基于多尺度特征注意Yolact網絡的堆疊工件分揀算法
2022-09-29 07:52:00徐勝軍李康平韓九強孟月波劉光輝
計算機測量與控制 2022年9期
關鍵詞:特征
徐勝軍,李康平,韓九強,2,孟月波,劉光輝
(1.西安建筑科技大學 信息與控制工程學院,西安 710055; 2.西安交通大學 電信學部,西安 710061)
0 引言
隨著國家工業的發展,僅依靠傳統人力對工件進行分揀已無法滿足當今工業的生產需求,以工業機器人代替人力完成工件分揀任務逐漸成為研究的熱點。利用工業機器人的自動識別抓取工件是提高自動化生產線效率的關鍵環節之一。在空調驅動電機的生產過程中,需要將大量電機轉軸從容器中分揀出來放置于工業流水線上,由車床、銑床進行精加工。然而由于隨機擺放的大量電機轉軸存在復雜的堆疊遮擋問題,因此這種非結構化場景的堆疊遮擋工件的個體識別難題給基于機器人的自動識別抓取工作帶來了很大挑戰性。
當前,基于視覺機器人的工件識別分揀方法受到了重點關注。這些研究方法主要分為基于傳統視覺方法和基于深度學習方法。基于傳統視覺方法主要包括邊緣檢測方法、特征匹配方法和圖像分割方法。伍錫如等[1]基于Otsu閾值分割、形態學處理、與邊界像素檢測等方法實現了對象棋棋子的識別。高贏等[2-3]通過VisonPro視覺工具中的PatMax特征匹配方法識別發動機瓦蓋,實現了發動機瓦蓋上料機器人系統。宋海濤等[4]采用SIFT特征匹配算法研發了移動機器人物體抓取系統。熊俊濤等[5]利用K-means聚類分割和Hough圓檢測實現了柑橘的識別分割。由于傳統機器視覺算法對外界環境變化較為敏感,且算法各階段所采用的閾值參數均是根據人為經驗設定,因此難以準確提取待識別物體的特征,在實際工件分揀機器人系統中不能準確定位抓取非結構化場景的堆疊遮擋工件的個體。
面向圖像處理的深度學習網絡已被證明在感知問題上具有強泛化能力,因此基于深度學習的機器視覺技術受到了廣泛關注。基于深度學習的目標檢測算法[6,8-10]是機器人自動識別與抓取物件的常用算法。武星等[11]提出了一種基于輕量化YOLOv3網絡的蘋果檢測算法。楊長輝等[12]基于改進YOLOv3網絡設計了一種柑橘采摘機器人系統,可實現柑橘自動采摘,并對多類障礙物進行識別、避障。朱江等[13]基于Faster R-CNN模型實現了曲軸瓦蓋上料機器人系統,提升了發動機裝配生產線的工作效率。王欣等[14]基于快速SSD深度學習算法開發了一種水果識別分揀機器人。杜學丹等[15]利用Faster R-CNN目標檢測網絡得到目標物體的類別與位置,再根據對目標物體分類檢測的結果使用基于深度學習的方法學習抓取位置以達到對物體的自動抓取。薛騰等[16]根據抓取過程中物體抵抗外界擾動的能力,提出一種基于觸覺信息的抓取質量評估方法,應用此方法搭建了機器人抓取系統實現了對10種目標物體的抓取。雖然基于深度學習的目標檢測算法對抓取物體與背景有明顯差異情況下的簡單場景物體識別效果較好,但是由于空調驅動電機的生產過程中大量電機轉軸堆疊在工業流水線上,利用目標檢測算法在使用樣本學習時會學習到過多冗余特征,因此這種算法難以有效識別這種復雜堆疊場景下的電機轉軸。
電機轉軸抓取屬于復雜背景下的堆疊工件抓取問題。實例分割是目標檢測與語義分割任務的結合,可以同時得到圖片中感興趣物體的位置、所屬類別、與掩碼信息。因此像素級的實例分割算法更適用于三維堆疊工件的圖像處理。Li等[17]基于實例感知全卷積網絡中位置感知特征圖的概念提出FCIS實例分割方法。He等[19]基于Faster-RCNN[18]邊界框識別分支的基礎上增加了一個mask預測分支,同時使用ROI Align[19]解決了在候選區域與特征圖像進行映射時由于ROI pooling[18]造成的匹配誤差問題,在檢測目標對象的同時為每個實例生成掩碼。楊攀等[20]使用Mask-RCNN算法對不同尺寸的木材端面圖像進行了分割,實現了復雜背景下不同尺寸木材的檢測、計數功能。趙庶旭[21]基于改進Mask-RCNN算法實現了牙齒的識別與分割。王濤[22]基于平衡金字塔思想對Mask-RCNN的特征提取網絡進行改進,實現了零件回收抓取系統。但由于Mask-RCNN屬于兩階段實例分割算法,需要RPN網絡產生建議區域再將建議區域映射至特征圖像,根據建議區域與其特征預測實例掩碼。建議區域的產生過程與分割操作的不并行會導致模型處理圖像速度較慢,無法滿足工業生產中的實時性要求。
針對非結構化場景中存在的多個物體堆疊遮擋等問題,提出了基于多尺度特征注意Yolact網絡的堆疊工件識別定位算法。首先,針對堆疊工件圖像分割結果邊緣模糊及邊界框定位不準問題,提出了多尺度特征注意Yolact網絡;其次,針對工件位置難以確定問題,利用目標掩碼進行最小外接矩形生成,結合目標邊界框與目標掩碼的最小外接矩形確定了工件的位置信息。最終基于所提算法設計了一種工件分揀機器人系統,并應用于實際空調電機轉軸分揀作業場景,通過實驗證明了該系統的有效性。
1 Yolact網絡基本原理
Yolact[23]一種基于單階段目標檢測網絡的實例分割網絡,該網絡在單階段目標檢測網絡[24-25]上增加了一個掩碼模板生成分支,此分支與目標檢測分支并行,同時在目標檢測分支中增加掩碼系數預測分支,最終利用掩碼系數與掩碼模板產生實例掩碼。由于該網絡無需等待RPN[18]生成建議區域后再進行特征映射產生實例掩碼,因此Yolact的速度遠遠高于雙階段的實例分割網絡,適用于工業場景下的實時檢測任務。
Yolact網絡的基本結構如圖1所示。該網絡主要由骨干網絡(Backbone)、掩碼模板生成分支(Protonet)、預測模塊(Prediction module)、聚合分支(assembly)和剪裁模塊5個部分組成。

