基于社交網絡的影響力最大化算法
2022-09-03 10:30:36王璿張瑜周軍鋒陳子陽
通信學報 2022年8期
王璿,張瑜,周軍鋒,陳子陽,2
(1.東華大學計算機科學與技術學院,上海 201620;2.上海立信會計金融學院信息管理學院,上海 201620)
0 引言
影響力最大化(IM,influence maximization)[1-2]研究如何從社交網絡中選擇一組最具影響力的種子節點,基于這些節點發起信息傳播,使最終的傳播范圍最大化。該問題廣泛應用在產品營銷[3]、疾病控制[4]和個性化推薦[5]等方面。例如,商家會從社交網絡中選擇最具影響力的部分用戶,基于這些用戶對產品進行推廣和營銷,使更多的用戶了解并最終轉化為潛在顧客。
影響力最大化問題需要基于特定傳播模型來描述信息在網絡中的傳播過程。目前使用最為廣泛的是獨立級聯(IC,independent cascade)模型[6]和線性閾值(LT,linear threshold)模型[7]。不同的傳播模型適用于不同類型的社交網絡。社交網絡可以分為個體網絡和群體網絡[8]。個體網絡主要考慮單個節點和單個節點之間的影響關系,適用于獨立級聯模型。群體網絡主要考慮單個節點和多個節點之間、多個節點和多個節點之間的影響關系,適用于線性閾值模型。基于選定的傳播模型,影響力最大化問題等價于選擇影響力盡可能大的種子集。
為了得到合適的種子集,Kempe 等[1]首先基于IC模型和LT 模型提出了一個貪心算法。該算法可以同時在這2 個模型上提供近似保證(ε為誤差參數),但是時間復雜度過高,難以適用于大規模社交網絡。后續的研究者陸續提出基于某種特定傳播模型的高效算法[10-12]。這些算法雖然在大規模社交網絡上的運行效率得到提升,但是僅局限于特定傳播模型中,只能解決單一類型社交網絡下的影響力最大化問題,當使用在不同類型社交網絡上時效果較差[13]。為解決該問題,本文提出一種可以同時支持IC 模型和LT 模型的高效種子集求解算法,該算法包括3 個階段。1)預處理階段,基于節點度篩選策略,篩選出有效節點集;2)采樣階段,基于邊界約束策略,確定采樣次數并從有效節點集中采樣;3)種子選擇階段,應用貪心策略選擇種子節點,并基于影響力增量剪枝策略,剪枝種子選擇時的部分無效排序。具體來說,本文的貢獻如下。
1)提出邊界約束策略,以快速確定估計最優采樣次數。提出基于節點度篩選策略,以提升種子集質量。提出基于影響力增量剪枝策略,以提高算法運行效率。
2)結合這3 個策略,提出一種三階段的影響力最大化(MTIM,mixed three-stage influence maximization)算法,該算法不但能夠同時支持IC 模型和LT 模型,而且具備優越的近似保證和期望時間復雜度。
3)將MTIM 與IMM、TIM、PMC 等貪心算法,以及OneHop、DegreeDiscount 等啟發式算法在4 個真實社交網絡上對比實驗。結果表明,MTIM 算法能夠適用于大規模社交網絡,提供近似保證,并有效提升影響范圍和效率。
1 背景知識和相關工作
1.1 背景知識
本文使用加權有向圖G=(V,E,W)表示社交網絡,其中,V表示節點集(用戶),E表示有向邊集(用戶間關系),W表示每條有向邊對應權值的集合。W(u,v)∈[0,1]表示有向邊(u,v)的權值,代表傳播過程中節點u把信息傳遞給節點v的概率,即u激活v的概率。為表述方便,使用n和m分別表示節點集V和有向邊集E的大小,In(v)和Out(v)分別表示節點v的入鄰居集合和出鄰居集合。
影響力最大化問題旨在通過種子集(信息傳播的源頭節點)進行信息傳播,實現傳播范圍的最大化。而信息如何在網絡中傳播是由傳播模型確定的。在信息傳播過程中,如果節點v接受某種信息,則稱該節點為激活節點,否則稱其為未激活節點。目前主流的2 種影響力傳播模型的主要區別在于節點的激活方式。
