基于AI 的第三代圖書館服務平臺數據管理研究*
2022-09-01 14:03:56馬曉亭
新世紀圖書館 2022年8期
0 引言
近年來,隨著大數據技術、云計算技術、傳感器網絡技術與人工智能技術的快速發展,圖書館已跨入了第三代圖書館時代。第三代圖書館可以全方位、多對象、多角度和不間斷地采集服務系統運營與讀者個性化服務相關大數據,并通過對所采集大數據的完全價值挖掘與知識發現可大幅提高圖書館服務能力,在服務平臺系統構建、讀者閱讀需求預測、個性化服務定制與推送等方面改善和提升用戶關系管理的智慧化水平
。
大數據技術是第三代圖書館的核心技術,大數據應用在提高圖書館智慧服務能力與讀者閱讀滿意度的同時,也導致圖書館大數據應用場景中被訪問的數據總量以指數級激增,使圖書館大數據環境呈現出海量(Volume)、多類型(Variety )、處理速度快(Velocity)、價值密度低(Value)的“4V”特點。可以說當下的大數據應用現實狀況對圖書館數據管理提出了新的要求。
傳統的第二代圖書館數據管理策略與技術已不能滿足第三代圖書館大數據智慧決策的需求
。調研機構Gartner公司也在其2018年4月發布的名為《數據中心即將消亡,數字基礎設施出現》的調查報告中表明,到2025年,80%的企業將關閉其傳統的數據中心
。因此,如何利用人工智能技術(AI)強大的機器學習、邏輯推理和系統規劃能力,來智慧管理復雜數據場景下的圖書館大數據庫系統與應用,是第三代圖書館提升大數據管理效率與智慧化水平,降低大數據決策與應用成本,保證圖書館智慧化建設與用戶服務能力的關鍵。
表8列示了經過GDP平減指數調整與增加經濟周期變量后研發投入的斷點診斷分析結果。筆者發現,企業研發投入在供給側改革當年(2013年)就呈現出顯著的結構性調整效果,斷點跳躍(Lwald)系數顯著為正的0.366,且達到了最高峰值,2014年跳躍系數僅為0.148。而相對地,供給側改革前(2012年)企業研發投入斷點回歸中卻有一個顯著地向下跳躍的斷點,跳躍系數顯著地為負的0.113。這表明在排除經濟周期性與通貨膨脹等因素后,供給側改革前我國企業研發投入是存在一個遞減的趨勢。因此,整體而言,上述斷點檢驗結果佐證了供給側改革結構性調整的結構性效果,而且政策執行效果在2013年底體現出實質性調整效果。
1 第三代圖書館基于AI 大數據管理的價值
第三代圖書館的概念源于“上海圖書館東館”籌建調研。為了確保新館20年不落后,調研組對全球圖書館建筑現狀和發展趨勢進行了深入分析研究,并結合新中國建立前后兩個時期上海圖書館建筑的特點,提出了作為第三代的上海圖書館東館建設規劃
