數字人文視域下SikuBERT增強的史籍實體識別研究*
2022-09-23 00:58:30劉江峰馮鈺童王東波胡昊天張逸勤
圖書館論壇 2022年10期
劉江峰,馮鈺童,王東波,胡昊天,張逸勤
0 引言
中華文明源遠流長,一本本典籍演繹著一幅幅絢麗的歷史畫卷。以人為鑒,可以明得失;以史為鑒,可以知興替。從漫長的歷史中獲取知識與經驗,是實現國家富強、民族復興、人民幸福的制勝法寶。近年傳統人文學科社科化、社會科學信息化的趨勢日益增強,數字人文(又稱人文計算)研究悄然興起,為傳統人文與社會科學研究提供了新的研究范式[1]。文本挖掘與可視化分析成為數字人文領域研究的重要技術,典籍文獻的深度挖掘和利用成為可能。從研究的精細程度來看,文獻信息處理主要分為詞匯級、句子級、篇章級。古文詞匯級研究主要包括自動分詞、詞性標注與命名實體識別[2]。其中,實體識別作為實體關系識別、知識圖譜構建以及其他研究的基石,其準確性和效率尤為重要。
隨著深度學習技術的發展,文學、地理、天文等領域均對命名實體識別進行廣泛研究。機器學習時代,CRF模型能夠融合上下文特征,被廣泛應用于常見實體的識別,但存在過分依賴標注數據集的缺點,對較少見的實體名稱,識別效果不夠理想。近年來,深度學習技術日益成熟,諸如LSTM、BERT模型及其變體在命名實體識別領域均有很多成功的應用。由于語法上的獨特性且與現代漢語、英語存在較大差異,漢語古文語料的分詞、詞性標注、命名實體識別難度較大。
2018 年Google 發布基于雙向Transformer編碼器表征的語言模型(BERT)。在BERT 模型中,一個已經過大量語料預訓練的預訓練模型能使模型的下游應用效率更高:只需一個額外的輸出層就可對已有的預訓練模型進行微調,并應用在各類領域任務中,無需根據特定任務對模型進行實質性修改。BERT發展了預訓練-微調的語言模型研究新范式。當前常用中文預訓練模型包括Google官方提供的BERT-Base-Chinese(以下簡稱“BERT-base”)、哈爾濱工業大學訊飛聯合實驗室提供的中文RoBERTa、北京理工大學提供的GuwenBERT等。其中,BERT-base和RoBERTa是基于中文維基百科的包含簡體與繁體中文的預訓練模型,GuwenBERT是基于殆知閣古漢語語料的簡體中文預訓練模型。相較于殆知閣古漢語語料,中文維基百科在語法上與典籍文獻有較大差異;而GuwenBERT卻是完全采用簡體中文古文文獻的預訓練模型。可以預見,在繁體中文的典籍文獻命名實體識別中,上述3個預訓練模型皆有其各自的優缺點。
《四庫全書》是我國古代最大的文化工程,完整呈現了我國古典文化的知識體系。近日由南京農業大學信息管理學院牽頭、南京師范大學文學院參與,使用《四庫全書》繁體版本語料分別在BERT-base和Chinese-RoBERTa-wwmext(以下簡稱“RoBERTa”)上進行繼續訓練的SikuBERT、SikuRoBERTa發布。該研究在基于《左傳》語料的自動分詞、詞性標注、斷句、命名實體識別等下游任務上作了簡要驗證,效果較上述3 個預訓練模型均有不同幅度的提升。因此,本文嘗試利用BERT-base、RoBERTa、GuwenBERT、 SikuBERT、 SikuRoBERTa 等BERT預訓練模型,以《左傳》《史記》《漢書》《后漢書》《三國志》等為實驗語料,對人名、地名、時間詞等3種歷史事件的主要構成實體進行識別,進一步探究SikuBERT、SikuRoBERTa在不同典籍、不同規模、不同語體風格語料上的泛化能力并作可能的改進嘗試。
1 研究回顧
1.1 數字人文視域下的古籍智能信息處理
