析取置信規(guī)則庫系統(tǒng)參數(shù)優(yōu)化的深度神經(jīng)網(wǎng)絡模型
2022-08-30 09:05:08鄭銘鴻方煒杰葉己峰傅仰耿
福州大學學報(自然科學版) 2022年3期
鄭銘鴻,方煒杰,葉己峰,傅仰耿
(福州大學計算機與大數(shù)據(jù)學院,福建 福州 350108)
0 引言
為更好地解決信息中存在的模糊性、不確定性和不完整性等問題,Yang等[1]在D-S證據(jù)理論[2]、模糊理論[3]、決策理論[4]和傳統(tǒng)的IF-THEN規(guī)則[5]的基礎上,提出了基于證據(jù)推理的置信規(guī)則庫推理方法,能夠更好地表示與處理不確定性信息.置信規(guī)則庫(belief rule-base,BRB)系統(tǒng)的前件屬性的連接方式主要有合取和析取[6]兩種方式,前者被稱為CBRB(conjunction belief rule-base,CBRB),后者被稱為DBRB(disjunction belief rule-base,DBRB).Chang等[6]對兩者進行了充分分析,證明了DBRB系統(tǒng)在具有更小規(guī)模的同時也擁有較好的推理精度.
在置信規(guī)則庫的基礎上,Raihan等[7]將深度學習與置信規(guī)則庫結合(BRB-DL),使用神經(jīng)網(wǎng)絡計算BRB的規(guī)則權重,利用神經(jīng)網(wǎng)絡對信息的記憶性,提高BRB對數(shù)據(jù)的處理能力.然而,在推理過程中,規(guī)則權重、屬性權重等系統(tǒng)參數(shù)都將直接影響最終的推理結果.目前已有許多學者在BRB的參數(shù)優(yōu)化問題上進行研究,如Chen等[8]使用Matlab工具箱的“fmincon”函數(shù)進行參數(shù)優(yōu)化,但是該方法基于Matlab平臺實現(xiàn),算法的可移植性低.Wang等[9]提出使用差分進化算法進行參數(shù)優(yōu)化(differential evolution,DE),但是DE算法需要額外的大量時間計算尋優(yōu),每次的尋優(yōu)都是通過一定的規(guī)則或概率分布逼近最優(yōu)點,優(yōu)化效率較低,而BRB-DL由于引入了神經(jīng)網(wǎng)絡增加了系統(tǒng)的參數(shù)和規(guī)模,將導致DE算法的訓練效率進一步降低.Wu等[10]引入梯度下降算法來提高BRB模型的優(yōu)化速度和收斂精度,但是由于BRB模型本身參數(shù)的約束,需要通過設置特定的步長來確保模型參數(shù)滿足約束條件,從而導致了梯度下降實現(xiàn)困難,優(yōu)化效率不高.總之,目前針對BRB-DL的參數(shù)優(yōu)化方法或多或少都有其自身的不足.
針對以上問題,本研究首先引入深度神經(jīng)網(wǎng)絡(deep neural network,DNN)與DBRB結合(DBRB-DNN),DBRB系統(tǒng)的規(guī)則構建是通過前件屬性的參考值線性組合而成,系統(tǒng)規(guī)則數(shù)和參數(shù)的數(shù)量相比CBRB更加精簡,系統(tǒng)的復雜度更低.接著,引入梯度下降算法對DBRB-DNN的系統(tǒng)參數(shù)進行優(yōu)化,同時針對DBRB-DNN中因參數(shù)約束導致梯度下降算法應用效率低的問題,對DBRB-DNN的系統(tǒng)參數(shù)進行預處理,從而使得梯度下降算法更好地應用在DBRB-DNN上.最后,將模型的應用范圍擴展到分類問題上,并在分類和回歸問題上進行實驗,驗證本文提出方法的有效性.
1 析取置信規(guī)則庫(DBRB)系統(tǒng)
1.1 DBRB的規(guī)則表示
析取型BRB系統(tǒng)[6]是通過析取符號連接不同的前件屬性,其中第k條規(guī)則表示為
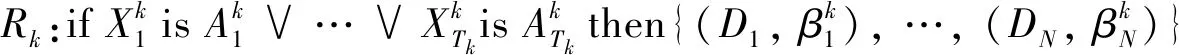
(1)
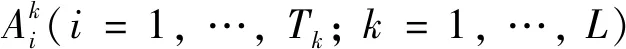
1.2 DBRB-DNN模型
DBRB-DNN系統(tǒng)是對BRB-DL[7]系統(tǒng)的改進.首先,DBRB-DNN使用析取置信規(guī)則庫與神經(jīng)網(wǎng)絡結合,縮小了系統(tǒng)規(guī)模,簡化了前件屬性權重δ和規(guī)則權重θ兩個系列的參數(shù).其次,針對BRB-DL因使用“relu”函數(shù)導致的神經(jīng)元壞死,損失值無法下降的問題,DBRB-DNN引入“tanh”函數(shù)進行改進.最后,針對BRB-DL只用于解決回歸問題的局限性,本文將DBRB-DNN應用在分類問題上,擴展其應用范圍.DBRB-DNN模型主要的工作過程如圖1所示.
