面向數字人文的典籍語義詞匯抽取研究
——以SikuBERT預訓練模型為例*
2022-09-23 00:58:26孫文龍張逸勤王凡銘魚匯沐劉江峰王東波
圖書館論壇 2022年10期
孫文龍,張逸勤,王凡銘,魚匯沐,劉江峰,王東波
0 引言
2020年11月教育部新文科建設工作組發布的《新文科建設宣言》指出,融入現代信息技術賦能文科教育,新文科建設勢在必行[1]。近10年數字人文在推動古文信息處理研究邁向交叉研究道路上發揮著重要作用,成為新文科建設的熱門話題,為人文學科拓寬問題域,實現研究范式創新與重構人文知識脈絡提供了契機[2-3]。
在大數據時代,信息之于讀者閱讀需求的可得性(Availability)和可及性(Accessibility)均得到空前提升,這與關鍵詞抽取技術的快速發展有著密切關系。關鍵詞是文章主旨的高度凝練,代表特定文獻的主題內容,是人們在閱讀、研究文獻內容時快速判斷是否需要精讀的重要線索。另外,在人們無法快速獲取文本關鍵內容時,關鍵詞抽取還可以幫助其節約時間。在現代漢語文本中,關鍵詞抽取技術已經相對成熟,但古漢語文本相關研究仍處于起步階段。我國古籍浩如煙海,承載著中華優秀傳統文化。因此,利用好關鍵詞抽取技術并對古籍進行整理研究,意義重大。一方面,古籍關鍵詞抽取可以幫助讀者快速了解古籍文本的核心內容;另一方面,該技術還可應用于古籍分類管理,為古籍電子化平臺提供信息檢索、在線查閱、知識關聯等服務。在新文科建設背景下,以數字人文研究為抓手,探索關鍵詞抽取技術在古漢語文本中的實踐路徑,有助于降低古籍文獻閱讀門檻、普及古漢語知識。
1 相關研究
近年隨著深度學習技術及預訓練語言模型發展,研究者開始關注面向數字人文的古籍文本自動處理問題,基于BERT模型框架,構建面向古文智能處理任務的SikuBERT預訓練語言模型的系列研究具有較強的代表性。王東波等基于BERT模型框架,以《四庫全書》全文語料作為無監督訓練集,提出構建“SIKU-BERT典籍智能處理平臺”設想,論述了該預訓練模型較強的古文詞法、句法、語境學習能力和泛化能力[4]。其后涌現一批以SikuBERT預訓練模型為例,專門探討進一步提升古代典籍的自動分詞、詞性自動標注、典籍分類、摘要自動生成、典籍命名實體識別效率的系列研究,通過相關實證實驗研究從多維度探索SIKU-BERT典籍智能處理系統的發展和應用前景[5-9]。然而,在古文典籍關鍵詞提取方面,尚未有驗證SikuBERT預訓練模型的適用性及應用前景的研究。
在關鍵詞自動抽取研究方面,自Luhn提出基于詞頻的關鍵詞自動抽取方法以來[10],經過60多年發展,關鍵詞自動提取方法已經衍生出眾多類別,大體可分為兩類:基于無監督的方法和基于有監督的方法[11]。從現有研究看,以采用TF-IDF 算法、LDA 主題模型和圖模型TextRank算法3種無監督方法的研究為主。
TF-IDF是被廣泛用于自然語言處理領域的經典算法,具有簡潔易實現的特點,對字詞或短語具有很好的分類能力。國外的該算法研究起步早。Salton等針對文本中詞語重要性問題,提出用來評估一個詞對一個文本集合中某一文本的重要程度的TF-IDF 算法[12]。Basili 等提出的TF*IWF*IWF算法提高了特征詞在文檔集合中的權重,一定程度上解決了逆向文檔頻率沒有考慮特征項分布情況的問題[13]。Bong 等提出利用CTD來改進TF-IDF,以改善不同類別的文檔數引起的誤差[14]。國內研究集中在改進TF-IDF算法對現代漢語各類文本的處理能力。許曉昕等提出以主題方式緩存歷史來提高TF-IDF算法對聊天文本的處理能力[15];張建娥探索融合詞語關聯度的TF-IDF改進算法,避免TF-IDF在漢語關鍵詞抽取上產生的偏差[16]。國內外對LDA模型的研究集中于主題挖掘、社交網絡分析等領域。