基于微博數據的云南省地理情感及主題特征研究
2022-09-02 02:20:46李梁森楊德宏翟文龍李劉飛高勵
城市勘測 2022年4期
關鍵詞:情感
李梁森,楊德宏,翟文龍,李劉飛,高勵
(1.昆明理工大學,云南 昆明 650093; 2.南方海洋科學與工程廣東省實驗室(廣州),廣東 廣州 511458; 3.中國科學院軟件研究所天基綜合信息系統重點實驗室,北京 100190; 4.山東正元數字城市建設有限公司,山東 煙臺 264000)
1 引 言
隨著互聯網和定位技術的快速發展,發布在社交媒體平臺中的信息越來越多帶有位置標簽。這些信息不僅是人們真實生活在網絡世界中的展示,也包含著人們的觀點、興趣和需求等。通過社交媒體信息了解人群活動,進而發掘區域的地理情感和主題特征,對推動區域協調發展具有重要意義。
在國外,社交媒體數據主要來源于Twitter。Mitchell等利用Twitter地理標記數據集進行了美國州和城市的分類及居民幸福感的評估[1];Dyer等研究了美國新冠肺炎大流行期間美國人的關注點及情緒變化[2];于亞新等利用Twitter數據集研究了MFCD算法在用戶行為理解方面的優越性[3];Suparna等研究了組織推文中的情緒與公司股價的關系[4]。在國內,社交媒體數據主要來源于微博及攜程網等。劉逸等通過與聯合國UNWTO數據進行校驗,驗證了微博旅游大數據在情感分析中的可行性[5];李萍等利用百度旅游和攜程網點評數據揭示了北京市5個社區的旅游形象[6];劉萌通過黃山景區微博數據探究了景區不同旅游路徑上的游客情感[7];費濤研究了日常與假期期間微博主題時空分布特征的差異性[8]。
根據《第47次中國互聯網絡發展現狀統計報告》顯示,微博作為全球最大的中文社交媒體平臺,在網絡新聞、政策發布、疫情防控等方面發揮著巨大的作用,已經成為人們獲取信息、抒發情感和表達意見的重要渠道[9]。本文選取新浪微博數據,利用基于情感詞典的情感分析方法和基于主題模型的主題建模方法,獲取每一條微博的量化情感分值及主題類別,探究云南省129個區縣的地理情感及主題分布特征,為云南省的區域協調發展提供有意義的參考。
2 數據采集及預處理
原始數據是通過網絡爬蟲獲取2021年3月~5月期間定位在云南省范圍內的新浪微博數據,并且不包含微博大V、機構團體等數據,僅采集個人用戶的數據,包括用戶名、發布日期、發布位置及發布內容。
由于本文的情感計算需要細化到區縣粒度,因此首先去除沒有定位信息和定位信息大于區縣粒度的數據。其次,微博數據的文本信息不僅包含文字、表情、符號等表現形式,還含有轉發、艾特等互動信息。因此在微博文本中充斥大量的對情感計算無用的標記信息,主要有@用戶、#話題#、網頁鏈接等。為了保證情感計算的準確度,利用正則表達式提取微博的正文內容,并剔除@用戶、#話題#、網頁鏈接等無用信息。最終得到的有效微博數據為26萬余條。
3 研究方法
3.1 情感計算