數字人文(Digital Humanities)[3]為傳統人文學科提供了新的研究方法,著眼于數字化文本計算,如“數字敦煌”項目[4]、青州龍興寺遺址出土佛像保護項目[5]以及其他古籍修復[6]項目。近年隨著各類資源數字化規模的擴大和機器學習、大數據等計算機技術的飛速發展,數字人文研究模式轉變為采用數據密集型計算來服務人文學科領域[7]。在20世紀末期,我國古籍數字化研究就已取得一定成果,如1999年史睿[8]提出古籍數字化構建方案。21世紀初以來,我國逐步構建了大批古籍數據庫[9],古籍數字化技術[10](如數字化輸入技術、OCR光學識別技術、字處理技術、智能化處理技術)得到很大發展。近年文本挖掘技術的進步推進了古籍信息智能處理研究的不斷發展,自然語言處理技術為更加方便地處理、利用古文文本知識提供了理論、方法和應用思路。其中,古文自動斷句、古文詞匯處理(分詞、詞性標注、命名實體識別等)是古籍智能處理的關鍵方向。
(1)古文自動斷句。古文斷句是根據古代漢語句子的組合原則,結合現代漢語的句讀集合,通過自動和智能化的策略完成對古代漢語自動添加句讀的功能,進而實現對古代漢語句子的斷句[11]。目前古文自動斷句技術主要分為兩類。一是基于規則庫的方法,主要由人工制定斷句規則來進行匹配,如黃建年[12]構建了農業古籍的斷句標點規則庫,并設計出農業古籍斷句標點的原型系統。再如,陳天瑩等[13]提出了基于上下文的N-gram模型,用于古文斷句。但這種方法由于規則的泛化能力較差、難以覆蓋全面等原因,越來越不被學者使用。二是基于機器學習或深度學習的方法。一些學者[14-15]提出了層疊條件隨機場模型,這一策略的性能比基于規則匹配的方法效果更優,更加適用于古文斷句。王博立等[16]提出一種基于循環神經網絡的古文斷句方法,在大規模語料上訓練后能獲得比傳統機器學習更高的準確率。俞敬松等[17]使用BERT+微調模型對《道藏》文本進行斷句,模型的效果優于BiLSTM+CRF模型并擁有較好的泛化性。這類深度學習方法是目前主流的自動斷句方法,擁有較大的研究空間和研究價值。
(2)古文詞匯智能處理。古文詞匯處理是指通過計算機算法,對數字化處理后的古代典籍文獻進行自動分詞、詞性標注、命名實體識別等操作,從而開展詞匯層面的知識挖掘[18]。由于漢語中詞與詞之間沒有分隔,需要對句子進行詞匯切分。自動分詞技術可以使分詞更為高效、準確,同時也是進行詞性標注、命名實體識別的基礎。基于機器學習的自動分詞方法是目前的主流分詞方法。比如,梁社會等[19]利用條件隨機場模型和注疏文獻對《孟子》進行自動分詞;魏一[20]使用殆知閣古漢語語料進行BERT 模型訓練,使用《左傳》數據集進行模型測試,獲得了泛化能力和穩定性較好的分詞模型。
古文的詞性標注是在分詞的基礎上,按照一定的規則為詞語標注對應的詞性,以進一步增強詞匯的特征。目前詞匯標注主要通過機器學習展開,有分詞和詞性標注分別進行和分詞與詞性標注一體化兩種方式。例如,王東波等[21]使用條件隨機場模型,并結合統計方法確定組合特征模板,得到具有較強推廣性的先秦典籍詞性自動標注模型。石民等[22]使用條件隨機場模型對《左傳》文本進行分詞標注一體化實驗,證明一體化方法可以提高分詞和詞性標注的精度。留金騰等[23]在上古漢語分詞和詞性標注的過程中,采用自動標引和人工校正相結合的方式,使用條件隨機場模型并嘗試調整特征模板進行分詞和詞性標注,有效提高了模型準確性,減少了后續人工校正的工作量。
命名實體識別是古文詞匯處理過程中的關鍵環節,也是本文的研究內容。如皇甫晶等[24]以《三國志·蜀書》為實驗文本,驗證了基于規則匹配的方式進行實體命名識別的可行性;朱鎖玲等[25]以《方志物產》為語料,采用規則匹配和統計學習相結合的方式,實現了物產地名的自動識別。諸多學者[18,26]在進行古籍命名實體識別研究時,使用隱馬爾科夫模型(HMM)、最大熵模型(ME)、支持向量機(SVM)、條件隨機場模型(CRF)等統計機器學習模型。近年隨著深度學習技術的不斷深入發展,各類深度學習模型被應用于各類命名實體識別任務。命名實體識別既是古文信息提取的重要任務,也是文本結構化的基本步驟。