Zhao等構建可同時對用戶和文本進行主題建模的Twitter-LDA 模型,提高文本數據分析準確性[17];Wang 等考慮到網絡文本隨時間變化特點,提出基于時間的變遷主題模型,用于對網絡文本的主題挖掘[18];陳曉美等分析LDA主題模型從海量網絡評論中提取輿情觀點的優勢及路徑[19];陳嘉鈺等利用LDA主題模型和文本挖掘方法探討微信用戶倦怠的潛在主題[20]。較之上述兩種算法,TextRank 在文本處理領域應用更廣泛,計算速度較快,通過構建詞與詞之間的邏輯分布矩陣來抽取文本關鍵詞,是一種有向有權的圖模型。Rahman等將用戶搜索喜好作為特征,基于TextRank算法完善搜索系統的識別和定位功能[21]。張莉婧等設計改進TextRank-CM 算法,該算法在現代漢語文本關鍵詞自動抽取方面的性能表現良好[22]。趙占芳等的發現與之類似,較之經典的TextRank和TF-ID算法,改進后的TextRank關鍵詞抽取算法在準確率、召回率及F值上均有顯著的提高[23]。
綜上所述,在現代漢語文本中,關鍵詞抽取技術研究及其應用已較普遍,但針對篇章相對短小、單字詞較多的古漢語文本而言,關鍵詞抽取技術的研究才剛剛起步。近5年雖然學界對古漢語研究中關鍵詞抽取技術的關注逐漸增多,但仍不足以挖掘和有效呈現古漢語豐富的知識價值。在中國知網中,能夠檢索到的直接以古籍關鍵詞抽取技術為主題的研究僅有1篇[24]。該研究基于關鍵詞抽取的3 種無監督方法,對數字化后的《春秋經傳》進行關鍵詞抽取,對比分析關鍵詞的分布情況和抽取效果后發現,TextRank算法明顯優于其他兩種關鍵詞抽取算法,更適用于針對古漢語典籍的關鍵詞抽取研究。在古籍關鍵詞抽取技術研究領域,該研究具有一定的補白性。然而,TextRank算法對分詞結果有很強的依賴性,即:如果某詞在分詞時被切分成兩個詞,那么在關鍵詞提取時,TextRank僅有部分黏合效果,且要求這兩個詞均為關鍵詞。因此,是否添加標注關鍵詞進行自定義詞典,會導致關鍵詞抽取結果在準確率、召回率的評估方面出現大相徑庭的情況。此外,TextRank模型雖考慮到了詞之間關系,但仍具有抽取高頻詞作為關鍵詞的傾向性。與TextRank算法相比,深度學習模型存在無需預先對語料文本進行分詞等優越性,該算法模型在古文關鍵詞抽取研究領域具有較大的應用前景,值得進一步探索。鑒于尚未有基于BERT模型來提取古文關鍵詞的相關研究,本文采用SikuBERT模型對先秦兩漢的古文典籍進行關鍵詞抽取,選擇具有代表性的“儒家”“史書”兩個子類別古籍作為分析對象,通過對預訓練模型所抽取關鍵詞的文本相似度的分析,探討SikuBERT模型在古漢語文本關鍵詞抽取任務中的技術實現路線與應用前景。
2 實驗設計與流程
2.1 預訓練模型選取
本實驗采用模型為南京農業大學、南京師范大學團隊基于《四庫全書》語料訓練得到的SikuBERT模型。與Google開發的BERT模型相比,該模型在訓練方法的深度、掩碼方式的有效性、輸入表示的全面性等方面均展現出更出色的性能。SikuBERT模型已在古文領域的分詞、斷句、詞性標注、實體識別等任務上得到了實際應用,取得了預期中的實驗效果,為本研究的開展打下了前期研究基礎。本研究的實驗框架包括3個部分,見圖1。
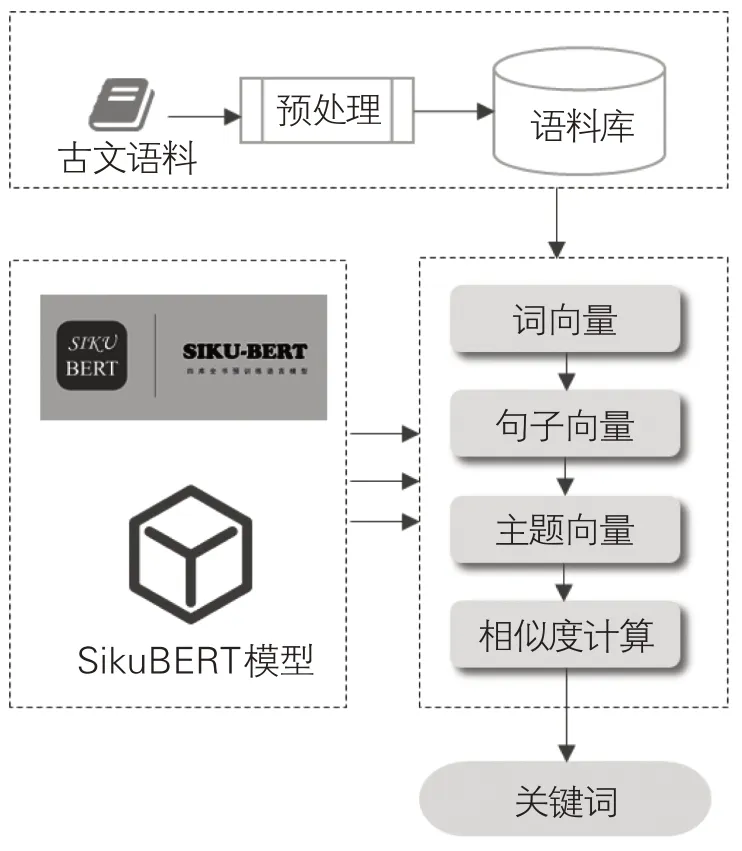
圖1 詞匯抽取實驗框架
2.2 數據描述
典籍語義詞匯抽取任務中的SikuBERT預訓練模型訓練語料來源于網絡資源“中國哲學書電子化計劃”網站①。該網站提供中國歷代傳世文獻,收藏的古籍文本超過3 萬部,文本質量較高,包括中文善本特藏項目中的高質量影印本(如收錄的燕京圖書館500多萬頁歷代中文文獻的影印資料)。該資源站包括“先秦兩漢”“漢代之后”兩大數據庫,每個數據庫下又分設按不同標準建成的子庫。前者依據研究主題細分為13個子庫:儒家、墨家、道家、法家、名家、兵家、算書、雜家、史書、經典文獻、字書、醫學、出土文獻;后者按照時間順序構建魏晉南北朝、隋唐、宋明、清代、民國5 個子庫。本實驗下載“先秦兩漢”全文數字資源作為SikuBERT預訓練模型的數據來源。依據“先秦兩漢”數據庫大規模語料的預訓練任務完成后,為確保最終訓練模型的準確性,選取“儒家”“史書”兩個子數據庫作為SikuBERT預訓練模型下游任務中的語料來源。“儒家”語料庫包括26部古籍②,“史書”語料庫包括19部古籍③。兩類語料在先秦兩漢典籍中占比大,影響力強,具有作為實驗訓練語料的適宜性與合理性。其基本信息及語料樣本分別見表1和圖2。

