古代中國醫學文獻的命名實體識別研究
——以Flat-lattice增強的SikuBERT預訓練模型為例*
2022-09-23 00:58:28劉江峰王東波
圖書館論壇 2022年10期
謝 靖,劉江峰,王東波
0 引言
古代中國醫學文獻所記錄的中醫知識是中華傳統科學文化的重要分支,對中醫文獻進行深度加工和知識標注,有助于挖掘蘊含在其中的古代醫學知識及中醫哲學思想。比如,青蒿素的發現就是從古代中醫文獻《肘后備急方》中得到啟發。古代中醫文獻以文言文的形式存在,是中國古籍文獻的重要組成部分,其中的醫學知識又形成了獨立的醫學和哲學體系,涉及較多中醫學概念。古代中醫文獻的數字化、智能化加工,對中醫知識的深度挖掘具有重要價值。其中,對古代中醫文獻進行命名實體識別,有助于理清古代中醫文獻的知識概念表達,是古代中醫文獻信息化、智能化處理的重要任務。
數字人文近年來成為中國古代文獻研究的新范式,極大推動了中國古代文獻智能化處理的進程。以古文獻分詞、詞性標注、命名實體識別、語義消歧等為研究內容的文本挖掘方法得到了廣泛關注,如王姍姍等在多維領域知識下對《詩經》的自動分詞研究[1];李娜等對古籍方志地名的自動識別[2];王東波等對先秦典籍歷史事件的自動識別[3];劉瀏等對《春秋經傳引得》中同名異指和異名同指現象的自動識別[4]。BERT預訓練模型的提出為中國古文獻智能處理提供了新思路,用戶可以使用預訓練模型完成斷句、分詞、詞性標注、信息抽取等任務。例如,王倩等通過BERT-LSTM-CRF模型對《四庫全書》進行斷句和標點標注,調和平均值分別達86.41%與90.84%[5];張琪等構建了先秦典籍分詞、詞性一體化標注BERT模型,分詞和詞性標注準確率分別達到95.98%、88.97%[6];喻雪寒等采用RoBERTa-CRF模型實現對《左傳》戰爭句論元的抽取,準確率達87.6%[7]。以上研究為數字人文環境下運用BERT預訓練模型,實現中國古代醫學文獻的智能化處理提供了借鑒思路。
本文以古代中醫文獻的代表作《黃帝內經·素問》(以下簡稱《素問》)為研究對象,通過分詞、命名實體標注構建“素問語料庫”,該語料庫能夠體現《黃帝內經》所包含的中醫學理論體系。在素問語料庫基礎上,利用由南京農業大學信息管理學院牽頭、南京師范大學文學院共同構建的SikuBERT 及SikuRoBERTa 預訓練模型,考查其對于古代中醫文獻命名實體自動標注的效果,并通過Flat-Lattice Transformer平面格子結構增強對《素問》中命名實體詞匯的詞向量表達,進而優化SikuBERT、SikuRoBERTa預訓練模型對古代中醫文獻命名實體識別的效果,為古代中國醫學文獻的智能化處理做出益探索。
1 我國古代文獻命名實體研究概述
1.1 命名實體研究
命名實體識別(Named Entity Recognition,NER)是信息抽取技術的重要組成,能從文本文獻中識別預定義的命名實體,如新聞語料中的人物、地點、時間、事件。命名實體識別術語在MUC(Message Understanding Conferences)第六次會議上提出[8],并在其他相關國際會議中由人名、地名、機構名等逐漸細化擴展至跨語言、多領域的命名實體,如CoNLL-2003(Conference on Computational Natural Language Learning 2003)中提出的語言無關命名實體識別[9]。
