基于壓縮空間句子選擇的涉案新聞話題摘要*
2022-10-16 08:39:36盧天旭
通信技術(shù) 2022年9期
盧天旭
(昆明理工大學(xué),云南 昆明 650500)
0 引言
涉案話題新聞簇中含有描述同一話題的多篇新聞文檔,需要從這些文檔中提取出關(guān)鍵句子作為摘要來(lái)描述涉案話題關(guān)鍵信息,以實(shí)現(xiàn)涉案輿情信息的監(jiān)管。當(dāng)社會(huì)上發(fā)生一個(gè)與司法案件相關(guān)的熱點(diǎn)事件時(shí),信息往往會(huì)在新聞網(wǎng)站和媒體上快速傳播、發(fā)酵,因此如何有效地進(jìn)行涉案輿情監(jiān)管是一個(gè)關(guān)鍵問(wèn)題。通過(guò)技術(shù)手段快速獲取輿情信息,及時(shí)提取案件輿情話題新聞的關(guān)鍵內(nèi)容,對(duì)有關(guān)部門監(jiān)管網(wǎng)絡(luò)動(dòng)向,維護(hù)網(wǎng)絡(luò)秩序穩(wěn)定而言至關(guān)重要。同一話題下新聞文檔數(shù)量成百上千,用戶如果直接從這些新聞中搜索描述話題的信息,需要花費(fèi)較多的時(shí)間和精力一一閱讀,處理起來(lái)非常不方便。通過(guò)文本自動(dòng)摘要技術(shù),從話題簇的新聞中提煉出含有話題關(guān)鍵信息的形式簡(jiǎn)練、覆蓋準(zhǔn)確的話題摘要,將極大減少用戶的閱讀時(shí)間,并能有效減少信息存儲(chǔ)的代價(jià)。對(duì)于有關(guān)部門開展的針對(duì)涉案話題的輿情監(jiān)管工作,獲取輿情話題關(guān)鍵內(nèi)容的技術(shù)起到了重要作用。
目前在通用領(lǐng)域針對(duì)話題摘要的研究分析是比較多的,并且由于近年來(lái)深度學(xué)習(xí)和神經(jīng)網(wǎng)絡(luò)算法取得了很大的發(fā)展,將其應(yīng)用在話題摘要任務(wù)上也取得了許多研究成果。
涉案新聞的話題摘要針對(duì)的是同一案件話題下的新聞文檔,其標(biāo)題和正文內(nèi)容均包含了涉案話題的要素關(guān)鍵信息,如表1 所示。

