一種基于改進(jìn)SSD的特殊服飾識別
2022-09-07 03:41:06朱書霖吳新春成鑫才
電子元器件與信息技術(shù) 2022年7期
朱書霖,吳新春,成鑫才
西南交通大學(xué) 信息科學(xué)與技術(shù)學(xué)院,四川成都,611756
0 引言
在當(dāng)前時代,信息的獲得、加工、處理技術(shù)以及應(yīng)用都有了飛躍發(fā)展。人們認(rèn)識世界的重要知識來源就是圖像信息。隨著計算機(jī)視覺技術(shù)在不斷發(fā)展與進(jìn)步。計算機(jī)在一些領(lǐng)域上已經(jīng)可以通過獲取的各種圖像信息理解并且進(jìn)行分析。同時目標(biāo)檢測如今已經(jīng)成了計算機(jī)視覺的主要研究領(lǐng)域之一[1]。目標(biāo)檢測是指能夠精確定位一些圖像或者場景中的目標(biāo)的技術(shù)[2]。
對于我國來說,隨著經(jīng)濟(jì)的發(fā)展,城市化進(jìn)程的加大,治安水平也在不斷提高,但針對一些特定的場合,由于其經(jīng)濟(jì)水平和科技水平較低,其治安情況仍相對于其他地方較低。因此對于這些地方來說仍然可能存在有危害社會安全的行為發(fā)生的可能。對于這些地區(qū)來說,人員組成復(fù)雜,現(xiàn)代科技普及較少。同時雖然現(xiàn)在天網(wǎng)系統(tǒng)較為普及,但是監(jiān)控攝像頭一般只能在案發(fā)后進(jìn)行刑事追責(zé),而很難起到實時報警的作用。
基于卷積神經(jīng)網(wǎng)絡(luò)的目標(biāo)檢測算法是如今最流行的目標(biāo)檢測方法,主要包括目標(biāo)檢測器(single shot multiBox detector,SSD)[3],You Only Look Once(YOLO)[4-7], Regions with CNN features(RCNN)[8-10]。其中YOLO和SSD屬于單階段目標(biāo)檢測算法,而RCNN屬于雙階段目標(biāo)檢測算法。單階段的目標(biāo)檢測算法采用了回歸分析的思想,省略了候選區(qū)域生成階段,直接得到目標(biāo)分類和位置信息。雙階段檢測算法將檢測問題劃分為兩個階段,首先產(chǎn)生候選區(qū)域,然后對候選區(qū)域分類。其中雙階段算法識別準(zhǔn)確率高,但是計算復(fù)雜度過于龐大。對于單階段目標(biāo)檢測算法來說,YOLO V1 、YOLO V2物體識別準(zhǔn)確率相對SSD較低,同時YOLO V3、YOLO V4計算量相對較大[11],本文在SSD的基礎(chǔ)上進(jìn)行輕量化網(wǎng)絡(luò)設(shè)計,從而大幅度減少目標(biāo)檢測模型的計算量,同時保證整個模型的精度。
