基于模糊貝葉斯決策的核心概念抽取方法*
2022-09-21 08:36:34徐藝嘉孫旌睿
計(jì)算機(jī)工程與科學(xué) 2022年9期
鐘 寒,徐藝嘉,鹿 浩,孫旌睿
(1.中國人民公安大學(xué)信息網(wǎng)絡(luò)安全學(xué)院,北京 102623;2.安全防范與風(fēng)險(xiǎn)評(píng)估公安部重點(diǎn)實(shí)驗(yàn)室,北京 102623)
1 引言
本體[1]包含著豐富的語義信息,是一種重要的知識(shí)庫,是智能信息檢索[2]、自然語言處理、信息建模、語義Web和信息抽取[3]等領(lǐng)域應(yīng)用的基礎(chǔ)。在當(dāng)前的人工智能領(lǐng)域中,本體技術(shù)也是研究熱點(diǎn)之一。根據(jù)需求建立的領(lǐng)域本體能有效進(jìn)行知識(shí)表示,通過概念、屬性和概念之間的關(guān)系以及各種約束對(duì)特定領(lǐng)域的知識(shí)進(jìn)行細(xì)致描述,可以表示成某一特定領(lǐng)域內(nèi)的特定知識(shí)。領(lǐng)域概念是領(lǐng)域本體的重要組成部分,如何從文本中準(zhǔn)確地抽取核心概念是構(gòu)建本體的前提和基礎(chǔ)。
隨著大數(shù)據(jù)的迅速發(fā)展,各領(lǐng)域產(chǎn)生了大量的文本,構(gòu)建本體時(shí)需要從大量文本中將需要的概念抽取出來。然而,在大量概念中,部分概念在文本所屬領(lǐng)域具有一定的代表性,另外一部分概念與文本領(lǐng)域關(guān)聯(lián)性較低。為方便描述,本文將在文本所屬領(lǐng)域中具有代表性的概念統(tǒng)稱為核心概念。
綜上所述,領(lǐng)域概念對(duì)本體構(gòu)建有著重要的作用,而文本是領(lǐng)域概念的主要來源,文本的核心概念抽取又是其中的一個(gè)關(guān)鍵環(huán)節(jié)。基于此,本文以領(lǐng)域核心概念的自動(dòng)抽取為研究目標(biāo),提出了一種基于模糊貝葉斯決策的文本核心概念抽取方法。該方法借鑒了傳統(tǒng)文本概念抽取的流程,對(duì)文本中概念特征進(jìn)行重要性排序,能夠較為精準(zhǔn)地抽取文本中的核心概念。
2 相關(guān)工作
