基于多層次特征的RoQ 隱蔽攻擊無監督檢測方法
2022-10-09 12:48:56趙靜李俊龍春萬巍魏金俠陳凱
通信學報 2022年9期
趙靜,李俊,龍春,萬巍,魏金俠,陳凱
(1.中國科學院計算機網絡信息中心,北京 100083;2.中國科學院大學計算機科學與技術學院,北京 100049)
0 引言
隨著當前網絡安全防護方法和能力的升級,拒絕服務(DoS,denial of service)等常見攻擊已可以被輕松識別。然而,一類新的隱蔽攻擊悄然而生,即降質(RoQ,reduction of quality)攻擊。與傳統DoS 相比,RoQ 攻擊的原則不再是使目標系統完全喪失對正常請求的服務能力,而是利用互聯網廣泛采用的確保網絡公平性、穩定性的自適應機制,通過周期性地在短暫間隔內突發攻擊數據包,降低目標主機的服務質量。這種攻擊流量與正常流量幾乎沒有區別,很容易繞過常規的入侵檢測系統。
具體分析,RoQ 攻擊主要有以下特點。
1) 從流量特點上看,RoQ 攻擊呈現出脈沖式的特征。在一個攻擊周期中,只有大約的時間存在攻擊流量。因此,RoQ 攻擊也稱為脈沖式隱蔽攻擊[1]。
2) 從攻擊方式上看,RoQ 攻擊廣泛分布的攻擊者在目標路由器的末端聚合攻擊流量,使攻擊流量的分布在整個網絡中更加分散,平均流量更低。
3) 從攻擊行為上看,RoQ 攻擊可以使用從網絡層到應用層的任何協議合法流量,與普通應用具有相同的行為特征,能夠完全隱藏在海量網絡流量中。
4) 從攻擊目的上看,RoQ 攻擊主要是為了使系統運行速度減慢,服務質量下降。因此,大部分網絡管理員往往將此類情況歸因于系統故障或網絡線路故障,忽略了攻擊的可能性而導致處理延后。
僅利用流特征不能完全準確地區分RoQ 攻擊流量和正常流量。但是,從包特征上看,異常流量整體分布的形態差異與正常流量相比具有一定的區分度(例如,將兩段不同的流量從時域轉換到頻域,就能發現其中的不同)。因此,利用時序特征對這類攻擊進行檢測更合適。再者,真實環境中RoQ 攻擊樣本稀少,且每次攻擊都具有獨立性、特殊性,不容易使用監督學習方法來學習隱蔽的攻擊特征。因此,要求檢測方法在零先驗知識或極少先驗知識的情況下發揮作用。綜上,本文在完成大量攻擊試驗,并梳理RoQ 攻擊相關特征之后,提出了一種基于多層次特征的RoQ 隱蔽攻擊無監督檢測方法,主要創新點如下。
1) 提出了基于多層次特征的RoQ 隱蔽攻擊檢測的兩階段方法。根據目標在不同階段使用不同層面的特征,整體上達到了較好的效果。
2) 為了篩除大部分正常流量,減少對后續結果的干擾,研究了基于正樣本監督信息的半監督譜聚類方法。利用流特征,構造少量正樣本監督信息以修正樣本中偏離過大的離群點。同時構造標簽損失算法來評價算法損失度以便調整參數,使篩除正樣本的準確率接近100%。
3) 考慮到RoQ 攻擊流量特征不明顯,為了提高檢測率,將經典Shapelet 時間序列算法修改為多維算法,利用流量時序包特征構造了最具辨識度的n-Shapelet 基序列空間。經過空間投影后的特征能夠最大限度體現相似序列差別最大的局部特征,提高了RoQ 攻擊特征的識別率。
4) 考慮到RoQ 攻擊樣本稀少無法訓練檢測模型但仍需實現高精度檢測,構造了無監督分類優化模型。該模型能夠根據檢測結果多次迭代直至收斂到最優解,實現了無學習樣本的高精度檢測。
1 相關工作
一直以來,很多研究者著重研究RoQ 攻擊如何繞過檢測系統,以期更好地解決RoQ 攻擊檢測問題。Guirguis 等[2]最早提出了一種利用TCP 協議的低速率拒絕服務攻擊,這種攻擊沒有明顯的異常特征,利用傳輸控制協議(TCP,transmission control protocol)中自適應機制造成信道阻塞,從而達到攻擊目的。緊接著,Luo[3]介紹了一種短時間內阻塞鏈路的脈沖式拒絕服務攻擊;Guirguis 等[1,4]提出了利用動態負載均衡機制的RoQ 攻擊和針對內容自適應機制的脈沖式攻擊。近幾年的主要研究包括利用KeepAlive 機制占滿服務器等待隊列的攻擊[5]、強效的Shrew 變種FB-Shrew 攻擊[6]、利用物聯網設備之間消息隊列遙測傳輸(MQTT,message queuing telemetry trandport)協議漏洞的攻擊[7]、隱蔽漏洞掃描等其他脈沖探測類攻擊[8]。總體來講,RoQ 攻擊隱匿性高,缺乏已知樣本,是一種極難發現的新型攻擊。
