基于Bi-LSTM-Attention 的英文文本情感分類方法
2022-09-02 06:24:56朱亞輝
電子設計工程 2022年16期
朱亞輝
(長沙師范學院外國語學院,湖南長沙 410100)
情感分類是自然語言處理中的一種底層技術,對于問答系統、推薦系統等任務都有較大的幫助[1]。當前,隨著社交媒體的廣泛普及,網絡上的很多關于商品、服務的評論留言對改善商家服務以及了解人們的情感傾向很有幫助[2]。而情感分類任務就是能夠根據評論文本中的情感色彩傾向性進行分類,得到積極和消極情感兩個類別[3]。該文將重點討論句子級別的情感分類任務,即對給定的語句進行情感二分類。
1 相關工作
最近十幾年里,基于深度學習的理論在圖像和文本處理領域均取得了飛躍式的成果與發展[4-5],情感分類任務自然也引入了基于深度學習的方法[6-8]。當前,盡管情感分類領域中有不少的研究工作都已達到了良好的成效,但一方面情感模型無法有效地捕捉兩個方向的句子上下文依賴[9],另一方面又無法對情感特征內部的相互依賴性進行建模。
為了解決上述問題,該文同時采用雙向長短期記憶(Bidirectional Long Short-term Memory)網絡Bi-LSTM 與自注意力機制,提出了一種采用Bi-LSTM 與Attention 的英文文本情感分類算法模型。
2 相關技術
2.1 長短期記憶網絡LSTM
圖1為一個基本的LSTM的結構圖。
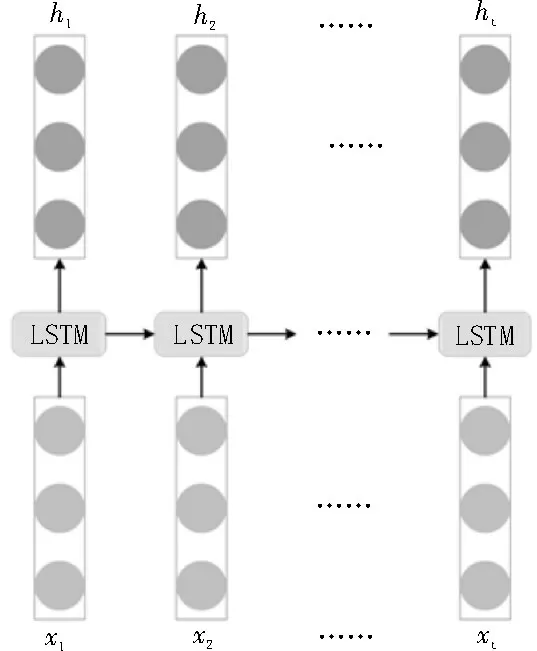
圖1 標準的LSTM結構
LSTM 網絡[10]是基于門控機制構建而成的,每個LSTM 單元中主要包含了輸入門i、遺忘門f和輸出門o。首先,遺忘門根據當前輸入與上一個隱藏狀態ht-1來選擇遺忘上一個狀態ht-1中的哪些信息。其次,輸入門對單元的狀態進行更新,決定了輸入xt和上一個隱藏狀態ht-1的信息通過量。最后,輸出門控制從當前單元狀態到隱藏狀態的信息流。在第t個時間步單個LSTM 單元狀態的運算流程如下:
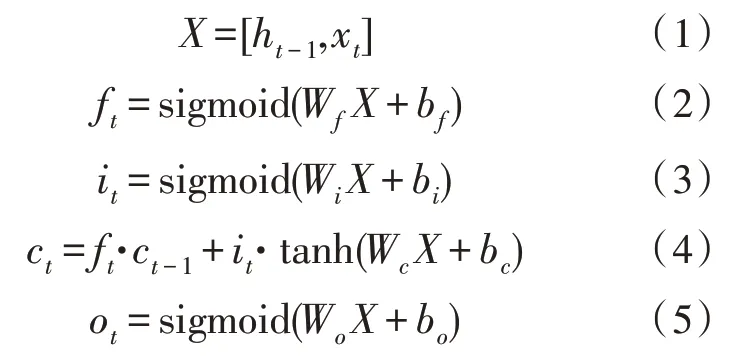
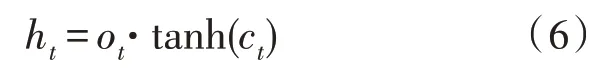
其中,xt∈Rn是輸入向量,而W∈Rm·n是各個門的參數,b∈Rm是偏置向量;上標n與m分別是輸入向量的維度與數據集中單詞的總數;而[·]表示拼接操作。
