多模態藏語情感分類的研究*
2022-10-14 06:55:04拉桑吉安見才讓
計算機時代 2022年10期
拉桑吉,安見才讓
(1.青海民族大學計算機學院,青海 西寧 810007;2.青海省藏文信息處理與機器翻譯重點實驗室;3.省部共建藏語智能信息處理及應用國家重點實驗室)
0 引言
近年來,深度學習體現出較為優異的學習表現,越來越多的研究人員開始傾向使用神經網絡來學習文本或者圖像的特征用于情感分類。但是單一模態的信息量容易受到其他因素干擾。通常情況下,對于一個雖然帶有情感色彩但情感傾向不明顯的藏文句子,如果配上表情和圖,其情感傾向相對會清晰很多。在社交平臺中圖像與文本存互補性,圖文兩種模態的信息往往比單一模態表達的情感更明確。所以多模態數據能有效地預測藏族網民所表達的情感傾向。
1 相關研究
多模態情感分類的目標是識別帶有情感色彩的文本及圖像內容的情感極性。本文將情感極性分為三大類,即為積極情感傾向和消極情感傾向、中性等三種極性。積極情感極性由{1}來表示、消極由{-1}表示、中性由{0}表示。
1.1 單模態情感分類研究
⑴文本情感分類
本文是基于深度學習的方法。孫旺本等將深度學習算法的CNN-LSTM(convolutional neural networklong short-term memory,CNN-LSTM)等模型引入藏文的情感傾向分析中;訓練了藏文微博詞向量模型,提高了特征向量對文本語義信息的表達。
一些藏文語料分詞存在不統一的問題。普次仁等將藏文用詞向量表示詞語,利用無監督遞歸自編碼算法對矩陣向量化,預測藏文語句的情感傾向,其不足點是并未探究語料庫大小對深度學習算法性能的影響,以及深度學習中參數較多引起的過擬合現象。曲塔吉將基于注意力機制和LSTM 的神經網絡對藏文多極情感句子做了情感分析實驗,建立藏文多極情感數據集,使用注意力機制和BiLSTM 神經網絡模型來實驗,正確率很高。
本課題先收集藏文情感數據集,對其進行數據預處理。由于目前在藏民族居住地區沒有公開的情感數據資源,在數據預處理時將藏文分詞、情感標注等工作都按照藏文傳統文法結構,由人工進行完成。
⑵圖像情感分類
