回環結構與PAM結合的雙目圖像超分辨率網絡
2022-09-06 11:09:22張紅英吳亞東廉煒雯
計算機工程與應用 2022年17期
李 雪,張紅英,吳亞東,廉煒雯
1.西南科技大學 信息工程學院,四川 綿陽 621010
2.西南科技大學 特殊環境機器人技術四川省重點實驗室,四川 綿陽 621010
3.四川輕化工大學 計算機科學與工程學院,四川 宜賓 644000
視覺信息是人類獲取萬物信息的主要來源,通過軟件的方法提高原始圖像分辨率的過程稱為圖像超分辨率(super resolution,SR)重建,圖像超分辨率技術滿足了人們觀感所需,在計算機視覺領域蓬勃發展。雙目圖像超分辨率旨在由同一場景下不同視角的兩張低分辨率(low resolution,LR)圖像重建出高分辨率(high resolution,HR)圖像,隨著雙攝系統在大眾生活中的出現,雙目圖像超分辨率在計算機視覺領域日益廣泛應用。由于輸入為左右視角的兩張LR 圖像,使得輸入圖像之間存在視覺、特征、景深和分辨率等差異,解決這些差異性問題,并充分利用雙目圖像間有效細節信息優勢可以提高超分辨率性能,所以豐富的上下文特征提取與表示研究成為了雙目圖像超分辨率重建的研究重點。
圖像超分辨率的研究從最開始基于插值的方法到現在基于學習的方法經歷了飛躍性成就,從人工處理到人工智能、從淺層網絡到深層網絡、再從深層網絡到輕量級網絡,圖像超分辨率技術為人類科技發展做出了卓越貢獻。傳統插值方法[1-3]得到的SR 圖像過于平滑,丟失了高頻細節信息的同時重建出虛假的人工痕跡。基于重構的方法[4-6]研究圖像退化模型,圖像退化的過程本就是SR 成像的病態逆問題,采樣因子的隨意性也使得重建的SR圖像不能滿足人眼視覺需求。基于學習的方法[7-8]是圖像超分辨率領域的巨大飛躍,近年來,深度學習的方法成為圖像處理研究的代表性方法。SRCNN(super resolution convolutional neural network)的問世也給圖像超分辨率研究者奠定了基礎;Dong 等[9-10]在SRCNN 的基礎上改進得到了FSRCNN(accelerating the super-resolution convolutional neural network),FSRCNN 中的擴張塊與收縮塊提升了模型的性能與速度。Shi等[11]在ESPCN(efficient sub-pixel convolutional neural network)中提出的亞像素卷積層廣泛用于超分辨率網絡的重建部分。Tai 等[12]提出的DRRN(deep recursive residual network)結合了Resnet[13(]deep residual network)的多重路徑局部殘差學習、VDSR[14(]accurate image super-resolution using very deep convolutional networks)的全局殘差學習和DRCN[15(]deeply recursive convolutional network for image super-resolution)的多權重遞歸學習,增加網絡深度的同時減少訓練參數,達到了理想的SR 性能。SRGAN[16(]super-resolution using generative adversarial network)采用無監督學習方法為LR圖像生成更多具有真實感的細節。單幅圖像超分辨率在圖像超分辨率領域取得了重要成果,但輸入為單幀圖像也導致重建過程中特征張量缺乏更多的細節信息。
