圖像分類中的白盒對抗攻擊技術綜述
2022-09-25 08:42:26魏佳璇杜世康于志軒張瑞生
計算機應用 2022年9期
魏佳璇,杜世康,于志軒,2,張瑞生
(1.蘭州大學信息科學與工程學院,蘭州 730000;2.蘭州大學第一醫院,蘭州 730000)
0 引言
近年來,得益于圖形處理器(Graphics Processing Unit,GPU)技術突飛猛進的發展以及計算機硬件升級帶來的算力提升,深度學習取得了令人矚目的發展成果。當前,深度學習技術不僅大量地應用在圖像分類、語音識別和自然語言處理領域的常規任務中,更是在自動駕駛系統[1]、人臉識別系統[2]、惡意軟件自動分類[3-4]和異常檢測[5]等工業生產和生活領域的大量關鍵任務中發揮著重要作用。雖然深度學習技術在眾多問題的解決上取得了一系列重要研究成果,但對于自身還存在一些關鍵的問題亟待解決,特別是深度學習模型存在的對抗樣本問題。
2013 年,Szegedy 等[6]在研究圖像分類任務時發現,在一個可以被深度學習模型正常分類的樣本圖片上添加噪聲數據后,即使是分類準確率很高的深度學習模型也會以極高的置信度對該樣本誤分類。而添加在樣本圖片上的噪聲數據是微小的,以人的肉眼幾乎察覺不到在樣本圖像上進行的篡改,篡改后得到的輸入樣本被稱為對抗樣本。對抗樣本的一個示例如圖1 所示,原始樣本為ImageNet 數據集[7]中圖片,其真實的標簽和在ImageNet 上預訓練的ResNet 模型[8]的分類結果均為足球。添加了惡意的擾動數據后得到對抗樣本,此時ResNet 模型將該對抗樣本誤分類為橄欖球。

圖1 對抗樣本示例Fig.1 Examples of adversarial sample
對抗樣本問題揭示了深度學習模型存在嚴重的安全漏洞,給深度學習技術的普遍應用帶來了嚴峻的安全挑戰。在圍繞對抗樣本的研究過程中,主要以用于對抗樣本生成的對抗攻擊技術的研究為主,迭代發展出了多樣性的對抗攻擊算法。目前已知的大部分對抗攻擊算法針對圖像分類任務提出,并經過改造應用在諸如語義分割、目標檢測等常見的計算機視覺任務上。經過改造的攻擊算法甚至可以很好地推廣到自然語言處理和語音識別等任務中。此外,對抗攻擊現象不僅發生在數字圖像空間,對于部署在真實應用場景下的深度學習模型[4,9-11]也能夠帶來安全威脅。
對抗攻擊技術由于其破壞力和潛在的應用前景,成為近年來深度學習學術界和工業界共同的研究熱點。Carlini等[12]統計的2014 年至今,arXiv 網站發表的對抗樣本相關論文的數量情況如圖2 所示。攻擊者利用已有的對抗攻擊算法可以在深度學習模型推理階段對輸入樣本添加噪聲數據,而達到惡意改變模型推理結果的目的。根據對抗攻擊技術在生成對抗樣本時是否需要了解目標模型的網絡結構、參數設置、訓練數據和方式等知識,對抗攻擊技術可分為白盒攻擊和黑盒攻擊;根據攻擊是否需要讓模型輸出指定的目標類別,又分為目標攻擊和無目標攻擊。目前針對對抗攻擊技術的研究大多以白盒攻擊方式為主,其攻擊成功率大幅高于黑盒攻擊方式,對深度學習模型帶來的安全威脅也較為嚴峻。為及時評估對抗攻擊技術給深度學習模型帶來的安全風險,以便為深度學習技術的安全應用提供有益參考。本文圍繞圖像分類任務,對近年來研究人員提出的具有一定代表性的白盒對抗攻擊技術進行全面闡述和分析總結。
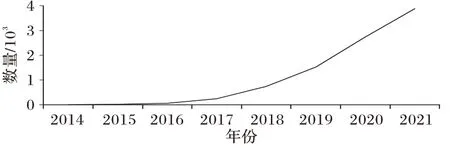
圖2 對抗樣本論文數量Fig.2 Number of adversarial example papers
1 對抗攻擊技術背景知識
對抗攻擊是一種發生在深度學習模型推理階段的攻擊行為。在圖像分類任務中,給定一個深度學習模型f(x)=y,x∈Rm為模型的輸入,y∈Y為針對當前輸入x的模型輸出。模型f(·)一般還包含一組訓練好的權重參數θ,為方便說明,對模型描述時省略該參數。對抗攻擊技術描述為在針對目標模型f(·)的輸入x上尋找一個小的噪聲數據r,當r疊加在x上輸入目標模型后,使得f(x+r) ≠f(x);在目標攻擊中,使得f(x+r)=yt,yt為需要讓模型輸出的目標類目。
為了使噪聲數據r足夠小,保證人眼察覺不到攻擊者在圖像上進行的篡改,大多數對抗攻擊算法[6,13-14]會使用l0、l2或l∞范數對擾動噪聲r的大小進行限制。用l2范數來約束擾動大小時,在目標攻擊中,對抗樣本的生成問題可描述為如下的優化形式:

其中:yt是要攻擊的目標類別;x為原始輸入樣本;r表示擾動噪聲;x+r表示得到的對抗樣本,后文也用xA表示。
下面簡要說明和定義在本文中出現的對抗攻擊技術相關術語。
模型 深度學習模型,文中一般指圖像分類模型。
對抗樣本(Adversarial Examples)對抗樣本概念由Szegedy 等[6]提出,攻擊者對原始輸入樣本添加輕微的噪聲數據后能使深度學習模型推理錯誤,這類添加噪聲數據后影響模型推理能力的樣本稱為對抗樣本。
擾動/對抗擾動(Adversarial Perturbations)在原始輸入樣本上添加噪聲數據后能使深度學習模型推理錯誤,被添加的噪聲數據稱為擾動或對抗擾動。
通用對抗擾動(Universal Adversarial Perturbations)不同于對抗擾動只針對特定的輸入樣本,通用對抗擾動添加在大部分輸入樣本上都會使得深度學習模型推理錯誤。
對抗擾動的遷移攻擊性 針對目標模型A,在輸入樣本x上生成對抗擾動r。當擾動r疊加在針對目標模型B 的輸入樣本上后能使模型B 推理錯誤的現象稱為對抗擾動的遷移攻擊性[6,14-15]。如果對抗擾動能夠在目標模型B 的大部分數據點上使模型推理錯誤,則稱該對抗擾動具有很好的遷移攻擊能力。利用對抗樣本的遷移攻擊性進行攻擊是一種有效的對抗攻擊方式。
模型魯棒性 指模型的對抗魯棒性,針對對抗攻擊技術自身防御效果良好的模型,則稱該模型具有較好的魯棒性。
對抗訓練 一種提升模型對抗魯棒性的訓練方式[14,16],在訓練模型時,使用正常樣本和對抗樣本同時對模型進行訓練的方式。
攻擊成功率 利用對抗攻擊技術生成對抗樣本輸入目標模型后,模型推理錯誤樣本數占所有輸入樣本數的百分比,有時也可用模型對對抗樣本的分類準確率代替表示,模型對對抗樣本的分類準確率越低說明攻擊者的攻擊成功率越高。
2 白盒對抗攻擊技術
就目前的研究來看,白盒對抗攻擊技術是主要的對抗樣本生成方式。大部分的白盒對抗攻擊算法針對單個輸入圖像生成對抗擾動,但也有算法針對目標模型和整個數據集生成通用對抗擾動[17-18]。通過對大部分研究人員主要的成果[19-21]進行研究分析,發現大部分的白盒對抗攻擊算法目前主要分為以下4 種:1)基于直接優化的方法;2)基于梯度優化的方法;3)基于決策邊界分析的方法;4)基于生成式神經網絡生成的方法。其他方面,研究人員也利用差分進化、空域變換等思路進行對抗樣本的生成。本文依據上述分類,對在白盒條件設置下主要的對抗攻擊算法進行全面分析和闡述,最后在表1 中對攻擊算法進行了比較和總結。
2.1 基于直接優化的攻擊方法
基于直接優化的攻擊方法是目前較為重要的一類對抗攻擊技術,主要包含兩種對抗攻擊算法:基于Boxconstrained L-BFGS(Box-constrained Limited-memory BFGS)的攻擊算法[6]是第一個提出的對抗攻擊算法,該算法也首次揭示了深度學習模型中存在的對抗樣本問題;C&W(Carlini&Wagner)攻擊[13]通過對基于Box-constrained L-BFGS的攻擊算法的改進,能夠生成對蒸餾防御網絡[22]具有較好攻擊能力的對抗樣本。這類攻擊方法通過算法對目標函數直接優化生成的對抗擾動相對較小,但存在優化時間長,算法需花費大量時間尋找合適超參數的問題。
2.1.1 基于Box-constrained L-BFGS的攻擊
2013 年,Szegedy 等[6]首先提出了利用Box-constrained L-BFGS 算法[23]直接優化求解的對抗樣本生成方法。由于式(1)中的擾動限制條件難以直接優化,Szegedy 等利用拉格朗日松弛法將其中的f(x+r)=yt限制條件簡化為lossf(x+r,yt)進行優化,lossf表示交叉熵損失函數,最終得到的優化目標如下:

其中:輸入圖像被歸一化在[0,1],以滿足凸優化方法中的箱型約束條件,使得上述目標可以利用L-BFGS 算法進行求解。
利用Box-constrained L-BFGS 算法生成對抗樣本的方法是最早被設計的對抗攻擊算法,該算法首次將生成對抗樣本的過程抽象為一個凸優化的問題處理,是重要的基于優化方法的對抗攻擊算法。該算法為目標攻擊算法,使用該算法求解的思路是先固定超參數c來優化當前參數值下的最優解,再通過對c進行線性搜索即可找到滿足f(x+r)=yt條件的最優對抗擾動r,最終得到的對抗樣本為x+r。
2.1.2 C&W攻擊
為了攻破Papernot 等[22]提出的蒸餾防御網絡,Carlini 和Wagner 提出了著名的C&W 攻擊[13]。該攻擊算法可以使用l0、l2或l∞范數分別對擾動進行限制生成對抗樣本,是目前較為強大的目標攻擊算法之一。C&W 攻擊算法屬于直接優化的攻擊算法,是基于Box-constrained L-BFGS 算法(式(2))的改進版,改進主要體現在兩點:
1)基于Box-constrained L-BFGS 的攻擊中損失函數為交叉熵損失函數,而C&W 攻擊算法考慮了攻擊目標類和其他類別之間的關系,選擇了更好的損失函數[13],如下所示:

式中:Z(xA)=Logits(xA)表示目標網絡Softmax 前一層的輸出;i表示標簽類別;t表示目標攻擊的標簽類;k表示對抗樣本的攻擊成功率,k越大,生成的對抗樣本的攻擊成功率越高。
2)去除了式(2)中的Box-constrained 限定條件,使該優化問題轉化為無約束的凸優化問題,方便利用梯度下降法,動量梯度下降法和Adam[24]等算法求解。為實現該目的,Carlini 等[13]提供了兩種有效方法:①采用投影梯度下降法的思路將每次迭代過程中得到的x+r裁剪在[0,1]m內,以去除x+r的區間約束條件,但此方法在對x+r進行裁剪時會帶來梯度信息的損失;②引入新的變量ω,令ω∈[-∞,+∞],構造一個映射函數將ω從[-∞,+∞]映射到[0,1],通過優化ω去掉方法①中由x+r∈[0,1]m條件引起的優化誤差,具體映射函數如下:
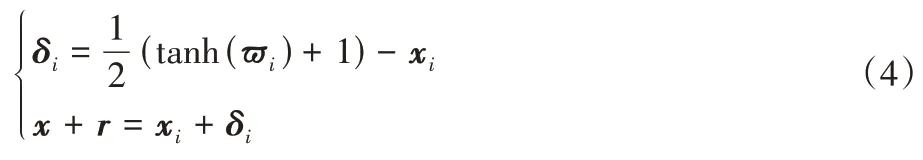
其中:-1 ≤tanh(?i) ≤1,故0 ≤x+r≤1。
Carlini 等[13]分別用方法①和方法②進行了實驗分析,發現用投影梯度下降法處理Box-constrained 限定條件時生成的對抗樣本攻擊能力較強,但引入變量進行優化的方法生成的對抗擾動較小。此外,在優化算法的選擇上,梯度下降、動量梯度下降和Adam 等優化算法都可以生成相同質量的對抗樣本,但Adam 算法的收斂速度要比其他兩種快。C&W 攻擊算法生成的對抗樣本針對蒸餾防御的模型攻擊能力很好,是目前較為強大的白盒攻擊算法,也是用于評估模型魯棒性的主要測試算法之一。
2.2 基于梯度優化的攻擊方法
基于梯度優化的攻擊方法是目前一種主要的對抗攻擊技術。這類攻擊方法的核心思想是在模型損失函數變化的方向上對輸入樣本進行擾動,來使模型誤分類輸入樣本或使模型分類輸入樣本到指定的不正確目標類別上。這類攻擊方法的優點是方法實現簡單,且白盒對抗攻擊成功率較高。該類方法以FGSM(Fast Gradient Sign Method)算法[14]為基礎,衍生發展出了I-FGSM(Iterative FGSM)算 法[25]、PGD(Projected Gradient Descent)算法[26]、動量迭代的MI-FGSM(Momentum Iterative FGSM)算法[27]以及多樣性的梯度攻擊算法[28-29]。
2.2.1 FGSM攻擊
2014 年,Goodfellow 等[14]在其研究中認為,深度學習模型存在對抗樣本是由于模型過于線性的特性導致,基于該觀點提出了基于一步梯度計算的對抗樣本生成算法FGSM。這項工作意義深遠,受Goodfellow 等啟發,后來出現的基于梯度優化的大部分攻擊算法都是FGSM 算法的變種。
FGSM 攻擊算法的思想是使對抗擾動的變化量與模型損失梯度變化的方向保持一致。具體來說,在無目標攻擊中,使模型損失函數關于輸入x的梯度在上升的方向上變化擾動達到讓模型誤分類的效果。假設θ為模型的參數,x為模型的輸入,y為輸入x對應的正確類別標簽,J(θ,x,y)為模型的損失函數,為交叉熵損失函數,?xJ(θ,x,y)為損失函數關于x的梯度。FGSM 算法描述為:

其中:α為超參數,表示為一步梯度的步長;sign(·)為符號函數,故該方法生成的擾動為在l∞范數約束下的對抗擾動。FGSM 算法由于只計算一次梯度,其攻擊能力有限,但生成的對抗樣本具有較好的遷移攻擊能力。
2.2.2 I-FGSM攻擊
由于FGSM 算法只經過一次梯度計算生成對抗樣本,并且該方法成功應用的前提條件是損失函數的梯度變化方向在局部區間內是線性的。在非線性的優化區間內,沿著梯度變化方向進行大步長優化生成的對抗樣本并不能保證攻擊成功。針對該問題,Kurakin等[25]提出了迭代FGSM(I-FGSM)算法,通過把優化區間變小來使Goodfellow 的線性假設[14]近似成立。I-FGSM 算法的無目標攻擊描述為:

I-FGSM 算法較FGSM 算法生成的對抗樣本攻擊能力更強[30],但其生成的對抗樣本遷移攻擊能力卻不如FGSM算法。
此外,Kurakin 等[25]還在I-FGSM 算法的基礎上,通過將攻擊的目標類別y指定為原始樣本在模型上輸出置信度最低的類別標簽yl來進行針對置信度最低類別的目標攻擊。在目標攻擊過程中,擾動的變化方向與模型損失函數關于輸入的梯度下降方向保持一致,其優化的目標形式為:

這種目標攻擊方式生成的對抗樣本使模型誤分類到與正確類別差距很大的類,其攻擊效果更具破壞性。
2.2.3 PGD攻擊
2017 年,Madry 等[26]提出的PGD 攻擊算法是目前公認為最強的白盒攻擊方法,也是用于評估模型魯棒性的基準測試算法之一。PGD 攻擊本質上也是迭代的FGSM 算法,與I-FGSM 攻擊類似。與I-FGSM 算法相比,PGD 算法的迭代次數更多,并在迭代過程中對上一版本得到的xA隨機地進行了噪聲初始化,以此避免優化過程中可能遇到的鞍點[26]。使用PGD 算法生成的對抗樣本攻擊能力比I-FGSM 攻擊能力強,但同樣具有的遷移攻擊能力弱的問題。
2.2.4 MI-FGSM攻擊
在接下來的研究中,為了使對抗樣本兼具強大的攻擊能力和良好的遷移攻擊能力,Dong 等[27]提出了基于動量的迭代生成對抗樣本的MI-FGSM 算法。該算法在I-FGSM 算法的迭代過程中引入動量技術[31-32],以此在損失梯度變化的方向上累計速度矢量以穩定梯度的更新方向,使得優化過程不容易陷入局部最優。MI-FGSM 算法描述為:
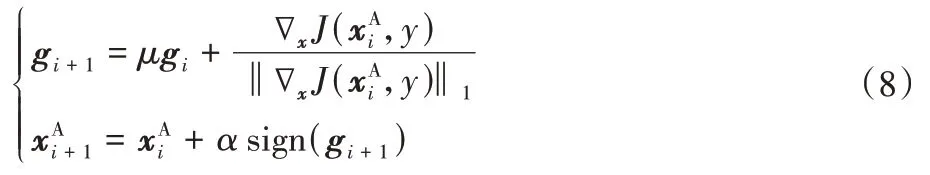
其中:gi+1表示在第i次迭代后累計的梯度動量;μ為動量項的衰減因子,當μ=0,則上述形式為I-FGSM 算法的形式。由于多次迭代中得到的梯度不在一個量級,將每次迭代中得到的當前梯度?xJ(,y)通過其自身的l1距離進行歸一化。
MI-FGSM 攻擊算法生成的對抗樣本在具有較好攻擊能力的基礎上還保留了一定的遷移攻擊能力,是目前常用的白盒對抗攻擊方法。
此外,為了更加有效提升基于梯度優化的方法生成對抗樣本的遷移攻擊能力,Xie 等[28]提出了一種輸入多樣性的對抗攻擊方式,采取數據增強的思路,在將圖像輸入到模型前,先對輸入樣本進行隨機轉化,如隨機調整樣本大小或隨機填充給定的分布等。將轉換后的圖像輸入至目標模型后,再應用I-FGSM[25]、MI-FGSM[27]等算法進行梯度計算生成對抗樣本。另外,通過減輕對抗樣本在不同模型間識別的敏感程度,也可以提高對抗樣本的遷移攻擊能力。Dong 等[29]提出了基于梯度的平移不變攻擊方式,通過將梯度與一個預先定義的核進行卷積來生成對大部分模型識別區域不太敏感的對抗樣本。
2.3 基于決策邊界分析的攻擊方法
基于決策邊界分析的攻擊方法是一類特殊的對抗攻擊方法。該方法最初由Moosavi-Dezfooli 等[33]提出,分為針對單個輸入圖像生成對抗擾動的DeepFool 攻擊算法和針對目標模型和整個數據集生成通用對抗擾動的UAPs(Universal Adversarial Perturbations)攻擊算法[17]。該類攻擊方法的核心思想是通過逐步減小樣本與模型決策邊界的距離來使模型對該樣本誤分類,故其生成的對抗樣本一般較小,但這類攻擊方法不具備目標攻擊能力。
2.3.1 DeepFool攻擊
Moosavi-Dezfooli 等[33]在對模型的決策邊界分析后提出了一種精確計算對抗擾動的DeepFool 方法。DeepFool 算法生成的對抗擾動非常小,該擾動一般被認為近似于最小擾動。DeepFool 算法具體描述為:首先,針對線性二分類問題,給定一個分類器(x)=sign(f(x)),f(x)=ωx+b,分類器的決策邊界用F={x:f(x)=0}表示,如圖3 所示。要使當前數據點x0被該模型誤分類到決策邊界另一邊,其最小擾動對應于x0在F上的正交投影r*(x0):

圖3 線性分類器的決策邊界Fig.3 Decision boundary of linear classifier

根據f(x)=ωx+b,推導得r*(x0)=,此為模型決策邊界線性時計算得到的最小擾動值。
推廣到非線性決策邊界的二分類問題,可通過迭代的過程來近似得到針對數據點x0的最小擾動r*(x0)。具體來說,在每次迭代過程中認為模型f(·)近似線性,此時擾動后數據點x0對應于這次迭代的最小距離ri(xi)為:

根據式(9)得到的閉解,繼而推導得出針對非線性決策邊界的最小擾動距離ri(xi)=通過將每次迭代得到的擾動ri累加就可以得到針對當前數據點x0所需的最小擾動。
2.3.2 UAPs攻擊
多數對抗攻擊算法[14,25,33]針對單個輸入樣本生成對抗樣本,從而達到攻擊目的。而Moosavi-Dezfooli 等[17]發現深度學習模型存在與輸入樣本無關的通用對抗擾動,這種擾動與目標模型結構和數據集特征相關。當通用對抗擾動疊加在數據集的輸入樣本上時得到對抗樣本,得到的對抗樣本大部分具有攻擊能力。通用對抗擾動定義如下:假設μ表示數據集中數據的分布情況,δ表示分布μ上所有數據點希望攻擊成功的比例,ξ用于度量擾動的大小,通用對抗擾動ν要滿足如下兩個條件:

Moosavi-Dezfooli 等[17]提出的UAPs 攻擊算法通過在采樣的少量數據點上迭代計算生成通用對抗擾動。每次迭代過程中,計算能夠使當前數據點xi欺騙分類器的最小擾動Δνi,其優化目標描述為:

最后,將在采樣數據點上計算得到的擾動匯總到通用對抗擾動ν。為了保證匯總得到的通用對抗擾動滿足‖ν‖p≤ξ,在每次迭代匯總時,對更新的擾動進行如下投影操作:

于是,ν的更新規則為ν←Pp,ξ(ν+Δνi)。直到滿足預先定義的愚弄率后,算法停止迭代。愚弄率定義如下:
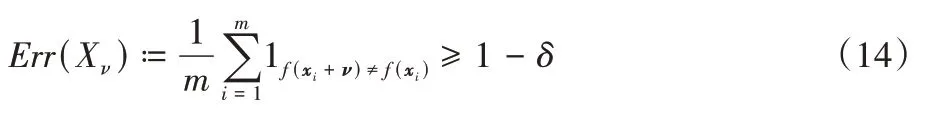
UAPs 攻擊算法在迭代過程中的擾動計算使用DeepFool算法[33]進行求解。最終,經過多次迭代后通過將數據點推送到模型決策邊界另一邊,達到對抗攻擊的目的。
2.4 基于生成式神經網絡生成的攻擊方法
基于生成式神經網絡生成的攻擊方法利用自監督的方式,通過訓練生成式神經網絡來生成對抗樣本。這類攻擊方法的特點是一旦生成式模型訓練完成,可非常高效地生成大量具有良好遷移攻擊能力的對抗樣本。典型的這類攻擊方法有ATN(Adversarial Transformation Network)攻擊[34]、UAN(Universal Adversarial Network)攻擊[18]和AdvGAN 攻擊[35]。
2.4.1 ATN攻擊
Baluja 等[34]首次提出利用生成式神經網絡生成對抗樣本的ATN 攻擊方式,并設計了ATN 用來生成對抗樣本。ATN 將一個輸入樣本轉換為針對目標模型的對抗樣本,ATN 定義如下:

其中:θ表示神經網絡g的參數,f表示為要攻擊的目標網絡。針對目標攻擊問題,對ATN 中參數θ的訓練,可描述為如下的優化目標:

其中:LX為視覺損失函數,可用常見的l2范數表示或者采用與文獻[36]中類似的視覺感知相似性函數;LY為類別損失函數,定義為LY=L2(y',r(y,t)),其中y=f(x),y'=f(gf(x)),t是目標攻擊的類別,r(·)是重新排序函數[34],它對x進行修改,使yk≤yt,?k≠t。
ATN[34]可以訓練為僅生成對抗擾動的P-ATN(Perturbations Adversarial Transformation Network),這種情況下ATN 一般選擇殘差的網絡結構[8]就可有效地生成擾動。ATN 還可以訓練為直接生成對抗樣本的AAE(Adversarial AutoEncoding)網絡,這種情況下ATN 結構采用自編碼器可很好地生成對抗樣本。通過這兩種方法得到的對抗樣本差異較大,AAE 方法生成的對抗樣本整體變化較為明顯,而P-ATN 方法生成的對抗樣本擾動程度較小。總體而言,該方法生成對抗樣本的速度較快,且其攻擊能力較強,但遷移攻擊能力較弱。
2.4.2 UAN攻擊
Hayes 等[18]提出了基于神經網絡生成通用對抗擾動進行攻擊的UAN 攻擊算法。UAN 攻擊通過訓練一個簡單的反卷積神經網絡將一個在自然分布N(0,1)100上采樣的隨機噪聲轉換為通用對抗擾動。針對目標攻擊問題,Hayes 等[18]為反卷積神經網絡的訓練設計了如下的優化函數:
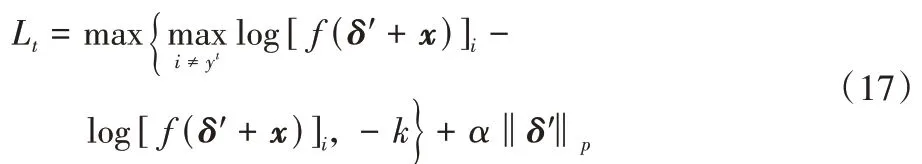
其中:模型損失函數選擇了與C&W 攻擊[13]相同的損失函數,yt為目標攻擊選擇的類別,α控制擾動大小優化項的相對重要程度。
在實際利用UAN 攻擊方式[18]進行攻擊時,使用l2或l∞范數均可生成攻擊能力較好的通用對抗擾動,其攻擊能力強于先前提出的UAPs 攻擊[17]。
2.4.3 AdvGAN攻擊
Xiao 等[35]在基于神經網絡生成的攻擊算法中首次引入了生成式對抗網絡[37]的思想,提出了包含生成器、鑒別器和攻擊目標模型的AdvGAN。如圖4 所示,經過訓練的AdvGAN 可以將隨機噪聲轉換為有效的對抗樣本。
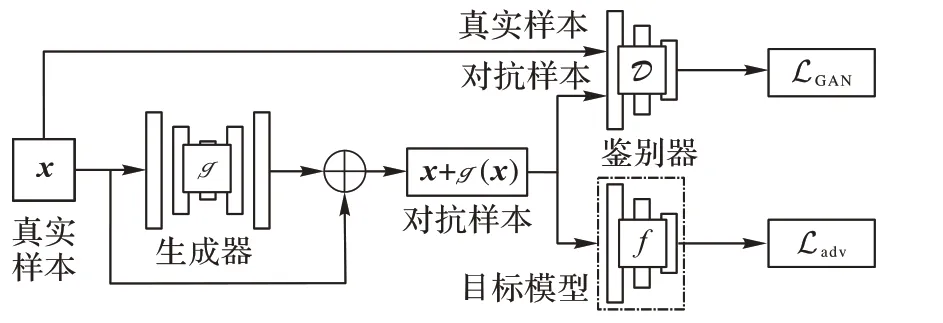
圖4 AdvGAN架構Fig.4 Architecture of AdvGAN
與UAN 攻擊[18]中使用lp范數對擾動大小的限制不同,AdvGAN 利用生成式對抗網絡中的“對抗損失”項,來保證對抗樣本的真實性。AdvGAN 中的對抗損失項采用與Goodfellow 等[37]相同的定義:
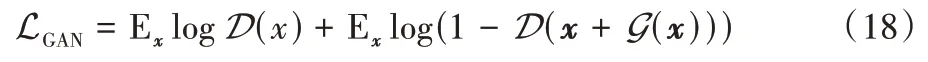
其中:生成器G(·)用于將輸入噪聲轉化為對抗擾動,鑒別器D(·)的目的是盡可能使生成的對抗樣本與原始輸入樣本具有較高的相似性。在目標攻擊中,針對目標模型的誤導損失項定義為:

其中:yt為目標攻擊的類別,lossf為交叉熵損失函數。此外,為了明確量化擾動大小以及穩定GAN 的訓練過程[38],對擾動添加一個soft hinge 損失項,如下所示:

其中c為指定的擾動大小。最終,針對AdvGAN 訓練的整體優化函數設計如下:

其中:α和β參數用來控制每個優化項的相對重要性,整體來說,LGAN損失項的目的是使生成的對抗擾動與原始樣本相似損失項的目的是達到對抗攻擊的效果。
2.5 其他的攻擊方法
2.5.1 JSMA攻擊
Papernot 等[39]提出的JSMA(Jacobian-based Saliency Map Attack)算法是一種基于l0范數約束下的攻擊,通過修改圖像中的幾個像素來使模型對輸入樣本誤分類。JSMA 攻擊算法利用顯著圖[40]表示輸入特征對預測結果的影響程度,每次修改一個干凈圖像的像素,然后計算模型最后一層的輸出對輸入的每個特征的偏導。通過得到的前向導數,計算得出顯著圖[40]。最后利用顯著圖找到對模型輸出影響程度最大的輸入特征,通過修改這些對輸出影響程度較大的特征點從而得到有效的對抗樣本。
2.5.2 單像素攻擊
在其他的攻擊算法中,單像素攻擊[41]是一種基于差分進化算法[42]的攻擊算法。單像素攻擊算法每次只修改樣本數據點的1 個像素值試圖讓模型誤分類。實際應用中,這是一種極端的攻擊方式。該方法對于簡單的數據集有較好的攻擊效果,比如MNIST 數據集[43]。當輸入圖像的像素空間較大時,1 個像素點的改變很難影響到分類結果,隨著圖像增大,算法的搜索空間也會迅速增大,使得算法性能下降。
2.5.3 stAdv攻擊
Xiao 等[44]提出了一種通過對圖像樣本進行空域變換來產生對抗樣本的stAdv(spatially transformed Adversarial)攻擊算法。該算法對局部圖像特征進行平移、扭曲等操作實現針對輸入樣本的空域變換攻擊。使用stAdv 算法生成的對抗樣本較于傳統基于lp范數距離度量生成的對抗樣本更為真實,且針對目前采用對抗訓練措施的模型具有很好的攻擊效果。
2.5.4 BPDA攻擊
破碎梯度策略[15]是一種用來針對FGSM[14]、I-FGSM[25]等基于梯度攻擊方法的對抗防御方法。破碎梯度策略使用一個不可微的函數g(x)預處理輸入樣本,使訓練得到的模型f(g(x))在x上不可微,使得攻擊者計算不出用于對抗樣本生成的梯度[15]。
Athalye 等[45]針對破碎梯度策略,提出利用近似梯度生成對抗樣本的 BPDA(Backward Pass Differentiable Approximation)算法。BPDA 算法在反向傳播計算梯度時,使用一個可微的函數h(x)替代函數g(x)來近似獲得梯度,生成對抗樣本。
本文從擾動范數、攻擊類型和攻擊強度等角度對上述白盒對抗攻擊算法進行了比較,總結分析了不同算法的優勢及劣勢。其中,對抗攻擊類型分為單步迭代攻擊和多步迭代攻擊。單步迭代攻擊算法生成對抗樣本速度較快,而多步迭代攻擊算法的攻擊能力較強。對比分析的結果如表1 所示,其中在攻擊強度的對比結果中,*的數量代表攻擊強度。

表1 對抗攻擊算法總結Tab.1 Summary of adversarial attack algorithms
3 應用場景下的白盒對抗攻擊技術
對抗攻擊技術同時給部署在大部分應用場景下的深度學習系統帶來了安全威脅,諸多研究[9-11,46]已表明這類系統面臨的被對抗攻擊技術誤導的風險。與在第2 章中介紹的白盒對抗攻擊技術可以直接向深度學習模型輸入對抗樣本不同,真實的應用場景下并不能直接操作深度學習系統的輸入。本章介紹幾類發生在不同應用場景下的白盒對抗攻擊,通過不同應用場景的白盒對抗攻擊說明針對當前部署的深度學習系統的對抗照片攻擊和對抗貼紙攻擊技術。
3.1 針對移動終端應用的攻擊
隨著深度學習技術的發展,越來越多的人工智能技術應用在諸如手機、平板電腦等智能化的移動終端設備上,而這類部署在移動終端設備上的深度學習系統也面臨著被對抗攻擊技術攻擊的風險。Kurakin 等[25]對部署在手機上的圖像分類應用進行了攻擊測試,首次展示了對抗攻擊技術給移動終端設備上部署的深度學習系統帶來的危害。
Kurakin[47]攻擊的目標模型是一個手機圖像分類應用,該應用基于Inception 分類模型[48]構建,可對手機相機拍攝得到的照片進行分類。Kurakin 利用FGSM[14]和I-FGSM 攻擊算法[25]分別針對Inception 分類模型[48]生成對抗樣本后,把得到的對抗樣本打印為照片,這種照片被稱為對抗照片。最后,使用手機相機拍攝輸入對抗照片后實現對手機圖像分類應用的攻擊。Kurakin 的攻擊使圖像分類應用誤分類了大部分拍攝得到的對抗照片,但Kurakin 在利用手機相機拍攝對抗照片時,采取了固定相機的拍攝距離、角度和光線等措施。在現實的攻擊場景中,并不能完全具備這些條件,但Kurakin團隊的工作首次驗證了針對真實應用場景下深度學習系統進行對抗攻擊來干擾其正常工作的可行性,提供了一種在該場景下對抗攻擊的思路。
3.2 針對人臉識別系統的攻擊
人臉識別系統是目前深度學習技術在現實生活中較為成功的應用,其廣泛地部署在安檢、考勤、支付等諸多身份核驗場景。Sharif 等[10]針對部署在真實場景下的人臉識別系統進行了對抗攻擊測試,并提出一種對抗貼紙的攻擊方式。針對人臉識別系統,在Kurakin 等[25]的工作基礎上,鑒于無法直接對輸入圖像像素進行修改的限制,使用攻擊算法生成對抗擾動后,通過將擾動打印在貼紙上,最后將貼紙張貼在眼鏡框區域來達到對抗攻擊的目的,如圖5 所示。