概念抽取是知識(shí)庫構(gòu)建的第一要素,依賴于知識(shí)抽取等相關(guān)技術(shù),當(dāng)前國內(nèi)外的研究大多集中在關(guān)鍵詞提取方面。關(guān)鍵詞提取方法分為有監(jiān)督和無監(jiān)督2類[4],包括基于統(tǒng)計(jì)機(jī)器翻譯的方法、基于序列標(biāo)注模型的方法[5]、基于排序?qū)W習(xí)的方法[6]和基于機(jī)器學(xué)習(xí)的分類方法等。近年來,深度學(xué)習(xí)模型在概念抽取任務(wù)上也得到了廣泛應(yīng)用。常用的關(guān)鍵詞提取方法包括樸素貝葉斯、決策樹、最大熵算法和支持向量機(jī)等,都需要大量數(shù)據(jù)來訓(xùn)練分類器。Wang等人[7]采用長(zhǎng)短期記憶LSTM(Long Short-Term Memory)神經(jīng)網(wǎng)絡(luò)和卷積神經(jīng)網(wǎng)絡(luò)CNN(Convolutional Neural Network)作為分類器提出了深度學(xué)習(xí)模型;趙洪等人[8]提出了深度學(xué)習(xí)模型Bi-LSTM-CRF,將中文文檔中每個(gè)詞的詞向量和詞性特征作為輸入,提升概念的抽取效率。通過機(jī)器學(xué)習(xí)進(jìn)行概念的抽取是當(dāng)前研究的熱點(diǎn)。Yuan等人[9]使用10種常見的統(tǒng)計(jì)數(shù)據(jù)作為訓(xùn)練的特征,提出了一種機(jī)器學(xué)習(xí)方法,不同語料庫上的測(cè)試對(duì)比表明,該方法在概念抽取方面具有較高效率。丁澤源等人[10]在中文生物醫(yī)學(xué)領(lǐng)域基于深度學(xué)習(xí)提出了一種生物醫(yī)學(xué)實(shí)體關(guān)系抽取系統(tǒng),可以準(zhǔn)確地從中文文本中抽取實(shí)體及關(guān)系。有監(jiān)督提取方法的預(yù)處理代價(jià)大,且依賴于人工標(biāo)注和分類器特點(diǎn)。
無監(jiān)督提取方法通過對(duì)無標(biāo)記的數(shù)據(jù)進(jìn)行學(xué)習(xí),能夠發(fā)現(xiàn)數(shù)據(jù)中隱藏的結(jié)構(gòu)性知識(shí),泛化能力強(qiáng)。因此,對(duì)于關(guān)鍵詞提取的研究主要集中于使用無監(jiān)督抽取方法。無監(jiān)督方法包括基于簡(jiǎn)單統(tǒng)計(jì)、基于圖和基于主題的方法3類。在抽取準(zhǔn)確率方面,一些研究人員采用外部資源包括參考語料庫、維基百科等來提高概念抽取的準(zhǔn)確率,Lopes等人[11]通過采用候選術(shù)語與出現(xiàn)的參考語料庫頻率來評(píng)估候選概念的領(lǐng)域特點(diǎn);Mykowiecka 