現有針對RoQ 隱蔽攻擊的檢測方法大致可以分為基于信號處理、基于統計分析、基于數據建模及基于人工智能技術這4 種類型。
基于信號處理的檢測方法是最常用的,其核心思想是將流量時域特征轉換成頻域,來增加正常流量和異常流量的區分度。Chen 等[9]采用了2 個新的頻域特征:傅里葉功率譜熵(FPSE,Fourier power spectral entropy)和小波功率譜熵(WPSE,wavelet power spectrum entropy),提高了檢測率。Agrawal等[10]將流量從時域變換到頻域上,通過功率頻譜分布判斷攻擊。基于信號處理的檢測方法能夠從一定程度上檢測出RoQ 攻擊,但是在檢測深度偽裝、特征不明顯的攻擊時效果不佳。
基于統計分析的檢測方法根據流量偏離正常狀態的特征行為來進行識別。吳志軍等[11]根據低速率拒絕服務(LDoS,low-rate denial of service)攻擊周期性的小信號特征構造出特征值估計矩陣來判斷是否發生了攻擊。Tang 等[12]提出了一種自適應指數加權移動平均算法,根據加權值的變化檢測攻擊。在之后的研究中又基于脈沖流量離散特性提出一種新的統計方法來進行檢測[13]。為了進一步提高檢測率,Tang 等[14]提出利用用戶數據報協議(UDP,user datagram protocol)流量與傳輸控制協議(TCP,transmission control protocol)流量的比值(UTR,ratio of UDP traffic to TCP traffic)能夠更準確區分攻擊流量和正常流量。基于統計分析的檢測方法在設立閾值的過程中需要大量的專業領域知識和工程技能,煩瑣復雜,很難大規模使用。
基于數學建模的檢測方法是利用數據方法對網絡流量進行分析,區分出正常流量中的隱蔽RoQ攻擊。如Wu 等[15]研究了RoQ 攻擊對網絡流量的多重分形特性的影響,提出了MF-DFA(multifractal detrended fluctuation analysis)算法,計算正常情況和攻擊情況下的網絡流量H?lder 指數的差值來判斷是否發生了攻擊。
考慮到隱蔽RoQ 攻擊的特征提取困難,一些研究者開始考慮使用人工智能技術。例如,Koay 等[16]基于熵特征集成了循環神經網絡、多層感知網絡、交替決策樹3 個分類器形成投票系統,共同判斷流量異常。Tang 等[17]基于SADBSCAN(self-adaptive density-based spatial clustering of applications with noise)算法提出了在多密度數據集中自適應識別聚類的解決方案。根據網絡流量受到RoQ 攻擊的特點,對網絡流量進行分組。然后使用余弦相似度來確定每個組中是否包含攻擊數據。特征工程是基于人工智能技術的檢測方法中重要的一環,為了提高攻擊檢測率,Tang 等[18]提取了RoQ 攻擊中包括信息熵在內的28 個特征,并提出改進的MF-Adaboost算法,能夠更準確地檢測RoQ 攻擊。吳志軍團隊近幾年著重研究了利用路由器隊列管理機制漏洞的RoQ 攻擊的檢測方法。2018 年,吳志軍等[19]提取了路由器瞬時隊列和平均隊列作為數據特征,利用核主成分分析(KPCA,kernel principal component analysis)進行特征處理,并利用反向傳播(BP,back propagation)神經網絡進行訓練和檢測,效果較好。2020 年,該團隊[20]提出了基于序列確認號(ACK,acknowledge number)、報文大小和隊列長度的多特征融合的路由器降質攻擊檢測方法。每種特征分別輸入K 鄰近(KNN,K-nearest neighbor)分類器得到綜合的決策輪廓矩陣,并定義融合決策指標D 作為檢測RoQ 攻擊的依據,在一定程度上提高了檢測率。利用路由器漏洞的攻擊屬于眾多RoQ 攻擊的一種,在檢測時比較容易提取路由器隊列特征。而傳輸層和應用層的攻擊因流量特征與正常流量區別很小,很難提取有效特征,隱蔽性很強。