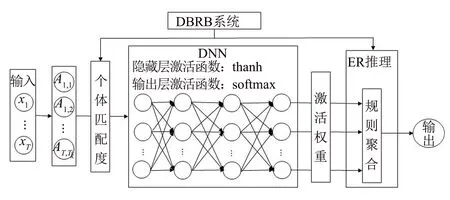
圖1 DBRB-DNN工作流程Fig.1 Working process of DBRB-DNN
1.3 DBRB-DNN系統(tǒng)的推理方法
DBRB-DNN推理過程主要分為2個步驟[1]:1) 激活權重計算;2) ER算法合成規(guī)則.
1.3.1 激活權重計算
計算激活權重之前,首先要計算輸入數(shù)據(jù)對前件屬性參考值之間個體匹配度,一般采用歐式距離進行計算.對于輸入數(shù)據(jù)X的第i個分量xi,可以轉化為如下形式.
S(xi)={(Ai,j,αi,j),i=1,2…,T;j=1,2,…,Ji}
(2)
其中:αi,j表示輸入xi對于前件屬性參考值Ai.j的匹配程度.接下來,使用DNN計算每條規(guī)則的激活權重,其中輸入層的神經(jīng)元個數(shù)等于前件屬性參考值的個數(shù),輸出層神經(jīng)元的個數(shù)等于規(guī)則的條數(shù),每層神經(jīng)元之間采用全連接的方式.神經(jīng)元之間的具體工作方式如下.
zk=ckαk+bk
(3)

(4)

(5)
其中式(3)和(4)為隱藏層神經(jīng)元工作方式,式(3)和(5)為輸出層神經(jīng)元工作方式;ck表示的是神經(jīng)元的權重值,為一組矩陣向量;ak表示的是個體匹配度,為一組輸入向量;bk表示的是神經(jīng)元的偏置值;uk表示隱藏層的非線性輸出;wk為權重值.
1.3.2 ER算法合成規(guī)則
計算出每條規(guī)則的激活權重后,用ER合成公式對所有的激活規(guī)則進行合成.在規(guī)則完整的情況下,輸入x,第i個結果評價等級上的置信度βi(x)計算公式[12]為
(6)
其中,
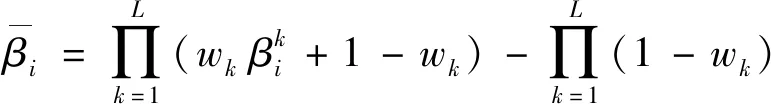
(7)
上述公式合成后,得到結果置信分布{(Dn,βn)|n=1,2,…,N}.對于分類問題,一般直接選取置信度值最大所對應的結果評價等級作為結果輸出.對于回歸問題,則要使用各個評價等級對應的效用值與其對應的計算得出的置信度進行加權,得到數(shù)值型的輸出.
2 基于梯度下降的參數(shù)優(yōu)化方法
2.1 DBRB-DNN的偏導數(shù)
通過節(jié)1.3,可分析得出DBRB-DNN需要優(yōu)化的參數(shù)有神經(jīng)網(wǎng)絡中每個神經(jīng)元的權重和偏置值以及每條規(guī)則的結果置信度,本研究應用梯度下降法[13]訓練DBRB-DNN.