1)IC 模型。假設節點u在i時刻被激活,則節點u在i+1 時刻只有一次機會以傳播概率W(u,v)激活其尚未被激活的出鄰居v∈Out(u)。
2)LT 模型。每個節點有概率閾值φ∈[0,1],該閾值表示節點被激活的難易程度。如果節點v在i時刻未被激活,且滿足,則節點v在i+1 時刻被激活,其中A是節點v在前i時刻被激活的入鄰居集合。
給定社交網絡G、種子集S?V以及傳播模型M,傳播過程如下。1)在第0 時刻,S中的所有節點被激活,其他節點未被激活。2)如果一個節點在i時刻被激活,則該節點在i+1 時刻只有一次機會激活其尚未被激活的出鄰居(激活方式取決于傳播模型M),之后它就不能再激活任何節點。3)重復步驟2),直至不再有節點被激活,傳播結束。種子集S在傳播模型M下激活節點的總數表示為σ(S),代表種子集S的預期影響范圍。表1 給出了本文的常用符號。

表1 常用符號設置
問題定義(影響力最大化問題)給定社交網絡G、參數k以及傳播模型M,影響力最大化問題旨在找出種子集S?V且=k,使種子集預期影響范圍σ(S)最大化。
1.2 相關工作
現有影響力最大化算法大多基于反向影響采樣(RIS,reverse influence sampling)技術[9]選取種子節點。反向影響采樣就是先隨機選一個節點,從該節點出發,沿著該節點所有入邊的相反方向模擬傳播,這樣反向可達的節點集合就稱為反向可達集(RR set,reverse reachable set);再生成足夠多的反向可達集,從中找出影響力最大的種子集(即能夠覆蓋最多反向可達集的節點集合)。這里,如果節點v在集合R中出現,則稱節點v覆蓋集合R;如果集合S中至少有一個節點在集合R中出現,則稱集合S覆蓋集合R。根據文獻[9]可知,對于從節點v反向采樣得到的反向可達集R,節點u∈V{v}覆蓋集合R的概率等于節點u激活節點v的概率。利用RIS 技術,可以使反向可達集更容易包含極具影響力的節點,從而提高算法效率。
例1(反向可達集構建示例)以IC 模型為例,反向可達集構造如下。首先在圖1(a)所示的社交網絡g中隨機選擇節點b,此時反向可達集R={b}。接著沿節點b的所有入邊反向執行廣度優先遍歷,對入邊(c,b)生成隨機數r1=0.3。由于r1≤0.6,節點c被節點b激活,將節點c加入R中,即R={b,c}。同理,為節點c的入邊(a,c)生成隨機數r2=0.9。由于r2>0.8,節點a沒有被節點c激活,不將節點a加入R中,圖1(b)中的虛線表示遍歷失敗,灰線表示遍歷成功,黑線表示社交網絡g中的有向邊。此時不再有節點能被激活,最終反向可達集R={b,c}。
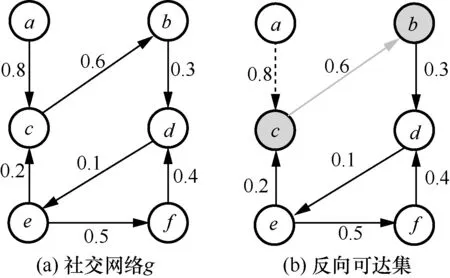
圖1 反向可達集構建示例
Borgs 等[9]在種子集預期影響范圍與反向可達集之間建立了以下聯系。
引理1設S?V為種子集,R為傳播模型M下生成的反向可達集,則
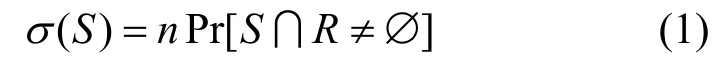
引理1 表明,可以使用反向可達集來估計任意種子集的預期影響范圍。假設生成一個反向可達集集合 R={R1,R2,…},令ΛR(S)表示種子集S覆蓋的反向可達集數量,代表種子集S在集合R 中的覆蓋范圍,則是對種子集預期影響范圍的無偏估計,即E[σ(S)]=。
Borgs 等的解決方案。利用引理1,Borgs 等[9]提出一種影響力最大化算法,該算法分為兩步:1)采樣,即生成足夠多的反向可達集;2)種子選擇,即貪心地選擇對反向可達集覆蓋率最大的種子集。Borgs 等證明,如果檢驗了條邊,則該算法可以提供近似保證。
