基于信息增強的中文輿情文本情感分析*
2022-08-23 01:52:56裴貴軍
通信技術 2022年7期
魏 剛,裴貴軍,張 毅,張 麒
(1.成都融微軟件服務有限公司,四川 成都 610213;2.上海三零衛士信息安全有限公司,上海 200030)
0 引言
情感分析是自然語言處理中的經典任務,被廣泛應用在各行各業中,發揮了很大作用。目前,我國互聯網具有極高的民眾普及度,網絡成為民眾表達觀點的主要場所,而互聯網上信息龐大,無法使用人工的方法對海量輿情信息進行觀點分析。情感分析則可以對輿情文本進行自動分析,及時反饋民眾對于事件的情感傾向。
輿情文本情感分析屬于篇章級情感分析,其目的是對輸入文本自動分析出其整體所具有的正面或負面情感極性。篇章級情感分析可被視為文本二分類問題,類別標簽為正面和負面。雖然基于預訓練語言模型的方法在多個情感分析任務中取得了最佳的效果,但仍存在一些值得改進的地方,即沒有顯式地對情感極性信息進行建模,未能突出情感信息在情感分析中的重要作用。因此,本文提出一種基于情感信息增強的情感分析方法,結合預訓練模型的優點,同時顯式強調情感信息。實驗結果表明,基于情感信息增強的情感分析方法在公開數據集ChnSentiCorp及自建的中文輿情情感分析數據集上,均取得了明顯的效果提升。
1 相關工作
情感分析的研究由來已久,其方法可以總結概括為情感詞典的規則方法、統計機器學習方法及深度學習方法。
基于情感詞典的規則方法不需要訓練模型,僅制定判定規則即可,因而具有簡單、快捷、解釋性強的優點,對于情感強烈的文本效果較好。但其無法在進行情感判斷時,考慮文本語義的因素,且效果受限于情感詞典的規模和質量。雖然在實際應用中存在一些問題,但研究者長期以來一直繼續進行這方面的研究[1-2]。
統計機器學習方法首先需要人工設計特征,然后基于這些特征選用機器學習模型進行訓練和分類,這類方法的效果往往受特征的影響較大。該方法采用詞向量均值作為輸入文本的句向量表示,然后采用分類模型實現情感分類的任務,其中,支持向量機是其常采用的分類模型[3]。
深度學習方法不需要人工進行特征提取,神經網絡可以自動提取特征并進行分類,其效果優于基于特征工程的統計機器學習方法,其中,TextCNN是經典神經網絡方法[4]。近年來,預訓練語言模型技術快速發展,如生成式預訓練(Generative Pre-Training,GPT)模型、BERT 模型等[5-6],為情感分析任務帶來了較大的效果提升。基于預訓練語言模型的方法是目前情感分析的最佳方法。