表1 實驗語料的基本信息

圖2 語料樣本
2.3 實驗流程
(1)獲取文檔向量。SikuBERT模型以字為單位對輸入的中文序列進行分詞,通過模型內置的中文字典將字符映射為數值序列。例如,當模型讀入“風者何謂也?風之為言萌也……”序列時,序列先被模型按字符為單位進行分割,再為每句添加起始標記[CLS]和終止標記[SEP]。通過標記特殊標志位,原始文本被轉換為輸入序列“[CLS],風,者,何,謂,也,[SEP]……”然后模型將自動結合每個字在詞表中相對應的索引值原字符生成詞向量,同時結合詞在句中的位置向量與表示句子類別的分段向量,使得組合向量滿足后續實驗任務的需求。
(2)過濾停用詞。研究選取的基礎停用詞表是包含1,753個詞匯的現代漢語停用詞表,包括數字、符號、標點和無實際意義的詞匯。鑒于研究對象為古漢語文本,在現代漢語停用詞表基礎上,根據齊夫定律對“史書”語料進行詞頻統計,將出現頻次超過1,000次的詞匯認定為高頻詞。從高頻詞與停用詞之間的關系看,高頻詞并不等于停用詞。停用詞多為副詞、助詞、虛詞、代詞等,如“之”“乎”“者”“也”“而”“無”等沒有實際意義的詞匯。經過逐一校對篩選,最終確定將107個詞頻雖高但不具有實際意義的詞語列入停用詞表。之后利用算法,在模型讀取時自動去除文檔中包含的停用詞,降低對最終關鍵詞抽取結果影響。
(3)關鍵詞抽取。此步驟需從文檔中創建一個關鍵詞或關鍵詞列表,詞語長度根據具體實驗進行調整。因古漢語單字的單音節性和多義性,將關鍵詞長設置為1(即單字),暫不考慮雙音節詞或其他類型詞語作為關鍵詞的情況。在抽取方法上,采取基于BERT的Tokenizer方法來實現對文檔中的詞進行向量表達。該方法具有表達能力強、保留原字詞特征等優點,與N元語法詞、詞袋模型等方法相比,注重對上下文語境信息和一詞多義等問題的處理。
(4)相似度計算。文本相似度是預訓練模型計算關鍵詞之于所抽取文檔的代表性數值指標。采用SikuBERT模型的古漢語典籍關鍵詞抽取實驗不同于TF-IDF、LDA主題模型等常規的機器學習算法,其差異點主要體現在關鍵詞抽取方式上,即:SikuBERT模型不是基于詞語的出現頻次,而是通過詞向量與文檔向量的相似度比較結果來確定。
依據上述步驟,在獲取文檔的篇章向量及候選詞向量后,再通過余弦相似度算法依次計算出詞語向量與文檔向量的相似度,按降序排列,選取相似度最高的20個詞作為最終的抽取關鍵詞。
3 實驗結果分析
3.1 模型抽取效果評估
在現代漢語文本關鍵詞抽取任務中,傳統機器學習方法的應用已有不俗表現,但大多數技術路線對復雜的先驗知識有著較高要求。例如,在利用詞匯特征時,過度依賴分詞精度會導致分詞錯誤、詞性錯誤、停用詞錯誤,影響關鍵詞抽取結果的信度。有學者指出,由于古漢語在詞法、句法和語法等方面與現代漢語存在較大差異,將適用于現代漢語的關鍵詞抽取技術直接遷移至古文文本會產生適用性差與精確性無法保證的缺陷[25]。本研究采用的SikuBERT模型是將繁體漢字無注釋與標點版《四庫全書》作為訓練語料得到的預訓練語言模型。由于BERT模型的基礎框架具有雙向transformer編碼器結構的特性,SikuBERT模型在詞向量的訓練中能夠最大程度地保留古漢語文本的原始特征,從而使關鍵詞抽取實驗過程能夠擺脫訓練文本分詞質量的限制。在利用SikuBERT模型對先秦兩漢時期的“儒家”“史書”語料進行關鍵詞抽取后,選擇排序最高的前20個詞作為最終結果。實驗結果表明,SikuBERT預訓練模型能夠較好地適應古漢語文本篇章短小、單字詞多的語言特征,關鍵詞抽取結果大體上反映了相關文本內容的主題特征。