命名實體識別是自然語言處理的關鍵任務,相關研究的發展主要歷經了4個階段。一是基于詞典與規則的早期階段,向曉雯等利用統計與規則相結合的方法,通過詞性序列識別命名實體,實驗結果F1 值達到80.02%[10];王昊構建基于層次模式匹配的實體識別模型,并應用于學術論文術語縮略語的識別,取得較好識別效果[11]。二是基于傳統機器學習模型的階段,陳懷興等提出利用HMM 詞對齊結果抽取命名實體翻譯等價對的方法,具有較高的識別率[12];陸偉等采用條件隨機場模型,利用詞匯、詞法及詞型特征,實現對商務領域產品的命名實體識別,取得較為滿意的識別效果[13]。三是基于深度學習模型的階段,李麗雙等提出基于CNN-BLSTMCRF的神經網絡模型,其在BiocreativeⅡGM和JNLPBA2004生物醫學語料上的F1值可達89.09%和74.40%[14];丁晟春等運用Bi-LSTM-CRF深度學習模型對商業領域中的企業全稱實體、企業簡稱實體、人名實體進行自動識別,識別率平均F1值達90.85%[15]。四是基于自注意力及遷移模型的階段,崔競烽等對菊花古典詩詞的7類命名實體進行標注,比對BiLSTM、BiLSTMCRF和BERT模型的識別效果,結果表明預訓練模型BERT 的F1 值最高[16];陳美杉等提出基于KNN-BERT-BiLSTM-CRF 的實例及模型遷移框架,對肝癌自動問答中的命名實體進行標注,遷移效果表明F1值可以提升1.98%[17]。
從以上研究可看出,命名實體的研究文本對象包括新聞、商業產品資料、學術文獻、網絡社區文本、生物醫學文本及病歷等,實體對象也由人名、地名、機構名擴展至商務企業名、生物醫學術語、古代詩詞實體等。從近年來研究技術的發展來看,在深度學習和神經網絡算法基礎上,加入注意力、遷移學習等機制成為主流方案。在中文命名實體的識別應用中,由于中文分詞的特殊性,分詞效果對于命名實體識別效果具有一定影響,基于字的識別機制會丟失詞匯級的上下文信息。Zhang等提出了用于中文命名實體識別的Lattice(格子結構),并將Lattice結構詞向量應用于LSTM模型,避免了由于分詞而導致的命名實體識別錯誤[18];Li等在Lattice結構上進一步提出了平面結構的Flat-lattice Transformer 微調索引機制,該機制可以繼續提升Lattice-LSTM模型對命名實體識別的效果[19]。本文在選擇適合古代中醫文獻命名實體識別的模型時,考慮到古文及中醫術語構詞的特殊性,采用Flat-lattice Transformer 結構完成對《素問》中《黃帝內經》術語的標注,并考查其對于現有古文BERT預訓練模型的提升效果。
1.2 中文古籍BERT預訓練模型研究
BERT模型是2018年由Google提出的一種雙向Transformer預訓練模型[20]。Transformer是Vaswani等提出的基于“自注意力機制(Selfattention)”疊加形成的深度網絡,能夠有效表達詞匯上下文的特征[21]。BERT在大規模數據集上進行了預訓練,用戶可以直接下載預訓練模型,而后通過微調(fine-tuning)獲得更好的訓練效果。對于用戶而言,BERT預訓練模型可以作為實驗的組件進行搭配,所有任務無需從零開始。自提出以來,BERT預訓練模型在自然語言處理相關領域均取得了優異效果。陸偉等基于BERT和LSTM方法構建對關鍵詞的自動分類模型,實驗效果中F1值達85%[22];趙旸等比對了BERT中文基礎模型(BERT-Base-Chinese)和中文醫學預訓練模型(BERT-RePretraining-Med-Chi)在中文醫學文獻摘要數據上的分類效果,實驗結果表明,BERT模型在大規模文本分類中能取得較好效果,而BERT-RePretraining-Med-Chi則能進一步提高分類效果[23];吳俊等在BERT中嵌入BiLSTM-CRF模型,令自建數據集的術語提取效果(F1值)達到92.96%[24]。
