基于知識庫實體增強BERT模型的中文命名實體識別
2022-09-25 08:42:14胡燕劉夢赤張龑
計算機應用 2022年9期
關鍵詞:模型
胡 婕,胡燕,劉夢赤,張龑
(1.湖北大學計算機與信息工程學院,武漢 430062;2.華南師范大學計算機學院,廣州 510631)
0 引言
命名實體識別(Named Entity Recognition,NER)在自然語言處理(Natural Language Processing,NLP)的許多下游任務如知識庫構建[1]、信息檢索[2]以及問答系統[3]中扮演著重要角色。NER 任務主要方法有3 種:基于規則、基于傳統機器學習和基于深度學習的方法。其中基于深度學習的方法與基于規則和基于統計學的方法相比無需人工設置特征,神經網絡可以自動從數據中學習特征,被廣泛地應用于命名實體識別的任務中[4-6]。
NER 任務實質上是序列標注問題[7]。中文命名實體識別任務與英文有所不同,英文句子中有天然的邊界,而中文句子沒有,這給中文命名實體識別帶來了更多挑戰。中文NER 任務在進行單詞序列標注之前,一般要先進行分詞然后再將詞級別的序列標注模型應用于所分割的句子,命名實體邊界也就是詞的邊界;然而,分詞不可避免地會出現單詞的錯誤劃分從而造成實體邊界的錯誤識別。為了解決分詞錯誤對命名實體識別任務的影響,Li 等[8]認為基于字符的方法沒有中文分詞錯誤,比基于詞的方法更適用于中文NER 任務;然而,基于字符的NER 任務并不能充分利用詞和詞的序列信息。為了解決這個問題,Zhang 等[9]提出了格結構的長短期記憶網絡(Lattice Long Short-Term Memory network,Lattice-LSTM)模型,將詞典納入基于字符的模型。此外,當字符與詞典中的多個單詞匹配時,保留所有與字符匹配的單詞,而不是啟發式地為字符選擇一個單詞,讓后續的NER 模型來確定應用哪個單詞。通過使用Lattice-LSTM 來表示句子中的詞匯,將潛在的單詞信息整合到基于字符的LSTMCRF(Long Short-Term Memory network-Conditional Random Field)中,但是Lattice-LSTM 的模型架構相當復雜。為了引入詞典信息,Lattice-LSTM 在輸入序列中不相鄰的字符之間添加了多個額外的邊,顯著降低了其訓練和推理速度,而且很難將網格模型的結構應用到其他神經網絡結構,只適合于某些特定的任務,不具通用性。于是Ma 等[10]提出更簡單的方法來實現Lattice-LSTM 的思想,將每個字符的所有匹配單詞合并到基于字符的NER 模型中,在字符中表示編碼詞典信息,并設計編碼方案以盡可能多地保留詞典匹配結果。這種方法不需要復雜的模型結構,更容易實現,并且可以通過調整字符表示層快速適應任何合適的神經NER 模型。然而由于網格結構的復雜性和動態性,現有基于網格的模型很難充分利用圖形處理器進行并行計算,因而推理的速度通常較慢。因此,Li 等[11]提出了平面點陣變換器,核心是將點陣結構轉換成一組跨度,并引入特定的位置編碼,在性能和效率上優于其他基于詞典的模型;Xue 等[12]和Gui 等[13-14]利用詞匯特征,外部詞匯級信息增強了NER 訓練。
