基于知識指導的安全強化學習路由算法
2022-09-14 09:11:42李婧侯詩琪
中國工程機械學報 2022年4期
李婧,侯詩琪
(上海電力大學計算機科學與技術學院,上海 201306)
截至2020年12月,我國互聯網普及率達70.4%[1],網民增長規模使網絡接入流量激增。在高負載網絡中,以開放最短路徑優先(open shortest path first,OSPF)為代表的傳統數學模型驅動的協議不能感知節點和鏈路的狀態變化以調整路由策略,改善網絡傳輸質量[2]。如圖1所示,假設路由器R1、R2和R3均收到了需送往R7的數據,在OSPF算法下,R1、R2和R3會選擇通過R5將數據送達R7,R5成為影響網絡性能的瓶頸。

圖1 OSPF的局限性Tab.1 Limitation of OSPF
近些年,深度學習和強化學習也被應用在路由優化中,但這類基于數據驅動的算法在大流量傳輸場景中不能再做出最優或次優決策以保證網絡吞吐量,特別是在模型訓練初期。基于深度學習的模型訓練成本高且可解釋性不足,基于強化學習的模型還存在Q值過估計問題。
針對上述問題,本文提出一種基于先驗知識指導的安全深度強化學習路由選擇知識指導等路由算法(safe double deep Q network with priori knowledge guidance approach,PKG-DDQNS),此算法降低了訓練成本,提升了決策安全性和可解釋性以及網絡吞吐量。其工作主要體現在以下3方面:
(1)為加速模型收斂,提升模型訓練初期的吞吐量,降低丟包率,避免探索階段做出不安全的選擇導致網絡大范圍擁塞,算法將先驗知識融入深度強化學習模型,結合ε-greedy策略,生成下一跳。通過對動作進行預判和限制,制止不合適的動作選擇,保證整個決策階段動作安全性。
(2)為提升模型可解釋性,獎勵函數引入對路由回路的判斷,避免形成局部回路,可讓數據分組更快送達,提升路由器緩存資源的利用率。
(3)為評估算法有效性,將算法部署在基于Keras和Networkx的仿真環境,量化比較了本算法對網絡吞吐量、數據交付率等指標的提升程度。
1 智能路由研究現狀
基于數據驅動的路由選擇算法的主要作用為監督學習和強化學習,這類算法不對具體環境建立復雜數學建模,而是對數據建模[2]。
基于監督學習的算法以深度學習模型為主,這類模型可通過帶標簽數據學到更為復雜的策略。車向北等[3]、唐鑫等[4]分別提出基于圖神經網絡的路由算法,能感知網絡動態變化以優化路由策略。孫鵬浩等[5]、吳凡等[6]分別提出SmartPath和QoS(quality of service)感知算法(DLQA),可根據流量特征變化生成滿足不同QoS的路由策略。但這類算法存在3個問題:①訓練成本高,模型需通過傳統路由算法多次獲取足夠多帶標簽數據進行訓練;②深度學習存在不確定性,會使路由決策存在安全隱患,當訓練數據集之外的情況發生時,網絡性能可能會下降;③深度學習可解釋性不足,當出現突發情況導致網絡性能下降時,難以快速定位問題。
基于強化學習的路由算法的核心是Q-learning[7]。Boyan等[8]提出的Q-routing算法以及Daniel等[9]提出的QCAR旨在為數據分組選擇時延最短的路徑,可感知拓撲結構和負載變化,避免擁塞。但在探索階段,網絡性能不佳。隨后出現的Full echo Q-routing以及學習率可變的(FQLR)在路由決策前進行輪詢操作,加快節點間的信息交換以降低延遲[10],但在大流量傳輸中模型訓練初期延遲較高。這類算法的共性問題是當動作空間和狀態空間具有連續性時,Q表將急劇增大,查表操作嚴重影響算法性能。
有學者將Q-learning與深度學習相結合。這類算法基于集中式部署或分布式部署[11],使用基于深度強化學習(deep Q network,DQN)的路由選擇算法生成下一跳[12-13]。高飛飛等[13-14]提出基于集中式部署的SDMT-DQN和DOMT-DQN以降低網絡擁塞。胡玉祥等[15]、劉外喜等[16]分別提出基于深度確定性策略梯度的EARS和DRL-R,可感知流量大小生成相應的路由策略。但在探索階段,agent可能會做出使整個網絡性能下降的不安全決策。基于分布式部署的MARL算法把每個路由器都看作agent,減少了所需訓練的神經網絡數目,然而agent需從鄰居更新參數以避免陷入局部最優,這增加了通信成本,算法還存在過估計問題。
2 路由選擇建模
網絡采用經典網狀拓撲結構,如圖2所示。路由器r總數為N,可分為3類:①接收各種智能設備產生的數據,即源路由器rs;②目的路由器rd;③中途路由器rm可轉發來自其他路由器的數據分組。Ns、Nm、Nd分別是3類路由器的數目,關系如下:

圖2 實驗拓撲結構Tab.2 Experimental topology

算法旨在為數據分組生成合適的下一跳,將其送達目的路由器。由于單一DQN只能使數據分組送達單一目的地,因此需訓練多個參數不同的DQN[14]。在實際決策時,根據數據分組包含的目的節點信息,選用相應DQN來生成下一跳。
3 PKG-DDQNS詳細設計
PKG-DDQNS算法的總體架構如圖3所示。算法采用軟件定義網絡的架構。路由器構成了環境,agent位于控制器中。環境、狀態、動作、獎勵函數、狀態價值函數和指導模塊是PKG-DDQNS的6要素。

圖3 PKG-DDQNS詳細設計Tab.3 Detailed design of PKG-DDQNS
3.1 環境
數據源生成的數據送達源路由器,控制器與路由器進行通信收集傳輸任務,根據目的節點信息,選擇相應agent產生下一跳,并發送到路由器執行轉發操作。控制器收集環境狀態,評估上一時隙的動作,并把狀態、動作、即時獎勵以及執行動作后的狀態存至經驗回放池。
3.2 狀態
狀態包括2部分:①t時刻路由器緩沖區的數據量Dt,Dt=[D1,t,D1,t,…,DN,t],Di,t為t時刻第i個路由器緩沖區的數據總量;②采用改進的one-hot編碼記錄t時刻數據分組的位置信息Pt,長度為N,Pt=[P1,t,P2,t,…,PN,t],且為t時刻數據分組是否在第i個路由器中,每時刻數據分組只存在一個路由器中,此路由器對應的Pi,t為1,其余為0。若agent做出非法選擇,如選取當前路由器的非鄰居節點,Pi,t為-1,其余為0。綜上,t時刻的狀態S為St=[Dt,Pt]。
3.3 動作
agent根據狀態信息,依照ε-greedy原則為數據分組選擇當前路由器的鄰居節點作為下一跳A。agent會以ε的概率選取最優動作,以1-ε的概率選取其他動作。
3.4 獎勵函數
為在大流量傳輸場景中減少丟包,令數據分組盡快交付,獎勵函數包括因數據分組被丟棄時的懲罰性獎勵以及被正常轉發時的即時獎勵:

式中:λ+φ=1,且λ,φ∈[0,1],φ∈{0,1};λ與φ為權重,衡量指標的重要程度,權重越大,表示該指標越重要。
agent將在以下2種情況獲得懲罰性獎勵,數據分組傳輸被終止:①當下一跳路由器的緩沖區已無法存儲數據分組時,此時路由器負載過大;②當下一跳不是當前節點的鄰居節點,動作非法。
agent在以下3種情況獲得即時獎勵:①當下一跳已出現在數據分組的路徑中,可認為產生了回路,此時給予agent負向獎勵Rloop;②數據分組每被轉發一次,agent獲得負向獎勵Rhop;③當下一跳是目的路由器,agent獲得正向獎勵Rarrive,設置正向獎勵有助于加速模型收斂。
3.5 狀態動作值函數
算法的核心是不斷改進對特定狀態的特定行動質量的評估。算法構造的元組記錄狀態轉移情況如下,并將其存儲至經驗回放池,狀態轉移元組O為
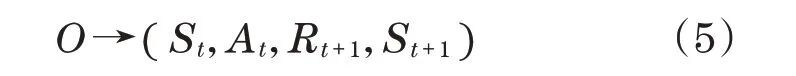
每隔一定時間進行隨機采樣,更新神經網絡參數,預防值Q為

