基于機器學習的電力網絡安全檢測技術研究
2022-09-26 02:37:52邵志鵬李偉偉
自動化與儀表 2022年9期
邵志鵬,李偉偉,周 誠
(國網智能電網研究院有限公司,南京 210003)
隨著電力網絡建設工作不斷深化,攻擊手段復雜多樣和靜態安全防護措施部署與策略配置之間形成尖銳的矛盾。 網絡威脅來自多方面,并且會隨著時間的變化而變化,其中網絡攻擊檢測技術是網絡安全技術中非常重要的一部分[1-3]。
前人對網絡攻擊檢測技術進行了深入的研究,構建了多種檢測工具[4-6]。 然而,在一些敏感和特殊的網絡中,網絡數據通常被加密或保護,傳統的網絡攻擊檢測方法并不理想。 基于網絡流量統計特征的網絡攻擊檢測方法不需要分析數據內容和連接特征,可以更好地實現敏感和特殊網絡中的攻擊檢測[7-8]。
近年來,研究人員對人工智能技術進行了深入研究,并在各領域取得了很好的效果[9-11]。 一些研究者也將其應用到網絡攻擊檢測領域,實現了對網絡攻擊指令的高效檢測。 然而,目前對于已知的網絡攻擊指令的檢測技術較多,而對于未知攻擊指令的檢測技術較少,檢測工具也缺乏。 這些問題影響了網絡攻擊檢測的準確性和可靠性。
為了解決上述問題,提出了一種基于機器學習的電力網絡安全檢測技術。 采用監督學習與非監督學習相結合的方法,實現對網絡攻擊指令的全面安全檢測,采用隨機森林算法對網絡特征進行選擇和優化,提高網絡攻擊指令檢測的準確性和效率。
1 系統方案
通常攻擊者、惡意軟件、計算機病毒會通過外部網絡指令實施攻擊,而內部網絡也存在潛在的攻擊指令或者錯誤操作。 為了實現網絡攻擊指令檢測,本文設計了基于指令流量統計分析的網絡攻擊檢測防護系統,系統框架如圖1 所示。
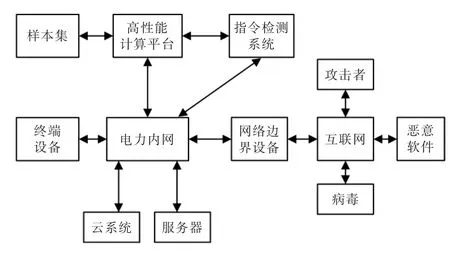
圖1 系統框架圖Fig.1 System frame diagram
首先,本系統收集并整理已披露的網絡指令流量數據,融入網絡威脅數據庫、網絡漏洞數據庫(如NVD、CNVD)中的相關特征數據,并補充通過網絡數據采集與分析模塊采集到的數據包,構建網絡指令流量樣本集。 運行于高性能計算平臺中的檢測模型構建模塊,提取樣本數據中的相關數據,分別通過SVC 算法、超球體SVM 算法和無監督聚類算法學習構建異常流量檢測模型、已知攻擊檢測模型和未知攻擊檢測模型。 攻擊檢測模塊和數據采集與分析模塊綜合運行于指令檢測系統、網絡邊界、云平臺、應用服務器、終端等網絡設備中,提取高性能計算平臺中檢測模型構建模塊的構建的預測模型,實現網絡攻擊檢測。
2 攻擊指令檢測算法設計