預訓練語言模型泛指由多層Transformer 結構組成并提前經過大規模數據訓練的語言模型,預訓練語言模型的出現開啟了自然語言處理的新時代。基于Transformer 結構[7]的預訓練語言模型在多項自然語言處理任務中取得了良好的效果,且僅在預訓練語言模型后添加全連接層,就可以達到情感分類任務的最佳效果。
ERNIE 是非常具有代表性的預訓練語言模型,在2019 年由百度公司提出。該公司受BERT 掩碼策略的啟發,提出實體級別和短語級別的掩碼方式,這種掩碼策略更加符合中文的特點,在包括情感分類的5 項中文自然語言處理任務中,創造了當時的最好成績[8]。
除以上所列方法之外,許多研究者[9-12]也嘗試在不同類型文本的情感分析中使用融合的方法,例如預訓練語言模型結合深度學習的方法、增加注意力機制的方法等,這些方法都取得了不錯的成果,推進了情感分析技術的發展。
2 方 法
輿情文本中包括情感相關與情感無關部分,以情感詞和情感短語的形式出現的情感相關部分與文本情感極性高度相關,其他部分則是無關緊要的,甚至會對情感極性的判斷造成干擾。因此,本文將輸入文本中與情感極性相關的部分稱之為情感極性信息,并設計出了一種情感極性信息增強的情感分析模型,以達到顯式地突出情感極性信息重要性,提升情感分析效果的目的。
2.1 情感極性信息提取
情感極性信息由情感詞、修飾詞和否定詞構成。情感詞類型包括固定成語、形容詞、動詞、名詞、副詞、介詞及網絡產生的新詞匯[13],其常搭配修飾詞或否定詞以組合的方式出現或單獨出現。情感詞的組成分布如圖1 所示。修飾詞是對情感詞起修飾作用的詞匯,常為修飾程度的副詞,其可造成情感極性的加強或減弱,而否定詞的出現則會造成情感極性的反轉。
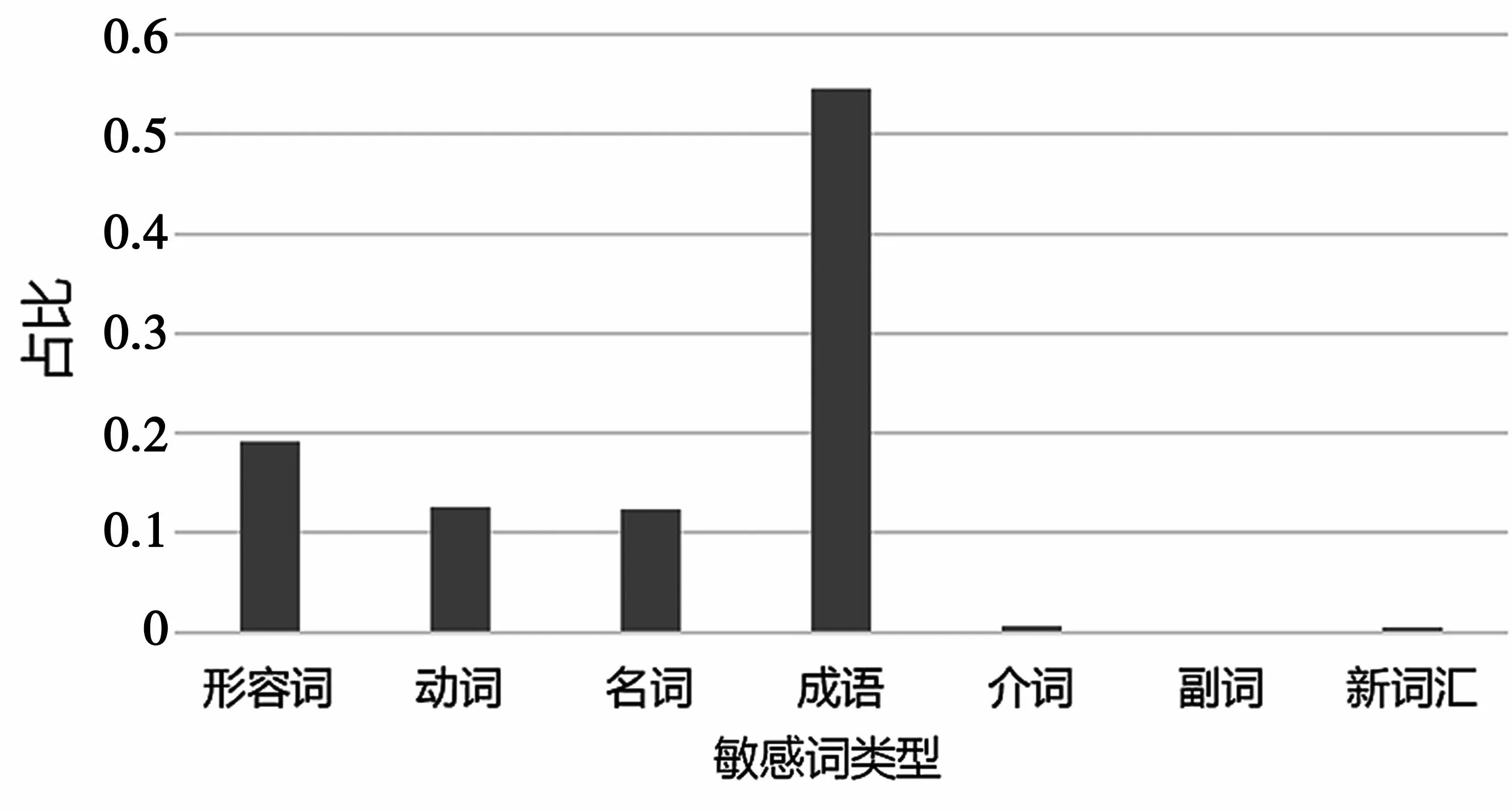
圖1 情感詞組成分布
情感極性信息通常具有多種組成結構,其結構不同也會造成情感極性的差異,如“不很好”與“很不好”。通常,否定詞加在程度副詞之前表示對程度的否定,情感極性不發生變化,極性程度則減輕;否定詞加在程度副詞之后表示對否定程度的加強,情感極性發生逆轉,極性程度則增加。
情感極性信息有以下6 種組成方式:單獨的情感詞;否定詞—情感詞組合;否定詞—否定詞—情感詞組合;否定詞—程度副詞—情感詞組合;程度副詞—情感詞組合;程度副詞—否定詞—情感詞組合。情感極性信息組合方式及示例如表1 所示。情感信息極性強度是衡量信息中所包含情感極性的程度,本文采用張成功等人[13]提出的情感極性強度計算方法。