受理性原則的支配,地理學對情感的研究時間雖然不長,但情感分析作為自然語言處理的一個重要分支,經過多年的發展,技術已經比較成熟[10]。情感計算的方法主要有兩種:非監督的分類方法和監督的分類方法[11~13]。本文采用非監督的分類方法,即利用情感詞典進行微博數據的情感定量化計算。為了盡可能匹配較多的情感詞匯,保證情感計算的準確度,在采用大連理工大學情感詞匯本體庫的7大類21小類情感分類的基礎上,融合其他情感詞典構建通用情感分析詞典,根據情感傾向(正向、中性、負向)和情感強度(1~9、0和-1~-9),計算每條微博的量化情感分值[14,15]。
利用Python結巴分詞進行中文分詞,并在分詞中添加上述的情感詞典作為用戶自定義詞典,從而保證盡可能獲取到較多的情感詞匯[16]。對分詞后得到的詞匯與情感詞典進行匹配,根據情感詞典對其進行賦值,未匹配到的詞則賦值為0;選用中科院中文情感詞典之程度詞典來匹配程度副詞。匹配到的程度副詞根據詞典對其進行賦值,未匹配的詞賦值為1,從而使得其與情感詞相乘不會產生變化;采用四川大學機器學習實驗室的停用詞詞表來去除停用詞對微博情感計算的影響。微博數據中,除了文本數據具有情感傾向以外,還有多種多樣的表情符號。本文參考龐磊和陳冉對微博表情的情感分類及賦值方法對微博數據中的表情符號進行匹配賦值[11,17]。最終,得到每一條微博的平均情感得分,其計算公式為:
(1)
式中,S為該條微博的情感得分;qi為與情感詞典匹配后的得分;di為與程度副詞詞典匹配后的得分;ej為與表情詞典匹配后的得分;m為分詞后的詞語個數;n為匹配到的表情的數量。
3.2 主題建模
文本建模的目的在于發現語料庫中的詞序列如何生成,并構建數學化的描述方法使文本信息可以參與計算。基于概率的潛在語義分析模型(Probabilistic Latent Semantic Indexing,PLSI)和潛在狄利克雷分配模型(Latent Dirichlet Allocation,LDA)是傳統的用于長文本建模的主題模型[18,19]。微博文本由于短文本特有的短小、特征信息少和語義稀疏等原因,使用傳統方法進行主題建模,會產生特征矩陣稀疏的問題,建模效果不理想[20]。Yan等學者2013年5月在萬維網大會上提出的雙語詞話模型(Biterm Topic Model,BTM),在LDA模型基礎上,采用用一元混合模型中所有文檔共享一個主題分布的方法,克服了傳統主題模型的數據稀疏問題,是首個針對短文本的主題模型[21]。
為了提高主題建模的精度,對微博數據進行分詞及詞性標注后,僅保留名詞、動詞和形容詞,并去除少于4個詞的微博數據。采用主題一致性指標(Topic Coherence)確定主題數目并采用BTM模型對微博數據進行主題建模,最終確定微博數據的文檔-主題概率分布和主題-詞概率分布。
3.3 空間分布模式
空間現象受到距離和方向的作用,使得傳統的統計分析方法無法準確描述地理現象。20世紀60年代,法國統計學家Matheron G開創了空間統計[22]。空間統計學的主要思想在于空間中鄰近的現象或數據比遠處的現象或數據具有更高的相似性。采用全局Moran’s I指數的方法對微博情感進行空間自相關分析,根據計算判斷微博情感的空間相關性及置信度[23]。Getis-OrdGi*方法可以獲取高值或低值要素在空間上聚類,用于獲取微博情感及主題模型在空間上高值(熱點)和低值(冷點)的空間聚類特征[24]。
4 結果與分析
4.1 微博情感分值的空間分布特征
