基于文本挖掘的后疫情時期民眾訴求主題研究*
2022-10-14 06:55:02劉建義
計算機時代 2022年10期
劉建義,夏 換,周 潔
(1.貴州財經大學信息學院,貴州 貴陽 550025;2.貴州財經大學電子商務大數據營銷工程研究中心)
0 引言
隨著后疫情時代的來臨,我國民眾的健康信息素養(yǎng)顯著提升,居家隔離時通過各種渠道獲取健康信息知識,并且在微博、抖音等社交媒體平臺發(fā)布個人訴求、表達個人情感等,特別是伴隨著熱點事件的出現,民眾的情感表達和現實訴求會集中性的出現。
智能終端的普及使得我國網民下沉現象明顯,研究對象不僅僅局限于青年群體,中老年群體也開始成為研究對象的一部分,一定程度上豐富研究對象的年齡屬性和群體屬性使得結論更具現實意義。
當下社交媒體的便利性使得民眾表達訴求和情感的方式變得簡單。例如:一條微博抖音評論、一條政府留言板留言、一條朋友圈、一條彈幕等都可成為其表達情感和訴求的途徑。表達途徑的方便往往造成信息的冗雜,為方便政府及時了解后疫情時期民眾的切實訴求,所以采用LDA 主題模型和社會網絡分析對人民網評論數據進行歸類總結,構建主題詞圖譜;同時根據時間的推移構建民眾訴求主題的演化趨勢。
1 研究綜述
曾子明、孫晶晶兩位學者以新冠疫情為例,從用戶注意力的角度對突發(fā)公共衛(wèi)生事件輿情情感的演化進行了相關研究,著重考慮了影響用戶情感分析的用戶特征這一影響因子,提出基于用戶注意力的情感分析模型,對輿情情感演化具有一定的可解釋性,但是其數據單一,未考慮數據的多元性。曹樹金,岳文玉就突發(fā)公共衛(wèi)生事件微博輿情主題挖掘與演化分析進行了相關研究,通過生命周期理論對突發(fā)公共衛(wèi)生事件微博轉播階段進行劃分,利用LDA 主題模型實現文本聚類和TF-IDF 特征權重賦值,分析2020.01-04的熱門微博和評論文本數據,指出LDA 主題模型可以揭示突發(fā)公共衛(wèi)生事件微博的傳播內容主題。王偉、高寧、徐玉婷等利用LDA 主題模型對眾籌項目在線評論主題動態(tài)演化分析進行了相關研究,得出LDA 主題模型可以很好的處理在線評論的主題動態(tài)演化。楊建梁、劉越男等就2019 年12 月1 日-2020 年5 月15 日部分地市的人民網地方政府留言板的民眾留言進行了數據挖掘分析,數據來源較為單一,部分民眾的訴求還是難以得到體現,但是他考慮到了空間因素對民眾訴求的影響。顏端武、梅喜瑞等基于主題模型和詞向量融合的微博短文本主題聚類研究,利用LDA 主題模型對微博一段時間內的的熱點進行聚類分析,發(fā)現對微博短文本的處理效果較好。楊奕、張毅以中美貿易爭端為案例,利用LDA 主題挖掘與社會網絡分析算法探究復雜公共議題下社交媒體演化趨勢,先利用LDA 主題模型提取出議題關注主題,實現降維分類,然后進行主題時間趨勢分析,最后利用社會網絡分析構建主題詞圖譜,明確了主題議題之間的聯系。