然而,上述方法都是有監督的模型,當處理有較少標記數據的數據集時,小數據無法反映出語言間的復雜關系,同樣也很容易讓復雜的深度網絡模型過擬合,很難獲得很好的訓練網絡,因此預先訓練的半監督語言模型就顯得尤為重要。Devlin 等[15]提出的BERT(Bidirectional Encoder Representations from Transformers)模型就是一個預訓練半監督模型,可以在與最終任務無關的大數據集上訓練出語言的表示,然后將學到的知識表示用到任務相關的語言表示上。Sun 等[16]提出了ERNIE(Enhanced Language Representation with Informative Entities)模型,它通過知識整合來增強BERT。ERNIE 通過屏蔽完整實體來訓練,而不像BERT 那樣屏蔽單個字詞標記。ERNIE 預訓練的實體級掩碼技巧可以看作是一種通過錯誤反向傳播來集成實體信息的隱式方法。由于命名實體識別中的實體可能出現二義性,即相同的詞在不同的領域有不同的語義,因此包含領域的實體詞典對于該任務是有用的。考慮到這一點,Jia 等[17]提出了將詞典嵌入到針對中文NER 的預先訓練最小均方誤差模型中,提出了一種半監督實體增強的最小均方誤差預訓練模型Entity Enhanced BERT Pre-training。具體來說,首先使用新詞發現方法從原始文本以及相關文檔中提取實體詞典;然后使用Char-Entity-Self-Attention 機制替換原始的自我注意力機制將實體信息嵌入到BERT 中,也就是使用字符和實體表示組合來增強自我關注。該機制可以更好地捕捉字符和文檔特定實體的上下文相似性,并將字符隱藏狀態與每一層中的實體嵌入顯示結合;但是提取實體詞典的方式較為復雜而且獲取的實體詞數量和使用范圍有限。如今,開放域和領域知識庫構建越來越完善,可免費獲得的知識庫也越來越多,因此本文提出了在詞典中加入知識庫信息的方法來擴展詞典中的實體信息,使詞典中的詞使用更具廣泛性。具體來說,首先在中文通用百科知識圖譜CN-DBpedia[18]中下載其提供的mention2entity 文檔,該文檔中包含了110 多萬條數據,這些數據中包含了大量的實體,使用Jieba 分詞對數據進行分詞處理,留下帶有名詞標簽的詞,使得詞典中的實體詞更豐富、應用領域更廣泛;而且由于各個領域的實體詞典可以從其領域知識庫中獲得,可以減少前期詞典創建的工作量。隨后將詞典中的實體嵌入到BERT 預訓模型中進行預訓練,然后在NER 微調任務中將訓練得到的詞向量輸入到BiLSTM 中提取特征,最后通過CRF 層從訓練數據中獲得約束性規則,為最后預測的標簽添加約束來保證預測標簽的合法性,生成最優序列結果。實驗結果表明本文模型在CLUENER 2020 數據集[19]上的F1 值達到了78.15%,在MSRA 數據集[20]上的F1的值達到了88.11%,相比上述Entity Enhanced BERT Pretraining 模型以及其他三個基線模型BERT+BiLSTM(Bidirectional Long Short-Term Memory)、ERNIE 和BiLSTM+CRF都有所提升,從而驗證了加入知識庫之后的詞典結構在中文NER 語言模型預訓練中整合實體信息的有效性,以及在實體識別的微調任務中加入CRF 層預測標簽的有效性。