在數字人文研究領域,BERT 相關預訓練模型的構建得到了國內學者的重視,包括中文RoBERTa(Chinese-RoBERTa-wmm-ext)、SikuBERT 及 SikuRoBERTa 等。 中文 RoBERTa是由哈工大訊飛聯合實驗室發布的中文預訓練語言模型,其中Whole Word Masking(全詞掩碼,WWM)可以保證在BERT進行Mask任務時將粒度由字延伸至詞,確保中文詞匯整體參與BERT 自注意力機制[25]。SikuBERT、SikuRo-BERTa 預訓練模型是在Bert-Base-Chinese、Chinese-RoBERTa-wwm基礎上加入繁體《四庫全書》繼續訓練后得到的預訓練模型,在《左傳》的分詞、詞性標注、斷句、命名實體識別等多項任務中均表現優異[26]。文章以主流中文古籍BERT 預訓練模型為基礎,探索在中醫這個特色主題文獻集上BERT 預訓練模型對中醫學命名實體的識別效果。預訓練模型見表1。
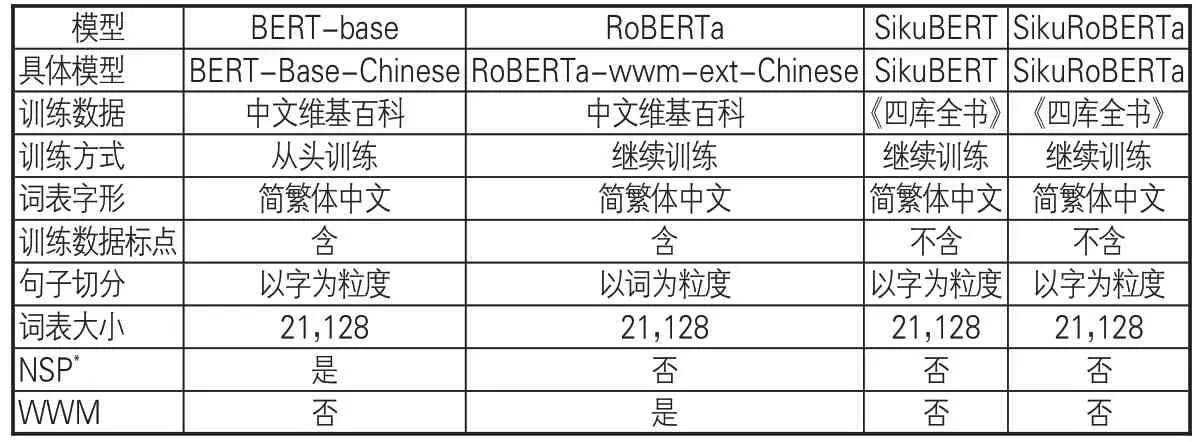
表1 古文BERT預訓練模型簡介
2 數據與研究框架
2.1 語料來源與數據標注
《黃帝內經》是中國最早的中醫典籍,成書于先秦兩漢時期,由《素問》《靈樞》兩部分構成。《素問》系統闡述了中醫的基礎理論體系,包括病因、病證、病理、臟腑、經絡、陰陽五行等,而《靈樞》則以經絡腧穴、針灸治法等主題為主。《黃帝內經》是中醫思想的源泉,其理論體系成為后世中醫理論的先導,相關術語為后世中醫廣泛繼承使用。在中國古代醫學文獻研究中,對《黃帝內經》《傷寒論》《難經》《神農本草經》等典籍的研究相對較多、相關詞典資源相對豐富,但大量的其他中醫古籍文獻仍有待進一步深度加工處理。本文以《素問》為主要研究對象,利用詞典資源完成《素問》文本內中醫學概念實體的識別及標注,在此基礎上通過現有BERT 古文預訓練模型實現對中醫命名實體術語的自動提取。BERT 預訓練模型為中國古籍文獻的智能化處理提供了新思路,以BERT 模型為框架、《四庫全書》等典籍為全文語料進行無監督訓練而獲得的預訓練模型,可以作為工具直接運用于特定古籍文獻的分詞、詞性標注、命名實體識別等任務中。但對于中醫這一特殊專業領域的文獻,需要對領域知識詞匯進行補充。現有的中醫學詞典可提供相關詞型知識,而通過以Word2Vec為代表的詞向量模型可以進一步獲取領域詞典的上下文特征。《黃帝內經》(特別是《素問》)對后世的中醫文獻影響深遠,因而《黃帝內經》相關的詞典資源及其在具體中醫文獻中的上下文信息,可以作為BERT預訓練模型在中國古代醫學文獻處理中的有力補充。在《素問》語料的版本來源上,選擇郭靄春先生校注的《黃帝內經素問校注》[27]。該版本詳細梳理了《素問》的各個古籍注版,是《素問》研究集大成著作。在《黃帝內經》醫學術語的詞典選擇上,本文選擇了周海平等主編的《黃帝內經大詞典》。該詞典是目前收錄《黃帝內經》詞條最多、詞義最為詳盡的工具書[28],共包含詞型1.9萬多種。