。面向未來的第三代圖書館相比第二代圖書館而言,具有促進知識流通、創新交流環境、注重多元素養、激發社群活力等4個顯著功能,將更加注重人的需求、可接近性、開放性、生態環境和資源融合,致力于促進知識流通、創新交流環境、注重多元素養和激發社群活力。在此基礎上,圖書館需要在服務系統構建、運營和讀者服務過程中,加大對相關全數據進行有效的收集、存儲、處理和應用,才能滿足其大數據智慧管理和用戶服務智慧決策的需求。而隨著圖書館數據中心數據總量、結構復雜度的不斷增長,以及大數據決策的效率、可用性需求和數據管理工作量的快速上升,圖書館必須利用人工智能(AI)技術來完成這一任務。
1.1 AI 可實現大數據管理平臺的自動化管理與維護
數據質量保證層接收來自底層數據資源層的數據,通過大數據清洗與過濾、數據集成提取、數據分析處理等流程,實現圖書館大數據的噪聲信號過濾和價值提取。清洗后的數據交付數據價值評估模塊進行數據價值總量、信噪比、決策相關性和可用性評估,并依據評估結果對大數據清洗、數據集成提取;數據分析處理模塊進行反饋控制與二次優化,并將最終達標合格信號交付標準化輸出系統進行數據格式、內容的轉換與標準化處理,然后傳輸至可用數據驗收模塊進行存儲管理
。
此外,基于DL (深度學習)的AI數據管理系統,也應通過自我學習的威脅檢測和監控算法來鑒別被管理數據的完整性和安全性,以及實施最優化的數據管理負載平衡、服務系統電力分配和服務系統資源調度等工作
。
1.2 可確保動態變化的主數據管理具有科學性和準確性
圖書館主數據是用來描述讀者個體特征與閱讀行為、第三方增值服務商業務、圖書館管理與服務系統、讀者個性化服務內容、傳感器采集數據、讀者評價與反饋數據、閱讀終端采集數據的數據。這些數據具有較高的大數據決策價值,可以在圖書館不同業務部門和不同決策對象中反復使用,并且存在于多個異構的應用系統中。集成、共享、數據質量、數據治理是圖書館主數據管理的四大要素,對于圖書館主數據管理應堅持高價值總量、高價值密度、精確、完整、一致和權威性的原則,確保主數據可支持圖書館不同的業務部門、業務系統、業務流程和業務對象大數據決策的科學性
。
伴隨著圖書館服務模式多樣化和大數據應用技術的不斷發展,圖書館數據環境復雜度快速增長。在讀者個性化閱讀服務中,圖書館服務產生的非結構化數據主要有服務系統運營數據、傳感器網絡采集數據、閱讀終端采集數據、讀者閱讀行為數據、讀者個體位置與移動路徑數據、視頻監控數據等,且數據總量也由GB上升到PB級。這些非結構化數據在維度、內在關聯性等方面的復雜度均不斷在大幅提升,將占據數據總量的80%以上,且呈現逐年遞增現象
。從空間維度上來說,這些非結構化數據屬于不同的圖書館要素,這些要素之間存在著千絲萬縷的關聯性,如何完全、實時、準確和經濟地發現他們之間隱匿的知識,對圖書館大數據應用提出了嚴峻挑戰。從時間維度上分析,這些非結構化數據采集于圖書館各要素不同的歷史時間,在不同的決策對象和決策目的上有著不同的價值
。因此,面對復雜的大數據環境,有必要采取AI技術來解決。
1.3 可支持復雜大數據的價值發現與知識圖譜構建