2 數據獲取
研究數據采用2021 年5 月-11 月人民網地方政府留言板的新冠疫情有關留言內容、留言標題和央視新聞2021年5月-11月與新冠疫情有關的微博評論內容。
數據的獲取采用Python 爬蟲技術獲取,利用Python 爬蟲第三方庫selenium 即瀏覽器自動化操作框架,這里主要用到WebDriver這一個工具,接著利用element_by_xpath 或css_selector 進行數據抓取,具體處理過程為:
⑴新建.py 文件導入第三方庫selenium、Pandas、time、csv、requests、json、lxml、urllib.;
⑵獲取URL;
⑶設置代碼自動點擊登錄按鈕,然后選擇掃碼登錄,程序休眠5秒方便掃碼;
⑷登錄后利用by_xpath 選擇內容搜索,keyword=新冠疫情;
⑸建立空白詞典詞典內容包括留言時間、留言內容內容、留言標題;
⑹抓取數據,F12 進入開發(fā)者選項利用by_xpath抓取所需數據的源代碼,同時設置代碼將滾動條拖到最后方便獲取全部數據。
另外因為微博評論的特殊性,使用移動端源代碼獲取評論較為簡單,需要找到爬取微博評論的URL、cookie、Referer、User-Agen;除此之外因為現在微博的反爬蟲機制,20 條評論后會出現一個隨機變化的max_id 參數,設置代碼捕捉這個參數就可以實現翻頁爬取。
3 LDA主題聚類及社會網絡分析可視化
LDA主題模型(圖1)是一個“文本-主題-單詞”的三層貝葉斯產生式模型,即三層貝葉斯概率圖,包含文檔、主題、主題詞三層結構,該方法首先選定一個主題向量θ,確定每個主題被選擇的概率。然后在生成每個單詞的時候,從主題分布向量θ 中選擇一個主題z,按主題z的詞語概率分布生成一個詞語。
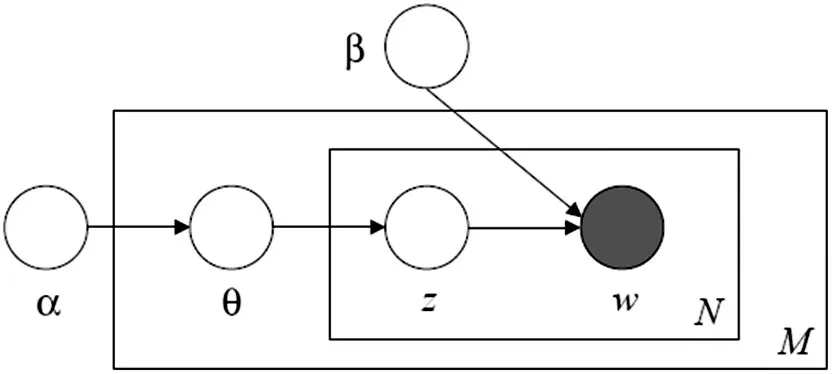
圖1 LDA主題模型邏輯圖
為了更科學的確定主題數不僅要從模型效果的角度,還要考慮所獲主題是否具有良好的解釋性。擬采用困惑度(Perplexity)指標來確定最優(yōu)主題數,困惑度越低,說明聚類的效果越好。
根據困惑度確定好主題數之后,進行LDA 主題模型分析,分析結果利用pyLDAvis 包進行數據可視化,方便政府更加清晰直觀的獲取民眾訴求主題熱點。
從圖2 可以很明顯的看出,文本聚類圈之間沒有重合,說明聚類效果很好。

圖2 LDA聚類圖