圖1 Yolact實例分割網絡
骨干網絡由Resnet101[26]與特征金字塔網絡(FPN)構成,基于FPN得到特征圖像P5、P4、P3,并對特征圖像P5進行卷積操作得到特征圖像P6、P7。隨后將實例分割分為兩個并行的子任務,一個子任務將特征圖像P3輸入Protonet生成一系列掩碼模板(prototype masks),不同的掩碼模板對不同實例的敏感程度不同。另一個子任務在目標檢測分支中增加了掩碼系數預測分支,在預測目標物體邊界框位置與類別的同時,產生掩碼模板中表示實例掩碼的掩碼系數(mask coefficients)。最終,將掩碼系數與掩碼模板進行線性組合得到實例掩碼,再根據預測所得的邊界框對圖像進行剪裁實現實例分割。
2 多尺度特征注意Yolact網絡
由于Yolact網絡采用掩碼模板與掩碼系數線性組合的方式獲得目標物體的分割結果,因此掩碼模板的質量好壞對目標物體的分割結果有很大的影響。由于本文需要對堆疊工件進行單體識別并進行抓取,在這種堆疊工件識別抓取場景中,最頂層無遮擋的工件與疊加工件的形狀、顏色、紋理特征極為相似,故需要深度學習網絡提取高級抽象語義特征并識別出最上方可分揀的工件。然而堆疊工件的分割任務不同于常規物體檢測,這種任務既需要識別網絡能捕獲長距離范圍內像素點之間的語義關系,同時也需要準確提取工件的空間細節特征。由于標準Yolact網絡的Protonet分支利用CNN進行特征提取時僅簡單利用卷積層增大其感受野,忽略了不同尺度特征圖像之間的特征差異與不同特征對于目標分割精度的重要性。與此同時,由于工件的數量與堆疊程度不同,工件在圖像中的尺度大小會發生變化,而Yolact算法的預測模塊使用特征圖像的感受野豐富度較低。因此會造成目標工件邊緣分割結果精度低、工件邊界定位不準確等問題。為解決此問題,提出了多尺度特征注意Yolact實例分割網絡,該網絡由骨干網絡、多尺度特征注意掩碼模板生成分支、膨脹編碼預測模塊、聚合分支與剪裁模塊組成。所提網絡如圖2所示。首先利用由Resnet101與特征金字塔網絡構成的骨干網絡對工件圖像的特征進行提取。隨后將提取到的特征圖像P3輸入多尺度特征注意掩碼模板生成分支獲取掩碼模板。多尺度特征注意掩碼模板生成分支在標準Yolact網絡的Protonet分支中嵌入多尺度融合與注意力機制,可以在聚合多尺度工件圖像特征的同時,引導網絡學習與目標工件相關特征生成一系列高質量的掩碼模板。同時將由骨干網絡獲得的特征圖像P3至P7輸送至膨脹編碼預測模塊預測工件圖像中實例的類別、邊界框位置、掩碼系數。膨脹編碼預測模塊在標準Yolact網絡的預測模塊中引入膨脹編碼機制增強網絡對于不同尺度大小目標的適應能力。聚合分支將實例的掩碼系數與掩碼模板進行線性組合得到實例掩碼。剪裁模塊根據膨脹編碼預測模塊預測的邊界框對圖像進行剪裁完成實例分割。