綜上,現有RoQ 攻擊檢測方法大部分假陰性率較高,僅適用于小規模數據,或只能在仿真集中實現,在真實環境中應用有一定的局限性。目前,基于人工智能技術的檢測方法研究進展較慢、實用性不強。大部分方法在訓練模型時需要大量已知的訓練樣本支撐,這與缺少真實樣本的現實情況相悖。其次,部分研究中的實驗是基于NS2 等模擬軟件的,實驗條件理想、數據單一,不具有說服力。此外,目前大部分研究沒有考慮到RoQ 攻擊的偽裝性,在海量流量中的識別性較差。
2 基礎知識
2.1 譜聚類
譜聚類是一種聚類算法,相較于傳統聚類算法,它對數據分布的適應性更強,聚類效果更好,計算量更小,在攻擊檢測中常常被用作聚類算法[21]。在對相似攻擊行為的聚類方面,譜聚類比K-means、(DBSCAN,density-based spatial clustering of applications with noise)等聚類算法輪廓系數更高,識別效果更好[22]。
譜聚類的主要思想是基于圖譜分割理論,主要流程如下。
目標:輸入n個數據點集,獲得k個聚類。
1) 利用距離公式計算每個點集的相似度,形成相似矩陣。
2) 利用相似矩陣構建鄰接矩陣N和度矩陣G。
3) 由步驟2)得到的鄰接矩陣N和度矩陣G計算得出拉普拉斯矩陣
4) 選取拉普拉斯矩陣的前k個最大特征值對應的特征向量。
5) 標準化特征向量,形成k×n維特征矩陣。
6) 將特征向量的每一行作為一個k維的樣本,共n個樣本,使用K-means 等聚類算法進行聚類。
2.2 Shapelet 時間子序列
2009 年,Keogh 等[23]在數據挖掘頂級會議上首次提出了時序數據中的Shapelet 的概念。Shapelet 是時間序列的子序列,是相似時間序列中最不相同的一段序列,在區分相似度很高的序列方面穩健性更強,準確性更高。它可以較充分地說明各個類別之間的差異,使分類結果具有更強的可解釋性。
Shapelet 子序列各概念定義如下。
定義 1時間序列及子序列。時間序列是按時間順序采樣的數據點構成的序列,t i(i∈1,2,…,n)是任意實數。子序列是從某一位置開始、長度為k的一段連續序列,
定義2時間序列的距離。將長度為m的2 條時間序列看作向量,它們之間的距離
定義3子序列和時間序列的距離。對于長度不同的子序列S和時間序列T,距離定義為S與T中長度與S相同的子序列的距離的最小值,即表示T中長度與S相同的所有子序列。
定義4信息增益。設數據集D被劃分為數據子集D1和D2,則其信息增益可表示為
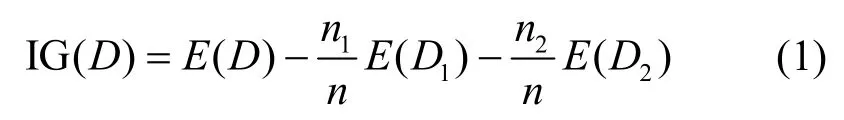
其中,n、n1和n2分別表示數據集D、D1和D2的大小。E(D) 表示D的熵,表示為
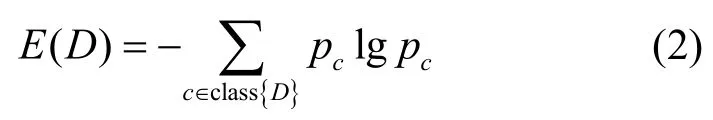
其中,pc表示屬于數據集D的元素c的概率。
定義5Shapelet 子序列。定義分裂點為一個二元組 <S,δ>,由子序列S和距離閾值δ組成,根據S與數據集中每一條時間序列之間的距離是否大于δ,將時間序列數據D分為DL和DR,當信息增益最大時即Shapelet,此時的距離閾值
Shapelet 子序列在網絡安全領域是一個較新的概念,但是已經在其他領域被用于時序異常檢測和預測[24-25]。在現有的研究中,Shapelet 可以與圖論[26]或神經網絡[27]結合完成分類。
3 RoQ 隱蔽攻擊無監督檢測模型總體框架
本文提出的RoQ 隱蔽攻擊無監督檢測模型包含2 個階段,分別使用了不同層面的流量特征。首先,利用流特征對流量進行初篩,篩除大量可能會干擾檢測效果的正常流量,保留正常流量與異常流量相對均衡的樣本。因此,要求篩選速度快、效率高,且篩除的正常流量的精確率接近100%。其次,利用時序包特征,在沒有先驗知識的情況下,對篩選后的流量進行無監督精準分類,要求分類模型具有局部特征差異的辨識能力。RoQ 隱蔽攻擊檢測模型整體框架如圖1 所示。其中,網絡流量通過數據平面開發套件(DPDK,data plane development kit)進行采集過濾,進入后續處理流程。
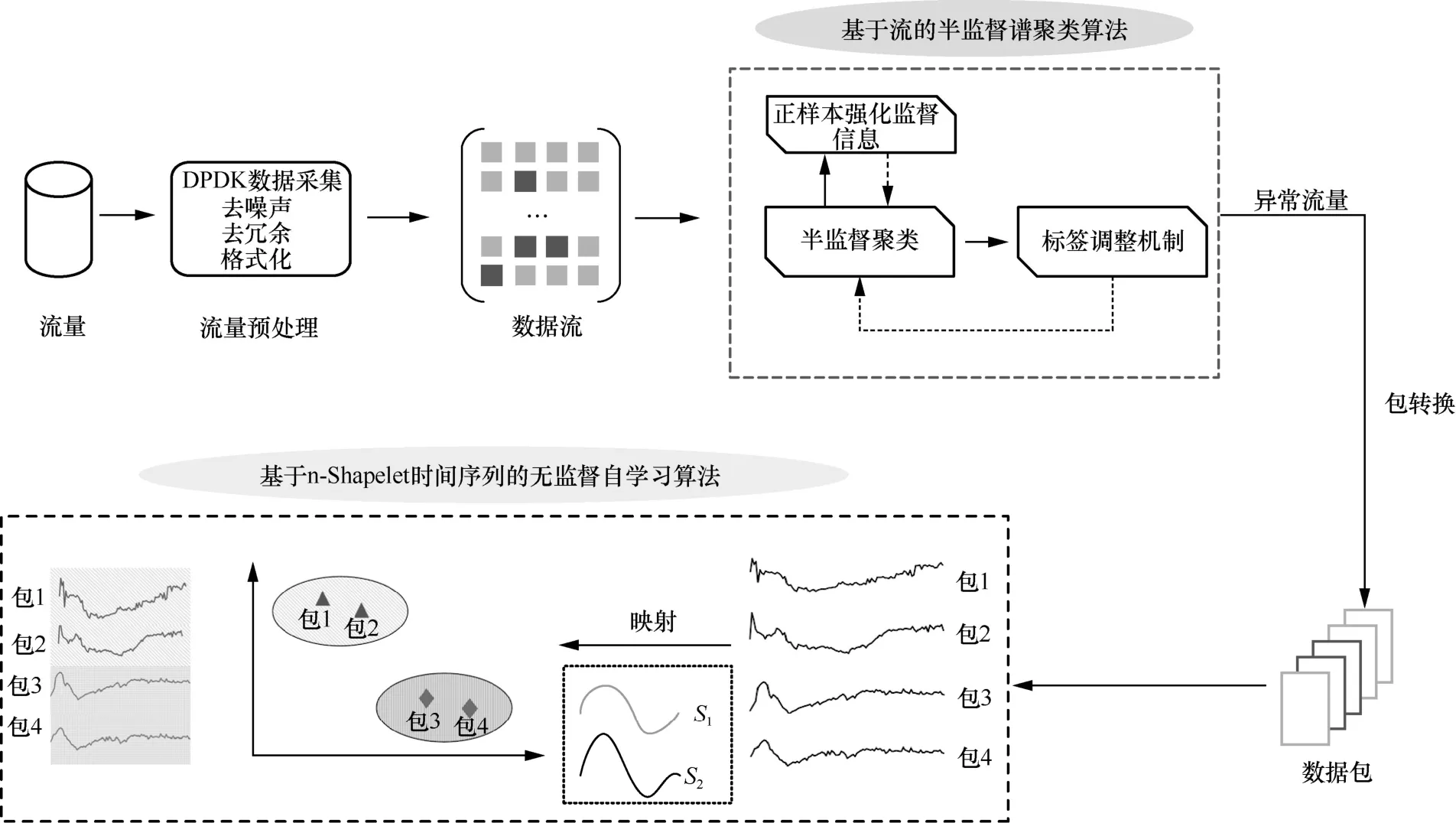
圖1 RoQ 隱蔽攻擊檢測模型整體框架