式中:γ為折扣因子;a為動作符合;為target network神經網絡采參數。
agent結構如圖3所示,包含2個結構相同的神經網絡,輸入層為狀態,輸出層為Q值。eval_network產生下一跳,target_network評估狀態動作價值。
參數更新時,對于隨機采樣的每一個狀態轉移元 組,St輸 入eval_network,得 動 作A的Q值Q(St,At),St+1輸入eval_network,得下一時刻狀態 下 各 動 作 的預 測Q值Q(St+1,At+1),St+1同 時輸入target_network,從eval_network的輸出層選 取 最 大Q(St+1,a)對 應 的 動 作a',即argmaxa'(Q(St+1,a;θ)),再 從target_network中選取a'對應的Q值,利用式(6)求出Target_Q,再對式(7)求導,更新參數[17]。為保證模型收斂,每隔一定時間將eval_network中的參數θ賦值給target_network的參數。
3.6 知識指導模塊
為提升決策有效性和安全性,增強模型可解釋性,加速模型收斂,保障agent訓練初期的網絡吞吐量,算法引入知識指導模塊和ε-greedy策略共同決定下一跳。首先,模型根據ε-greedy策略,選出動作A。A送入知識指導模塊,進行合法性檢查、安全性評估和建議指導。
集中式部署下,agent擁有全局視角。若A是當前路由器的非鄰居節點,則A非法,模塊給出建議動作A',并把經驗存至經驗回放池。若動作A通過合法性檢查,模塊將對A做安全性評估。若A導致路由器負載過重,模塊嘗試給出建議動作A',若A'不存在,數據分組將被丟棄,評估的經驗將存至經驗回放池。若A通過了合法性檢查和安全性評估,控制器把A發送至路由器執行轉發操作。
建議指導部分使用one-hot向量,記錄在當前節點選擇每一個動作的評估結果,維度為Nm+Nd。向量n=[n1,n2,…,nNm+Nd]記錄當前節點的鄰居節點,若ni為當前節點的鄰居,ni為1,否則為0。向量d記錄動作是否會造成路由器負載過重。若低于負載閾值,di為1,否則為0。向量l評估動作是否產生回路。若否,li為1,否則為0。向量對應位置相乘,若存在多個i,使ni×li×di=1,則按照εgreedy選擇。若只存在一個i,則返回i作為下一跳。若i不存在,則選擇使ni×di=1的i作為下一跳A'。

式(8)為加速算法收斂,建議指導部分將評估目的路由器是否在當前節點的鄰居中,若在,模塊會建議下一跳選擇目的路由器。
4 實驗仿真與結果分析
4.1 實驗設計
4.1.1 實驗環境
實驗采用的拓撲結構如圖2所示,源路由器和目的路由器緩沖區無限制,其余每個路由器緩沖區大小為45 MB。數據源產生的數據分組個數符合泊松分布。神經網絡輸入層設2N個神經元,輸出層設N個。每個時隙數據源生成的數據總量相同。算法所在環境每時隙生成的數據分組一致,模型神經網絡參數一致。
4.1.2 模型
為評估算法性能,實驗選取以下模型。
OSPF:各路由器通信獲取全局拓撲結構后,用Dijkstra算法計算到各節點最優路徑。
QCAR[10]:采用Q-learning和隨機選取不擁擠節點的方式生成下一跳,將流量分配到多條路徑。
DOMT-DQN[17]:基于Nature DQN[15],根據目的節點選擇對應DQN產生下一跳。
4.1.3 實驗思路
(1)在相同輸入流下,比較網絡吞吐量。每時隙數據源生成47 MB數據。為驗證狀態動作函數設計和知識指導模塊的有效性,引入以下模型變體:
PKG-DQNS:Target_Q沿 用Nature DQN計算,其余與PKG-DDQNS一致。
DOMT-DDQN:Target_Q沿用式(6)計算,其余與DOMT-DQN一致。
(2)在不同負載下,比較平均吞吐效率以及平均丟包率。定義吞吐效率為每輪訓練結束后已送達的數據量與數據總量的比值,平均吞吐效率和平均丟包率分別表示對200輪訓練的吞吐率γavt、丟包率求平均γavd為