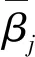
(8)
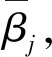
(9)
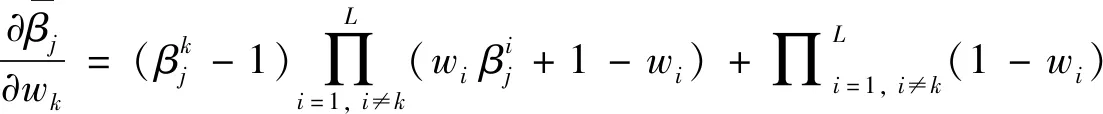
(10)
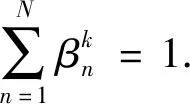
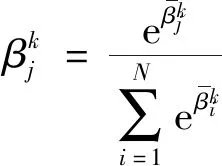
(11)
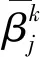
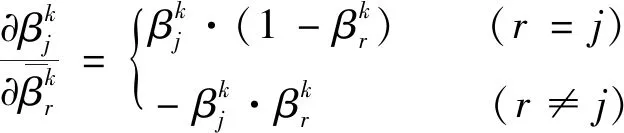
(12)
式(7)中第k條規(guī)則的激活權重wk來自于神經(jīng)網(wǎng)絡的輸出.本研究選用多層的全連接深度神經(jīng)網(wǎng)絡與DBRB進行結合,當損失值通過反向傳播到神經(jīng)網(wǎng)絡后,神經(jīng)網(wǎng)絡將根據(jù)損失值計算每一層神經(jīng)元的權重和偏置的偏導數(shù),根據(jù)式(5)可以求得輸出層激活權重對線性輸出zi的偏導數(shù)為
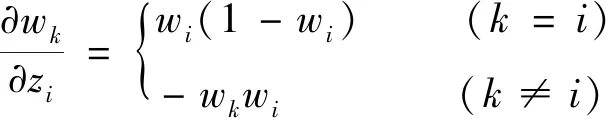
(13)
根據(jù)式(4)可以求得神經(jīng)層內部權重對線性輸出zk的偏導數(shù)為
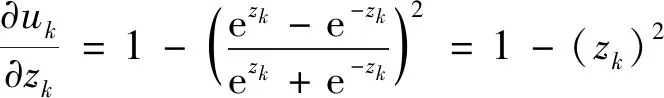
(14)
接著,根據(jù)式(3)求得線性輸出zk對輸出層神經(jīng)元權重和偏置的偏導數(shù)為
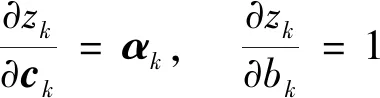
(15)
當求出輸出層神經(jīng)元對應的權重和偏置的導數(shù)時,可根據(jù)損失值繼續(xù)反向傳播求出神經(jīng)網(wǎng)絡每一層的神經(jīng)元權重和偏置的偏導數(shù).
得到系統(tǒng)每一步參數(shù)的偏導數(shù),根據(jù)鏈式求導法則,可以分別得到損失函數(shù)對推理系統(tǒng)第k條規(guī)則各參數(shù)的偏導數(shù).第k條規(guī)則中第j個結果屬性的置信度的偏導數(shù)為
(16)
這里用C和B表示神經(jīng)網(wǎng)絡中所有的神經(jīng)元權重和偏置值,神經(jīng)元的權重和偏置值偏導數(shù)為
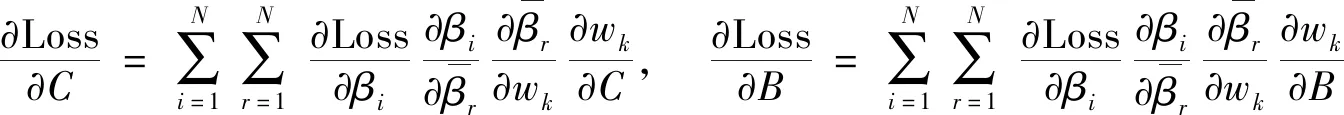
(17)
計算出系統(tǒng)所有待優(yōu)化參數(shù)的偏導數(shù),就可以求得參數(shù)優(yōu)化的方向,使用梯度下降算法訓練DBRB-DNN模型.
2.2 優(yōu)化模型
通過對DBRB-DNN模型的分析,需要優(yōu)化的參數(shù)有
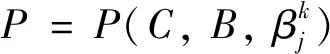
(18)
使用梯度下降進行參數(shù)訓練的模型可以表示為
Pnew(C,B,β)=Pold(C,B,β)-λ?Poldloss
(19)
其中,λ表示參數(shù)模型沿負梯度方向更新的學習步長.
基于BRB的優(yōu)化模型[14],提出DBRB-DNN的優(yōu)化模型如圖2所示.