為解決單幅圖像超分辨率輸入圖像細節缺乏的問題,雙目圖像超分辨率應運而生。雙目圖像超分辨率在網絡輸入上比單幅圖像超分辨率擁有更多的細節,由于輸入是同一場景左右目的圖像信息,所以相比視頻超分辨率的多輸入也能夠避免運動模糊和壓縮影響等問題。雙目圖像超分辨率進入深度學習時代是由Jeon等[17]提出的StereoSR(enhancing the spatial resolution of stereo images using a parallax prior)開始的,StereoSR 參照立體匹配的思想,也只是圖像像素級別上的位移對齊,并沒有充分利用好左右圖的信息。Wang等[18-19]提出的PASSRnet(learning parallax attention for stereo image super-resolution)采用視差注意力機制,利用對極幾何極線約束提取左右圖的特征,并取得優異的成果,次年,他們改進了PASSRnet得到了一個通用的模塊SAM(stereo attention module for stereo image superresolution),將其放入單圖超分辨率的網絡中,有利于提高單圖SR 性能。PASSRnet 和SAM 使用3 個卷積核為3×3的具有不同膨脹率的卷積來提取特征,能夠很好提取到不同的大特征,當特征映射小于或等于采樣率時,3×3卷積核不能很好地捕獲上下文的信息,只有濾波器中心用于特征提取工作。
針對雙目圖像重建網絡中特征提取不完整問題,本文提出一種基于深度學習的回環結構與PAM相結合的雙目圖像超分辨率網絡。該網絡在特征提取上提出一種MJR-ASPP+(mixed jumping residuals-atrous spatial pyramid pooling+)構成的回環結構,能很好地提取圖像中的高低頻細節特征,混合跳躍式殘差連接相結合的首尾呼應結構可獲取最小損耗的同時得到較高精度,從不同的深度操作捕獲網絡多尺度信息;在特征提取與視差注意力模塊中采用擴張殘差(expanded residuals,ERes)網絡作為過渡塊,用來學習雙目立體匹配特征的網絡能力,以此來緩解其在共享網絡ERes與MJR-ASPP+塊中的競爭;在雙目立體視覺的四個公開數據集中,都取得了優異的SR性能,特別是在Middlebury測試集中,×2放大倍數的PSNR 達到34.67 dB,×4 放大倍數的PSNR 達到28.75 dB。
1 本文網絡結構
回環結構與PAM結合的雙目圖像超分辨率網絡由雙目立體視覺LR圖像對作為輸入,并重建出左圖(或右圖)SR圖像。整體網絡框架如圖1所示,所提網絡由特征提取、視差注意力機制和超分辨率重建三部分構成。首先利用權值共享的卷積操作初步提取LR 的淺層特征,通過交替級聯的MJR-ASPP+與擴張殘差Res1 塊進一步提取圖像的深層特征;接著將提取的特征張量輸入PAM 計算視差圖并融合所有特征張量信息;最后利用四個殘差塊對融合后的特征張量進行卷積操作,經反卷積處理后得到高維張量并通過卷積映射到RGB 空間,得到最終的SR圖像。整體網絡框架參數設置如表1所示,表中介紹了網絡中各模塊參數的設置及特征張量輸入與輸出的通道變換。下面將對網絡設計中的各模塊及損失函數進行詳細說明。
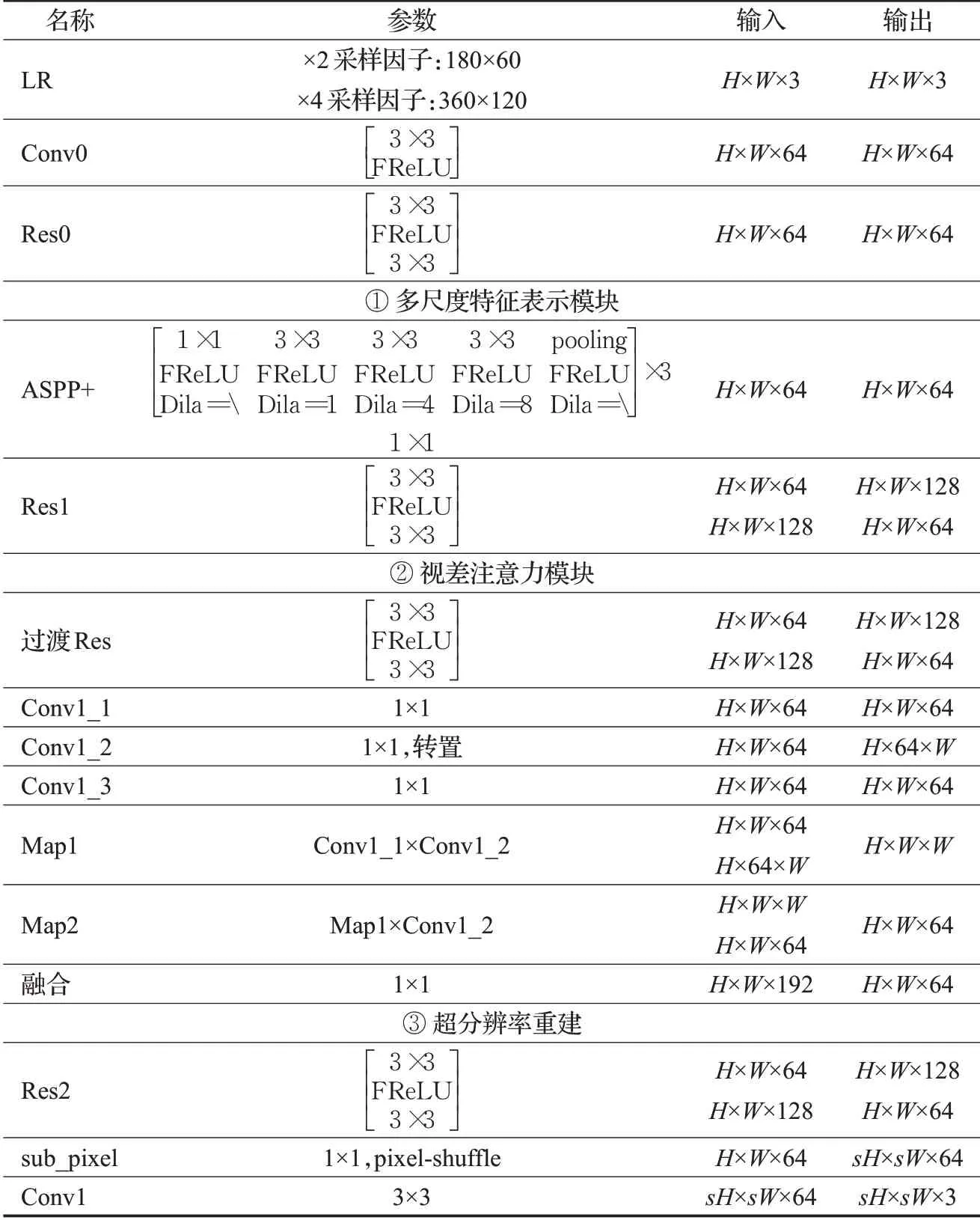
表1 整體網絡參數設置說明Table 1 Description of overall network parameter setting
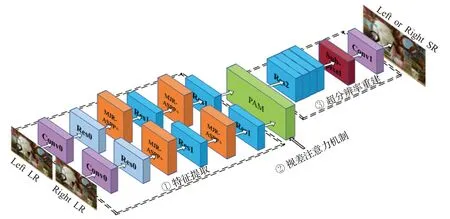
圖1 整體網絡框架Fig.1 Overall network framework
1.1 特征提取
利用權值共享的卷積網絡提取輸入LR圖像的淺層特征,獲取圖像中大致概貌和輪廓,得到圖像的近似信息。第一層卷積層與第二層殘差塊的卷積核都為3×3,用每個卷積核去遍歷輸入雙目圖像時,卷積核的大小是固定不變的,每個卷積核都會去掃描整張輸入的LR 圖像,輸入圖像中所有特征都共享了相同的權值。在卷積神經網絡中,利用權值共享卷積網絡不僅可以減少神經網絡中需要訓練的參數個數,使深度學習網絡運算簡潔高效,也能使網絡在大規模的數據集上靈活運算。
