基于Python 爬蟲的旅游網站數據分析與可視化
2022-09-02 06:25:18趙薔
電子設計工程 2022年16期
趙薔
(咸陽師范學院計算機學院,陜西咸陽 712000)
我國旅游業在國家的大力推動下出現了高增速的發展狀態,旅游業已成為我國GDP 的重要組成部分,是具有顯著發展速度與競爭優勢的產業[1]。據旅游部發布的數據顯示,旅游業對GDP 綜合貢獻從2014年的6.61萬億元上升到2018年9.94萬億元,旅游業GDP比重占總GDP貢獻榜單的11.04%。2018年我國從事旅游行業和相關產業的就業人數達7 991 萬人,占全國就業總人口10.3%[2]。與此同時,在線旅游服務作為新興的生活模式,在國內發展十分迅速,已成為旅游業的中流砥柱[3]。
在線旅游是指旅游消費者通過網絡向旅游服務提供商預定旅游產品或服務,并通過網上支付或者線下付費,旅游主體通過網絡進行旅游產品營銷[4]。在此過程中,人們通過搜索引擎瀏覽和查詢相關旅游信息。而隨著海量數據的出現,搜索引擎技術凸顯了其重要性[5]。為了快速搜索到所需信息,聚焦網絡爬蟲引起人們關注。
結合旅游網站的特點,創建基于Python 的聚焦型網絡爬蟲,爬取旅游網站的數據,然后通過數據分析和可視化,給出全國熱門旅游城市和地區的分布和排名情況。
1 網絡爬蟲技術
網絡爬蟲(Web Crawler)是一種按照一定規則自動抓取萬維網信息的程序或者腳本[6],被廣泛應用于搜索引擎以及相關網站的設計。爬蟲技術在數據分析、科學研究、web 安全、輿情監控等領域都有廣泛應用。在數據挖掘、機器學習、圖像處理等科學研究領域,通過編寫爬蟲腳本程序在網上爬取信息,為理論研究提供數據[7]。網絡爬蟲主要分為以下幾種類型:
1)通用型網絡爬蟲[8]。其針對的目標范圍最廣,又被稱為全網爬蟲,缺點是爬行效率低而且對于網頁抓取數據的質量難以保證。
2)增量式網絡爬蟲。將已經爬取過的網頁作更新和添加操作,其時間成本小但實現難度較大,算法要求高[9]。
3)Deep web爬蟲。可分為surface web和deep web,前者針對表層網絡和深層網絡,主要用來對大多數靜態網站頁面進行爬取,后者則是對動態網頁進行爬取[10]。
4)聚焦型網絡爬蟲。也稱為主題網絡爬蟲,其原理是在通用網絡爬蟲的基礎上添加機制和步驟,以實現特定的功能需求[11]。通過制定相關規則,過濾掉已經抓取或不需要的數據,能夠在短時間內從網絡上抓取大量有用數據,這種爬蟲目標明確且工作量較小[12],是目前應用較多的一種網絡爬蟲。
聚焦型網絡爬蟲的實現原理如下:
①根據數據需求和功能需求,定義爬蟲程序的爬取目標,對爬取目標內容進行描述;
②獲取初始的URL,即最初的網址;
③根據去哪兒網初始的URL 爬取頁面,并獲得新的URL,每一個被爬取數據的URL 都是不同的,爬取一個數據后,把這個URL 加入到已爬取URL 列表里,接著獲取新的URL,此過程本質是去重和判斷是否已爬取內容;
④在新的URL 中,過濾掉與定義爬取目標不相關的鏈接和信息數據;
⑤將判斷和過濾的URL 鏈接地址加入到URL隊列里面;
⑥再次獲取URL,重復以上步驟直到滿足設置的停止條件時,或無法獲取新的URL地址時,停止爬取。
聚焦型網絡爬蟲的原理如圖1 所示。

