基于大數據背景的大學生就業預測平臺設計與實現研究
2022-09-05 04:19:24劉國強
蘭州職業技術學院學報 2022年4期
劉國強
(蘭州職業技術學院 電子信息工程系, 甘肅 蘭州 730070)
一、引言
近年來,我國高校畢業生人數不斷增加(圖1),2021屆全國普通高校畢業生總數更是達到歷史最高值909萬[1]。隨著畢業人數的逐年攀升,就業壓力更加凸顯。
目前大學生就業存在幾個現象:一是“后疫情時代”全國各地尤其是大中城市疫情時有突發,高校畢業生畢業找不到工作,畢業等于失業;二是隨著我國社會人口老齡化,很多行業人才短缺出現了用工荒;三是我國各地區經濟發展不平衡,用工需求不平衡,導致很多畢業生不知到何處就業,而很多用人單位又找不到所需要的人才;四是我國近幾年大力開展鄉村振興,急需大量的高校畢業生投入到家鄉建設中去。解決這些問題需要對影響大學生就業的各個方面的數據進行收集分析,從而為高校畢業生就業提供就業指導,為高校教育教學調整給出參考數據,設計開發就業預測平臺隨之應用而生。
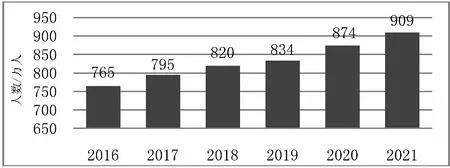
圖1 2016—2021年中國高校畢業生人數變化趨勢
二、大學生就業預測平臺的建設意義
大數據分析和預測各城市的某職位飽和度,并通過多個角度分析職位熱度,受歡迎度等信息,并以此來觀測某區域的職位容納、待遇等指標,預測其未來的趨勢,為平臺發布透明的分析結果,為求職者給予可信的職業建議。
從2015—2021年中國就業人員數據統計情況表1所示入手,利用大數據分析職位給出預測及建議是一種非常有用且有效的方法。利用Hadoop搭建大數據平臺,結合近兩年新冠肺炎疫情突發時間地點進行分析,并且將其不斷優化及改善,為大學生就業提供可參考的數據。

表1 2015—2021年中國就業人員數據統計情況
三、大學生就業預測平臺的建設現狀
在現有的市場中,作為就業預測的平臺并不多見,更為平常的則是形如“2020年就業調查報告”“2020年就業形勢分析報告”“2021中國就業形勢及職業發展前景大數據分析”這樣的以文本內容和邏輯分析為核心的報告說明。在諸如此類的報告中,對于數據的把控,以及對求職者的具體需求涉及程度較淺[2]。故本平臺在數據存儲的成本相對便宜的前提下,將會爬取大量數據進行基礎的相關分析,并進行分析結果的透明展示,以增加可行性以及真實性。