式中:Eepi為訓練輪次;Nrd為每輪訓練成功送達的數量;Nad為每輪訓練生成的數量總量;γdrop為每輪訓練丟包率。
(3)在相同輸入流下,比較每輪訓練數據分組傳輸的平均路徑長度lav為

式中:Nrp為送達目的節點的數據傳送任務數目;len為每個分組跳數。
4.2 結果分析
4.2.1 消融實驗
吞吐量與訓練輪次如圖4所示,就吞吐量而言,總體上PKG-DDQNS優于PKG-DQNS;DOMTDDQN優于DOMT-DQN,證明了用式(6)計算Target_Q的有效性,對狀態動作的更優估計可提升網絡性能;同時證明知識指導模塊的有效性,且知識指導模塊對于吞吐量的提升作用更大。訓練100輪后,4個基于深度強化學習的模型使網絡吞吐量高于部署了QCAR和OSPF的環境,這證明了使用深度強化學習方法的有效性。

圖4 吞吐量與訓練輪次Tab.4 Throughput and training times
4.2.2 負載變化與性能
根據圖5(a)所示,每時刻生成的數據量增加22%時,PKG-DDQNS的丟包率僅增加了1.52%,其余模型丟包率增長均高于1.52%。根據圖5(b)所示,當數據生成速率從每個時隙生成45 MB到46 MB、50 MB到51 MB時,除QCAR的其他模型平均吞吐量均有上升現象,證明基于深度強化學習方法在感知流量變化方面的優越性。模型能根據網絡的流量情況,調整策略。PKG-DDQNS和PKGDQNS使網絡平均吞吐率高于DOMT-DQN和DOMT-DDQN,且平均吞吐率的變化幅度更小,表明ε-greedy與知識指導聯合決策可保證吞吐率的穩定。PKG-DDQNS使平均吞吐率保持在85%以上。盡管在負載逐漸增加的情況下QCAR的平均丟包率最低,但總體上QCAR的吞吐效率低于其他模型,說明QCAR更傾向于丟棄數據量更大的分組,也表明知識指導模塊作用可兼顧分組送達數目和分組數據量送達率。