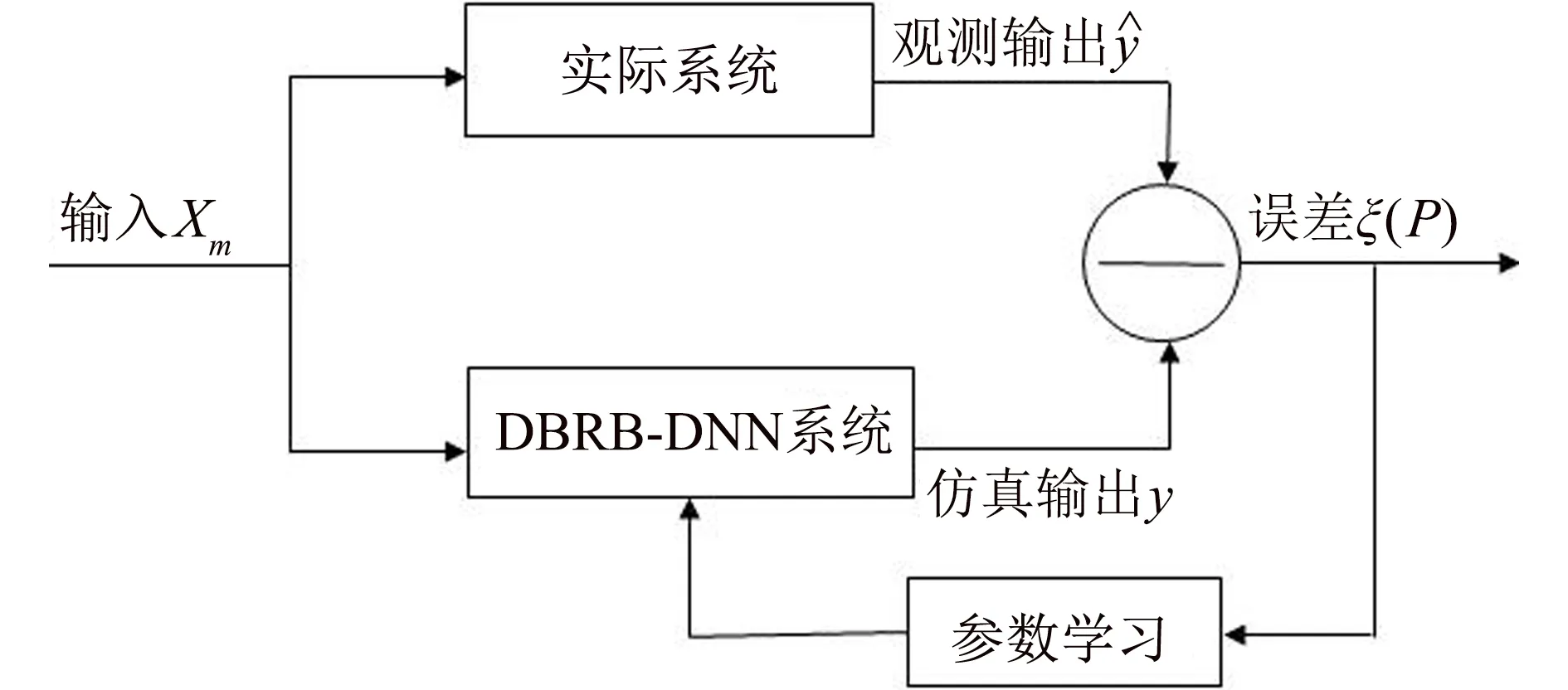
圖2 DBRB-DNN參數(shù)優(yōu)化模型Fig.2 Parameter optimization of DBRB-DNN
DBRB-DNN優(yōu)化的目標函數(shù)為
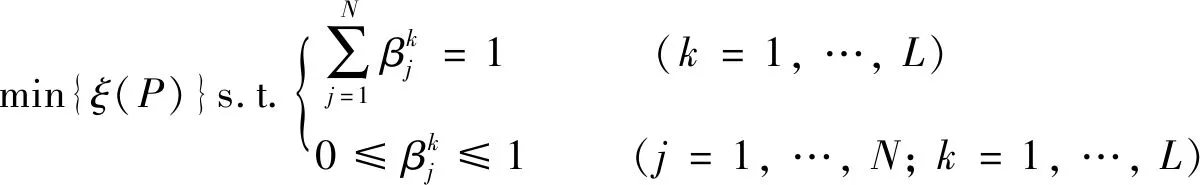
(20)
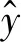
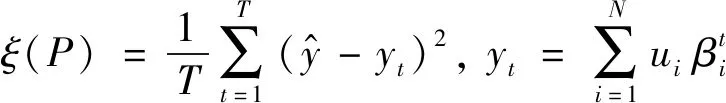
(21)
其中:ui表示第i個結果屬性對應的效用值.
(22)
從上述分析可以看出,假設神經(jīng)網(wǎng)絡有K層,輸入層有A個神經(jīng)元,隱藏層的神經(jīng)元有S個,輸出層神經(jīng)元有L個,DBRB-DNN系統(tǒng)的訓練模型包含的訓練參數(shù)為S1=N×L+S×(K-2)+L+A×S+S×L+(K-3)×S2個,約束條件為S2=N×L+L個,實際上就是一個求解含有S1個參數(shù),且?guī)в蠸2個約束條件的非線性優(yōu)化問題.算法步驟如下.