在淺層特征的基礎上進一步提取輸入圖像的深層特征,得到圖像的邊緣、輪廓和細節信息。如圖1 整體網絡框架所示,本文通過交替級聯的回環結構MJR-ASPP+與擴張殘差Res1 塊進一步提取圖像的深層特征,輸入特征首先進入回環結構MJR-ASPP+中以生成多尺度特征,接著,這些多尺度特征經過擴張殘差塊Res1進行特征融合,最后,將回環結構與擴張殘差塊相結合操作重復兩次以生成最終左右圖的特征張量。下面對回環結構進行詳細介紹。
1.1.1 回環結構MJR-ASPP+
豐富上下文的圖像特征提取與表示對超分辨率任務有著重大意義,本文在特征提取部分提出一種混合跳躍式殘差空洞空間金字塔池化(mixed jump residualsatrous spatial pyramid pooling+,MJR-ASPP+)的回環結構用于多尺度特征表達,MJR-ASPP+是將ASPP+采用回環結構的方式連接而成,如圖2 所示,將三組ASPP+塊使用長短跳躍連接的方式,每一塊的輸出與輸入相連,首尾緊扣,形成回環式結構。回環結構能有效捕獲圖像多尺度特征,相比傳統多尺度特征提取網絡,回環結構具有以下三個優點:第一,回環結構采用不同卷積核和不同膨脹率的卷積層提取圖片中不同層次細節特征的同時,采用全局平均池化層可以有效保留圖像背景信息,在整個網絡結構上做正則化防止過擬合,賦予每個通道實際的類別意義;第二,回環結構中ASPP+采用殘差連接的方式,加深網絡深度,使得網絡每一條通路都有一個感受野,形成不同感受野和不同膨脹率的卷積集合,從而獲取更多細節紋理信息;第三,在殘差連接網絡中,采用長跳躍連接,將不同層次的特征拼接在一起,達到增加特征多樣性、加快訓練的目的。下面將具體介紹每一模塊的作用。
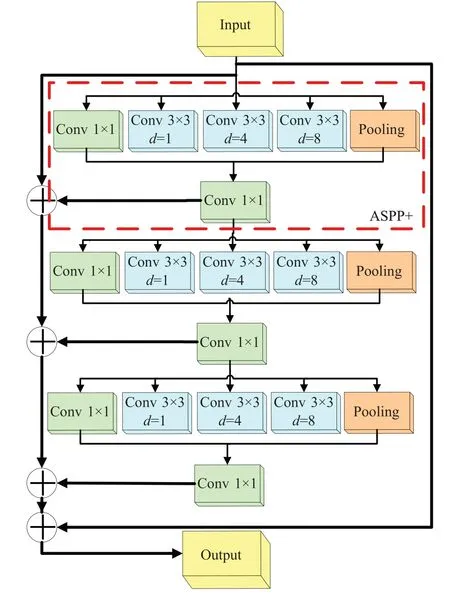
圖2 MJR-ASPP+模塊Fig.2 MJR-ASPP+ module
(1)改進空間空洞金字塔池化模ASPP+
圖像超分辨率任務的核心是重建出高頻細節信息的同時保留低頻細節信息,DeepLabV3 工作中Chen等[20]對ASPP(atrous spatial pyramid pooling)進行了改進,改進的ASPP 很好地處理特征映射過大或過小的情況,而在所有的超分辨網絡中,第一步是提取LR圖像特征,本文將改進的ASPP 思路運用在雙目圖像超分辨率特征提取與表示這一步驟中,可以使網絡獲得多尺度的特征表達。本文所提的MJR-ASPP+模塊中,ASPP+模塊包含一個核為1×1的卷積層、三個核為3×3的卷積層(膨脹率分別為1、4、8)和一個池化層。其中1×1卷積負責提取大范圍的圖像信息,也能避免因3×3卷積層的膨脹率過大而忽略掉的邊界信息;3 個3×3 的卷積層擁有不同的膨脹因子,能夠擴大感受野提取到多尺度的圖像特征;對特征張量進行自適應平均池化后再通過雙線性插值上采樣,是從圖像級特征出發,獲取圖像的全局特征。將三者信息進行融合,即可提取到圖像的大小局部特征及背景全局特征,也為網絡下一層傳遞了輸入圖像的高低頻多尺度特征,符合超分辨率重建的初衷,所以將改進的ASPP 運用于雙目圖像超分辨率特征提取部分,在文中消融實驗部分也證明了此方法的有效性。
(2)混合跳躍式殘差連接MJR