經大數據的分析,平臺可以將大量的結果展示給用戶,從而可以讓用戶更為直觀的接收到我們的信息。再對用戶的習慣,偏好,需求了解的基礎上,可以進行一定程度上的定制、具體建議以及相關的服務,這將有助于提高平臺的用戶轉化率。
傳統的就業分析報告沒有統一的標準,某些用語晦澀難懂,并且內容繁雜的問題勢必造成不良影響。在將此平臺化之后,各方面的問題將會得到一定程度的解決,將為用戶提供優質的服務。平臺將圖形化展示所查詢職業在各個地區具體需求情況、工資分布、學歷要求、經驗需求等等,而且通過多元線性回歸模型輸入本人城市、學歷、經驗可預測薪資等。
四、大學生就業預測平臺的設計思路
利用大數據分析職位的數量,爬取選定的城市或地區的職位信息,再參考行業信息、地區職位飽和度等因素,多維度的分析職位數據,并以此來評估其接納能力、發展潛力、晉升情況等指標,并且參考評價內容來預測其未來的發展趨勢給出合理的建議,給用戶提供詳細的數據支撐,為用戶提供最為合理貼心的服務。
本文所涉及的技術及平臺:ECS上面的 CentOS、Linux 7.3、Hadoop、JDK 1.8、Echarts。根據平臺分析,大數據分析就業情況時,結合用戶因素和具體數據等幾大要素,對于用戶或某行業發展都具有極大的參考價值。在疫情影響后的就業整體情況來看,多數職位都在要求、待遇方面都做出了相應的調整,使其更貼合當下趨勢。
(一)總體功能結構圖
總體功能結構圖2所示。
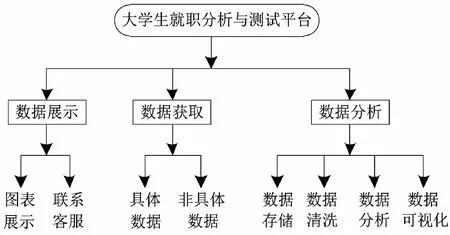
圖2 總體功能結構圖
(二)模塊功能介紹
該平臺主要進行數據展示、數據獲取以及數據分析三方面,以確保達到目的。為了直觀簡潔,我們以網頁為載體進行效果呈現。在數據獲取方面,主要以爬蟲為主的具體數據獲取。數據分析方面分為兩個重點:數據存儲和Hadoop架構的大數據分析平臺[3],利用這個平臺將我們的數據進行清洗得到有價值的數據,再通過數據可視化進行呈現,最后結合統計學知識提取有效信息。
1.數據管理設計
