基于改進XGBoost模型的信用風險評估研究
2022-09-02 10:53:02金庫瑩
微處理機 2022年4期
金庫瑩,郭 瑩
(沈陽工業大學信息科學與工程學院,沈陽 110870)
1 引言
根據中國銀行業監督管理委員會數據統計,2021年中國商業銀行的不良貸款率為1.73%,精準識別良好用戶與違約用戶、評估銀行用戶的信用風險成為亟待解決的問題。信用風險評估是典型的二分類問題,目前已有很多分類算法應用到對銀行用戶的信用評估中,如邏輯回歸[1]、樸素貝葉斯[2]、決策樹[3]、隨機森林[4]、XGBoost[5]等,但通常局限于將模型算法直接套用于對用戶的信用風險研究,忽視了在信用風險領域中類別不平衡問題對于模型的影響。為解決數據不平衡的影響,學者們提出了相關采樣算法,如過采樣算法SMOTE[6]、欠采樣算法EasyEnsemble[7]等。本研究基于現有成果,采用SMOTE與TOMEK算法相結合的采樣方式處理不平衡數據集,提出一種改進的ST-XGB算法,旨在提高銀行用戶風險評估中的泛化能力,以更好地解決現實中的貸款人信用評估問題。
2 改進的XGBoost集成算法
2.1 SMOTE+TOMEK采樣算法
由于SMOTE算法采樣過程中易出現樣本重疊問題,同時也存在合成數據具有邊緣性與質量差的劣勢,在對數據進行分類時,對于邊界的臨界點容易產生誤判;TOMEK欠采樣法解決的正是數據邊界模糊不清的問題。以SMOTE+TOMEK的方式處理不平衡數據的步驟為:先使用SMOTE過采樣,擴大樣本后再對處在邊界模糊的點用TOMEK進行刪除,最終得到一個邊界線較為清晰的數據集,最初的不平衡數據經過采樣后正負樣本也達到了平衡。處理前后的效果對比如圖1所示。
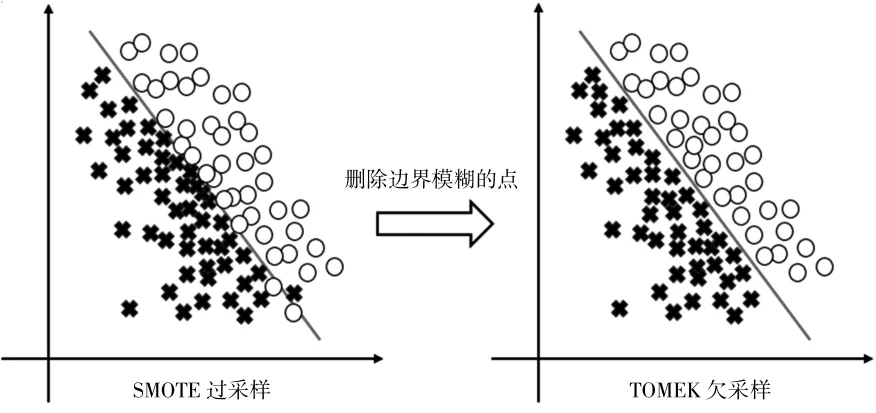
圖1 SMOTE+TOMEK采樣結果示意圖
2.2 XGBoost集成算法
XGBoost模型是Boosting思想的另一種實現,其算法思想就是不斷地添加新的樹,每次添加的樹本質是學習一個新函數,將上一棵樹的損失函數梯度下降方向作為新函數優化目標,去擬合上一棵樹預測的殘差。
假定所使用的數據集為(xi,yi),其中xi∈Rm、yi∈Rm,即m維數據集;xi表示數據集中特征屬性,yi表示樣本數據的標簽,則XGBoost的模型定義為:
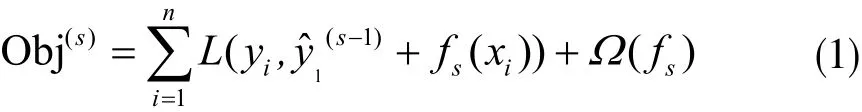
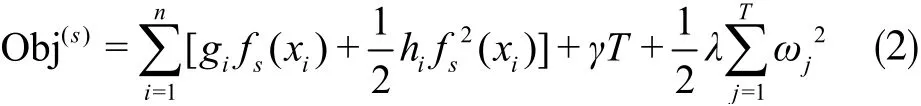
式中gi為損失函數的一階梯度統計;hi為二階梯度統計,ωj為葉子節點的權重。可以看出XGBoost的目標函數與傳統梯度提升樹的方法不同,XGBoost在一定程度上做了近似并通過一階梯度統計和二階梯度統計表示。
fs(xi)本質上是樹模型,每個樣本在每棵樹中會落到對應的一個葉子節點,則式(2)可以改寫成:
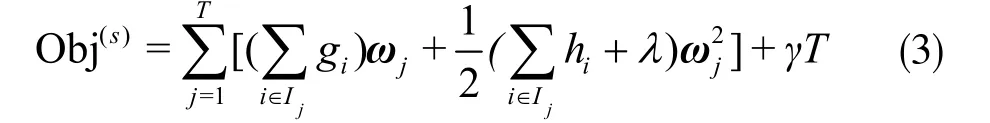
式中,Ij為葉子節點j的樣本集,fs(xi)將樣本劃分到葉子節點,計算該葉子節點的權重ω,因此i∈Ij時,可以用ωj代替fs(xi)。Obj為目標函數,s為它進行迭代的輪數。
將式(3)看成以自變量ωj、因變量為Obj(s)的一元二次函數。根據最值公式,葉子節點j的最優權重ωj*為:
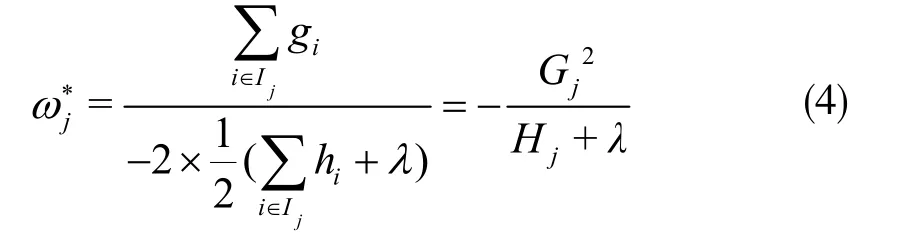
將式(4)代入式(2)中可以得出最優的目標函數值為:
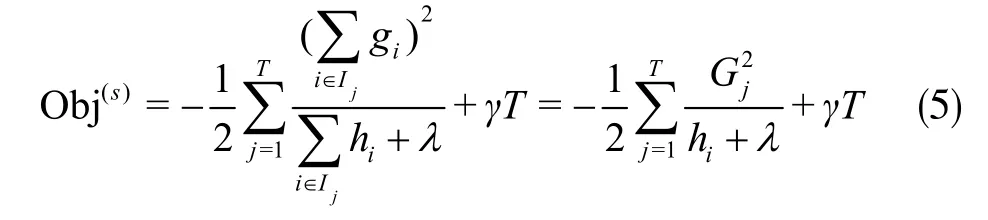
式(5)可以用作評分函數,分值越小表示該樹模型性能越佳。在每次的迭代學習過程中,需對每棵樹模型進行評分,并從中選出最佳,但候選樹的數量是有限的。XGBoost采取貪心策略算法,從根節點開始計算目標函數值,如果節點分裂后的目標函數值相比于分裂前的目標函數值有所減少,則不進行分裂劃分,之后將新生成后的預測函數加入模型中。
3 實驗設計與數據處理
3.1 數據集
實驗的任務是預測用戶貸款是否存在潛在違約風險。選擇信貸業務豐富的Lending Club數據集,采集的總數據量約為40萬,良好用戶與違約用戶比例為4:1。實驗選用的數據集包含27列變量信息,數值型變量13列,類別型特征14列,數值型變量中包括連續型變量11列,離散型變量2列。
3.2 數據預處理
數據處理包含缺失值處理、異常值處理、數據轉換和數據不平衡處理。實驗采用模型填充的方式處理數據中的缺失值,將數據中異常值刪除,作為缺失值進行填充。對于類別型變量無法直接放入算法模型,根據類別型特征分類為有序型和無序型,其中無序型分為高維度與低維度兩種。將有序型類別特征采用目標編碼的方式進行處理;對于低維度無序型類別特征采用獨熱編碼;高維度無序型類別特征采用頻數編碼。