需要說明的是,在對《素問》相關命名實體語料的加工過程中,筆者對《黃帝內經大詞典》收錄詞型做進一步加工,如提取在詞型說明中包含“病證名詞”“運氣學說術語”“病理名詞”“穴位名詞”“五行術語”“經絡名詞”等命名實體明確標識的詞條,并對命名實體同義詞條(如別稱、縮略語等)進行了提取。在《黃帝內經大詞典》收錄的《黃帝內經》術語實體分類基礎上,以其中主要命名實體詞匯為研究對象,并將脈學及脈象等關聯密切的術語類別進行合并,最終形成本文命名實體識別的主要分類(類目),如表2所示。
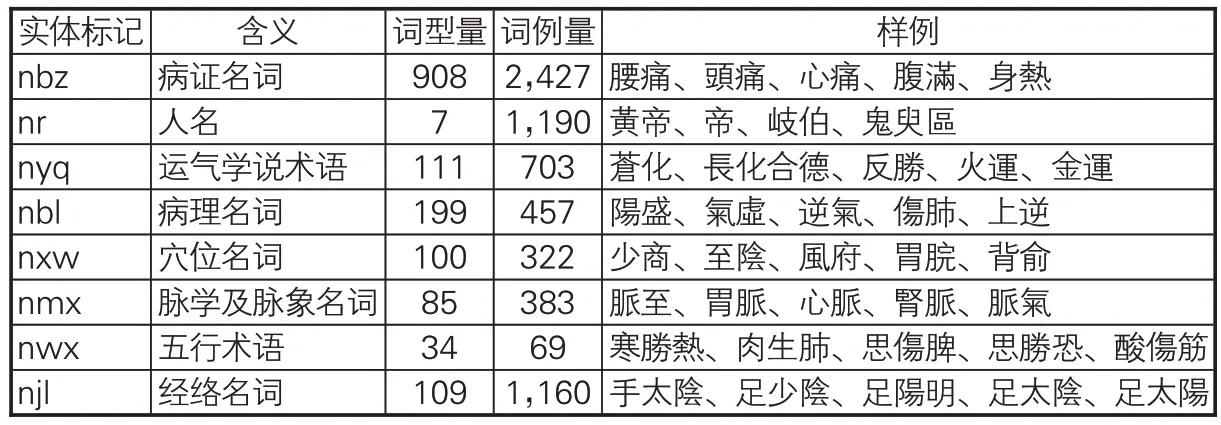
表2 《素問》主要命名實體標記集及其樣例
文章以《黃帝內經大詞典》收錄詞條為基礎,通過最大匹配算法對《素問》繁體文本語句進行了分詞并加以人工校對,對其中由于分詞歧義引起的詞匯切分錯誤進行了核對。比如,“則脈充大而血氣亂”可以切分為“則/脈/充大/而/血氣/亂”和“則/脈/充大/而/血/氣亂”,這里根據上下文信息選擇“則/脈/充大/而/血氣/亂”。在此基礎上利用詞典詞條內的術語分類標記對《黃帝內經》術語命名實體進行標注,樣例如下:
【nbz 霍亂】/,刺/【nxw 俞】/傍/五/,【njl足陽明】 /及/上/傍/三/。
分詞后,《素問》含詞匯6,753個,其中術語詞型1,553個、詞例6,711條。在所有術語詞型及詞例中,病證名詞最多,人名、經絡名詞次之,五行術語出現最少。從構詞及上下文特征來看,不同術語類型有不同特點:病證名詞的構詞多包括“厥、聾、攣、痛、脹”等字樣;經絡及穴位名詞,前后多出現“刺”字。《素問》分詞及中醫命名實體標注后的基本情況如表3所示。

表3 語料基本統計數據
在已分詞、已命名實體標注的繁體《素問》文本基礎上,文章將其轉為序列標注格式。本實驗的序列標注集合為{B,I,E,S,O},其中B代表命名實體詞匯首字符,I代表命名實體中間字符,E代表命名實體詞匯尾字符,S代表單字型命名實體字符,O代表非命名實體相關字符,正常實體序列由B標記開始、E標記結束。在標記BIESO的同時,文章還在相關標記記號后附上實體分類,標記樣例見表4。
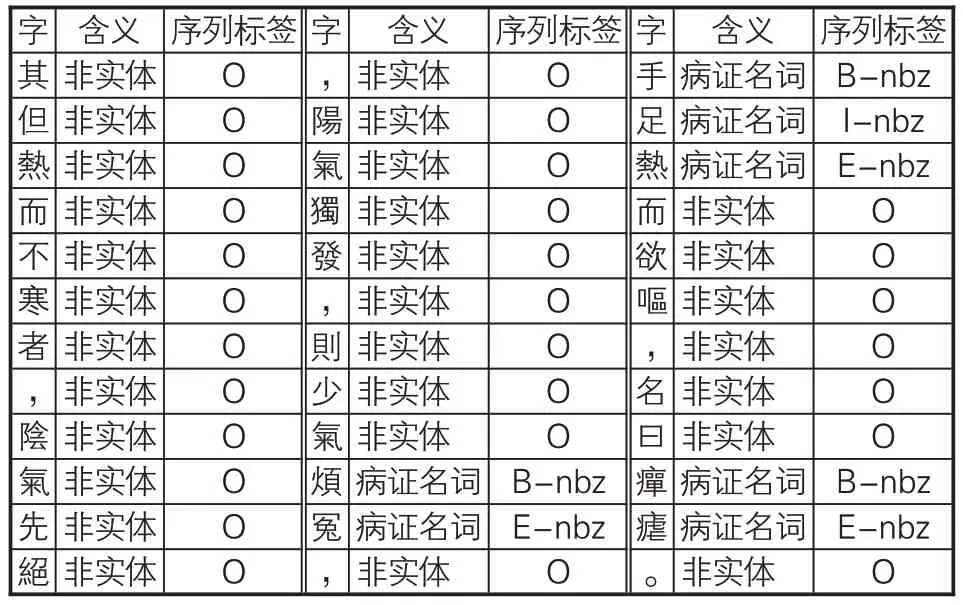
表4 《素問》命名實體數據集的標注示例
2.2 研究框架及模型微調過程
2.2.1 研究整體思路
在已切分詞語及已標注術語實體的語料上,本文利用現有的4 種古文繁體BERT 預訓練模型,對《素問》術語命名實體自動標注展開研究。研究主要分為3個階段:一是直接考查現有古文繁體BERT模型對中醫術語命名實體的標注效果,遴選效果較好的預訓練模型進入下一階段微調過程;二是為防止由于預訓練模型詞典中醫學詞匯缺失而導致詞匯向量切分有誤,選用了Flat-lattice 結構對中醫學術語進行標注序列轉化,并通過Word2Vec模型在“中醫笈成”[29]全文數據庫收錄的繁體中醫典籍文本上獲取《素問》中醫學術語的上下文知識;三是用Flatlattice Transformer微調后的中醫術語詞向量結合古文繁體BERT 模型,觀察“預訓練+微調”模型處理后《素問》中醫術語命名實體的自動標注效果。在所有命名實體識別的訓練和標注中,均采用十折交叉驗證的方法,即將已標注的素問語料庫平均分為10份,展開10輪訓練,每次選出其中9份用于訓練,1份用于結果驗證;在考查結果時,以通過10輪交叉驗證的均值來驗證效果。研究思路框架如圖1所示。
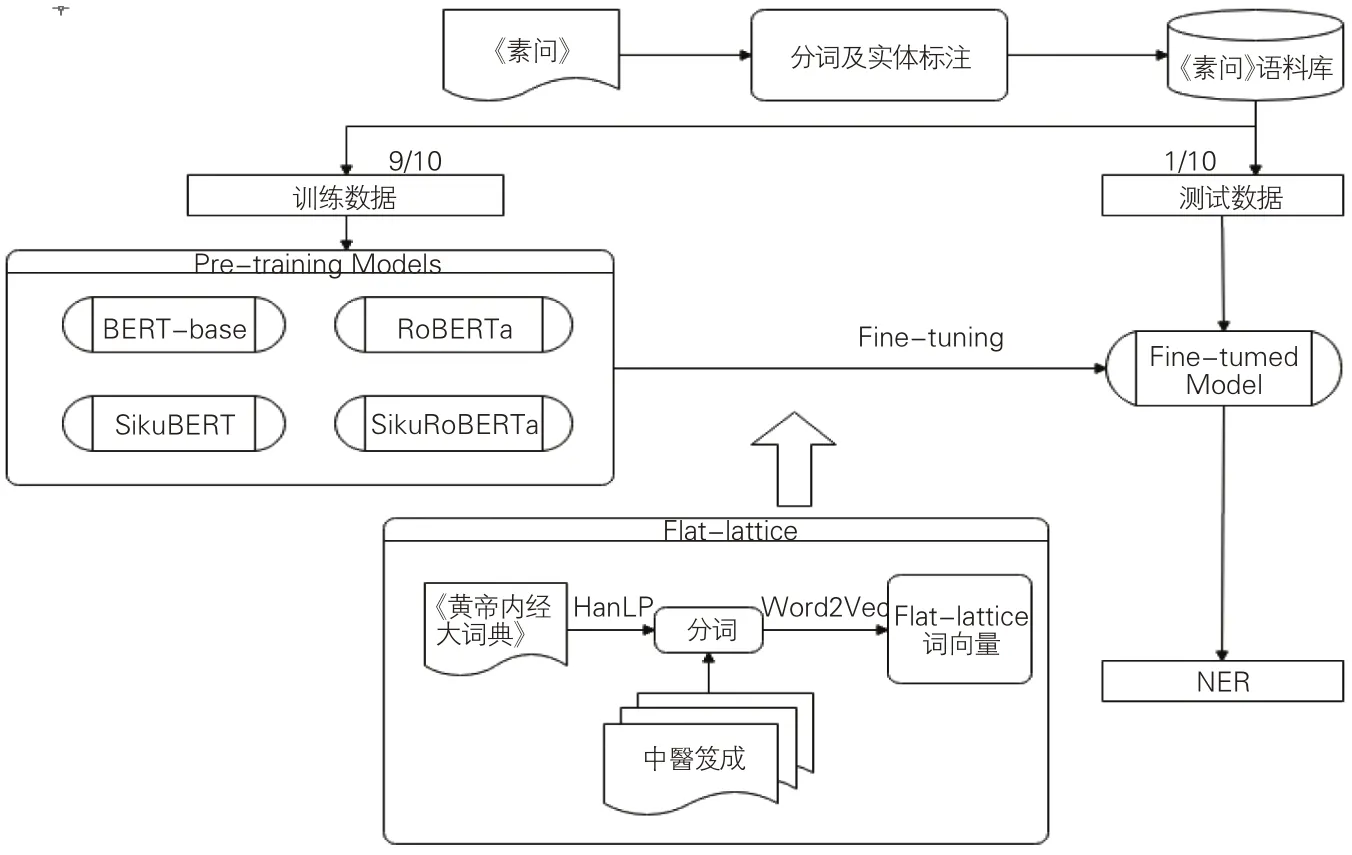
圖1 研究框架