數據層面主要涉及到數據的爬取、清洗、存儲以及在展示和預測所需的查詢。系統要求具有海量數據,在此前提下,盡量保證數據的更新。因為少量的數據會提升預測的局限性,過時數據將會極大的提升預測的不確定性。除此之外對數據的相應處理是必要的,例如:刪除空白數據、剔除敏感數據、預測涉及不到的臟數據等,處理過后所產生的數據才可以提供給預測作為基本數據。大量的數據存儲和查詢勢必造成數據庫壓力,適當的采用搜索引擎實現低延遲的數據檢索是解覺該問題的有效方案,故采用基于Lucene的Elasticsearch適合該場景[4]。
2.設計流程
調查發現,很多同學碰到的最大問題是在各類平臺上了解的職位信息較為片面,對于社會反響、滿意度、城市的人員飽和度等因素了解較少,或者根本不了解,因而發現找到的工作并不滿意等等一系列問題[5],該系統針對這一現象,給同學們提供最為全面的信息以及未來一段時間的預測,設計流程圖3所示。

圖3 設計流程
3.數據庫設計
本系統涉及到多張表,數據職位數據存儲設計到兩張表。一是存放職位數據的主表,二是存放城市編號和城市名映射的城市表。
職位數據關系模式:職位信息關系(work_id,post_name, comp_name, salary, edu,experi, tags,ter_name,id);單個城市編號和城市名映射關系(id, city_name, city_num)[6]。
4.系統流程圖
通過系統的分析,設計該系統的流程圖如圖4所示
(三)平臺實現
使用Java語言編寫,以MySQL存儲數據,以Web應用的形式進行信息查看,利用大數據爬取數據、分析數據技術進行職業評估[7]。現以數據分析師中Python崗位為例進行分析報告。數據來源與51job,實現過程如下:
1.數據爬取
分析網頁信息,爬取關鍵字段信息。
2.對爬取數據進行清洗,將空缺或雜亂數據進行處理
選取需要的特征,對數據進行差分和必要的計算,例如對城市字符串進行處理。
3.數據分析和可視化,分別進行區域分析;工資情況分析等
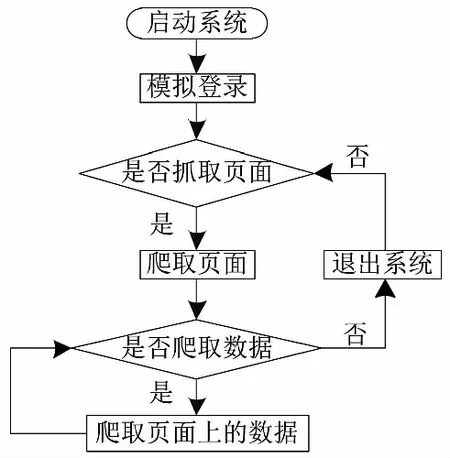
圖4 基于JAVA的網絡爬蟲系統流程圖
由圖5可得結論:在一線城市中,Python崗位的需求最多,對于想要從事該行業的,一線城市選擇就業機會大,不過人才比較集中,也意味著競爭壓力也較大。

圖5 前五個城市崗位需求量(萬人)