表1 涉案話題新聞結(jié)構(gòu)示例
表1 中新聞的標(biāo)題和正文中包含了案件名、涉案主體、描述、時(shí)間地點(diǎn)等要素關(guān)鍵詞,如果使用通用的自動(dòng)摘要方法,容易遺漏或覆蓋不全這些關(guān)鍵信息,也可能提取到與涉案話題描述無(wú)關(guān)的句子,造成摘要中的句子突出度不高。此外,現(xiàn)有方法使用句子選擇模型直接從原文中抽取代表性句子,比較簡(jiǎn)單實(shí)用,但是在涉案新聞話題摘要任務(wù)上,通用的自動(dòng)摘要方法不能適應(yīng)話題簇中新聞數(shù)據(jù)多案件要素的特點(diǎn),生成的摘要句子關(guān)鍵性不足,重復(fù)性也較高,不具有實(shí)用性。因此,需要結(jié)合涉案話題的要素關(guān)鍵詞進(jìn)行句子重要性篩選,并使用一種可以平衡突出特征和重復(fù)特征的句子選擇方法,才能在壓縮搜索空間的基礎(chǔ)上提升生成的話題摘要的質(zhì)量。
1 相關(guān)工作
話題摘要的研究可以根據(jù)提出的方法劃分為基于特征、基于主題模型、基于圖、基于句子排序和基于神經(jīng)網(wǎng)絡(luò)5 類。相較于單篇新聞文檔的摘要,話題摘要輸入的樣本數(shù)量更多,更容易產(chǎn)生重復(fù)性內(nèi)容。此外,相較于一般的文本摘要任務(wù),話題摘要任務(wù)要求生成的摘要句子包含描述話題的關(guān)鍵信息,并且最終得到的摘要句子集合既要凝練多篇話題文檔的主要內(nèi)容,又不能具有重復(fù)特征。
基于特征的摘要方法通過(guò)提取文檔中的關(guān)鍵詞、引導(dǎo)詞等統(tǒng)計(jì)特征來(lái)對(duì)句子進(jìn)行排序,從而選出排名靠前的句子作為摘要。Moradi 等人[1]提出了一種貝葉斯分類器的自動(dòng)摘要模型,它將生物醫(yī)學(xué)百科詞典作為參照,從文本中分類出帶有生物醫(yī)學(xué)特征的句子作為摘要。Yan 等人[2]提出了基于時(shí)間特征的自動(dòng)摘要,建立文檔句子間的時(shí)間依賴關(guān)系。Liu等人[3]構(gòu)建關(guān)鍵詞組成的語(yǔ)義模塊,并尋找與參考摘要重疊的模塊,通過(guò)權(quán)重函數(shù)最大化該模塊所在句子的重要程度來(lái)提取摘要句。Lin 等人[4]提出了一種多文檔摘要系統(tǒng),通過(guò)詞頻、句子位置等特征來(lái)選擇需要提取和過(guò)濾的內(nèi)容以提高和參考摘要的覆蓋率。Ouyang 等人[5]融合詞語(yǔ)的出現(xiàn)次序和出現(xiàn)頻率計(jì)算句位特征,特征得分高的句子作為摘要句。
基于主題模型的摘要方法通過(guò)傳統(tǒng)的主題模型獲取文檔的主題分布,并通過(guò)計(jì)算句子與主題的相似度得分來(lái)提取得分高的句子作為摘要。Shen 等人[6]提出了一種應(yīng)用在摘要任務(wù)上的概率潛在語(yǔ)義分析模型,可允許詞語(yǔ)與文檔的潛在類別數(shù)量不同,同時(shí)引導(dǎo)文檔聚類和生成摘要的過(guò)程。劉娜等人[7]在多文檔摘要任務(wù)上融合詞頻等統(tǒng)計(jì)特征和潛在狄利克雷分布(Latent Dirichlet Allocation,LDA)主題模型建立的重要主題特征,在摘要公共數(shù)據(jù)集上取得了不錯(cuò)的效果。Xiong 等人[8]利用LDA 主題模型,通過(guò)無(wú)監(jiān)督方法篩選有用的評(píng)論,生成評(píng)論話題摘要,并考慮將其應(yīng)用在多文檔摘要任務(wù)中。Gong 等人[9]綜合了原始文檔中的句子相關(guān)性排序和潛在語(yǔ)義分析模型發(fā)掘的語(yǔ)義重要的句子,選取綜合排名高的句子作為摘要句。Kar 等人[10]將LDA 主題模型應(yīng)用在在線文本摘要任務(wù)上,對(duì)單個(gè)術(shù)語(yǔ)進(jìn)行評(píng)分,然后使用評(píng)分信息對(duì)句子進(jìn)行選擇,生成最終摘要,并使用LDA 主題模型來(lái)尋找隱藏的主題變化結(jié)構(gòu)。
基于圖模型的摘要方法是基于構(gòu)建圖結(jié)構(gòu)的思想,通過(guò)節(jié)點(diǎn)與邊的關(guān)系構(gòu)建句子之間的關(guān)聯(lián)關(guān)系,并通過(guò)圖結(jié)構(gòu)的優(yōu)化來(lái)計(jì)算句子的重要性。Mihalcea 等人[11]提出了經(jīng)典的TextRank 算法,通過(guò)構(gòu)建文檔句子的圖結(jié)構(gòu)并根據(jù)相似度計(jì)算句子的重要性權(quán)重,可用于關(guān)鍵詞和關(guān)鍵句子的抽取。Wan 等人[12]提出了一種基于圖的流形排序算法,從多文檔中提取以主題為中心的摘要,將文檔內(nèi)句子關(guān)系和跨文檔句子關(guān)系視為兩個(gè)獨(dú)立的圖結(jié)構(gòu),并采用線性、順序和分?jǐn)?shù)組合3 種形式融合這兩種關(guān)系。Canhasi 等人[13]提出了一種新的基于圖的方法,將輸入文檔和查詢表示為多元素圖,然后使用一種加權(quán)原型分析分解方法根據(jù)句子與查詢的相關(guān)性來(lái)估計(jì)句子的重要性。Xiong 等人[14]在多文檔摘要任務(wù)上,提出了一種新穎的基于超圖的頂點(diǎn)增強(qiáng)隨機(jī)游走模型,首先利用分層狄利克雷過(guò)程主題模型來(lái)學(xué)習(xí)句子中的詞和主題概率分布,其次使用超圖來(lái)捕獲基于詞和主題概率分布的聚類關(guān)系和句子之間的成對(duì)相似度,并進(jìn)行句子排序。Van Lierde等人[15]提出了一種使用模糊超圖來(lái)推斷句子的主題分布的方法,最大化句子與定義的查詢的相關(guān)性、在模糊超圖中的中心性以及它們對(duì)語(yǔ)料庫(kù)中存在的主題的覆蓋來(lái)生成摘要。
基于句子排序的摘要方法通過(guò)優(yōu)化的句子選擇模型為文檔中的句子進(jìn)行打分排序,選取得分高的句子作為摘要。Carbonell 等人[16]提出了一種將查詢相關(guān)性與信息新穎性相結(jié)合的經(jīng)典方法,通過(guò)最大邊際相關(guān)性減少重復(fù),同時(shí)在重新排名中保持查詢相關(guān)性檢索文檔,并選擇合適的段落進(jìn)行文本摘要。Lebanoff 等人[17]利用最大邊際相關(guān)性方法從多文檔輸入中選擇具有代表性的句子,并利用抽象的編碼器—解碼器模型將不同的句子融合到抽象的摘要中。Zhang 等人[18]提出了一種通過(guò)將文檔集編碼器添加到分層框架中,來(lái)實(shí)現(xiàn)為多文檔任務(wù)中預(yù)訓(xùn)練成功的單文檔摘要模型進(jìn)行句子選擇的方法。Cao 等人[19]提出了一種新的摘要系統(tǒng),它共同處理句子和文檔集群的分布式表示,以及應(yīng)用注意力機(jī)制來(lái)模擬在給出查詢時(shí)對(duì)人類行為的注意力閱讀這兩個(gè)任務(wù),取得了較好的句子排序效果。Narayan等人[20]通過(guò)優(yōu)化評(píng)價(jià)指標(biāo)訓(xùn)練模型提取候選摘要,同時(shí)優(yōu)化獎(jiǎng)勵(lì)函數(shù),可以提取到符合預(yù)期的摘要句子。
基于神經(jīng)網(wǎng)絡(luò)表征的摘要方法是在神經(jīng)網(wǎng)絡(luò)學(xué)習(xí)句子的向量表征的基礎(chǔ)上,進(jìn)行句子選擇生成摘要的方法。Cheng 等人[21]基于編碼器提取器的數(shù)據(jù)驅(qū)動(dòng)的摘要框架,通過(guò)分層神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)分別提取句子和詞的特征,從而得到更好的摘要。Cao 等人[22]使用循環(huán)神經(jīng)網(wǎng)絡(luò)的排序模型來(lái)選擇文檔集合中的句子,將句子排序任務(wù)表示為,在層次回歸過(guò)程中,同時(shí)測(cè)量句子的突出度及其在解析的句子中的潛在表征,并使用貪婪的啟發(fā)式方法來(lái)提取突出句子,同時(shí)避免重復(fù)特征。Zhang 等人[23]提出了增強(qiáng)型多視圖卷積神經(jīng)網(wǎng)絡(luò),以共同獲取句子的特征,并對(duì)句子進(jìn)行排序。Nallapati 等人[24]提出了基于循環(huán)神經(jīng)網(wǎng)絡(luò)的模型生成摘要預(yù)測(cè),包括句子內(nèi)容、突出性和重復(fù)性等抽象特征。此外,可以單獨(dú)訓(xùn)練參考摘要,消除對(duì)句子抽取標(biāo)簽的依賴。Yasunaga 等人[25]在構(gòu)建句子關(guān)系上使用圖卷積網(wǎng)絡(luò),將句子嵌入作為網(wǎng)絡(luò)的輸入,并通過(guò)網(wǎng)絡(luò)傳播生成用于突出性估計(jì)的句子潛在表征,并使用貪婪的啟發(fā)式方法來(lái)提取突出句子,同時(shí)避免重復(fù)特征。
以上方法是摘要任務(wù)中常用的方法,基于特征的方法依賴于統(tǒng)計(jì)學(xué)特征,使用環(huán)境發(fā)生變化時(shí)效果受影響較大;基于主題模型的方法容易受到數(shù)據(jù)的質(zhì)量和任務(wù)類型的影響,會(huì)造成主題不一致的問(wèn)題;基于圖的方法依賴于句子之間的相似度計(jì)算,可以構(gòu)建出多文檔句子間的關(guān)聯(lián)關(guān)系;基于句子排序的方法需要平衡突出度和重復(fù)度才能生成質(zhì)量較好的摘要;基于神經(jīng)網(wǎng)絡(luò)的方法依賴于模型的表征能力,訓(xùn)練的參數(shù)較多。在完成話題摘要任務(wù)時(shí),往往需要結(jié)合多種方法才能達(dá)到良好的模型效果。
本文考慮結(jié)合句子排序和神經(jīng)網(wǎng)絡(luò)的方法,并融入話題關(guān)鍵詞特征,實(shí)現(xiàn)突出度高且重復(fù)特征少的涉案新聞話題摘要。
2 基于壓縮空間句子選擇的涉案新聞話題摘要
2.1 模型框架
本文提出一種基于壓縮空間句子選擇的涉案新聞話題摘要方法,先通過(guò)句子重要性評(píng)估步驟確定包含話題關(guān)鍵詞的重要句子,然后通過(guò)文檔集合編碼器編碼話題簇新聞文檔集合和句子,再使用突出度計(jì)算模塊和重復(fù)特征計(jì)算模塊確定候選句子,最終得到候選摘要句子的評(píng)分,話題摘要由評(píng)分靠前的句子組成。模型主要分為5 個(gè)部分,分別為句子重要性評(píng)估模塊、基于改進(jìn)的基于Transformer 的雙向編碼表示(Bidirectional Encoder Representation from Transformers,BERT)模型[26]的文檔集合編碼器、突出度計(jì)算模塊、重復(fù)特征計(jì)算模塊和句子選擇模塊。模型框架如圖1 所示。