圖5 對抗眼鏡Fig.5 Adversarial glasses
人臉識別系統本質上是一個多分類的深度學習模型,針對人臉識別系統的目標攻擊,其對抗樣本生成可描述為如下的優化問題:

其中:r表示要生成的對抗擾動,l表示要攻擊的類別,X表示攻擊者的人臉數據集。為了使得生成的擾動更加“平滑”和“自然”,保證攻擊的隱蔽性。使用全變差約束方法對r進行約束,全變差約束函數的定義如下:
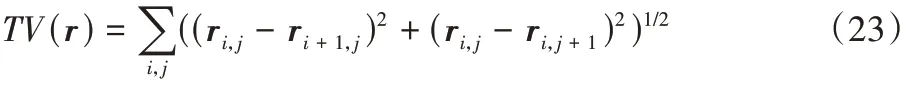
針對Kurakin 等[25]在將對抗樣本打印為“對抗照片”時,未考慮到打印設備帶來的數字圖像與打印輸出之間的色域誤差。Sharif 等[10]定義了色域誤差值來明確這種誤差,NPS(Non-Printability Score)值的定義如下:

其中:p表示打印機能打印出來的顏色值,p表示為數字圖像中的顏色值。
綜合考慮對抗貼紙的隱蔽性和打印設備帶來的打印誤差,最終針對人臉識別系統的對抗貼紙生成的優化問題描述為:

通過常見的優化算法,求解上述優化問題,即可得到對抗貼紙。Sharif 等[10]利用梯度下降法求解得到的“對抗眼鏡”使得人臉識別系統以高置信度將攻擊者誤識別為攻擊目標人,達到了攻擊目的。
Sharif等[10]針對人臉識別系統的攻擊,較為全面地考慮到了打印設備帶來的打印誤差,其生成的“對抗貼紙”較Kurakin等[25]生成的“對抗照片”的對抗魯棒性有了一定提升,但該攻擊方式依然缺乏在復雜物理因素影響下的攻擊能力。
3.3 針對自動駕駛系統的攻擊
近年來,依托于深度學習技術的自動駕駛系統取得了越來越大的進步。基于深度學習技術決策的自動駕駛系統已普遍搭載應用在無人駕駛車輛上,而對抗攻擊技術的發展也為這類自動駕駛系統的安全性帶來了嚴重的危害。Eykholt等[11]針對自動駕駛系統的交通標志識別功能進行了攻擊測試,展示了對抗攻擊技術給自動駕駛系統帶來的安全威脅。
由于大部分對抗攻擊算法在數字圖像空間中生成的對抗擾動由于打印設備[10]、相機輸入[11]等過程帶來的誤差無法有效針對應用場景下部署的深度學習系統進行攻擊。Eykholt 等[11]設計了一種針對復雜物理場景下的深度學習系統進行攻擊的RP2(Robust Physical Perturbations)算法。RP2攻擊算法[11]盡可能考慮到不同光照、視角、距離等物理因素的影響,采用類似數據增強的思路來生成在復雜物理因素影響下魯棒的對抗擾動。在針對運動中自動駕駛車輛的道路交通標志識別進行攻擊測試時,Eykholt 等利用相機拍攝要攻擊的“STOP”交通標志在各種光照、視角、距離條件下得到的圖像加入用于生成對抗擾動貼紙的數據集;同時,在定義擾動生成的目標優化函數時,引入Sharif 等[10]定義的NPS 誤差,以此減少打印設備帶來的誤差;最后采用Sharif 等[10]貼紙攻擊的方法,將生成的對抗擾動打印后張貼在要攻擊的道路交通標志上,以此達到自動駕駛系統無法識別正確該標志的目的,如圖6 所示。