1.2 命名實體識別
以命名實體識別(Named Entity Recognition,NER)為代表的信息抽取技術研究,最早開始于20 世紀60 年代。MUC-6(Sixth Message Understanding Conference)會議提出,命名實體識別研究為信息抽取效果評測的重要指標之一[27]。按其歷史發展進程,命名實體識別研究主要分為基于規則和詞典匹配的命名實體識別、基于統計機器學習的命名實體識別、基于深度學習的命名實體識別等3類。早期的命名實體識別主要采用基于規則的方法,通過分析實體的特點及其在語言文本中的特征,構建一定數目的規則,從文本中匹配符合這些規則的實體。這些規則往往需要眾多領域專家耗費較長時間來構造,且可移植性差。隨著領域知識的發展,規則還需要不斷更新。如今,這類方法在特殊語種(如阿拉伯語[28])的命名實體識別上尚有一定應用。
(1)基于機器學習的命名實體識別。20 世紀90 年代,基于統計機器學習的命名實體識別研究逐漸興起。隱馬爾可夫模型(Hidden Markov Models,HMM)、最大熵模型(Maximum Entropy Models,MEM)、支持向量機(Support Vector Machines,SVM)、條件隨機場(Conditional Random Field,CRF)等統計機器學習模型成為該時期改進NER研究的重點。1999年Bikel等[29]使用HMM對日期、時間等實體進行識別,在英語、西班牙語的語料測試中取得較好的結果。Borthwick等[30]將MEM與其他基于規則的查找工具結合,提出一個最大熵命名實體(MENE)系統。Lee等[31]提出基于SVM的兩階段命名實體識別器,使用生物醫學領域的GENIA語料進行測試,有效解決了語義分類的多類問題。Song等[32]使用CRF模型對生物醫學語料進行命名實體識別,獲得具有競爭力的系統POSBIOTM-NER。基于統計機器學習的NER研究,主要思路是將實體識別問題轉換為序列標注問題。HMM的輸出獨立性假設使其無法考慮上下文特征,MEM彌補了這一缺陷,但其在每個結點都要進行歸一化處理,只能獲得局部最優解。而CRF模型不僅考慮上下文特征,還實行全局歸一化,能得到全局最優值,較HMM、MEM等效果更優。因此,在眾多機器學習模型中,CRF模型更受到學者的關注。
在CRF的模型訓練方面,McCallum[33]提出一種自動歸納特征的方法,可以提升準確性、顯著減少參數計數,并提高模型在命名實體識別實驗中的性能。Cohn等[34]提出一種利用糾錯輸出碼(ECOC)訓練CRF模型的方法,發現糾錯CRF訓練消耗的資源更少,能有效縮短實體識別時間。在中文命名實體識別方面,向曉雯[35]以CRF為基本框架,采用層疊結構構建了適用于人名、地名的命名實體識別系統。何炎祥等[36]使用CRF模型進行地名識別,并加入規則庫對實體進行召回,研究表明,設計合適的規則可以提升識別效率。郭劍毅等[37]提出一種旅游領域命名實體識別方法,能實現嵌套景點、特產風味等實體的識別,此實證研究表明,采用層疊CRF模型,比HMM和單層CRF模型的性能有所提高。CRF模型擁有靈活加入多種特征、克服標注偏置問題等優點,但隨著深度學習技術的興起和發展,命名實體識別領域的技術重心逐漸向深度學習偏移。
(2)基于深度學習的命名實體識別。2006年Hinton等[38]提出深度學習的概念,開啟深度學習在學術界和工業界的應用浪潮。近年深度學習通過模擬人腦的識別處理能力,成為熱門的技術研究方向。在命名實體識別研究中,深度學習逐漸取代基于統計機器學習的方法。其中,主流深度學習模型有卷積神經網絡(Convolutional Neural Network,CNN)、循環神經網絡(Recurrent Neural Network,RNN)和最近提出的Transformer。
