基于模糊聚類的核電工程數據分析與處理方法研究
2022-09-02 06:24:54李英
電子設計工程 2022年16期
李英
(上海核工程研究設計院有限公司,上海 200233)
為了優化核電工程物項數據采集管理問題,可以基于目前較成熟的模糊聚類技術處理數據[1-9]。提取數據的主要方法有傅里葉變換、經驗模態分解、小波變換和局部特征分解;數據分類方法主要有智能診斷專家系統、神經網絡、樹狀分析、支持向量機(SVM)等[10]。在數據特征提取方面,短時傅里葉變換對數據的變化并不敏感[11],這主要是由于小波變換的窗口有限,可能會遺漏部分數據。因此該文采用希爾伯特-黃變換,利用經驗模態分解方法將數據信息分解成眾多有意義的固有模態函數分量[12-13],從而解決了專家知識庫更新較慢,難以跟隨最新信息調整的問題[14-16]。該文提出了一種基于模糊聚類的核電工程數據分析與處理方法,該方法可以突出不同采購物資的樣本特征,在內核空間進行聚類,實現高效的工程采購管理。
1 理論基礎
1.1 模糊聚類方法
每種隸屬度類型的樣本范圍在0~1 之間,其中接近1 的值表示樣本出現的可能性極低,接近0 的值表示樣本出現的可能性較大。與普通的數據分類方法相比,通過模糊聚類后,訓練樣本的數量有所減少,從而有效提高了訓練率與分類算法的精度。
原始空間樣本集下,x=(x1,x2,…,xl),xi∈Rn(i=1,2,…,l)的非線性映射是β:x→β(x)。若在高維特征空間中使用歐氏距離,模糊聚類算法的公式為:
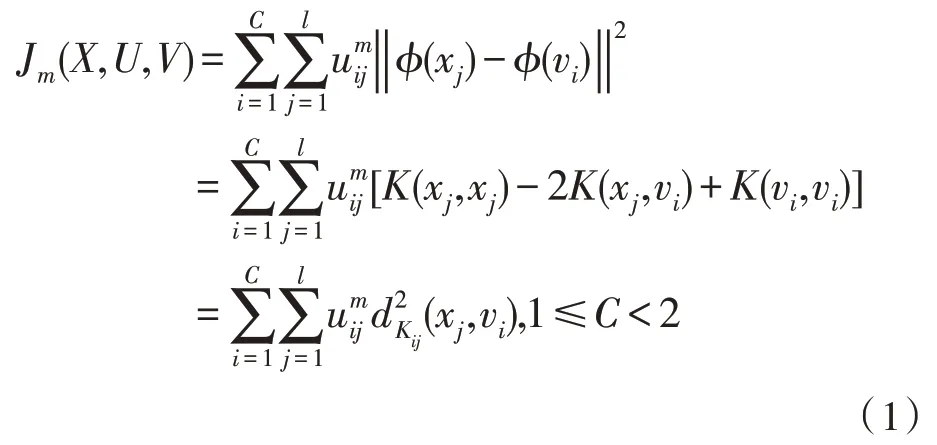
其中,uij是成員,C是模糊組別的數量,vi是第i組的中心,?(vi)是核空間的中心,m∈(1,∞)是模糊權重指數,K(xj,vi)是核公式,是樣本到中心點的距離。
根據KFCM 優化方法,成員的計算公式為:
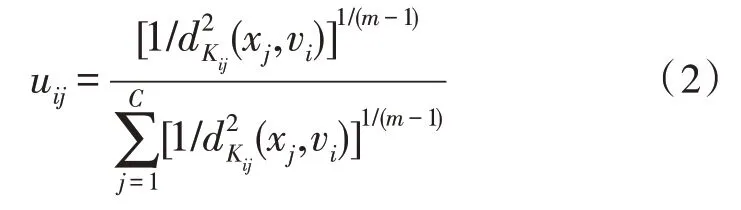
為了最小化目標函數,則需要計算K(xj,vi),其為空間中心的函數,且有K(xj,vi)={?(xj),?(vi)}。
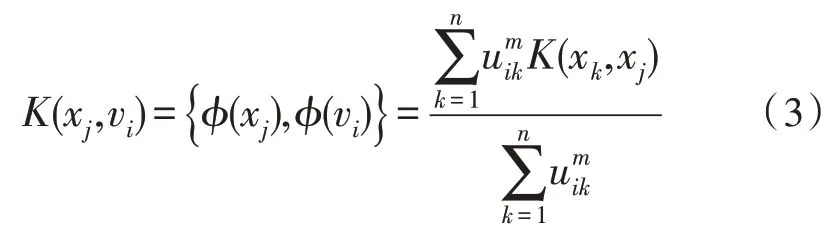
1.2 模糊聚類的步驟