2.2.2 Flat-lattice Transformer結構轉化
Flat-lattice Transformer(FLAT)結構源自對漢語詞匯標識的Lattice(格)結構,該結構能避免因分詞錯誤的傳遞而引起的命名實體識別問題。中文的命名實體識別與分詞任務密切相關,命名實體的邊界也是詞匯邊界,詞匯切分錯誤會影響命名實體識別效果。在現有古文繁體BERT預訓練模型中,多以字為粒度(見表1),然而古代中國醫學文獻含有大量的中醫學術語,以字為粒度的訓練并不能滿足醫學領域的知識表達。Lattice 結構可以利用顯性的詞和詞序信息,且不會出現分詞誤差。Flatlattice結構在Lattice結構基礎上標記詞匯Token及其頭尾位置Head、Tail。這種標記方式可以簡單地將命名實體標記BIESO序列進行轉換及還原。同時,Flat-lattice Transformer結構的自我注意機制使字符能夠直接與任何潛在的單詞交互(含自我匹配),并可有效防止標記序列出現“OIE”表達錯誤。本文涉及的《素問》語料Flatlattice Transformer 微調標記過程如圖2 所示,包括BIESO序列標記及實體類型標記。
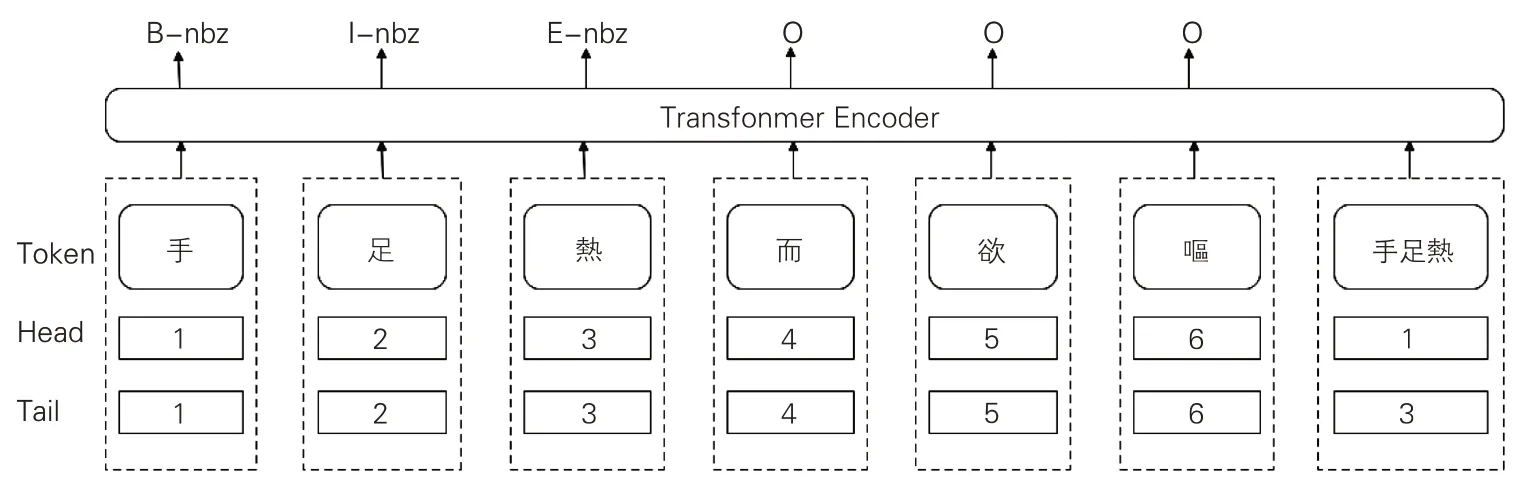
圖2 Flat-lattice Transformer結構示意圖
2.2.3 《素問》命名實體的詞向量生成
BERT預訓練模型的出現為小規模語料智能處理提供了新的解決方案:在大規模語料訓練基礎上,BERT模型能夠快速、準確地為小規模語料提供預訓練數據支持。RoBERTa、SikuBERT及SikuRoBERTa等預訓練模型在大規模古漢語文本基礎上進行了訓練,尤其是《四庫全書》語料的加入,使它們能夠覆蓋經、史、子、集等多種題材的古籍文本。但對于古代中醫文獻這個領域,由于有大量中醫實體名詞存在,命名實體在分詞階段就可能存在切分錯誤。基于詞典的方式可以獲取相關中醫命名實體,但如何對這些實體的上下文信息進行充分獲取又亟待解決。劉耀等提出,可以由醫學網站定期、批量提取相關知識并建立索引[30]。文章借鑒這個思路,收集“中醫笈成”網站收錄的843部中醫典籍文本作為本次實驗中《素問》涉及中醫學術語的上下文知識補充。
在《素問》中醫命名實體詞向量的補充表達上,文章選擇詞向量生成模型Word2Vec作為解決方案。Word2Vec是谷歌公司提出的一種將詞匯表達為數值向量的工具技術,以詞匯作為特征并將其映射至K維向量空間,進而為文本詞匯獲取更深層次的上下文特征表達[31]。Word2Vec模型主要有CBOW和Skip-Gram這兩種算法。CBOW算法是給定上下文預測當前詞的詞向量,Skip-Gram 算法是給定當前詞預測上下文詞向量;CBOW算法的訓練速度更快且對頻次較高的詞匯表征較好,Skip-Gram算法則對稀有詞匯和短語表征較好,因而本文選用Skip-Gram算法。王名揚等引入Word2Vec模型實現情感詞及其所在微博語句的向量化表達,進而提升文本情感分類結果[32]。文章借鑒了這個思路,將《黃帝內經大詞典》內收錄與《素問》相關的中醫命名實體作為研究對象,通過Word2Vec獲取其上下文的詞向量表達。這部分詞向量以FLAT格子結構補充進從《四庫全書》訓練而來的BERT模型中。
在計算Word2Vec詞向量之前,對從“中醫笈成”中采集的中醫典籍文本進行數據清洗和分詞。具體步驟為:(1)分詞前預處理,去除文獻txt文本中的異常字符和開頭題錄信息;(2)以《黃帝內經大詞典》作為自定義詞典,使用HanLP對中醫典籍文本進行分詞,并使用自定義詞典進行最大匹配詞匯切分以優化分詞結果[33]。本文運用Word2Vec處理詞向量過程中的相關參數見表5。