首先,AI主數據管理可以在圖書館不同的分散系統中實現主數據的集中管理,實現主數據的自動合規檢測、應用決策快速部署、一致性保證和增強決策系統IT結構靈活性,在圖書館大數據決策時可以全面、快速、準確地共享主數據資源。其次,AI通過增強的計算能力、數據自動查錄與輸入,可提升圖書館主數據決策的效率與準確性,使主數據決策更加高效、精確、快速和經濟。再次,將AI引入到圖書館主數據的質量管理和治理中,可構建適應于主數據特征和主數據決策需求而動態變化的主數據管理標準,有效降低圖書館員對主數據管理的人工干預程度,有利于主數據的價值挖掘與知識發現
。
首先,AI可以輔助圖書館數據管理員科學地實現對非結構化大數據的有效管理、價值挖掘與知識發現,并依據圖書館大數據決策的對象、內容和標準需求,將大數據精準、實時和經濟地輸出到決策系統來支持圖書館數據決策。其次,AI可以通過深度挖掘圖書館復雜大數據之間的關聯性構建知識圖譜,為讀者個性化服務提供科學的大數據決策依據
。
圖書館在基于AI的大數據管理平臺業務架構中,應堅持大數據管理平臺業務系統架構支持智能化的大數據應用開發、統一的業務語義層結構、一站式數據決策服務、智能自動化的系統運維管理原則,確保圖書館數據管理員與數據管理平臺科學、高效、協同、彈性伸縮、成本可控地構建人機綜合應用系統,滿足復雜大數據環境下圖書館數據智慧決策的需求
。本文構建的基于AI的圖書館大數據管理平臺業務架構如圖1所示。
1.4 可實現大數據全生命周期流程的科學管理
AI數據管理涉及大數據采集、傳輸、識別、整合、清洗、發布、監控和反饋優化等全數據生命周期流程。從當前數據存儲方式實際看,圖書館可根據所存儲大數據的復雜環境特點和大數據科學決策的需求,采取圖書館自建私有云與租賃公有云相結合的數據存儲與管理方式。
首先,圖書館可采用高性能海量數據分布式存儲架構的模式來統一數據管理平臺,依據大數據的價值、數據總量、決策對象和決策標準將數據存儲于不同的云空間上,并在多云之間形成統一的全局命名空間,實現數據在不同云空間之間的自由傳輸與交換。同時可對不同數據訪問接口的交換數據進行統一管理,以提升大數據管理、讀取的效率
。其次,圖書館數據管理系統要堅持構建圖形化數據管理界面的原則,支持異構數據對象的連接及建模,支持靈活多樣的數據交互管理途徑,建立實時數據傳遞觸發的機制,以保障系統之間數據的快速交換響應能力。第三,數據管理應根據大數據存儲需求與決策對象特點,構建圖書館服務系統運營數據域、圖書館管理員域、讀者域、個性化定制服務產品域、第三方合作服務商域、圖書館資產域等多個數據業務模型,實現對數據全生命周期管理流程的準確性、一致性、完整性、可用性和可靠性的全程監控,并將監控結果通知大數據管理員,最終保障基于AI的大數據質量自動化監控、評估、反饋控制與優化
。
2 圖書館基于AI 大數據管理的內容與目標