卷積神經網絡(CNN)是一種前饋神經網絡,主要由輸入層、卷積層、池化層、激活層以及頂端的全連接層、損失函數層組成[39],模型參數小,表達能力強。在命名實體識別中,Collobert等[40]首次使用CNN 與CRF 結合的方式來實現NER,發現加入CRF層后NER的效果有了明顯提高。Strubell等[41]提出了DI-CNN模型,通過在卷積核中增加空洞,擴大上下文的接收寬度,使模型獲得更好的泛化能力。Zhu等[42]同時使用字符嵌入和單詞嵌入,提出GRAM-CNN模型,用于生物醫學領域的實體識別。
循環神經網絡(RNN)是一種鏈式連接的遞歸神經網絡,其最大的特點就是對輸入信息有記憶功能,但RNN存在梯度消失等問題;于是出現了RNN的變體長短期記憶模型(Long Short-Term Memory, LSTM), 以及實現雙向上下文模型訓練的BiLSTM。其另一變體——門控循環單元 (Gated Recurrent Unit,GRU),則是對LSTM的簡化。在命名實體識別中,Chiu等[43]使用BiLSTM和CNN混合結構模型來自動檢測字符級特征,減少了人工構造特征的需要。Lample 等[44]使用添加了CRF層的BiLSTM模型,對英語、荷蘭語、德語和西班牙語語料進行命名實體識別,均取得較好的效果。王仁武等[45]提出面向中文實體識別的實體—屬性抽取方法,使用GRU 與CRF 結合的模型提高識別能力。
2017 年 Vaswani 等[46]提 出Transformer 模型,摒完全依賴于self-attention機制,并憑借其高效性和易訓練性在自然語言處理領域獲得了巨大的成功。2018 年Google 提出了采用雙向Transformer 結構的模型BERT(Bidirectional Encoder Representations from Transformers),在當年11 項NLP 任務中取得了令人矚目的成績,成為目前最好的突破性技術之一[47]。Kim等[48]訓練了多語種BERT模型,并在韓語臨床實體識別數據集上進行測試,證明BERT的識別結果顯著優于字符級BiLSTM-CRF 模型。楊飄等[49]構建BERT-BiGRU-CRF模型,用于表征語句特征,實現了表征字的多義性,并在MSRA語料上取得了較高的F值。岳琪等[50]使用基于實體Mask 的BERT 詞向量,構建BERT-BiLSTMCRF模型,進行中文林業領域的實體識別,發現使用BERT模型能更加充分地提取語義特征。
2 數據與方法
2.1 研究框架
作為中華優秀傳統文化的重要載體,史籍文獻一直占據著重要地位。如圖1所示,本研究以“前四史”(《史記》《漢書》《后漢書》《三國志》)以及《左傳》共5本史書為研究對象,基于深度學習模型識別其中的命名實體(包括人名、地名、時間詞)。
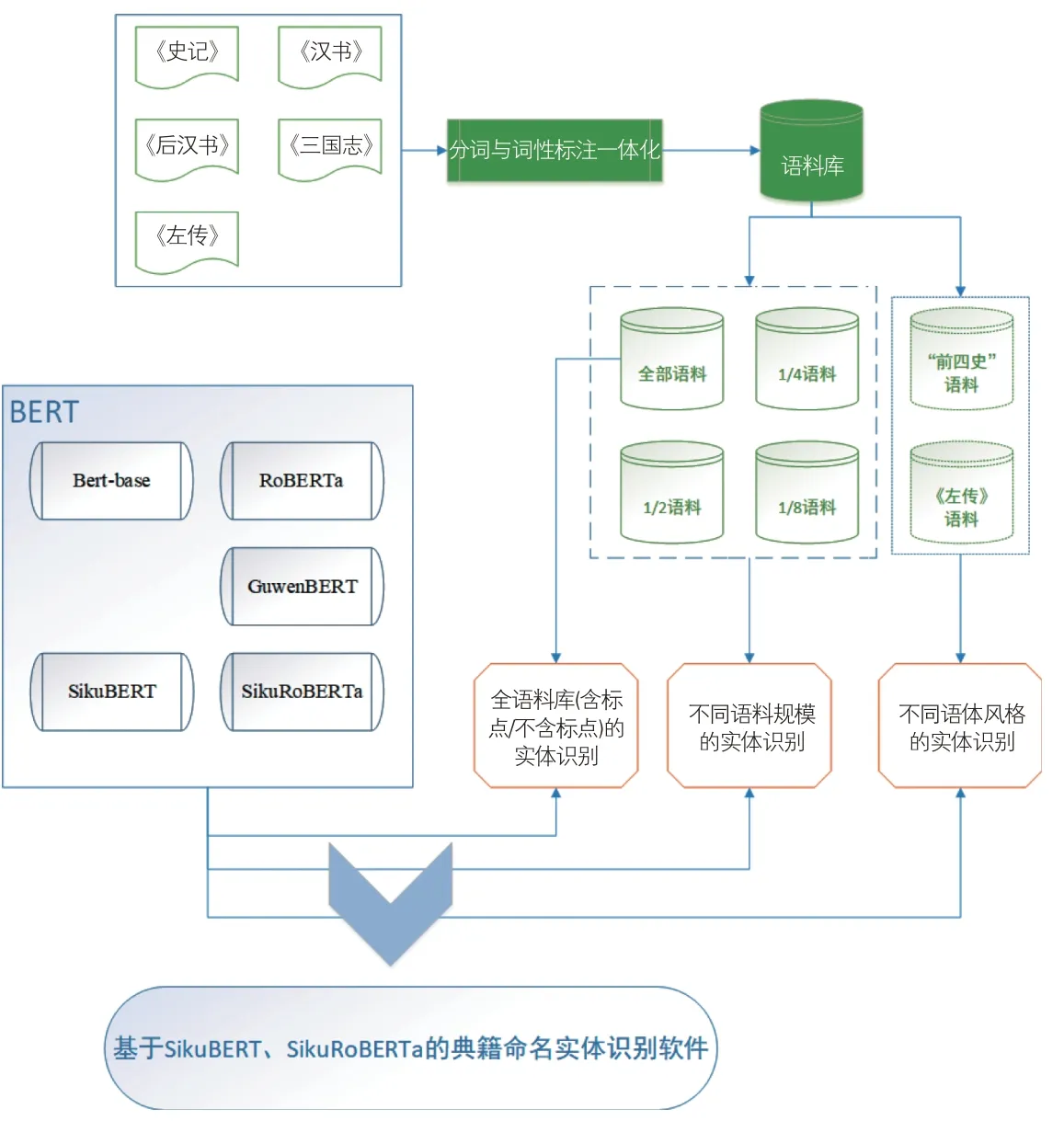
圖1 研究框架
2.2 數據
(1)語料庫簡介。《左傳》以比較原始的材料,相對全面地反映了春秋時期的政治、經濟、文化等情況,是現存有關春秋時期歷史社會的最珍貴史料。《史記》《漢書》《后漢書》《三國志》合稱“前四史”,是對中國各民族進行系統記錄與研究的重要史籍,其民族傳記開創了統一多民族中國歷史的敘事范式,最早揭示了各民族之間的矛盾、交流和交融,對于后世有著重要而深遠的影響[51]。本研究所采用的訓練語料是基于人工分詞和詞性標注并經過多輪校對的上述5種典籍文獻,語料中包含標點符號。
(2)數據標注。本研究中,對典籍文獻的標注采取分詞與詞性標注相結合的方式,使用“/”進行分詞,使用人民日報標注語料庫(PFR)的詞性標記標簽標準,其中所需的人名、地名、時間詞標記如表1所示。標注示例:董仲舒/nr以為/v先/n是/r四國/n共/d伐/v魯/n,/w大/v破/v之/r於/p龍門/ns。/w