步驟1構造初始DBRB-DNN系統(tǒng)并設置梯度下降的初始參數(shù)(如學習率、步長等).
步驟2劃分訓練集和測試集,并使用訓練集正向推理計算出損失值ξ(P).
步驟3計算出DBRB-DNN模型待優(yōu)化參數(shù)的偏導數(shù),并根據(jù)損失值反向傳播更新待優(yōu)化參數(shù).
步驟4根據(jù)更新得到的參數(shù)判斷損失值ξ(P)是否減小.如果減小,則更新參數(shù);否則,保留上一代的參數(shù).
步驟5判斷是否滿足終止條件(如:達到設定的最大迭代次數(shù)),如果滿足,跳出訓練并保存模型;否則,跳回步驟3.
3 實驗部分
本實驗選取一個5層的DNN神經(jīng)網(wǎng)絡與DBRB相結合,輸入層神經(jīng)元的個數(shù)為前件屬性參考值個數(shù),輸出層神經(jīng)元個數(shù)為DBRB規(guī)則庫的規(guī)則數(shù).本節(jié)首先對多峰非線性函數(shù)進行擬合;然后,通過北京市PM2.5的預測實驗驗證模型的性能;最后,從UCI上選取多個公共數(shù)據(jù)集進行分類問題上的對比實驗.實驗環(huán)境為:Inter(R) Core(TM) i7-6700 CPU @ 3.40 GHz 3.41 GHz;16 GB內存;Windows 10操作系統(tǒng);算法實現(xiàn)平臺為Visual Studio Code 1.57 x64;Python版本3.8.5.
3.1 多峰函數(shù)非線性擬合
在本節(jié)中,擬合一個多峰非線性函數(shù),以驗證梯度下降算法優(yōu)化參數(shù)的有效性.DBRBD-DNN的神經(jīng)網(wǎng)絡有5層,輸入層有5個神經(jīng)元,輸出層有5個神經(jīng)元,3個隱藏層各有20個神經(jīng)元.非線性函數(shù)公式如下.
g(x)=e-(x-2)2+0.5e-(x+2)2(x∈[-5,5])
(23)
由式(23)分析可知,當變量x取-2,0,2時為多峰函數(shù)的極值點,根據(jù)極值點可以設置規(guī)則結果屬性的評價等級和相應的效用值.
{D1,D2,D3,D4,D5}={-0.5,0,0.5,1.0,1.5}
(24)
選擇自變量x作為規(guī)則的前件屬性,選擇5個極值點作為前件屬性的參考值,分別為{-5,-2,0,2,5}.然后在0和1之間隨機初始化結果屬性的置信度,同時隨機初始化神經(jīng)網(wǎng)絡中的權重值和偏置值.
接著,采用梯度下降算法對初始DBRB-DNN模型進行訓練.通過在定義域上對自變量x均勻選擇1 000個值作為擬合數(shù)據(jù)集,學習率設置為0.001,每個批次使用64個樣本,訓練次數(shù)分布設置500,1 000和1 500次進行3次實驗.訓練后的DBRB-DNN的性能如圖3所示.可以看出,經(jīng)過訓練的DBRB-DNN可以很好地擬合函數(shù)g(x).