圖6 “STOP”交通標志Fig.6 “STOP”traffic sign
Sharif 等[11]提出的RP2 攻擊算法進一步提高了復雜應用場景下對抗擾動的攻擊能力和對抗魯棒性。利用RP2 攻擊算法結合對抗貼紙進行攻擊的手段是目前針對應用場景下深度學習系統的主要對抗攻擊技術。
4 對抗攻擊實驗
選擇第2 章中所介紹的算法分別進行以下兩組實驗:1)基于CIFAR10 數據集[49],介紹了不同種類的攻擊算法對目標模型分類準確率的影響程度;2)基于MNIST 數據集[44],介紹了基于梯度優化的攻擊算法在不同擾動強度設置下對目標模型分類準確率的影響和其生成的對抗樣本的擾動差異程度。實驗中用到的MNIST 數據集[43]包含6 萬張訓練圖像和1 萬張測試圖像,每張圖像為28×28 像素的灰度圖像;CIFAR10 數據集包含5 萬張訓練圖像和1 萬張驗證圖像,每張圖像為32×32 像素的RGB 圖像。
4.1 不同種類算法攻擊模型的分類準確率對比
在介紹的4 種不同類型的攻擊算法中,分別選擇C&W[13]、PGD[26]、DeepFool[33]和UAN[18]算法在CIFAR10 數據集上進行攻擊實驗。實驗中,攻擊算法的擾動范數值統一l∞范數值。攻擊的目標模型分別為CNN 模型、ResNet34 模型和VGG19 模型,訓練后的目標模型在驗證集上的分類準確率分別為81.97%、93.50%和92.03%。算法的攻擊能力以其生成的對抗樣本在目標模型上的分類準確率表示,分類準確率越低,則說明該算法的攻擊能力越強。實驗結果如表2所示,從結果中可以看到PGD 算法的攻擊能力較強,而ResNet34 模型相比CNN 模型和VGG19 模型更容易被對抗樣本攻擊。
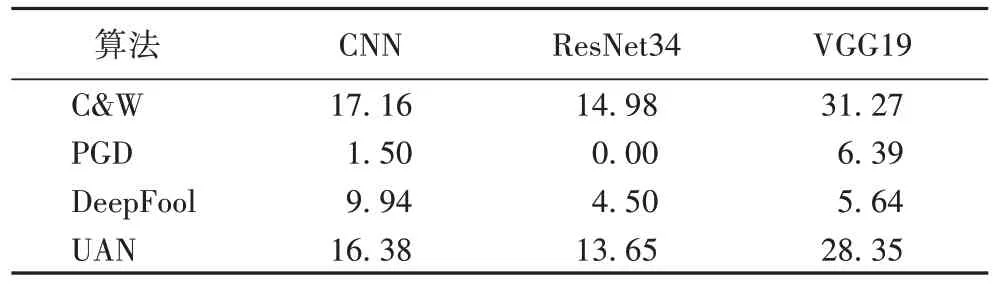
表2 CIFAR10驗證集上的對抗樣本分類準確率 單位:%Tab.2 Accuracy of adversarial examples classification on CIFAR10 validation set unit:%
4.2 基于梯度優化算法攻擊模型的擾動強度對比
選擇基于梯度優化的FGSM[14]、I-FGSM[25]、PGD[26]和MI-FGSM[27]算法在MNIST 數據集上進行攻擊實驗。實驗中,攻擊算法的擾動范數設置為l∞范數,eps表示擾動強度。Goodfellow 等[14]中將eps值設置為0.07 以保證攻擊成功率的同時限制擾動的大小。在實驗中,為了比較不同擾動強度對模型分類準確率的影響程度,本文將eps值分別設置為0.05、0.1、0.2 和0.3 進行實驗。攻擊的目標模型為CNN 模型,訓練后的該模型在驗證集上可以達到99.04%的分類準確率。實驗結果如表3 所示,可以看到隨著擾動強度值(eps)的不斷增大,攻擊算法的攻擊能力不斷提高,生成的對抗樣本能夠被正確分類的可能性越小。4 種攻擊算法在eps值設置為0.3 的情況下生成的對抗樣本如圖7 所示,圖中的每張字圖表示一個原始輸入樣本或其對應的對抗樣本。

表3 MNIST驗證集上的對抗樣本分類準確率 單位:%Tab.3 Accuracy of adversarial examples classification on MNIST validation set unit:%

圖7 MNIST數據集上的對抗樣本(eps=0.3)Fig.7 Adversarial examples on MNIST dataset(eps=0.3)
5 結語
隨著互聯網技術的不斷發展以及人工智能理論研究、相關方法的推廣應用,有關對抗樣本生成的方法將會層出不窮。研究對抗攻擊技術,不但能促進深度學習模型可解釋性研究的發展,進一步使對抗攻擊防御技術得到完善,而且還可以利用對抗攻擊技術促進一些相關領域的研究。目前,圖像分類任務中針對白盒對抗攻擊技術的研究已經取得了顯著的成果。本文以圖像分類任務作為切入點,對白盒對抗攻擊技術進行了全面的回顧和研究。主要研究分析了當前白盒對抗攻擊的幾類方法,同時結合實際的應用場景,介紹了對抗攻擊方法給深度學習模型帶來的巨大影響和安全威脅。
本文通過對所調研的文獻進行研究,按照對抗攻擊算法生成對抗樣本原理的不同,將主要的對抗攻擊算法分為4類,按照分類對算法進行了全面的分析和闡述。其中,基于直接優化的算法生成的擾動較小,但存在尋找合適超參數耗時較長的問題;基于梯度優化的算法是目前對抗攻擊算法中主要的一類算法,該類算法大多通過多步迭代計算梯度生成高質量對抗樣本,其特點是針對無防御措施的模型攻擊能力較強;基于決策邊界分析的算法通過精確計算得到的擾動更小,但不具備目標攻擊的能力;基于神經網絡生成的算法是一種特殊的對抗攻擊技術,這類算法通過訓練一個生成模型來生成對抗樣本,一旦生成模型訓練完成,在對抗樣本生成階段可非常高效地生成大量對抗樣本。
未來,隨著對抗攻擊技術在自然語言處理[50-51]、語音識別[52-53]等任務上的推廣應用,人工智能系統將面臨更加嚴峻的安全挑戰。為實現真正安全的深度學習應用,對抗攻擊技術的研究將會受到長期的重視。其中的白盒對抗攻擊技術依然會是重要的研究課題之一,其研究目標將朝著生成高隱蔽性、高魯棒性和高遷移攻擊能力的對抗樣本進行;同時,白盒對抗技術在其他類型的任務中進行推廣應用也將是一個可能的發展方向,而與之相對應的,針對黑盒對抗攻擊技術的研究也頗受關注。面對黑盒對抗攻擊技術給深度學習系統帶來的危害,也將在接下來的研究中予以持續的關注。
猜你喜歡
房地產導刊(2022年5期)2022-06-01 06:20:14
建材發展導向(2021年12期)2021-07-22 08:06:48
建材發展導向(2021年7期)2021-07-16 07:07:52
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:48
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