論文選用情感特征提取方法研究圖像情感數據集。Chen等提出一個包含多個CNN的深度神經網絡對圖片情感進行分類,模型性能顯著優于傳統的機器學習模型。Yang等提出了圖片局部區域信息和整體信息的圖片情感識別模型,取得良好的效果。曹建芳等提出了基于Adaboost-BP 的圖像情感分析方法,使用Adaboost 算法結合BP 神經網絡的弱分類器,構成一個強分類器,取得了良好的實驗效果。
首先收集圖像情感數據集,這些圖像數據集都是在各種社交平臺中使用藏文的網民平時所使用的評論表情圖像,然后對其進行情感標注及數據預處理工作。
1.2 多模態情感分類研究
多模態情感分類研究可分為特征融合好、中間層融合和決策融合,本課題選擇特征融合。在多模態情感分類研究方面,各專家和學者都選用適合各種課題的技術來研究。
Jindal 和Singh使用卷積神經網絡(Convolutional Neural Network,CNN)構建圖像情感預測框架,使用于對象的識別與遷移學習當中,在人工標注的圖像數據集上進行實驗。多模態情感分類有著很大的研究空間。謝豪等提出了一種基于多層語義融合的圖文情感分類模型對社交媒體圖文數據進行情感分類,以提高情感分類性能、為政府、企業決策提供科學依據。
綜上所述,目前在藏民族居住地區對情感分類的研究尚未涉及多模態情感分類。所以,本文選擇對多模態藏語情感分類進行研究,以期得到更準確的藏民族情感分析數據。
2 模型設計
對本課題的研究選用一種即適合藏文文法結構,又適合圖像情感特征提取的神經網絡模型是對多模態情感分類及識別的重要基礎。從多模態藏文文本及圖像情感分類的角度出發對神經網絡模型的選擇進行了分析研究,將深度學習的算法模型引入多模態藏語情感分類當中。接下來會簡單的將兩種單個模態的模型以及融合后的結果進行分析。
2.1 基于全連接神經網絡的藏文情感分類模型
在藏文文本的情感分類任務中,對藏文句子提取特征的時候應該要增大對藏文關鍵詞的影響力,從而提高藏文情感分類的神經網絡模型識別率。
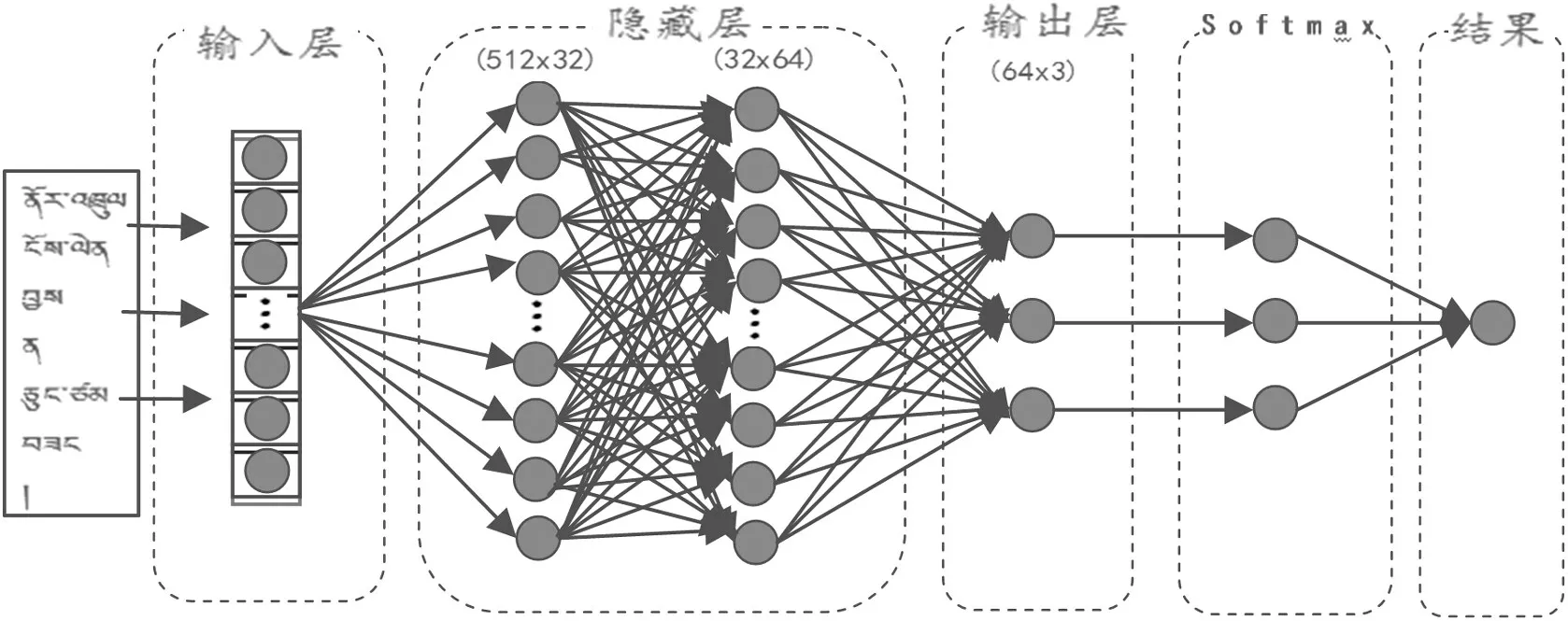
圖1 藏文文本情感分類的全連接神經網絡模型(FCNNMSCTT)
FCNNMSCTT 模型主要目的是識別出不同藏文句子的情感的類別和極性,有3種分類極性,分類任務數據集表示為D=(S,S,…,S,…,S)。公式如下:

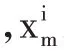
FCNNMSCTT 模型把輸入數據分成兩個部分:詞和字符,并將詞和字符都表示成嵌入向量。其表達形式如式⑵中兩個公式:
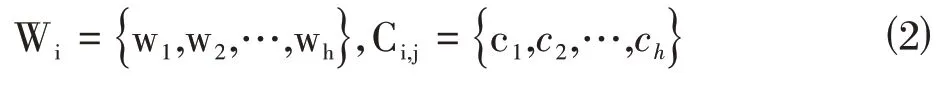
其中,W表示第i 個的詞S詞向量,C表示第i 詞的第j 個字符嵌入向量。
在收集的情感語料中,其訓練句子樣本的長度不同,包含的詞與字符的長度也不同。在藏文情感分類上我們需要考慮怎樣把藏文的字符向量和詞向量的維度大小一致,長度大小一致等問題,因此,我們把藏文情感語料的字符向量和詞向量設置為512,句子長度統一設置為80,模型的輸入向量Tc計算方法如式⑶所示:

句子S的向量表示為:

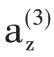
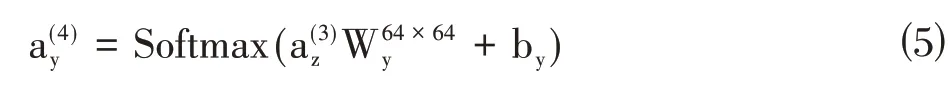
2.2 基于卷積神經網絡的藏語情感分類表情圖像模型
藏語情感分析表情圖像的深度學習我們采用了卷積神經網絡,模型如圖2所示。
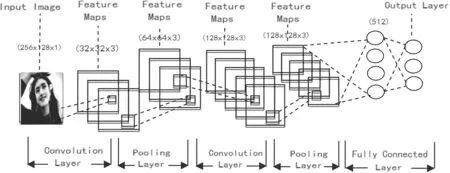
圖2 藏語情感分類中表情圖像的卷積神經網絡模型(CNNMEITSA)
使用CNNMEITSA 模型中,輸入層圖像大小為256×128×1。使用卷積核對此進行特征提取和特征映射,第一個卷積層深度為32,卷積了四次池化了四次之后,全連接三次把第五層的輸出數據全部做拼接成維度為512 的張量YC,再做全連接處理,激活函數ReLu,輸出維度為3的張量Y,表達式為:
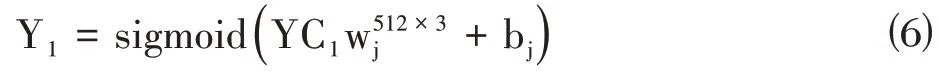
輸出結果Y計算出每一個圖像情感繼續極性。
2.3 基于神經網絡的多模態圖文融合的網絡模型
多模態圖文情感分類中每一張積極圖像的特征和一條積極的藏文情感文本的特征相對應,一張消極圖像的特征和一條消極的藏文情感文本的特征相對應,中性圖像的特征和中性句子的特征對應的存在。在最后結果輸出時,對比圖像標簽和文本標簽的權重哪個模態正確率高,就會取出那一方的正確率來輸出分類結果。
3 實證研究
3.1 實驗概述
基于神經網絡情感分類模型的實驗平臺是基于Python 編程語言的Anaconda 平臺中環境選擇了TensorFlow 和Keras。實驗數據為多模態藏語圖文情感分類數據共6000多條,主要運用的神經網絡算法的知識有全連接神經網絡、卷積神經網絡等。
3.2 實驗環境介紹
本課題的所有實驗都是在同一個的硬件配置下的計算機上完成的,下面硬件及軟件的實驗環境進行介紹,具體如表1、表2所示。

表1 計算機硬件配置表
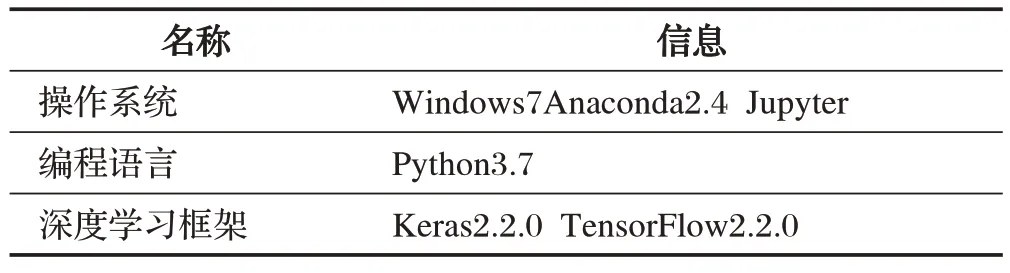
表2 計算機軟件配置
4 實驗結果分析
4.1 測試數據
本課題是以藏文情感句子當中的情感極性以及圖像中文的情感特征為研究對象,從而建立起6000多條藏文情感句子及情感圖像的數據集。
⑴藏文文本的三種情感極性:積極情感數據有表示滿意句子、表示一般滿意句子、表示非常滿意的句子;消極情感數據有表示不滿意的句子、表示一般不滿意的句子、表示非常不滿意的句子;中性句子不表達任何帶有情感色彩及情感傾向的句子。每一種情感數據都會按照句子本身所表達的情感極性做與之相對應的標注。其數據示例表3所示。