圖1 基于壓縮空間句子選擇的涉案新聞話題摘要模型框架
2.2 句子重要性評(píng)估模塊
句子重要性評(píng)估模塊首先需要定義話題簇中的關(guān)鍵詞。話題簇中標(biāo)題往往涵蓋了準(zhǔn)確的話題描述詞,也是正文內(nèi)容的高度概括,如果某個(gè)詞語(yǔ)既屬于案件的要素信息,又在各個(gè)新聞標(biāo)題中高頻出現(xiàn),說(shuō)明該詞語(yǔ)比較重要,可以作為描述話題的關(guān)鍵詞。因此本文定義了話題簇下標(biāo)題的關(guān)鍵詞作為話題的關(guān)鍵詞。以話題“章瑩穎案訴訟被駁回”為例,可以提取新聞標(biāo)題中的“章瑩穎案”“訴訟”“駁回”“家屬”“校方”和“責(zé)任”等詞語(yǔ)作為話題關(guān)鍵詞。對(duì)于新聞文檔中的句子,包含話題關(guān)鍵詞越多,說(shuō)明該句子重要性越高。基于這種思路,計(jì)算句子的重要性得分。
首先需要計(jì)算關(guān)鍵詞的得分,也就是關(guān)鍵詞的詞頻。使用Python 的正則化匹配提取出含有關(guān)鍵詞的句子集合,過(guò)濾掉包含無(wú)關(guān)信息的句子。其次計(jì)算新聞文檔中關(guān)鍵詞的詞頻。設(shè)num(wi)為關(guān)鍵詞wi在某篇新聞中出現(xiàn)的次數(shù),∑num(wi)為所有詞語(yǔ)在該篇新聞中出現(xiàn)次數(shù)之和。則關(guān)鍵詞wi的得分SC(wi)的計(jì)算方式為:

計(jì)算出該文檔中關(guān)鍵詞的得分后就可以計(jì)算文檔中句子的得分。設(shè)文檔集合中第m個(gè)文檔的第n個(gè)句子Smn的重要性得分為SC(smn),那么該句子的重要性得分的表達(dá)式為:

計(jì)算出文檔集合中句子的重要性得分后,需要根據(jù)分?jǐn)?shù)進(jìn)行一次句子篩選。本文使用BERT 模型進(jìn)行文檔集合句子編碼。BERT 模型對(duì)于編碼的長(zhǎng)度有限制,因此本文在句子編碼前先提取了各文檔中重要性得分最高的句子,組合成新的文檔集合L進(jìn)行后續(xù)的編碼操作。
2.3 文檔集合編碼器模塊
經(jīng)過(guò)句子重要性評(píng)估后,新組合而成的文檔集合L中包含了m個(gè)涉案新聞句子,即{l1,l2,…,lm},其中l(wèi)i表示集合中的第i個(gè)句子。為了得到高質(zhì)量的句子和文檔集合表征,本文考慮將BERT 預(yù)訓(xùn)練模型應(yīng)用到話題摘要任務(wù)中。由于BERT 模型是基于詞元級(jí)別的編碼,不是句子級(jí)別的編碼,且該模型的片段嵌入部分用來(lái)判斷兩個(gè)句子是否有關(guān)聯(lián),只包含兩種類型的片段嵌入,不能直接運(yùn)用到輸入多個(gè)句子的話題摘要任務(wù)中。因此本文使用了基于改進(jìn)的BERT 模型的文檔集合編碼器,如圖2 所示。

圖2 文檔集合編碼器模塊
在文檔集合的每個(gè)句子li之前加入[CLS]標(biāo)記用來(lái)匯總句子嵌入信息,末尾加入[SEP]標(biāo)記以區(qū)分不同句子的界限。為了區(qū)分不同位置的句子,引入了Eodd和Eeven兩種不同的間隔片段嵌入。對(duì)于句子li,如果i為奇數(shù),則該句子的間隔片段嵌入為Eodd,反之i為偶數(shù)時(shí)嵌入為Eeven。通過(guò)這種編碼方式每個(gè)句子可以獲得句子的Token 嵌入El、間隔片段嵌入Eodd和Eeven以及位置嵌入Ep3 種嵌入的融合。經(jīng)過(guò)多個(gè)Transformer[27]編碼層編碼后,將句子li之前的[CLS]標(biāo)記輸出的表征T[cls]作為對(duì)應(yīng)句子的表征,可以記作Eli′。Eli′和每個(gè)句子表征在文檔集合編碼器中的位置嵌入Ep′,融合后組成一個(gè)輸入的表示序列。在序列的頭部加入一個(gè)能表示文檔集合的嵌入Eset,組合成一個(gè)完整的文檔集合-句子表征輸入序列,輸入到多個(gè)Transformer 編碼層中編碼。最終得到完整的文檔集合L的表征rset和句子編碼表征。
2.4 突出度計(jì)算模塊
話題摘要任務(wù)需要提取出具有代表性的句子,也就是突出程度高的句子,本文在文檔集合編碼和句子編碼的基礎(chǔ)上設(shè)計(jì)了一個(gè)單步步驟的句子突出度計(jì)算模塊。設(shè)文檔集合L的人工編寫的參考摘要為R,目標(biāo)是從L中提取k個(gè)能概括關(guān)鍵信息的句子作為摘要句。對(duì)于第t個(gè)選擇步驟,當(dāng)前已經(jīng)生成的摘要句子集合為-1。設(shè)lj為L(zhǎng)中尚未選擇的句子,通過(guò)計(jì)算由文檔集合編碼器輸出的集合表征rset和句子表征rli的雙線性映射函數(shù)Fpro,來(lái)衡量所選句子包含在參考摘要R中的概率,其表達(dá)式為:

式中:Wbm為雙線性映射的權(quán)重矩陣,可以對(duì)rset和兩個(gè)維度不同的向量分別做線性變換并將二者映射到另一個(gè)空間中。其目標(biāo)函數(shù)是將訓(xùn)練樣本中包含在參考摘要R中的句子的對(duì)數(shù)似然函數(shù)最大化,即:
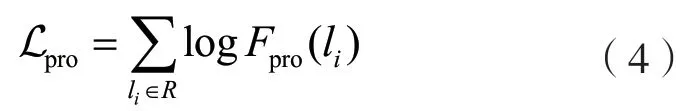
式中:雙線性映射函數(shù)Fpro作為衡量當(dāng)前候選句子li和尚未選擇的句子lj的突出度評(píng)分函數(shù),可以計(jì)算出每個(gè)候選句子的注意力得分,也就是句子的突出度得分。
2.5 重復(fù)特征計(jì)算模塊
計(jì)算出候選句子的突出度得分后,還需要計(jì)算句子的重復(fù)特征。在進(jìn)行第t個(gè)選擇過(guò)程時(shí),首先計(jì)算該過(guò)程的n元語(yǔ)法模型匹配特征,它表示候選句子li和已選擇的摘要句lt-1的n元語(yǔ)法詞組的重合程度,則有:

重合的詞組越多表明重復(fù)的特征越多,為了準(zhǔn)確計(jì)算重復(fù)特征,本文分別計(jì)算了一元、二元及三元語(yǔ)法模型的詞組重合度。
為了挖掘更深層的句子表征相似性,本文在得到n元語(yǔ)法模型的詞組重合度的基礎(chǔ)上,又融合了句子表征的最大語(yǔ)義相似性Fsim來(lái)計(jì)算重合特征,如:
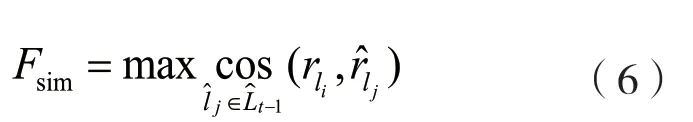
為了擴(kuò)大通過(guò)候選句子和已選句子的余弦相似度計(jì)算出的重合特征的數(shù)值差異,使用線性歸一化將特征值離散到0 和1 之間,則有:

重復(fù)特征計(jì)算模塊計(jì)算出兩種重復(fù)特征,將兩種特征融合可以得到整體的重復(fù)特征。首先將0 到1 的區(qū)間長(zhǎng)度等分為c個(gè)分塊,根據(jù)一元、二元和三元語(yǔ)法詞組的重合度特征以及歸一化的語(yǔ)義相似性特征將其數(shù)值離散到0 到1 之間等分的對(duì)應(yīng)分塊中,從而將每部分特征轉(zhuǎn)換為長(zhǎng)度為c的one-hot向量表示,并將各部分拼接融合,得到模塊整體的重復(fù)特征向量表征Frep(li)為:

式中:為各部分的重復(fù)特征向量分塊后的one-hot向量。這樣可以捕捉到各部分重復(fù)特征的影響,這是因?yàn)楣P者希望選擇的摘要句子具有較少的重復(fù)特征。
2.6 句子選擇模塊
通過(guò)句子突出度計(jì)算模塊和重復(fù)特征計(jì)算模塊得到突出度得分和重復(fù)性特征后,需要在句子選擇模塊中平衡這兩種特征,使得選擇的摘要句既要有一定的突出度,又不能含有過(guò)多的重復(fù)性特征。在句子選擇的第一步中,本文只提取突出度得分最高的句子作為摘要的第一句。通過(guò)計(jì)算突出度特征Fpro(li)和重復(fù)特征Frep(li)的雙線性映射函數(shù)來(lái)平衡候選句子li的兩種特征,得到一個(gè)d維的映射匹配向量。將其輸入到多層感知機(jī)中得到句子的最終得分SC(li),其計(jì)算公式為:

式中:為兩種特征的雙線性映射矩陣;Wh為多層感知機(jī)的權(quán)重矩陣。句子選擇模塊在訓(xùn)練過(guò)程中從參考摘要R里隨機(jī)選擇句子,讓模型學(xué)習(xí)上下文信息,并學(xué)習(xí)尋找下一個(gè)突出且不重復(fù)的句子。句子選擇模型的目標(biāo)函數(shù)為:

目標(biāo)函數(shù)表示在第t個(gè)過(guò)程中,選擇任何句子li的概率是句子得分SC(li)在L中剩余的句子lj上的softmax 函數(shù)。句子選擇模塊的損失與句子選擇的順序無(wú)關(guān),因?yàn)樵谟?xùn)練過(guò)程中給定的句子是一組無(wú)順序的句子,模塊的選擇對(duì)象總是下一個(gè)突出又不重復(fù)的句子,最終得到句子集合作為生成的話題摘要。
3 實(shí)驗(yàn)結(jié)果與分析
3.1 涉案新聞話題摘要數(shù)據(jù)集
涉案新聞話題摘要任務(wù)屬于針對(duì)司法案件特定領(lǐng)域的任務(wù),目前尚未有公開的數(shù)據(jù)集。因此本文在自行構(gòu)建的涉案新聞話題摘要數(shù)據(jù)集的基礎(chǔ)上開展具體工作。首先從各大新聞網(wǎng)站爬取涉案新聞話題數(shù)據(jù),并從中選取了30 個(gè)話題新聞簇,每個(gè)簇中的新聞都描述同一話題,每個(gè)簇含有20 篇涉案新聞,包括標(biāo)題與正文內(nèi)容,總計(jì)15 343 個(gè)句子;其次進(jìn)行了預(yù)處理。針對(duì)話題摘要任務(wù)對(duì)每個(gè)句子進(jìn)行標(biāo)注,構(gòu)建了涉案新聞話題摘要數(shù)據(jù)集,數(shù)據(jù)集的劃分如表2 所示。

表2 話題摘要數(shù)據(jù)劃分
3.2 評(píng)價(jià)指標(biāo)
本文模型性能的評(píng)估采用文本自動(dòng)摘要領(lǐng)域中常用的內(nèi)容度量評(píng)價(jià)方法,即通過(guò)計(jì)算ROUGE 值[28]來(lái)衡量生成摘要的質(zhì)量。ROUGE 關(guān)注的是召回率,其值越高表示模型生成的摘要與參考摘要越接近,效果越好。ROUGE-n通過(guò)匹配n-gram模型詞組的個(gè)數(shù)來(lái)確定生成的摘要與參考摘要的相似性,其計(jì)算方法為:

式中:n為n-gram模型詞組的大小,本文選取n=1,2 時(shí)的一元和二元詞組計(jì)算ROUGE-1 和ROUGE-2 的值來(lái)評(píng)價(jià)模型;nummatch(n-gram,為n元詞組在參考摘要R中出現(xiàn)的次數(shù)和生成的摘要中出現(xiàn)的次數(shù)二者之中的最小值;分母為參考摘要中所有n元詞組的總數(shù)。為了更全面地評(píng)價(jià)模型生成摘要的質(zhì)量,本文還采用了ROUGE-L指標(biāo)。ROUGE-L指標(biāo)是衡量生成的摘要與參考摘要之間最長(zhǎng)字符串的共現(xiàn)率的指標(biāo)。設(shè)參考摘要R={r1,r2,…,rn},ROUGE-L計(jì)算方法為:

式中:RL和PL分別為召回率和準(zhǔn)確率;α為召回率權(quán)重的超參數(shù)。RL和PL的計(jì)算方式為:

式中:L(ri,為參考摘要和生成的摘要中共現(xiàn)的最長(zhǎng)字符串的長(zhǎng)度;|ri|為參考摘要中的句子長(zhǎng)度;為生成的摘要的總長(zhǎng)度。ROUGE-L更多考慮召回率,因此將α 取較大的值。ROUGE-L越大代表兩句話共現(xiàn)的字符串長(zhǎng)度越長(zhǎng),二者更相似。
3.3 實(shí)驗(yàn)設(shè)置
模型實(shí)驗(yàn)采用改進(jìn)的BERT 預(yù)訓(xùn)練模型編碼話題簇新聞文檔和句子,包含12 個(gè)隱藏層,每層有12 個(gè)注意力頭,隱藏層維度為768,詞表大小為30 522。文檔集合編碼器編碼文檔集合的Transformer層數(shù)為2 層,各層的dropout 設(shè)置為0.1。訓(xùn)練批次大小為128,訓(xùn)練輪次為20,學(xué)習(xí)率為2e-3,優(yōu)化器采用Adam,β1為0.9,β2為0.999。式(8)中各部分重復(fù)特征的one-hot向量表示長(zhǎng)度c為20,式(9)中突出度特征和重復(fù)特征的雙線性映射輸出的特征維度d為10。模型訓(xùn)練采用從參考摘要中隨機(jī)選擇的無(wú)順序句子作為上下文信息。
3.4 基線模型分析
為了驗(yàn)證本文提出的壓縮空間的句子選擇模型對(duì)于涉案新聞話題摘要任務(wù)的有效性,本文選取了5 個(gè)模型作為基線模型,分別在構(gòu)建的數(shù)據(jù)集上進(jìn)行實(shí)驗(yàn),基線模型分別為L(zhǎng)EAD-3、LDA 主題模型、TextRank、BertSum 和RL-MMR。
(1)LEAD-3:是一種根據(jù)句子在文檔中的位置來(lái)抽取句子作為摘要的方法,該方法認(rèn)為文檔最重要的部分就是開頭部分,重點(diǎn)關(guān)注文檔開頭部分的前三句話,屬于一種硬攔截方法,只提取前三句話作為摘要句,其余內(nèi)容不考慮。
(2)LDA[7]:是一種主題模型,以概率分布的形式得到文檔的主題分布,其在摘要任務(wù)上選取含有主題信息最多的句子作為摘要句。
(3)TextRank[11]:是一種基于圖的重要性排序算法,以相似度構(gòu)造句子關(guān)系圖,計(jì)算每個(gè)句子節(jié)點(diǎn)的TextRank 得分,選取得分高的句子作為摘要句。
(4)DPP[29]:是將行列式點(diǎn)過(guò)程應(yīng)用在抽取式摘要任務(wù)上的方法,行列式點(diǎn)過(guò)程的目的是使得子集的選擇更具有多樣性,越相似的樣本越不能夠被同時(shí)選擇。
(5)RL-MMR[30]:該方法在最大邊際相關(guān)性(Maximal Marginal Relevance,MMR)算法的基礎(chǔ)上,利用分層編碼對(duì)多篇文檔進(jìn)行句子編碼,融合句子的表征和MMR 指導(dǎo)特征以及摘要的表征等多種特征迭代模型,從而選取句子的摘要。
將3 種ROUGE 值作為評(píng)價(jià)指標(biāo)進(jìn)行對(duì)比實(shí)驗(yàn),實(shí)驗(yàn)結(jié)果如表3 所示。