在深度學習網絡中,跳躍式連接的方式能很好地解決梯度消失等問題,本文所提的MJR-ASPP+模塊,采用長短跳躍相結合的混合跳躍式連接方式來獲取圖像的多尺度特征。具體為:將三個ASPP+塊以混合殘差的方式分別級聯起來,稱為短跳躍式殘差ASPP+(short jump residual-ASPP+,SJR-ASPP+),根據梯度鏈式法則,梯度是從最后一層往前逐層傳遞回來的,這種殘差方式的短跳躍連接相當于是一個深層網絡,提取了圖像的深層特征;將輸入與SJR-ASPP+塊的輸出結果經長跳躍式(long jump residual,LJR)連接,得到最后的特征張量圖。這種混合跳躍式的連接方式從不同深度對圖像特征進行處理,根據圖像的尺度自相似性,長短跳躍連接能夠獲取多尺度的圖像特征,在本文實驗中也證明了混合跳躍式連接使超分辨率網絡具有更好的SR性能。
(3)擴張殘差模塊ERes
回環結構MJR-ASPP+提取的特征張量來自不同感受野和膨脹卷積的集合,為融合多尺度特征,本文將傳統的殘差塊替換為擴張殘差ERes塊,與普通殘差相比,ERes 具有更好的特征提取和綜合迭代功能。如圖3 所示,ERes 將第一層卷積的輸出變為原來通道的2 倍,在最后輸出時將通道數恢復為原來的通道數,特征維度的變換有利于圖像去噪和多尺度特征的融合,ERes 與回環結構交替級聯使網絡更加充分地提取與融合圖像從淺層到深層的特征信息。
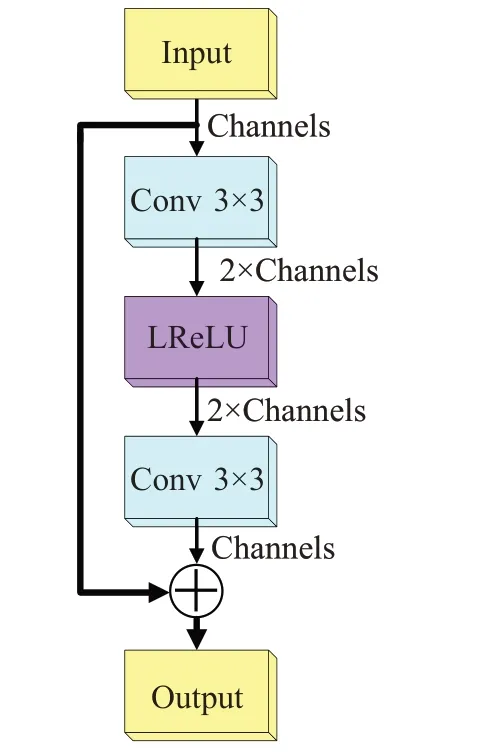
圖3 擴張殘差模塊Fig.3 Extended residual module
1.1.2 FReLU激活函數
本文在特征提取模塊提出了一種高效且復雜的回環式網絡用于提取圖像特征,由于網絡結構的復雜性,導致常規卷積無法學習類似的精度,面對網絡模型的復雜度,本文用FReLU 替換LReLU。FReLU[21]是專門用于視覺任務的激活函數,增加空間條件來擴展ReLU和PReLU,增強激活空間的敏感度,顯著提高圖像視覺效果。FReLU 表達式如公式(1)所示,式中T(x)表示高效率的空間上下文提取結構,使用了空間表示信息。FReLU 能自適應地獲取ASPP+塊中提取到的特征信息,膨脹卷積層和FReLU 激活函數層的結合提高了卷積神經網絡(convolutional neural network,CNN)中捕獲空間相關性的效率,本文在消融實驗中也對FReLU激活函數在網絡中的使用進行了驗證。

1.2 視差注意力模塊PAM
視差注意力模塊(parallax-attention module,PAM)是Wang 等在PASSRnet 中提出的一種沿極線具有全局感受野的視差提取模塊,巧妙運用對極幾何中的極線約束,有效地集成了雙目立體視覺LR圖像對的有用信息,即雙目圖像對之間無遮擋的有效區域信息。PAM如圖4所示,本文將MJR-ASPP+提取的左右特征張量輸入擴張殘差過渡塊Res2 中,過渡塊用來學習雙目立體匹配特征的網絡能力,以此來緩解其在共享網絡中擴張殘差塊與MJR-ASPP+塊的競爭。

圖4 視差注意力模塊Fig.4 Parallax-attention module
圖4 中的視差圖ML-R和MR→L描述左右目的相似關系。圖5給出了視差圖計算的示意圖,其中圖5(a)為左右目相似關系,(b)為左右目對齊操作。在圖5(a)中,MR→L是一個H×W×C三維特征,MR→L(i,j,k)表示沿著i的維度取出切片MR→L(i,:,:)∈?W×W,將切片MR→L(i,:,:)∈?W×W經softmax函數處理后,水平方向和變為1,切片(j,k)這一點表示右圖(i.k)這一點對左圖(i,j)的貢獻,在真實三維世界中,期望(j,k)的值為1。視差注意力圖中的值描述了左右圖像素級別的對應關系,利用此對應關系做左右目的對齊操作,稱為幾何已知的矩陣乘(geometry-aware matrix multiplication)。如圖5(b)所示,得到右到左的視差注意力圖MR →L后,做右圖到左圖的對齊操作,從左圖IL∈?H×W×C中沿H維度取 出 切 片IL(i,:,:)∈?W×C,同 理 視 差 圖 的 切 片 為MR→L(i,:,:)∈?W×W,右圖的切片為IR(i,:,:)∈?W×C,由圖(a)中(j,k)的含義可知,當(j,k)為1時,左圖(i,j)點的值對應等于右圖的(i.k)點,從亞像素的層面講,當(j,k)為0.5 時,是將左右圖兩個像元按50%的貢獻值混合在一起。由于采用矩陣乘的方式得到視差圖,所以不用單獨計算出每點的視差值,左右視差圖就能很好地得到左右目的對應關系。