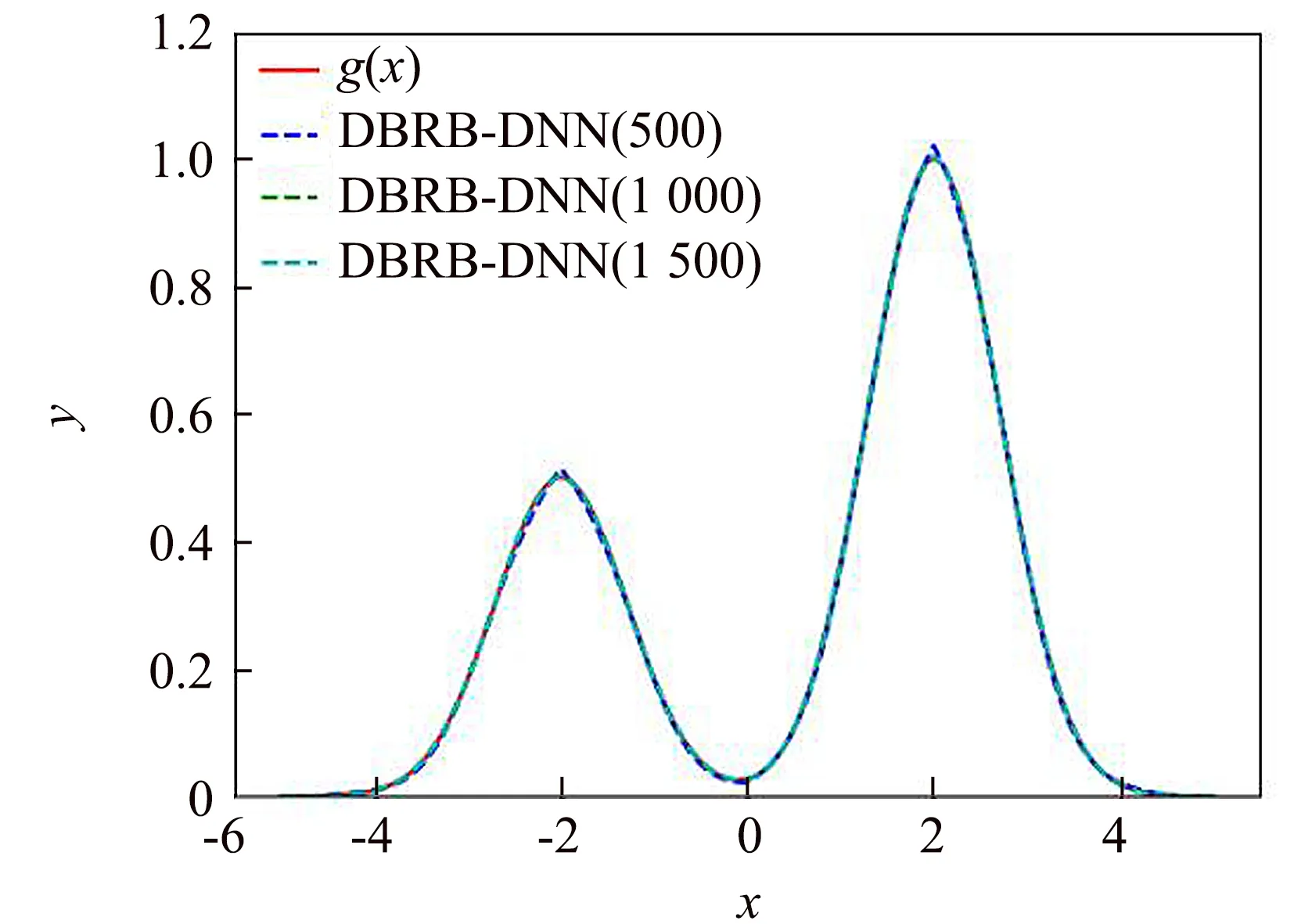
圖3 基于梯度下降的DBRB-DNN輸出結果Fig.3 Results of DBRB-DNN based on the gradient descent algorithm
為更好地驗證本文所提出的基于梯度訓練的DBRB-DNN方法,本實驗分別與文獻[7,9,15]中的方法進行比較,以均方誤差(MSE)和運行時間(s)為指標,文獻[7]的相關實驗在MATLAB R2020b中實現(xiàn).從表1可以看出,本文所提方法在1 000次迭代訓練以后時間和精度上都最佳,而500次迭代訓練雖然排名第二,但是在時間上仍遠高于其他文獻的方法.

表1 函數(shù)擬合性能比較Tab.1 Comparison of function fitting performance
3.2 北京市空氣質量污染預測
為進一步驗證本文提出的DBRB-DNN模型的性能,使用北京市空氣質量數(shù)據(jù)集進行實驗,數(shù)據(jù)集總共含有43 824個樣本點.首先對數(shù)據(jù)集進行歸一化處理,接著使用五折交叉驗證來評估模型的性能.露水、風向、風速作為前件屬性,PM2.5的值作為結果屬性.其中每個屬性有3個參考值,神經(jīng)網(wǎng)絡有5層,輸入層神經(jīng)元有9個.輸出層神經(jīng)元有3個,3個隱藏層神經(jīng)元各有12個.學習率為0.001,每個批次使用128個樣本,并進行1 500次迭代訓練.圖4展示了DBRB-DNN在測試集上PM2.5預測值與實際值的對比.其中橫坐標為樣本點的數(shù)量,縱坐標為PM2.5歸一化后的預測值.