3.2 儒家典籍關鍵詞抽取結果分析
本研究對SikuBERT模型提取出的前20個儒家典籍關鍵詞依次進行語境共現排序(見圖3),從關鍵詞所反映的主題內容看,可以將其分為4類:一是為政類,包括:王、人、廢、下、民、樂、道、尊、世、士;二是修身類,包括:言、身、改、養、長;三是人與他者關系類,包括:蟲、物;四是其他類,包括:子、為、衛。從模型“相似度”計算結果看,上述關鍵詞與所抽文本的相似度介于76%~78%,較好地反映了先秦兩漢儒家典籍的主題內容。
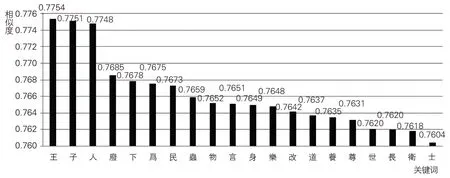
圖3 儒家典籍關鍵詞抽取結果
第一類關鍵詞與儒家治國理政思想密切相關。從“王”(6,698次)的語境信息看,語境分布大致分為兩大類:以“圣王(或先王)”或是以“楚王、魏王、齊王、秦王、晉王”等為代表的君主。與前者相關的主題以頌揚堯、舜、禹、商湯、周文王和周武王的仁德為主,與后者相關的主題多探討先秦諸侯或君王“德”“位”匹配情況。雖然敘事視角不同,但兩個主題圍繞著一個共有內核,即王道政治。孔子所講“先王之道,斯為美,小大由之”(《論語·學而》),孟子建言梁惠王等所效法的“王天下”之道(《孟子·梁惠王下》),以及荀子論述的“王者之人”“王者之制”“王者之論”“王者之法”4個概念,共同構成一條理解儒家王道思想的線索。其他9個關鍵詞均與“王”字所揭示的主題有著直接或間接的聯系。具體而言,“人”字多出現在寡人、人君、人臣、庶人、賢人、仁人、人心、擇人、取人等語境中,話題多與君臣關系和用人之道有關;“人”還較多地出現在周人、殷人、秦人、齊人、楚人、燕人、晉人、魯人、宋人、鄭人等語境中,通過對各國外交、軍事和民風等方面的評述來說明治國之道。“廢”的語境共現信息雖然偏少(414次),但其是唯一一個從反面來揭示儒家王道理想的關鍵詞。例如,“長幼之節”“君臣之義”的倫理綱常不可廢(《論語·微子》),刑罰和慶賞不可廢(《中論·賞罰》),禮樂不可廢(《荀子·樂論》),王道不可廢(《新書·過秦中》)。這可能是SikuBERT模型提取該字作為關鍵詞的重要原因。“下”的語境共現信息有5,783次,近一半出現在“天下”語境中,另有較多的語境與“序上下”有關,如“君臣上下父子兄弟,非禮不定”(《新書·禮》)、“明別上下之倫”(《春秋繁露·度制》),均與君臣之禮和教化民眾有密切關系。其他幾個關鍵詞的主要語境信息也均與儒家倡導的王道政治相關:“民”與儒家民本思想有關;“樂”多與始自夏商的禮樂制度相關;“道”的語境共現信息較多體現了“天道”“先王之道”(或“王道”)方面的內容信息;“尊”較多地出現在尊王和尊上的語境中;“士”的語境分布最為集中,主要圍繞“何如斯可謂之士矣?”(《論語·子路》)這一問題展開,體現了春秋時期的尚士傳統;“世”的語境多與王道的傳承有關。篇幅所限,上述幾個關鍵詞不再逐一展開論述。另外,值得注意的是,10個關鍵詞并不是孤立存在的,相互之間存在著或多或少的聯系,其中“王”起著提綱挈領的作用,其他9 個關鍵詞各有側重,可以從不同方面揭示儒家王道思想的內涵。