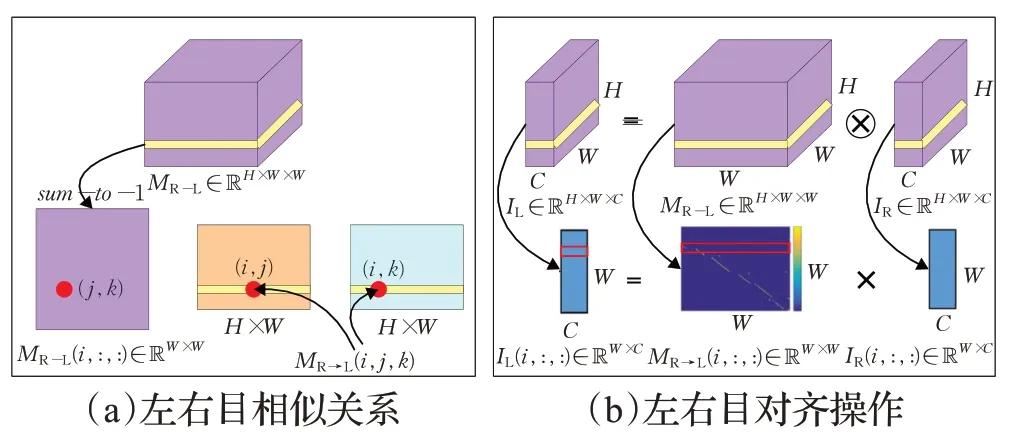
圖5 視差圖計算Fig.5 Disparity map calculation
1.2.1 一致性
由對極幾何極線約束,左圖中的一點a,在右圖中一定在點a所在的那一行里。左右目圖像進行對齊操作時,假設ILL與IRR是從低分辨率圖像對中提取出的深層特征,PAM 生成視差注意力圖MR-L和ML-R,理想情況下,左右圖的對應關系可得出如公式(2)所示的左右一致性原理,右到左視差圖MR-L乘以右圖ILR可以得到左圖ILL,同理得到右圖ILR。進而得到循環一致性如公式(3)所示,其中,ML→R→L表示左圖到右圖再到左圖的視差圖,?表示批次化矩陣乘。
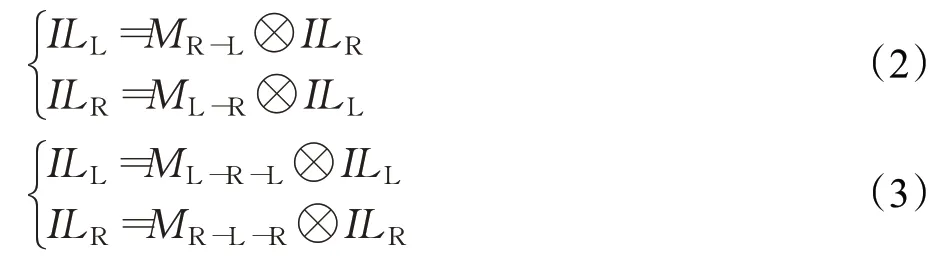
其中:
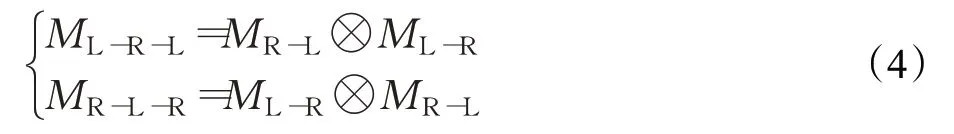
1.2.2 有效掩碼
視差注意力圖不僅描述左右圖的相對信息,還能描述左右圖之間的遮擋信息。在遮擋范圍內,賦予像素極小的權重值,如公式(5)所示,當ML→R(i,j,k)或MR→L(i,j,k)的值小于0.1時,認為像素在對應圖中是被遮擋的,本文采用形態學的操作來處理遮擋區域。

1.3 超分辨率重建
如圖1 整體框架圖中③超分辨率重建模塊所示,本文采用四個殘差塊的目的是對融合后的左右圖特征張量進行多卷積操作,得到高維特征張量,有利于反卷積處理;此外,殘差塊除了能減弱梯度消失外,還是一種自適應深度操作,多個殘差塊級聯起到直接信息的傳遞作用。本文在消融實驗部分證明了選用四個殘差塊能更好提升網絡的整體性能。殘差塊中采用FReLU作為激活函數,反卷積采用Shi 等[11]的sub-pixel 上采樣對高維特征進行操作,避免上采樣時出現人工痕跡等不真實的信息。最后利用卷積將特征圖映射到RGB 空間,得到最后的超分辨率左圖或右圖。
1.4 損失函數
為了訓練回環結構與PAM結合的雙目圖像超分辨率網絡,本文充分利用雙目圖像對之間的一致性原理,采用公式(6)所示的損失函數,該損失函數由超分辨損失LSR、照度損失Lphotometric、平滑損失Lsmooth和循環一致性損失Lcycle構成。
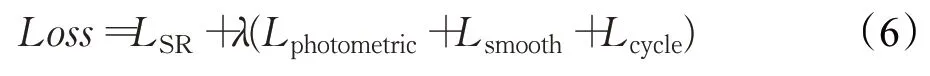
LSR為超分辨率中的均方誤差(mean squared error,MSE)表示,其表達式如公式(7)所示,它衡量原始的HR圖像IHR與重建出的SR圖像ISR間的差異性,其中‖ · ‖2是2范數。

對圖中的非遮擋區域引入照度損失Lphotometric,如公式(8)所示,其中p表示具有有效掩碼遮擋值的像素,‖ · ‖1是1 范數。視差圖MR-L與ML-R反映左右圖與之間的對應關系,采用視差圖計算照度損失可以使其更好地表示左右目圖像之間的左右一致性。公式中可看出,視差注意力圖與右圖(左圖)批次化矩陣乘后方可得到左(右)圖。
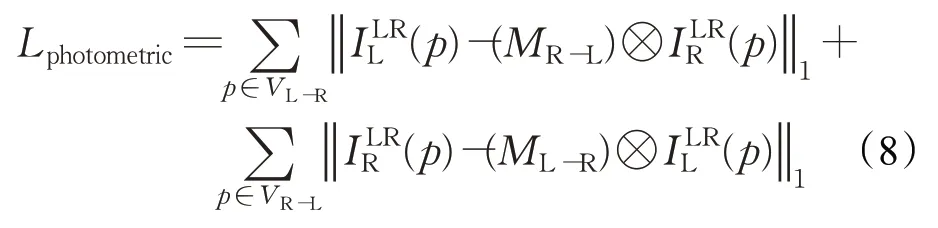
為了在無紋理或弱紋理區域生成準確一致的視差注意力圖,本文在視差圖上采用公式(9)所示的平滑損失Lsmooth。該等式的兩項因式分別代表視差注意力圖中的垂直一致性與水平一致性。
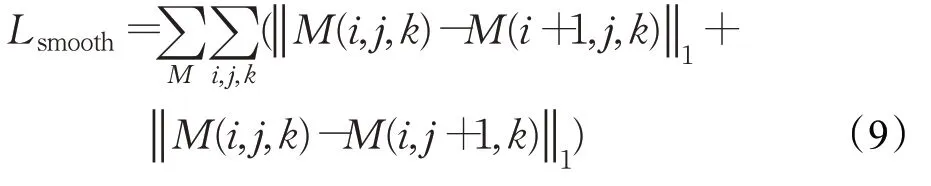