由圖6可得結論:從總體薪酬可以看出,Python的收入還是可觀的。薪酬主要集中在5k-18k,但也有明顯的斷層,主要分為5k-10k,11K-13K,15K-16K,17K-18K幾個階段,中間有幾個小分水嶺,起薪相對較高,薪酬的提升幅度也很可觀。
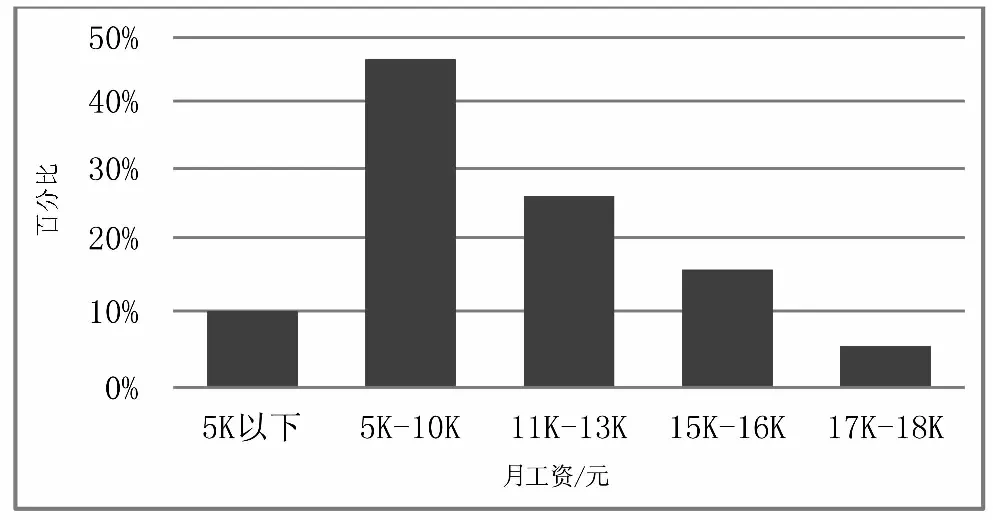
圖6 工資分布
由圖7可得結論:北京的工資最高,其次是上海,杭州,深圳,廣州。
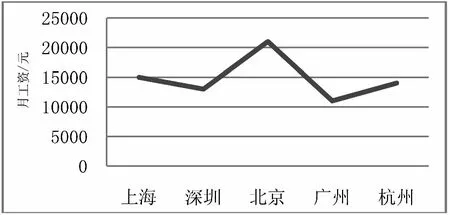
圖7 前五個城市工資比較
由圖8可得結論:2-3年經驗的需求比較大,主要集中在這兩個年限。從這個情況看,雖然該崗位需求大,但是不能盲目轉行,畢竟對經驗要求比較大。從長遠看,5年以上經驗的需求還是比較少的,10年以上近乎無,可以看出5年這個點是比較關鍵的,職業規劃需要在前幾年做好,盡快提升自己。
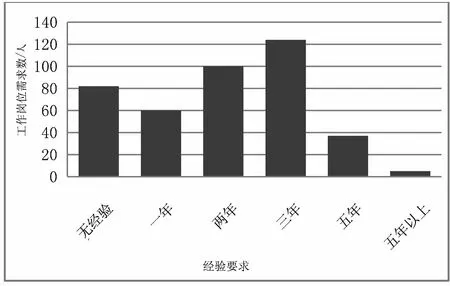
圖8 經驗要求分布
由圖9可得結論:Python對本科生的需求最大,其次是大專,其他學歷需求很少,對于博士需求基本沒有。
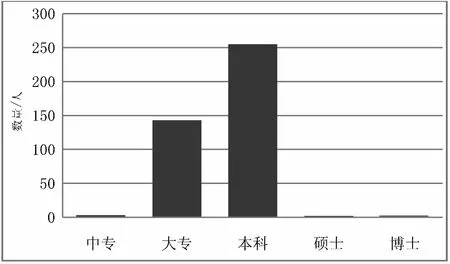
圖9 學歷分布
由圖10可得結論:隨著工作經驗的增加,相應的工資也會隨著增加。
由圖11可得出結論:隨著學歷的上升,相應的工資也會隨著增加。這些均符合我們的常識判斷。
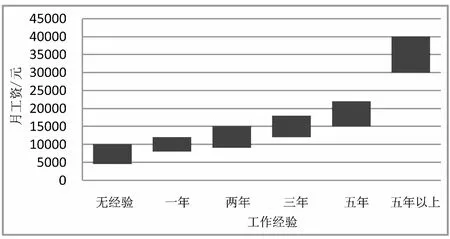
圖10 工作經驗與薪酬相關情況
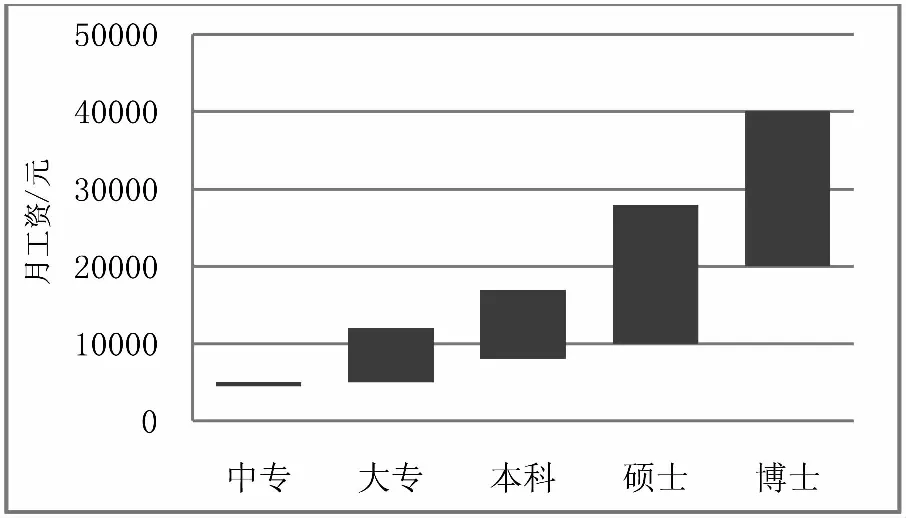
圖11 學歷與薪酬相關情況
4.疫情造成的就業數據分析
新冠疫情突發以來,對就業造成了許多不利影響。從國家統計局公布的城鎮失業率如圖12所示,2019—2020年期間,新冠疫情突發后就業總量比突發前減少約750萬人,我國2019年各月城鎮調查失業率均保持在5.0%至5.3%之間。而2020年1月城鎮調查失業率同比上升0.2%,自2月起陡升至6.2%同比上升了0.9%,且連續數月均維持在6.0%左右的較高水平。預計2022年我國城鎮失業率將進一步上升[8]。
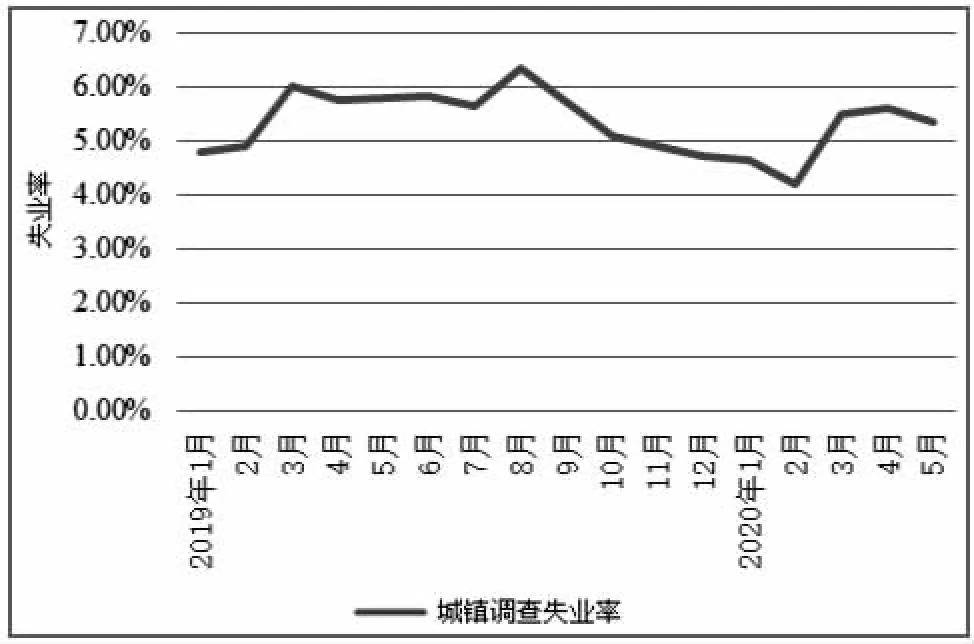