TIM 和IMM。Tang 等[14-15]基于RIS 技術提出了TIM 算法和IMM 算法,這些算法的時間復雜度均為,明顯優于Borgs 等的算法,但是仍存在大量冗余的計算開銷。TIM 算法利用切爾諾夫邊界(Chernoff bound)來確定采樣次數,而不再通過檢驗遍歷的邊數來判斷是否滿足近似保證,該算法適用于LT 模型。而IMM 算法利用鞅技術改進,進一步減少采樣次數,能夠同時適用IC模型和LT 模型,算法性能穩定高效。
其他基于特定傳播模型的解決方案。Sun 等[10]基于多輪擴散(MRT,multi-round triggering)模型提出的MRIM 算法,解決了多輪擴散下的影響力最大化問題。Guo 等[11]基于觸發(TR,triggering)模型提出的IMCB 算法,從社區結構角度解決了影響分布不平衡的問題。Guo 等[12]基于加權級聯(WC,weighted cascade)模型提出SUBSIM 算法,對反向可達集生成過程進行了優化。
2 MTIM 算法
本文針對現有算法效率低、適用傳播模型單一的問題,提出一種三階段影響力最大化算法——MTIM 算法。MTIM 算法包括3 個階段。
1)預處理階段。基于節點度篩選策略,根據節點的出度和被鏈接程度,篩選出有效節點集C。
2)采樣階段。基于邊界約束策略,先迭代地確定近似最優采樣次數θ*,再從C 中隨機選點采樣θ*次,得到反向可達集集合 R={R1,R2,…,Rθ*}。
3)種子選擇階段。應用貪心策略找出對集合R 覆蓋率最大的種子集;同時,基于影響力增量剪枝策略,剪枝部分種子選擇時的無效排序。
MTIM 算法的具體流程如算法1 所示。

2.1 基于節點度篩選策略的預處理
RIS 方法每次從整個社交網絡中隨機選點采樣,由于所選節點質量參差不齊,導致求解出的種子集對反向可達集的覆蓋率偏低,使種子集影響范圍有限。針對該問題,本文提出基于節點度篩選策略。該策略的基本思想為根據節點的出度和被鏈接程度(lv,linked value)[16],篩選出潛在影響力較大的節點集合(即有效節點集)。利用該策略,不僅可以縮小采樣時的選點范圍,而且可以提高種子集對反向可達集的覆蓋率,從而有效改善種子質量。
預處理階段的主要工作如下。1)根據節點的出度和被鏈接程度,從社交網絡G中篩選出節點集合A 和集合B,且;2)取這2 個集合的并集作為有效節點集C。算法2 為預處理階段的偽代碼。


對于有向圖中的節點,其度包含出度和入度這2 個含義,因而從這2 個方面考慮。1)出度大的節點,影響其出鄰居的潛在可能性較大,則其影響力往往較大。因而,可以根據節點的出度降序排序,獲得出度前r% 大的節點集合A(算法2 的步驟2)~步驟5))。2)由于傳播在多個節點間進行,考慮單個節點的入度并無意義,可求單個節點被其入鄰居鏈接的程度。被鏈接程度大的節點,其被入鄰居影響的潛在可能性大,則影響力大的節點往往存在于被鏈接程度大的節點的反向可達集中。因而,可以先根據式(2)迭代地計算節點的被鏈接程度(d為平衡因子),再根據節點的被鏈接程度降序排序,獲得被鏈接程度前r% 大的節點集合B(算法2 的步驟6)~步驟9))。
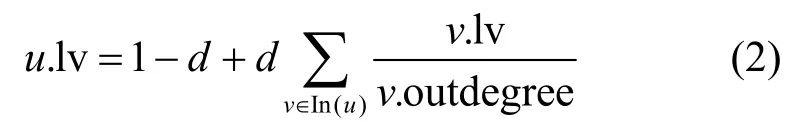
此時,潛在影響力大的節點多在集合A 和集合B 中,因而,可以取兩集合的并集作為有效節點集C 輸出(算法2 的步驟10)~步驟11))。
例2(預處理示例)對圖1(a)社交網絡g預處理流程如下。假設篩選比例為70%。首先,計算每個節點的出度,并根據出度降序排序,取出度前70%大的節點集 A={a,c,d,e};然后,計算每個節點的被鏈接程度,并根據被鏈接程度降序排序,取被鏈接程度前70%大的節點集 B={b,c,d,e};最后,取A 和B 的并集 C={a,b,c,d,e}作為有效節點集。
2.2 基于邊界約束策略的采樣
針對RIS 方法難以確定采樣次數的問題,提出邊界約束策略。該策略的基本思想如下,首先估計出近似最優采樣次數的取值區間;然后根據該區間依次計算不同采樣次數下影響范圍近似解下界和最優解上界之比,不斷計算直至該比值達到給定要求時停止。利用該策略,可以快速確定近似最優采樣次數。