第一階段為基于流的聚類檢測算法,主要實現大量正常流量的篩除。該階段的輸入是去噪聲、去冗余格式化后經過特征提取后的網絡流特征,核心算法為改進的半監督譜聚類算法。為了提高正樣本分類的精確度,利用極少數已知的攻擊樣本構造正樣本強化監督信息。同時,為了最大化利用這些已知攻擊樣本,使譜聚類算法有最優的迭代次數限制,設計基于極少已知標簽的算法調整機制,根據調整機制評價結果調整參數和聚類次數。
第二階段為基于n-Shapelet 子序列的無監督自學習算法,主要實現剩余流量的準確分類。該階段的輸入是按時間排列的數據包,稱為時間包序列。首先,利用Shapelet 子序列的特點構造Shapelet 序列空間,該空間代表了樣本間差距最大的局部特征。其次,將每一個時間包序列映射到Shapelet 序列空間內,轉換為S空間特征,使用聚類算法進行聚類。為了使分類結果更準確,構造無監督目標優化函數來調整算法參數。
4 基于流的聚類檢測算法
通常,距離比較遠的數據被認為是不同類的,而距離較近的數據則是同類的。但在一些特殊情況下,存在一些距離較大但屬于不同類的、或者距離較小但屬于同類的離群點需要被修正。因此,本節提出一種基于半監督譜聚類的正常流量篩除方法,盡可能保證篩除的正常流量的精確度接近100%。在具體方法上包括3 個部分:正樣本強化監督信息構造主要實現去除正樣本側的離群點;半監督譜聚類算法主要實現數據流的聚類;基于極少已知標簽的算法調整機制主要實現聚類結果的合理評價。
4.1 正樣本強化監督信息構造
構造正樣本強化監督信息對,包括距離很大的正樣本信息對、正樣本與其他類型樣本距離很小的信息對。具體方法如下。
1) 關注的正常類別。初始化監督信息限制數目M,集合A為空,利用簡單專家知識規則在Qint中確定一定數量的正樣本,加入集合S中;初始化當前監督信息數目m=0 。
重復步驟2)和步驟3),完成正樣本監督信息集構造。監督信息集包括2 個集合,集合1 中都為正樣本,但彼此距離較遠;集合2 中一個為正樣本,另一個為其他類型樣本,但距離很近。
4.2 半監督譜聚類算法
本文提出的改進后的半監督譜聚類算法具有對正樣本修正的能力,具體算法R如下。
4) 選取P矩陣最小e個特征值對應的特征向量組成特征矩陣F,對F進行標準化后再聚類,得到聚類結果為正樣本的類別。
4.3 基于極少已知標簽的算法調整機制
基于半監督譜聚類算法通過監督信息消除了正樣本側的離群點,提高了分類的精度。在聚類過程中,數據集帶有極少已知的標簽信息。為了提高這部分信息的利用程度,得到更精確的聚類分配結果,使算法結果可評價,收斂速度可控,本文提出基于極少已知標簽的算法調整機制。
首先,定義p(yi,q)為樣本yi與類別q的相似度,也可以看作樣本yi屬于類別q的概率。
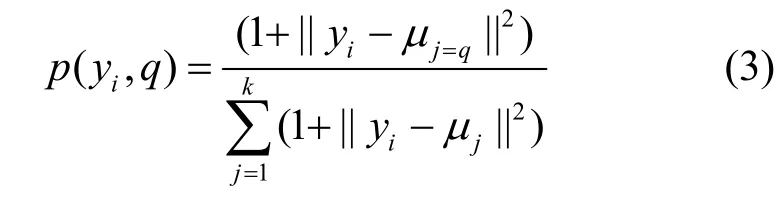
算法調整機制具體方法如下。
1) 對數據集使用算法R進行首次聚類,得到聚類結果,統計每類結果中標簽數據量最大的那一類作為該類的標簽c。對于已知標簽的部分樣本經過聚類后被劃分為代表不同的類別,*為任意整數。
2) 使用標記列表A′標記正樣本點的劃分正確與否,標記列表A′中元素ai的含義為
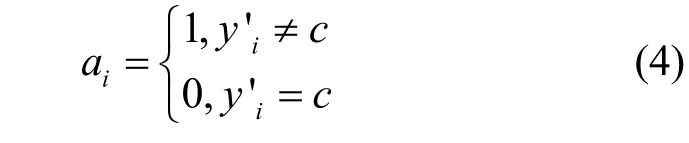
則已知標簽的正樣本聚類損失為
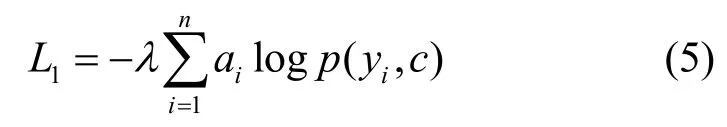
3) 使用標記列表B′標記負樣本點的劃分正確與否,標記列表B′中元素bi的含義為
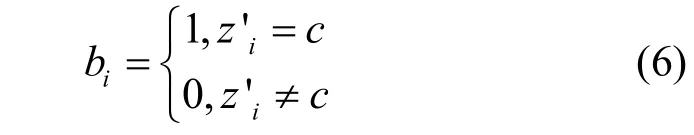
則已知標簽的負樣本聚類損失為
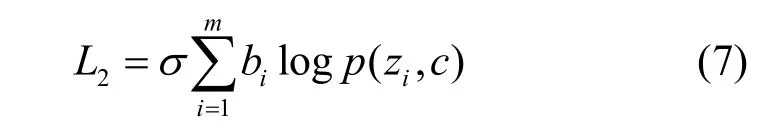
則整體損失為
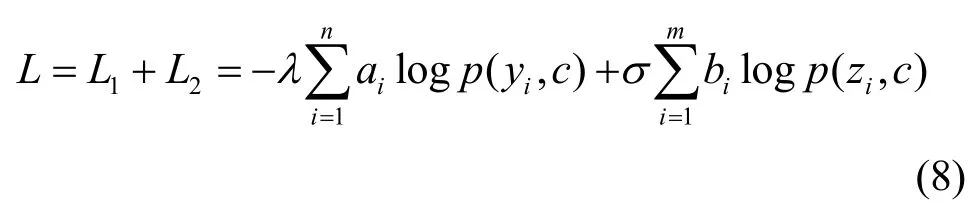
5 基于n-Shapelet 子序列的無監督自學習算法
第一階段的初步分類旨在精準地篩除大部分正常樣本,第二階段將完成更準確的分類。不同于第一階段基于流特征的方法,第二階段將剩余的流還原成數據包,按照時間順序排列形成時間序列,一條流表示為

其中,l表示時間序列的長度,n表示每一個數據包的特征維度。
5.1 Shapelet 空間特征映射
為了找到局部更具有區分度的特征,本節利用Shapelet 子序列完成特征提取。在待檢測的流量中尋找到時序包序列中的若干個最優Shapelet,構成S空間。將時間包序列投影到新空間,轉換為新特征再進行檢測。