圖12 2019年1月—2020年5月城鎮失業率
2020年2月13日,根據BOSS直聘網發布的《2020年春節后十天人才趨勢觀察》顯示,2020年春節后十天,就業市場新增招聘需求較2019年同期有明顯的減少,3月以后隨著各地疫情得到控制,就業需求有明顯的的增加。疫情突發后企業的招聘方式發生了變化如圖13所示。疫情突發后傳統的招聘方式所占比例有較為明顯的下降,跨區域的招聘比例下降,現場招聘和校園招聘會比例下降。網上招聘方式和企業內部員工推薦所占比例明顯增大[8]。
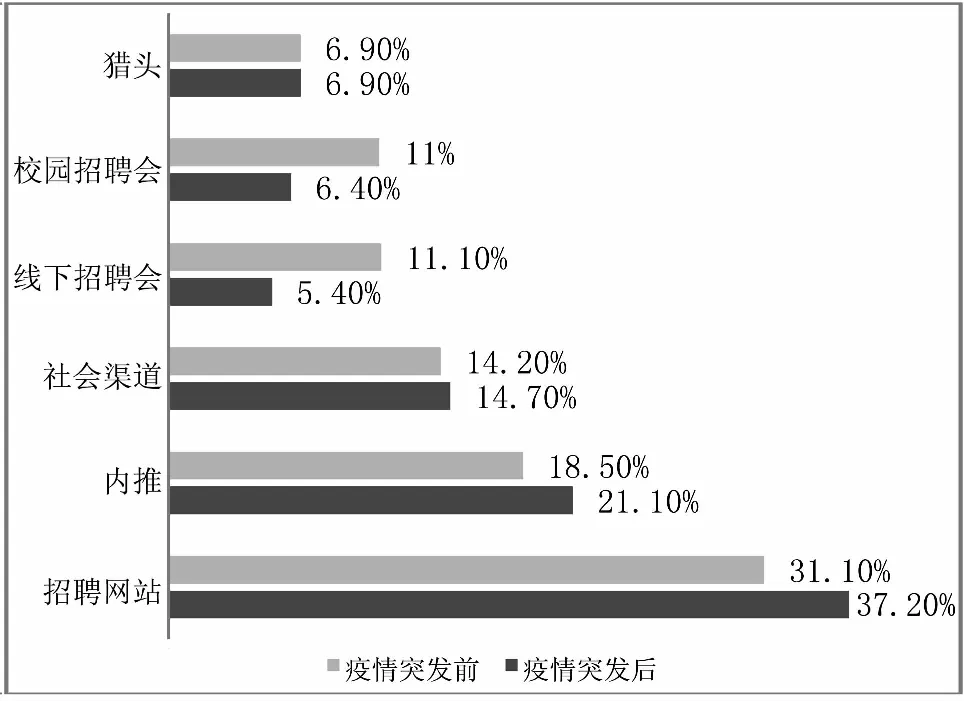
圖13 疫情突發前后企業招聘渠道變化
5.數據分析
通過大學生就業預測平臺對近幾年的大學生就業進行分析可得出以下參考結論:
第一,就業機會主要集中在一線城市,如上海、深圳、北京等城市;但由于近幾年受到新冠疫情的影響,一線城市疫情爆發頻率較高,大學生就業崗位多但不穩定。
第二,崗位的薪資主要集中在5k-18k,中間有幾個小分水嶺,薪資有較大的發展空間,且一線城市中北京的工資最高,其次是上海,杭州,深圳,廣州。
第三,崗位的經驗要求集中在2-3年,該崗位對經驗方面比較看重,且工作經驗和工資呈正相關。值得注意的是從長遠看,5年以上經驗的需求還是比較少的,可以看出5年這個時間點是比較關鍵的,需要做好職業規劃。
(四)根據數據分析指導性建議
新冠疫情突發,致使很多就業崗位不穩定。很多大學畢業生一邊做著不穩定的工作,一邊又要為應對隨時到來的失業做好準備。在這種情況下,大學生就業觀念、就業意向和態度都得發生根本性的轉變才能適應后疫情時期。針對現在大學生就業給出以下幾點建議:
第一,大學生就業不能一味的以薪資作為標準,更不能扎堆到一線城市;第二,鼓勵大學生到基層就業;第三鼓勵大學生創新創業;第四,鼓勵大學生投身到家鄉建設中去,為建設美麗新農村做出貢獻;第五,對于大學生來說,一定要行動起來,做好簡歷,找好目標崗位和公司,通過多種就業渠道,加快求職進度;第六,新冠疫情期間,很多公司都選擇了遠程互聯網辦公的方式,大學生完全可以選擇居家網絡就業的方式來解決工作;第七,建議這段時間加強自身專業能力,分析下自己到底能力在哪,興趣在哪,為就業做好準備。