1 本文方法
本文的命名實體識別方法主要分為3 個部分:首先從中文通用百科知識庫CN-DBPedia 中抽取實體來構建實體詞典;然后將詞典中的實體嵌入到BERT 中進行預訓練,將訓練得到的詞向量輸入到BiLSTM 提取特征;最后經過條件隨機場修正后輸出。
1.1 詞典的構建
為了獲得特定文檔的實體信息,將其嵌入到BERT 預訓練語言模型中,Jia 等[17]采用Bouma[21]所提出的無監督方法在原始文檔中自動發現候選實體,分別計算連續字符之間的交互信息值和左、右熵度量值,然后將這3 個值相加作為可能實體的有效評分。
本文在此基礎上加入開放域知識庫中所提供的實體來對原有的詞典進行擴充,將實體詞典擴充成一個大小為6 086 KB 的實體詞典。本文使用的知識庫是由復旦大學知識工場實驗室研發并維護的大規模通用百科知識圖譜知識庫CN-DBpedia,其數據來源于中文百科類網站如百度百科、互動百科、中文維基百科等的純文本頁面中提取的信息,經過過濾、融合、推斷等處理后,最終形成的高質量結構化數據。本文使用CN-DBPedia 所提供mention2entity 文檔中的數據,其包含110 多萬條信息,包含了大量的實體,所包含的領域非常廣泛,獲取的途徑也很方便。本文的具體做法,從OpenKG.CN 網站下載mention2entity 中的文本后對數據進行清洗,清洗的過程是用可以標注詞性的Jieba 分詞工具對文本進行全模式分詞,將標注為名詞詞性的詞挑選出來,去掉重復的詞語,將剩余的詞加入詞典中作為候選實體。
1.2 嵌入詞典實體信息的BERT預訓練
嵌入實體信息的BERT 預訓練模型結構如圖1 所示,與基于中文BERT[15]的Transformer 模型中Encoder 結構類似,為了利用提取的實體,即將實體信息嵌入到模型中,將Transformer 擴展為Char-Entity-Transformer,如圖2所示它是由一個多頭的Char-Entity-Self-Attention 塊堆棧組成。
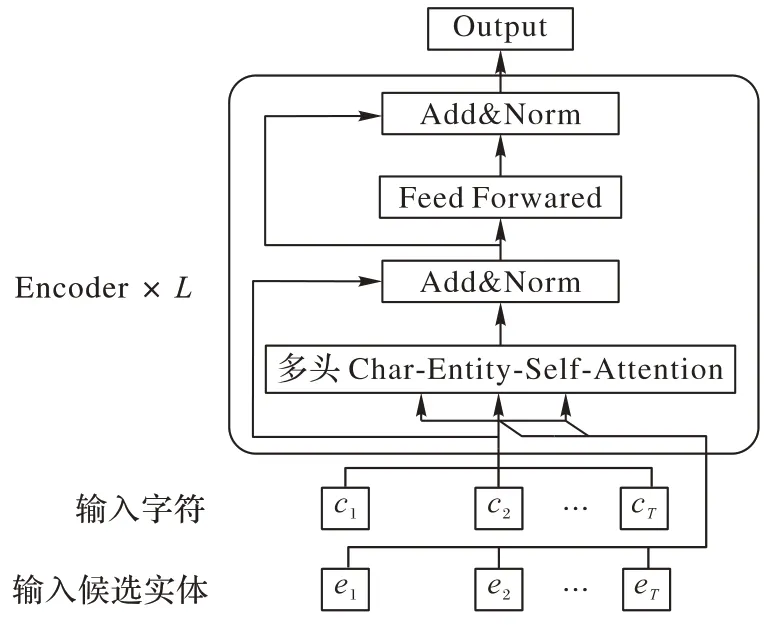
圖1 嵌入實體信息的BERT預訓練模型結構Fig.1 Structure of BERT model embedding entity information

圖2 Char-Entity-Self-Attention模型結構Fig.2 Structure of Char-Entity-Self-Attention model
首先將字符與提取的實體進行匹配,給定字符序列c={c1,c2,…,cT}和提取的實體字典Entity,使用最大實體匹配算法得到對應的實體標記序列e={e1,e2,…,eT}。用包含該字符詞典中最長實體的索引來標記每個字符,并將沒有實體匹配的字符標記為O。