表1 情感極性信息組合方式
本文研究所用的情感詞來自大連理工大學發布的中文情感詞匯本體庫[14],修飾詞采用藺璜等人[15]所總結的86 個修飾詞,否定詞采用郝雷紅等人[16-17]所總結出的否定詞。
考慮到情感信息的組成方式等因素,本文為了在輿情文本中提取極性信息,設計了情感極性信息提取算法。該算法首先對輸入中文輿情文本進行分詞,分詞方法采用百度公司的LAC 工具[18];其次遍歷分詞結果中的每個詞,并判斷是否為情感詞,若為情感詞則判斷情感詞周圍詞匯是否為修飾詞或否定詞,將修飾詞、否定詞及情感詞組成的情感信息提取出來,若情感詞單獨出現則將其視為情感極性信息提取出來;最后依據情感極性強度排名來提取出前3 位的情感極性信息。例如,在算法中輸入文本“這款手機性能不是很好”,得到情感極性信息“不是很好”;在算法中輸入文本“這里風景秀麗”,得到情感極性信息“秀麗”。情感極性信息提取算法的偽代碼如下:


2.2 模型設計
信息增強的情感分析模型(Enhanced Information Sentiment Analysis Model,EISA)結構如圖2 所示。與Transformer 類預訓練模型相比,EISA 有兩處不同:第一,增加了情感信息提取部分;第二,EISA預訓練部分輸入由之前的輿情文本變為情感信息+輿情文本。情感信息和輿情文本共同進入到預訓練模型中進行雙向交互,有利于增強模型中的情感信息。
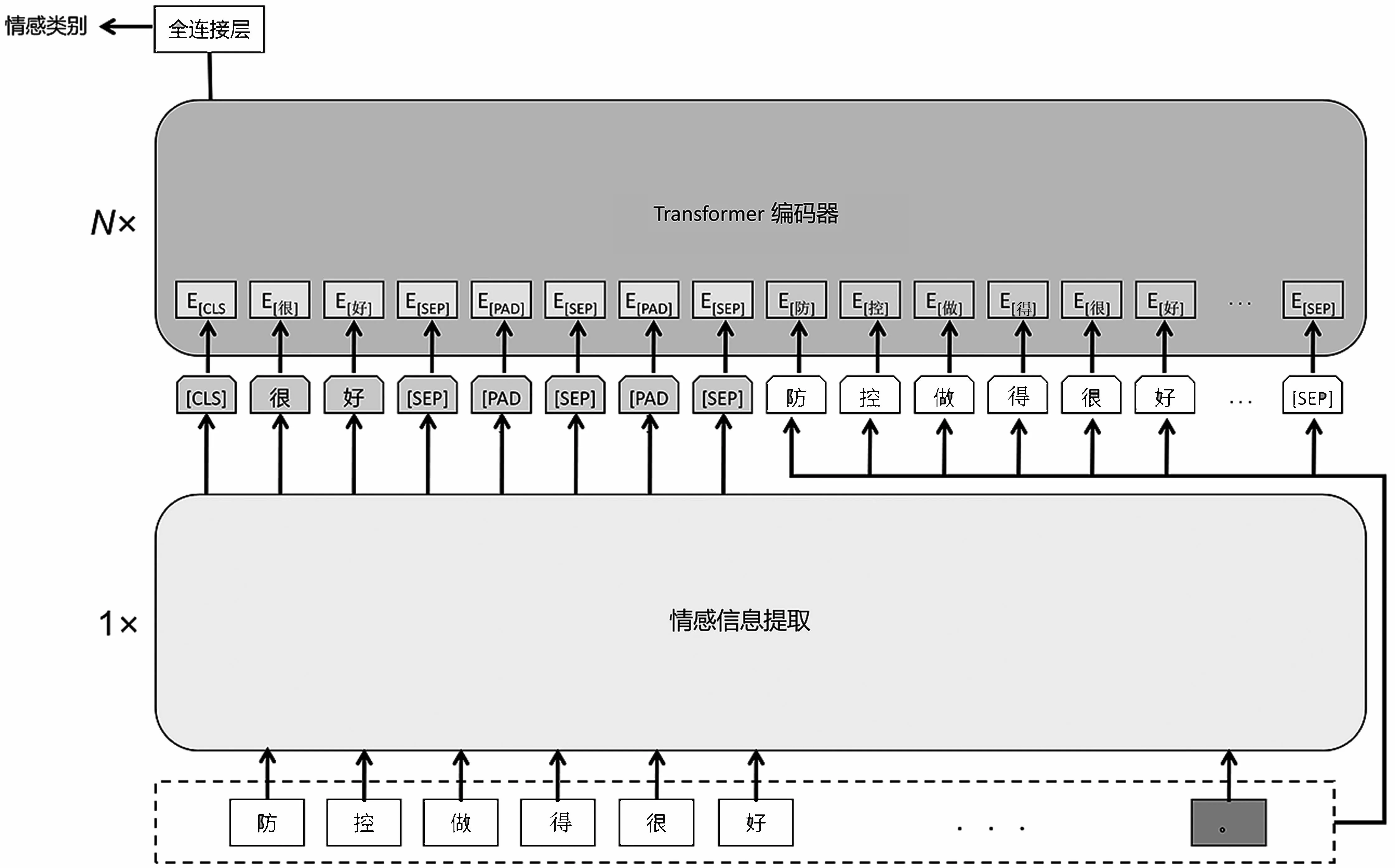
圖2 EISA 模型結構
預訓練部分由多層Transformer 編碼層組成,即Transformer 類預訓練語言模型,其可以有多種選擇,如GPT、BERT 和ERNIE 等,此處本文中采用中文版ERNIE 預訓練模型,由12 層Transformer 編碼層堆疊而成,采用實體級和短語級別的掩碼方式進行預訓練。
2.2.1 模型輸入
模型的輸入為中文輿情文本,經過情感信息提取模塊后,文本轉換為預訓練模塊的輸入,其形式為情感極性信息與輸入輿情文本的拼接。然后模型將拼接后的文本按字粒度進行切分,在文本開始處添加符號[CLS],在情感極性信息及文本結束處添加符號[SEP],情感極性信息之間使用英文逗號進行分割,即“[CLS]信息1,信息2,信息3[SEP]輿情文本[SEP]”。