數據管理是指通過規劃、控制與提供數據和信息資產職能,來開發、執行和監督有關數據的計劃、政策、方案、項目、流程、方法和程序,以獲取、控制、保護、交付和提高數據與信息資產價值。大數據時代的圖書館數據管理是著眼于第三代圖書館發展、職責與讀者服務需要,站在未來圖書館事業宏觀發展的全局高度,將所擁有的大數據視為有價值的信息資源而進行的貫穿于數據全生命周期的管理。2015年,國際數據管理協會在DBMOK2.0知識領域將其擴展為11個管理職能,分別是數據架構、數據模型與設計、數據存儲與操作、數據安全、數據集成與互操作性、文件和內容、參考數據和主數據、數據倉庫、商務智能、元數據、數據質量等。由此,本研究基于第三代圖書館讀者個性化服務大數據智慧決策與大數據管理需求,并結合國際數據管理協會在DBMOK2.0知識領域將數據管理擴展的11個管理職能,我們定義第三代圖書館基于AI大數據管理的內容與目標,如表1所示
。
宋某的公司在經營轉型過程中,選擇在規模化農業生產方面進行投資,這與其以前所經營的農業機械等現代農業生產資料銷售和服務有著密切的關系。宋某的公司經營了近40年的農機銷售業務,因而推進農業生產機械化和規模化與其公司的以往業務有著內在一致性的聯系。宋某選擇在Y鄉進行土地流轉和規模農業生產經營的投資,主要看中了Y鄉的6000多畝耕地。在這個鄉,主要交通公路兩旁的甲村和乙村以及其他幾個村子的耕地面積較為廣闊,且有交通便利的優勢(圖1)。按照宋某公司的規劃,他們希望能在幾年時間里將Y鄉所有耕地全部流轉到公司名下,建立規模化農業生產的園區。

圖書館基于AI的大數據管理應堅持統一數據管理模型、統一數據管理標準化體系、統一數據管理系統平臺、統一數據決策服務標準的原則,才能確保圖書館大數據管理適應圖書館大數據復雜、異構的環境特點,才能確保大數據管理安全、智能、自動化和動態可擴展。
3 第三代圖書館基于AI 大數據管理平臺業務架構
百香果、胡蘿卜、白砂糖、奶粉,均為市售;保加利亞乳桿菌、嗜熱鏈球菌,廣東燕塘乳業有限公司提供;黃原膠、羧甲基纖維素鈉(CMC)、小蘇打,均為食品級。
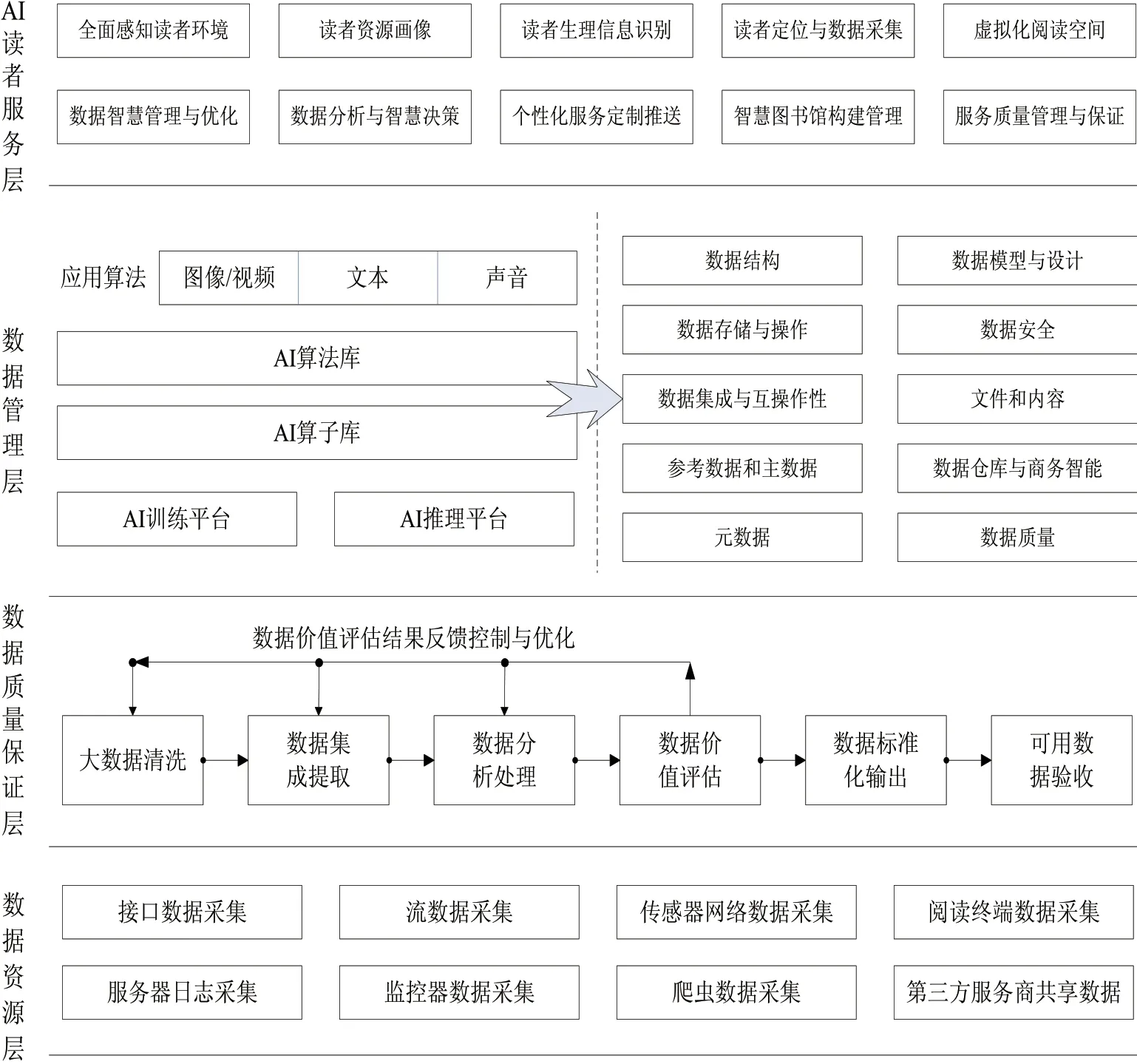
該平臺業務架構按照圖書館大數據生命周期管理流程與數據智慧決策需求設計,共由數據資源層、數據質量保證層、數據管理層、AI讀者服務層四部分組成。
數據資源層是該平臺的基礎層,負責對圖書館業務服務數據、相關服務系統與監控系統數據、讀者閱讀活動數據、第三方共享數據的采集與傳輸管理,數據資源層所涉及的數據主要是圖書館服務原始數據,具有數據海量、結構復雜、低價值密度、干擾信號多樣和可用性低的特點,不適宜圖書館的大數據管理與決策需求。
基于AI的大數據管理平臺都是機器通過自主學習而集成的模型。機器結合各種技術在大數據管理工作中通過不斷的自我學習而優化,進而將數據管理工程師和數據分析師從繁雜的大數據管理常規工作中解放出來。
A 52-year-old man with compensated alcoholic cirrhosis presented for follow up esophagogastroduodenoscopy and multiple duodenal polyps were found.