圖2 多尺度特征注意Yolact實例分割網絡
2.1 多尺度特征注意掩碼模板生成分支

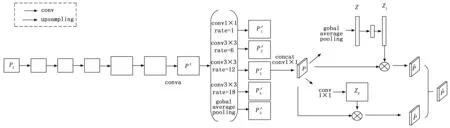
圖3 多尺度特征注意掩碼模板生成分支
為了增強所提網絡對感興趣區域細節特征的學習能力,基于注意力機制構成空間金字塔注意力模塊即在其后加入通道注意力分支、空間注意力分支兩個并行的網絡分支。通道注意力分支由全局池化層與兩組卷積核尺寸大小為1×1的卷積層構成。該分支的輸入為特征圖像P={p1,p2,…,pc},其中pi∈RH*W表示第i個通道,H,W分別表示特征圖像的高和寬。該分支使用全局平均池化對特征圖像P進行壓縮操作,即將每個特征通道都壓縮成一個實數,從而將感受野擴展到全局范圍。特征圖像P經過全局平均池化后得到一個向量Z,且Z∈R1*1*C,則每個位置的值zc為:
(1)
式中,c為特征圖像的通道數,H,W分別為特征圖像P的高和寬。
將每個特征通道pi壓縮后得到的向量Z使用一個卷積層降維,然后通過整流線性單元ReLU激活,再經過一個卷積層升維,最后利用sigmoid激活函數生成長度為32的特征注意權重向量Z1,整個過程表示如下:
Z1=δ[w2(σ(w1Z))]
(2)
式中,w1,w2分別為兩個卷積層的權重,σ(·)表示整流線性單元ReLU,δ(·)表示sigmoid激活函數。

(3)
式中,z1i為第i個通道的權重,衡量了第i個特征通道pi的特征重要程度。
空間注意力分支由尺寸大小為1×1、卷積核數量為1的卷積層構成。此分支的輸入圖像為P={p1,1,p1,2,……,pi,j,……,pH,W},H,W為特征圖像的尺寸,i,j為特征圖像的空間位置。首先使用卷積層w3∈R1*1*c*1對特征圖像P進行空間壓縮操作,得到一個特征注意權重張量Zs:
Zs=w3(P)
(4)
式中,特征張量Zs中的權重表示圖像上不同位置對于圖像分割任務的貢獻度。
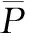
(5)
式中,δ(·) 為sigmoid激活函數,δ(Zs(i,j))代表特征圖P中位置(i,j)處的特征重要度。
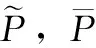
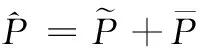
(6)
2.2 膨脹編碼
Yolact網絡把FPN網絡輸出的5層特征圖像P3~P7輸入預測網絡實現邊界框的預測,利用邊界框對集成掩碼進行剪裁并生成實例掩碼。如果邊界框定位準確,那么網絡會生成高質量的實例掩碼;反之生成的實例掩碼包含大量“噪聲”,對分割結果帶來很大干擾。由于特征圖像感受野的豐富程度對邊界框的定位精度至關重要,為使檢測網絡對不同尺度的物體均實現準確檢測,本文選擇感受野較大的特征圖像檢測大尺度目標,感受野較小的特征圖像檢測小尺度目標。所提網絡在預測模塊的Convb卷積層后加入膨脹編碼模塊,膨脹編碼模塊首先使用1×1的卷積將特征圖像的通道數縮小為原來的四分之一,之后使用3×3的卷積對特征圖像的上下文語義信息進行整合,并連續疊加4個相同結構的殘差塊,殘差塊的結構如圖4所示。