在模型的輸入階段,給定一個字符序列c={c1,c2,…,cT},輸入層中的第t個字符的表示是字符、文本和位置嵌入的總和,表示為:

其中:Ec、Es、Ep分別表示字符的字嵌入查找表、文本嵌入查找表和位置查找表,因為沒有用到下一句預測任務的輸入句子順序,所以將文本索引s設置為常數0。
接下來將給定字符序列和前面所得到的實體標記序列一起輸入到如圖2 所示的多頭Char-Entity-Self-Attention 模型,將漢字的隱含維數和新詞實體的隱含維數分別表示為Hc和He,L是層數,A是自注意力頭的個數。對于給定l-1 層字符的隱藏序列的Key 矩陣和Value 矩陣與BERT 的多頭注意力有所不同,它用實體的隱藏字符和實體嵌入組合來生成Key 和Value 矩陣,表示為:

1.3 NER任務
本文NER 任務模型框架如圖3 所示。
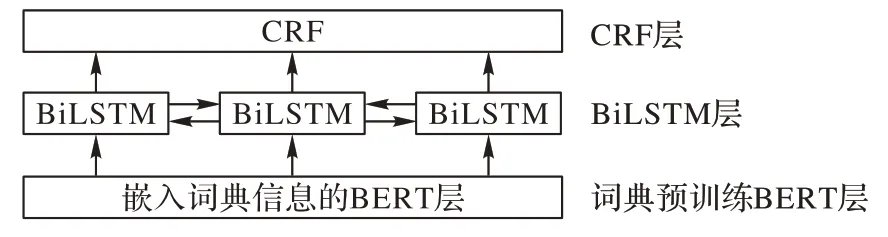
圖3 NER任務模型框架Fig.3 Model framework of NER task
將文本信息轉化為計算機可以識別的數據形式是任務的第一步。目前常用的詞嵌入模型主要是BERT 預訓練語言模型,它通過雙向Transformer 編碼器生成字向量,但是實體識別的任務是識別人名、地名等實體信息,BERT 模型無法利用現有的實體信息。本文使用如1.2 節所述的嵌入實體信息的BERT 預訓練模型,其Char-Entity-Self-Attention 機制可以很好地捕捉字符和文檔特定實體的上下文相似性,并顯式地將字符隱藏狀態與每一層實體嵌入結合,再將擴展后的模型對數據集信息進行編碼。將嵌入詞典實體預訓練BERT模型的最后一層輸出輸入到BiLSTM 中進行訓練,進一步提取文本特征。通過BiLSTM 對序列的上下文信息進行學習,為每個標簽打分,BiLSTM 的輸出為字符的每一個標簽分值,輸出結果如圖4 所示。
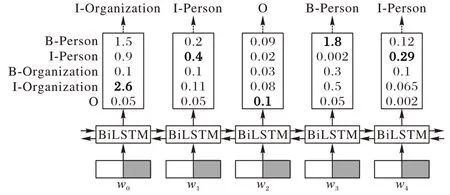
圖4 BiLSTM 輸出標簽Fig.4 BiLSTM output label
BiLSTM 通過挑選每個標簽分值最高的作為該字符的標簽,并選取最大分值作為每個字符最終的輸出標簽。如圖4所示,模型所生成的標簽為I-Organization I-Person 和B-Person I-Person,但是顯然I-Organization 之后不可能出現I-Person,即:標簽序列“I-Organization I-Person”是錯誤的。這種取最大值的方法雖然可以得到正確的標簽序列B-Person I-Person,但是并不能保證每次的預測都是正確的,因此模型不能僅以BiLSTM 的輸出結果作為最終的預測標簽,需要在預測標簽與標簽之間引入約束條件來保證生成標簽的合法性,因此本文將BiLSTM 的輸出結果輸入到CRF 層。CRF 層可以為最后預測標簽添加約束關系來保證預測標簽的合理性。