等人[12]通過參考語料庫和短語的上下文提出了過濾不相干短語的方法,但是一些領(lǐng)域并沒有可用的外部資源;夏天[13]通過word2vec生成詞向量,融合維基百科文檔,根據(jù)詞語與聚類質(zhì)心的距離對(duì)詞語重要性加權(quán),進(jìn)而構(gòu)建新的概率轉(zhuǎn)移矩陣;方俊偉等人[14]通過引入學(xué)術(shù)資源數(shù)據(jù)庫構(gòu)建領(lǐng)域詞表,生成候選關(guān)鍵詞集合[15]。
綜上所述,基于深度學(xué)習(xí)的概念抽取方法在處理文本規(guī)模較大的任務(wù)時(shí)表現(xiàn)較優(yōu),具有較高的準(zhǔn)確性和較強(qiáng)的穩(wěn)定性,但其依賴復(fù)雜的學(xué)習(xí)模型,導(dǎo)致跨領(lǐng)域泛化力相對(duì)弱,且需要大量的標(biāo)注數(shù)據(jù)和較長(zhǎng)的訓(xùn)練時(shí)間。這些方法都將概念抽取視為一個(gè)二分類的問題,同時(shí),在標(biāo)注的過程中涉及到的標(biāo)注的復(fù)雜性和主觀性都關(guān)系到最后的質(zhì)量,進(jìn)而影響模型性能。針對(duì)以上問題,結(jié)合文本概念的專業(yè)性特點(diǎn),本文采用模糊貝葉斯決策對(duì)傳統(tǒng)核心概念抽取方法進(jìn)行改進(jìn)。首先,隨機(jī)選取大量文本進(jìn)行分詞對(duì)詞匯進(jìn)行篩選優(yōu)化處理;其次,結(jié)合詞頻-逆向文件頻率TF-IDF(Term Frequency- Inverse Document Frequency)和信息熵對(duì)分詞進(jìn)行特征值計(jì)算,提出概念隸屬度,根據(jù)詞匯的概念隸屬度進(jìn)行排序;最后,抽取到核心概念詞匯,同時(shí)結(jié)合機(jī)器學(xué)習(xí)方法提高概念抽取效率。為避免人工標(biāo)注的主觀失誤影響模型效果,本文以傳統(tǒng)抽取方法得出的結(jié)果作為語料庫來訓(xùn)練和驗(yàn)證本文方法的準(zhǔn)確率和效率,將本文方法與傳統(tǒng)抽取方法對(duì)比以優(yōu)化本文方法中的各項(xiàng)參數(shù),使其達(dá)到最優(yōu)效果。
3 基于模糊數(shù)學(xué)的核心概念抽取方法
本文核心概念抽取主要包括3個(gè)階段:數(shù)據(jù)預(yù)處理階段、核心概念抽取階段和算法優(yōu)化處理階段。數(shù)據(jù)預(yù)處理階段通過分詞、去停用詞和詞性過濾得出候選詞;核心概念抽取階段基于TF-IDF進(jìn)行詞匯的二元指標(biāo)特征統(tǒng)計(jì),提出了概念隸屬度并且計(jì)算各候選詞的概念隸屬度進(jìn)而抽取核心概念,同時(shí)通過混淆矩陣驗(yàn)證概念隸屬度方法抽取的核心概念的準(zhǔn)確率;在算法優(yōu)化處理階段通過貝葉斯分類器及BP神經(jīng)網(wǎng)絡(luò)搭建對(duì)比模型,得出最優(yōu)實(shí)驗(yàn)結(jié)果。整體框架如圖1所示。