為了實現基于對網絡攻擊指令的有效檢測,本文設計并實現了一個基于流量統計分析的網絡攻擊指令檢測方法。 該方法主要采用基于SharpPcap的數據采集技術、基于SVC 的異常流量檢測技術、基于超球體SVM 的已知攻擊檢測技術、基于無監督聚類的未知攻擊檢測技術和基于隨機森林的特征選擇與優化技術5 種技術的綜合運用。 下文對算法流程進行詳細分析。
2.1 基于SharpPcap 的網絡網絡采集
基于SharpPcap 構建數據采集與分析技術將網卡設置成為混雜模式,在此工作模式下,網卡不對目的地址進行判斷,對收到的每個數據幀產生硬件的中斷提醒操作系統進行處理。 隨后通過軟件編程實現相應的捕獲以及分析,掌握數據報文每字段的含義。 基于SharpPcap 的數據采集工作在網絡環境的最底層,攔截網絡上傳送的所有數據,并且通過相應的動態鏈接庫進行處理, 實時的分析數據內容,統計所處網絡的狀態以及網絡數據流量。 采集流程如圖2 所示。
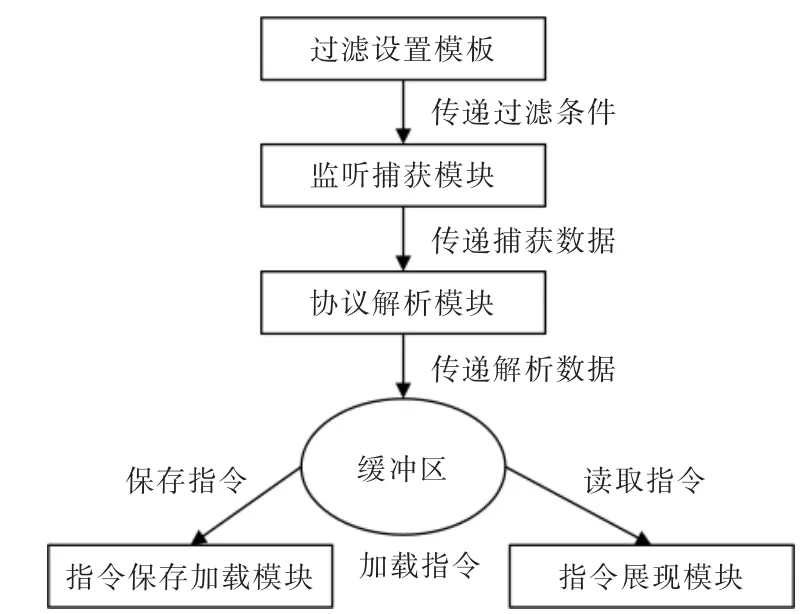
圖2 基于SharpPcap 指令采集流程Fig.2 Instruction acquisition process based on SharpPcap
捕獲數據包之前需要設置過濾條件,并由過濾設置模塊將其傳遞到捕獲模塊。 基于SharpPcap 流量采集技術讀取過濾的字符串,根據過濾的字符串判斷過濾的條件所屬的類型。
數據包分析使用的是SharpPcap 中數據包的處理方法。首先對數據包中的數據進行簡略信息的解析,再將數據包按網絡協議層次進行解析。對于鏈路層數據從比特流轉換成數據幀后解析。 解析出鏈路層數據包后,根據上層使用的協議調用相關方法構建上層協議類型的數據包,以此類推一直完成數據包的指令解析。 最后將解析后的指令數據交于緩沖區,保存數據。
2.2 基于SVC 支持向量機的異常指令檢測
運用獲取的指令數據集,劃分數據集為訓練集與測試集。 然后用這些數據集構造二分類支持向量機模型,實現正常指令與異常指令的分類,從而實現檢測異常指令功能。 具體如下文所述。
首先, 將數據庫中的指令數據樣本集按照3∶1的比例劃分為訓練集與測試集,將測試集中的正常數據樣本標識為+1,異常的數據樣本標識為-1。 用標識完成的訓練集開始模型的構建過程,再建立一個未知的超平面,設出未知的支持向量,列出支持向量到超平面的距離公式作為決策函數,根據限制條件求最大的值,選擇核函數。 設置參數gamma 值和C 參數為定值,然后進行對比分類試驗,通過準確率與召回率的比較,選擇最優的核函數。 運用已選擇好的最優核函數, 改變gamma 值和C 參數的值,形成多組對比實驗,從而選擇出最優的gamma值和C 參數。