給定輸入序列X={x1,x2,…,xn},假設訓練得到對應輸出標簽序列Y={y1,y2,…,yn},其中n代表NER 標簽的數量,則標簽序列的得分可表示為:
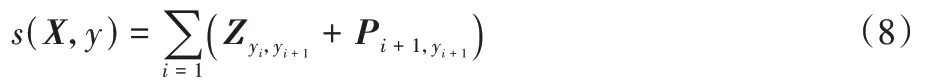
其中:Z為轉移矩陣為標簽從yi轉移到yi+1的分值;為輸入序列第i+1 個字對應標簽yi+1的分值。對標簽序列y的概率進行計算,可表示為:
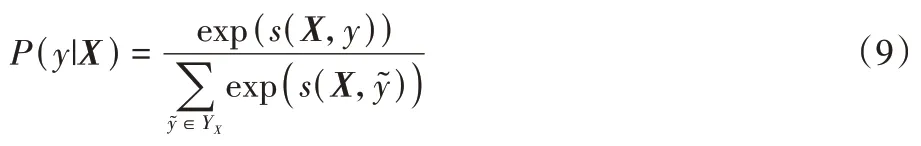
其中YX為所有可能的標簽序列集合,最終輸出序列的標簽為概率最大的標簽集合。
2 實驗結果與分析
2.1 數據集與評價指標
2.1.1 數據集
為了驗證本文模型的有效性,在兩個公開使用的數據集CLUENER 2020 和MSRA 上做了對比實驗。
CLUENER 2020 數據集[19]是一個細粒度的中文NER 數據集,包含10 種不同的實體類別,分別是組織(organization)、人 名(name)、地 址(address)、公 司(company)、政 府(government)、書籍(book)、游戲(game)、電影(movie)、職位(position)和景點(scene),并對常見類別進行了細粒度的劃分,如將“組織”細分為“政府”和“公司”等;同時存在同一實體在不同語境下屬于不同類別的情況,如Twins 的字面意思是雙胞胎,但是在娛樂新聞的背景下,它指的是Twins 組合。本文從CLUENER 2020 數據集中隨機抽取5 200、600 和748個句子分別作為訓練集、評估集和測試集,并將抽取的句子劃分為4 個新聞領域:GAM(游戲)、ENT(娛樂)、LOT(彩票)和FIN(金融)。
MSRA[20]是中文NER 的通用數據集。它包括三種類型的實體,分別是PER(人名)、LOC(地名)和ORG(組織名)。本文使用標記集{B,I,E,O}進行標記。
數據集的詳細信息如表1 所示。
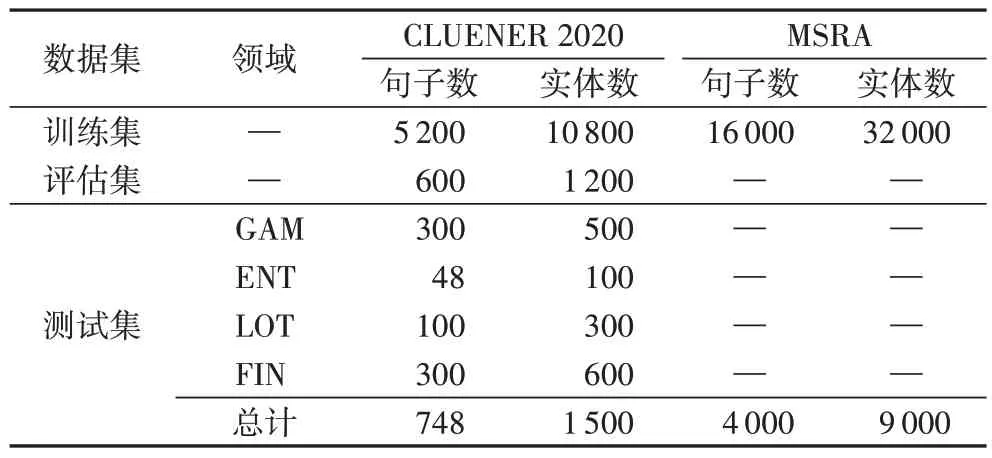
表1 數據集描述Tab.1 Description of datasets
2.1.2 評估標準
本文采用準確率(Precision,P)、召回率(Recall,R)和F1的值作為評價指標,這三種評價指標越高,代表模型性能越好。評價指標的計算公式如下:

2.2 實驗環境
本文所有的實驗均在Python3.6,pytorch1.7,GTX 5000平臺上運行。
2.3 實驗設置
本文模型使用BERT 構建,層數L=12,自注意頭數A=12,字符的隱藏大小Hc=768,實體的隱藏大小He=64,其他超參數的設置如表2 所示。

表2 本文模型參數Tab.2 Parameters of the proposed model
2.4 實驗結果與分析
1)本模型與基線模型實驗對比。