為了使用循環損失體現視差注意力圖的循環一致性,本文采用公式(10)所示的循環一致性損失Lcycle,由該式可知左圖(右圖)經過兩次注意力圖的映射后,將得到左(右)圖本身。其中MR-L-R是單位矩陣。
2 實驗結果與分析
本章將詳細介紹具體實驗操作與實驗結果,首先介紹實驗的數據集與實驗的預處理細節,接著通過消融實驗測試本文提出網絡的有效性,最后將實驗結果與典型的超分辨率算法比較,進一步驗證本文方法的SR性能。
2.1 數據集
為驗證實驗過程的一致性與準確性,本文采用與PASSRnet網絡同樣的數據集。在訓練集上使用該團隊收集的Flickr1024數據集中的800張訓練集和雙目立體視覺公開數據集Middlebury 中的60 張訓練圖片。將860張HR圖片進行2倍和4倍下采樣,得到本文網絡最終的訓練數據集,并將LR 圖像對和相應的HR 圖像對送入網絡進行有監督訓練。考慮到測試集的選取要遵循景物的多樣性、視差變化的靈活性、景深的可對比性等必要條件,按照PASSRnet的實驗數據準備,本文也相應選取了Middlebury 測試集中的5 幅圖像、KITTI2012測試集中的20 幅圖像、KITTI2015 測試集中的20 幅圖像和Flickr1024 測試集中的112 幅圖像作為測試集,同樣對測試集進行2倍或4倍下采樣。
2.2 實施細節
本文實驗在Nvidia GTX 2060 GPU 上進行,在Pytorch網絡框架上實現,使用Adam方法對網絡模型進行優化,其中,Bach size設置為40,初始學習率為0.002,每30 個Epochs 后降低一半,訓練在90 個Epochs 后結束,因為更大的Epochs對SR性能影響不大。
在訓練階段,首先對雙目HR 圖像進行雙三次插值下采樣,生成對應的LR 圖像對;然后對生成的LR 圖像進行預處理,將其裁剪為30×90 個步長為20 的圖像塊,它們在HR圖像中對應的圖像塊也被裁剪出來,水平塊的大小慢慢增加到90 以避免訓練集中圖片的大小差異;最后為了增加訓練集的樣本數量,對裁剪出來的圖像塊進行平移和旋轉。本文采用峰值信噪比(peak signal-to-noise ratio,PSNR)和結構相似性(structural similarity,SSIM)指標來評價測試圖片的SR性能。
2.3 消融實驗
本節對消融實驗進行介紹,以證明本文網絡的設計與選擇,消融實驗在KITTI2012和Middlebury測試集上實現,采樣因子為4倍,圖6訓練曲線顯示了80個Epochs的訓練結果,具體實驗環節與實驗結果如表2、圖6和圖7所示。
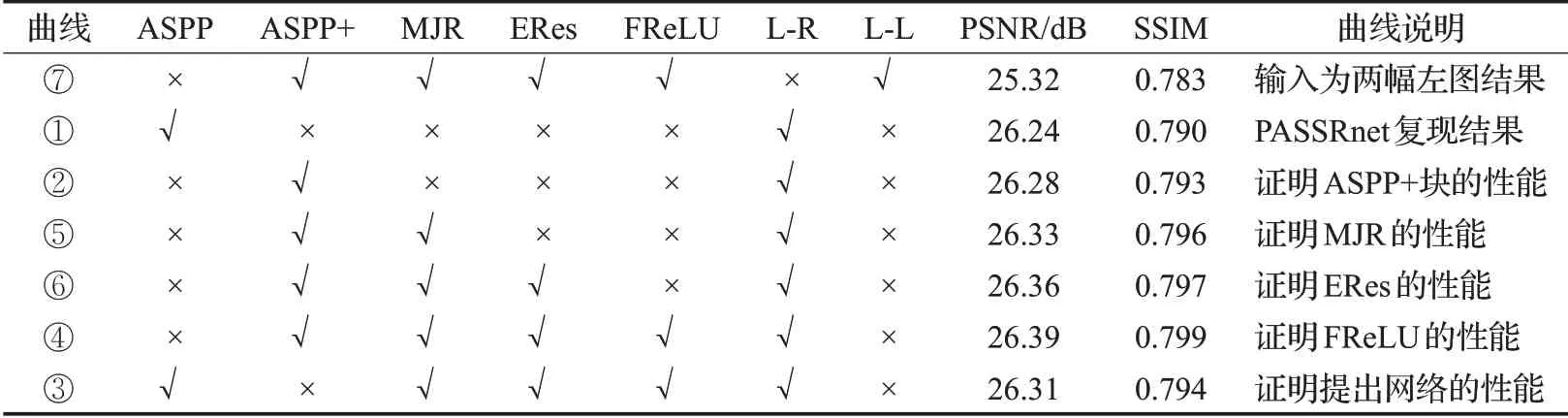
表2 消融實驗各環節與測試結果Table 2 Ablation study and test results
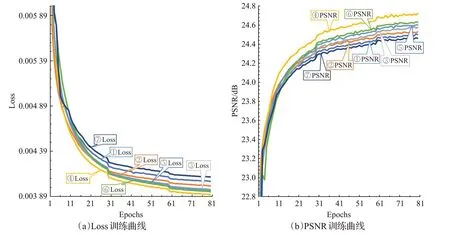
圖6 消融實驗訓練結果Fig.6 Ablation study and test results
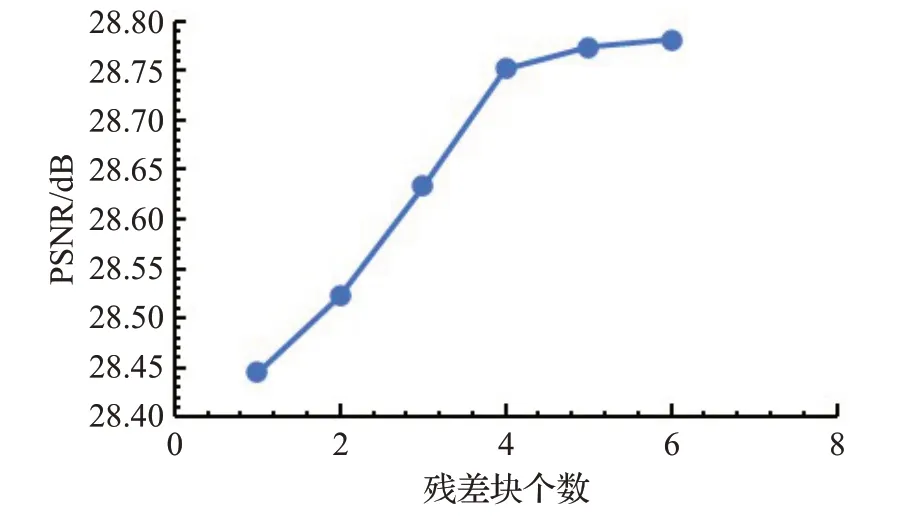
圖7 網絡重建部分的殘差塊個數Fig.7 Number of residual blocks in network reconstruction