采樣階段的主要工作如下,首先估計出近似最優采樣次數θ*;然后從預處理階段獲得的有效節點集C中隨機選點采樣θ*次,從而得到反向可達集集合R={R1,R2,…,Rθ*}。
2.2.1 最優采樣次數的估計
為估計采樣次數θ,需進一步分析。假設是期望影響力最大的k大種子集,即OPT=,根據引理1,如果θ大小適當,則≈OPT。給定ε∈[0,1],根據文獻[15]可推導出近似最優采樣次數θ*,如式(3)所示。
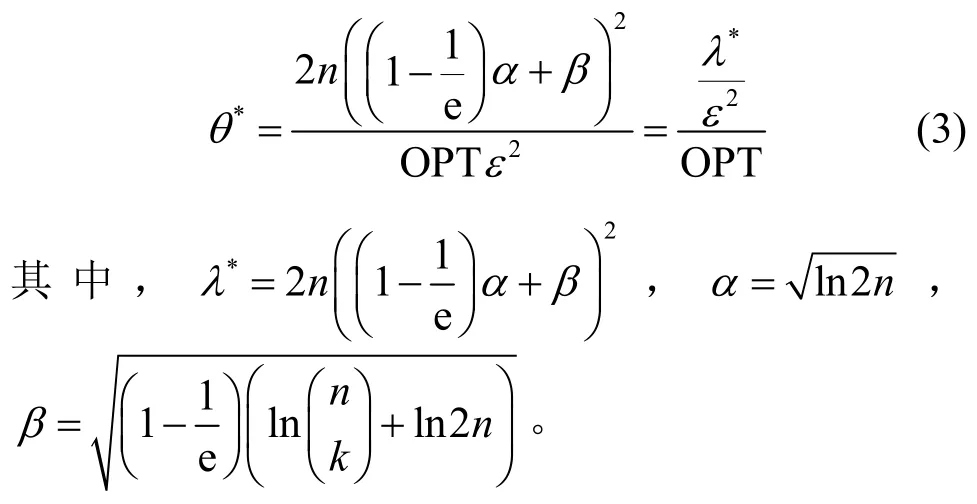
根據式(3),如果OPT 已知,則可以計算出近似最優采樣次數。但是OPT 實際未知,因而考慮根據OPT 的取值范圍估計出θ*的取值區間。
已知OPT∈[1,n],由于中包含k個節點,至少能夠影響到這k個節點,則可知OPT∈[k,n]。為估計出θ*的取值區間,給出引理2[15]與定理1。
引理2給定ε∈(0,1),?≥1,令θO表示理論最優采樣次數,θ*表示根據式(3)計算出的近似最優采樣次數,則滿足

定理1給定x∈[k,n],令θmax=2λ*ε?2k?1,θmin=λ*n?1,根據引理2,可知
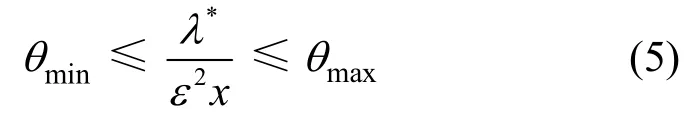
證明構造函數θ(x)=λ*ε?2x?1,可知該函數隨著x的增大而單調遞減。已知x∈[k,n],則函數值域為[θ(n),θ(k)]。根據引理2,θmin≤θ(n)≤θ(x);同時根據式(3)計算的近似最優值恰在θ(x)的值域內,則必然滿足
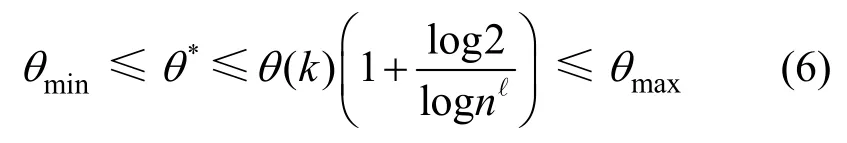
證畢。
根據定理1,可以估計出近似最優采樣次數的取值區間為[θmin,θmax]。
2.2.2 影響范圍邊界的估計
為了從取值區間[θmin,θmax]中找出近似最優采樣次數θ*,可以根據該區間依次計算出不同采樣次數θ下影響范圍的近似比,即當前解下界和最優解上界之比,如果該比值大于或等于,則立刻停止并返回當前采樣次數θ,否則將當前采樣次數θ乘以2 并重復上述步驟。為估計影響范圍的邊界,給出引理3[17]。
引理3給定種子集S和由θ個反向可達集構成的集合 R={R1,R2,…,Rθ},則對于?λ>0,滿足
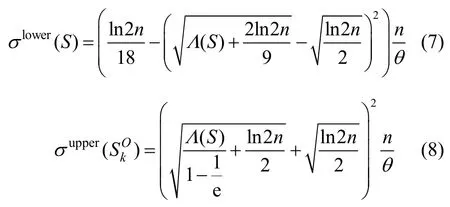
根據引理3,當前種子集S影響范圍的近似比可以用表示。
2.2.3 算法描述
根據2.2.1 節估計出的近似最優采樣次數θ*的取值區間[θmin,θmax],以及2.2.2 節判斷是否為近似最優采樣次數的邊界約束條件,將其組合,即可構成基于邊界約束策略的采樣階段。
算法3 為采樣階段的偽代碼。具體地,首先,根據式(5)初始化θmin和θmax(算法3 的步驟1));接著,至多執行imax次for 循環(算法3 的步驟3)~步驟13)),在第i次時,先從有效節點集C 中隨機選擇節點采樣,生成θi個反向可達集,再根據式(7)和式(8)計算出當前采樣次數下種子集Si影響范圍下界與上界之比,如果該比值大于或等于或者當前執行第imax次循環,則停止并返回當前種子集,否則將θmin乘以2 并重復計算。組合后算法的近似比為,原因在于:1)如果循環次數少于imax時就停止,則必能夠提供近似保證;2)如果循環次數為imax時才停止,此時的采樣次數必大于或等于θ*,則必能采樣足夠多的反向可達集,即必能提供近似保證。

算法4 為生成反向可達集集合的偽代碼。具體流程如下。首先,將集合H 初始化為空集(算法4的步驟1));接著,執行θ次for 循環(算法4 的步驟2)~步驟6)),每次隨機選擇節點v∈C,沿該節點所有入邊的相反方向進行廣度優先遍歷(即基于傳播模型發起信息傳播),將激活的節點依次插入反向可達集Ri,并將Ri插入H;最后,輸出H(算法4 的步驟7))。