本文對比的基線模型是Entity Enhanced BERT Pretraining[17]。它首先在與數據集相關的文檔中獲取詞,將其作為候選實體放入實體詞典中;然后將實體詞典信息嵌入到BERT 的預訓練中,并將預訓練模型用于NER 任務中進行實體的分類輸出。它在前期詞典的獲取過程中使用的方法并不能識別所提取詞是否是真正的實體,導致詞典中真正的命名實體比例降低,而加入了無關實體的詞進行預訓練會降低模型的性能。本文詞典的提取方法是使用開放域知識庫CN-DBpedia,其包含大量的實體三元組,用于提高抽取的候選實體中真正實體的比例。此外,基線模型在NER 任務中沒有利用CRF 層來對生成的標簽進行約束。
為了驗證本文模型的有效性,在同一實驗環境下,設計了兩組實驗與基線模型Entity Enhanced BERT Pre-training[17]在測試集上進行對比,在CLUENER 2020 數據集和MSRA 數據集上F1 值的對比如表3 所示。

表3 測試集上模型F1值的對比 單位:%Tab.3 Comparison of F1 scores of models on test sets unit:%
從表3 可知,與基線模型Entity Enhanced BERT Pretraining 相比,本文加入開放域知識庫的實體增強BERT 模型OpenKG+Entity Enhanced BERT Pre-training 在上述兩個數據集上F1 值都有一定的提升。從CLUENER 2020 數據集的所有類別(All)F1 的值可以看出,加入知識庫之后的模型F1 值提升了0.92 個百分點,在MSRA 數據集上F1 值提升了0.58個百分點,這是因為本文選取的開放域知識庫中mention2 entity 文檔包含110 多萬條信息,包含了各個領域的大量實體,本文從中提取了3 000 多條候選詞加入對應新聞領域詞典中。F1 值的提升可以驗證加入開放域知識庫的有效性。在此基礎上,本文使用OpenKG+Entity Enhanced BERT Pretraining+CRF 模型在NER 微調中加入CRF 層來修正標簽,從表中CLUENER 2020 數據集所有領域(All)的F1 可以看出,相比只加入開放域知識庫的模型OpenKG+Entity Enhanced BERT Pre-training 的F1 值提升了0.71 個百分點,在MSRA 數據集上F1 值提升了0.52 個百分點。相比基線Entity Enhanced BERT Pre-training 模型,在CLUENER 2020 數據集上F1 值提升了1.63 個百分點,在MRSA 數據集F1 值提升了1.10個百分點,驗證了NER 微調加入CRF 解碼層的有效性。
Entity Enhanced BERT Pre-training 模型與本文的兩組模型在CLUENER 2020 數據集的所有領域(All)和MSRA 數據集的測試集上準確率、召回率和F1 值的對比如表4 所示。
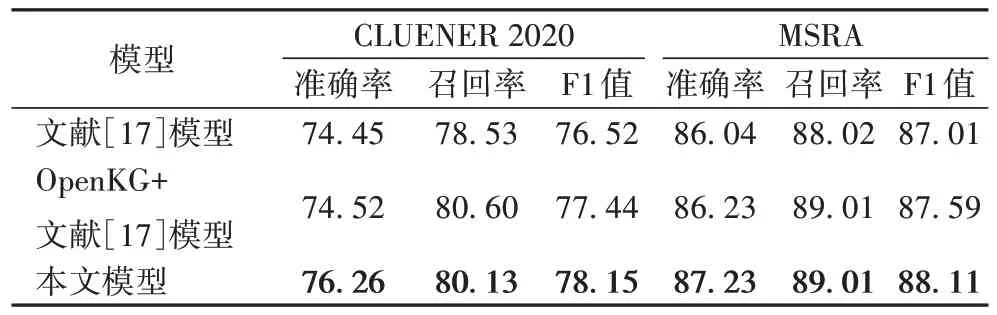
表4 測試集上的模型各評標指標對比 單位:%Tab.4 Comparison of evaluation indexes of models on test sets unit:%