為了評估所建測試模型的泛化性能,運用交叉驗證的方式進行測試,即多次的劃分數據,并訓練多個模型,然后取平均值,計算出模型的平均精度,最終完成異常指令檢測模型的構建。
2.3 基于超球體SVM 算法的已知指令檢測
針對常見的攻擊指令集,分別構建一個超球體模型, 落在超球體以內的測試對象為該攻擊類型,而落在超球體以外的不是該攻擊的類型,實現了該常見的攻擊指令類型與其它攻擊類型的區分,從而實現對已知攻擊指令的檢測識別功能。 技術實現如下所述。
使用經過異常指令模型檢測后的異常指令數據集,針對每一個已知的攻擊指令集,先依據隨機森林進行特征的選擇,選擇出最優的區分該攻擊的特征。 進而構建未知超球體,既要盡量把該攻擊所有數據都包入球體內部,又要保證球半徑盡可能的小。 因此,根據中折關系求解超球體決策函數,并不斷調整參數選出最優, 然后進行閾值計算與分析,確定球心位置與半徑大小,最終完成超球體檢測模型構建。 對所有的已知攻擊分別按照上述過程構建一個超球體的已知攻擊檢測模型,實現對所有已知攻擊的檢測與識別。
2.4 基于無監督聚類模型的未知指令檢測
對于已知攻擊以外的其他未知攻擊指令,通過構建無監督聚類模型實現對其的檢測與識別。 在已構建的所有已知攻擊指令檢測模型的基礎上,將落入超球體模型以外的數據集劃分為訓練集與測試集,用訓練集開始未知攻擊指令模型的建立。 先隨機選取k 個數據點分別作為中心點建立k 個簇,隨著訓練集數據點的不斷進入,分別計算其到各個簇中心點的距離,根據所計算的距離結果,將其劃入到最近的簇中,同時取擴充后該簇內所有數據點的平均值作為新的簇中心點, 不斷地循環上述過程,直至所有的訓練集用完,可形成k 個聚類。 并計算各個聚類屬性上任意兩個離散數據值a 與b 之間的距離,從而確定每一個聚類的具體范圍,每一個聚類的攻擊指令集即為一個特定的未知攻擊類型,從而實現未知攻擊指令的分類。
2.5 基于隨機森林的特征選擇與優化
在上述機器學習預測模型的構建過程中發現,由于網絡流量數據集屬于多特征、大容量的樣本數據集,即使使用高性能計算平臺,其模型構建過程花費時間過長, 且預測模型會出現過擬合的情況。因此,為了高效、準確地建立預測模型,必須對網絡流量特征進行選擇與優化。 通過大量研究特征選擇與優化,本文使用隨機森林算法對樣本特征集進行排序,并通過交叉驗證的方法進行不同特征子集模型間的評估比較, 實現網絡流量特征的選擇與優化,從而提高預測模型的構建效率和泛化能力。
將獲得的流量數據集,不斷地獨立重復地取相同數量的測試樣本,分別建立多個決策樹,把每一棵決策樹特征分割決策得到的基尼指數進行線性累加或者加權線性累加,可以獲得特征的重要性排序,從而達到對特征的選擇與優化目的。