根據Shapelet 定義[23],n維包序列的Shapelet子序列表示為
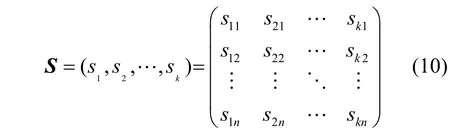
其中,k(k<l) 為Shapelet 子序列的長度,子序列的每個元素保持n個維度,用于表示序列短時間內(即長度k內)在所有維度上的綜合變化特征。選取若干個 Shapelet 子序列,構造 S 空間為
定義時間序列T與子序列S的距離為
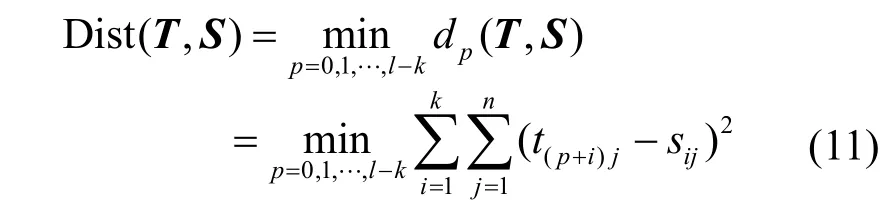
為了方便后續的最小化求解,距離函數連續化為
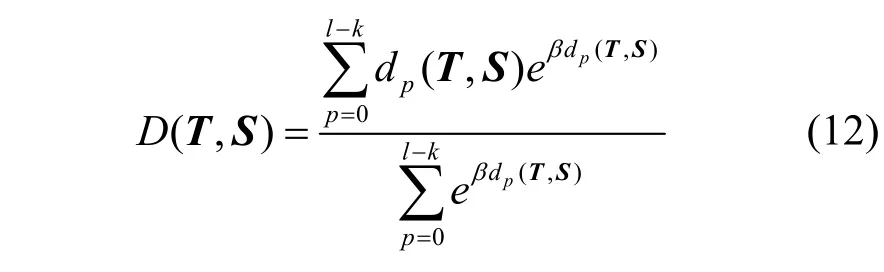
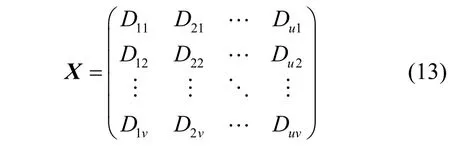
至此,原始包序列各特征投影到新空間形成新的特征矩陣X,新特征是在不同Shapelet 子序列上的投影,具有最佳辨識度,可以使用聚類算法對X進行聚類。
5.2 無監督分類優化模型
S空間的Shapelet 子序列可以最大程度地學到各個時間序列的最大區分局部特征,因此,需保證各個Shapelet 子序列的相似度最低。定義Shapelet相似度矩陣表示為

X經過聚類之后得到分類結果Y,并根據分類優化函數對參數W和S進行迭代優化,迭代過程如下。
1)Y的迭代
根據分類優化函數中的第1 項
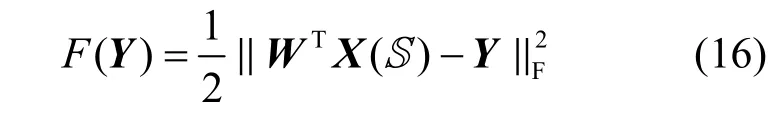
對Y求導并令其為0,有
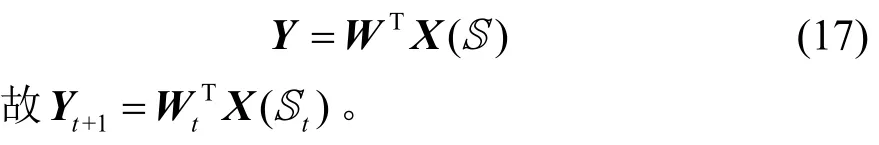
2)W的迭代
根據分類優化函數中的第1 項和第3 項
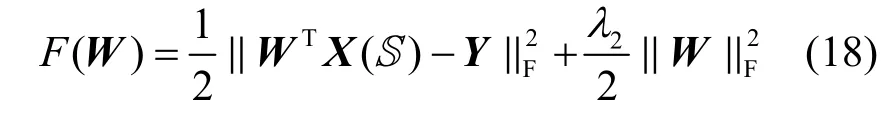
對W求導并令其為0,有
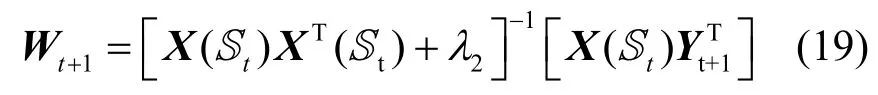
3)S的迭代
根據分類優化函數中的第1 項和第2 項
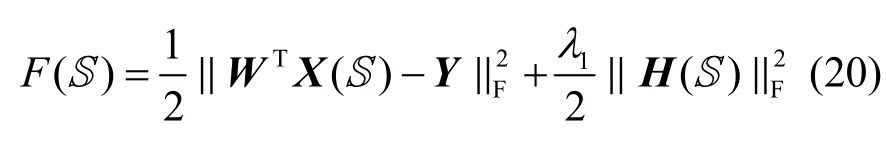
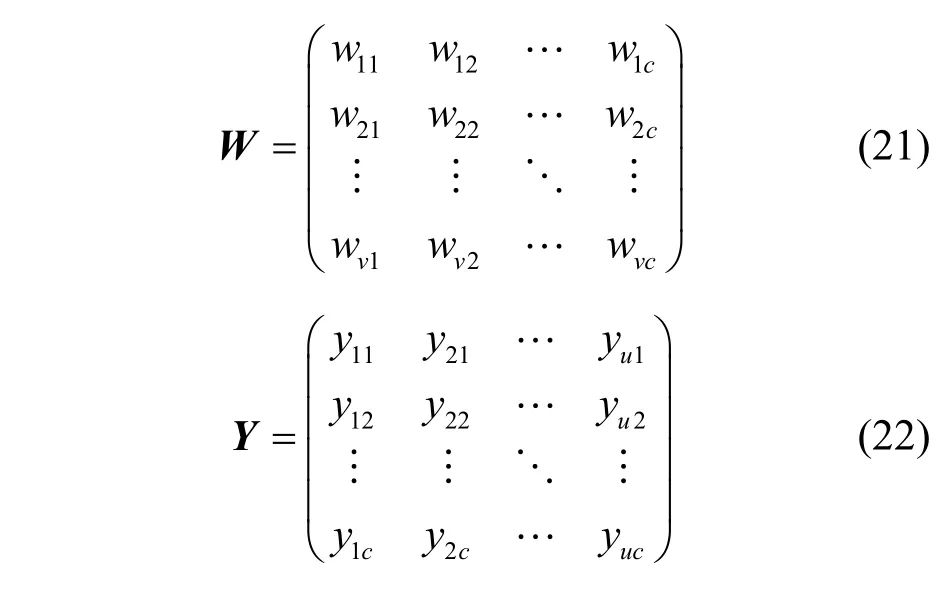
其中,c為類別數目。
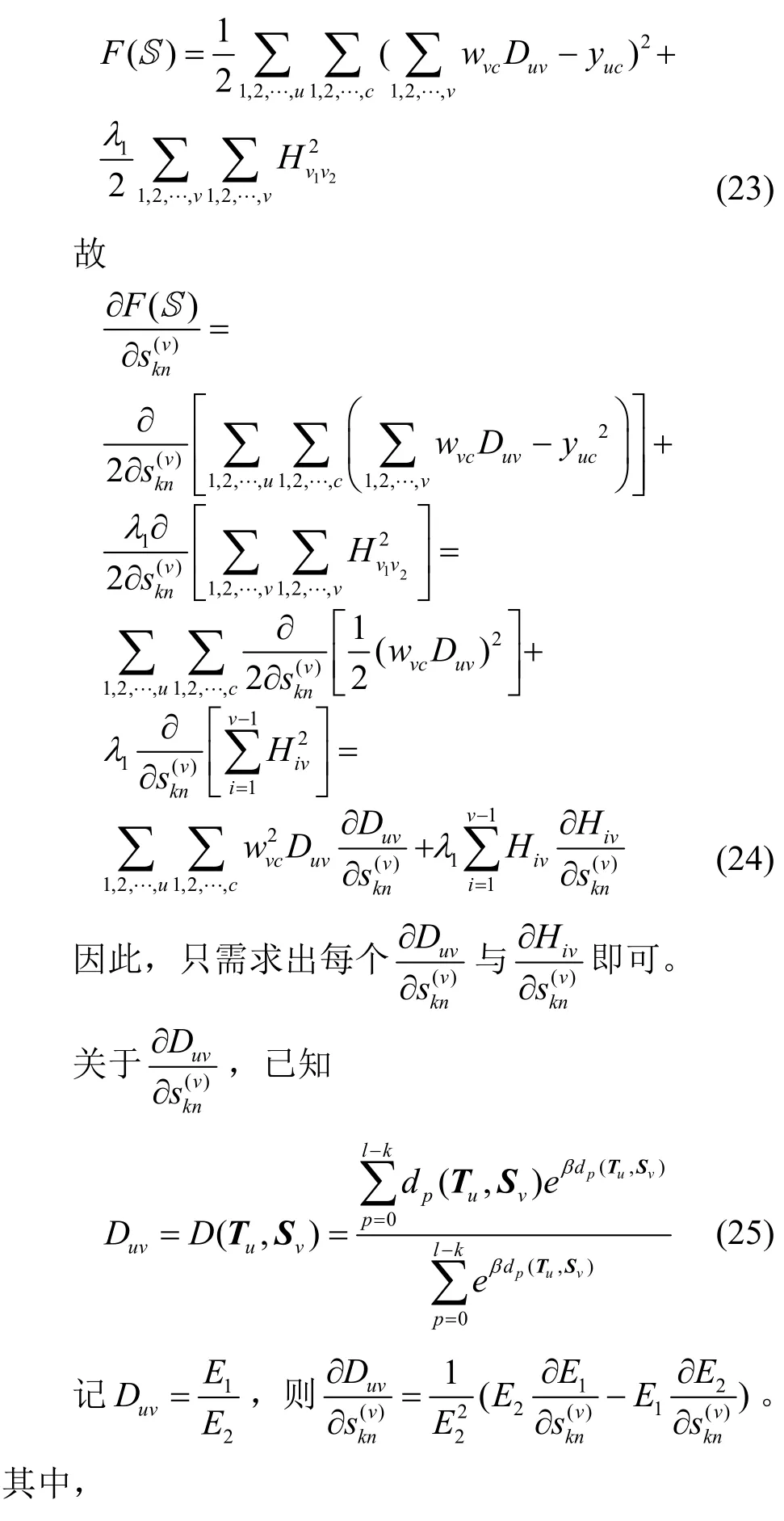
將W、Y、X、H代入F(S),展開得
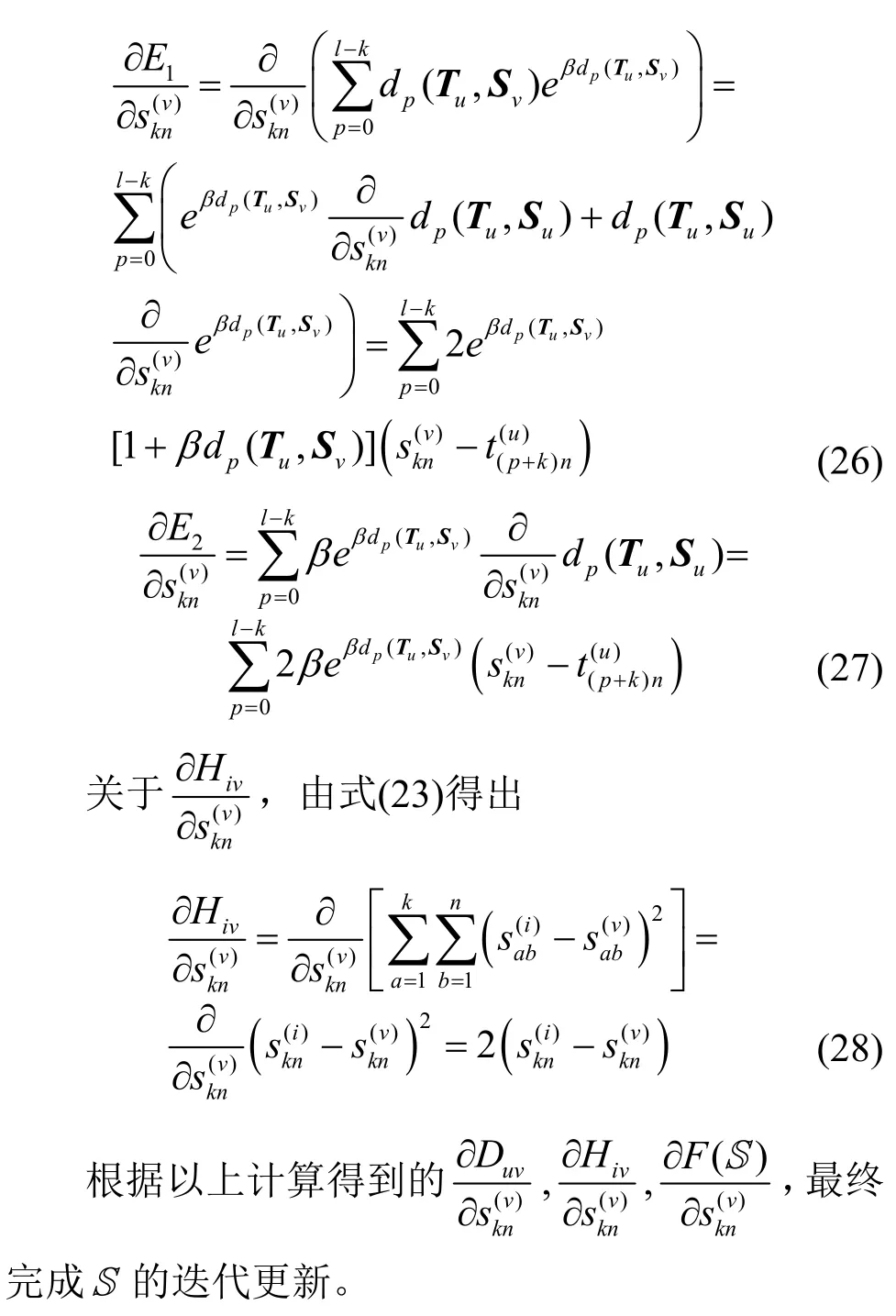
5.3 時間復雜度評估
在無監督學習和推理過程中,經過參數的初始化后,目標函數需要多次迭代直至收斂。每次迭代過程都包括2 個矩陣的計算階段以及3 個參數矩陣的更新階段。根據5.2 節的定義,包序列數據集,一條時間序列T長度為l,每個包有n維特征;S空間Shapelet 子序列長度為k,大小為v;聚類類別為K。那么,在矩陣X,H的計算階段,根據式(13)和式(14)可得計算X的時間復雜度為O(uvkln),計算H的時間復雜度為O(v2kn)。在參數矩陣(Y,W,S)的更新階段,根據式(16)可得更新參數矩陣Y的時間復雜度為O(Kuv),根據式(18)可得更新參數矩陣W的時間復雜度為O(v2u+vuK+v2K+v3),根據式(24)~式(28)可得更新參數矩陣的時間復雜度為O(uvlk2n2K+v2kn)。因此,無監督聚類算法的總體時間復雜度為O(I(uvkln+v2kn+Kuv+v2u+v2K+v3+uvlk2n2K)),I是迭代次數,又因為參數中k?l,v?u,K?u,因此,時間復雜度可表示為O(I(uln2))。
6 實驗分析
6.1 實驗環境及數據說明
由于目前開源數據集中沒有TCP 擁塞控制等攻擊樣本,且在真實網絡數據中也較難捕捉到這類攻擊,因此,實驗搭建了簡單的模擬環境,模擬部分攻擊來采集攻擊數據。實驗環境配置如表1 所示。
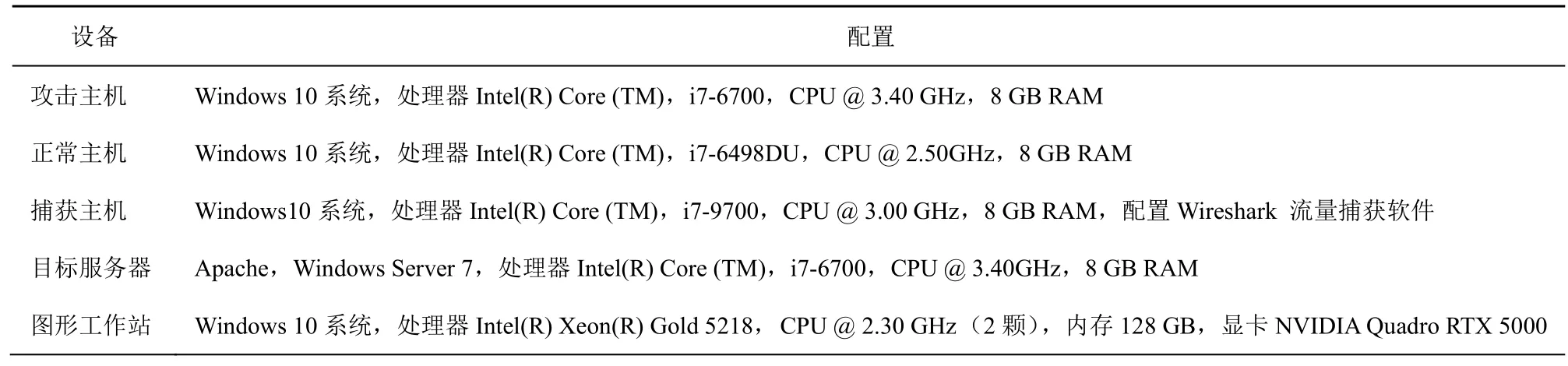
表1 實驗環境配置
為了從不同角度驗證本文方法的合理性,實驗基于模擬場景使用開源數據集,模擬攻擊流量和真實網絡流量構造了多種數據集。攻擊類型覆蓋了利用HTTP 自適應機制的攻擊、新型隱蔽攻擊、逃避攻擊等多種組合。