圖4 膨脹編碼模塊
每個殘差塊均由3個卷積層構成,卷積核的尺寸大小分別為1×1、3×3、1×1,其中3×3的卷積層使用了空洞卷積,4個殘差塊中尺寸大小為3×3的卷積層的空洞率分別設置為2、4、6、8。通過4個殘差塊的疊加將不同感受野大小的特征圖像以逐像素點相加的方式進行融合,得到上下文信息足夠去檢測不同尺度目標的特征圖像Q。由于特征圖像Q中蘊含的上下文信息較原始網絡Q′更加豐富,涵蓋了在實際分揀作業場景中可能遇到的各種不同大小尺度工件的特征。因此基于此特征圖像進行目標邊界框回歸,可以提升網絡對于不同尺度目標的適應調節能力進而提高邊界框的預測精度。
2.3 損失函數
本文所使用的損失函數由類別損失、邊界框位置損失與掩碼預測損失三部分組成。總損失函數L=?1Lclass+?2Lbbox+?3Lmask如下式所示:
L=?1Lclass+?2Lbbox+?3Lmask
(7)
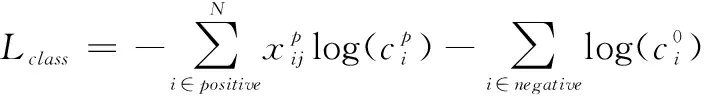
(8)

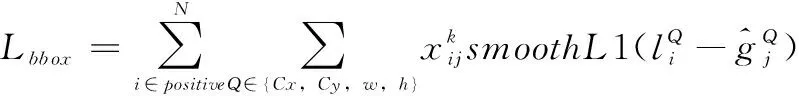
(9)
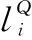
(10)
(11)
(12)
(13)
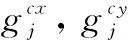

(14)

Lmask掩碼預測損失定義為:
(15)
式中i表示圖片中的像素點序號,N為像素點總數。xi代表第i個像素點所屬類別的預測值,yi代表第i個像素點所屬類別的真實值。
3 基于視覺引導的堆疊工件分揀機器人
堆疊工件分揀機器人以廣州數控RB06-900六軸工業機器人為主體,在其機械臂上安裝了英特爾D435i深度相機與SRT公司生產的SFG-FMA4-M5072柔性夾爪末端執行機構。由深度相機獲取容器內雜亂堆放的工件圖像,控制器對獲取的容器內堆疊工件圖像進行分析處理,根據工件識別定位結果引導工業機器人進行工件夾取、搬運等分揀操作。研發的堆疊工件分揀機器人作業系統如圖5所示。

圖5 堆疊工件分揀機器人系統
基于構建的多尺度特征注意Yolact網絡可實現對堆疊工件中可分揀工件的識別,但要實現對工件的抓取,需要計算工件抓取點在世界坐標系下的坐標與旋轉角度,進而確定機器人的抓取位姿。令機器人的抓取位姿G={xw,yw,zw,a,b,c},其中xw,yw,zw為工件抓取點在世界坐標系下的坐標值,a,b,c為機器人末端柔性夾爪中心點繞世界坐標系的x,y,z軸的旋轉角度。坐標轉換示意圖如圖6所示,圖中u-o1-v為像素坐標系,x-o2-y為物理坐標系,xc-o3-yc-zc為相機坐標系,xw-o4-yw-zw為世界坐標系。