表3 基線模型性能比較
從表3 中的實(shí)驗(yàn)結(jié)果可以看出,LEAD-3 算法在生成涉案新聞話題摘要時(shí)效果最差,因?yàn)樗魂P(guān)注文檔集合的開頭部分,通過(guò)硬截止的方式抽取前三句話,而前三句話敘述了較多的無(wú)關(guān)信息,導(dǎo)致不具代表性的內(nèi)容較多,模型性能較差。LDA 主題模型依靠統(tǒng)計(jì)特征,由于涉案新聞的特殊性,LDA會(huì)出現(xiàn)主題重要性不一致的問(wèn)題。TextRank 算法是基于圖模型的,在構(gòu)建文檔集合中句子的關(guān)聯(lián)關(guān)系上有明顯優(yōu)勢(shì),但是該方法沒(méi)有首先進(jìn)行句子重要性篩選,應(yīng)用在涉案領(lǐng)域容易受到非話題關(guān)鍵詞的高頻詞的影響,所以在ROUGE-2 和ROUGE-L 指標(biāo)上有明顯的不足。DPP 模型的各項(xiàng)指標(biāo)均比之前的對(duì)比方法要好,該模型通過(guò)行列式點(diǎn)過(guò)程選擇具有代表性的樣本,利用膠囊網(wǎng)絡(luò)過(guò)濾掉含有重疊詞較少但是語(yǔ)義重復(fù)的句子,在去除重復(fù)特征方面效果較好,但是該模型缺少端到端的表示學(xué)習(xí),會(huì)造成誤差的積累,效果仍有待提高。RL-MMR 模型效果相比本文模型之外的對(duì)比模型,取得了不錯(cuò)的效果,但對(duì)比本文模型,RL-MMR 引入的軟注意進(jìn)行句子排名的方式并不完善,沒(méi)有話題關(guān)鍵詞信息的指導(dǎo),排名高的句子也會(huì)出現(xiàn)非話題關(guān)鍵信息。
本文模型引入句子重要性評(píng)估模塊后,過(guò)濾掉大量與關(guān)鍵信息無(wú)關(guān)的句子,并且將重復(fù)特征與突出特征進(jìn)行了平衡,最終選擇的句子的得分不會(huì)偏向于任意一種特征,從而達(dá)到了最好的效果。與基線模型相比,本文模型的ROUGE-1 值提升了1.44~6.47,ROUGE-2 值提升了0.96~6.34,ROUGE-L值提升了0.91~6.42,這也驗(yàn)證了本文提出的基于壓縮空間句子選擇的涉案新聞話題摘要方法的有效性。
3.5 消融實(shí)驗(yàn)分析
為了驗(yàn)證本文提出的話題摘要模型中各部分的有效性,將主模型消融為主模型去除句子重要性評(píng)估、主模型去除突出特征和主模型去除重復(fù)特征3個(gè)子模型,評(píng)價(jià)指標(biāo)均使用ROUGE 值計(jì)算,最優(yōu)結(jié)果用粗體表示,主模型和簡(jiǎn)化后的模型性能比較結(jié)果如表4 所示。