利用LDA 主題聚類結果可以很清楚的了解到住房問題、工作問題、醫(yī)療問題、考試教育問題、旅游問題成為當下民眾最關心的問題,也代表了他們當下的切實訴求。為了方便歸類統計,設計了表1。

表1 主題熱詞歸類表
另外,為了更直觀地表達各個主題詞聯系的緊密程度和主題熱詞隨時間推移的演化趨勢,本次研究中采用社會網絡分析法來進行可視化分析。利用社區(qū)探測算法(模塊化),根據原始圖中各個關系節(jié)點相互連接的歸類。類型相同的兩個節(jié)點在模塊化處理過程中會隨之增加一個字段(數字表示)。通過計算社交網絡各個節(jié)點的連邊數與隨機點的連邊數之差,用于判斷該社交網絡的緊密程度。
將所獲數據依據時間維度來進行數據劃分,根據上述兩個網絡圖譜來分析,前幾個月,疫苗、防疫等主題熱詞出于中心緊密點,而隨著時間的推移,旅游、交房、供暖等主題熱詞開始由邊緣向中心移動。這表明疫情防控措施是非常有效的,公民由最開始的關心疫情物資政策逐漸變?yōu)殛P心疫情時期的教育、旅游、住房等重要的民生問題。我國民眾也由最初的恐慌性情緒轉變?yōu)橹饾u接受新冠疫情的常態(tài)化存在,特別是全民接種疫苗計劃的推進,使得民眾對新冠疫情的恐懼降到了最低,所以后疫情時期的日常生活問題就成了民眾最為關心的問題。
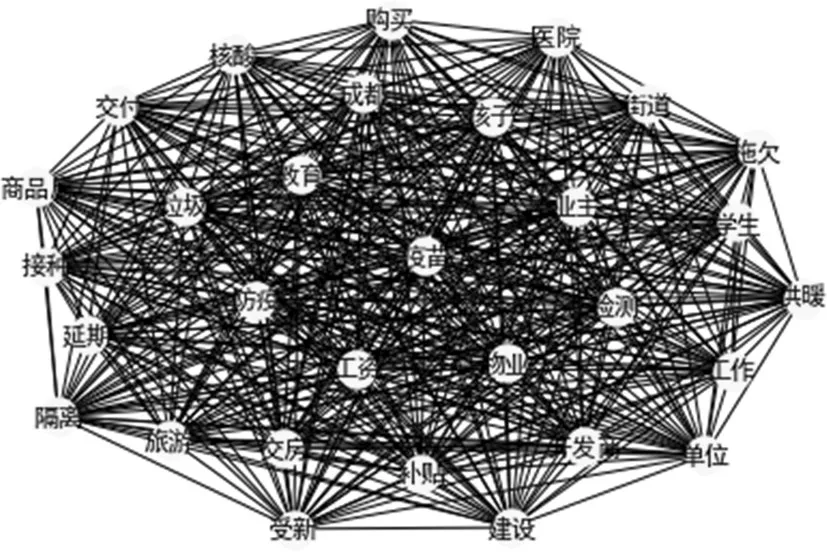
圖3 5-7月主題熱詞網絡圖
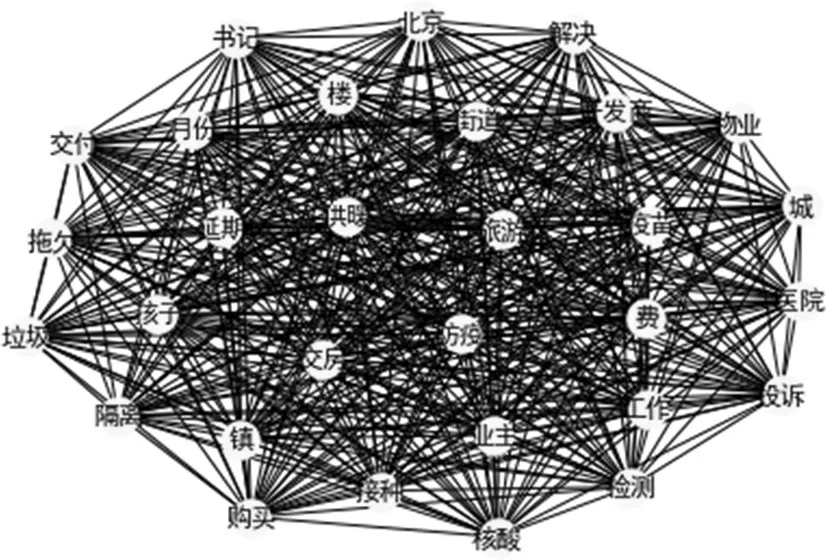
圖4 9-11月主題熱詞網絡圖
在研究過程中發(fā)現,民眾的訴求主題中不僅僅包括現實問題,還包括對熱點事件和政府防疫政策的情感表達(主要分為消極、積極兩種態(tài)勢)。針對這一突出問題,我們在閱讀相關文獻之后,決定在后續(xù)研究中采用機器學習算法對民眾情感進行分類研究,其中為了測試那種機器學習算法精確度和適配度最高,利用獲取到的數據構建了數據測試集,將1000條情感數據按照消極積極地情感屬性進行評分,帶入支持向量機、隨機森林、樸素貝葉斯三種機器學習算法檢驗模型適配度,結果如下:

圖5 隨機森林測試集數據圖
根據表2 顯示,隨機森林算法的各項指標都是比較理想的,所以針對新冠疫情熱點事件中民眾的情感態(tài)勢的科學把控,可以采用隨機森林算法進行情感分類。根據分類結果責成權威媒體進行發(fā)聲,方便政府進行社會輿論的引導。
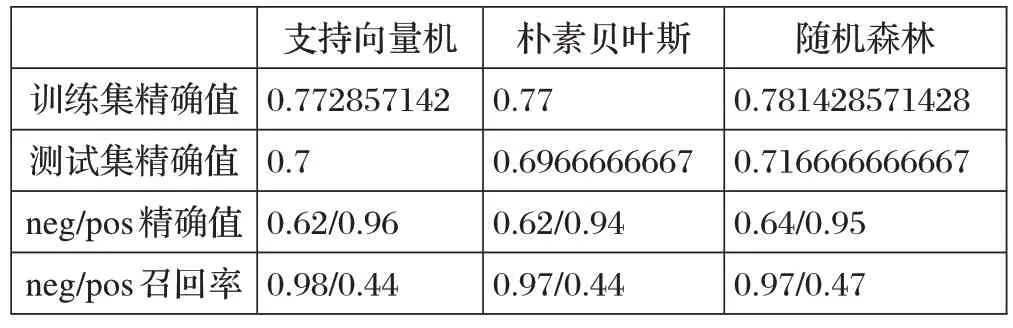
表2 測試集數據表
4 研究結論及解決意見
根據數據分析結果可以得出,住房問題、教育問題、工作問題、旅游問題成為了受關注度最高的問題,社會各界應當集中優(yōu)勢資源,優(yōu)先解決這些問題。