圖6 坐標轉換示意圖
獲取工件抓取點像素坐標與旋轉角度方法的具體步驟如下。
步驟1:令機器人的抓取位姿G={xw,yw,zw,a,b,c},其中xw,yw,zw為工件抓取點在世界坐標系下的坐標值,a,b,c為機器人末端柔性夾爪中心點繞世界坐標系的x,y,z軸的旋轉角度。工件抓取點坐標xw,yw,zw定義如下:
(16)
式中,R、T為世界坐標系相對于相機坐標系的旋轉、平移矩陣。u0、v0為圖像中心點的像素坐標,cx、cy為工件抓取點在像素坐標系下的像素坐標,f為相機焦距,d為由深度相機獲取的工件抓取點與攝像頭光心之間的距離,dx,dy為圖像中u,v方向上一個像素點對應的真實距離。
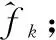
(17)
式中,fk表示預測出的第k個目標工件,Ω為采集到的工件圖像;K表示網絡預測出的目標總數,F表示實例分割網絡的推理過程,conf(fk)表示第k個待抓取工件的置信度。

(18)
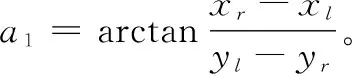
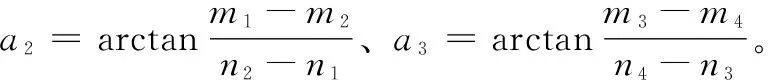
步驟8:若a2與a1的符號相同,則取a2為工件的旋轉角度。若a3與a1的符號相同,則取a3為工件的旋轉角度。即機器人抓取工件旋轉角度φ定義為:

(19)
步驟9:根據步驟5得到的抓取點像素坐標{cx,cy}和步驟8得到的機器人抓取工件旋轉角度φ,輸出機器人抓取位姿參數G={xw,yw,zw,a,b+φ,c},機器人執行抓取工件操作。
4 實驗分析
4.1 模型訓練平臺與工件數據集
深度學習平臺的配置為Ubuntu18.04系統,兩塊顯存為11G的GeForce_RTX_2080_TiGPU,python版本為3.6.5,pytorch版本為1.2.0,Cuda版本為10.1。
訓練參數配置中批大小Batchsize設置為8,學習率設置為0.002,訓練回合數為2 000,采用隨機梯度下降法(SGD)對網絡各層權重進行優化。
工件數據集使用自建的堆疊空調電機轉軸數據集,利用深度相機對圖像進行采集,設計了隨機擺放的不同堆疊程度、不同數量的工件場景,涵蓋了在實際工業分揀場景中工件可能出現的所有場景。數據集共采集800張圖片,部分示例圖像場景如圖7所示。為了提高網絡泛化能力,本文采用隨機鏡像、隨機翻轉、隨機旋轉、光度扭曲等數據增強方法對實驗數據集進行增強,增強后的數據集共3 00張圖片,其中復雜堆疊場景下的圖片1 148張,輕微堆疊場景下的圖片1 184張,無堆疊場景下的圖片868張。將全部標注圖片轉化為coco數據集格式,并按照8∶2的比例劃分為訓練集與驗證集。利用labelme軟件對工件數據集進行標注,標注信息可提供深度學習網絡訓練所需要的工件掩碼特征。

圖7 數據集部分圖像
4.2 評價指標
本實驗采用實例分割模型通用評價指標MAP(平均精度均值)來評判算法模型的好壞,MAP的計算方法如下:
首先根據樣本的真實值與預測值將樣本劃分為4種類型:
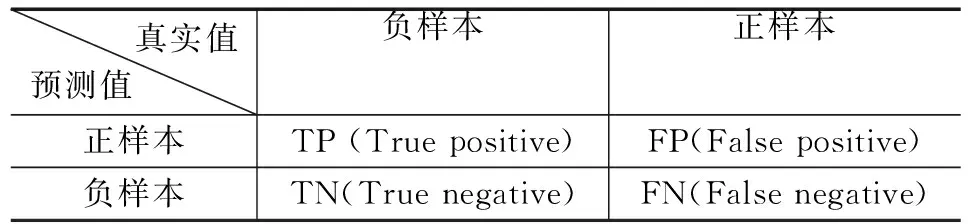
表1 樣本類型劃分
然后計算精確度(Precision)與召回率(Recall),P指精確度(Precision)計算方式如式所示:
(20)
R指召回率(Recall)計算方式如式所示:
(21)
以P為縱軸,R為橫軸繪制P-R曲線,該曲線與坐標軸圍成的面積即為單類別的AP。MAP即為所有類別AP的平均值。
4.3 實驗結果對比分析
為了驗證本文提出的多尺度特征注意Yolact網絡的有效性,分別與Yolact、改進掩碼模板生成分支的Yolact、引入膨脹編碼的Yolact、Mask-RCNN (Resnet50)[19]、Mask-RCNN(Resnet101)[19]、改進Mask-RCNN[21]、FCIS[17]共7個網絡進行對比實驗。
定性分析。為驗證所提出網絡對工件掩碼的提取效果,堆疊工件掩碼提取效果對比結果如圖8所示。圖8(a)為標準Yolact網絡對堆疊工件掩碼提取結果,圖8(b)為本文提出的多尺度特征注意Yolact網絡對堆疊工件掩碼提取結果。由圖8第一行工件圖像掩碼提取結果可看出標準Yolact網絡在對工件圖片掩碼進行預測時存在掩碼不完整的情況。而本文構建的多尺度特征注意Yolact網絡可以完整的將掩碼預測出來。由圖8第二行工件圖像掩碼提取結果可以看出由標準Yolact網絡得到的工件掩碼的邊緣比較模糊,而由本文提出網絡得到的工件掩碼的邊緣細節效果較好,掩碼更加貼近工件邊緣。由圖8第三行工件圖像掩碼提取結果可以看出,由標準Yolact網絡提取的工件掩碼存在誤判情況,而由本文提出網絡提取的工件掩碼較為準確,可以更好地區分出上下方工件。

