類比算法的提出以及在人工智能發展中的應用研究
2022-09-07 03:40:58焦正張強通信作者韓清華李明遠
電子元器件與信息技術 2022年7期
焦正,張強(通信作者,韓清華,李明遠
1.棗莊學院 人工智能學院,山東棗莊,277160;2.伊爾庫茨克國立理工大學,俄羅斯伊爾庫茨克州,664074
0 引言
人類在接觸一個新事物的時候,會把新事物分為兩類:已知和未知。分辨的依據就是我們腦海中已有的知識,通過與腦海中已知事物進行特征比對,可以很快地辨別出,新事物以前是否見過。如果匹配,則會將腦海里有關這個事物的所有知識全部調用出來;如果不匹配,下一步則會想,這個新事物和這個已知的事物有多少特征相似,然后通過已知事物的特征來標記未知事物,然后通過各種渠道搜集資料和信息,得到新事物的一個定義,然后結合剛剛的特征,就會把這個未知事物轉化為已知事物,進而成為儲存在腦海里的知識。這就是人類接觸一個新事物的時候,大腦中的一個簡單的連鎖反應。
1 “類比算法模型”概念的提出
1.1 類比思維模式
人認知世界的過程中就是在不斷地給各種事物打上各種各樣的標簽:高、矮、胖、瘦……打的標簽越多,我們對這個世界的認知就越全面,對世界的認知也就更容易。數據標注,就是在給數據打標簽。目前的數據標注,大部分工作還是需要人力來完成,所需人力資源龐大[1]。為了解決這個問題,我們通過類比思維模式提出了一個算法概念。首先,該算法可以通過已知事物的標簽來標注未知事物,數據庫中的數據越多,標簽的定義也就越詳細,通俗來講就是已有標注數據越多,對新數據的標注工作也就越輕松。該算法就是在模擬人接觸新事物的一個思維過程——類比思維模式。
此算法雖然基于機器學習,但不同于現有的算法,此算法會對已經儲存的數據進行一個簡單的運用:通過儲存的知識讓標簽的定義更加完善;更加完善的標簽則可以更好地完成數據標注的工作,這樣就構成了一個良性循環,它更符合人的思考方式。在人類學習知識的過程中,有這樣一個概念:“歸屬學習”,而“歸屬學習”還分為上位學習和下位學習,上位學習是指新學習的知識在概括程度上高于認知結構中已有的知識,下位學習則與之相反,認知結構中已有的知識可以概括新知識,而通過類比算法來學習的一個概念就是下位學習。標簽可以囊括我們所需要標注的內容,而標注的內容則能更好的豐富標簽的定義,使標簽愈發完善。
相比于目前主流機器學習算法,該算法更注重的是數據的“運用”、智能結構的搭建以及如何不斷完善和更新。對數據的運用并不是簡單的存儲和調用,通過這些數據的存儲可以很好的完善所搭建的“智能結構”。
1.2 類比算法模型的提出
本文基于類比思維模式,提出了一種實現機器學習數據集半自動標注的算法模型——“類比算法模型”,人類認知事物的基本邏輯是給予各個事物以標簽,包括:外貌、名稱、特征等。并通過這些標簽和已知事物來與未知事物進行類比,相似的標簽,將直接挪用在未知事物上,未知的特征,將通過各種渠道了解,然后再標注。