2.2 雙向長短期記憶網絡
Bi-LSTM 網絡[11]同時考慮了從前往后和從后往前兩個方向的上下文信息,這樣就可以獲取到單個句子中相鄰詞語間的依賴關系。如圖2 所示是一個標準的Bi-LSTM 的基本結構。給定輸入xt和上一個時間步的隱藏狀態ht-1,前向和后向的LSTM 的隱藏狀態的計算公式如下:
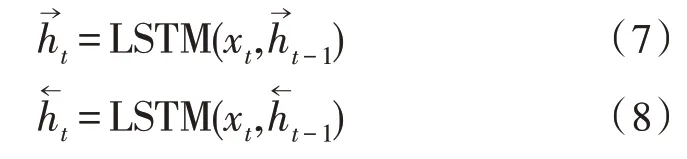
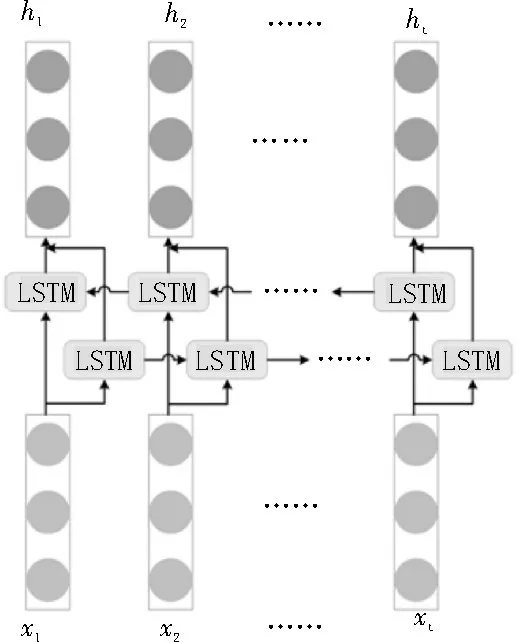
圖2 標準的Bi-LSTM結構
最終,Bi-LSTM 的輸出是拼接前后兩個方向的隱藏狀態得出的,即。
3 基于Bi-LSTM-Attention的情感分類模型
如圖3 所示為該文所提模型的整體網絡架構圖。該模型主要包含了以下幾個必不可少的組成部分,分別是輸入句子序列層、詞嵌入層、Bi-LSTM 層、自注意力層和一個Softmax 分類器。

圖3 Bi-LSTM-Attention模型的整體架構圖
3.1 輸入句子序列層
輸入的第i句子si可以表示為:
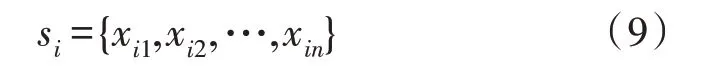
其中,xik是句子序列中的第k個單詞,n是句子序列的最大長度。
3.2 詞嵌入層
詞嵌入層主要用于將輸入句子序列中的單詞表示為一個個維度為n的實值向量。該文使用了300維的GloVe 向量作為詞嵌入預訓練模型。
3.3 Bi-LSTM層
Bi-LSTM 利用前后兩個方向的上下文特征信息,有效解決了上下文信息的提取和利用問題。Bi-LSTM 層的輸出為:
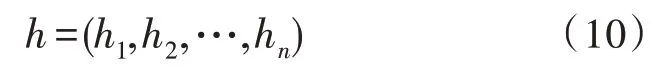
3.4 自注意力層
在情感分類任務中,自注意力機制可以實現對當前輸入進行權重調整,突出了對分類結果有重大影響的詞語的作用,而非同等對待所有的上下文信息。給定Bi-LSTM 層的隱層輸出h,注意力權重的計算過程如下:
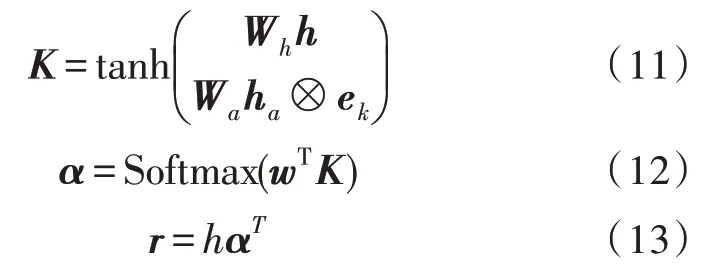
其中,K∈,α∈RT,r∈Rd,Wh∈Rd×d,Wa∈以及w∈都是參數矩陣。α是注意力權重矩陣,而r是輸入句子的權重表示。ha?ek表示向量h重復地拼接了k次,而ek是大小為k的列向量。