本文實驗中使用的部分開源數據集來自ISCX-SlowDoS-2016[5]、CIC-DDoS-2019[28]、CIRA-CIC-DoHBrw-2020[29],詳細描述如表2 所示。ISCX-SlowDoS-2016 數據集包含了應用層各種DoS攻擊,包含大量的應用層的小容量隱蔽攻擊。CIC-DDoS-2019 數據集中包含了WebDoS、Port Scan 等多源的DDoS 變種隱蔽攻擊。CIRA-CICDoHBrw-2020 中的惡意流量包含了針對網站的隱蔽攻擊樣本。這3 個數據集均提供了原始的包捕獲文件(.pcap 文件),數據完整。

表2 本文實驗使用的數據集詳情
6.2 特征提取與參數設置
6.2.1 流量特征提取
本文方法在實驗過程中需要提取2 個層面的特征。首先是基于流特征的初步篩選,需要在原始流量中提取一段時間內流量的宏觀特征。其次是基于時間包序列的精確分類,需要將剩余流量還原成按照時間排列的包序列,提取每一個包的具體特征。流特征和包特征描述分別如表3 和表4所示。

表3 流特征描述

表4 包特征描述
為了能夠直觀看出多層次特征使用的意義,本文選取部分具有代表性的數值化特征繪制了對比曲線。本文方法第一階段的正常流量與攻擊流量的部分流特征對比如圖4 所示,從圖4 中可以看出,流特征在正常流量和攻擊流量中有明顯差異,能夠使用聚類算法完成大部分流量的分類。
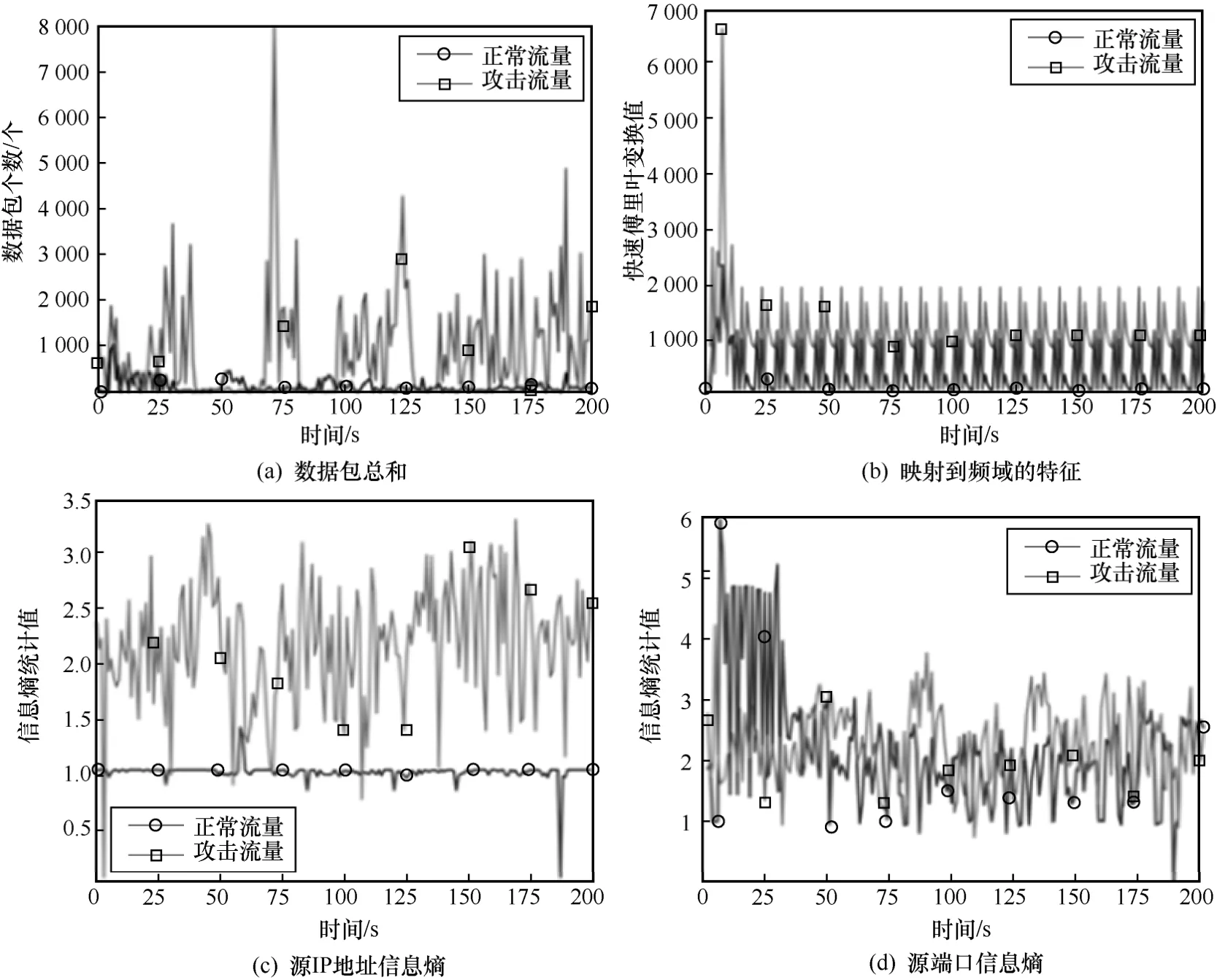
圖4 正常流量與異常流量的部分流特征對比
本文方法第2 個階段的正常流量與攻擊流量的部分包特征對比如圖5 所示。從圖5(a)和圖5(b)中可以看出,正常流量和攻擊流量的獨立的包特征差別較小,很難用可視化的圖分辨。從圖5(c)中可以看出,正常流量和攻擊流量的包的前序包特征有較明顯的差別。因此,在這一階段提取時間序列特征對流量進行分類比較有效。

圖5 正常流量與異常流量的部分包特征對比
6.2.2 參數選擇
本文方法2 個階段的算法需要確定超參。在第一階段中,聚類類別數K與拉普拉斯矩陣的最小特征向量個數e取值一致,均可以根據實驗數據集本身的標簽獲得。監督信息的數量M則通過正樣本的聚類純度P來確定。
監督信息數選擇如表5 所示。從表5 中可以看出,有0.5%的監督信息比無監督信息精確率提高了4.4%。為了使實驗結果有明顯區分度,選擇0.5%為增長間隔。當監督信息占比進一步增加至1%時,精確率提升至99.7%。從表5 后兩行可以看出,隨著監督信息的繼續增加,精確率并沒有明顯提升,當監督信息占比增長至2%時,精確率只比1%時提升了0.1%,回報率低。因此,監督信息占比1%為最佳平衡點,可在盡量少的監督信息下獲得盡量高的精確度。

表5 監督信息數選擇
第二階段中,S空間的大小即Shapelet 子序列的長度k和v-S空間中Shapelet 的個數v為待確定的參數,通過聚類純度P、蘭德系數(RI,Rand index)及F1 值確定。
在TCP-Congestion Dos 數據集中,數據的長度范圍為100~4 000,參考Zhang 等[31]實驗中的參數選擇,本文實驗分別選取最短序列長度的5%、8%、10%、15%、20%進行對比。需要說明的是,經過前期的實驗,當Shapelet 子序列長度k選取5%以下時,信息量過少會影響區分度,因此最短序列長度從5%開始。為了方便實驗,選擇Shapelet的個數為2,不同Shaplet 長度的性能表現如表6所示。從表6 中可以看出,在k從5%增長到20%的過程中,性能呈現先上升后下降的趨勢,可以推斷,在TCP-Congestion Dos 數據集中,最具辨識度的k在5%~20%,也說明在這個區間內存在局部最優解。進一步分析,k在10%~15%時P、RI 和F1 值均較高,因此最優的Shapelet 子序列長度應在10%~15%。為了計算方便,后續實驗選取最短序列長度的10%為k的最優值。
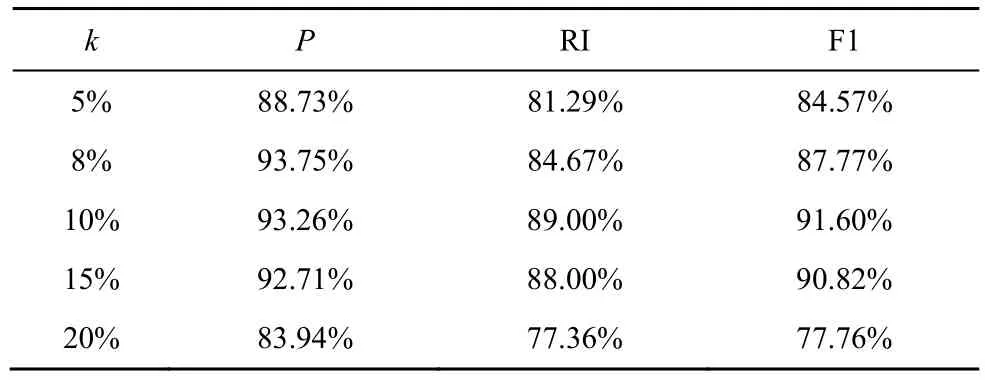
表6 不同Shapelet 長度的性能表現
S空間中Shapelet 的個數v的選擇同樣重要,v過大會影響計算速度,過小又會使區分度不夠明顯。因此,實驗分別選取v為2、3、4、5、6、7、8,在計算效率可接受的情況下選取最優值。