第二類關鍵詞與個人修養有關。在此類5個關鍵詞中,從數據看,“言”“身”的語境共現頻次最多,分別為5,369次和1,837次,與總文本的相似度也分列第一、二位,均接近76.5%,較之其他幾個關鍵詞,體現出“言”“身”在該類關鍵詞中的統攝地位。具體而言,常與“言”共現的字詞有“信、行、禮、德、仁、君子、篤敬”等,主題思想是做人要多做實事,少講空話,這是君子的立身之本之一。“身”字則對古人的身心修養之道做了多維性描述。該字常出現在“察身、省身、修身、治身、正(其)身、為身、身行、身正”等語境信息中,明顯體現出古人對正身修德的重視,相關例證在《論語》《春秋繁露》《潛夫論》《韓詩外傳》《新序》《荀子》等典籍中均有較多體現。“改”字的語境信息較少(417次,在該類5個關鍵詞中出現頻次最低),但其是唯一一個從反面來體現儒家對修身立德的態度,即“過則勿憚改”(《論語·學而》)與“過而不改,是謂過矣”(《論語·衛靈公》),這與“身”字所體現的主題之一“自省”是相照應的。“養”“長”均與儒家所倡導的倫理道德規范相關。“養”與孝道有較大關聯,如“今之孝者,是謂能養。至于犬馬,皆能有養。不敬,何以別乎?”(《論語·為政》);“長”主要指“長幼之序”,與“君臣之義”“父子之親”“夫婦之辨”(《說苑·貴德》)共同構成了儒家倫理思想體系的要義。
第三類關鍵詞較多體現了人與他者的關系。在儒家的三維哲學中,“天一,地二,人三”是最常見的思維方式。SikuBERT 模型提取的“蟲”“物”兩個關鍵詞集中體現了該類內容主題。“蟲”字的語境信息主要出現在《春秋繁露》(“五行逆順”篇和“治亂五行”篇)、《大戴禮記》(“夏小正”“易本命”“曾子天圓”篇)、《論衡》(“商蟲”“物勢”“無形”“順鼓”“遭虎”“龍虛”“感虛”“別通”篇,“商蟲”篇中最多)、《孔子家語》(“執轡”篇最多)、《禮記》(“月令”篇最多)中,其他儒家典籍中也有部分語境信息(如《說苑》“辨物”“修文”篇)。在上述篇目中,“蟲”是儒家“考日月星辰”與“知幽明之故”的通達路徑之一,因為在他們看來:“萬物鳥獸昆蟲,各有奇偶,氣分不同,而凡人莫知其情,唯達道德者能原其本焉。”(《孔子家語》“執轡”篇)。“物”字的語境共現信息能夠反映出儒家對外部世界的基本看法,也體現了改造外部世界的實踐取向。“物”的初始含義是“大共名也”(《荀子·正名》),即物是一個最大的類,作為“自我”的人和“他者”的非人都在其內。但在具體討論人與世界關系時,往往要將二者剝離開來。例如,《大戴禮記·誥志》中講到“天生物,地養物,物備興而時用常節曰圣人”,就是從天地人的三維哲學觀來探討其對物的理解。整體看,儒家對“物”持較為中庸的看法:一方面承認人主觀能動性的有限性,贊同“善假于物”(《荀子·勸學》)的實踐方式,另一方面又從德化角度對人的物欲進行約束,如孟子所提及的“親親而仁民,仁民而愛物”。
第四類關鍵詞在揭示儒家典籍內容主題方面呈現出一定的離散性,故將之歸入其他類。首先,“子”被抽取為關鍵詞的一個重要因素在于其語境信息頻次較高(20,565次)。該字主要出現在“子曰”(3,299次)、“孔子”(2,772次)、“君子”(2,578 次)、“天子”(1,774 次)、“夫子”(653 次)、“孟子”(436 次)、“曾子”(471 次)、“之子”(339次)、“父子”(240次)等語境中。顯然,造成“子”指代多樣性的主要原因與本研究僅提取單字詞有著直接的關系。其次,“為”字被提取為關鍵詞的原因更為復雜:一方面該字的語境信息頻次較高(13,747 次),另一方面讀音、詞性和用法多樣,導致一詞多音多義問題,SikuBERT模型無法處理此類問題。例如,“為”讀wéi時,僅用作動詞時就包含多個含義:“見義不為,無勇也”(《論語·為政》)中意為“做、干”;“為政以德”(《論語·為政》)中作“掌管、治理”。同時,“為”還用作連詞和語氣助詞。再考慮到其讀wèi,作動詞(言說、告訴)和介詞(因為、由于)的用法時,SikuBERT模型在提取古文關鍵詞時面臨的情況會更加復雜。因此,盡管“為”字所展示的儒家典籍主題內容并不明確,但受上述兩個方面的影響,SikuBERT模型仍將其識別為儒家典籍關鍵詞。“衛”的語境信息相對單一,近90%語境信息與衛國有關。該字被抽取為關鍵詞的一個主要原因可能在于其與孔子的關系較為密切。公元前497年,孔子55歲,開始周游列國,第一站便是衛國;孔子周游在外14年,近一半時間居住在衛國,衛國之于孔子的重要性不言而喻,這從《論語》記載的許多與衛國有關的事例即可管窺一二。如“魯衛之政,兄弟也”“富之”“教之”(《論語·子路》)、“吾未見好德如好色者也”(《論語·子罕》)等均與衛國密切相關。