模糊聚類算法基于統計學習理論,使用有限的樣本信息來平衡模型復雜性和學習能力,并尋找出分離超平面最優分類的過程。在保持分類精度的同時,兩側的最大超平面空白空間就可以實現最優分類,然后再通過線性分類來劃分類別邊界。由于一般的線性可分最優超平面樣本可以分為兩種類型,因此,若從最近樣本到超平面的距離被最大化,那么最優超平面的構成問題就被轉化成了基于約束條件的優化問題。
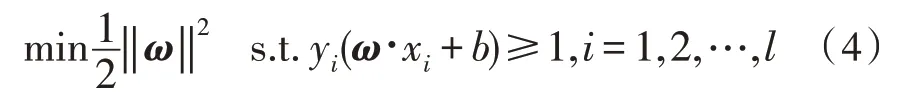
在這一約束條件中,b是閾值,(xi,yi)是樣本,ω是最優超平面法向量。將拉格朗日乘數應用于上述問題,設αi是拉格朗日乘數,則目標函數可以寫作:
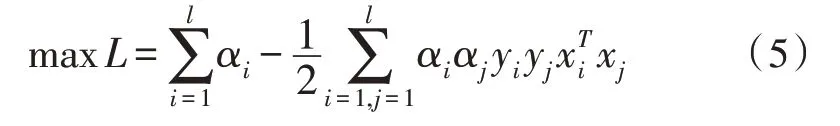
模糊聚類方法的目的是通過最大化兩個對立類之間的邊際來解決分類問題。在訓練之前,聚類算法將其數據在最大程度上簡化為訓練樣本,使用隸屬度來確定類型。為了小于給定閾值,聚類算法的中心值選擇隸屬度,然后將該學習放入訓練集中。
基于KFCM 隸屬度步長的算法步驟如下:
1)選擇0~1 之間的一個隨機數初始化隸屬矩陣u,并且使矩陣滿足約束條件。那么通過計算C 聚類中心就可以計算出新的u矩陣;
2)在這些初始聚類中心vi上使用迭代KFCM 算法后,設置模糊指數m、迭代次數閾值t以及迭代停止條件;
3)計算樣本對聚類中心的隸屬度uij;
4)重新定義集群中心的種類?(vi),計算新的K(xj,vi)和K(vi,vi),并更新成員uij為;
6)聚類算法結束后,u輸出按隸屬度排序且樣本小于80%Aoutput的數據;
7)對輸出樣本進行訓練,依次用數據集的初始分類來檢驗其有效性。
2 核電工程數據處理算法
2.1 數據聚類
在進行采購數據管理系統設計之前,需要根據不同的應用功能對數據類別進行區分。
1)信息共享功能。采購數據共享是系統最主要的應用之一,設計符合采購信息、合同核對、倉庫儲存信息交換的模塊功能業務需求,可以與現存財務管控信息、項目管理模塊、廠家信息以及內容管控相結合。從而確定這些功能模塊和采購流程的邏輯銜接,實現物資信息的共享。
2)物項信息管控。核電工程建設的物項信息數據庫較大、種類繁多,甚至有上百萬類,包括器材、設備、電力部件、工器具和備品等。物項主數據的準確性尤為重要,決定了物資信息的可使用度。為了方便掌握物資的信息情況,對每個物項設定唯一編碼并通過編碼區分類別,對應采購合同的性質以及時間節點。