五、大學生就業預測評平臺建設的難點突破
本平臺開發過程中,主要遇到3個技術難點,具體技術難點及解決方法如下:
(一)數據爬取技術難點
本平臺使用的數據主要來自各大招聘網站,在爬取數據過程中,由于其反扒措施的影響,我們使用了其力度較低的 51job招聘網站和國家統計局網站。在后續使用過程中,在爬蟲技術成熟的前提下,可以采用其他的招聘網站,使數據更加全面。
(二)數據格式技術難點
在研究數據存儲時:頁面數據解析,平臺的不同導致了數據格式不盡相同(異步數據、js數據、頁面數據),在存儲時不得不提前將數據格式進行統一,并采用不同的方法進行解析數據,以便于將數據導入數據庫的時候不會發生錯誤。
(三)WebMagic框架的應用場合
WebMagic 強大的頁面抽取API、模塊化的設計、靈活簡潔嵌入、分布式多線程的支持使其在絕大數的情況下都可以應用,但是并不支持一些特殊資源的爬取,而且在超大數據量的爬取情況下,耗時較為嚴重。在使用過程并結合其上手難度來說,WebMagic是極為優秀的爬蟲框架。
六、結語
大學生就業相關數據只是被相關人員進行簡單的展示和統計,其背后蘊含的寶貴價值并沒有得到最大化的利用,因此這一部分的數據需要我們進一步的開發和利用。筆者主要使用大數據技術對后疫情時期大學生就業情況數據進行了分析研究,主要目的是為了給大學生就業提供參考建議,助力完善高校就業指導工作。
猜你喜歡
音樂天地(音樂創作版)(2022年1期)2022-04-26 13:51:10
民用飛機設計與研究(2020年4期)2021-01-21 09:15:02
人大建設(2020年5期)2020-09-25 08:56:22
快樂作文(1.2年級)(2020年8期)2020-09-10 07:22:44
37°女人(2020年5期)2020-05-11 05:58:52
下一代英才(酷炫少年)(2019年3期)2019-03-25 02:34:18
電子制作(2018年18期)2018-11-14 01:48:24
黃河之聲(2017年14期)2017-10-11 09:03:59
山東工業技術(2016年15期)2016-12-01 05:31:22
中國火炬(2013年7期)2013-07-24 14:19:23