綜上,上述4類關鍵詞中,前三類能夠大體展現出先秦兩漢儒家典籍的主題內容,第四類僅能為讀者提供一些了解儒家典籍的認知線索,在揭示主題內容方面呈現出明顯的離散性。究其原因,這一方面與部分古漢語字詞語義和用法的復雜性有關,另一方面也與SikuBERT模型僅抽取單字詞的人文計算方法相關。
3.3 史書典籍關鍵詞抽取結果分析
通過逐一檢索圖4 中關鍵詞的語境共現信息,依據其揭示的內容主題,可將20個史書典籍關鍵詞大致分為五類:國別史類,包括:衛、吳、曹、梁、魏、趙;皇族類,包括:公、王、長、立、元、宮、家;軍事類,包括:武、擊;歷史人物類,包括:子、厲、樊;其他類,包括:為、皆。上述關鍵詞與所抽史書文本的相似度為74%~78%,整體上略低于前文SikuBERT模型有關儒家典籍文本的相似度計算結果。究其原因,這可能與儒家典籍的主題多與抽象的理念相關(如治國和修身),文本主題思想相對一致;相比之下,先秦兩漢時期的史書文本所載內容更為具象,歷史事件常與某一國家、某一時期或某一特定人物緊密聯系在一起。因此,史書類關鍵詞所展現的內容主題也具有更大的離散性。
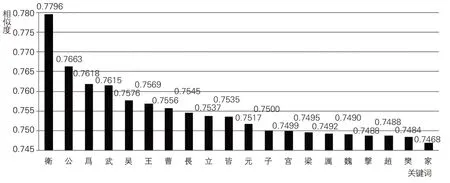
圖4 史書典籍關鍵詞抽取結果
第一類關鍵詞主要展現春秋戰國時期部分諸侯國的歷史。在20個關鍵詞中,“衛”與文本的相似度最高(約78%)。一方面,從語境信息分布看,這可能與“衛”的主題內容相對集中有著較大關系。該字語境共現信息共計2,441條,其中約80%語境與衛國相關。例如,衛君、衛侯、衛公、衛世子蒯聵、衛靈公、衛穆公、衛繆公、衛定公、衛恒公、衛孫良夫、衛世叔齊、衛公孟彄、侵(圍)衛、衛地、衛人、衛師(兵)等,內容主要涉及衛國的政治、軍事和外交。另一方面,從衛國興衰看,這也可能與其特殊的歷史地位有關。衛國是周朝姬姓諸侯國之一,從立國至滅國出現41位國君,共計907年。在強敵環伺的春秋戰國時期,衛國多次躲過滅國之險,可謂國運多舛,這在先秦史書中有較多記載。例如,成候三年(公元前372 年),趙國“伐衛,取鄉邑七十三”(《史記·趙世家》);懷君三十一年(公元前254 年),“魏囚殺懷君”(《史記·衛康叔世家》)。衛國一直生存到秦二世時期:“始皇既并天下,猶獨置衛君,二世時乃廢為庶人”(《漢書·地理志》)。衛國是周朝姬姓諸侯國中最后被秦滅亡的國家,這既是奇跡,也反映了先秦時期的政治生態——軍事上弱肉強食,道統上宗周為正。衛國雖小,卻成為春秋戰國時期大國之間博弈的重要棋子,這可能是“衛”這一關鍵詞與文本相似度最高的主要原因之一。其他幾個關鍵詞的語境信息分別如下:“吳”主要與《越絕書》《吳越春秋》《國語》中的《吳語》《越語》相關,反映的主題集中在吳越地區的政治、經濟和軍事方面,尤其是吳越爭霸的史實最豐富。“曹”語境約有40%與曹國相關,集中在《春秋谷梁傳》《春秋公羊傳》兩部典籍,主要共現語境關鍵詞有(圍)伐曹、救曹、入曹、過曹、滅曹、曹師、曹人、曹叔振鐸、曹伯、曹伯陽等,主題內容反映了統治集團如何利用禮義教化和宗法情誼來緩和內部矛盾。“梁”語境有近三分之一出現在《戰國策》《史記》中,梁國自建國到滅亡僅130年,是春秋戰國時期諸侯割據一方、戰事紛爭不斷的縮影。“魏”字的語境共現信息共3,013條,約83%與魏國相關,集中出現在《戰國策》《國語》《史記》《漢書》四部典籍中。從其反映的主題內容來看,魏國與春秋戰國時期的各個國家幾乎均有交集,《戰國策》中有關魏國的記載就是一個典型例證:在該典籍中,“魏”主要出現在東周策(一卷)、西周策(一卷)、秦策(五卷)、齊策(五卷)、楚策(四卷)、趙策(四卷)、魏策(四卷)、韓策(三卷)、燕策(三卷)、宋衛策(一卷)和中山策(一卷)中,涉及《戰國策》三十三卷中的三十二卷。此外,《史記》中有關魏國記載的《魏世家》《晉世家》《衛康叔世家》《周本紀》《秦本紀》《魏公子列傳》《蘇秦列傳》《春申君列傳》《商君列傳》等則是另一佐證。簡言之,魏與周、晉、齊、楚、燕、韓、趙、齊、秦、宋、衛等國之間的關系得到充分展示。與“魏”相比,“趙”字的語境信息更加豐富(4,444次),約78%信息與趙國有關,但涉及的主題內容不如“魏”廣泛,更多地集中在“趙”與晉、楚、齊、韓、魏、燕、秦之間的關系上。