3)合同管控。在國外通常使用SRM 系統來管控采購合同,但國內類似的應用案例較少,尤其是對于體量龐大的工程,這種準確管理的實現要求較為繁瑣,不符合現場實際。若強行推行SRM 系統可能會導致無效數據的混雜,這需要核電工程項目在管控方式、技術方案上有所創新。
4)倉儲管控。倉儲資料包括核電工程建設的新建和擴建驗收、入庫、出庫、移交等中間階段的信息,在物資最終登記為固定資產前,倉庫中的流通信息量十分龐大。目前的倉儲管控系統通常負責物資從“到貨”開始到被領用出庫的全部信息,管控系統的建立則有助于實現設備和材料等物資信息的充分利用。對于多個種類的物資,倉儲管理需要實現物資的精確關聯。
5)財務管控。財務是資產采購的關鍵環節,但現有財務管控方法存在對前端業務部門的信息了解相對缺失、數據信息浪費的問題。例如合同進度款的匯總計算和支付等信息細化程度不合理,對判斷物資最終歸屬造成困擾,且財務管控依賴于大量人工勞作,對竣工決算和資產轉移等信息處理效率低下,計算效率和精確度均有待提升。
2.2 改進核C聚類均值算法
在基于模糊聚類的工程數據處理建模方法中,核C 聚類均值算法(KFCM)適合用于第一步優化中。首先計算出聚類中心xc,KFCM 算法先用φ(x)映射輸入數據x到高維特征空間,然后進行模糊C 均值聚類,其目標函數為:
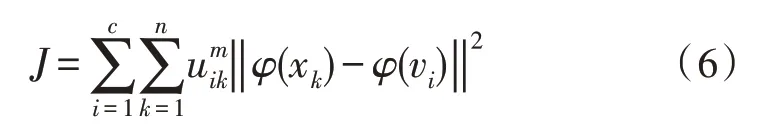
其中,uik(i=1,2,…,c且k=1,2,…,n)是第k個樣本對第i種類型的隸屬度,滿足uik∈[0,1]和歸一化條件=1,?k=1,2,…,n。
對于高斯核函數K(xk,vi),有:
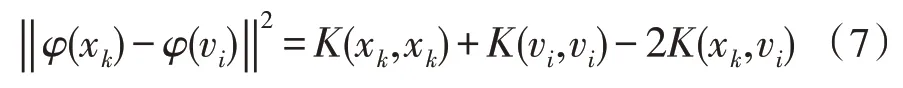
將上式代入目標函數表達式,并歸一化約束條件的隸屬度,再通過以下迭代公式來最小化目標函數:
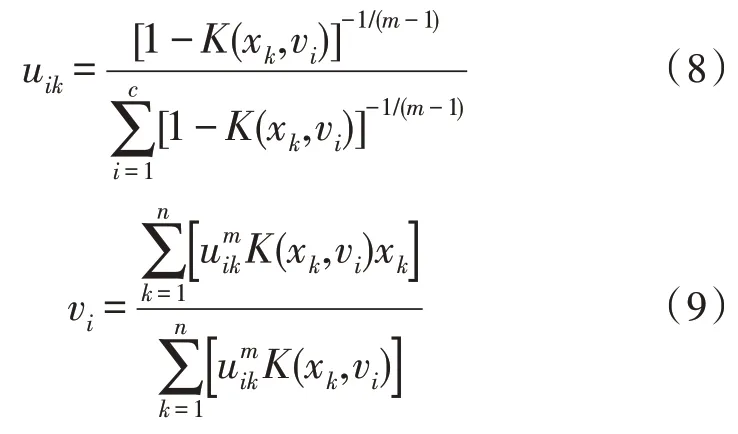
由上述方法可以得出基于核模糊C 均值的模糊聚類核電工程數據分析與處理算法流程,如圖1所示。
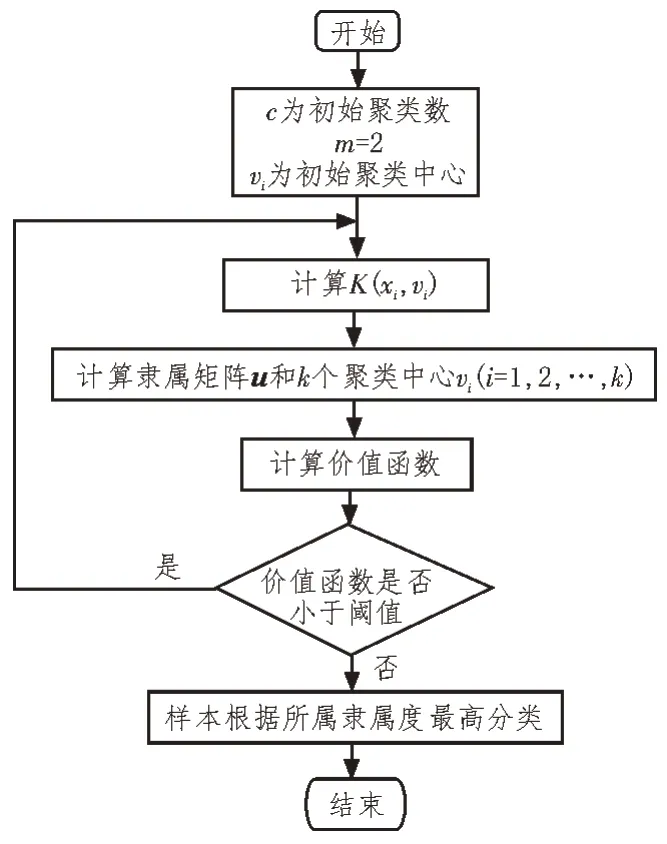
圖1 模糊聚類算法流程
3 聚類算法效果驗證
該文以核電工程采購管理數據為研究對象,基于模糊聚類算法驗證了上述方法的有效性。基于經驗模態對數據類型進行分類,將前10 個模態分量作為樣本矩陣。將特征矩陣奇異值分解得到奇異值特征向量,并劃分為初始訓練集和測試集,再根據基于KFCM 隸屬度的模糊聚類算法和認證算法對128 個樣本值進行分類和驗證。