3.3 特征工程
特征工程包括特征構造和特征篩選兩部分。根據金融風控領域專家的知識構造可解釋的銀行信貸業務特征,以此增加模型的預測能力。在此基礎上通過特征交叉和特征分箱的方式進一步衍生特征。通過特征構造衍生出的新特征不一定對模型的預測產生積極的影響,甚至會降低模型的泛化能力,因此實驗采用IV值(Information Value)對數據的特征字段進行篩選。通過IV值計算評估每個指標的有效預測能力,篩選出IV值大于0.1的特征,共計25個。
4 實驗與結論
從AUC分值、精準率和誤判為違約用戶三個方面對模型性能進行評價。采用傳統的分類模型與改進的XGBoost模型進行實驗對比分析,對比結果如表1所示。
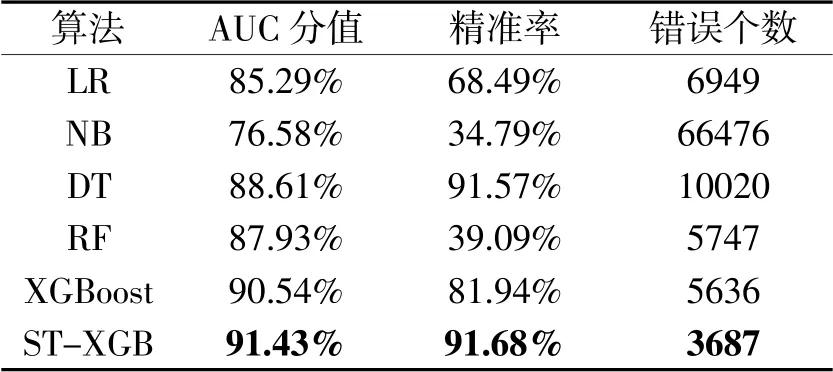
表1 模型性能對比
從表中可以看出,改進的XGBoost模型在AUC分數、精準率和判別錯誤個數三個方面均優于其它模型:AUC分值相比XGBoost模型提升了0.83%,精準率相比于決策樹模型提升了0.11%,在判別錯誤個數方面相比于其它模型大幅度減少為3687個。
對于銀行信貸部門來說,即使是提高1%的預測準確率,也可以極大地降低風險和損失[8]。在數據挖掘算法中,模型泛化能力的評判指標AUC分值若達到80%便證明了模型的預測能力。改進的STXGB模型的AUC分值達到了91.43%,模型的泛化能力較為理想,證明了改進算法的有效性。
5 結束語
針對銀行信貸數據中用戶類別不平衡的情況,通過SMOTE與TOMEK相結合的采樣方式改進了XGBoost模型。ST-XGB模型有效地提高了對用戶類別的識別精度,避免了不平衡數據對于判別結果過于樂觀的弊端,為銀行信貸業務人員的工作提供了更為有力的支持,更加避免了人工在辦理業務時的主觀性,對銀行用戶信用風險評估的進一步研究具有一定的意義。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
商用汽車(2016年11期)2016-12-19 01:20:16
光學精密工程(2016年6期)2016-11-07 09:07:19
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