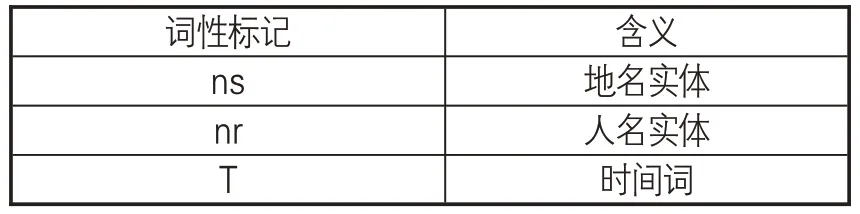
表1 命名實體詞性標記對照
(3)語料庫數據統計。表2展示各部典籍的句子數、字數、標點數、句長等,在統計字數、句長時沒有計算語料中的標點。總體而言,相較于《左傳》而言,“前四史”語料的句子數更多、平均句長更長、字數/標點數的比值更大。而《左傳》語料較小,卻擁有更多標點等特殊符號。
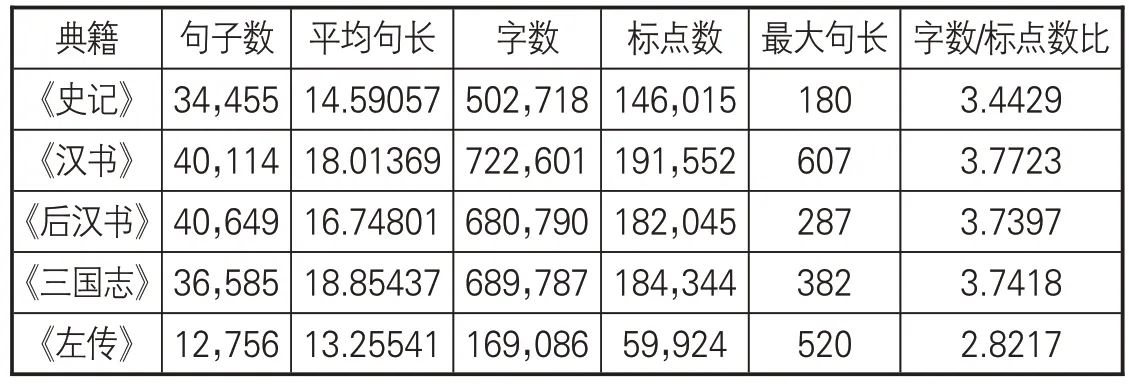
表2 典籍語料句子、字、標點統計數據
2.3 模型
BERT(Bidirectional Encoder Representation from Transformers)是一種雙向語言表征模型,采用基于自注意力機制的Transformer 結構,最先由Google自然語言處理團隊于2018年提出[52]。基于BERT的自然語言處理主要包含兩個步驟:模型預訓練(Pretraining)和微調(Fineturning)。BERT的預訓練模型是基于大量語料進行自監督訓練而形成的語言模型,在執行BERT具體任務時,可以選擇對應的預訓練模型,在此基礎上進行微調即可。本文采用的預訓練模型包括 BERT-base、RoBERTa、GuwenBERT、SikuBERT、SikuRoBERTa。各類預訓練模型的基本情況見表3。其中,BERT-base①是Google提供的中文BERT預訓練模型。RoBERTa②是更具魯棒性的預訓練模型,用動態掩碼機制替代原BERT 預訓練模型的靜態掩碼機制,去除效果不佳的下一句預測任務(Next Sentence Prediction,NSP),且采用更大的預訓練語料庫、Batch-Size(每次訓練的樣本數)和詞表。Ro-BERTa 采用全詞遮罩(Whole Word Masking,WWM)技術,將文本中的詞作為mask對象,相較于BERT-base以字為粒度的切分方式,其識別效果更優。
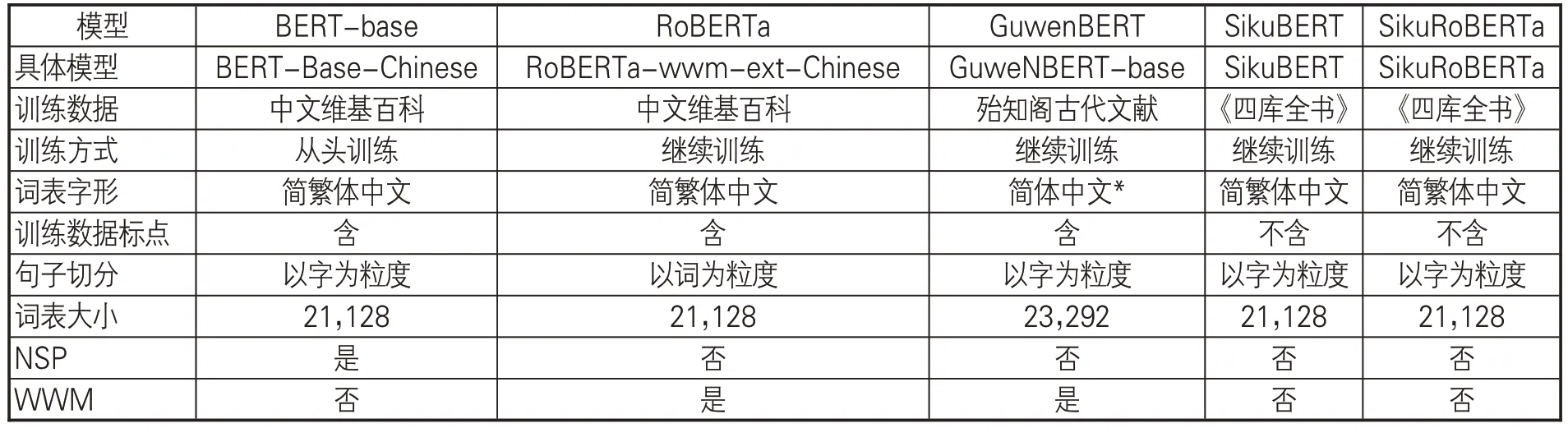
表3 5種BERT預訓練模型簡介
GuwenBERT③由北京理工大學提供,是基于殆知閣古漢語語料的古文預訓練模型,使用RoBERTa相同的技術并結合現代漢語RoBERTa權重與無監督古文語料進行繼續訓練。SikuBERT和SikuRoBERTa④是南京農業大學、南京師范大學等提出的使用繁體《四庫全書》語料分別在BERT-base和RoBERTa上進行預訓練的古文預訓練模型。與原始BERT 相比,SikuBERT、SikuRoBERTa 的預訓練過程僅保留掩碼語言模型(Masked Language Model,MLM)任務,去除對性能提升表現不佳的NSP任務。SikuRoBERTa在保留RoBERTa使用的全詞遮罩(WWM)技術的基礎上進一步從5 億多字的《四庫全書》語料上進行學習,一定程度上彌補了RoBERTa較少在繁體中文上訓練的缺憾。
3 實驗
3.1 實驗設計
(1)數據的預處理。實驗數據在前期手工分詞與詞性標注的基礎上,進一步進行命名實體識別實驗。此時,需要將語料轉換為序列格式,因而對實體采用BIESO的單字標注方式:使用S標識單獨由一個字組成的實體,使用B、I、E分別標識由多個字組成的實體的開頭、中間、結尾字,使用O標識非實體字。標注示例見表4。
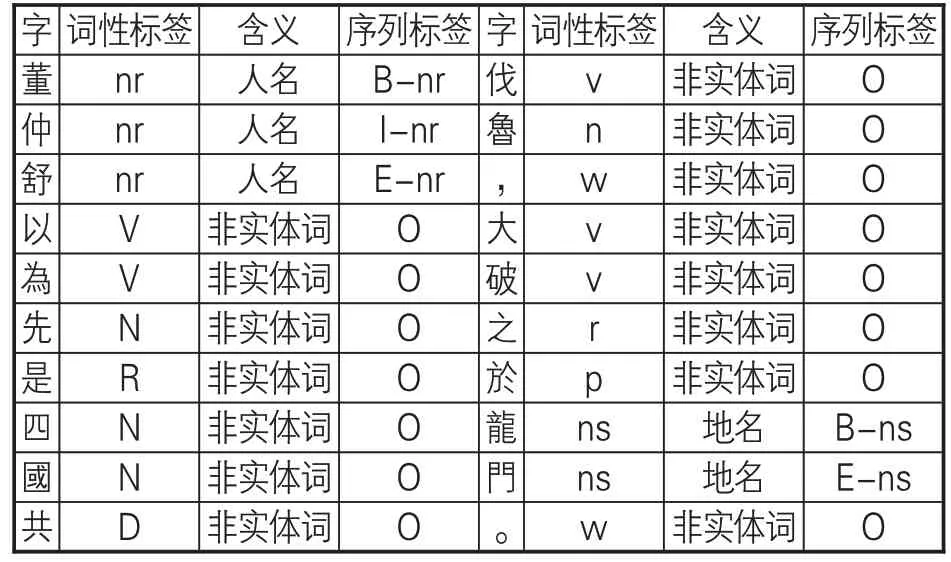
表4 序列數據的單字標注示例
(2)評價指標。為科學評價實驗結果的有效性,采用準確率(Precision,P)、召回率(Recall,R)、調和平均值(F1-score,F1值)這3個指標作為評價模型性能的標準。評估中的混淆矩陣見表5,指標計算采用公式(1)-(3):
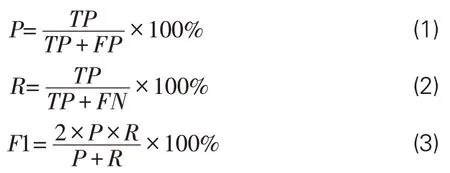