圖8 堆疊工件識別結果對比圖
為驗證所提算法在實際分揀作業中采集的不同場景下堆疊工件圖像進行識別的效果,分別與Yolact、Mask-RCNN(Resnet50)、Mask-RCNN (Resnet101)、改進Mask-RCNN等4個網絡進行實驗對比,對比結果如圖9所示。圖中,第一列為不同對比場景中相機采集的實際工件場景圖,從左向右分別為Mask-RCNN(Resnet50)、Mask-RCNN (Resnet101)、改進Mask-RCNN、Yolact等算法識別結果圖。圖9(a)為無堆疊場景下識別對比結果,圖9(b)為輕微堆疊場景下識別對比結果,圖9(c)為復雜堆疊場景下識別對比結果。由圖9(a)識別結果可以看出,雖然所有對比算法均識別出了簡單無堆疊場景下的工件圖像,但是Mask-RCNN (Resnet50)、Mask-RCNN(Resnet101)、改進Mask- RCNN等對比算法識別結果不完整,均出現了識別結果部分缺失的問題,Yolact算法雖然較完整的識別出了工件圖像,但是存在識別結果邊界不能完全貼合實際工件的圖像,由此導致機器人在抓取過程中出現定位不準確問題。由圖9(b)識別結果可以看出,在輕微堆疊場景下,Mask-RCNN(Resnet50)、Mask-RCNN(Resnet101)、改進Mask-RCNN等對比算法識別結果仍然存在識別結果不完整情況,并出現了漏檢問題;而Yolact算法和本文所提算法均完整識別出了所有可分揀工件圖像,但是本文所提算法識別結果邊緣更貼合實際工件圖像。由圖9(c)識別結果可以看出,對于復雜堆疊場景下工件圖像,Mask-RCNN(Resnet50)、Mask-RCNN(Resnet101)、改進Mask-RCNN等的識別結果出現了較多的漏檢問題,甚至Mask-RCNN(Resnet101)、改進Mask- RCNN的識別結果出現了誤檢問題,導致下方疊壓工件被錯誤識別;Yolact算法在復雜堆疊場景下也出現了誤識別問題,導致不易抓取工件的誤識別。本文所提算法均完整識別出了所有可分揀工件圖像,并且識別結果邊緣更貼合實際工件圖像。因此,由大量實驗結果可以看出,在非結構化場景下,本文提出算法較對比算法對工件圖像中可分揀工件的識別更為準確,并且在掩碼預測的完整度與邊緣細節效果上均強于對比算法,不會出現對比算法造成的掩碼缺失與邊界不貼合工件等問題。
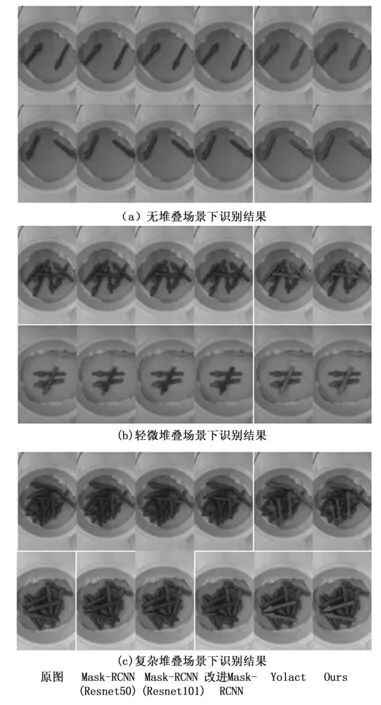