再次,圖書館數據中心要防止數據管理參數出現漂移和偏差,必須要在正確采集、評估和使用圖書館的大數據管理數據的基礎上才能科學部署數據管理模型,利用ML(機器學習)來訓練、優化和測試圖書館的數據管理系統性能,實現數據管理資源的動態分配與工作負載優化。
讀者服務層基于數據管理層提供的科學、正確、高價值和易使用數據,為圖書館服務系統構建、讀者個性化服務需求定制、用戶服務質量保證、圖書館未來宏觀發展預測等提供科學數據決策支持。從決策范圍和對象劃分,圖書館AI決策可分為戰略級別、戰術級別、運營級別三大類
。戰略級別決策主要涉及圖書館戰略發展宏觀規劃,重塑經營和管理模式、大數據智慧管理與優化、大數據分析與智慧決策、智慧圖書館構建管理等。戰術級別主要是對圖書館服務與讀者閱讀場景的構建做出更精準、實時、科學的決策,進而提升場景的服務效果和價值,主要涉及虛擬化閱讀空間構建、服務質量管理與保證等。運營級別決策是提升圖書館綜合服務能力的創造性、運營效率、可持續發展和服務收益等,主要涉及全面感知讀者閱讀環境、讀者資源畫像、讀者生理信息識別、讀者個體定位與位置信息數據采集等
。
4 基于AI 的圖書館大數據管理平臺管理策略
4.1 做好數據準備與管理系統自動化工作
為滿足復雜大數據環境下圖書館數據智慧決策需求,在實施AI數據科學管理的過程中,數據準備與管理系統自動化是必然的前提條件。
首先,圖書館必須提前采集、存儲與數據管理實際高度吻合的管理業務數據,并且實現數據存儲隨著圖書館數據管理業務活動的變更而動態變化。因為在基于AI的數據管理模型開發中,訓練數據與圖書館大數據應用決策服務場景的匹配度至關重要,關系到AI數據管理模型是否與服務場景高度一致,是否可以訓練出與圖書館數據管理實際超級匹配的AI數據管理模型,是否可以實現對現實數據安全、科學、動態和經濟的管理。
其次,隨著網絡化、信息化及其新媒體的發展,圖書館所涉及到的視頻與動態圖像數據將會成為數據管理的主流數據。這些數據具有數據總量以指數級增長、結構復雜和管理難度大的特點,對于圖書館的數據管理業務繁雜度和實時動態管理需求增加了不少難度。圖書館必須事先通過AI數據管理實現數據的自動清洗、糾錯和上傳,才能提升數據管理的效率。
數據管理層的AI訓練與推理開發平臺基于數據質量保證層標準化、結構化的可靠數據支持,通過可視化建模、大規模分布式訓練等操作,幫助數據管理員對海量大數據進行分析、建模和模型訓練,以增強圖書館訓練算法模型的科學性和開展機器學習的能力。同時,利用訓練好的AI模型應用算法對圖像、視頻、文本與音頻數據進行分析處理,將最優化決策結果部署到數據管理的各個層面和模塊,通過監控、學習、預測、推薦和實施5個過程,為圖書館數據結構管理、數據模型與設計管理、數據存儲與操作管理、數據安全管理、數據集成與互操作性管理、文件和內容管理、參考數據和主數據管理、數據倉庫管理、商務智能管理、元數據與數據質量管理等不同的數據治理場景,提供因果分析、自動參數調優、安全保證、負載預測和調度、性能預測和規劃、IT服務管理等數據管理服務
。
首先,AI可以從圖書館海量的數據管理歷史數據中自主學習規則、程序,明確這些數據所涉及的數據管理時間表及其有效性,不斷增強圖書館自動化智能數據管理中心的監控管理智慧水平,科學、準確和快速地預測與定位數據管理系統的故障點,及時監控、發現管理策略是否為整體水平評估最優,并自動形成智慧決策來提升大數據管理的科學性、準確性、可用性和經濟性
。其次,對于復雜度、價值和決策對象不同的大數據,AI大數據管理平臺可依據圖書館大數據決策實際,動態、個性化地定制與執行不同的大數據管理策略。第三,AI大數據管理平臺可依據圖書館大數據環境和大數據決策實際,實現大數據管理的無人值守和定期自動巡檢,并自動為管理員反饋數據管理的歷史指標參數和分析報表,提升數據管理的安全性與可靠性。
4.2 統一AI 數據管理標準及數據資產管理平臺