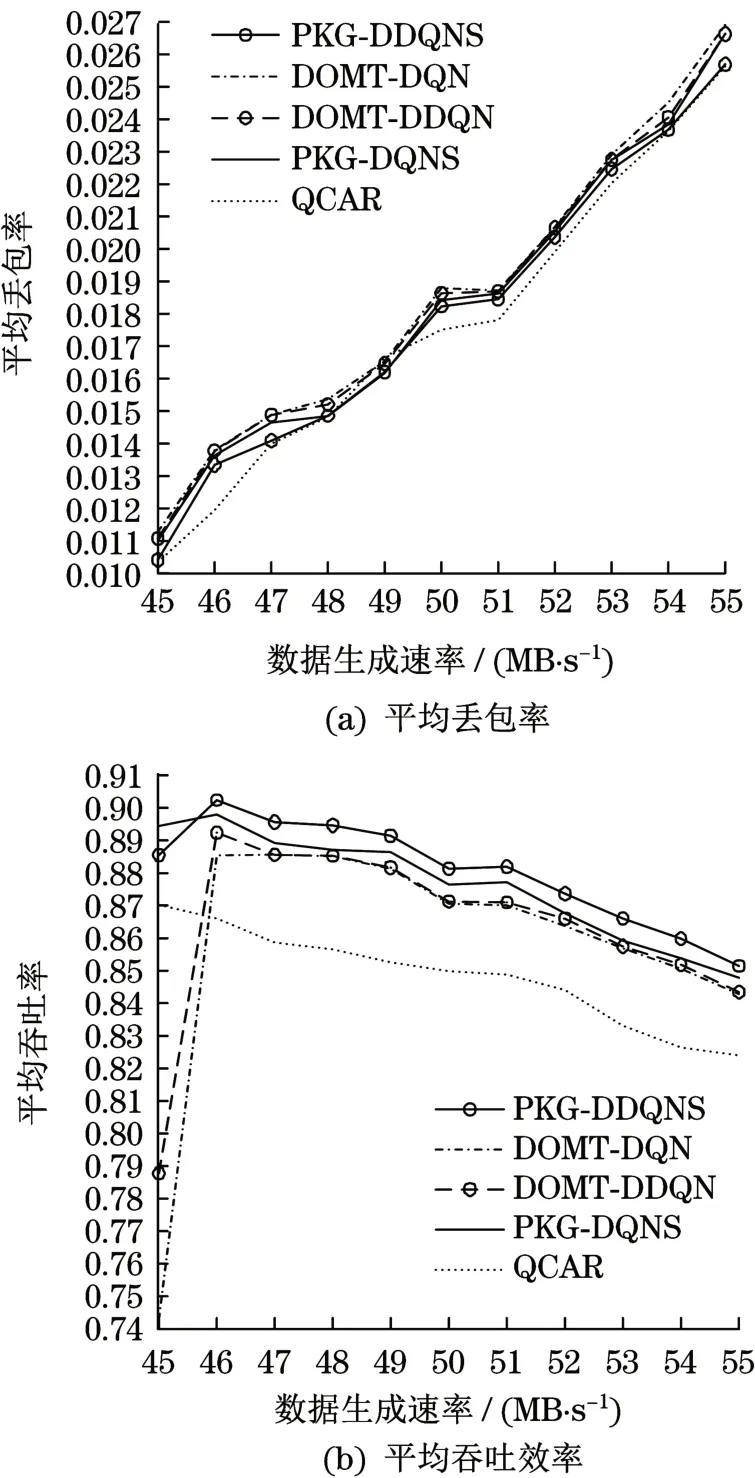
圖5 網絡負載變化與性能Tab.5 Network load changes and performance
4.2.3 平均路徑長度
如圖6所示,PKG-DDQNS的平均路徑長度在3~4之間,其余模型均高于PKG-DDQNS,證明了回路懲罰機制的有效性。PKG-DDQNS能在滿足QoS約束的同時優先選最短的路徑將數據分組送達。盡管OSPF的平均路徑長度最短,但沿著負載相對小的路徑轉發反而能提升網絡性能。

圖6 平均路徑長度Tab.6 Average path length
5 結語
為提升大流量傳輸時的網絡吞吐量,保障從訓練開始階段到相對收斂網絡始終具有較高的吞吐量,提出一種基于先驗知識指導的安全深度強化學習路由選擇算法PKG-DDQNS,融合ε-greedy和先驗知識評估,利用集中式部署的優勢,避免了網絡出現環路和大規模擁塞,降低了訓練成本。與現有算法相比,該算法顯著提升了網絡穩定性和吞吐量。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
動漫界·幼教365(大班)(2021年4期)2021-05-23 21:33:16
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
小學生作文(低年級適用)(2018年3期)2018-04-17 00:58:35
少年博覽·小學低年級(2017年4期)2017-06-09 16:22:28
作文周刊·小學一年級版(2016年28期)2017-06-03 00:28:49
作文評點報·低幼版(2017年7期)2017-03-11 20:49:41
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