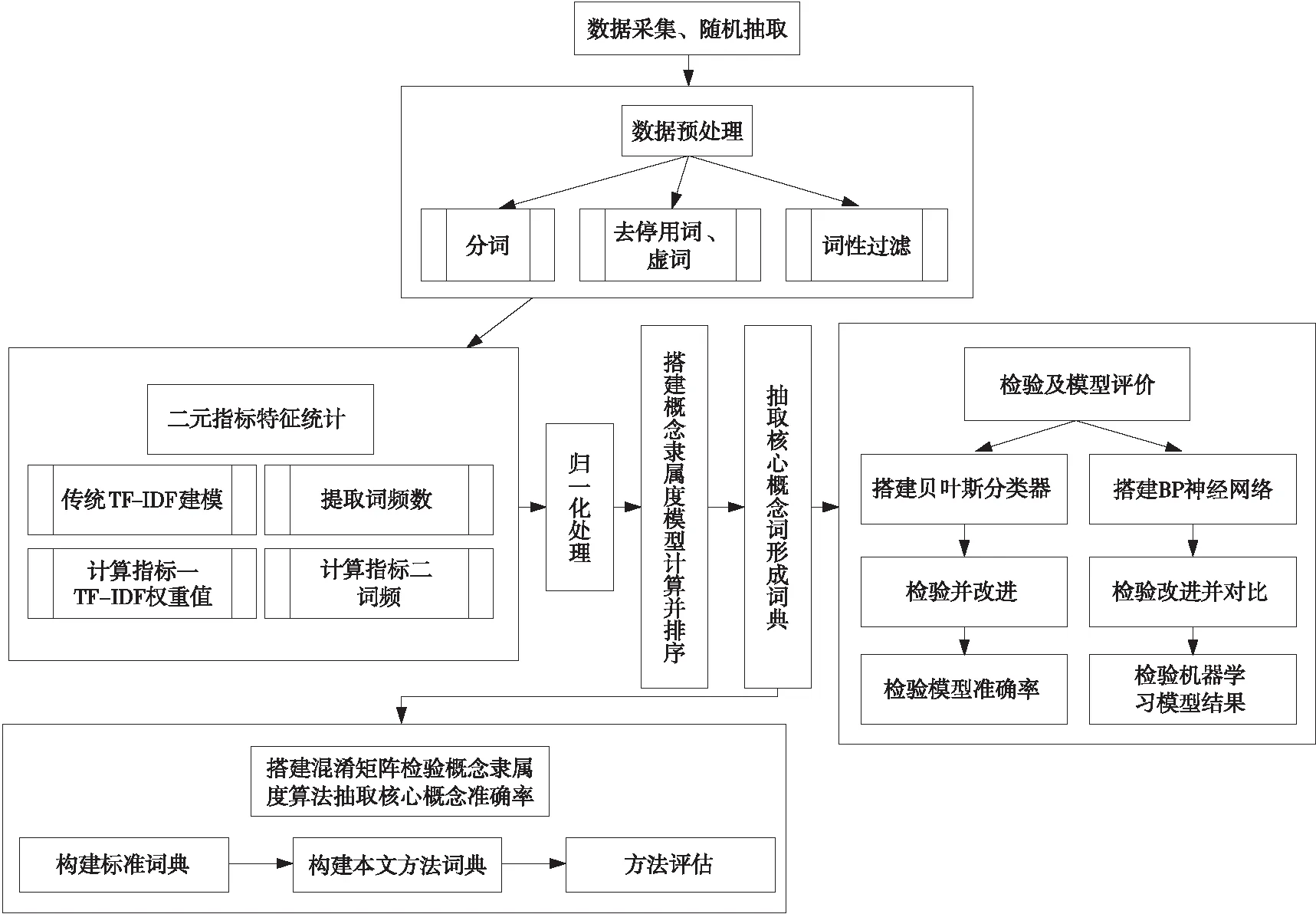
Figure 1 Framework of text core concept extraction method based on fuzzy Bayesian decision-making圖1 基于模糊貝葉斯決策的文本核心概念抽取方法框架
3.1 基于模糊數(shù)學(xué)的概念隸屬度
在進(jìn)行概念抽取之前,首先需要過濾得到候選概念。候選概念通常是由名詞或者帶有形容詞、副詞等修飾詞的短語組成[16],它們是待處理語料中具有代表性的概念。為了提升抽取的效率和準(zhǔn)確率,本文采用自然語言處理技術(shù)將候選概念從文本中提取出來。首先,調(diào)用Python中的jieba分詞工具進(jìn)行分詞和詞性標(biāo)注;然后,去停用詞和虛詞;接著,利用jieba分詞進(jìn)行詞頻統(tǒng)計(jì)并將候選概念降序排列;最后,根據(jù)概念詞的定義對(duì)詞性進(jìn)行過濾,得到最終的候選概念集。
本文采用模糊綜合評(píng)價(jià)法,引入模糊統(tǒng)計(jì)對(duì)影響概念的各個(gè)因素是否應(yīng)歸納為核心概念做出科學(xué)評(píng)判[17]。根據(jù)概念詞頻和詞頻-逆向文件頻率,提出一種概念的模糊關(guān)系表示,建立更為科學(xué)合理的隸屬關(guān)系。
為了描述概念的不確定性,本文以文獻(xiàn)[18]的模糊概念格為基礎(chǔ),引入概念隸屬度,給出概念隸屬度的定義,將概念與概念詞頻、詞頻-逆向文件頻率等屬性的關(guān)系推廣到模糊關(guān)系,實(shí)現(xiàn)概念與屬性間非確定性關(guān)系的模糊表示。通過分析發(fā)現(xiàn),概念的詞頻特征和詞頻-逆向文件頻率這2個(gè)因素越高的概念,屬于核心概念的概率越大。
通常情況下,一個(gè)概念的詞頻越大,說明它出現(xiàn)的頻率越高,也可以說明這個(gè)概念越重要,這些都反映了該概念屬于核心概念的概率大小。通過挖掘概念的詞頻權(quán)重和TF-IDF權(quán)重,有助于定量分析概念屬于核心概念的概率,從而實(shí)現(xiàn)概念與特征間的模糊決策。