圖書館應規范ETL(數據從來源端經過抽取、轉換、加載)標準的流程,實現跨部門、跨業務的統一數據指標口徑、統一對外數據服務接口、統一ID(身份標識號)體系等數據管理流程,確保被管理數據準確、完整、高價值和可用。在此基礎上,圖書館AI數據管理應堅持統一數據資產管理平臺和統一應用系統開發平臺的原則,利用統一的數據資產管理平臺實現數據源管理的統一,使多源數據管理、優化和決策變為對單源的管理,不斷提升AI數據管理、決策與服務的效率、安全性和可控性。
系統采用分層監控策略,首先設定參數上下限,對每一個監測變量進行單獨監測;其次,考慮到部分參變量之間的耦合性和相關性,利用主元分析法(Principle Component Analysis,PCA)[7-8]進行故障診斷,其流程如圖5所示.步驟如下:首先在模型訓練過程中利用歷史樣本選取主元變量,計算得到相應的過程統計量T2和殘差統計量SPE在95%置信度下的控制限;然后計算新樣本的T2和SPE統計量來判定是否存在故障.具體算法可參見文獻[7-8].
此外,圖書館AI數據管理平臺應支持所管理數據權責可溯源、質量可評估、可用性統一評分,將人工智能與機器學習技術應用到大數據標示、數據智慧決策、智能算法引擎設計、智慧管理策略優化、數據管理風險的警示與自動排隊、決策結果的可視化展示、數據管理系統與其它系統的應用對接中去,構建在統一圖書館AI數據管理平臺下跨部門、跨業務、跨決策對象、跨決策內容的高效數據管理與知識服務體系。
生物技術是以現代生命科學為基礎,結合其他基礎科學的科學原理,采用先進的科學技術,按照預先的設計改造生物體或加工生物原料,以提供產品為人類社會服務的技術。生物技術包括發酵工程、酶工程、細胞工程、基因工程和蛋白質工程技術等,其中發酵工程技術、酶工程技術等與人類生活息息相關,被廣泛應用于工業、農業、環境和醫藥等眾多行業之中。
4.3 通過數據高效存儲來消除AI 數據管理瓶頸
大數據時代的圖書館數據不僅呈現指數級快速增長現象,而且復雜結構化、半結構化和非結構化大數據已成為圖書館數據的主流,可以說當前數據管理系統的規模和工作負荷能力的增長,對圖書館大數據的管理提出了更高的要求。以往傳統的圖書館數據管理員憑借個人經驗或是啟發歸納式數據管理規則,來進行數據存取與查詢負載預測、數據庫配置參數調優等,已不適應圖書館復雜、海量、多類型和低價值數據環境的數據管理需求。數據管理員必須基于AI技術實現負載的精準、自動化分配與優化,需要基于AI技術數據管理來應對查詢負載、系統響應參數、大數據分布、數據庫硬件參數指標、數據查詢性能表現、故障與中斷、安全威脅、負載與負荷等歷史數據,通過數據特征抽取、訓練和建模等操作,有針對性的優化數據庫管理系統、流程和策略,才能確保AI數據管理安全、科學、高效與經濟
。
首先,為了提升圖書館大數據管理與決策的效率,必須增強圖書館數據傳輸網絡與數據存儲系統的吞吐量,防止因圖書館數據網絡傳輸延時和存儲堆棧IOPS(每秒輸入/輸出操作)調用延遲而產生數據管理瓶頸,特別應重點考慮數據管理系統在服務峰值時系統資源調度、分配與優化的效率和冗余性問題。
其次,必須利用人工智能的機器學習和數據挖掘知識發現技術,依靠AI數據管理技術來確定不同類型和安全級別最高的云存儲空間,以及選擇在哪些列上建立最優化的索引,來實現大數據的高速檢索、讀取和安全管理。
飛往韓國的班機上,我閉上眼睛,虔誠地哀求上蒼,但愿崔仁浩家庭強大的關系網,不要調查出我的整容記錄。但愿崔仁浩,永遠都不知曉我這個代孕的秘密。我會用一輩子的深愛和忠貞,去換取靈魂的救贖。
安:可能你聽過的都是經典版本的“拉三”,但我得說,在很多比賽的決賽里多次聽到讓我幾乎想要拂袖離場的“拉三”,也正是因為“拉三”在我心里的地位太高,所以我不能忍受演奏者對其機械、麻木、純炫技式的演繹。當然我贊成你的觀點,讓這樣完全無可比性的作品出現在同一輪次本身就不合理,如果我是比賽的藝術總監,我一定會制止這樣情況的發生!