圖1 聚焦性網絡爬蟲的流程圖
2 基于Python的旅游網站爬蟲
為了獲取旅游網站的大量旅游信息并進行分析,研究的內容包含四部分:聚焦型網絡爬蟲、數據儲存、數據預處理以及數據分析與可視化。
2.1 聚焦型網絡爬蟲
創建專門針對旅游網站的聚焦型網絡爬蟲,針對旅游網站的目標數據進行爬取。以Python 語言和Scrapy 框架創建Scrapy 項目,在CMD 窗口中,運行scrapy startproject 命令創建爬蟲項目框架,其中包含項目配置文件、Python 模塊、item 文件、piplines 管道文件、爬蟲目錄等。通過建立Cookie 池定時更換Cookie、偽裝user-agent、設置爬取時間間隔來應對網頁的反爬。
2.2 數據儲存
隨著大數據與云計算的發展,MongoDB 作為一種非關系型數據庫,其使用越來越廣泛。MongoDB是一個面向文檔存儲的數據庫[13],它將數據存儲為一個文檔,數據結構由鍵值(key=>value)對組成,字段值可以包含其他文檔/數組及文檔數組。MongoDB能夠為web 應用提供可擴展的高性能數據存儲解決方案[14],具有高性能、可擴展、易部署、易使用、存儲數據非常方便等特點。
使用非關系型數據庫MongoDB 儲存從網絡爬取的數據,在Pycharm 編輯器下進行MongoDB 數據庫的可視化配置安裝,首先執行啟動操作,等待連接建立,當連接被建立后,開始打印日志信息,然后使用MongoDB shell 來連接MongoDB 服務器。
2.3 數據預處理
數據預處理模塊主要負責對數據采集模塊所獲取的原始數據做進一步的處理與分析,消除網頁噪聲、去除重復網頁及利用網頁文字分詞技術進行網頁內容和特征項的提取。
在數據清洗環節,一般從數據的合法性、完整性、唯一性和正確性對采集的數據進行檢驗。對去哪兒網上采集的旅游數據進行清洗也是從這幾方面進行的,并使用排序算法以及isnull 和drop 等技術對數據進行檢驗和清洗。清洗之后的旅游數據信息完整準確,文件中包含區域、名稱、景點id、類型、級別、熱度、地址、特色、想要去哪里旅游、哪些城市等信息字段。
2.4 數據分析與可視化
數據可視化能夠更加有效、直接地反映數據,也有利數據分析,可以采用柱狀圖來展現全國各個城市旅游地區的熱度。旅游地區的熱門程度通過該地區內旅游景點受關注程度體現,景點的主要參照點是級別和熱度。根據熱門景點的出現次數,并結合其熱度對全國旅游熱門地區進行統計分析。根據地區內熱門景點的出現次數,對其求和從而得到該地區的熱門程度。
大陸所有省、市、自治區熱門旅游地區的旅游熱度餅圖如圖2 所示。
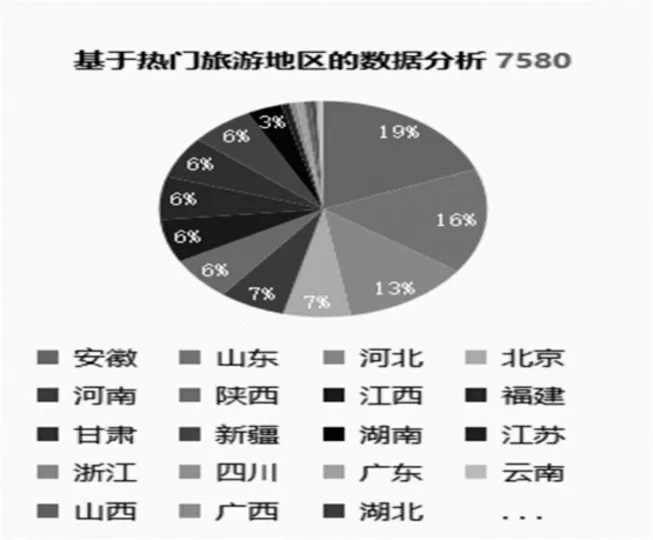
圖2 熱門地區的熱度統計餅圖
從圖2 可以看出,全國排名前十位的熱門旅游省份分別是安徽省、山東省、河北省、北京市、河南省、陜西省、江西省、福建省、甘肅省和新疆維吾爾自治區。其中排在前三位的省份內景區所有采集到的信息比重已經超過了10%,第三名的河北省已經達到13%。
3 繪制詞云
詞云(WordCloud)是目前流行的可視化方法,是文字組件的一種[15]。詞云通過字體的大小反映分詞出現的頻率,是由詞匯組成類似云的彩色圖形,對網絡文本中出現頻率較高的關鍵詞予以視覺上的突出顯示,形成“關鍵詞云層”或“關鍵詞渲染”,從而過濾掉大量文本信息,使瀏覽者一眼掃過文本就可以領略其主旨。詞云的作用是快速感知最突出的文字、快速定位按字母順序排列的文字中相對突出的部分,其本質是點圖,是在相應坐標點繪制具有特定樣式的文字的結果[16]。
在Pycharm 里面完成詞云的生成。首先下載Pycharm 第三方庫中文jieba 分析詞庫,通過第三方庫Pandas 和Matplotlib、wordcloud、PIL 和numpy 實現數據可視化,讀取數據并保存到腳本文件,通過在前面加入#encoding=gbk 防止出現格式錯誤,使用jieba分詞提取所爬取數據中的高頻率分詞,繪制300×400 大小的畫布,導入詞云的背景圖生成詞云。
對“去哪兒網”上大陸所有省、市、自治區的旅游熱度進行統計,其詞云如圖3 所示。

圖3 大陸所有省市自治區旅游熱度詞云
對“去哪兒網”上大陸地區旅游熱度排名前15的省、市、自治區進行統計,其詞云如圖4 所示。

圖4 排名前15的旅游熱門地區熱度詞云
4 結論
通過研究網絡爬蟲技術,提出一種專門針對旅游網站的聚焦型網絡爬蟲,使用MongoDB 存儲爬取的數據,并進行預處理,最后使用Pandas庫和Matplotlib庫等第三方庫進行數據分析和可視化,統計熱門旅游地區排名情況。實驗結果表明,提出的聚焦網絡爬蟲能夠提高對旅游數據的檢索效率,在旅游網站海量數據里快速找到所需信息,能夠為旅游愛好者以及同時為各地區、景點優化服務提供參考,促進旅游行業的發展。
由于聚焦型網絡爬蟲的局限性,不能實時更新數據。后續的研究工作將對系統進一步優化,將聚焦網絡爬蟲和增量網絡爬蟲相結合,用于旅游網站的數據爬取。
猜你喜歡
北京測繪(2022年6期)2022-08-01 09:19:06
少兒科技(2022年4期)2022-04-14 23:48:10
師道·教研(2022年1期)2022-03-12 05:46:47
云南化工(2021年8期)2021-12-21 06:37:54
北京測繪(2021年7期)2021-07-28 07:01:18
海洋信息技術與應用(2020年1期)2020-06-11 12:43:56
傳媒評論(2019年4期)2019-07-13 05:49:14
好孩子畫報(2018年7期)2018-10-11 11:28:06
今古傳奇·故事版(2016年24期)2017-02-07 04:29:04
數學大王·低年級(2014年7期)2014-08-11 16:36:44