表2為消融實驗各環節與KITTI2012測試集的實驗結果,圖6 是消融實驗訓練時的Loss 值與PSNR 值。圖6中曲線①是文獻PASSRnet的復現結果,曲線②是使用ASPP+后的結果,從結果可以看出在原本的ASPP塊中增加了1×1卷積層和池化層后,PSNR提升了0.04 dB,因為本文改進的ASPP+模塊能夠獲取更完整的感受野,達到了豐富的多尺度特征提取與表達的效果。在ASPP+的基礎上,繼續調試本文網絡,首先對殘差ASPP+添加長跳躍殘差連接,使整個ASPP+模塊通過混合跳躍殘差連接的方式傳遞不同深度的信息,如曲線⑤所示,對比曲線②的實驗結果,采用混合跳躍式殘差連接的ASPP+塊在最后的網絡重建結果優于曲線②。接著擴張殘差使用在本文網絡的特征提取和視差注意力機制上,曲線⑥中PSNR 值比曲線②提高了0.08,是因為擴張殘差可以起到很好處理網絡中圖像噪聲和平緩網絡模塊間權值共享的作用。最后,在本文提出的多尺度特征表示網絡上進行超參數的改進,替換ReLU 函數為FReLU,得到本文最終的SR 重建方法,曲線⑦無論在訓練中還是測試中都達到了最優的效果。為了證實本文網絡的有效性,去除PASSRnet 網絡的ASPP 塊,其他網絡連接方式都與本文一致,相比曲線③和曲線②可以看出,采用混合跳躍式殘差連接方式和FReLU 函數對網絡也有一定幫助。此外,本文還對輸入為兩張一樣的圖像進行實驗,結果可以看出曲線⑦得到的結果并不理想。
圖7 是本文在網絡重建部分使用殘差塊個數在Middlebury 測試集上的PSNR 結果,由圖中曲線可以看出殘差塊的個數越多,圖像的PSNR 值越高,特別是在曲線前半部分,每增加一個殘差塊,PSNR 值就提升0.1 dB左右,但當殘差塊的個數增加到四個之后,PSNR結果提升只有0.014 dB 左右,根據網絡模型大小和SR性能提升綜合考慮,在網絡重建部分采用四個殘差塊最為適宜,實驗結果也表明在超分辨率重建部分選取四個殘差塊能提升網絡的整體性能。
綜上,消融實驗驗證了本文多尺度特征表示的雙目圖像超分辨率重建網絡設計與選擇的意義,消融實驗中也看出了MJR-ASPP+塊、混合跳躍式殘差、擴張殘差、FReLU函數和重建使用四個殘差塊能更好提升網絡的SR性能。
2.4 本文網絡參數規模分析
本文網絡參數模型分別從參數數量Params、理論計算量FLOPs(floating point operations)、PSNR 和SSIM四方面來分析,測試結果在Middlebury 數據集中實現,具體分析結果如表3 所示。首先是對本文網絡自身的參數規模進行分析,去除本文網絡中的MJR-ASPP+塊和PAM 塊對于本網絡來說雖然參數量和計算量降低了,但總體SR性能也跟著降低;然后對比雙目圖像超分辨率重建的兩個典型方法,本文網絡參數量比StereoSR降低了0.38×106,計算量降低了0.329 GFLOPs,PSNR增加了2.01 dB,SSIM提高了0.011,取得了優異網絡性能,但對于PASSRnet 結果,雖然模型的參數量與計算量相對高一點,但最終也達到了更好的SR 性能。針對模型參數規模分析,本文的下一步工作也將沿著輕量級網絡發展,在降低模型計算量的同時取得良好的SR性能。
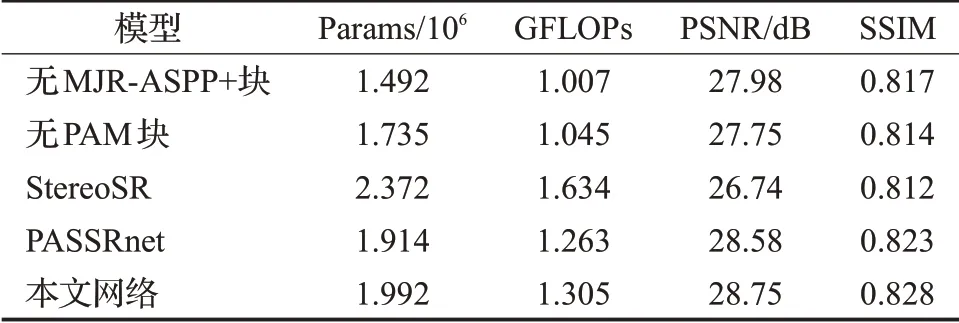
表3 網絡參數規模分析結果Table 3 Results of network parameter scale analysis
2.5 對比實驗
對比實驗選取Flickr1024、Middlebury、KITTI2012和KITTI2015四個雙目立體圖像公開數據集,與代表性單幅和雙目圖像超分辨率重建方法作對比,代表方法有SRCNN、VDSR、DRRN、StereoSR、PASSRnet,實驗結果如表4所示。表4實驗對比結果是對四個公開數據集圖片結果進行平均值比較,從表中可以看出MJR-ASPP+在×2 或×4 的采樣因子中都取得了最好的結果,在Middlebury 數據集中,×2 的PSNR 相比PASSRnet 提高了0.62 dB,×4 的PSNR 提高了0.17 dB;在KITTI2015 數據集中,×2 的SSIM 相比PASSRnet 提高了0.011,而×4 的SSIM提高了0.015。