例3(采樣示例)IC 模型下采樣階段流程如下。假設采樣次數θ=3,參數k=1。預處理階段從圖1(a)中篩選出有效節點集 C={a,b,c,d,e}(詳見例2)。如圖2 所示,從C 中隨機選點b、c、e,生成反向可達集集合 R={R1,R2,R3},其中R1={b,c},R2={a,c},R3={b,c,d,e}。圖2 中的虛線表示遍歷失敗,灰線表示遍歷成功,黑線表示社交網絡g中的有向邊。因為節點c對R 覆蓋率最大,即節點c的影響力最大,所以將其加入種子集。最后,返回種子集{c}。
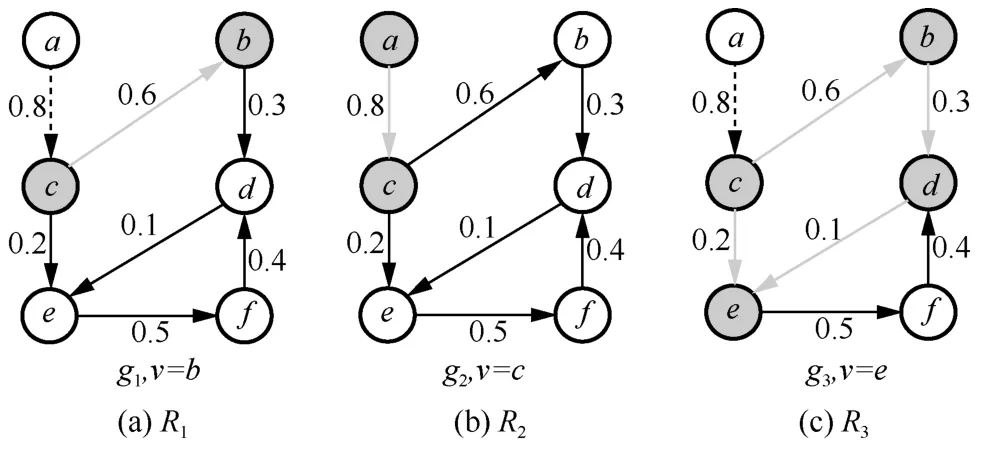
圖2 采樣示例
2.3 基于影響力增量剪枝策略的種子選擇
由于RIS 方法每次找出對反向可達集集合R覆蓋率最高的種子節點后,需要更新其他節點對R的覆蓋率,并根據各節點對R 的覆蓋率重新排序,導致存在節點對R 的覆蓋率更新后相對排名不變時的無效排序,影響算法運行效率。針對該問題,本文提出基于影響力增量的剪枝策略。該策略的基本思想為保存前一輪排序后的數據,在刪除該節點及其覆蓋的反向可達集后,比較前一輪中原次大節點更新后和第三大節點更新前對R 的覆蓋率,若前者大于等于后者,則直接選擇原次大節點作為新一輪中的種子,而無須重新排序。利用該策略,可以剪枝部分種子選擇時的無效排序,從而降低算法時耗。
種子選擇階段的主要工作如下。應用貪心策略找出對R 覆蓋率最高的種子集S;同時,剪枝節點對R 的覆蓋率更新后相對排名不變時的無效排序。
算法5 為種子選擇階段的偽代碼。具體地,首先,初始化種子集為空集(算法5 的步驟1)),計算出每個節點v∈V對集合R 的覆蓋率FR({v}),保存至pairs

例4(種子選擇示例)令表示第i輪中節點v對集合R 的覆蓋率。如圖3 所示,第1 輪已計算出每個節點對R 的覆蓋率,降序排序后選擇當前對R 覆蓋率最大的節點b作為種子,并更新其他節點影響力。進入第2 輪,先比較前一輪中原次大節點c更新后和原第三大節點a更新前對R 的覆蓋率,發現,則節點c必為新一輪的最優種子,直接選擇節點c而無須重新排序。
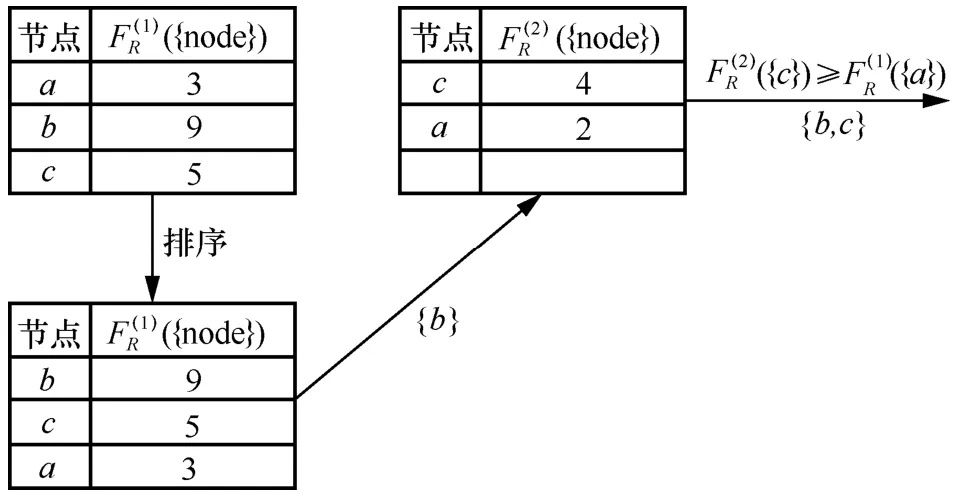
圖3 種子選擇示例
2.4 MTIM 算法時間復雜度分析
預處理階段(算法2)主要用于篩選有效節點,其時間復雜度為O(n(ncnt+logn)),其中cnt 為迭代次數。采樣階段(算法3)主要用于生成反向可達集,其時間復雜度為。種子選擇階段(算法5),所花時間主要與反向可達集集合R和采樣次數θ相關,其時間復雜度為。組合3 個階段后得到的MTIM 算法(算法1),其時間復雜度為。
3 實驗與分析
3.1 實驗設置
實驗的硬件配置Intel(R)Xeon(R)Silver 4208 CPU @ 2.10 GHz,運行內存64 GB,操作系統Ubuntu 20.04(64 位),所有算法均采用C++實現并使用G++4.8.5 編譯。
實驗采用4 個真實的社交網絡數據集。其中,Slashdot 是提供技術資訊服務的社交網絡;soc-LiveMocha 是提供外語學習服務的社交網絡;Web-BerkStan 是BerkStan 的社交網絡;soc-pokec是斯洛伐克的社交網絡。
表2 給出了數據集的統計信息。其中,|V|表示圖中的節點個數,|E|表示圖中的邊個數,Avg.deg表示圖的平均度。
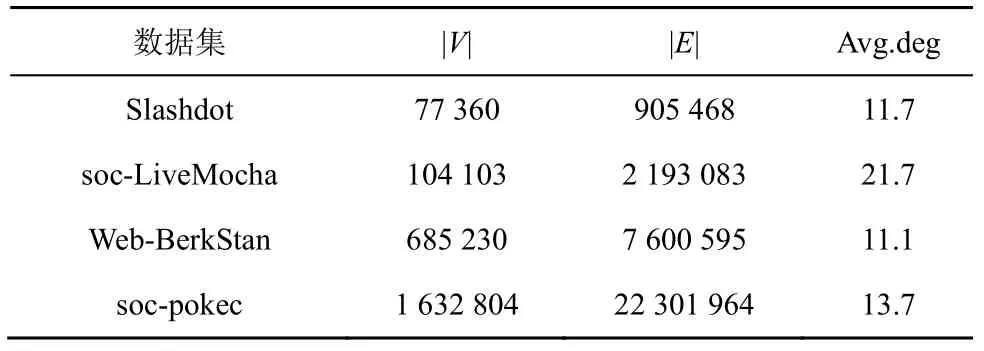
表2 數據集的統計信息
3.2 算法性能比較分析
算法評價標準包括:①運行時間,即求解出種子集的時間;②預期影響范圍,即求解出的種子集能夠影響到的節點個數。