4.4 重點突出對元數據與主數據的管理
元數據是描述信息資源或其它數據的數據,其使用目的在于識別資源、評價資源、追蹤資源在使用過程中的變化,以及實現簡單、高效地管理大量網絡化數據,實現信息資源的有效發現、查找、一體化組織和對已使用資源的有效管理。而主數據是指系統間共享數據(諸如不同讀者、圖書館不同部門、閱讀終端和第三方服務商共享的相關數據)。元數據與主數據管理的有效性是圖書館AI數據科學管理和智慧化決策的前提,因此,必須確保圖書館元數據與主數據在各子系統之間共享數據的一致性、完整性、可控性、通用性和正確性,才能實現圖書館數據管理安全、高效,才能為讀者提供科學、動態和經濟的大數據決策服務。
元數據作為圖書館執行全數據生命周期管理的應用數據,主要涉及數據分析、數據價值評估與保證、數據治理、數據風險和合規性管理等內容。因此,在元數據采集過程中,數據管理員應優化元數據比對算法與入庫邏輯,提高元數據采集、存儲的效率。同時,數據管理員應新增標簽管理功能來擴展業務元數據管理途徑,通過在標簽管理中維護業務元數據分類、業務術語等業務元數據信息,建立業務元數據與技術元數據的關聯,實現業務元數據與技術元數據的統一管理。
主數據具有多共享對象、多數據類型、多應用系統和多數據標準的特點,因此,圖書館必須構建涉及不同讀者、不同圖書館應用服務系統、不同讀者服務內容、不同第三方服務商的主數據標準化模型,以滿足不同閱讀場景下所需的信息視圖和主數據決策環境。此外,對需要多用戶共享的主數據要構建數據關系視圖和采取集中存儲的方式管理,提升主數據存儲和調用的效率。同時,提供豐富的數據管理接口與主數據決策應用業務平臺快速集成,滿足圖書館不同的數據決策系統對主數據的個性化需求。
5 結語
當前,圖書館已進入大數據時代,數據已成為第三代圖書館發展與服務質量保證的重要戰略資源。圖書館通過對大數據的采集、清洗、處理、分析、挖掘與決策,可以為圖書館宏觀發展戰略設計、讀者服務系統構建、讀者個體畫像、讀者個性化服務內容定制與推送、用戶服務質量評估與保障等,提供安全、科學、經濟和實時的數據決策支持。但是,圖書館大數據環境特有的數據海量、結構復雜、處理快速和低價值密度的特點,也給大數據的管理與決策帶來了許多挑戰。標準不規范、低可用性、多噪聲和錯誤的數據不僅會降低圖書館大數據決策的科學性、可用性和經濟性,甚至會導致錯誤、失敗的決策。因此,圖書館必須對大數據開展全生命周期的管理,而基于AI的大數據管理技術能夠在復雜數據環境下,實現大數據生命周期全程的安全管理、隱私保護、價值提升、知識發現和科學決策。
3種類型避雨棚內溫度不同,除了半拱式簡易避雨棚溫度略低于對照,差異不顯著,其他2種類型溫度高于對照,標準連棟避雨棚內的溫度最高,比對照高10.40%。3種類型避雨棚內濕度差異不顯著,標準連棟避雨棚略低于對照。
圖書館在基于AI的大數據管理中,應重點關注關系數據質量和數據決策科學性的數據采集、數據清洗、數據存儲、數據標注、數據分析等環節,堅持統一數據標準、兼容開放、彈性管理和科學高效的原則。此外,在大數據資源管理系統構建和管理模式選擇上,應堅持管理系統集成化、管理范圍時空化、管理表述知識化、管理流程模塊化和管理結果可視化的原則,充分利用AI技術海量存儲、高性能分布計算、機器學習、邏輯推理與系統自動進化等能力,才能實現數據、人員、知識和服務的高度聚合,才能為圖書館讀者個性化定制服務、服務系統運營管理、經營策略制定與運行、未來發展戰略規劃提供可靠的大數據科學決策支持
。
[ 1 ]吳建中.走向第三代圖書館[J].圖書館雜志,2016(6):4-9.