第二類關鍵詞表明先秦歷史較多關注皇族政治和宮廷生活。“公”主要指王朝大臣或諸侯,如衛靈公、秦惠公、齊景公。“王”是諸侯在其封地的稱號,如越王勾踐、定陶王、秦昭王、楚成王。“長”語境共現信息多與官職名有關,如左庶長、長史、丞長、禮樂長、署長。“立”較多出現在立君、立為王、立皇后等語境中。“元”多用在年號或紀年、諸侯謚號等語境中,如元帝庶孫、元延四年、永建元年、許元公。“宮”多與宮廷生活相關,如太子之宮、長信宮、內宮、東宮、后宮。“家”是和“國”相對應的一個概念:先秦時期諸侯的封地為國,大夫的封地稱家。從“家”語境共現信息看,語境多出現在皇家、世家、漢家、太子家、王家、國家等語境中,《史記·班彪列傳上》中所述“都都相望,邑邑相屬,國藉十世之基,家承百年之業”可以說是對先秦史書中“家”概念的最好注解之一。
第三類關鍵詞以“武”“擊”為代表,展現先秦時期(尤其是春秋戰國時代)各諸侯國之間相互征伐的軍事活動,以及漢朝時期抗擊匈奴的戰爭。例如,武王克殷、揚武將軍、武威將軍、武夫、揚威武、擊韓之新城、擊秦、擊趙、擊楚軍、擊匈奴、擊漢軍、擊殺。《竹書紀年》記載了夏朝至戰國時期所發生的血腥政變和軍事沖突,即使是在周王朝所奉行的禮治時代,軍事征伐也是主題,如《穆天子傳》前五卷詳述周穆王率師南征北戰盛況。《越絕書》《逸周書》《吳越春秋》《國語》《戰國策》等典籍中所記載的君權之爭、諸侯爭霸、強國謀略和戰爭過程等內容更加豐富。
第四類關鍵詞與先秦兩漢時期的著名歷史人物有著密切的關系。“子”的語境共現信息多達25,630 次,集中在天子、太子、弟子、臣子、父子、孔子、子曰等語境中,其中與孔子相關的語境信息最多(2,253 次),這一點與前文中“子”在儒家典籍中也被抽作關鍵詞的情況有相似之處,其原因可能有兩點:一是儒家典籍與史書典籍存在交叉之處,如《春秋谷梁傳》《春秋公羊傳》既屬于儒家典籍,也可劃入史書范疇;二是先秦兩漢時期的正史與儒家思想有著密切關系,“孔子”是兩者耦合的一個關鍵節點,即時常通過引用孔子的言論以達到針砭時政的目的,如《史記·酷吏列傳》中的“孔子曰:‘導之以政,齊之以刑,民免而無恥。導之以德,齊之以禮,有恥且格’”。《漢書·地理志》中的“繇文翁倡其教,相如為之師,故孔子曰:‘有教亡類’”等均為典型例證。“厲”和“樊”的語境共現信息偏少,前者有651 條信息,后者僅389條。從語境分布看,“厲”有123條語境信息有明確指代,即周厲王,其他語境信息較分散,尚無明確的主題。在先秦史中,周厲王是處于歷史轉折期的關鍵人物之一,周王室自其始逐漸走向衰微,多數史書均有記載。例如,“下至幽、厲之際,朝廷不和,轉相非怨,詩人疾而憂之曰:‘民之無良,相怨一方’”(《漢書·楚元王傳》)。“樊”字有約88%的語境信息作為姓氏,如樊姬(楚莊王夫人)、樊遲、樊噲、樊豐、樊于期、樊陵、樊崇、樊稠、樊鯈、樊宏、樊曄、樊重、樊準等,其中有關樊噲的描述最多,占到全部語境信息的三分之一(113條)。此外,對樊鯈開創的“樊侯學”,參與荊軻刺秦的樊于期的著墨也較多,以歷史人物為觸角,生動展示了先秦兩漢時期的歷史畫卷。