實驗使用IC 模型和LT 模型,基于4 個社交網絡數據集分別在k∈{1,10,20,50,100}5 種規模下實驗。根據之前的工作[10-15,17],設置誤差參數ε=0.5。根據表3,不同數據集單位時間篩選節點總數在r=70時最大,因而預處理階段的篩選比例r%設置為70%。為避免誤差,本文所涉及的算法都運行30 次,各算法評價指標取其均值。

表3 不同篩選比例r%下的篩選節點個數和篩選時間比較
為驗證算法高效性,設置對比算法,具體如下。
1)TIM 算法[14],為貪心算法。TIM 算法基于反向影響采樣技術,利用切爾諾夫邊界確定采樣次數,支持LT 模型,可應用于大規模社交網絡。本文將該算法用于LT 模型下對比實驗。
2)IMM 算法[15],為貪心算法。IMM 算法是TIM算法的改進算法,利用鞅技術確定采樣次數,同時支持IC 模型和LT 模型。本文以IMM 算法為基準,并同時用于IC 模型和LT 模型下對比實驗。
3)OneHop 算法[18],為啟發式算法。OneHop算法基于跳步思想選取種子,支持IC 模型,是目前精確度最高的啟發式算法。本文將該算法用于IC模型下對比實驗。
4)PMC 算法[19],為貪心算法。PMC 算法基于蒙特卡羅模擬技術,支持IC 模型。該算法將原圖隨機切割為τ個子圖,在子圖中進行T 次傳播模擬來估計節點影響力,選擇前k大的節點作為種子。本文設置τ=200,T=10 000,并將該算法用于IC模型下對比實驗。
5)DegreeDiscount 算法[20],為經典啟發式算法。DegreeDiscount 算法基于折扣度思想選取種子,支持LT 模型。本文將該算法用于LT 模型下對比實驗。
6)MTIM 算法,為本文算法。
3.2.1 IC 模型下的結果
第一組實驗。基于IC 模型比較了MTIM、IMM、OneHop、PMC 這4 種算法在不同數據集上的預期影響范圍,結果如圖4 所示。根據圖4 可以發現,1)隨著種子集規模k的增大,4 種算法的預期影響范圍總體均呈上升趨勢,并且種子集預期影響范圍的增幅隨種子個數的增加而遞減。2)MTIM 的預期影響范圍最廣,IMM 和PMC 次之,而OneHop 表現最差。具體而言,MTIM 算法的預期影響范圍較IMM 算法提高了約20%,IMM 算法的預期影響范圍較PMC 算法提高了10%~20%,而OneHop 算法的預期影響范圍為IMM 算法的50%左右。
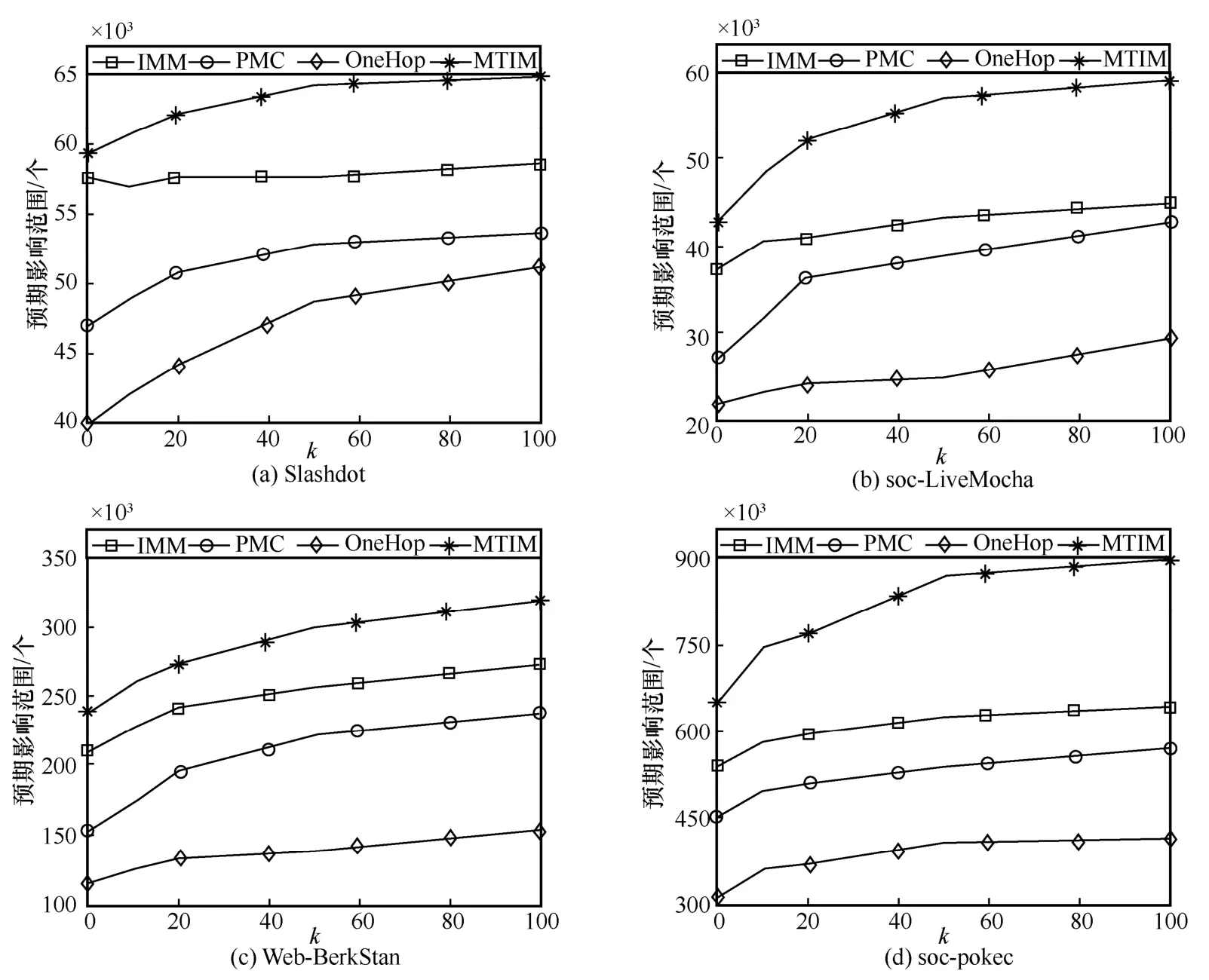
圖4 IC 模型下的預期影響范圍比較
其原因主要是節點度篩選策略的應用。該策略通過約束采樣范圍,提高種子集S對反向可達集集合R 的覆蓋率FR(S),從而擴大影響范圍。根據式(1),,即種子集預期影響范圍E[σ(S)]與覆蓋率FR(S)正相關。圖5 統計了k=100時IMM算法和MTIM 算法在各數據集上的覆蓋率,可以發現MTIM 算法較IMM 算法覆蓋率提高約20%。因而,MTIM 算法較IMM 算法預期影響范圍提高約20%。而PMC 算法由于需要對網絡中的所有節點進行多次傳播模擬,取預期影響范圍平均值來估計節點影響力,導致實際結果不夠精確。OneHop 啟發式算法基于跳步思想選擇種子,并未考慮復雜網絡結構,導致所選節點質量不高。因而,IMM 算法、PMC 算法和OneHop 算法的預期影響范圍均不如MTIM 算法。
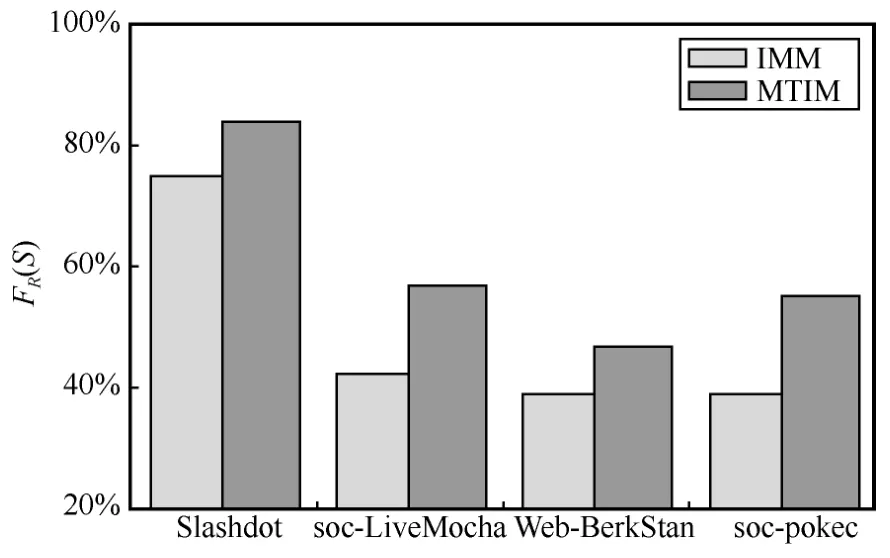
圖5 覆蓋率統計信息
第二組實驗。基于IC 模型比較了MTIM、IMM、OneHop、PMC 這4 種算法在不同數據集上的運行時間,結果如圖6 所示。根據圖6 可以發現,1)隨著種子集規模k的增大,MTIM 算法、IMM 算法和PMC 算法的運行時間及其差距倍增,而OneHop 算法運行時間趨于平穩。2)OneHop 的運行時間最短,MTIM 次之,PMC 和IMM 的運行時間較長。具體而言,當k<20 時,MTIM 算法與OneHop 算法的性能差異不大;當k>20 時,MTIM 算法略慢于OneHop 算法。MTIM 算法較IMM 算法快了4~9 倍,且數據集規模越大,提升效果越明顯。PMC 算法較IMM 算法減少運行時間約50%。