在文獻(xiàn)[19]的基礎(chǔ)上,結(jié)合詞頻權(quán)重和TF-IDF權(quán)重獲取概念出現(xiàn)的頻率,并計(jì)算該詞的特征值。在經(jīng)過歸一化處理后,得到概念-特征模糊矩陣。概念隸屬度的計(jì)算過程描述如下:首先,對(duì)文本進(jìn)行預(yù)處理獲得候選概念集D;然后,計(jì)算概念的詞頻權(quán)重wTF和TF-IDF權(quán)重wTF-IDF;最后,通過歸一化方式將值標(biāo)準(zhǔn)化,得到概念s在概念集D中不同概念的模糊隸屬度。規(guī)定隸屬度越大,概念屬于核心概念的概率越大。概念s在概念集D中的權(quán)重w值及歸一化計(jì)算如式(1)所示:
w=wTF×FTF+wTF-IDF×FTF×FIDF=
(1)
其中,F(xiàn)TF表示概念s在文檔di中出現(xiàn)的概率,F(xiàn)IDF表示逆向文本頻率,fs,i表示概念s在文檔di中出現(xiàn)的次數(shù),ND表示概念s出現(xiàn)在背景語料中的文檔數(shù),N表示背景語料的文檔總數(shù)。那么概念隸屬度μ(s,c)的計(jì)算如式(2)所示:
(2)
其中,μ(s,c)表示標(biāo)準(zhǔn)化后的概念s關(guān)于特征c的概念隸屬度,ts表示權(quán)重w標(biāo)準(zhǔn)化之后的值,tsmax是向量值中的最大值,tsmin是向量值中的最小值。
設(shè)定三元組K=(S,C,R)為一個(gè)模糊形式背景,其中,S為概念集,C是概念的特征集,R是S*C上的一個(gè)模糊關(guān)系。如果關(guān)系集中的任意元素,均存在一個(gè)映射,使得s∈S,c∈C滿足μ(s,c)∈[0,1],則μ(s,c)是概念s關(guān)于特征c的概念隸屬度,即概念隸屬度是S*C上的一個(gè)模糊關(guān)系。對(duì)概念的隸屬度進(jìn)行評(píng)價(jià),首先獲取大量候選概念,計(jì)算概念的詞頻權(quán)值和TF-IDF權(quán)值,然后對(duì)候選概念進(jìn)行模糊分類。概念隸屬度的引入使得概念的抽取圍繞著核心概念集合,縮小了概念的抽取范圍,減少了噪聲數(shù)據(jù)的產(chǎn)生。
3.2 基于貝葉斯決策的核心概念抽取
在統(tǒng)計(jì)學(xué)中,貝葉斯分類算法分類準(zhǔn)確率高、簡(jiǎn)單、速度快,是一種常用的分類方法。為了提升本文方法在實(shí)際運(yùn)用中的效率和準(zhǔn)確率,在抽取核心概念的基礎(chǔ)上,搭建一個(gè)貝葉斯分類器,便于在實(shí)際應(yīng)用中對(duì)本文方法進(jìn)行評(píng)估與改進(jìn)。