2.2.2 輸入信息編碼
輸入信息的編碼由字編碼、塊編碼和位置編碼3 部分相加得到。塊編碼將情感極性信息及其前后的[CLS][SEP]設置為0,輿情文本及其后的[SEP]設置為1,如圖3 所示。
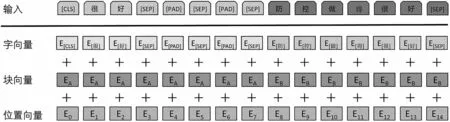
圖3 模型的輸入表示
位置編碼采用函數式的相對位置編碼[19]。之前研究者已經證實,在預訓練模型中,自注意力機制計算時起作用的是相對位置而非絕對位置。本文采用的位置編碼方式與相對位置的正弦函數有關,位置編碼的每個維度對應不同的正弦曲線,不同維度所對應的正弦函數的波長不同。相對位置編碼如式(1)、式(2)所示。
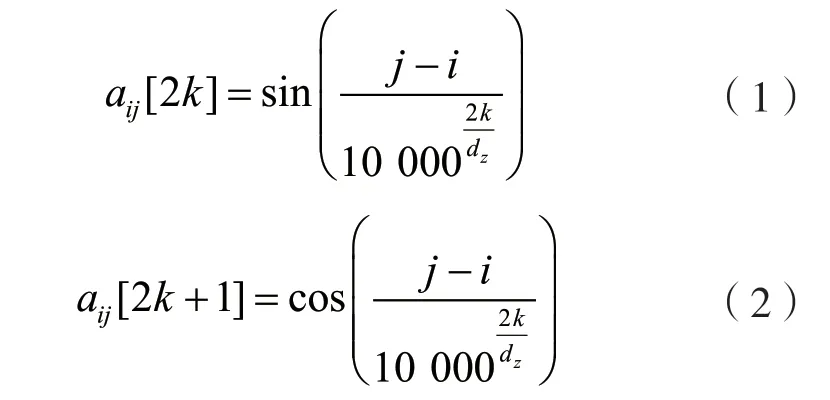
式中:k為維度;dz為隱藏狀態特征數量與注意力頭數量之比;j-i為相對位置。
3 實 驗
3.1 數據集
中文輿情情感數據集是本文所制作的數據集,是通過網絡爬蟲采集的民眾關于某些重大事件、政府政策的評論文本,經過數據清洗后進行正負面的人工標注后得到的數據集,共有1 萬條數據。該數據集任務是判斷評論文本屬于積極情感還是消極情感。按照8 ∶1 ∶1 的比例將數據集劃分為訓練集、驗證集與測試集。ChnSentiCorp 是公開的情感分析數據集,它包括酒店、圖書、電子產品多個領域的評論文本,共12 000 條,包含訓練集9 600 條、驗證集1 200 條、測試集1 200 條。該數據集任務是判斷數據集中每段文本屬于積極還是消極。數據集示例如表2 所示。

表2 中文輿情文本數據集和ChnSentiCorp 數據集示例
3.2 參數設置
本文采用中文版ERNIE 模型作為預訓練部分的模型進行實驗,其具有12 層Transformer 層,采用實體級和短語級別的掩碼方式進行預訓練。
實驗中,文本最大長度限制設置為256,批次大小設置為32,用[UNK]來表示未登錄詞,[PAD]用來對輸入文本進行補齊。采用Adam 作為優化算法,學習率設置為2E-5,動量參數分別設置為β1=0.9,β2=0.999,殘量ε=10-8。Dropout 概率的值設置為0.2。將訓練輪次設置為50,在每個輪次訓練結束后自動保存模型參數,并在驗證集上進行驗證,最后依據每個輪次的驗證結果選取最優的模型。
3.3 評價指標