我們把人當作一個算法模型,其認知事物的過程可以這樣描述:首先數據庫中存在已標注的數據集,且這些數據集可以隨時調用,然后輸入一個新數據,算法模型將調用數據集中與新數據相似度高于80%(該參數會隨著模型的訓練趨近于一個穩定的值)的數據,并與之進行對比,判斷相似的地方,然后直接挪用標簽,剩余未知的內容與以標注的內容同時輸出,由人工復檢,人工復檢需要檢查標注的內容是否正確,然后再標注未知的內容,標注未知的內容過程與人工標注的方式相同。這一過程的流程如圖1所示。
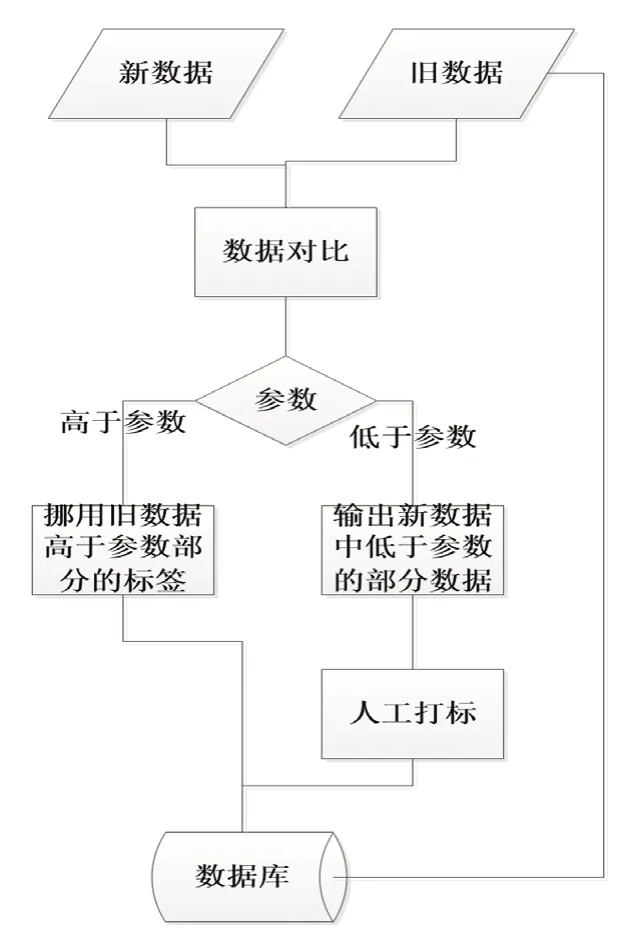
圖1 類比算法流程圖
2 人工智能的發展現狀與未來發展方向的論述
人工智能簡單來說就是類人化的一個系統,可以模仿人類除了創造類的所有行為[4]。要想讓它實現“獨立思考”,就要先探討人的獨立思考是如何形成的。人與生俱來就有自己獨立的思維,但是,人類認知這個世界的過程卻不是僅僅依靠自己來摸索的,在人類認知世界的過程中,會有老師、父母、朋友等來進行引導和影響,簡單來說,老師和父母會把他們認知的世界傳輸給你,然后通過自己的自我化,轉化為自己的知識,從而形成對這個世界的概念,然后以此為基礎來對接觸的新事物打標簽、下定義。這是我們認知世界的一個大致過程。機器學習就是讓我們人類來當人工智能的老師,把我們的世界觀灌輸給人工智能,通過大量的數據訓練,使它能實現某一方面的“智能化”[6]。但這一方式有一個缺點,它不能進行數據的自我更新,訓練完的模型并不會因為它處理的數據越多從而越智能[5]。因此,這一類模型依然是人工智能方面的一個“工具”,并沒有形成一個可以“自我完善”的良性循環。
讓人工智能擁有獨立思考的能力,還有很長一條路要走,但是讓人工智能“類人化”卻并非無法實現,人類認知世界的過程是基于已有的知識來記憶新知識,但是目前的人工智能并沒有很好的“運用”存儲的知識,它沒能通過知識來“獲取”知識。人類是通過類比來不斷豐富對這個世界的認知,所以,構建人工智能框架時,可以借鑒這一思考方式。首先要使人工智能的框架呈開放性,可以隨時進行更新、完善、填充以及更改。然后把儲存的數據打上各種標簽以便進行特征查找和比對。無數的標簽構成了所需要的知識網絡,擴大知識網絡就是在不斷創建新的標簽,充實知識網絡的內容,就是在不斷豐富標簽下的數據。
人工智能的實現依然離不開對算法的開發,算法是人工智能的基礎,就像是人類認識世界的一個底層邏輯,判斷是非對錯、判斷特征等。給事物打上標簽是人類認識世界最普遍的手段,然后隨著自己的理解越來越多,再進行標簽的增加與刪除。所以,我們不能把系統看做一個處理事務的工具,為了處理事務而被寫出來的人工智能系統,并不能稱得上是真的人工智能,大多數智能系統都是通過使用大量的數據訓練模型,當模型達到要求的時候,“成品”就出來了,但是這樣的“成品”,后期的更新與維護,依然需要人工來添加數據和模塊,然后再進行訓練。不能是為了讓它處理數據而處理數據,要做到,處理數據的同時,能不斷完善自身的系統,當系統真正能脫離人工的輔助,方能成為“人工智能”。