設(shè)F={x1,x2,x3,…,xn}為待分類項(xiàng)集合即訓(xùn)練集,訓(xùn)練集和測(cè)試集根據(jù)一定的比例分配。x={a1,a2,a3}為一個(gè)待分類項(xiàng)即一個(gè)數(shù)據(jù)樣本,而每個(gè)a為x的一個(gè)特征屬性,一個(gè)待分類項(xiàng)有3個(gè)特征屬性。本文實(shí)驗(yàn)中,a1為標(biāo)準(zhǔn)化后的TF-IDF值,a2為標(biāo)準(zhǔn)化后的詞頻,a3為熵權(quán)法的計(jì)算結(jié)果。本文實(shí)驗(yàn)將待分類數(shù)據(jù)分為2類,G={y1,y2},y1為核心概念,y2為非核心概念。計(jì)算估計(jì)類先驗(yàn)概率,本文實(shí)驗(yàn)每個(gè)類別所占整體數(shù)據(jù)集的比例記為p。
假設(shè)特征的條件概率分布滿足正態(tài)分布,實(shí)現(xiàn)高斯貝葉斯分類器,采用概率密度函數(shù)計(jì)算條件概率p(x|g)。計(jì)算各個(gè)屬性在各類樣本的條件概率如式(3)所示:
(3)
其中,i個(gè)屬性分別表示a1,a2,a3;g表示y1和y2,μ(g,i)和σ(g,i)2分別是第g類樣本在第i個(gè)屬性上取值的均值和方差。
然后,對(duì)待分類數(shù)據(jù)進(jìn)行分類時(shí)通過貝葉斯公式計(jì)算后驗(yàn)概率分布并得出預(yù)測(cè)結(jié)果,如式(4)所示:
p(g|xi)=p(xi|g)*p
(4)
其中,p是先驗(yàn)概率。
再通過式(5)取出后驗(yàn)概率最大的作為最終預(yù)測(cè)結(jié)果:
(5)
4 實(shí)驗(yàn)過程和結(jié)果分析
4.1 數(shù)據(jù)預(yù)處理
本文采用THUCNews作為目標(biāo)語料庫進(jìn)行實(shí)驗(yàn)。該語料庫包含了74萬篇新聞文檔,均由來自于新浪新聞RSS訂閱頻道的歷史數(shù)據(jù)篩選過濾生成[20]。本文從語料庫中隨機(jī)選取了涉及財(cái)經(jīng)的1 000篇文本進(jìn)行概念抽取。
從文本中抽取核心概念,需要先對(duì)文本進(jìn)行劃分,獲得由詞語組成的待抽取文本,然后篩選出符合概念詞詞性的分詞,最終得到包括10 685個(gè)候選概念的候選概念集。
4.2 實(shí)驗(yàn)過程
本文實(shí)驗(yàn)利用傳統(tǒng)TF-IDF算法對(duì)候選詞進(jìn)行篩選分類,實(shí)驗(yàn)中top-k設(shè)置為10 685,計(jì)算出所有候選詞的權(quán)重。結(jié)果如表1所示(以TF-IDF權(quán)重值前10的數(shù)據(jù)為例),然后選取大于TF-IDF權(quán)重平均值的候選詞構(gòu)建候選概念集。