圖9 對比網絡識別結果對比圖
定量分析。為進一步定量分析所提算法性能,分別與Yolact、改進掩碼模板生成分支的Yolact、引入膨脹編碼的Yolact、Mask-RCNN(Resnet50)、Mask-RCNN(Resnet101)、改進Mask-RCNN、FCIS等7個網絡進行實驗對比,對比結果如表2所示。由表2可知,改進掩碼模板生成分支的Yolact網絡與標準的Yolact網絡相比其Mask_MAP提升了1.22個百分點,證明本文提出的多尺度融合與特征注意機制可以提高網絡對目標物體的分割精度。引入膨脹編碼的Yolact網絡對比標準的Yolact網絡其B_box_MAP提升了1.74個百分點,Mask_MAP提升了1.5個百分點,證明以感受野更加豐富的特征圖像進行預測會提高網絡完成目標檢測和語義分割兩大任務的效果。多尺度特征注意Yolact網絡在B_box_MAP與Mask_MAP上均達到最大值,證明本文提出的網絡相對于標準的Yolact網絡在邊界框回歸與掩碼預測兩個方面均有所提升,可以更好地引導視覺機器人系統進行工件分揀任務。
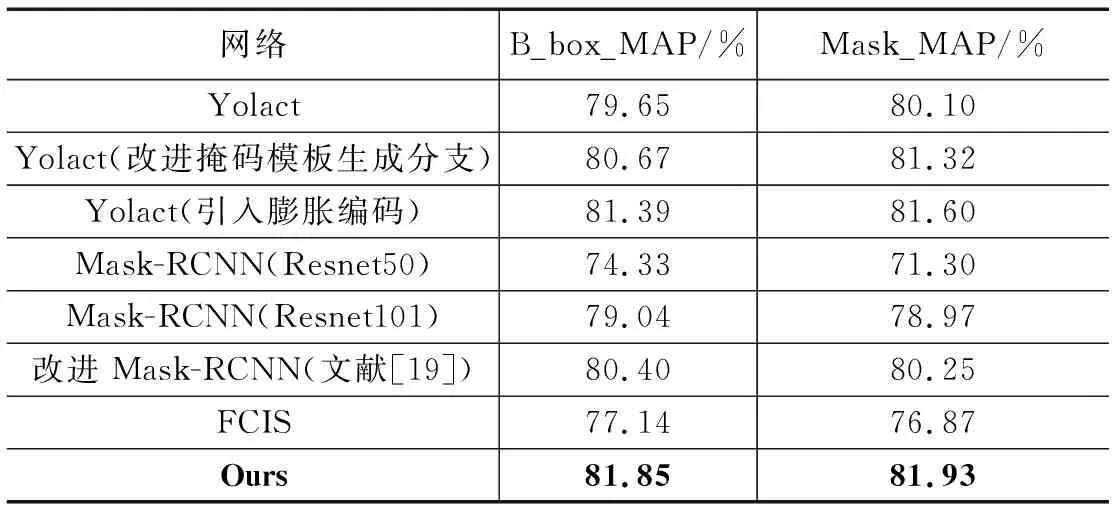
表2 平均精度均值對比
模型大小與處理單張圖片所用時間對比如表3所示。由表3可以得知本文提出的多尺度特征注意Yolact算法模型較標準Yolact算法模型在模型大小上增加了2.1 M,處理單張圖片所需時間增加了0.14 s。此時長在滿足實際工件分揀作業需求的可接受范圍之內。本文所提出的算法網絡在與標準Yolact算法處理單張圖片所用時間相差無幾的情況下有效提升了工件識別的準確率。
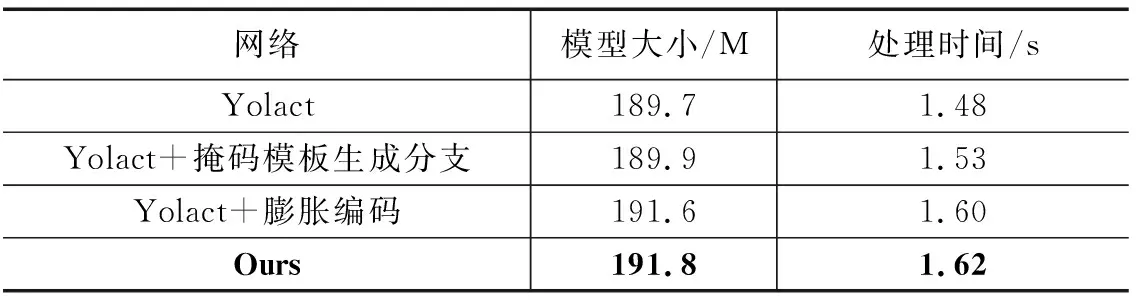
表3 實時性對比
為進一步驗證所提網絡的有效性,將所提網絡部署在工業機器人系統中,并研發了一種堆疊工件分揀機器人。按照空調電機轉軸實際生成場景構建測試環境,每次將15個空調電機轉軸隨機擺放在待抓取區域,由機器人連續抓取直至將所有空調電機轉軸全部取出,并利用工件分揀機器人的作業情況分別進行了900次抓取對比測試實驗。對比實驗分別采用基于所提網絡、標準Yolact算法的視覺工件分揀機器人作業情況進行對比,機器人根據對比算法得到的工件位置信息對工件進行抓取并放置于目標位置。本文以空調電機轉軸分揀成功率作為性能評價指標,定義如下:

(22)
設計的實驗分為A組與B組兩組,在A組實驗中使用標準的Yolact算法對工件進行識別,B組實驗使用所提的多尺度特征注意Yolact算法進行工件識別。兩組實驗中工件的位置信息與機器人的抓取位姿均由對應算法獲得。實驗對比結果如表4所示,基于本文所提網絡的視覺機器人工件分揀系統完成堆疊工件分揀作業的成功率為97.5%。與標準Yolact算法的視覺機器人工件分揀系統95.8%的成功率相比提高了1.7%。識別并輸出每個電機轉軸的機器人抓取位姿并由機器人進行抓取及放置的平均時間為4.62 s。因此基于所提算法的視覺機器人工件分揀系統滿足實際應用場景需求,能有效提高空調電機轉軸自動化生產的智能化水平。
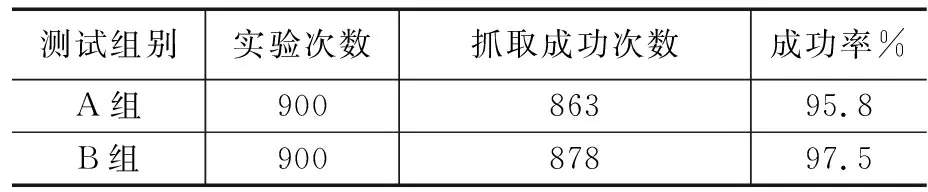
表4 空調電機轉軸抓取成功率對比
5 結束語
針對非結構化場景中存在的多工件堆疊遮擋等問題,提出了基于多尺度特征注意Yolact網絡的堆疊工件圖像分割網絡。所提網絡基于多尺度特征融合器與注意力機制,有效提高了網絡對于堆疊工件圖像特征的學習能力;基于膨脹編碼增強算法對于不同尺度大小目標的適應能力,提升了網絡對堆疊工件定位回歸的精度,最終研發了一種機器人工件分揀系統,并將該系統應用于實際空調電機轉軸分揀任務中,實驗結果證明了機器人工件分揀系統具有良好的性能。
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學生數理化(高中版.高考數學)(2022年3期)2022-04-26 14:04:16
數學年刊A輯(中文版)(2020年1期)2020-05-19 00:30:36
空間科學學報(2020年2期)2020-04-01 03:50:40
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
中等數學(2019年8期)2019-11-25 01:38:14
當代陜西(2019年10期)2019-06-03 10:12:04
新聞傳播(2018年11期)2018-08-29 08:15:24
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
廣西科技大學學報(2016年1期)2016-06-22 13:10:38