最終,用于分類的句子表示為:

3.5 Softmax分類器
該文通過Softmax 層來計算條件概率分布,即預測輸入句子對應的標簽。條件概率的計算公式為:
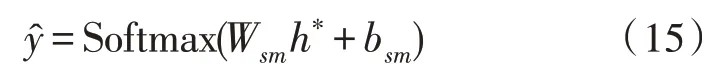
其中,Wsm和bsm分別是Softmax 層的權重參數與偏置參數。
3.6 損失函數
該文在訓練的過程中主要使用交叉熵損失函數:
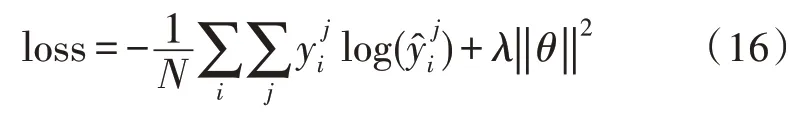
其中,i和j分別是句子的索引與類別索引,yi是預測的標簽。λ是L2正則化項,θ代表模型的可優化參數集合,即{Wf,bf,Wi,bi,Wc,bc,Wo,bo,Wsm,bsm}。同樣地,詞嵌入向量也是模型的參數。
4 實驗結果與分析
4.1 實驗設置
在訓練模型之前,該文通過GloVe 詞向量來建立所有的詞向量,模型中的詞向量及其隱藏層向量均為300 維,Bi-LSTM 層的節點數為16 個。注意力權重的長度與句子的最大寬度是相同的,設為25。批次大小設置為32,學習率初始值設置為0.001,衰減因子為0.01,選擇Adam 作為優化器,L2正則化項λ=0.1。為了防止模型過擬合,該文使用了隨機失活的方法隨機丟棄掉Bi-LSTM 層中的一些網絡單元,隨機失活率設為0.3,訓練總輪數為50。
4.2 數據集和評價指標
該文主要使用兩個常用的公開數據集來進行實驗,分別是MR 數據集和SST-2 數據集。表1 中給出了各個數據集的詳細統計信息。

表1 數據集的詳細信息
該文主要采用準確率(Accuracy)作為指標來評估所提出的模型的性能和有效性。上述指標的計算公式如下:
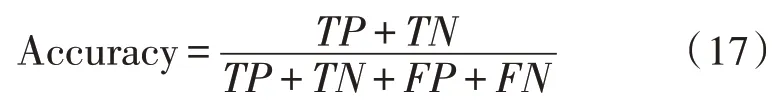
其中,TP為被準確地區分為正例的總數,FP為被誤分為正例的總數,FN為被誤分為負例的總數,TN是被準確地區分為負例的總數。
4.3 對比的基準模型
為了充分地驗證所提算法模型的效果,該節將所提出的模型與其他8 種基準模型進行了實驗對比,即SVM[12]、RNTN[13]、RAE[14]、MV-RNN[15]、CNNmultichannel[16]、CNN-non-static[16]、LSTM與Bi-LSTM。為了確保公平合理,所有的對比模型都是基于同一訓練集從零開始訓練的。
4.4 實驗結果