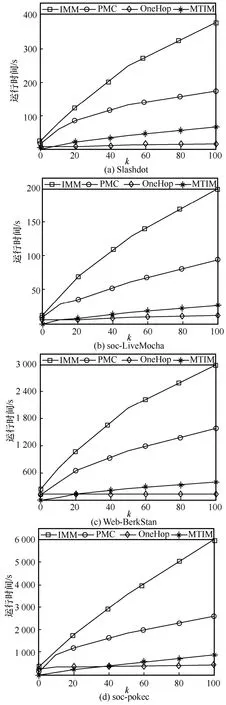
圖6 IC 模型下的運行時間比較
其原因主要有兩點。1)邊界約束策略的應用。該策略利用更高精度的邊界約束來估計最優采樣次數,降低確定采樣次數時間,從而提升算法的運行效率。圖7(a)統計了k=100時IMM 算法和MTIM 算法在各數據集上的確定采樣次數時間,由于各數據集的運行時間相差較大,因此將時間設置為T=lgy,其中y表示實際運行時間,可以發現:MTIM 算法較IMM 算法減少確定采樣次數時間40%~50%。圖7(b)統計了k=100時IMM算法和MTIM算法生成的反向可達集個數(即采樣次數),可以發現,MTIM 算法所確定的采樣次數約為IMM 算法的70%。2)影響力增量剪枝策略的應用。該策略避免了部分種子選擇時的無效排序。圖7(c)統計了k=100時IMM 算法和MTIM 算法在各數據集上種子選擇時的有效排序次數,可以發現:MTIM 算法較之IMM 算法剪枝了約15%的無效排序。因而,MTIM 算法較之IMM 算法快了4~9 倍。而PMC 算法將原社交網絡隨機分割為多個較小規模的子圖網絡,從子圖中選擇種子。因而,PMC 算法快于IMM 算法。OneHop 算法基于啟發式規則粗略估計節點影響力,直接選擇前k大的節點作為種子。因而,OneHop 算法的運行速度總體優于MTIM 算法、IMM 算法和PMC 算法。
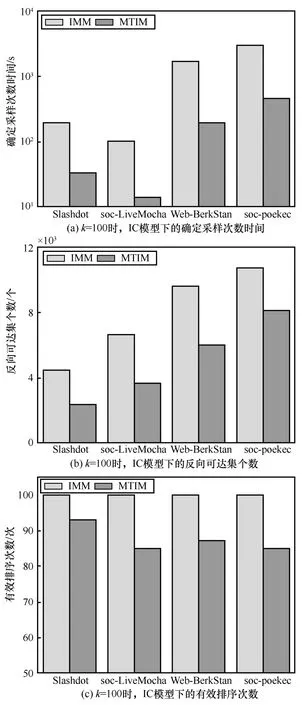
圖7 統計信息
3.2.2 LT 模型下的結果
第一組實驗。基于LT 模型比較了MTIM、IMM、TIM、DegreeDiscount 這4 種算法在不同數據集上的預期影響范圍,結果如圖8 所示。根據圖8 可以發現,1)隨著種子集規模k的增大,4 種算法的預期影響范圍總體呈上升趨勢,且預期影響范圍的增幅隨種子個數的增加而遞減。2)MTIM 的預期影響范圍最廣,IMM 和TIM 次之,而DegreeDiscount 表現最差。具體而言,MTIM 算法較IMM 算法擴大預期影響范圍約30%,且數據集規模越大,提升效果越明顯;IMM 算法和TIM 算法折線幾乎重合,性能差異不大;而DegreeDiscount 算法的預期影響范圍約為IMM 算法的50%。
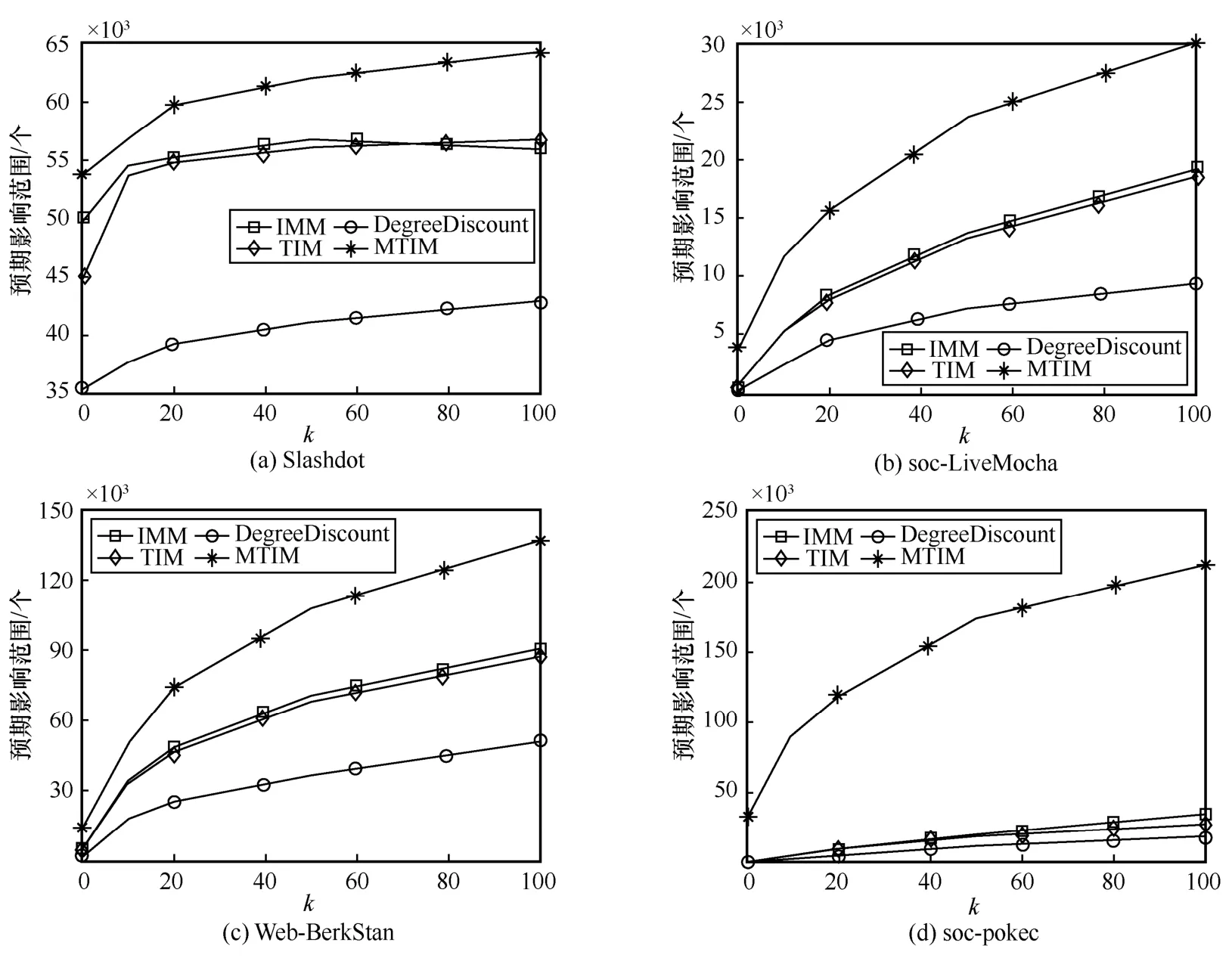
圖8 LT 模型下的預期影響范圍比較
其原因與IC 模型類似,主要是節點度篩選策略的應用。利用該策略,可以提高種子集對反向可達集的覆蓋率,從而擴大種子集預期影響范圍。因而,MTIM 算法較IMM 算法擴大預期影響范圍約30%。IMM 算法是TIM 算法的改進算法,在確保獲得相同近似保證的同時,主要研究如何提升算法的運行速度。因而,IMM 算法和TIM 算法的預期影響范圍極為接近。DegreeDiscount 算法是經典啟發式算法,基于折扣度思想來選擇種子節點,并未考慮網絡結構的復雜性。因而,該算法的預期影響范圍遠不如MTIM算法、IMM 算法和TIM 算法。
第二組實驗。基于LT 模型比較了MTIM、IMM、TIM、DegreeDiscount 這4 種算法在不同數據集下的運行時間,結果如圖9 所示。根據圖9 可以發現,1)隨著種子集規模k的增大,DegreeDiscount、MTIM 和IMM 的運行時間遞增,并且增幅逐漸減小;而TIM 在k<10 時運行時間遞減,在k≥10 時運行時間遞增,并且增幅逐漸減小。2)MTIM 運行時間最短,DegreeDiscount 和IMM 次之,TIM 運行時間最長。具體而言,MTIM 算法略快于DegreeDiscount 算法,MTIM 算法較IMM 算法快了1.5~2.3 倍,而TIM 算法的運行時間為IMM 算法的2 倍多。