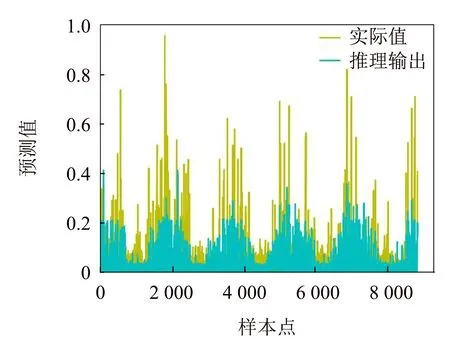
圖4 DBRB-DNN對PM2.5的預測值與實際值的比較Fig.4 Comparison of actual PM2.5 values and predicted PM2.5 values by DBRB-DNN
從圖4中可以看出,經(jīng)過訓練后的DBRB-DNN模型在測試數(shù)據(jù)集上具有較好的預測精度.為了更加直觀地驗證本文模型的性能,接下來還將與文獻[7]方法、LSTM神經(jīng)網(wǎng)絡以及DNN神經(jīng)網(wǎng)絡進行比較,其中LSTM和DNN模型的具體參數(shù)和設置參考文獻[7].取均方誤差和運行時間作為評價指標,比較結果列于表2.其中表2中的第一輪到第五輪表示五折交叉驗證中每一輪的MSE值,平均表示五折驗證以后MSE的平均值,平均運行時間指五折交叉驗證每一輪的平均運行時間,文獻[7]的運行時間為本文在MATLAB R2020b中實現(xiàn).
從表2中可以明顯地看出,在五折交叉驗證中,DBRB-DNN每一輪的MSE值都優(yōu)于其他幾種方法,最終的平均MSE值為0.002 78也是最佳的.這一結果表明,本文所提出的方法優(yōu)于其他幾種模型,而在平均運行時間上,本文所提出的方法為753 s,也遠低于文獻[7]方法.

表2 不同方法下MSE值比較和平均運行時間Tab.2 Comparison of MSE values under different methods and average running time
3.3 公共分類數(shù)據(jù)集實驗研究
研究選取7組UCI的公共分類數(shù)據(jù)集來驗證本文所提出的方法.實驗方法采取十折交叉驗證,取平均準確率作為比較指標.DBRB-DNN的屬性參考值個數(shù)統(tǒng)一設置為5個(即DBRB的規(guī)則數(shù)為5條),神經(jīng)網(wǎng)絡有5層,輸入層有5n個神經(jīng)元(n為每個數(shù)據(jù)集對應的特征數(shù)),輸出層有5個神經(jīng)元,3個隱藏層各有20個神經(jīng)元,學習率為0.001,每個批次使用128個樣本,并進行1 500次迭代訓練.7組數(shù)據(jù)集的詳細信息列于表3.
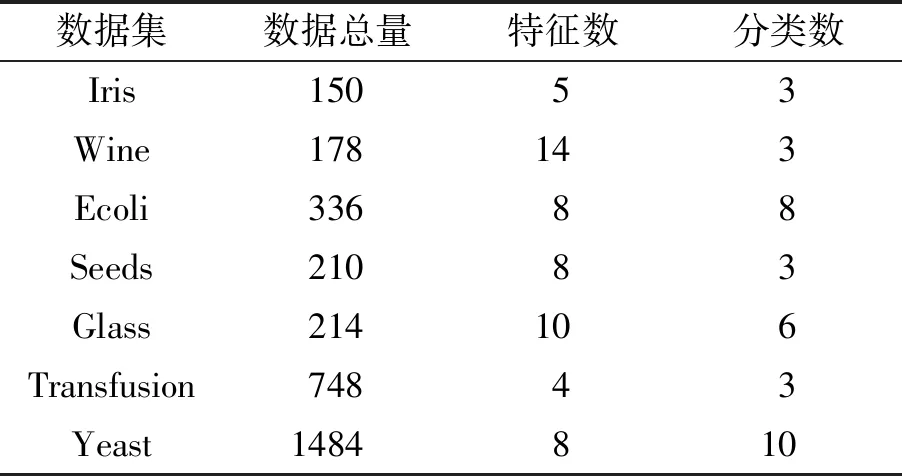
表3 分類數(shù)據(jù)集的詳細信息Tab.3 Information of classification datasets
表4列出了本文方法與其他改進的擴展置信規(guī)則庫(EBRB)方法的比較,指標是分類的精度.由于EBRB根據(jù)訓練集生成規(guī)則數(shù),所以EBRB的規(guī)則數(shù)等于訓練集的樣本數(shù)遠大于DBRB的規(guī)則數(shù).本文方法在5個數(shù)據(jù)集上都達到了第一名,在另外2個數(shù)據(jù)集上也達到第二名.這一結果驗證了本文所提方法的有效性,同時也表明本文所提出的方法在分類數(shù)據(jù)集應用上也具有較好的性能.