表4 簡(jiǎn)化模型性能比較
從消融實(shí)驗(yàn)的結(jié)果可以看出,去除模型的句子重要性評(píng)估模塊,各項(xiàng)指標(biāo)效果最差,ROUGE-1 值下降了6.28,ROUGE-2 值下降了6.32,ROUGE-L值下降了7.71。這是由于去掉該模塊后,模型輸入的句子集合未經(jīng)過(guò)濾,含有較多的非關(guān)鍵信息的詞語(yǔ),而且文檔集合編碼器模塊對(duì)于過(guò)多的句子編碼會(huì)進(jìn)行硬截?cái)啵瑢?duì)于話題內(nèi)容的描述不夠精確,與參考摘要的差異較大。模型去掉突出特征后,效果比去掉句子重要性評(píng)估模塊效果稍好一些,ROUGE-1 值下降了4.47,ROUGE-2 值下降了3.53,ROUGE-L值下降了5.94。因?yàn)槟P碗m然提取到了含有話題關(guān)鍵詞的句子,但是去掉了突出特征后,模型提取的摘要句子中的信息不具有代表性,同樣不能很好地描述話題內(nèi)容。模型去掉重復(fù)特征后各項(xiàng)指標(biāo)下降最小,ROUGE-1 值下降了3.73,ROUGE-2 值下降了2.42,ROUGE-L值下降了3.77。這是由于模型保留了突出特征的計(jì)算模塊,提取到的句子包含較多的代表性信息,但是去掉了重復(fù)特征,提取的句子集合會(huì)含有大量的重復(fù)信息,雖然關(guān)鍵信息多了,但是生成的摘要仍然不是最好的摘要,這也從側(cè)面印證了本文模型的有效性。
3.6 不同摘要長(zhǎng)度實(shí)驗(yàn)分析
為了驗(yàn)證模型生成不同長(zhǎng)度的摘要對(duì)ROUGE指標(biāo)的影響,即驗(yàn)證模型是否有較好的適應(yīng)性,本文設(shè)定生成4 種不同長(zhǎng)度的摘要進(jìn)行對(duì)比,實(shí)驗(yàn)結(jié)果如表5 所示。

表5 生成不同長(zhǎng)度的摘要性能比較
從表5 中可以看出,當(dāng)生成的摘要長(zhǎng)度為50和100 時(shí),模型的各項(xiàng)指標(biāo)效果最差,模型性能下降明顯,這是由于生成的摘要過(guò)短會(huì)造成大量的相關(guān)信息丟失。當(dāng)生成的摘要長(zhǎng)度為150 時(shí),模型接近最好的性能,長(zhǎng)度為200 時(shí)達(dá)到最好。這是由于構(gòu)建數(shù)據(jù)集時(shí),為各個(gè)話題簇編寫的人工參考摘要在測(cè)試集中的平均長(zhǎng)度在178 左右,生成的摘要越接近參考摘要的長(zhǎng)度,與參考摘要的共現(xiàn)詞組和最長(zhǎng)字符串?dāng)?shù)量就會(huì)越多,模型的性能效果就越好。
3.7 實(shí)例分析
為了直觀地驗(yàn)證本文模型的效果,通過(guò)實(shí)例分析對(duì)比了本文模型和部分基線模型生成的話題摘要的效果。以涉案話題“西安奔馳女車主維權(quán)案始末”生成的話題摘要為例子,如表6 所示。

表6 話題摘要實(shí)例分析
從表6 中的實(shí)例結(jié)果可以看出,LEAD-3 方法生成的話題摘要容易提取到文檔集合開頭部分的引言等與話題無(wú)關(guān)的信息,非常依賴文檔的排列順序;TextRank 方法生成的摘要容易受到非話題關(guān)鍵詞的影響,且生成的摘要句子不夠連貫,出現(xiàn)了明顯的句子重復(fù)信息;RL-MMR 模型比上述兩個(gè)對(duì)比模型效果要好很多,很少出現(xiàn)重復(fù)的句子,但是由于缺乏話題關(guān)鍵詞的指導(dǎo),某些非重要的句子也被賦予了高排名。本文提出的話題摘要模型相比上述模型提取到的摘要句子,包含了話題的全部關(guān)鍵詞,且信息具有代表性,沒(méi)有出現(xiàn)重復(fù)描述的句子,得到的話題摘要質(zhì)量較高,在本文的研究任務(wù)上具有優(yōu)勢(shì)。
4 結(jié)語(yǔ)
本文針對(duì)話題簇中文檔搜索空間較大,以及存在較多與話題關(guān)鍵信息無(wú)關(guān)的句子的問(wèn)題,提出了一種基于壓縮空間句子選擇的涉案新聞話題摘要方法。通過(guò)句子重要性評(píng)估模塊提取包含話題關(guān)鍵詞的句子,利用雙線性映射函數(shù)平衡句子的突出特征和重復(fù)特征進(jìn)行句子評(píng)分,實(shí)現(xiàn)與話題重要信息相關(guān)的句子的抽取。此外,基于構(gòu)建的涉案新聞話題摘要數(shù)據(jù)集以及人工編寫的參考摘要,通過(guò)各種實(shí)驗(yàn)證明本文提出的話題摘要模型可以抽取出既有代表性信息又不重復(fù)的關(guān)鍵句子,生成的摘要具有較高的質(zhì)量。
在未來(lái)的工作中,將探索大規(guī)模話題摘要數(shù)據(jù)集的處理工作,在大規(guī)模數(shù)據(jù)集預(yù)訓(xùn)練模型上進(jìn)一步提高生成的話題摘要的質(zhì)量。
猜你喜歡
瘋狂英語(yǔ)·新策略(2019年10期)2019-12-13 08:43:28
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
數(shù)學(xué)小靈通·3-4年級(jí)(2017年9期)2017-10-13 08:10:54
中華手工(2017年2期)2017-06-06 23:00:31
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長(zhǎng)指南(2015年4期)2015-05-19 14:47:56
中外會(huì)展(2014年4期)2014-11-27 07:46:46
河南科技(2014年23期)2014-02-27 14:19:15
祝您健康(1987年3期)1987-12-30 09:52:32
