基于人工智能的手語翻譯系統實現
2022-08-30 02:39:38劉繼興張帥峰曾令輝段珍靈沈順權
科技創新與應用 2022年23期
關鍵詞:進程
劉繼興,周 昕,張帥峰,曾令輝,段珍靈,沈順權
(哈爾濱理工大學 計算機科學與技術學院,哈爾濱 150080)
隨著社會的發展,人們的交際需求日益提高。健康人可以使用口語進行交流,而聽障人士(失聰)則需要通過手語交流。由于大部分普通人日常生活中并沒有學習過或接觸過手語,在人與人之間的聯系愈發密切的當代社會,聽障人士與非聽障人士的溝通需求愈發迫切。使用人工智能進行手語翻譯可以為聽障人士和非聽障人士的溝通提供一定的便利。因此,人工智能手語翻譯有著重要的理論價值、應用價值及社會意義。本手語翻譯系統能夠識別《國家通用手語常用詞表》中單獨手勢以及特定情況下連續的手語視頻,并將之翻譯成較為符合語境且具有可讀性的漢語,減輕聽障人士與非聽障人士溝通障礙。
1 系統功能描述
系統能夠實現相對簡單且連續的手語圖像和視頻的采集與翻譯。當聽障人士在攝像頭可識別的范圍內用手語與他人進行溝通,客戶機會通過攝像頭采集手語視頻,將數據上傳到云服務器。服務器會對數據流進行預處理、提取關鍵幀等處理并生成相應文字,然后將生成的文本發送給客戶機。客戶機接收到文字信息,顯示文字并通過語音模塊進行播放。
2 整體設計
整個系統可以分為客戶機和云服務器,如圖1所示。主控板收集攝像頭采集到的手語視頻,基于幀間差分算法在連續手語視頻幀中提取出關鍵幀。使用Tcp socket方式將關鍵幀數據發送給云服務器。云服務器得到幀數據后,對數據流進行解析,使用YOLOv5自訓練手部模型和OpenPose開源庫對圖像進行識別,生成相應的孤立的文字結果,然后采用隱馬爾可夫模型對離散的識別結果進行處理,將最終的文本結果發送給客戶機。客戶機接收到信息,將文字顯示到顯示屏并通過語音播放模塊播放語音。

圖1 手語翻譯系統整體架構圖
3 預處理及關鍵幀提取
采集到的原始圖像中存在大量噪聲,因此需對圖像進行預處理以減少噪聲干擾,使其突出肢體運動區域信息。預選出2種方法。第一種是將輸入圖像閾值化為二值圖像,然后采用高斯濾波對圖像中的每一個像素點進行卷積計算,并加入到原始圖像中進行噪聲點覆蓋;第二種是采用索貝爾算子進行邊緣計算,對肢體部分進行邊緣銳化,增強圖像關鍵信息。但由于第一種方法會造成圖像中的像素點與周圍像素點相似,降低圖像清晰度。所以綜合考慮使用索貝爾算子增強關鍵信息,以減少原始圖像中噪聲的干擾。
利用Opencv庫可以從手語視頻中提取出每一幀圖像,但如果對全視頻的幀進行處理會非常耗時,所以采取提取有效關鍵幀的做法降低處理幀數。關鍵幀的提取是基于幀間差分算法。幀間差分算法的原理是將兩幀圖像進行差分,得到圖像的平均像素強度來衡量兩幀圖像的變化大小。基于幀間差分的平均強度,每當視頻中的某一幀與前一幀畫面內容產生了大的變化,便認為它是關鍵幀,并將其提取出來。
基于幀間差分算法提取關鍵幀的方案如下。
3.1 使用差分強度的順序
對所有幀按照平均幀間差分強度進行排序,選擇平均幀間差分強度最高的若干張圖片作為視頻的關鍵幀。
3.2 使用差分強度閾值
選擇平均幀間差分強度高于預設閾值的幀作為視頻的關鍵幀。
3.3 使用局部最大值
選擇具有平均幀間差分強度局部最大值的幀作為視頻的關鍵幀。
在這里,選擇第三種方案,將具有平均幀間差分強度局部最大值的幀作為視頻的關鍵幀。
4 數據的傳輸
數據的傳輸使用Tcpsocket網絡編程。在整個系統中多臺客戶機與云服務器進行通訊,對后臺服務程序提出了并發要求。處理并發網絡編程常用的幾種方案如下。
4.1 單線程/進程
服務端程序只有一個進程/線程,沒有客戶端連接時會阻塞當前進程/線程。當檢測到新連接時會解除阻塞,與客戶端連接,進行收發數據。
4.2 多進程開發
服務端程序有多個進程,進程間具有父子關系。父進程負責監聽,處理客戶端的連接請求,創建子進程和回收子進程資源。子進程負責與客戶機收發信息。
4.3 多線程并發
和多進程并發類似,此時主線程負責監聽,處理客戶端的連接請求,創建子線程和回收子線程資源。子線程負責與客戶機收發信息。
4.4 IO多路復用epoll
epoll的好處就在于單個進程就可以同時處理多個網絡連接的IO。其基本原理就是epoll這個function會不斷地輪詢所負責的所有socket,當某個socket有數據到達了,就通知用戶進程。用一個進程就能實現服務器并發。
5 手語圖像識別
使用YOLOv5和OpenPose人體資態識別開源庫對圖像進行識別。YOLO(You Only Look Once)是目前流行的目標檢測模型之一,在業界的應用也很廣泛。YOLO的基本原理是:首先對輸入圖像劃分成7×7的網格,對每個網格預測2個邊框,然后根據閾值去除可能性比較低的目標窗口,最后再使用邊框合并的方式去除冗余窗口,得出檢測結果。OpenPose人體資態識別項目是美國卡耐基梅隆大學(CMU)基于卷積神經網絡和監督學習并以caffe為框架開發的開源庫。可以實現人體動作、面部表情和手指運動等資態估計。
手語圖像識別流程如圖2所示。
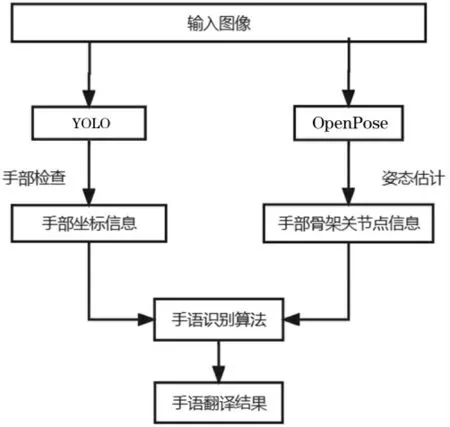
圖2 手語圖像識別流程圖
輸入圖片經YOLOv5處理,檢測出圖片中手部所在位置,得到手部方框左上角橫-縱坐標以及方框的寬-高,如圖3所示。