第五類關鍵詞未能展示先秦和兩漢時代的歷史特點與社會風貌,“為”和“皆”被抽取為關鍵詞的重要原因在于其多義性和常用頻次高。“為”的語境共現信息共計36,052條,其信息量在20個關鍵詞中位居首位,但該字詞性和語義多變,如作動詞時具有“種植,耕作”“以為,認為”“掌管,治理”等含義,還常用作連詞(和,表示并列關系)、助詞(的,用于名詞性偏正結構中)、介詞(被)。這與“為”在儒家典籍中被抽為關鍵詞的原因相同。“皆”的語境信息多達7,610條,意義較單一,絕大多數用作副詞,意為“都(是),一同”。簡言之,以“為”“皆”為代表的多義詞,具有搭配能力強、使用頻次高的特點,目前SikuBERT模型尚不能有效識別和處理該類字詞。另外,現階段亦無專門針對古文的停用詞表,這也是造成“為”和“皆”被模型識別為關鍵詞的另一重要原因。
從上述分析看出,利用SikuBERT模型的儒家和史書典籍關鍵詞抽取結果既存在明顯差異,也呈現出相似之處。相似之處主要體現在二者存在一些共同關鍵詞——王、長、子、衛、為。其中,“子”“衛”在兩類典籍中的語境共現信息基本相同,均與孔子和衛國相關,展現了孔子思想的影響力和衛國在春秋戰國時期的特殊歷史地位。“王”和“長”的語境信息則各有側重:在儒家典籍中,“王”與先王之道的王道思想密切相關,“長”多與“長幼之序”和“尊長”的儒家倫理有關;在史書類典籍中,“王”和“長”的語境信息更側重于展現較為具象的皇族生活和官場體制。“為”字因其詞性多變、語義復雜和搭配能力強的特點,雖然在兩類典籍中均有大量的語境共現信息,但并未有效揭示主題內容。
4 結論與展望
將關鍵詞抽取技術應用于古漢語典籍研究中不僅可以拓寬數字人文領域的發展廣度與深度,而且能夠有效加深研究者對古漢語文本內容的主題挖掘,進而推動中國古籍知識的傳播和普及。本文通過實驗設計,以先秦兩漢時期的“儒家”和“史書”文獻為研究和分析對象,探究了SikuBERT模型在古漢語文本關鍵詞抽取任務中的適用性和應用前景,為未來進一步構建面向古籍研究的深度學習預訓練模型提供有益參考。
在后續研究中可進一步展開以下工作:(1)提升對古漢語中單字與雙字詞的識別和區分。本研究中,抽取關鍵詞的詞長被設定為1,可能會導致雙字詞被機械切分成單字后不能有效體現相關古文信息的真正主題。比如,“中庸”和“君子”被切分成“中”“庸”“君”“子”,失去了術語的原意。(2)加強對多音、多義和跨詞性單字詞的識別和處理,從而避免抽取出以“為”和“皆”為代表的、與文本主題內容不相關的關鍵詞。(3)開發專門針對古漢語的停用詞表。下一步研究可通過迭代多次補充停用詞表和重復抽取關鍵詞,同時輔以結合專家知識的人工篩選方式,避免抽取出無效關鍵詞,從而達到提高關鍵詞文本相似度的目的。
注釋
①訪問地址:https://ctext.org/confucianism/zhs.
②分別是:《白虎通德論》《蔡中郎集》《春秋繁露》《大戴禮記》《獨斷》《風俗通義》《韓詩外傳》《孔叢子》《孔子家語》《禮記》《論衡》《論語》《孟子》《潛夫論》《申鑒》《說苑》《素書》《太玄經》《孝經》《新書》《新序》《新語》《荀子》《揚子法言》《中論》《忠經》。
③分別是:《春秋公羊傳》《春秋谷梁傳》《東觀漢記》《古三墳》《國語》《漢書》《后漢書》《列女傳》《穆天子傳》《前漢紀》《史記》《吳越春秋》《西京雜記》《鹽鐵論》《晏子春秋》《逸周書》《越絕書》《戰國策》《竹書紀年》。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
社會科學戰線(2022年4期)2022-06-15 03:23:36
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
原道(2019年2期)2019-11-03 09:15:12
制造技術與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
光學精密工程(2016年6期)2016-11-07 09:07:19
小學教學參考(2015年20期)2016-01-15 08:44:38
天府新論(2015年2期)2015-02-28 16:41:23