模糊聚類數據處理流程如圖2 所示。利用模糊聚類的思想,通過MATLAB 軟件為實驗平臺編寫測試程序。通過對數據的多次迭代,計算出各類的聚類中心,得到的待測樣本與各模型曲線聚類中心幅值的對照如圖3所示。圖3(a)表示待測樣本,圖3(b)為標準狀態,從圖中可以看出待測樣本與標準狀態差異較大,且數據走向也有較大差異。MATLAB 軟件中記錄的測試時間的顯示結果與曲線分析結果一致,模糊聚類的類型是一致的,驗證了所提算法的準確性。

圖2 模糊聚類數據處理流程
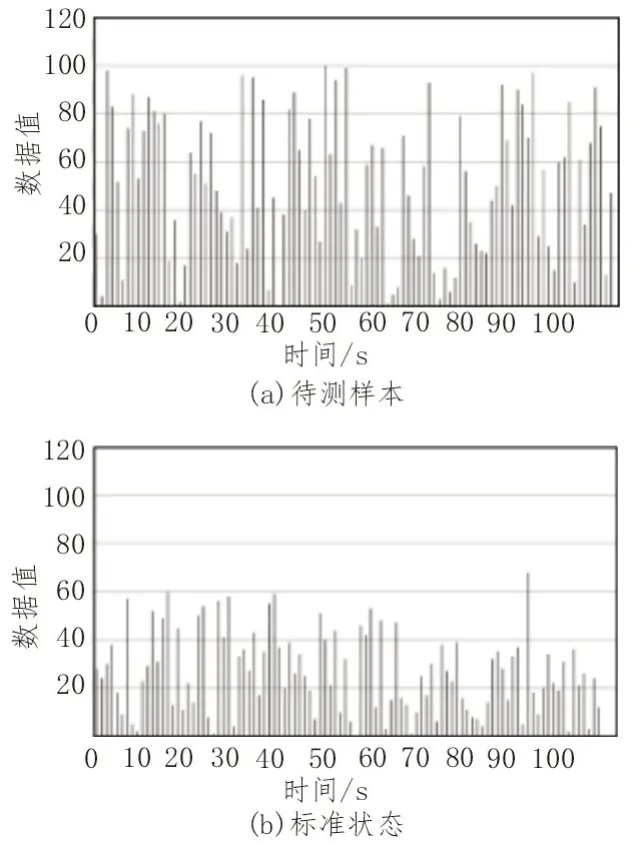
圖3 聚類算法處理樣本數據
該文使用奇異值分解對實驗樣本數據進行分解。首先將訓練樣本數據的列向量構成一個矩陣,然后對其進行奇異值分解,得到訓練樣本的一個特征矩陣,再通過該文算法計算價值函數,生成新的隸屬度和聚類中心。最后,在整個成員矩陣中隨機選擇成員,并將小于樣本輸出數80%的數據作為新的訓練集進行聚類算法訓練。該文實驗的測試樣本數量為128 個,分類結果如表1 所示。

表1 分類結果
實驗結果表明,KFCM 具有更優的特性且分類精度和速度均有所提高,且當訓練樣本線性不可分時,其保持了良好的可行性。
4 結束語
該文提出了核電工程數據改進的核C 值模糊聚類算法,考慮了實際工程量的規模和現場應用的可行性,實現將采購物資信息清單與系統數據準確、可靠地對應。最后通過初始訓練集和測試集128 個樣本的校驗,證明了所提基于模糊聚類算法的核電工程數據分析與處理的有效性和可行性,為后續關聯整合核電工程信息數據推廣應用奠定了基礎。該文所提出的采購全過程數據信息化方案可為核電工程的新建、擴建數據處理提供數據支持。
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
中華手工(2017年2期)2017-06-06 23:00:31
少兒科學周刊·少年版(2015年3期)2015-07-07 21:00:00
中外會展(2014年4期)2014-11-27 07:46:46
建筑創作(2001年3期)2001-08-22 18:48:14
祝您健康(1987年3期)1987-12-30 09:52:32