計算出260 878條微博數據的情感分值以后,根據計算結果,將微博情感分為三類:即情感分值大于0的正向情感,共有 173 973條,占總微博數量的66.69%;情感分值等于0的中性情感,共 39 419條,占總微博數量的15.11%;情感分值小于0的負向情感,共47 486條,占總微博數量的18.20%。個體微博的情感得分在空間上分布如圖1所示:
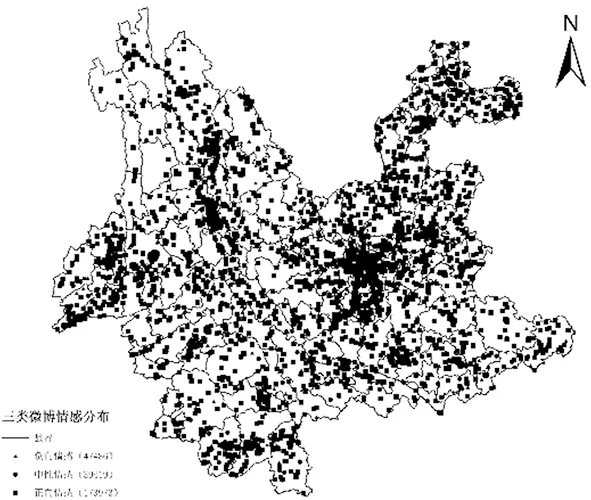
圖1 三類微博情感分布圖
總體上看,微博情感以正向情感為主,但個體微博的情感分值在空間上的分布是隨機的,各類情感互相交錯,在空間上沒有明顯的聚類或分離現象。因此,本文計算了云南省129個區縣的微博情感均值,如圖2所示:
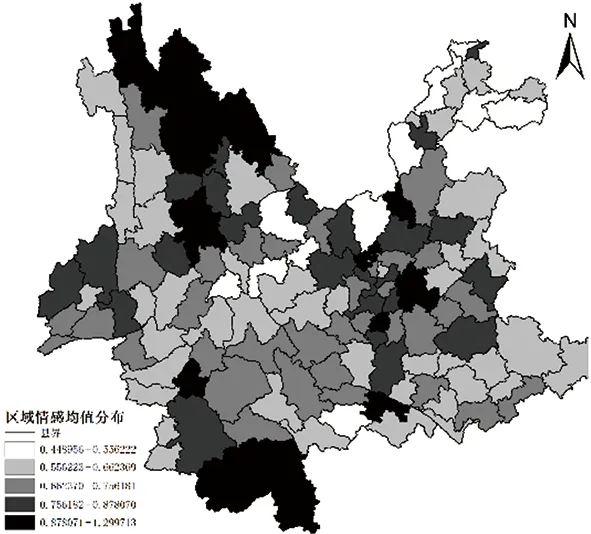
圖2 云南省微博情感均值分布
4.2 微博情感空間分布模式
為了判斷微博情感在云南省范圍內的空間自相關性,根據云南省微博情感均值分布采用全局Moran’s I指數進行空間自相關性的計算,最終結果如圖3所示:

圖3 全局Moran’s I指數計算結果
從圖3來看,最終計算結果:z得分為 4.177 75,p得分為0.000 029,且Moran’s I指數為 0.223 537,則有99%的可能認為微博情感在云南省范圍內具有聚類模式特征。由于Moran’s I指數為正,說明微博情感在云南省范圍內具有正的相關性,即相鄰的區縣具有相同或相似的微博情感。為了進一步探究微博情感在空間上的聚類分布特征,通過Getis-OrdGi*方法計算了云南省微博情感的冷熱點模式,如圖4所示:
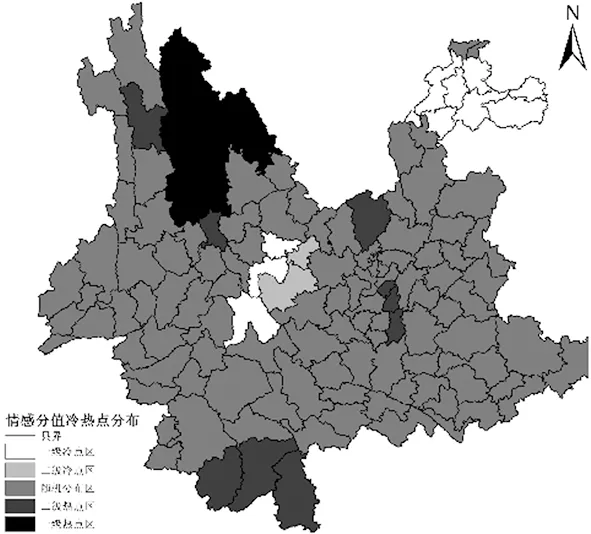
圖4 云南省微博情感冷/熱點分布
根據Getis-OrdGi*值的高低及顯著性水平,采用自然斷點分級法將微博情感在空間上的分布分為5類區域:一級冷點區(冷點高聚集區)、二級冷點區(冷點低聚集區)、隨機分布區、二級熱點區(熱點低聚集區)和一級熱點區(熱點高聚集區)。由圖6所示,云南省的微博情感在空間上具有明顯的冷/熱點(低/高值聚類)特征。熱點區一主要分布在云南省的西北(麗江市的古城區、玉龍納西族自治縣、寧蒗彝族自治縣,大理白族自治州的大理市、洱源縣、鶴慶縣、劍川縣,迪慶藏族自治州的香格里拉市、維西傈僳族自治縣),熱點區二主要分布在云南省的南部(西雙版納傣族自治州的勐海縣、景洪市、勐臘縣);冷點區一主要分布在云南省的東北側(昭通市的昭陽區、永善縣、大關縣、鹽津縣、彝良縣、鎮雄縣、威信縣),冷點區二主要分布在云南省的中部(楚雄彝族自治州的楚雄市、南華縣、姚安縣、牟定縣,普洱市的景東彝族自治縣)。
4.3 主題模型空間分布模式
通過BTM模型對微博文本進行主題建模后,獲取36個主題。選取每個主題下概率最大的前20個詞,采用詞云圖的形式對主題1~主題37進行展示,如圖5所示:

圖5 主題1~主題36詞云圖展示
利用Getis-OrdGi*對36個主題的冷/熱點分布模式進行探究,如圖6所示:

圖6 主題1~主題36冷/熱點分布