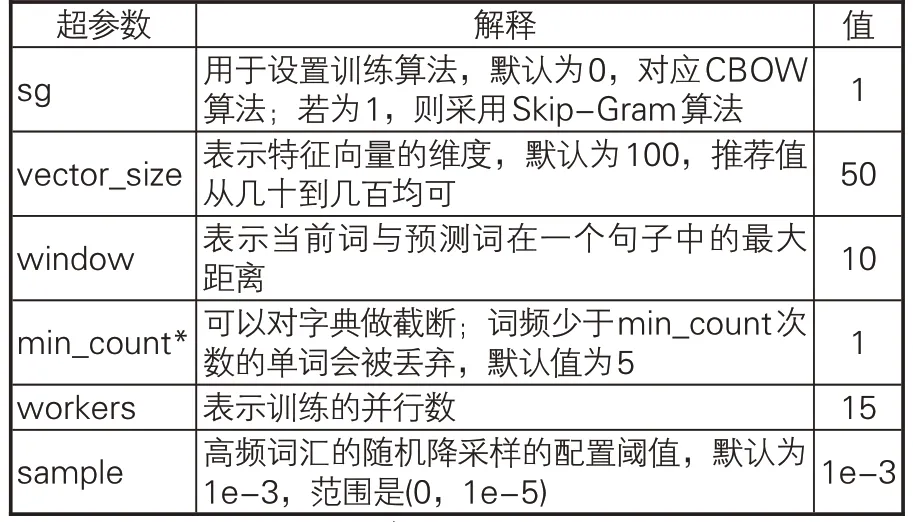
表5 Word2Vec詞向量生成參數設置
3 實驗環境及結果
3.1 實驗環境及模型參數
本實驗中,操作系統為CentOS 3.10.0;硬件配置為:CPU,Intel(R) Xeon(R) CPU E5-2650v4@2.20GHz,總核心數48;內存256GB;GPU,NVIDIA Tesla P40(6塊)。在實驗過程中,對于選用的4 種古文繁體BERT 預訓練模型(BERT-base、 RoBERTa、 SikuBERT、 Siku-RoBERTa),文章選取了相同的結構進行訓練,訓練模型的超參數見表6。
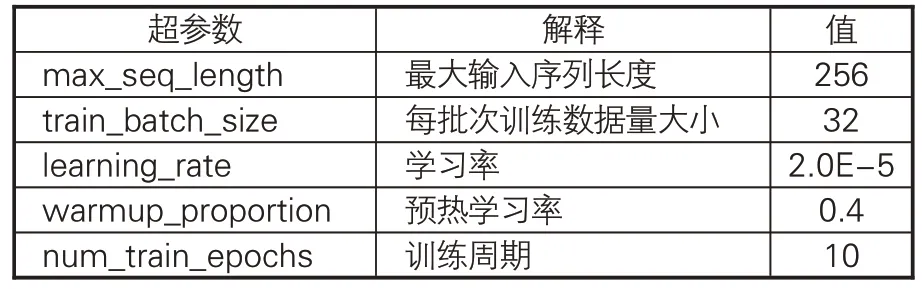
表6 實驗的主要超參數設置
在Flat-lattice Transformer 的詞向量訓練中,相關參數的最優設置如表7所示。需要說明的是,用于觀測F1值變化的數據集與4種古文繁體BERT預訓練模型使用的數據集相同。表7中的部分測試指標說明如下:(1)當epochs設置較小時,直至運行結束,模型尚未完全收斂,F1 值仍然在波動中上升。經過不斷嘗試將epochs 分別設置為10、20、50、70,發現當模型訓練至50-60輪左右時,F1值基本保持穩定,因而epochs參數選擇為70;(2)batch_size越大,訓練速度越快。本實驗對比了batch_size為4、8、16時模型的效果,發現batch_size為4時,模型訓練速度較慢;batch_size為16時,模型性能出現了可見的下降,而運行速度并未顯著提升,因而batch_size最終取值為8;(3)實驗對比learning_rate 學習率分別為2e-5、5e-5、6e-4 的情況,結果表明學習率為2e-5、5e-5時,訓練50輪結果不及6e-4訓練10輪結果,且50輪后F1值仍處于緩慢上升,因而學習率選擇默認為6e-4。
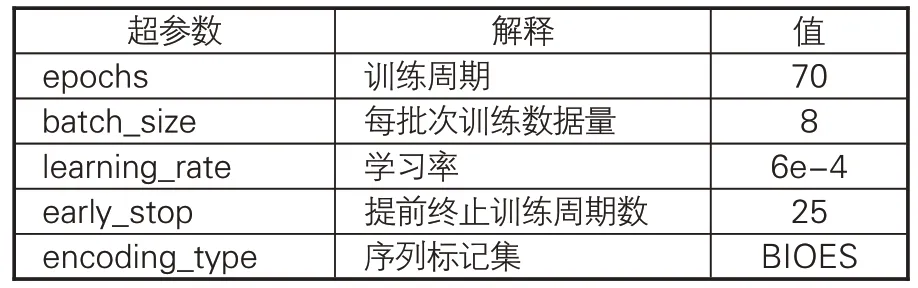
表7 本實驗Flat-lattice模型最優超參數設置
3.2 實驗評價指標及結果
實驗以分詞、命名實體標注后的《素問》為語料來源,選用交叉驗證的方式考查多種中文繁體BERT預訓練模型及Flat-lattice結構對中醫命名實體自動標注的效果。
3.2.1 實驗評價指標
文章采用命名實體識別的3個常見指標作為評價模型性能的標準:準確率P(Precision)、召回率 R(Recall)、調和平均數 F1 值(F1-score)。在實體標注結果中,會出現4種標注情況:實體數據標記為實體(正確標注,True Positive)、實體數據未能標記(錯誤標注,True Negative)、非實體數據標記為實體(錯誤標注,False Positive)及非實體數據未標記為實體(正確標注,False Negative)。相關實體識別結果說明見表8,而P、R、F1值計算公式如下:
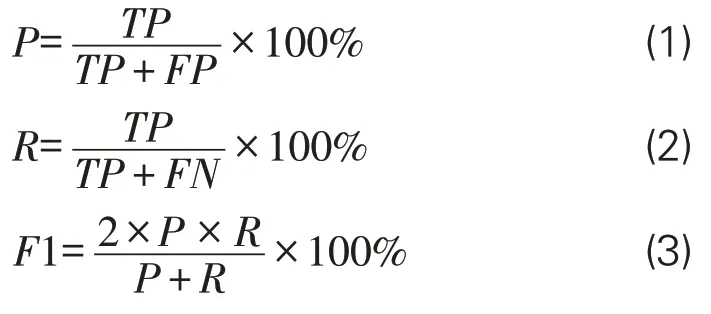
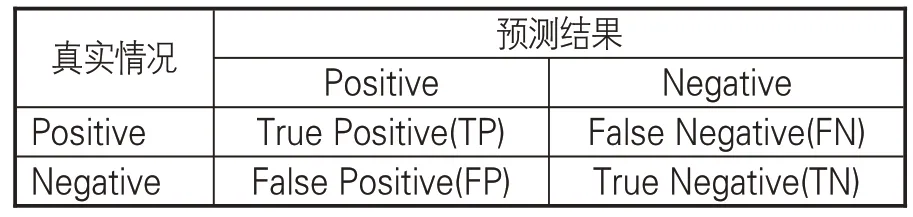
表8 實體識別結果混淆矩陣表
3.2.2 基于原始BERT預訓練模型的《素問》命名實體識別