1 改進(jìn)SSD模型
1.1 SSD網(wǎng)絡(luò)結(jié)構(gòu)
SSD的主體網(wǎng)絡(luò)結(jié)構(gòu)采用的是VGG16網(wǎng)絡(luò)結(jié)構(gòu)(VGG16是由Oxford的Visual Geometry Group提出的,整個網(wǎng)絡(luò)結(jié)構(gòu)是由13層卷積層加3層全連接層),但是對VGG16網(wǎng)絡(luò)結(jié)構(gòu)進(jìn)行了更改,舍棄了VGG16的三個全連接層,采用了兩個卷積層代替。此外SSD在VGG網(wǎng)絡(luò)的最后端,新增了4個卷積塊。
如圖1所示,SSD采用特征金字塔中各個層所提取的特征來對不同尺度的目標(biāo)進(jìn)行檢測。通過對Conv4_3、Conv7_2、Conv8_2、Conv9_2、Conv10_2、Conv11_2各個卷積層所提取的特征點進(jìn)行預(yù)測,從而得出目標(biāo)物體的先驗框。再通過非極大值抑制(Non-Maximum Suppression,非極大抑制值是對相鄰先驗框提取出目標(biāo)識別概率最大的一個先驗框,并且抑制概率較小的先驗框)。得到了最后的檢測結(jié)果。
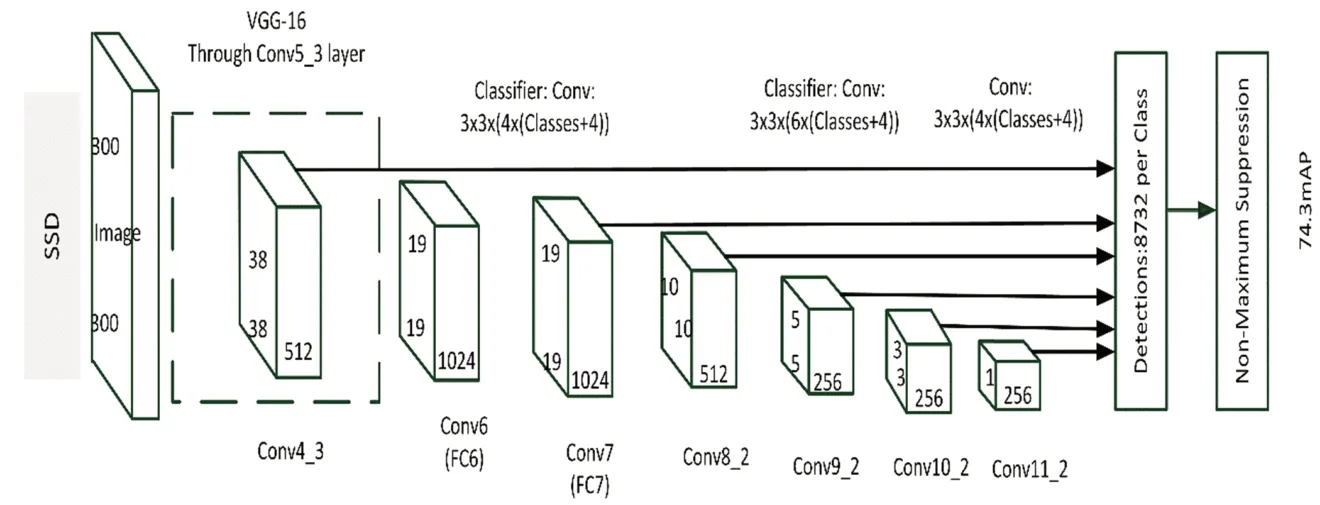
圖1 SSD網(wǎng)絡(luò)結(jié)構(gòu)圖
1.2 模型概述
改進(jìn)SSD模型借鑒了SSD與Mobilenet V1-SSD的思想,在原有SSD模型基礎(chǔ)上使用了Mobilenet V1的思想,對整個網(wǎng)絡(luò)進(jìn)行了輕量化的設(shè)計。并且通過對不同的特征層進(jìn)行預(yù)測,得到不同特征層分別的先驗框,最后通過非極大值抑制法刪除掉冗余的先驗框,得到精準(zhǔn)的檢測結(jié)果。
1.3 基本原理
1.3.1 多尺度預(yù)測
改進(jìn)SSD算法通過對特征金字塔中不同維度的特征圖進(jìn)行多尺度目標(biāo)檢測,從而完成對整張圖像的目標(biāo)檢測。改進(jìn)SSD算法采用的特征圖大小為{4、6、6、6、6、6}。同時其對應(yīng)的先驗框數(shù)量分別為{4、6、6、6、6、4}。
1.3.2 非極大值抑制
通過多尺度預(yù)測,會產(chǎn)生大量的冗余的先驗框。通過非極大值抑制使用交互比判斷冗余的候選框,對于兩個交互比大于模型所設(shè)的閾值時,對置信度較低的候選框進(jìn)行刪除,同時保留較高的候選框。