表3 情感文本數據示例
⑵情感圖像的三種情感極性:積極圖像數據有表示吉祥、開心、高興、興奮等圖;消極圖像數據表示不開心、不討喜、難過、傷心、孤獨、流淚等圖;中性圖像表面看不出任何內心活動的圖像、面無表情的圖。每一張圖都會根據圖片本身所表達的情感傾向為出發點進行標注。其數據示例圖3所示。

圖3 情感表情圖像數據集
本課題采用了基于深度學習全連接神經網絡和卷積神經網絡模型進行訓練,在數據相同的驗證集上提高識別精度。此外,在測試集中選擇不同情感極性的2400 條句子、2400 張圖片作為訓練樣本,600 條句子和圖像作為測試樣本來驗證識別效果。
4.2 結果分析
基于神經網絡的模型在圖像情感分類上的表現優異。本次實驗的數據共有3000 條文本情感數據和3000多張圖像情感數據其實驗結果如圖4所示。

圖4 三個模型訓練結果示例
其中圖4(左)表示文本模型的結果,圖4(中)表示圖像模型的結果圖4(右)表示融合后的結果,各個模型實驗結果數據如表4所示。
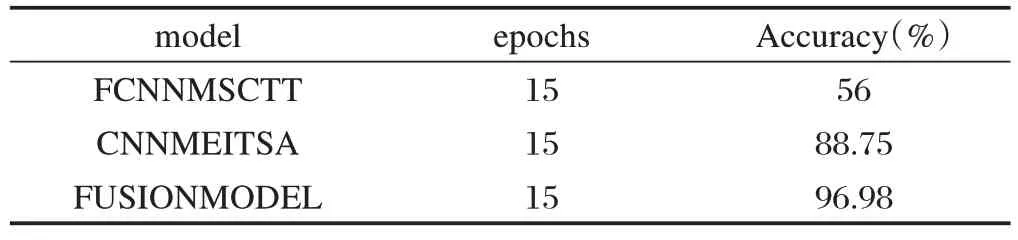
表4 各模型實驗結果示例
表4 中文本模型FCNNMSCTT 最終正確率56%、表情圖像模型CNNMEITSA 正確率88.75%、融合模型FUSIONMODEL 正確率96.98%。實驗分析可知數據在計算機識別后的結果跟人想要表達的情感是十分吻合的。證明了多模態對人類日常生活中情感表達的影響程度比單個模態強很多。
本文對多模態情感分類識別的模塊進行了實驗。最終的實驗結果表明模型框架損失值低、識別率高、分類性能優。得出實驗過程中樣本數據越多,其算法對情感分類的識別準確率也會逐步提升趨于穩定,損失值也會隨之降低的結論。后期還會增加數據查看此模型實驗相對于其他模型是否更具穩定性,增加語料之后的準確率會不會也隨之上升。
5 總結與展望
針對當前多模態藏語情感分類的不足,提出了基于神經網絡FCNNMSCTT、CNNMEITSA 情感分類模型。實驗結果表明,基于神經網絡的多模態情感分類模型具較高的準確率。但現有的多模態圖文情感分類的數據少、也沒有公開的數據,只能花費大量的人工進行采集和標注。在未來的研究中,多模態圖文情感分類語料庫需要進一步的建立、提高語料標注效率。
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
制造技術與機床(2019年10期)2019-10-26 02:48:08
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
電子制作(2018年18期)2018-11-14 01:48:06
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
小學教學參考(2015年20期)2016-01-15 08:44:38
湖北經濟學院學報·人文社科版(2015年8期)2015-12-29 05:53:07
上海電機學院學報(2015年4期)2015-02-28 14:30:00
計算物理(2014年2期)2014-03-11 17:01:39