文章首先考查現有4種古文繁體BERT預訓練模型在《素問》命名實體標注語料上的識別效果。在處理數據時,將實驗在有標點、無標點兩種情況下分別展開,具體結果如表9所示。
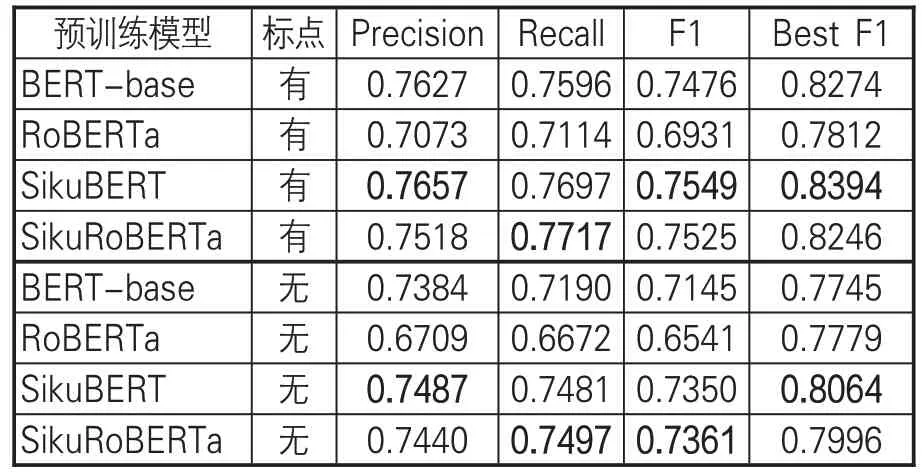
表9 4種原始BERT預訓練模型的《素問》命名實體識別效果
直接使用4 種古文繁體BERT 預訓練模型,考察多輪實驗結果可知:(1)有標點訓練和無標點訓練下,有標點訓練平均F1值為73.70%,無標點訓練平均F1值為70.99%,有標點訓練效果優于無標點訓練,其中平均F1值高2.71%,最佳F1 值(Best F1)高3.3%;(2)在有標點實驗中,SikuBERT預訓練模型實驗效果最好,在P、F1和最佳F1值上結果最佳,SikuRoBERTa預訓練模型的R 值最高,而BERT-base 取得與SikuRoBERTa接近的訓練效果;(3)在無標點實驗中,SikuBERT 預訓練模型在P 和最佳F1 值上效果最好,而SikuRoBERTa 在R、F1 值上效果最好,BERT-base 略低于SikuBERT、SikuRoBERTa 模型。從有無標點的訓練結果來看,有標點的訓練文本可以通過句讀完成對文本句子、段落的自動分隔,從而有利于訓練模型捕捉句子的自然分隔,但無標點訓練集更接近中醫古籍本身實際情況。綜上可知,4種古文繁體BERT預訓練模型對《素問》中醫命名實體自動標注效果的F1值介于65%~75%,SikuBERT、SikuRoBERTa 在有標點和無標點情況下,均能取得更好的實驗效果,實驗效果整體優于基準BERT-base模型。因而,后續FLAT+BERT 實驗只在SikuBERT、SikuRoBERTa上展開。
從訓練的不同類型命名實體的識別結果來看,“脈學、經絡、人名、穴位”效果最好,“病證”次之,“五行、運氣”由于樣本稀疏識別效果高低不定,“病理”名詞識別效果也不佳。在標記序列中,由于BERT預訓練模型本身不包括對標記集序列的約束,因而在結果中會出現IOE、BIO 這樣的錯誤序列。正常結果應該由B 開頭、E 結束,中間可以包含I。在相關的研究中,有學者通過BERT+CRF[34]或BERT+BiLSTM+CRF[35]來保證標注序列的合理性。考慮到中醫術語命名實體的領域特殊性,為了保證相關命名實體在分詞階段不產生錯誤以影響識別效果,文章選擇了Flat-lattice Transformer結構作為標記序列的約束,從而保證相關中醫命名實體不被切分。
3.2.3 基于FLAT+BERT預訓練模型的《素問》命名實體識別
Flat-lattice Transformer(FLAT)結構通過對命名實體詞匯進行頭尾位置標記(Head、Tail)實現由BIESO標記集的序列轉換。同時,Transformer自注意力機制可以保證字符與任意潛在詞匯進行交互,包括自匹配單詞。在FLAT結構下,可以保證領域術語以整體形式作為詞向量,參與BERT預訓練模型的Mask訓練,而不會產生有些命名實體的部分字符被遮掩(Masked)的情形,即FLAT 結構可以保證術語作為整體參與Mask訓練。在《黃帝內經大詞典》基礎上,文章以“中醫笈成”為上下文語境,獲取《黃帝內經》術語命名實體的Word2Vec 詞向量,作為SikuBERT、SikuRoBERTa 預訓練模型的中醫領域知識補充。在有標點訓練和無標點訓練下,相關FLAT+BERT 預訓練模型的實驗效果如表10 所示。