1.4 網(wǎng)絡(luò)結(jié)構(gòu)
改進(jìn)SSD模型基于VGG16模型進(jìn)行輕量化設(shè)計,詳細(xì)網(wǎng)絡(luò)結(jié)構(gòu)如圖2所示。
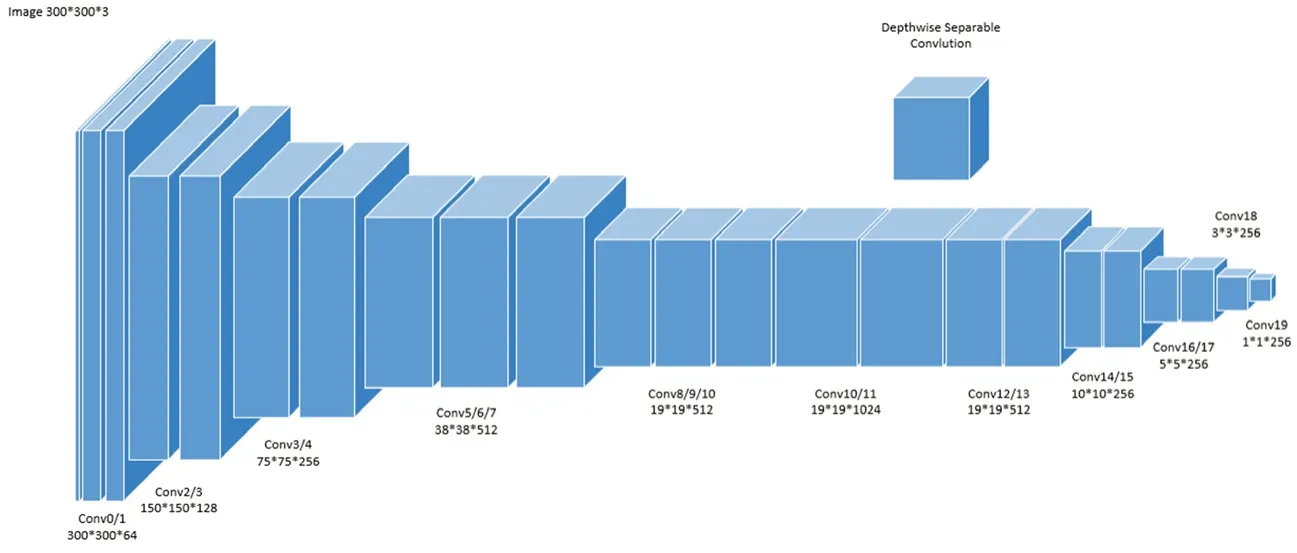
圖2 改進(jìn)SSD網(wǎng)絡(luò)結(jié)構(gòu)
2 數(shù)據(jù)集準(zhǔn)備
2.1 數(shù)據(jù)準(zhǔn)備
對于特殊服飾,現(xiàn)有數(shù)據(jù)集均未有各種服飾的數(shù)據(jù),因此本文主要采用了以下三種方法完成數(shù)據(jù)集的構(gòu)建。一部分是采用網(wǎng)絡(luò)爬蟲,爬取互聯(lián)網(wǎng)上的圖片,再進(jìn)行篩選得到的圖片,另外一部分則是選擇在網(wǎng)上搜索紀(jì)錄片,通過將視頻導(dǎo)出為圖片再進(jìn)行篩選,最后一部分來自已有數(shù)據(jù)集的圖像增強(qiáng)。
(1)網(wǎng)絡(luò)爬蟲。如果將互聯(lián)網(wǎng)比喻成一張網(wǎng),那么網(wǎng)絡(luò)爬蟲就是可以在網(wǎng)上爬來爬去得小蟲子,通過網(wǎng)頁的鏈接地址來尋找網(wǎng)頁,通常通過網(wǎng)站的某一個頁面開始讀取網(wǎng)頁的內(nèi)容,最后在該網(wǎng)頁中找到其他鏈接地址,從而尋找下一個網(wǎng)頁,最后抓取完該網(wǎng)站所有網(wǎng)頁。
(2)紀(jì)錄片導(dǎo)出。通過網(wǎng)上搜索相應(yīng)的紀(jì)錄片,錄制其視頻,再通過Adobe Premiere Pro軟件將錄制好的視頻通過每1秒一幀導(dǎo)出成圖片,再通過手動篩選出不符合需求的圖片。
(3)圖像增強(qiáng)。針對部分服飾種類實際數(shù)據(jù)的采集場景是有限的,因此采取一些數(shù)據(jù)增強(qiáng)的方法可以有效擴(kuò)展數(shù)據(jù)集數(shù)量,同時也可以防止目標(biāo)檢測模型學(xué)習(xí)過程中出現(xiàn)的過擬合現(xiàn)象。現(xiàn)有的圖像增強(qiáng)方法大致可以分為空間變換、色彩失真等幾種方法。
最后通過以上三種方法構(gòu)了一種特殊服飾專用的數(shù)據(jù)集,該數(shù)據(jù)集共有醫(yī)生、警察、藏族、藏傳佛教、普通人五種類別。最后生成的數(shù)據(jù)集總共有圖片2271張,并在實驗時候?qū)?shù)據(jù)集分為訓(xùn)練集2037張,測試集234張兩個部分。