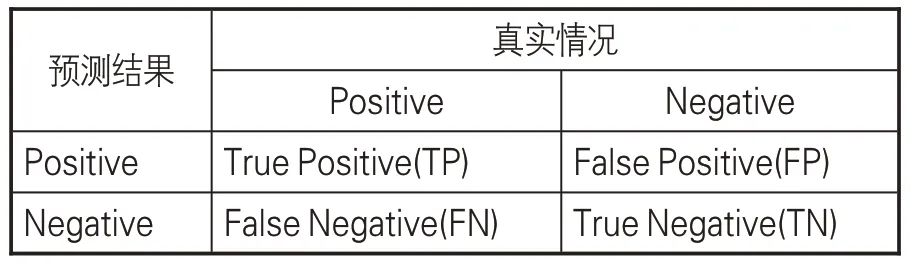
表5 混淆矩陣
(3)實驗環境與模型參數設置。由于一般CPU無法滿足神經網絡模型在訓練過程中所需的大量并行計算,因而本實驗采用高性能的NVIDIA Tesla P40處理器來完成實驗。計算機配置如下:操作系統為CentOS 3.10.0;CPU為48顆Intel(R)Xeon(R)CPU E5-2650 v4@ 2.20GHz;內存 256GB;GPU 為 6 塊 NVIDIA Tesla P40;顯存24GB。SikuBERT和SikuRoBERTa模型和用于對比的 BERT、RoBERTa 和 GuwenBert 均采用相同的結構進行預訓練,即實驗以統一的超參數進行實體識別任務,設置見表6。
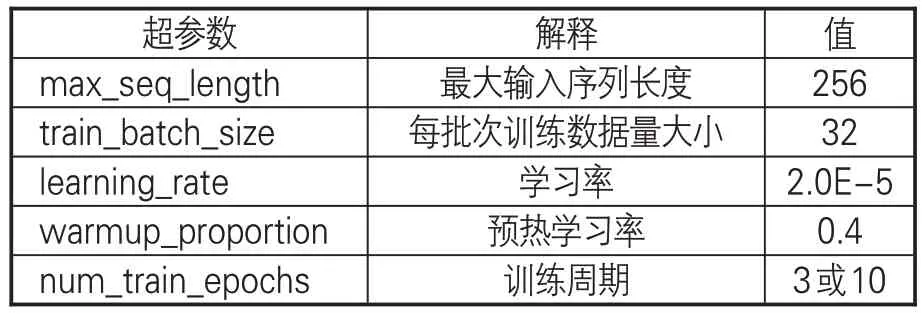
表6 實驗主要超參數設置
3.2 實驗結果
實驗基于BERT模型對典籍文獻中的人名、地名、時間名作識別。研究對數據集以整句為單位,按照9∶1劃分訓練集和驗證集。
3.2.1 全語料庫數據的實體識別
經過語料庫處理與模型構建,基于全部語料(包括含標點、不含標點兩種)訓練得到各類BERT 預訓練模型測試效果(如表7 所示)。從表7 可看出,在未進行任何人工操作情況下,有4 種BERT 預訓練模型在含標點的全部語料上取得不錯的效果,而GuwenBERT 由于其詞表中不含繁體中文,訓練效果略為遜色。在5 種預訓練模型中,BERT-base 效果最優,訓練三輪次調和平均值F1 就能達到89.74%,SikuBERT、SikuRoBERTa的F1值略低,分別為89.03%、88.74%。經過十輪訓練后,SikuBERT和SikuRoBERTa的效果均有略微提升。在去除標點的全部語料上,SikuBERT效果最好,三輪次調和平均值F1 能夠達到85.95%,其次是SikuRoBERTa,達到85.58%;十輪次后的訓練效果也得到略微提升。全語料庫數據實體識別效果的具體情況如下。
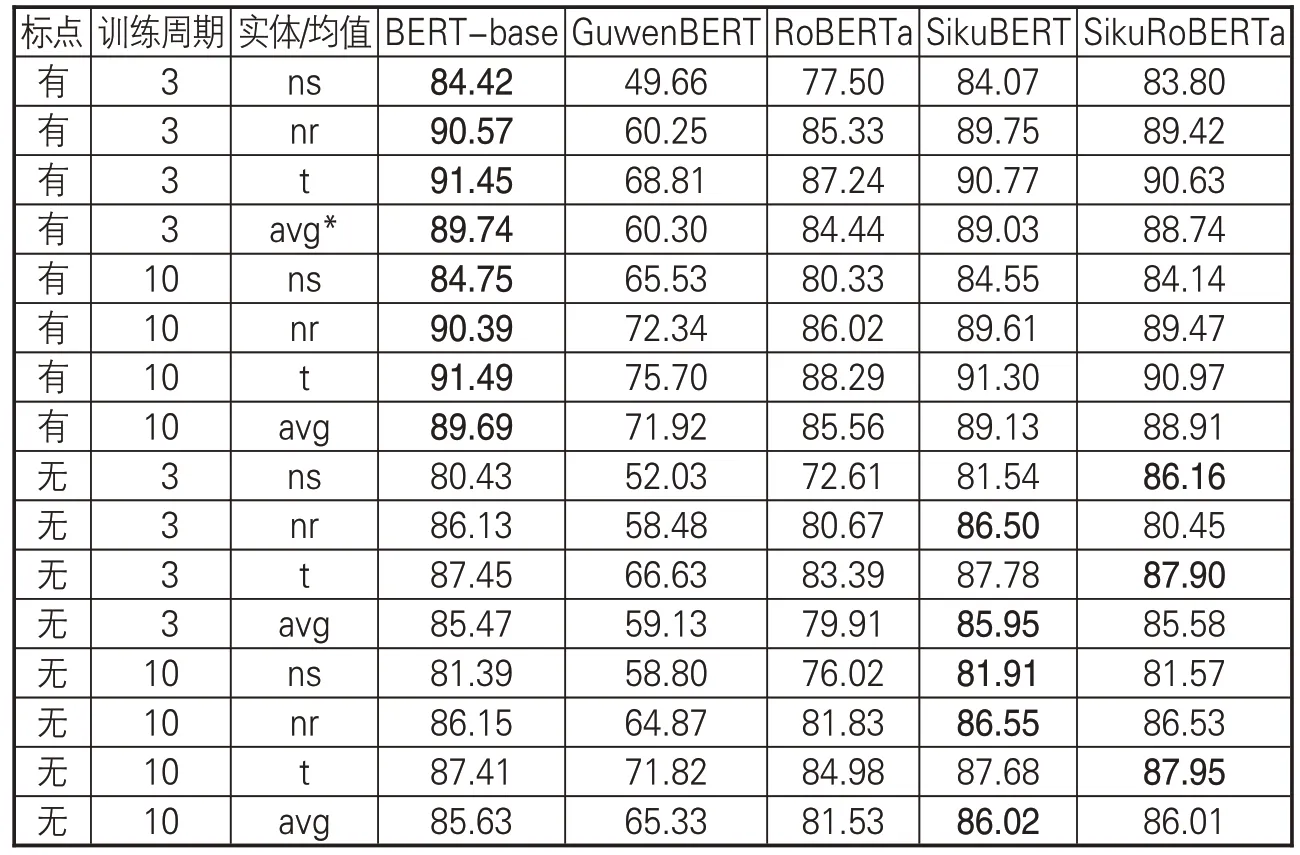
表7 全語料庫數據實體識別效果(F1值)
(1)總體上,無標點語料在各預訓練模型的測試效果均低于含標點語料的測試結果。這是由于標點符號在一定程度上反映了語言的句讀,而較為規則的句讀有助于深度學習模型習得語言特征。然而,傳統意義上的古籍均不含標點,因此在無標點語料上的測試結果對于古籍研究者而言更為重要。
(2)在去除標點的語料上,SikuBERT、SikuRoBerta 的效果超過了BERT-base。這可能是由于這兩個預訓練模型是在大量繁體無標點的《四庫全書》語料上進行訓練。在語料來源、語體風格上,相較于有標點的中文繁體維基百科等知識庫,無標點的繁體《四庫全書》訓練語料在結構及語言上可能與上古典籍文獻更為相似,因而效果略優。
(3)RoBERTa預訓練模型的效果低于BERT-base。這可能是由于RoBERTa 在BERT-base基礎上進行繼續訓練時,采用大量簡體語料,使模型中繁體字的權重下降。而SikuRoBERTa是在RoBERTa 基礎上,采用大量繁體《四庫全書》語料繼續進行預訓練的模型,因而其整體效果有所提升。
3.2.2 不同語料規模數據的實體識別
對于深度學習模型而言,大量的文本數據可以幫助其掌握更多的上下文文本特征,用于實體識別,從而有效降低學習過程中過擬合情況的發生。為研究不同語料規模對模型效果的影響,探究在小樣本數據上模型的實驗性能,本研究開展對比試驗。結果表明,相較于其他幾種典籍,《史記》的實體識別效果最好,因而本節僅以《史記》為語料進行實驗。本節將語料庫規模劃分為全部和1/2、1/4、1/8,實驗結果的調和平均值F1如表8所示。
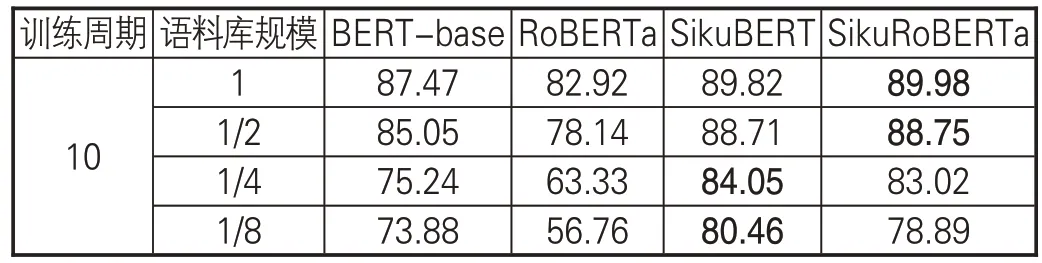