如圖6所示,微博情感熱點區一是主題16宗教、主題19人文旅游、主題20風景旅游、主題24正面情緒、主題31天氣分布的熱點區,主題9疾病分布的冷點區;微博情感熱點區二是主題1茶、主題20風景旅游、主題31天氣分布的熱點地區,主題23負面情緒分布的冷點地區。上述主題中,主題19和主題20均為旅游主題,同時旅游主題在微博情感熱點區二是二級熱點區,在微博情感熱點區一是一級熱點區,說明由于疫情影響,處于邊境的旅游城市的旅游業仍然受到較大的影響。出門旅行會對天氣有更多的關注,因此主題31在兩個微博情感熱點區域也屬于熱點分布。而主題23負面情緒的冷點分布與主題24正面情緒的熱點分布,可以近似的看作是同一類分布,說明兩個微博情感熱點區域的人們生活較為輕松愉悅。除此之外,兩個情感熱點區域的熱點分布主題還有其地域分布有關,微博情感熱點區一中的大理白族自治州和迪慶藏族自治州信仰佛教的人較多,因此是主題16宗教的熱點分布區,微博情感熱點區二的西雙版納傣族自治州是云南產茶區之一,因此是主題1茶的熱點分布區。綜上,云南省微博情感熱點分布的共性為關注旅游,并且有較多的正面情緒或較少的負面情緒。
微博情感冷點區一是主題9疾病、主題17離鄉、主題22負面情緒、主題23拼搏、主題33遺憾、主題35音樂分布的熱點區域,微博情感冷點區二是主題2出行、主題17離鄉分布的熱點區域。兩個微博情感冷點區均包含主題17離鄉,主題2出行和主題23拼搏也均與主題17有關。因此,兩個微博情感冷點區的共性為對離鄉有更多的關注。不同的是,微博冷點區域一全部分布在昭通市內,而昭通市作為云南人口第三的城市,僅有兩家三甲醫院,醫療資源短缺,且存在地方病氟骨病,因此對主題9疾病有更多的關注,且存在較多的負面情緒。
5 結 語
基于2021年3月~5月定位在云南省范圍內的26萬余條新浪微博數據,采用基于情感詞典的情感計算方法和基于BTM模型的主題建模方法,度量了微博數據在云南省的情感分布及主題聚類特征,揭示了影響云南省地理情感分布的主要因素。
研究表明,云南省基于微博數據的地理情感在空間上具有明顯的聚類特征,存在大范圍的熱點分布區和冷點分布區各兩個;旅游城市的微博情感較高,且具有更多的正面情緒或較少的負面情緒;微博情感較低的區域更多的關注離鄉拼搏,且微博情感冷點區一由于醫療資源不豐富和地方病的原因,對疾病有更多的關注,且有更多的負面情緒。
本文利用微博大數據,通過將情感分析與主題建模相結合的方式,衡量了云南省的區域地理情感特征及其影響因素,為推動區域的協調發展提供了一種新的思路。
猜你喜歡
今日教育·作文大本營(2025年3期)2025-03-24 00:00:00
中國生殖健康(2020年5期)2021-01-18 02:59:48
家庭醫學(下半月)(2020年4期)2020-05-30 12:42:50
現代裝飾(2020年4期)2020-05-20 08:55:06
北極光(2019年12期)2020-01-18 06:22:10
小太陽畫報(2019年10期)2019-11-04 02:57:59
海峽姐妹(2019年9期)2019-10-08 07:49:00
青年歌聲(2019年7期)2019-07-26 08:35:00
中國生殖健康(2018年5期)2018-11-06 07:15:40
發明與創新(2016年6期)2016-08-21 13:49:38