從表4 中可以看出,在CLUENER 2020 和MSRA 這兩個公開的數據集上,本文模型在準確率、召回率和F1 值上均有提升,驗證了本文模型綜合效果更佳。
2)與相關工作對比。
為了進一步驗證本文模型的有效性,本文還對三組中文NER 方法在CLUENER 2020 數據集和MSRA 數據集上進行了比較。這三組模型分別為:BERT+BiLSTM、ERNIE[22]和BiLSTM+CRF模型。其中,ERNIE是百度公司基于BERT 模型進一步優化得到的模型,它在中文NLP 任務上獲得了最佳效果,其主要是在掩碼(mask)機制上做了改進,在預訓練階段不僅采取字掩碼機制,而且增加了外部知識進一步采取全詞掩碼和實體掩碼的三級掩碼機制。
三組模型與本文模型在CLUENER 2020 數據集的所有領域和MSRA 數據集F1 值對比如表5 所示。
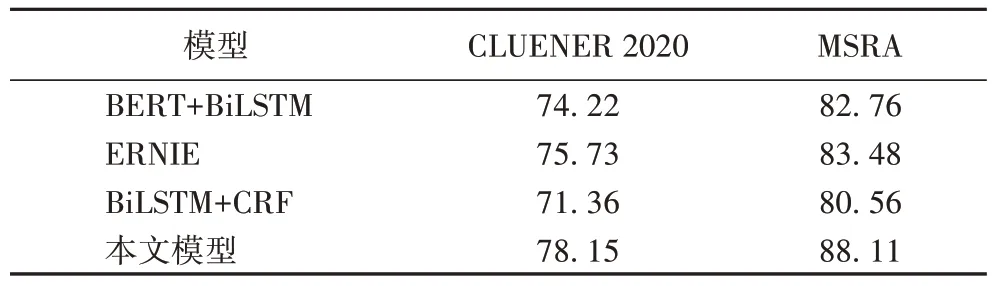
表5 相關模型F1值的對比 單位:%Tab.5 Comparison of F1 scores of related models unit:%
從表5 可以看出,相比直接對預先訓練的中文BERT 生成字向量與利用BiLSTM 方法解碼的模型,本文模型在CLUENER 2020 數據集上的F1 值提升了3.93 個百分點,在MSRA 數據集上的F1 值提升了5.35 個百分點,這是因為Char-Entity-Transformer 結構能夠有效地利用實體詞典信息,并且考慮到不同實體在不同語境下可能有不同的語義的情況,利用CRF 解碼層為最后預測的標簽添加約束關系來保證預測標簽的合法性,從而提高了F1 的值。與ERNIE 相比,盡管ERNIE 使用更多來自網絡資源的原始文本和實體信息進行預訓練,但是在CLUENER 2020 數據集上F1 值仍提升了2.42 個百分點,并且在MSRA 數據集上F1 的值提升了4.63個百分點,這表明了通過字符-實體轉換結構集成實體信息的顯式方法比實體級掩蔽方法對中文NER 更有效。與BiLSTM+CRF 模型相比,在CLUENER 2020 數據集上F1 的值提升了6.79 個百分點,在MSRA 數據集上F1 的值提升了7.55 個百分點,這是因為嵌入詞典實體的BERT 預訓練模型能夠將實體集成到具有字符實體轉換器的結構中,從而改善實體識別的效果。從各模型F1 值可以看出,本文模型的整體識別效果得到了明顯提升。
3 結語
針對實體增強預訓練模型的詞典獲得方法較為復雜而且獲取的實體詞數量和使用范圍有限的問題,本文充分利用了開放域知識庫資源,使得詞典的獲得更加便利,能夠包含更多相關領域的候選詞,從而提升了模型的效果。在NER任務中,由于只依賴BiLSTM 對標簽打分的輸出會導致出現大量不合法標簽,本文通過加入CRF 層的解碼得到最優序列,提高了實體提取的結果。實驗結果表明,利用加入知識庫的預訓練模型以及在NER 任務中加入CRF 解碼層的模型獲得了更高的F1 值,從而驗證了本文模型的有效性。未來的工作重點是簡化模型,以提升模型的訓練速度。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