3 “類比算法”在人工智能中的應用
類比算法是通過觀察人類認識世界的過程總結出來的,與現有的大多數算法不同,類比算法并不是為了處理數據而提出,它更傾向于對數據的一種“使用”,通過對數據的處理來不斷完善。這個過程依然需要人工輔助,不過可以肯定的是通過不斷處理數據,不斷完善自身,可以使其對人工輔助的依賴性越來越弱,無限趨近于“真正的人工智能”,本人通過類比算法提出了一個文本類半自動化數據標注系統,模型流程圖如圖2所示。
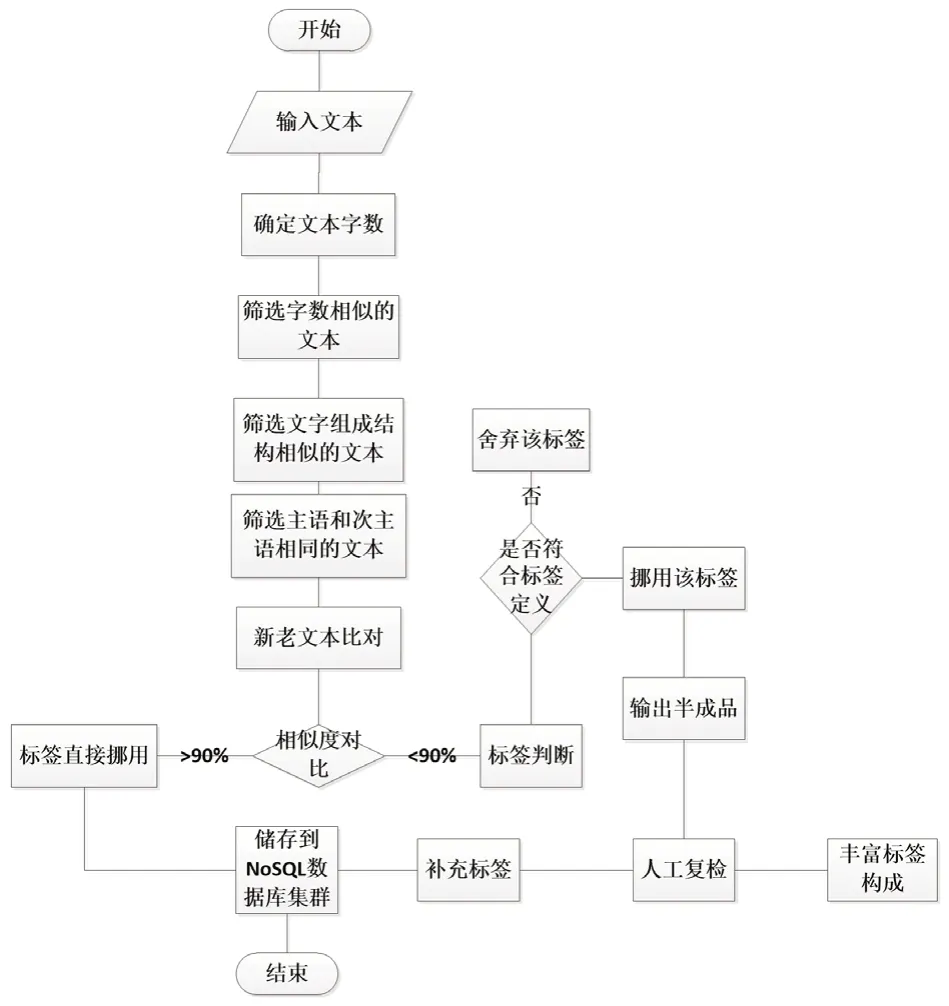
圖2 文本類半自動標注系統流程圖
在豐富標簽構成的過程中有一個完整的反饋環,可以很好地根據標記的內容去不斷完善標簽的定義。但是該過程依然需要人工的干預,例如:當該內容直接被模型定義,且與人工復檢一致,則不需要該內容定義,記作“容易”;如果該內容直接被模型定義,但是與人工復檢不一致,則由該內容完善標簽的定義,記作“中等”;當該內容不被模型定義,即模型已有的標簽無法標記該內容,則由人工干預,增加新的標簽,記作“困難”[3]。
通過這個完整的反饋環,可以不斷地去增加新的標簽,不斷地完善已有的標簽,即“越標記,越準確”。在不斷增加和完善標簽定義的過程中,通過各種類,將各個標簽關聯起來,實現相互關聯的知識網絡。
實現這一目標有一大難點:文本特征如何抓取。如果沒有辦法抓取文本特征,那么定義標簽則無法進行,要想抓取文本特征,就要搞明白什么是文本特征,這是一個很飄渺的東西,尤其是中國文化博大精深,同一句話用不同的語氣讀,意思完全不一樣。受小學語文試卷中精簡句子題的啟發,我發現“文本特征”就是“文本”。我們要做的任務就是縮減句子,盡可能地縮減句子,越簡單越好,直到句子成分只有主語、動詞、賓語、謂語。即,對文本的概括就是我們要找的文本特征。當然這僅僅是文本特征的一部分,更多的標簽還囊括了很大一方面,如:文本類型、篇幅長短、刊登地址。
為滿足多人并發同步訪問,標注平臺的服務器部分采用Nginx實現[2]。主要業務邏輯部分基于類比算法模型框架實現,并采用NoSQL數據庫實現原始文本數據、標簽數據的存儲。為實現友好的用戶界面,平臺的前端基于BootStrap框架實現,并通HTML和CSS控制頁面的美觀性。同時,利用Python的requests程序包實現爬蟲模塊,從互聯網中獲取合法的輔助提示信息。系統的整體框架如圖3所示。
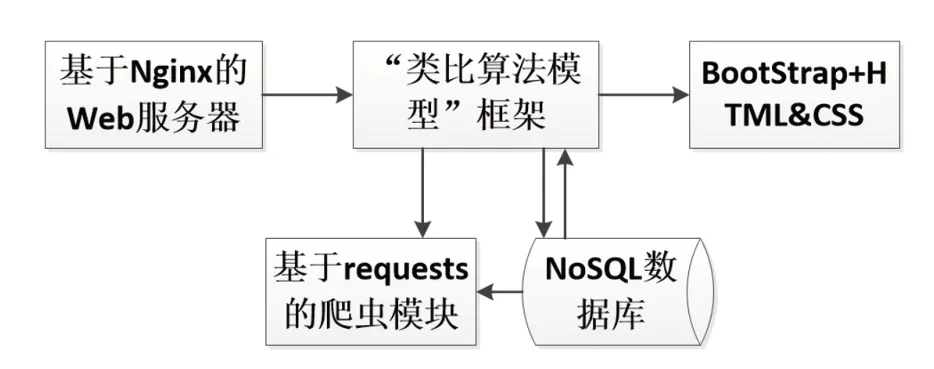
圖3 系統整體框架
