數據段范圍。找到時間劃分點后,對不同的空調運行模式下的能耗建模,即7~8月底,采用一個訓練模型,8~9 月采用第二個訓練模型,混合模型后得到新的預測。
具體對應月份數據(7~9月)預測效果對比見表 。

表5 隨機森林與混合算法的擬合度及均方誤差對比
可見經過多步處理后季節交換時段的能耗預測準確性顯著提高,較之前整體分別提高了 0.05 和 23.5%。
5 結 語
超大型建筑能耗的預測準確性的提高對相應國家的節能減排能夠起重要的作用。尤其是換季時期的能耗預測準確性的提高能夠幫助業主及時發現空調運行的異常。
本文采用了隨機森林回歸和 K-means 聚類 2 種算法,對超大型建筑的空調能耗預測進行了研究。本文主要結論如下。
(1)隨機森林回歸相較于 SVR、ANN 等算法主要優點在于不需要作特別的數據預處理,一樣能得到較高的預測準確性,因此具有很好的工程化優勢。在面對不同設備的模型訓練時,不需要做任何的超參設置,預測性能不受影響。因此,不必為每一個設備做單獨的算法模型的調試,能夠極大地發揮出數據驅動建模時的便利性,并保證預測準確性。
(2)同時,與大部分擬合算法一樣,無法應對換季時期的預測性能下降的問題,一旦空調運行規律改變,將會對預測的準確性有很大的負面影響。
(3)為了能夠讓模型及時相應天氣和節假日造成的空調運行規律改變,研究通過對設備能耗的歷史數據進行聚類,對聚類結果進行統計分析,可以發現不同季度空調設備運行規律區分度高,因此可以對不同季度空調設備能耗進行分別建模。
(4)在對設備能耗的歷史數據進行聚類,從而合理劃分運行規律改變的時間點,對不同運行規律采取不同的模型來進行訓練和測試,有效地提高了換季時期整體模型的預測準確率。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
北方建筑(2021年6期)2021-12-31 03:03:54
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
文苑(2020年10期)2020-11-07 03:15:36
現代裝飾(2020年6期)2020-06-22 08:43:12
數學物理學報(2020年2期)2020-06-02 11:29:24
現代裝飾(2020年4期)2020-05-20 08:55:08
光學精密工程(2016年6期)2016-11-07 09:07:19
福建農業科技(2016年10期)2016-03-07 09:46:49
少兒科學周刊·兒童版(2015年6期)2015-11-24 03:49:38