表8 不同語料規模的《史記》命名實體識別效果(F1值)
上述實驗結果顯示,語料庫的規模對于模型的效果有較大影響。(1)隨著語料庫規模的不斷減小,RoBERTa 預訓練模型的微調效果急劇下降,而 SikuBERT、SikuRoBERTa 的 F1 值下降幅度較小。雖然RoBERTa采用WWM全詞遮罩技術,能更好地學習文本的語體風格等,但從百科知識、社區平臺上獲取的具有現代風格的語言知識在小規模繁體古籍的命名實體識別中劣勢明顯。(2)SikuRoBERTa模型的效果在語料規模較小時或epoch 訓練輪次較小時,往往效果不如SikuBERT,但隨著語料規模的擴大與訓練輪次的增加,其效果逐步提升并能在某些實體類型或語料的識別上接近或超過SikuBERT。SikuRoBERTa 是基于RoBERTa 繼續訓練而獲得的預訓練模型,這表明在大規模語料上RoBERTa采用的WWM全詞遮罩技術具有先進性。(3)從1/8 語料到1/4 語料再到1/2 語料時,BERT模型的性能提高得很快;而從1/2語料到全部語料,模型效果的提升并不明顯。這說明BERT模型在大規模文本上的性能更為穩定,大規模數據集更適合BERT模型。
本節進一步論證了SikuBERT、SikuRoBERTa預訓練模型在典籍命名實體識別,尤其是小規模語料上的優勢。
3.2.3 不同語體風格數據的實體識別
“前四史”陸續成書于漢以后,《左傳》則成書于戰國中前期,在語體風格上具有一定差異。為探究不同語體風格對模型實驗的影響,本節分別在“前四史”、《左傳》(均去除了標點等特殊字符)上進行實驗,實驗結果(調和平均值/F1值)如表9所示。
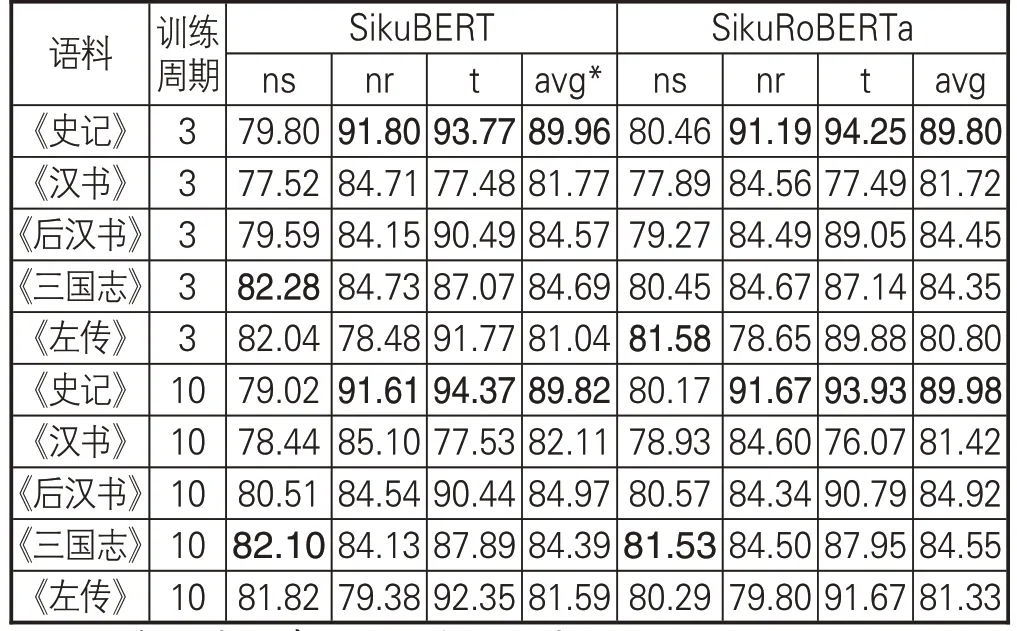
表9 不同語體風格的單一典籍命名實體識別效果(F1值)
根據本節實驗數據,可以發現語體風格對實驗結果存在一定影響。模型在字數最多的《漢書》和字數最少的《左傳》上,識別效果最差。而上節對不同規模數據的對照試驗表明,當語料達到一定大小時,模型的識別效果將變得相對穩定,語料規模的進一步擴大對實體識別性能的提升并無較大幫助。在本節中,《漢書》《后漢書》《三國志》的語料規模均大于《史記》,但三者的實體識別效果均低于《史記》。其中,模型在《漢書》上的識別效果最差,較《史記》約低8個百分點,《后漢書》《三國志》則約低5 個百分點。出現上述差異的影響因素包括:一是語料標注的規范性程度。規范不統一的標注、錯誤標注、漏標注等因素,都會造成模型識別性能的弱化。本實驗語料經過多輪人工校對,最大程度降低了錯漏標注的可能。二是各典籍在語體風格、時代文化背景上存在較大差異。《左傳》成書于戰國中期,《史記》成書于西漢前期,《漢書》成書于東漢時期,《后漢書》成書于南朝宋,而《三國志》成書于西晉時期。這些歷史時期相距較為遙遠,文學的風格也各有不同,與模型預訓練語料的語體風格相似度有所差異,因而可能會對模型識別造成影響。
4 基于SikuBERT的命名實體識別軟件構建
依據前述研究,本實驗構建了一個基于SikuBERT、SikuRoBERTa的命名實體識別應用系統,集成了分詞、詞性標注、斷句、實體抽取、自動標點等常見古籍智能信息處理功能。該系統旨在幫助古籍研究學者更好地快速了解典籍,以推動研究的深化。通過使用PyQt工具包,結合Mysql數據庫存儲方式和其他開發技術,完成基于Siku 系列BERT預訓練模型的“SIKU-BERT典籍智能處理系統”的構建。該系統具有兩種語料輸入模式:單文本模式和語料庫模式,見圖2。單文本模式可以即時輸入和處理文本,語料庫模式能對多個語料文件進行識別。SIKUBERT典籍智能處理系統可以識別人名、地名和時間詞3類經典實體,能更好地幫助使用者掌握事件發展脈絡,進行特定類別事件的篩選,挖掘文本特征和規律,提高研究效率,并對后續古籍資源的利用提供幫助。

圖2 SIKU-BERT典籍智能處理系統首頁