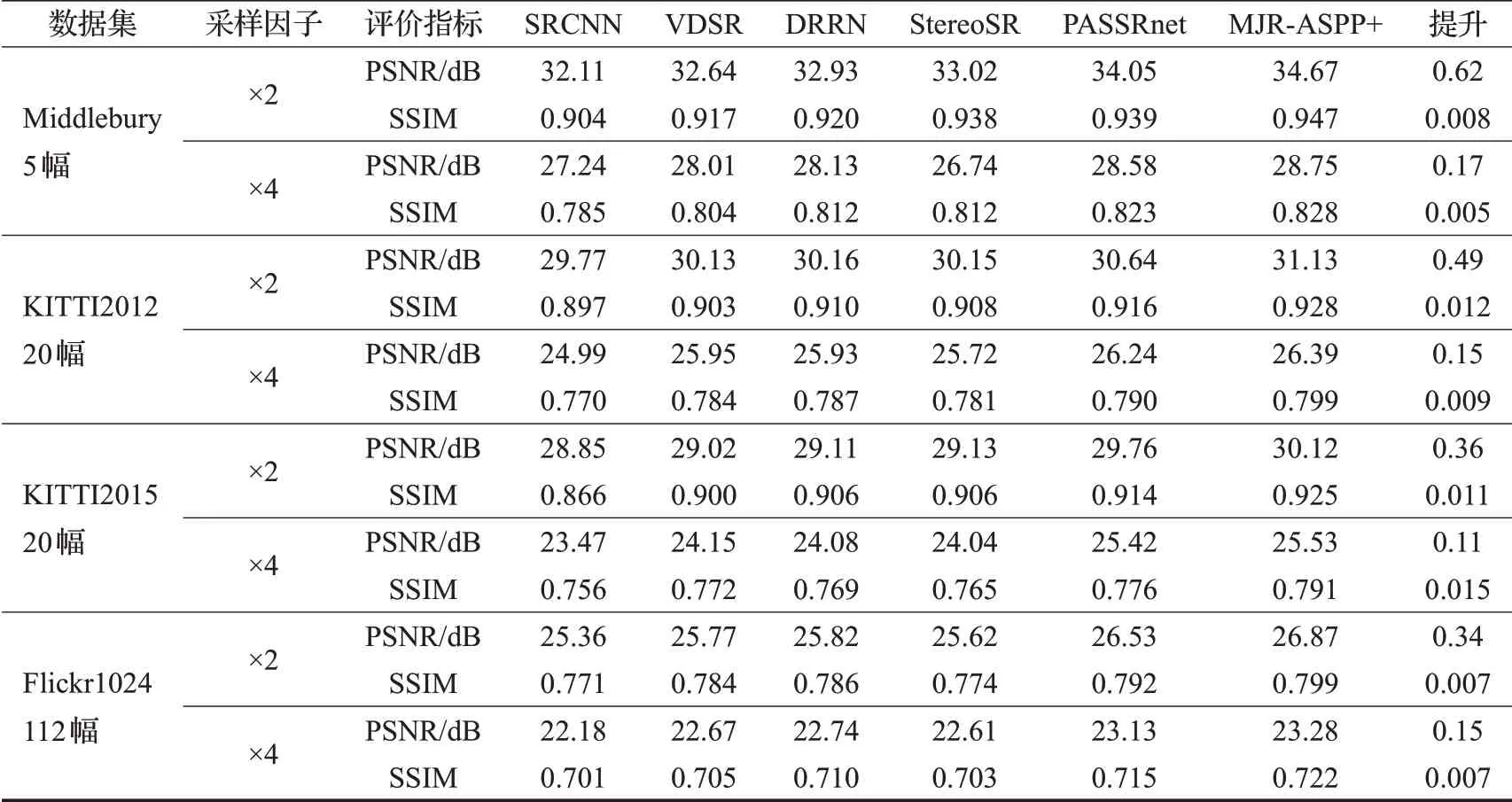
表4 數據集實驗對比結果Table 4 Experimental comparison of data sets
圖8 和圖9 的實驗結果分別為放大4 倍和2 倍的重建結果,選取Flickr1024 測試集中0031、0089、0107 和Middlebury中的motorcycle圖像,本文MJR-ASPP+網絡重建出的圖像在評估和視覺效果上都取得了較好的性能,其中,×4放大倍數的兩幅圖像的PSNR對比PASSRnet 分別提高了0.15 dB 和0.22 dB,×2 放大倍數的兩幅圖片PSNR分別提高了0.33 dB和0.75 dB。從視覺效果上看,圖片0089 解決了PASSRnet 重建后出現的噪聲,整體細節輪廓清晰了許多,如左上角白色弧線邊緣恢復的更連續,臺階分割線也更加分明,右下三角階梯上的高光和陰影部分也更加接近原始圖像;圖片0107 恢復的細節信息更平滑,如左側蒲公英樹干上的紋理細節要比幾種典型方法清晰,蒲公英上的絨毛部分PASSRnet和本文方法都恢復出了根根分明的效果,但本文方法恢復的絨毛邊緣信息更豐富;圖片0031 中字母和兩邊線條的輪廓信息相對PASSRnet 要更明顯,且恢復出的色彩信息更接近原始圖像;本文方法在圖片motorcycle中完整地恢復出了車的凹槽部分,其中在車輪與地面的分界部分,本文方法避免了PASSRnet中產生的噪聲顆粒,在車輪上的細節紋理部分,本文方法比原有的典型算法恢復出了更多的細節信息,特別是左下角磨損部分,也能很好地凸顯車輪的凹凸信息。

圖8 實驗對比結果(×4)Fig.8 Experimental comparison results(×4)

圖9 實驗對比結果(×2)Fig.9 Experimental comparison results(×2)
本文網絡采用回環結構MJR-ASPP+提取圖像多尺度特征,使圖像在重建后能完整恢復出物體邊緣輪廓信息,同時也能恢復出圖像中大部分細節紋理信息,在計算機視覺領域中,圖像中的輪廓邊緣信息用于區分物體間的差異,反映物體的位置信息,而圖像中的細節紋理信息則反映物體的主要信息,這兩種信息為圖像分割、目標檢測、機器視覺和模式識別等任務奠定基礎。
3 結束語
雙目圖像超分辨率在計算機視覺領域有著重要的應用前景,在超分辨率重建技術中,輸入為同一場景的兩張圖像相比單幀圖像擁有更多的細節信息,且相對多輸入的視頻圖像超分辨率可以避免運動模糊和噪聲影響等優勢。如何充分利用好雙目圖像左右圖的細節信息成為雙目圖像超分辨率重建的重難點,針對雙目圖像豐富上下文的特征提取與表示問題,本文提出一種多尺度特征表示的雙目圖像超分辨率重建方法,采用MJRASPP+模塊和擴張殘差對圖像進行特征提取,在整個網絡框架中使用FReLU 激活函數,并在比較四個公開數據集的實驗結果中,均達到了最優的效果,從而也進一步證實了本文多尺度特征表示網絡框架的優異性能。
本文提出的多尺度特征表示網絡雖然在輪廓信息重建上取得了很好的效果,但在細節紋理增強上還需深入研究。在接下來的工作中,將繼續沿著雙目圖像間信息提取和視差注意力機制方面內容,解決雙目圖像細節紋理恢復不明顯和視差變化影響大等問題;并進一步輕量化網絡,使網絡提高超分辨性能的同時,減輕內存消耗。
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
中華手工(2017年2期)2017-06-06 23:00:31
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
中外會展(2014年4期)2014-11-27 07:46:46
河南科技(2014年23期)2014-02-27 14:19:15