表2 中提供了上述各個對比模型在MR 與SST-2數據集中的測試結果。對比表2 中的各個模型的準確率可以發現,采用深度學習的分類模型的性能遠勝于常規的采用機器學習方法(即SVM)的分類模型。實驗對比結果表明,該文所提出的模型在兩個數據集上的性能是最優的。具體而言,原始的LSTM 模型在兩個數據集上的性能明顯低于CNN 模型的性能,而使用了Bi-LSTM 模型之后性能稍微有所提升,因為Bi-LSTM 同時考慮了前后兩個方向的上下文信息,但其整體性能依舊低于CNN 模型的。然而,所提出的Bi-LSTM-Attention 模型結合了自注意力機制之后,其性能一舉超越了CNN 模型,這充分表明結合了自注意力機制的Bi-LSTM 模型能夠更好地探索語義特征間的內部依賴關系,并自適應地提升句子中的情感詞的語義特征的權重,從而提升情感分類的性能。
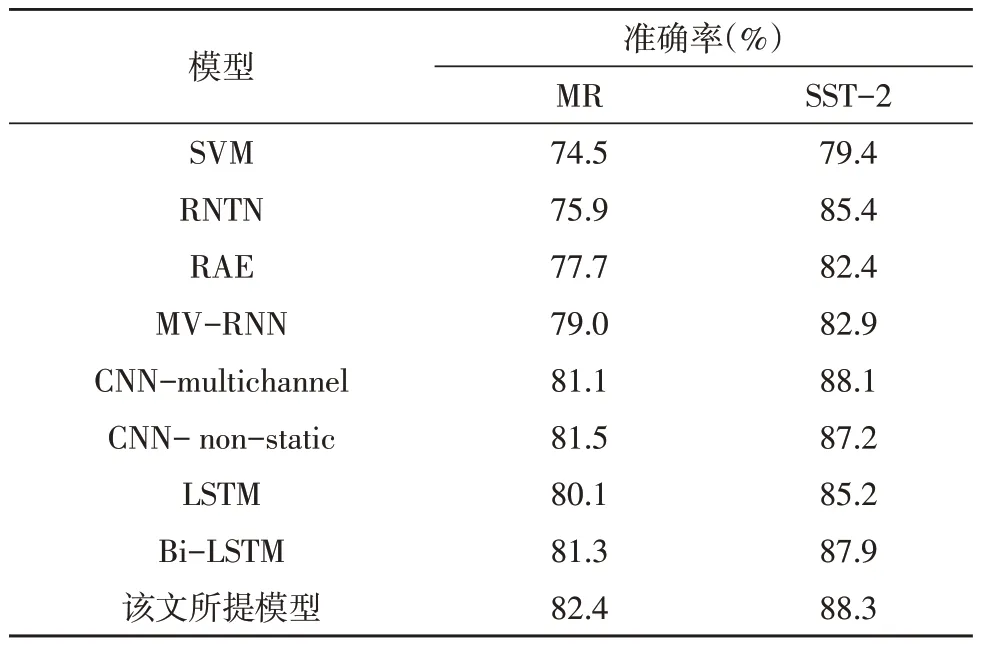
表2 在MR和SST-2數據集上的準確率
5 結論
針對英文文本的情感分類任務,該文主要提出了一種Bi-LSTM-Attention 分類模型。實驗結果表明,該文提出的Bi-LSTM-Attention 模型在MR 和SST-2數據集上的性能顯著勝于其他對比模型,能夠利用注意力機制提升評論文本中的重要情感詞語的權重,從而提升情感分類的性能。此外,該文提出的模型同時利用了前后兩個方向的LSTM 來捕獲雙向的上下文信息,大大提升了模型的特征捕獲與表達能力。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中國生殖健康(2020年5期)2021-01-18 02:59:48
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
北極光(2019年12期)2020-01-18 06:22:10
小太陽畫報(2019年10期)2019-11-04 02:57:59
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中國生殖健康(2018年5期)2018-11-06 07:15:40
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