[ 2 ]李娟,張雪蕾,楊峰.基于實證分析的下一代圖書館服務平臺選擇策略:以 ALAM、Kuali OLE、OCLC World Share 和 Sierra 為例 [J].圖書與情報,2017(3):84-92.
[ 3 ]劉煒.關于“下一代圖書館系統”的思考[J].國家圖書館學刊,2015,24(5):7-10.
[ 4 ]劉素清.從電子資源管理視角分析我國高校圖書館服務平臺的發展[J].大學圖書館學報,2018,36(4):11-17.
[ 5 ]謝蓉,劉煒,朱雯晶.第三代圖書館服務平臺: 新需求與新突破[J].中國圖書館學報,2019,45(3):25-37.
[ 6 ]BREEDING M. Library systems report 2018:new technologies enable an expanded vision of library services[J/OL]. American Libraries,2018(5)[2021-08-10]. https://Americanlibrariesmagazine.org/2018/05/01/library-systems-report- 2018/.
[ 7 ]楊新涯,袁輝,沈敏.向服務平臺轉型的下一代圖書館管理系統實踐研究[J].圖書館雜志,2015(9):23-27.
[ 8 ]周義剛,聶華.新一代圖書館服務平臺調研及思考:基于北京大學圖書館的需求[J].圖書館雜志,2019(2):69-78.
[ 9 ]許磊,夏翠娟.第三代圖書館服務平臺的元數據管理:以FOLIO 的Codex 方案為例[J].中國圖書館學報,2020,46(1):99-113.
[10]張磊,賀晨芝,趙亮. 面向數據與知識服務的第三代圖書館服務平臺[J].國家圖書館學刊,2018,27(6):40-47.
[11]BEHARA S.Breaking the monolithic database in your microservices architecture[EB/OL].[2021-08-11].https://dzone.com/articles/breaking-themonolithic-database-in-your-microserv.
[12]康曉丹. 構建第三代圖書館的技術思考:以上海大學圖書館為例[J].大學圖書館學報,2014(1):78-82.
[13]李國良,周煊赫.面向AI 的數據管理技術綜述[J].軟件學報,2021,31(1):21-40.
[14]LI GL, ZHOU XH, LI SH. XuanYuan:an AI-native database[J].IEEE Data Engineering Bulletin,2019,42(2):70-81.
[15]許磊.圖書館系統演變及其元數據管理[J].圖書館論壇, 2021,(6):1-11.
[16]GREENBERG J. Big metadata, smart metadata,and metadata capital: toward greater synergy between data science and metadata[J].Journal of Data and Information Science, 2017,2(3):19-36.
[17]The codex metadata model[EB/OL].[2021-08-12].https://wiki.folio.org/pages/viewpage.action?pageId=1415393.
[18]張曉林.顛覆性變革與后圖書館時代:推動知識服務的供給側結構性改革[J].中國圖書館學報, 2018, 44(1): 4-16.
[19]初景利,趙艷.圖書館從資源能力到服務能力的轉型變革[J].圖書情報工作,2019,63(1):11-17.
猜你喜歡
今日農業(2022年15期)2022-09-20 06:56:20
今日農業(2019年12期)2019-08-15 00:56:32
今日農業(2019年10期)2019-01-04 04:28:15
今日農業(2019年16期)2019-01-03 11:39:20
小太陽畫報(2018年1期)2018-05-14 17:19:25
商周刊(2017年9期)2017-08-22 02:57:56
少年博覽·小學低年級(2016年10期)2016-11-24 06:48:23
雜文月刊(2016年1期)2016-02-11 10:35:51
漫畫月刊·炫版(2015年4期)2015-05-27 07:52:10
現代企業(2015年8期)2015-02-28 18:54:47