3 實驗與結(jié)果分析
3.1 實驗環(huán)境
本文實驗硬件環(huán)境為Nvidia Geforce GTX 2080Ti,軟件環(huán)境為CUDA 10.1.243,Cudnn 7.6.5,Windows 10,Tensorflow2.1。
3.3 結(jié)果與討論
對于模型的評估,采用了文獻(xiàn)[20]中描述的mAP(一種計算不同的類別的平均精確度的方法)方法評價了該方法的性能。其結(jié)果如圖3所示,各個服飾的PR曲線如圖4所示。
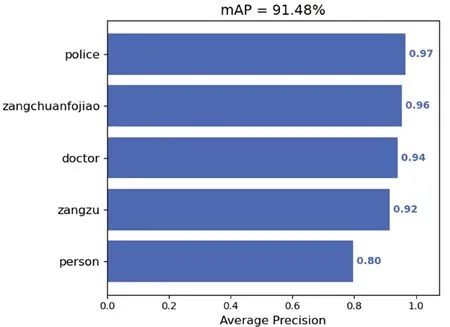
圖3 特殊服飾數(shù)據(jù)集mAP率
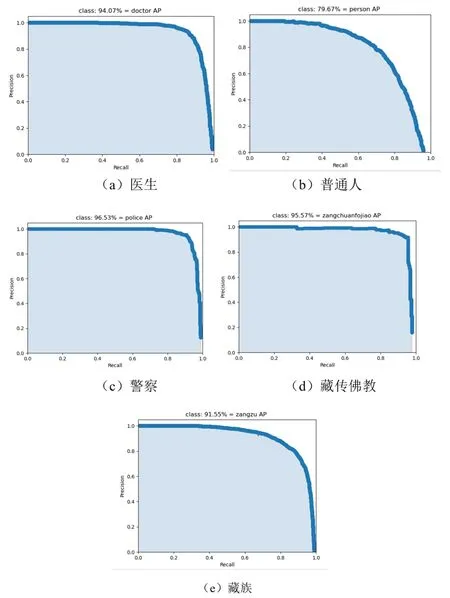
圖4 各個服飾的PR曲線
該模型對于未穿特殊服飾的普通人的檢測相比特殊服飾的人員檢測率有著較大的波動,這是因為相對于穿著特殊服飾的人員來說,普通人的衣服未有比較普遍的圖像特征,同時數(shù)據(jù)集中缺乏各種各樣的普通人服飾。但是對于本系統(tǒng)的主要目的是檢測特殊服飾人員,因此該系統(tǒng)仍然能夠完成所需要完成的任務(wù)。模型的部分檢測結(jié)果如圖5所示。

圖5 各服飾檢測結(jié)果圖
根據(jù)圖5,使用本文所提出的算法能夠較為精確地識別出各種特殊服飾,從而完成檢測的需求。
4 結(jié)論
為了進(jìn)一步保障一些特殊地區(qū)的安全需求,本文提出了一種改進(jìn)SSD算法,并且基于該模型對識別幾種特殊服飾進(jìn)行了訓(xùn)練與檢測。可以看到本文所提出的模型能夠較好地完成所需完成的任務(wù),同時由于其主體結(jié)構(gòu)全部采用深度可分離卷積,大量地減少了其計算量,從而能夠部署到各個終端系統(tǒng)中。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年12期)2021-01-18 06:57:46
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年12期)2021-01-18 06:57:46
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(2020年2期)2020-06-02 11:29:24
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
海峽科技與產(chǎn)業(yè)(2016年3期)2016-05-17 04:32:12