情感分析任務可視為文本分類任務,本文采用精確率P、召回率R及F1 值進行評價。精確率是模型預測正確的正樣本數量占模型預測為正樣本數量的比例。召回率是模型預測正確的正樣本數量占真正的正樣本數量的比例。F1 值是精確率和召回率的調和平均值,可以更好地反映模型的真實效果。精確率P、召回率R及F1 值的計算方式為:

式中:TP為真正面情感數量;FP為假正面情感數量;FN為假負面情感數量。
3.4 實驗結果分析
在兩個情感分析數據集中,分別使用TextCNN、ERNIE 及本文所提出的EISA 模型進行情感分析實驗,實驗結果如表3 所示。可以看出,基于預訓練語言模型的模型(ERNIE 和EISA)相比于TextCNN,在情感分類任務上有很明顯的效果提升。基于情感信息增強的模型EISA 比ERNIE 預訓練語言模型的F1 值提升了1.1~1.7 個百分點,這說明信息增強機制在情感分析任務中取得了明顯的效果提升。

表3 模型結果對比
4 結語
本文提出的EISA 模型解決了預訓練語言模型在情感分類任務中,沒有顯式地對文本中重要情感極性信息進行建模的問題。所提模型在利用預訓練語言模型強大的語義表示能力的同時,也顯式地對情感信息進行建模,實現了情感極性信息的增強。
在兩個情感分類數據集上的實驗結果表明,基于信息增強的模型EISA 在情感分類任務中有良好的表現,與預訓練語言模型的情感分類方法相比也有明顯的效果提升,這說明模型能夠有效捕獲輿情文本中與情感分類任務高度相關的極性信息,進而提高模型情感分析的能力。
本文所采用的情感信息提取算法屬于基于規則的方法,有一定的局限性,未來可采用序列標注的方式進行情感信息自動提取,然后將情感信息與輸入文本拼接后輸入信息增強的情感分析模型中,進一步提高情感分析的準確性。
猜你喜歡
民用飛機設計與研究(2020年4期)2021-01-21 09:15:02
中國生殖健康(2020年5期)2021-01-18 02:59:48
北極光(2019年12期)2020-01-18 06:22:10
小太陽畫報(2019年10期)2019-11-04 02:57:59
制造技術與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:24
電子制作(2018年18期)2018-11-14 01:48:06
中國生殖健康(2018年5期)2018-11-06 07:15:40
山東工業技術(2016年15期)2016-12-01 05:31:22
小學教學參考(2015年20期)2016-01-15 08:44:38