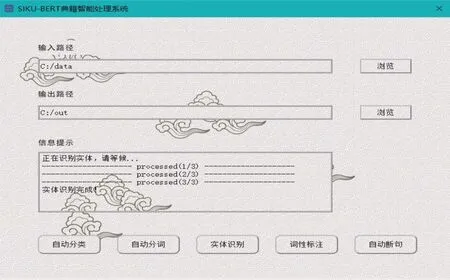
圖6 語料庫模式實體識別
點擊相應模式進入主功能頁面。單文本模式見圖3,在左側“原始文本”欄輸入待處理語料,系統在右側“處理結果”欄輸出結果;語料庫模式見圖4,單擊右側“瀏覽”按鈕,指定語料輸入路徑和結果輸出路徑,下方“信息提示”欄中會顯示輸入語料的詳情。該系統將自動分類、自動分詞、實體識別、詞性標注和自動斷句等功能集中羅列在主(功能)頁面的下方,方便操作。

圖3 單文本模式主功能頁面
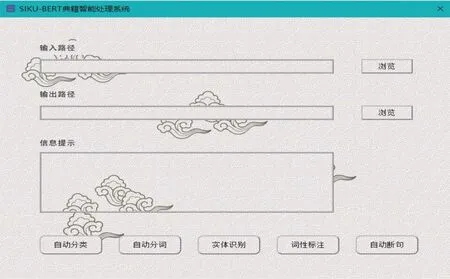
圖4 語料庫模式主功能頁面
單擊“實體識別”功能按鈕,系統自動調用模型對語料進行實體識別,并輸出結果。單文本模式直接在右側顯示處理結果,而語料庫模式則在“信息提示”欄顯示處理進度,任務完成后,將結果寫入txt文檔存儲在輸出路徑中(見圖5-6)。

圖5 單文本模式實體識別
在實體識別功能中,該系統使用SikuBERT和SikuRoBERTa 模型對輸入語料進行實體識別,并返回帶“<>”標簽的結果(見圖7)。比如,輸入序列:“二年冬十月,省徹侯之國。”輸出序列:“,省之國。”

圖7 語料庫模式實體識別效果
SIKU- BERT 典籍智能處理系統基于SikuBERT、SikuRoBERTa模型,能較為精準地實現古籍語料的命名實體識別任務,并且集成了自動分類等其他處理功能,界面簡潔、操作簡便、直觀易用,能更好地為學者提供幫助。
5 結語
基于自然處理技術的古代典籍命名實體識別對進一步分析挖掘和利用典籍文獻具有重要意義。本文基于SikuBERT 和SikuRoBERTa 構建典籍命名實體識別模型,模型在“前四史”、《左傳》等5種史籍中的表現,較文中其他3類基線模型更優。研究論證了深度學習模型應用于大規模古籍文本實體識別的可行性,探究不同預訓練模型、語料規模、語體風格對于典籍文獻實體識別的影響,進一步論證了BERT 引領的“預訓練-微調”深度學習新模式的優越性,為探究及構建更適合特定領域語料的預訓練模型提供參考。
下一步的研究將從以下方面開展:(1)以《四庫全書》為基準構建詞表,從頭開始訓練預訓練模型而非基于BERT-base或RoBERTA 進行訓練;(2)基于已有典籍知識圖譜構建BERT模型,以提高模型在專業性典籍自然語言處理任務中的泛化能力;(3)使用近期各研究機構提出的一系列能將外部知識融于預訓練語言模型的改進模型框架,基于《漢語大詞典》構建典籍詞表,并融入Siku系列預訓練模型,以提升現有識別效果。
注釋
①參見:https://github.com/google-research/bert.
②參見:https://github.com/ymcui/Chinese-BERT-wwm.
③參見:https://github.com/Ethan-yt/guwenbert.
④參見:https://github.com/SIKU-BERT/SikuBERT.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中老年保健(2021年12期)2021-11-30 02:58:01
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
攝影之友(影像視覺)(2019年2期)2019-03-05 08:27:14
中華詩詞(2018年11期)2018-03-26 06:41:34
光學精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年8期)2016-10-09 02:11:50
核科學與工程(2015年4期)2015-09-26 11:59:03
中國醫藥科學(2015年19期)2015-02-27 12:33:11