本文所提出的文本類半自動化標注系統包含5個模塊:基于BootStrap的前端表示層,基于“類比算法模型”的核心業務邏輯,基于Nginx的Web服務器,基于requests 庫的網絡爬蟲,以及基于NoSQL數據庫的數據庫集群模塊。各個模塊的具體實現功能如下所述。
(1)基于 BootStrap 的前端表示層:該模塊負責為用戶提供友好易用的可視化界面。每個具體頁面通過 HTML 控制界面的布局,并通過CSS 批量控制多個頁面的樣式。同時,該模塊負責處理數據標注師與頁面中的交互,如提交數據、刷新界面等。
(2)基于“類比算法模型”核心業務邏輯:該模塊負責整體協調其他各模塊的輸入輸出數據,實現標注系統的核心邏輯。
(3)基于 Nginx 的 Web 服務器:該模塊負責處理更底層的業務。如根據配置對不同的請求做出不同的轉發。
(4)基于NoSQL的數據庫:該模塊負責將原始數據、標注后的數據、用戶的數據存儲在服務器主機的磁盤中。在標注與查詢過程中,該模塊根據收到的請求對標注數據進行查詢、修改、新增、刪除等操作。
(5)爬蟲模塊:該模塊基于Python的requests程序庫實現。該模塊將原始的文本數據進行處理,封裝成網絡數據包,并以標準化的格式傳送給業務邏輯層。整套網站系統的開發與調試基于 PyCharm集成環境。
4 結語
類比模型的提出,并不僅僅局限在文本標注工作中,類比模型的核心是“通過已有的知識,類比未知的知識,從而減少工作量”。這一概念就可以運用在如自然語言處理,人工智能語音識別模塊,文字識別模塊等眾多場合。
類比模型給予了系統一個思考方式:這個東西是不是和我認知中(數據庫中)的東西一致,不一致的話,那有哪里相似?然后完全未知的部分就會輸出,由人工來定義標簽。“類比”是人類認知過程中很重要的一個思考方式,人工智能的發展依然離不開對人類思考方式的一種模仿,所以類比模型給人工智能提供了一個“磚”,人類的思考方式多種多樣,所以人工智能的思考方式,即模型,也應該是多種模型結合而來的,當遇到不同的情況時,可以調用不同模型來應對,而這些模型,也應該是由人類的思考方式演變而來的。
猜你喜歡
大科技·百科新說(2021年6期)2021-09-12 02:37:27
好孩子畫報(2020年5期)2020-06-27 14:08:05
意林·全彩Color(2019年6期)2019-07-24 08:13:50
商界(2019年12期)2019-01-03 06:59:05
IT經理世界(2018年20期)2018-10-24 02:38:24
小康(2017年16期)2017-06-07 09:00:59
南風窗(2016年19期)2016-09-21 16:51:29
山東青年(2016年1期)2016-02-28 14:25:25
奧秘(2015年2期)2015-09-10 07:22:44
當代修辭學(2014年3期)2014-01-21 02:30:44