不同Shapelet 個數的性能表現如表7 所示,從表7 中可以看出,隨著v的增加,聚類純度P總體呈上升趨勢,在RI 和F1 值上的表現也相對較好。綜合考慮性能和計算速度,v=3 是本文實驗的局部最優取值。同時需要說明的是,經過實驗發現,當v=8 時,所用時間是v=3 時的2 倍,因此,不再考慮v超過8 的情況。綜上,Shapelet 個數v最佳取值為3。
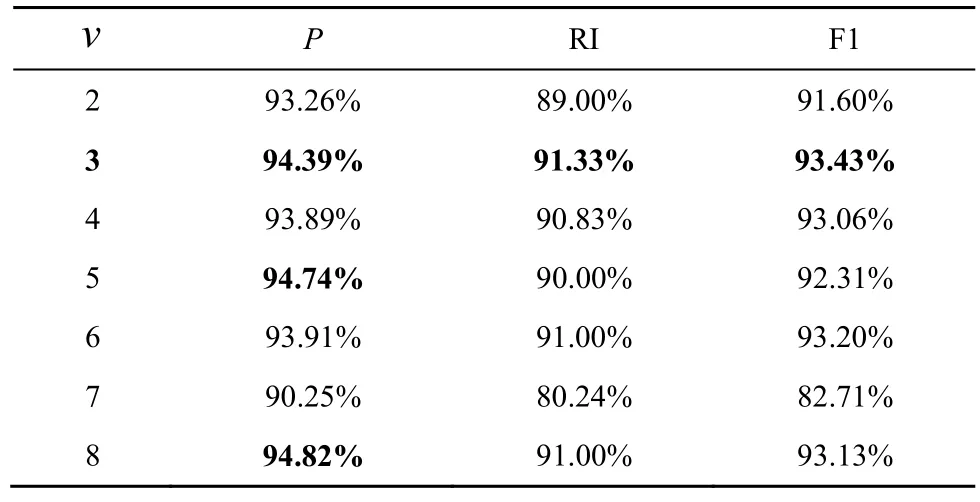
表7 不同Shapelet 個數的性能表現
至此,本文方法的超參分別確定為:監督信息占比為1%,Shapelet 長度為最短序列長度的10%,Shapelet 空間子序列個數為3。
6.3 實驗結果分析
6.3.1 檢測性能評估
為了驗證本文方法的先進性,實驗選取了部分具有代表性的無監督異常/攻擊檢測方法進行對比。這些方法主要分為以下三類:第一類為經典的基于原始流量的經典無監督聚類方法——K-means;第二類為專門針對隱蔽攻擊的檢測方法,包括自動編碼器(Autoencoder)[32]、Whisper[33]模型;第三類為基于Shapelet 的無監督檢測方法,如u-Shapelet[23]等。
由于K-means 和u-Shapelet 沒有針對樣本不平衡的處理,本文中的數據集正負樣本數量差距大,直接使用會影響后續結果的計算,因此這2 種方法使用的是經過本文方法第一階段處理篩除大量正常流量后的數據。具體的對比結果如表8~表10 所示。
首先,從表8~表10 的第一列和第二列中可以看出,K-means 對于RoQ 隱蔽攻擊基本起不到聚類的作用,平均聚類純度在50%左右,相當于隨機歸類。Autoencoder 對于Slowheaders、DoS slowloris等特征較明顯的攻擊檢測效果較好。同樣地,在混合數據1 上的表現也比較好,這是因為混合數據1中含有大量Slowheaders、DoS slowloris 攻擊數據。除此之外,Autoencoder 在其他數據集上表現一般。
其次,從表8~表10 的后三列中可以看出,Whisper、u-Shapelet 和本文方法各具優勢。Whisper最主要的特點是將時域數據轉換成頻域數據,因為攻擊者不能輕易干擾頻域特征,所以即使是手段復雜隱蔽的攻擊在轉換為頻域特征后也具有一定的識別率。從實驗結果上來看,在攻擊比較隱蔽的混合數據2和隱蔽攻擊1數據集中,Whisper的聚類純度最高;在頻域特征最明顯的DoS slowloris 數據集中,Whisper的F1 值最高。這說明該方法有較強的隱蔽攻擊識別能力,并且可以看出頻域特征是該算法所依賴的一個重要特征。
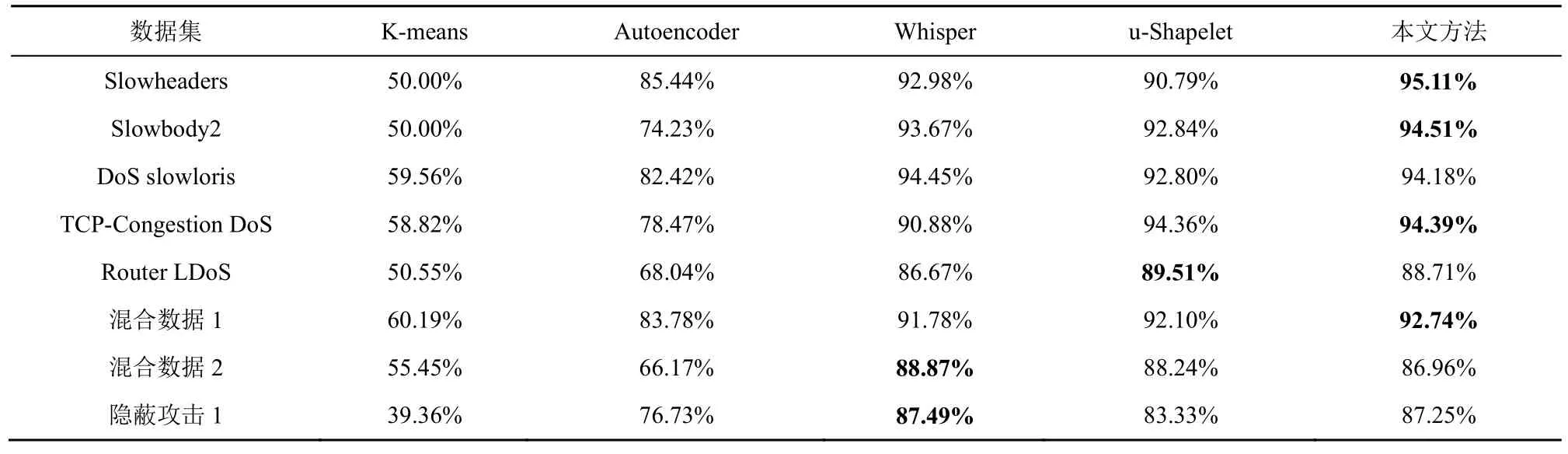
表8 不同方法在不同數據集上聚類純度P 的性能表現
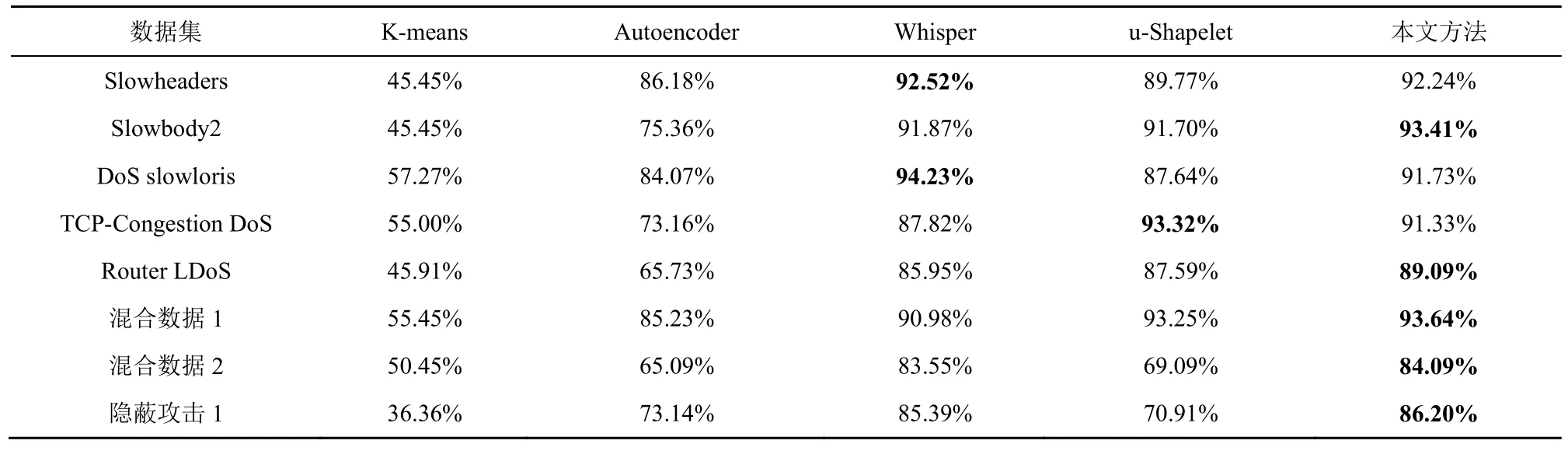
表9 不同方法在不同數據集上蘭德系數RI 的性能表現
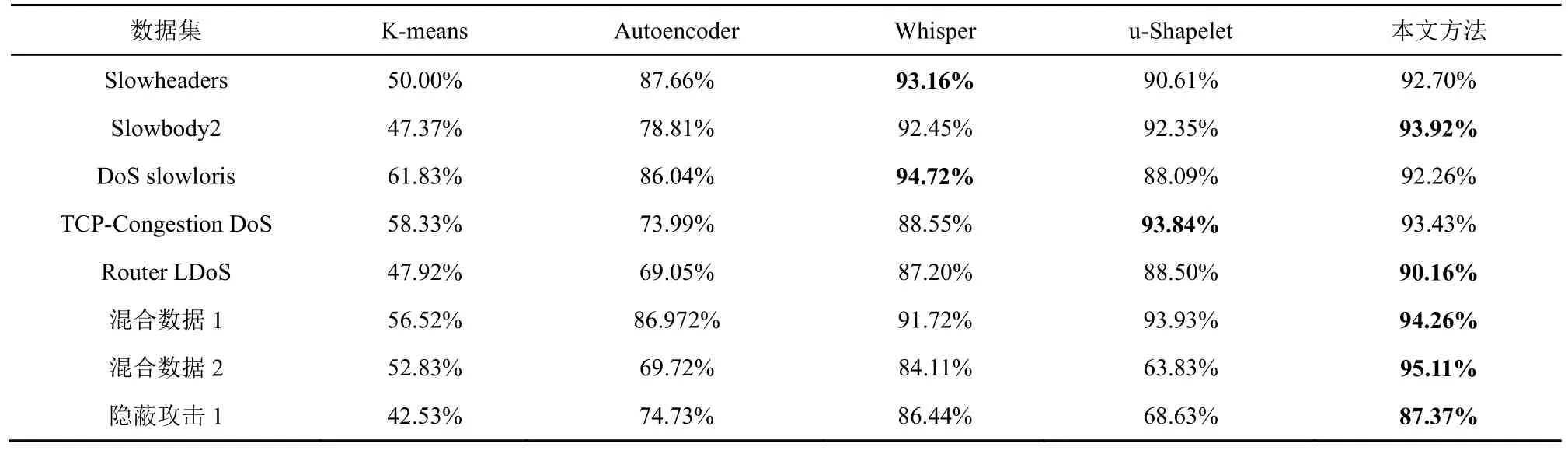
表10 不同方法在不同數據集上F1 值的性能表現
u-Shapelet 只適合一維時間序列,因此在實驗時只選取了包大小隨時間的變化特征。從實驗結果來看,在5 種方法中,u-Shapelet 在Router LDoS數據集中聚類純度最高,在TCP-Congestion DoS中RI 和F1 值最高,在其他數據集上的表現也相對均衡。這表明使用Shapelet 子序列辨識流量中的變化是可行的。
本文方法在4 個數據集上具有最優的聚類純度,在5 個數據集上具有最優的RI 和F1 值。對比Whisper,本文方法在時序特征的分辨上更細致,因此在檢測時序特征明顯的隱蔽攻擊時表現更好。對比u-Shapelet,本文方法使用了流量中更多的有效特征,檢測性能更好。綜上,本文方法在針對RoQ隱蔽攻擊的檢測時最具優勢。