3 實驗和分析
本實驗在一臺自行搭建的計算機上進行,采用Intel I7-7820X 處理器,RTX2080 顯卡,11 G 顯存,16 G 雙通道內存。 原始數據集選用IDS2017[12]及依據電力系統常用通信協議IEC60870-5-104 產生的模擬數據進行分析。
3.1 基于指令特征選擇與優化測試
3.1.1 SVC 模型的特征選擇與優化
樣本子集的選取與SVC 模型調參與選擇相一致。 對5 組樣本子集做基于隨機森林的特征選擇處理和無特征處理,得到特征子集后建立SVC 二分類分類器,以準確率為主進行評估。 整合所有樣本子集上的測試數據取均值與無特征選擇處理后建立的分類器相比較,并基于隨機森林算法計算出的特征重要性評分,決定最終特征子集的大小,測試結果見表1。結果表明,該模型特征選擇與優化能力強,在當特征子集的數量為7 或8 時,SVC 二分類分類器的泛化性能最佳。
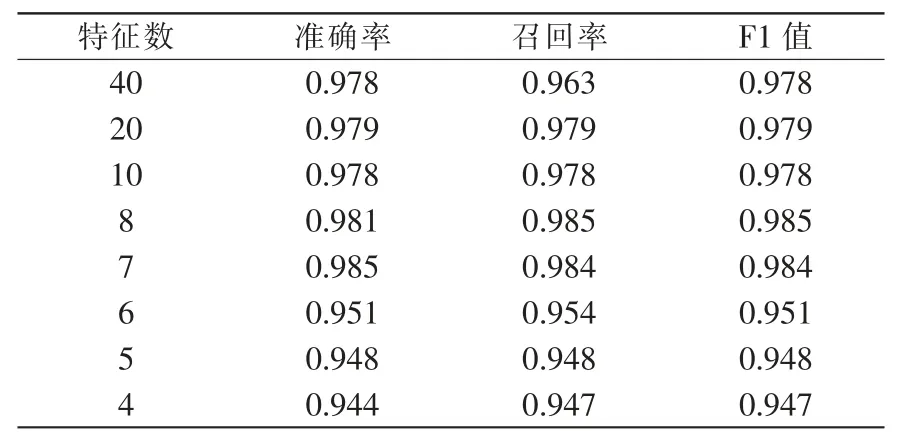
表1 SVC 模型泛化能力與特征數關系Tab.1 Relationship between generalization ability and feature number of SVC model
3.1.2 超球體SVM 模型特征選擇與優化
樣本子集的選取與SVM 模型調參與選擇相一致, 分別構建14 個已知攻擊基于部分特征的決策樹,并通過引入隨機數,利用隨機森林算法得出這些攻擊各自的特征重要性得分排序,代入不同特征子集的數量,建立對應的分類器模型,并對測試集數據進行預測,得出最終得分。 測試結果如表2 所示,分別以[10,9,8,7,6,5,4]作為特征子集的數量進行代入,當特征子集的數量為4 時,分類器泛化性能最佳。 按我們的特征選擇方法能夠有效的提高SVM 分類器的分類效率。
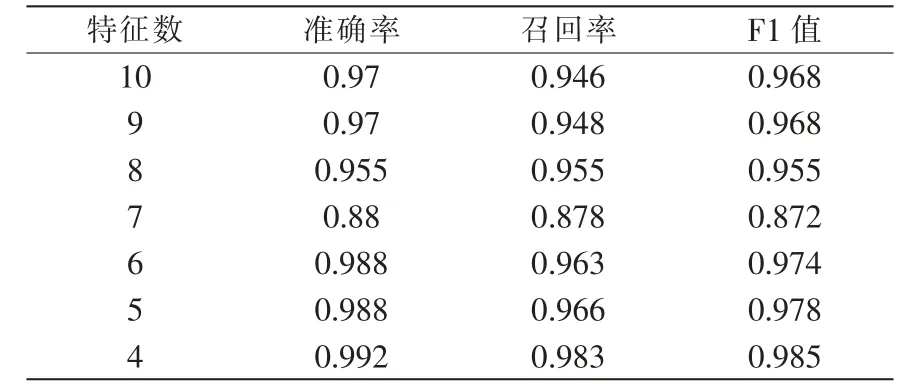
表2 測試集評估度量Tab.2 Test set evaluation metrics
3.2 攻擊指令檢測功能測試
本次測試選擇對事先采集好的統計數據進行測試,測試用的數據集為原始數據集中除去之前用于訓練和測試之外的異常流量和正常流量樣本集。
3.2.1 異常流量檢測測試
樣本數據導入后,在數據信息部分會顯示樣本數據集的基本信息,包括數據集名稱,樣本數量以及特征數量。 對測試樣本集進行同樣操作,得到正常流量數量和異常流量數量。 將10 個檢測結果與測試集中的標識進行比較,得到模型精度如表3 所示,模型平均精度超過99.9%,滿足設計要求。