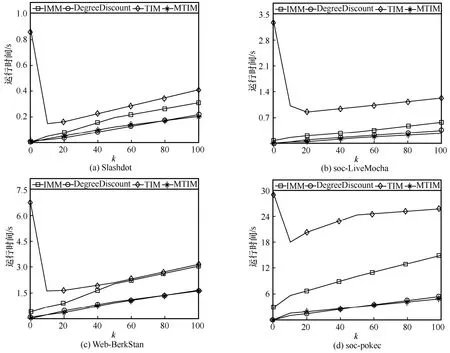
圖9 LT 模型下的運行時間比較
其原因與IC 模型類似,是因為邊界約束策略和影響力增量剪枝策略的應用。利用這2 個策略,不僅可以快速確定近似最優采樣次數,提升算法效率,而且可以避免部分種子選擇時的無效排序,降低算法時耗。因而,MTIM 算法優于TIM 算法和IMM 算法,略快于DegreeDiscount 啟發式算法。但是,相比于IC模型,LT 模型下的優化效果并不顯著,主要是因為節點信息的傳播方式不同,IC 模型下反映的是單個用戶與單個用戶之間的影響關系,而LT 模型下反映的是多個用戶與單個用戶之間的影響關系。
綜合2 個傳播模型下的實驗結果可知,1)相比于IMM、TIM 和PMC 等貪心算法,以及OneHop和DegreeDiscount 等啟發式算法,MTIM 算法均獲得最大預期影響范圍,提供近似保證,且種子集規模越大,優勢越明顯。2)與IMM、TIM和PMC 等貪心算法相比,MTIM 算法運行時間最短。而與啟發式算法相比,在IC 模型上,MTIM 算法略慢于OneHop 算法;在LT 模型上,MTIM 算法運行速度與DegreeDiscount 算法極為接近,總體略快于DegreeDiscount 算法。3)MTIM 算法不僅預期影響范圍更優、精確度更高,而且運行速度優于大多貪心算法,略快于部分啟發式算法。因而,MTIM 算法能夠更好地適用于大規模社交網絡。
4 結束語
針對現有影響力最大化算法效率低、適用模型單一的問題,本文基于2 個基礎影響力傳播模型,結合反向影響采樣技術,提出了MTIM 算法,該算法包括3 個階段。1)預處理階段:基于節點度篩選策略,篩選出有效節點集。2)采樣階段:基于邊界約束策略,確定近似最優采樣次數并從有效節點集中選點采樣。3)種子選擇階段:應用貪心策略選擇種子節點,并基于影響力增量剪枝策略,剪枝種子選擇時的無效排序。基于4 個真實社交網絡的實驗結果表明,MTIM 算法不僅可以提供近似保證,而且其預期影響范圍遠高于DegreeDiscount和OneHop 等啟發式算法,優于IMM、TIM、PMC等貪心算法;在運行時間方面,MTIM 算法顯著快于IMM、TIM、PMC 等貪心算法,總體上略慢于OneHop,略快于DegreeDiscount。因而,MTIM 算法在擁有較快運行速度的同時,保證了較大預期影響范圍、較高近似保證,能夠更好地適用于大規模社交網絡。
后續工作中將會進行如下深入研究。1)影響力傳播模型的擴展。進一步考慮特定的、復雜多變的應用場景下,如何解決影響力最大化問題。2)動態圖下的研究。實際情況下,社交網絡的結構以及用戶間的關系往往會隨著消息的傳播而發生一定變化,未來可以嘗試在動態圖上進行研究。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
教學考試(高考化學)(2021年2期)2021-05-30 06:15:52
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
中學生數理化·高一版(2020年3期)2020-04-21 08:03:20
中學生數理化(高中版.高考理化)(2020年2期)2020-04-21 05:32:50
小學生作文(低年級適用)(2019年9期)2019-10-08 08:37:10
數學大世界(2018年1期)2018-04-12 05:39:14
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