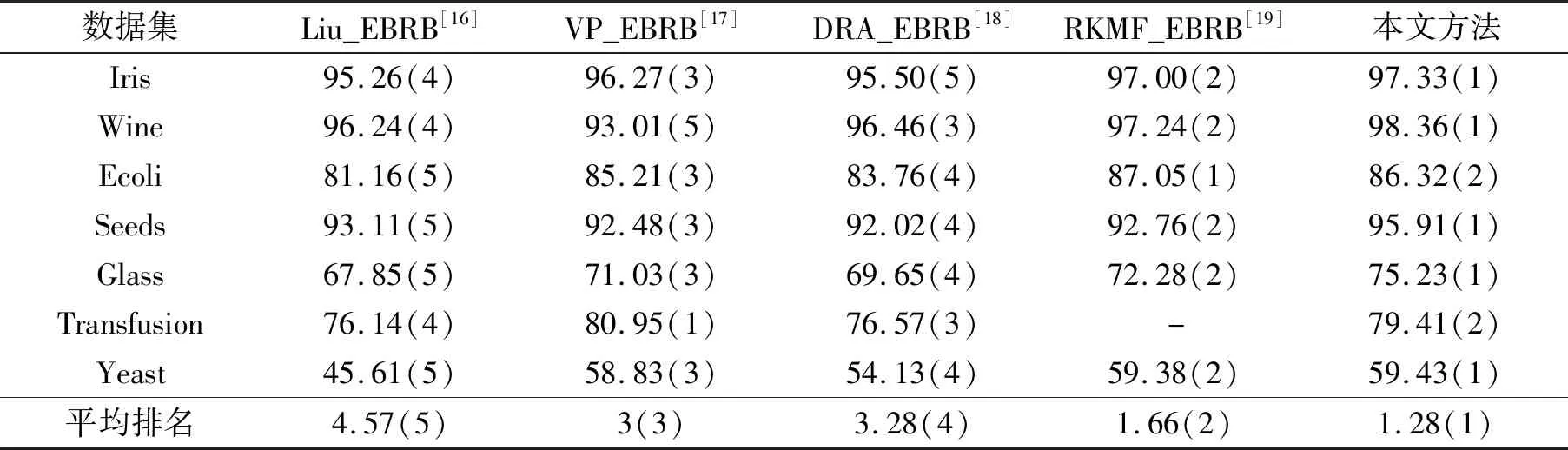
表4 與其他EBRB方法的比較Tab.4 Compare with other EBRB improvement methods
進一步將本文方法與其他傳統(tǒng)的機器學習方法進行比較,對比實驗結果為文獻[20-21]中的部分結果.表5列出了比較結果,指標是分類的精度.結果表明,本文所提出的方法在大部分數(shù)據(jù)集上的精度都是排在第一名,表明本文所提出的方法具有良好的性能.

表5 與其他機器學習方法的比較Tab.5 Comparison with other traditional machine learning methods
4 結語
針對BRB-DL模型參數(shù)優(yōu)化方法可移植性不足,應用效率低等問題,提出DBRB-DNN模型,并引入梯度下降算法對DBRB-DNN模型進行參數(shù)訓練;同時對模型中受約束的參數(shù)進行預處理,避免在應用梯度下降算法時構建困難和效率不高的問題.最后,將BRB-DNN模型應用在分類問題上,擴展模型的應用領域.本文算法是基于Python平臺實現(xiàn)的,可移植性更強.最后通過非線性函數(shù)的擬合實驗、北京空氣質量預測以及UCI上多個公共數(shù)據(jù)集的分類實驗,驗證所提出方法的有效性.不過本研究所選用的神經(jīng)網(wǎng)絡模型比較基礎以及所有實驗都是在規(guī)則完整的情況下進行的,沒有考慮到規(guī)則不完整的情況應該怎么處理,今后將針對這一問題進行更加深入的研究.
猜你喜歡
房地產(chǎn)導刊(2022年5期)2022-06-01 06:20:14
小獼猴智力畫刊(2022年3期)2022-03-29 01:09:42
建材發(fā)展導向(2021年12期)2021-07-22 08:06:48
建材發(fā)展導向(2021年7期)2021-07-16 07:07:52
數(shù)學小靈通(1-2年級)(2021年4期)2021-06-09 06:26:14
中學生數(shù)理化(高中版.高二數(shù)學)(2021年12期)2021-04-26 07:43:48
Coco薇(2017年11期)2018-01-03 20:59:57
暨南學報(哲學社會科學版)(2016年9期)2017-01-15 13:52:02
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