⑴住房問題的解決措施
住房問題多是何時可以交房、延期交房、供暖問題,所以針對這些問題政府應當敦促開發(fā)商嚴格按照合同規(guī)定交付住房、供暖等,落實追責制度;對于不可抗力原因延期交房、延期供暖的應當及時通過官方媒體、公眾號等渠道告知業(yè)主并且對其進行安撫,同時政府應當通過調配各種資源來保障這部分業(yè)主的正常生活。
⑵工作問題的解決措施
工作問題多是工資發(fā)放不及時、政府減免租金等問題。政府應當用盡用活各種優(yōu)惠政策,例如擴大租金減免的適用范圍、提高政府補助的額度、對符合條件的企業(yè)進行合理的稅務減免等等,給予中小企業(yè)強有力的支持,使其可以在新冠疫情的沖擊下仍能良性發(fā)展或者轉型;企業(yè)也應當調整發(fā)展戰(zhàn)略,適應后疫情時代的經濟環(huán)境,遵循政府的引導,挖掘潛在市場,為民眾提供一定的就業(yè)崗位,維護國家經濟穩(wěn)定。
⑶教育問題的解決措施
教育問題集中體現在各種證書和學歷的考試、公務員考試、幼兒園入學等。不同疫情地區(qū),在考試、開學時間,核酸檢測等方面應作出合理調整。
⑷旅游問題的解決措施
旅游問題集中體現在跨省旅游核酸、隔離、旅游退費等問題。針對這些問題加強防疫政策的宣傳,可考慮將抖音、快手等作為宣傳渠道。政府和相關機構應當制定出退費的標準,合理退費,從法律層面對疫情時期的退費進行規(guī)范法、法制化,不可自說其話影響自身公信力。
本文的研究主要是針對當下民眾的熱點訴求進行分析整理,針對新冠疫情熱點事件中民眾情感態(tài)勢的分類進行了數據集測試,結果顯示,隨機森林算法處理情感文本分類是最契合的。準確把握這些訴求有助于政府有針對性的解決民生問題,增強人民的獲得感、幸福感和自豪感。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
音樂天地(音樂創(chuàng)作版)(2022年1期)2022-04-26 13:51:10
中國生殖健康(2020年5期)2021-01-18 02:59:48
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
人大建設(2020年5期)2020-09-25 08:56:22
快樂作文(1.2年級)(2020年8期)2020-09-10 07:22:44
數學物理學報(2020年2期)2020-06-02 11:29:24
北極光(2019年12期)2020-01-18 06:22:10
小太陽畫報(2019年10期)2019-11-04 02:57:59