圖3 手部方框圖
同時,輸入圖片經過OpenPose處理后,提取出圖片中的人員手部骨架關節點坐標,如圖4所示。

圖4 手部骨架關節點圖
最終用手語識別算法處理上述信息得到相應的離散的手語識別結果。
6 采用隱馬爾可夫模型對離散的識別結果進行處理
HMM是一種基于貝葉斯的統計模型,主要用于處理基于時間序列或狀態序列的問題。早期HMM在語音識別和手寫字體識別中得到了良好的識別效果。基本的HMM技術,可以處理單個的時間序列特征向量。而手勢識別面對的是更加復雜的手勢信號,包括手形和運動軌跡等。因此,在手勢識別中,需要采用合適的數據融合方法對各種手語信息進行有效融合。一般在模式識別領域常用的數據融合方法有2種,一種是特征層融合,就是把多個數據流的特征向量組合在一起構成一個新的向量;另外一種就是分類器融合。多數據流模型可以獨立地處理多個數據流,每個數據流獨立地進行訓練,并允許數據流之間異步。同時在手語識別方面,Deng和Vogler提出利用并行HMMs來擴展可識別的手語詞匯量,實驗說明Pa HMM比傳統HMM在識別方面更具魯棒性。
在多流HMM中各個數據流是相互獨立處理的,每個數據流獨立地進行訓練,在識別時按照前述對幾個數據流進行融合,再計算與每個模型的匹配概率,匹配概率最大的模型即為識別結果。
7 結束語
本文提出了一種手語翻譯系統設計方案,使用YOLOv5和OpenPose開源庫對圖像進行識別。系統采用了C/S架構,服務器在云端部署,多臺客戶機可同時工作。使用YOLOv5得到圖片中手部位置坐標,使用OpenPose提取圖片中手部骨架關節點坐標。這些信息作為手語識別算法的輸入,最終輸出手語對應的文字。接下來將進一步探尋手部骨架關節點坐標、手部位置與手語之間的聯系,設計出合適的手語識別算法。
猜你喜歡
中國外匯(2019年20期)2019-11-25 09:54:58
中國外匯(2019年8期)2019-07-13 06:01:06
電腦愛好者(2018年15期)2018-08-23 17:24:06
民主與科學(2014年3期)2014-02-28 11:23:03
教育與職業(2014年7期)2014-01-21 02:35:04
計算機與網絡(2013年1期)2013-06-05 05:31:50
電腦迷(2012年24期)2012-04-29 00:44:03
中華女子學院學報(2012年6期)2012-03-25 13:52:27
俄羅斯問題研究(2012年1期)2012-03-25 09:54:45
杭州師范大學學報(社會科學版)(2011年3期)2011-04-04 08:58:20