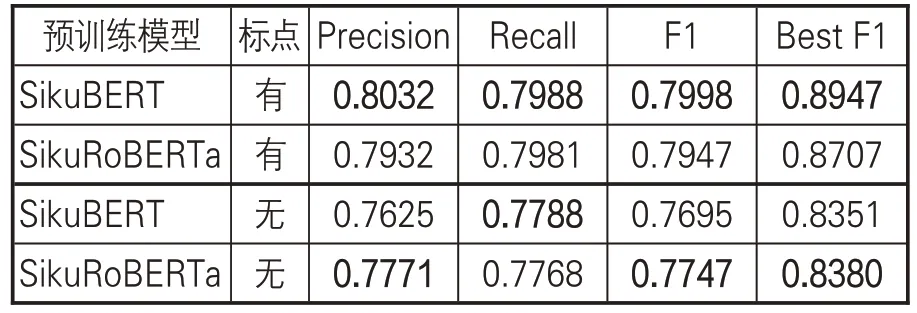
表10 FLAT+BERT預訓練模型的《素問》命名實體識別效果
考察表10中的數據,并對比表9相關模型的訓練結果可知:在FLAT 增強實驗環境下,對《素問》中醫術語命名實體的領域知識詞向量做補充,有助于SikuBERT、SikuRoBERTa取得更好的實驗效果。其中,在有標點和無標點情況下,P、R、F1及最佳F1值均有不小提升;在有標點訓練中,FLAT+SikuBERT模型在各指標上均略優于FLAT+SikuRoBERTa,比SikuBERT、SikuRoBERTa初始實驗提升了4%左右;在無標點訓練中,FLAT+SikuRoBERTa 除R值外其他指 標 均 優 于 FLAT + SikuBERT 模 型 , 比SikuBERT、SikuRoBERTa初始實驗約提升2%-3%。這個結果表明,有句讀的古籍訓練模型由于有標點的自然分隔,在捕捉上下文信息上,句讀可以作為重要參考特征。但對于中國古代醫學文獻來說,除了《黃帝內經》《傷寒論》《難經》《金匱要略》等重要典籍已經過句讀標注外,仍有很大一部分古籍(尤其是善本)以無標點的文本形式存在。在這種情況下,無標點的訓練模型具有重要的實際使用價值。
4 結論與未來研究
文章以4種古文繁體BERT預訓練模型為基礎,驗證了BERT預訓練模型在古代中醫文獻命名實體識別中的效果,結果顯示:SikuBERT及SikuRoBERTa 能夠直接取得更好的結果。進一步實驗結果表明,在古代中國醫學領域,相關BERT古文模型在添加中醫領域詞向量表達后能取得較理想的實驗效果。在現有中國古文繁體BERT 預訓練模型基礎上,FLAT+SikuBERT 及FLAT+SikuRoBERTa 兩個“預訓練+微調+詞向量”增強模型的效果優于初始SikuBERT、SikuRoBERTa 模型,且能保證中醫術語命名實體的完整性。本文探索了數字人文下我國古代醫學領域文獻的“預訓練+微調”模式適用性,為深度挖掘古代中醫藥知識提供了新的思路與方法。
未來的研究主要關注兩個方面。第一,對于中醫學領域知識的術語實體表達應從多個層面進一步展開。本研究主要以單字術語、詞匯級術語為研究對象,而中醫藥術語中還包括短語結構及句子級命名實體,這部分命名實體的中醫學知識表達并未在詞典中得到充分體現。第二,《黃帝內經》是古代中醫文獻的源頭,《素問》更是完整、體系化地呈現了中醫理論,在此基礎上后世中醫學家不斷豐富并完善中醫理論體系。因此,下一步研究將在現有語料基礎上完成對更多中醫理論典籍的標注,為古代中醫文獻這一特色領域資源積累訓練語料。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中老年保健(2021年12期)2021-11-30 02:58:01
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
攝影之友(影像視覺)(2019年2期)2019-03-05 08:27:14
中華詩詞(2018年11期)2018-03-26 06:41:34
光學精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年8期)2016-10-09 02:11:50
核科學與工程(2015年4期)2015-09-26 11:59:03
中國醫藥科學(2015年19期)2015-02-27 12:33:11