Table 1 Set of candidate concepts
結(jié)合信息熵對(duì)候選概念進(jìn)行指標(biāo)權(quán)重計(jì)算,進(jìn)而對(duì)實(shí)驗(yàn)數(shù)據(jù)進(jìn)行概念詞抽取。指標(biāo)由TF-IDF權(quán)重值及詞頻構(gòu)成,為避免后續(xù)實(shí)驗(yàn)數(shù)據(jù)規(guī)則不統(tǒng)一對(duì)實(shí)驗(yàn)結(jié)果造成的影響,首先對(duì)實(shí)驗(yàn)數(shù)據(jù)進(jìn)行歸一化處理,歸一化處理后的TF-IDF權(quán)重值記為特征值1,歸一化后的詞頻記為特征值2。同時(shí),本文根據(jù)熵權(quán)法指標(biāo)權(quán)重計(jì)算式[21],通過輸入所有候選數(shù)據(jù)及歸一化指標(biāo)得到各指標(biāo)的權(quán)重,得出TF-IDF權(quán)重值所占指標(biāo)權(quán)重為0.445 591 342,詞頻權(quán)重值所占指標(biāo)權(quán)重為0.554 408 658。然后對(duì)實(shí)驗(yàn)數(shù)據(jù)指標(biāo)進(jìn)行加權(quán)處理,計(jì)算出各候選概念的概念隸屬度,選取結(jié)果大于0.000 1的概念為核心概念,以本文方法排名前10的概念為例,如表2所示。
4.3 實(shí)驗(yàn)結(jié)果分析
為了深入驗(yàn)證本文方法的有效性和準(zhǔn)確性,將本文方法與傳統(tǒng)TextRank算法[22]、LDA主題模型[23]、word2vec詞聚類模型[24]、RNN[25]及LSTM[26]進(jìn)行對(duì)比,依次計(jì)算出概念抽取的準(zhǔn)確率等各項(xiàng)模型評(píng)估參數(shù)結(jié)果,結(jié)果如圖2所示。
實(shí)驗(yàn)結(jié)果表明,本文方法準(zhǔn)確率最高,錯(cuò)誤率最低,精確度方面與RNN、LSTM相近。在準(zhǔn)確率方面,word2vec的準(zhǔn)確率最低,達(dá)到了64%,本文方法的準(zhǔn)確率為96%,比LSTM方法的91%提高了5%。在精確度方面,TextRank和word2vec的精確度較低,本文方法與RNN和LSTM的精確度接近,比這2種方法略高。在F1-Score方面,本文方法與其它方法對(duì)比達(dá)到了最優(yōu),TextRank的F1-Score最低為62%,本文方法達(dá)到了95%。無論從準(zhǔn)確率還是效率,綜合評(píng)價(jià)本文方法都比其他方法更優(yōu),結(jié)果如表3所示。