表3 異常流量檢測精度Tab.3 Abnormal flow detection accuracy
3.2.2 已知網絡攻擊檢測測試
運行已知網絡攻擊檢測,導入異常流量檢測模塊檢測到的異常流量,并運用預測模型進行已知網絡攻擊檢測并標識,對測試樣本集進行同樣操作,得到已知攻擊的各類和數量。 將10 個檢測結果與測試集中的標識進行比較,得到模型精度如表4所示。 測試結果顯示,模型平均精度超過99.9%,滿足設計要求。
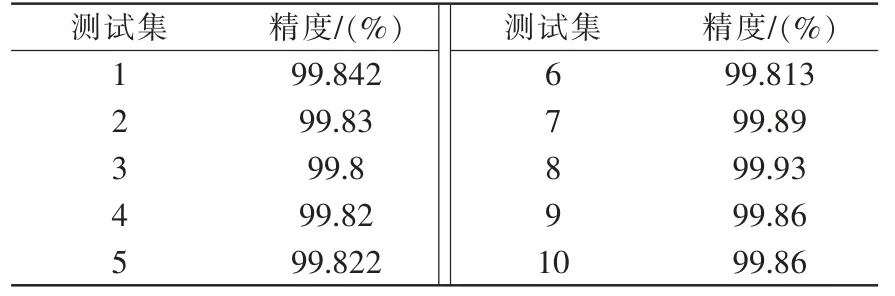
表4 已知網絡攻擊檢測精度Tab.4 Known network attack detection accuracy
3.2.3 異常流量檢測測試
在已知網絡攻擊預測模型組中刪除一組已知網絡攻擊預測模型,隨后重復前面兩個模塊的檢測過程,得到新的包含該攻擊樣本數據異常流量的測試數據集。 運行未知網絡攻擊檢測子模塊,此時系統將自動導入包含該攻擊樣本數據異常流量的測試數據集,并運用預測模型進行未知網絡攻擊進行檢測與聚類,檢測結果如表5 所示。 測試結果顯示,對于一種給位置攻擊的檢測精度超過90%,聚類精度超過80%,具有較好效果。
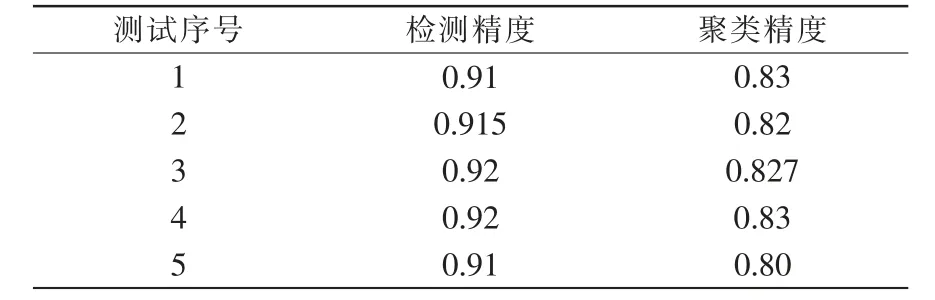
表5 未知網絡攻擊檢測精度Tab.5 Unknown network attack detection accuracy
4 結語
本文將SVC、超球體SVM、k 均值聚類、手肘法定k 值、回歸決策樹、隨機森林等算法有機結合,引入到電力網絡指令檢測模型構建過程中,構建全面合理的預測模型實現異常網絡指令、已知網絡攻擊指令和未知網絡攻擊指令的檢測。 以流量統計分析為基礎, 構建了更為合理的網絡攻擊指令檢測技術,通過監督學習算法和無監督學習算法有機結合完成已知和未知攻擊檢測,并基于隨機森林算法進行流量特征選擇與優化,提高模型構建速度、運行效率和泛化能力所適合的流量特征,使網絡數據集得到擴充,模型得到更新,攻擊檢測更為準確。
猜你喜歡
科普童話·神秘大偵探(2023年1期)2023-05-30 12:48:10
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
測控技術(2018年5期)2018-12-09 09:04:26
電子測試(2018年18期)2018-11-14 02:30:34
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
海峽科技與產業(2016年3期)2016-05-17 04:32:12