譜聚類算法篩除了大部分正常流量,僅留下比較難以識別的少量流量使進入第二階段。修改后的基于正樣本的半監督譜聚類算法進一步提高了篩選精度。為了驗證本文提出的半監督譜聚類的優勢,實驗分別選取了經典的聚類方法K-means、圍繞中心點的劃分(PAM,partitioning around medoid)及DBSCAN 替換譜聚類進行實驗對比,并依舊保留了原本的半監督機制,分別記為方法A、方法B 和方法C。實驗數據選擇混合數據1,結果如表11 所示。從表11 中可以看出,方法A 方法、B 方法、C 的性能逐漸提升,這是由于PAM 在獲取新的聚類中心時策略較K-means 更佳。基于密度聚類的方法C 的召回率能達到94.17%,說明了RoQ 攻擊流量在全流量中的分布也具有密度稀疏的特點。綜合來看,本文方法總體性能表現優異。

表11 不同聚類方法的性能表現
為了更加形象地表示本文方法的學習過程,實驗在Slowheaders 數據集上將分類過程進行了數值可視化,如圖6 所示。從圖6 可以看出,隨著迭代次數的增多,分類效果越明顯,當迭代次數達到6 次時,已經可以很明顯地區分出正常流量和攻擊流量。
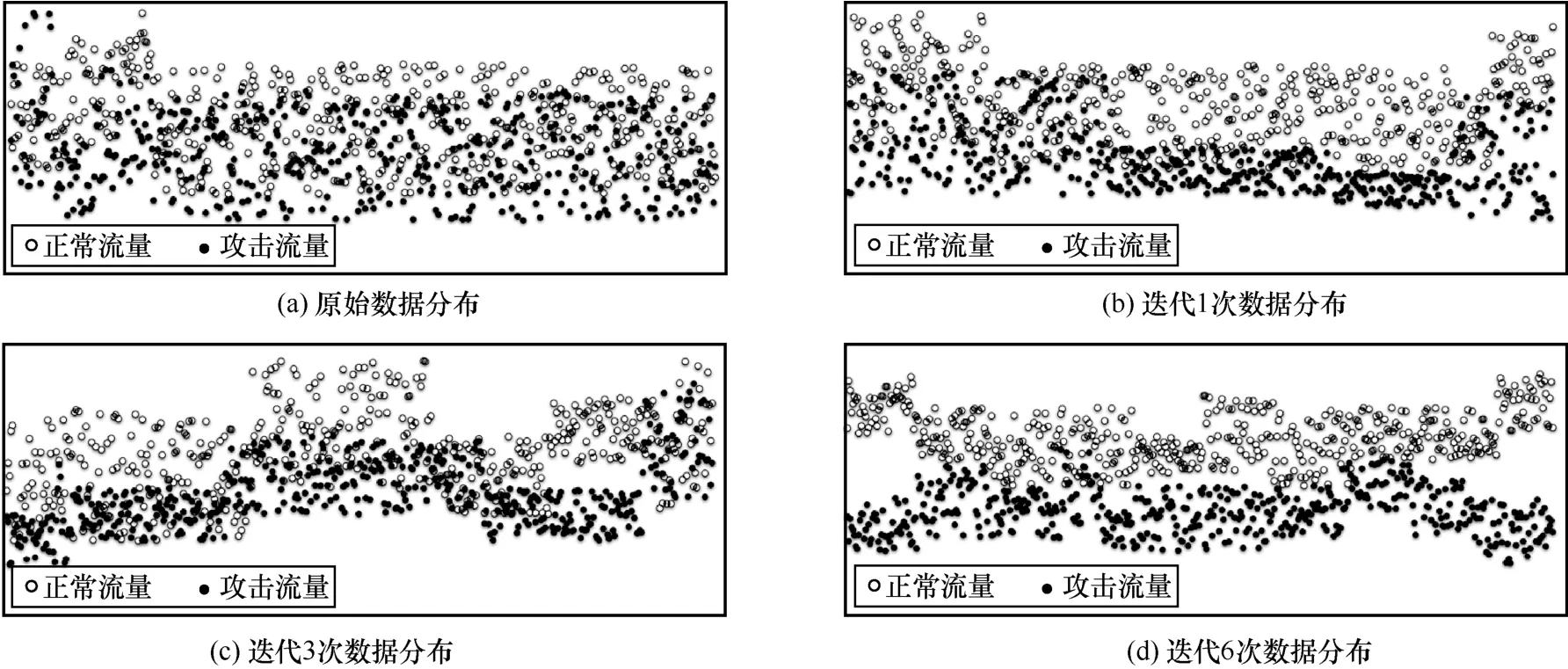
圖6 分類過程可視化
6.3.2 穩健性評估
本節將驗證本文方法的穩健性。實驗假設攻擊者知道惡意流量檢測的存在,可以構造規避攻擊,即通過注入各種良性流量將惡意流量偽裝成正常流量來逃避檢測。
在實驗中,選擇5 種惡意流量模式,并混入不同比例的良性流量,惡性流量和良性流量的比例在1:1 到1:8 之間。表12 顯示了不同方法在不同比例(惡意流量/良性流量)時對5 種攻擊的(AUC,area under curve)值。
從表12 中可知,K-means 的穩健性較差。在TCP-Congestion DoS 攻擊采取不同注入策略時,AUC 值最多降低了0.694,在大部分攻擊使用不同策略偽裝后檢測性能不穩定,部分AUC 值甚至低于0.5。對比K-means,Autoencoder 受規避攻擊的影響較小。在Slowheaders 偽裝攻擊上的AUC 值最多降低了0.229,推測這與自動編碼器本身在特征方面的處理優勢有關。u-Shapelet 從檢測結果來看,當良性和惡意流量為1:1 時,AUC 值較高,能夠達到0.879。當良性和惡意流量比例逐漸增加時,在WebDoS、Slowbody2 和Router LDoS 這3 種規避攻擊檢測中有比較明顯的降低,最多降低了0.311;但對于另外兩類規避類攻擊穩健性較好,可以推測Shapelet 子序列起到了關鍵作用。對比上述3 種方法,本文方法在Router LDoS 規避攻擊中AUC 值最多下降了0.136,在Slowheaders 規避攻擊和WebDoS 規避攻擊中保持了較高且較穩定AUC 值。以上結果說明本文方法穩健性較強,且本文方法的第一階段基于半監督譜聚類的正常流量篩除起到了重要的作用。
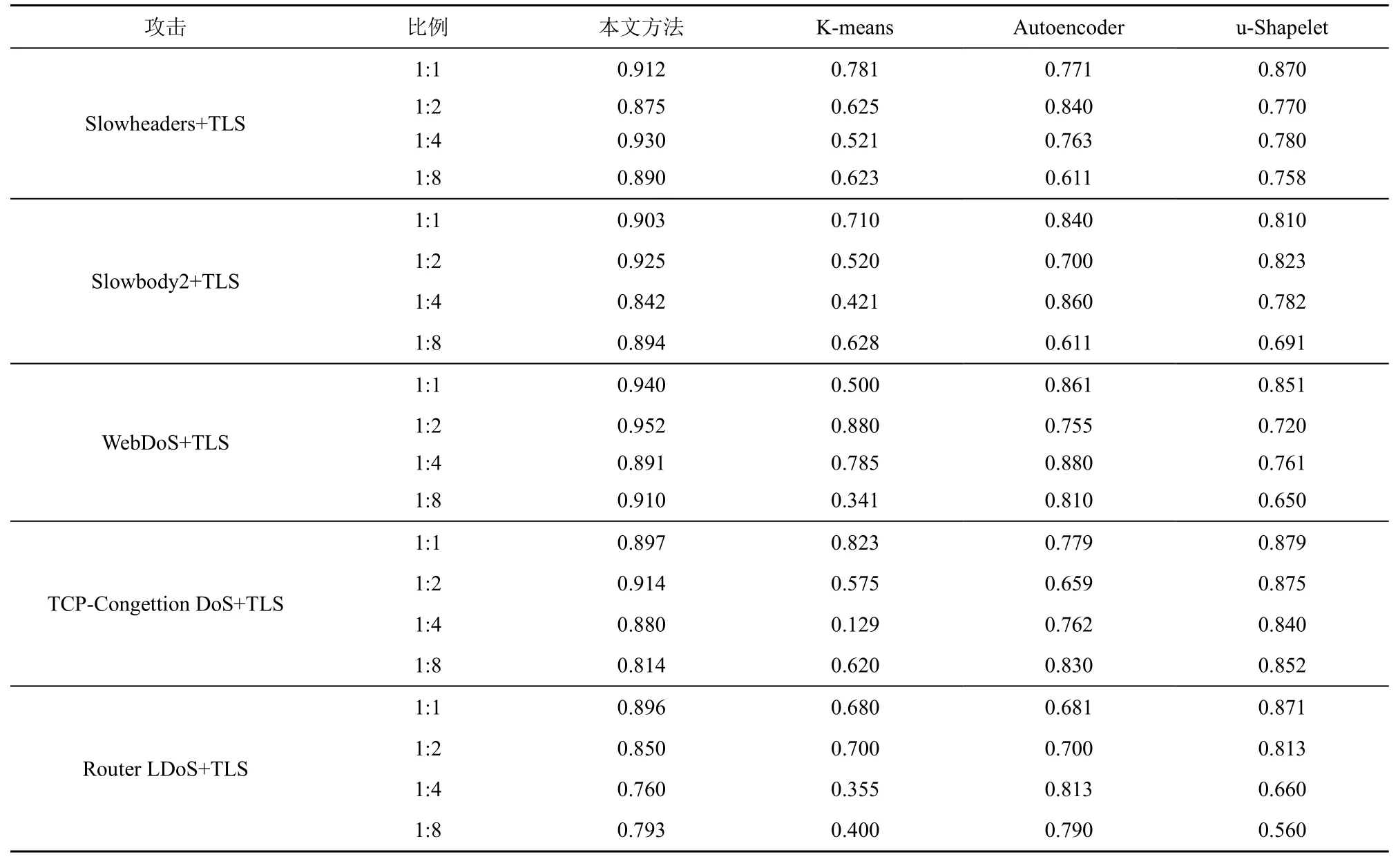
表12 不同方法在不同比例(惡意流量/良性流量)時對5 種攻擊的AUC 值
圖7 為不同方法的AUC 平均值對比,從圖7中可以看到,本文方法的 AUC 平均值最高,K-means 最低。在WebDoS 攻擊檢測中本文方法分類能力最突出。

圖7 不同方法的AUC 平均值對比
7 結束語
本文針對RoQ 攻擊特征不明顯,高質量學習樣本稀少等問題,提出了一種基于多層次特征的無監督隱蔽攻擊檢測方法。首先研究了基于半監督譜聚類算法,利用第一層流特征實現了正常流量高精度篩除,減少了對后續結果的干擾。其次,基于第二層時序包特征構造了基于n-Shapelet子序列的無監督攻擊檢測模型,實現了RoQ 攻擊的高檢測率。實驗結果表明,相較于現有方法,本文方法能夠保持較高的檢測性能,且對規避攻擊具有穩健性。但是,本文方法的無監督學習模型中有3 個超參,這3 個超參的迭代計算增加了整體方法的復雜度。因此,未來將研究無監督學習模型,使其達到更快的收斂速度。
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
人大建設(2020年4期)2020-09-21 03:39:12
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
人大建設(2017年2期)2017-07-21 10:59:25
人大建設(2017年9期)2017-02-03 02:53:31
海峽科技與產業(2016年3期)2016-05-17 04:32:12