Figure 2 Comparisive results of multiple methods圖2 多種方法的對(duì)比結(jié)果
由表3可以得出,本文方法在準(zhǔn)確率、召回率和F1-Score值方面都高于其它方法的,精確率與LSTM接近,證明了本文方法的可行性和有效性。當(dāng)然,在效率上本文方法相比其它方法還需要進(jìn)一步改進(jìn),精確度也需要進(jìn)一步提升。
5 結(jié)束語
針對(duì)概念抽取在領(lǐng)域本體構(gòu)建中的重要性,本文提出了一種基于模糊貝葉斯決策的核心概念抽取方法,采用TF-IDF算法計(jì)算候選概念的各項(xiàng)特征值,結(jié)合概念隸屬度歸一化處理候選概念特征值,通過貝葉斯決策計(jì)算候選概念為核心概念的概率,實(shí)驗(yàn)取得了較好的結(jié)果。這種方法不僅為核心概念的抽取提供了參考,同時(shí)也為下一步的關(guān)系挖掘和知識(shí)庫構(gòu)建奠定了基礎(chǔ)。
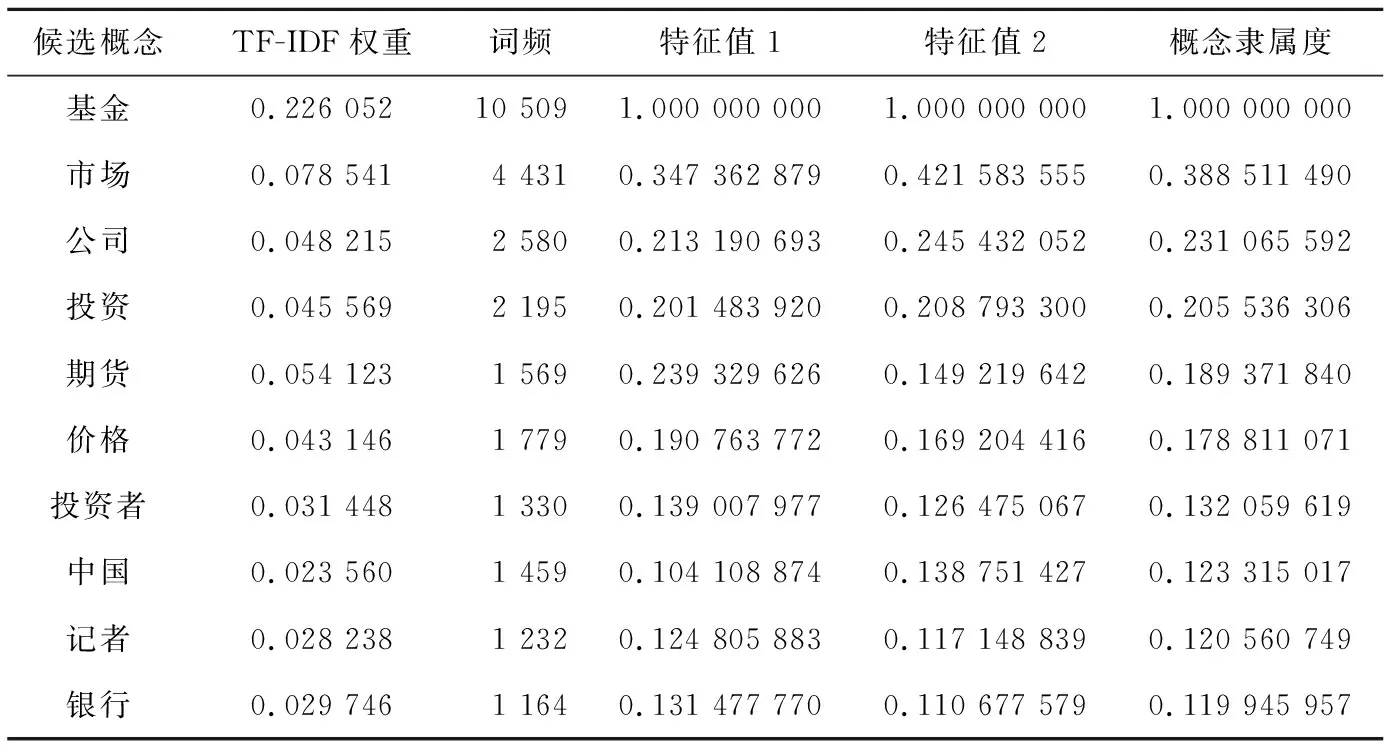
Table 2 Conceptual membership calculation
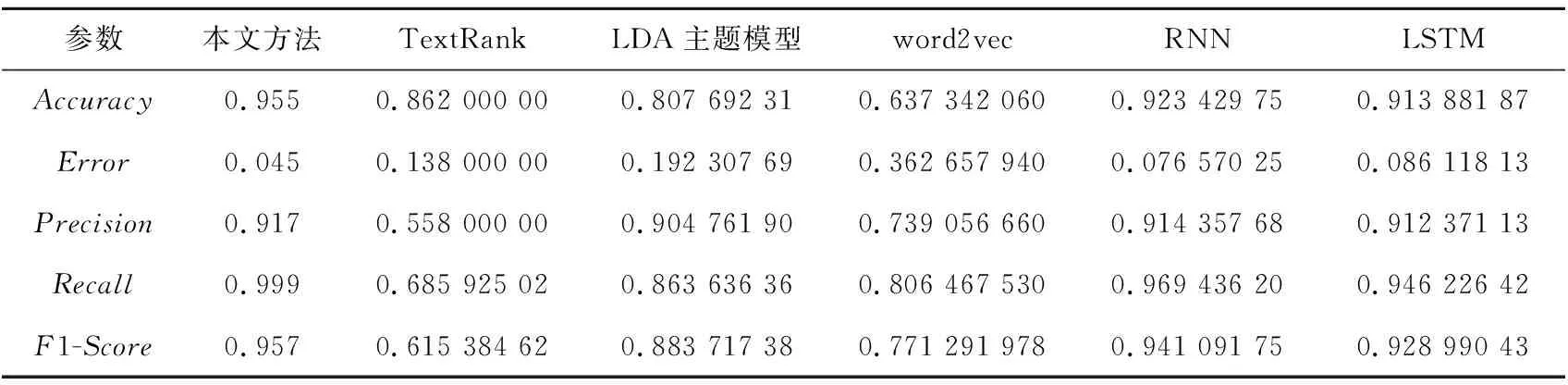
Table 3 Comparisive results in several ways
猜你喜歡
現(xiàn)代裝飾(2022年1期)2022-04-19 13:47:32
現(xiàn)代裝飾(2020年2期)2020-03-03 13:37:44
制造技術(shù)與機(jī)床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
中學(xué)生數(shù)理化·高一版(2018年9期)2018-10-09 06:46:48
中學(xué)生數(shù)理化·高一版(2017年9期)2017-12-19 12:15:14
Coco薇(2016年2期)2016-03-22 02:42:52
小學(xué)教學(xué)參考(2015年20期)2016-01-15 08:44:38
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長(zhǎng)指南(2015年4期)2015-05-19 14:47:56
