針對在線教育情感分析的數據擴充研究*
2022-08-23 06:49:08黃偉強梁韜文楊海華
網絡安全與數據管理 2022年7期
黃偉強,劉 海,梁韜文,楊海華
(1.華南師范大學 網絡中心,廣東 廣州 510631;2.華南師范大學 計算機學院,廣東 廣州 510631)
0 引言
隨著信息技術的飛速發展,在線教育逐漸興起,越來越多的人在在線教育課程中留下了有價值的評論,通過對這些評論進行情感分析可以達到多方面的目的,如分析學生對課程的滿意度、調查老師授課水平、挖掘課程質量等。
情感分析(Sentiment Analysis),又稱為情感傾向性分析[1],目的是找出文本中情感的正負性,如正面或負面、積極或消極,并且把這種正負性數值化,以百分比或者正負值的方式表現出來。情感分析的研究方法大致可以分為兩種:一是基于情感詞典的情感分析[2],主要通過建立情感詞典或領域詞典及通過文本中帶有極性的情感詞進行計算來獲取文本的極性,由于依賴于情感詞典,存在覆蓋率不足等缺點;二是基于機器學習的情感分析,包括監督學習、無監督學習和半監督學習三種方法,其中與監督學習和無監督學習相比,半監督學習通過少量標注數據和大量無標注數據進行識別,既不用對所有的數據進行標注,也不依賴先驗經驗,有較好的實用性,從而被許多學者應用在情感分析問題上,如陳珂等[3]利用基于分類器集成的self-training方法進行情感分析研究,使用少量標注樣本和大量未標注樣本來進行情感分析訓練,準確率達86%。
數據擴充[4]是一種結合機器學習使用的方法,在訓練樣本不足的情況下,可使模型訓練更好地擬合,通過與半監督的方法相結合,可達到標注少量數據以擴充至大量訓練數據的效果。數據擴充方法目前已被用于圖像、交通、醫療等領域[5-7],目前主流的數據擴充方法有圖像翻轉、隨機噪聲、標簽傳播等[8]。
情感分析目前已被應用于如電影評論、書籍評論、微博短評等多個領域,但在在線教育課程評論領域的應用還較缺乏,把情感分析應用在在線教育課程評論上存在著各種挑戰,如評論數據的獲取、評論數據的標注等。為了解決以上問題,本文借鑒半監督學習的方法,提出基于聚類分析的文本數據擴充方法:對少量關鍵數據進行標注,并通過聚類分析獲得大量已標注數據。在目前主流在線教育平臺爬取的569 970條課程評論中選取1 000條關鍵數據進行標注并使用本文數據擴充方法擴充至10萬條標注數據,分別利用SVM[9]、RandomForest[10]、AdaBoost[11]、GradientBoost[12]和CNN模型對標注數據進行訓練,實驗表明,與目前主流的LabelSpreading算法相比,本文的數據擴充方法均有準確率上的優勢。
1 課程評論情感分析的流程
在線課程評論情感分析的流程如圖1所示。

圖1 在線課程評論情感分析流程
(1)課程評論獲取與向量化:利用爬蟲爬取在線教育平臺課程評論數據,把文本的課程評論數據分詞及詞向量轉化后,再組合詞向量得到向量化的課程評論數據;
(2)主觀評論提取:手工對少量數據進行主客觀標注后,經聚類分析把課程評論分為主觀評論和客觀評論兩類,保留主觀評論并移除客觀評論;
(3)評論情感值計算與標注:手工對少量關鍵數據進行正負性標注后,利用聚類分析計算主觀評論的情感值,利用情感值對數據進行標注,以達到擴充數據的目的;
(4)情感分析模型訓練:分別利用CNN、SVM、RandomForest、AdaBoost、GradientBoost模型和前三步得到的大量標注數據進行課程評論情感分析模型訓練,并對各模型的課程評論情感分析準確率進行對比。
2 課程評論獲取與向量化
在課程評論獲取操作中,通過爬取“中國大學MOOC”[13]、“網易云課堂”[14]和“礪儒云課堂”[15]共10 037門課程,獲取共569 970條課程評論數據用于制作數據集。獲取的課程評論大多為數據長度在10~40字數的中文短評,具體數據長度的數量分布如圖2所示。

圖2 不同長度數據的數量分布
在課程評論向量化操作中,首先對爬取的課程評論進行分詞操作:基于Python環境下的中文分詞組件“jieba”對數據集課程評論進行分詞,為了支持含特殊字符的表情符的分詞操作,對“jieba”組件中匹配關鍵字的正則表達式及相關代碼進行了修改,使其能夠識別組成表情符的空格及特殊字符,并通過增加自定義表情符字典的方式,使其對表情符的分詞提供支持。
然后,對課程評論進行字典生成和向量生成:利用自然語言處理Python庫“gensim”的內置模塊“corpora”中的“Dictionary”方法,對分詞后的文本進行字典生成,并利用“gensim”中內置的詞轉向量算法“Word2Vec”對分詞后的文本進行詞到向量的轉換。由于字詞的重要性隨著其在文件中出現的次數成正比增加[16],為了增強文本向量表達的準確性,利用tf-idf向量[17]作為權值,對詞向量進行加權平均后得到文本向量:
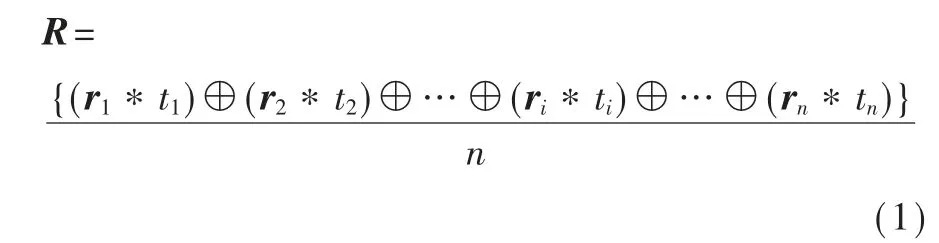
其中:⊕表示的是詞向量的拼接操作,本文使用的是向量的加法;ri表示文本各詞的向量;R表示文本向量;n表示該文本含有的詞的數量;ti表示詞的tf-idf權值。
課程評論向量化操作中使用的詞向量維度為128維,詞向量訓練規模為268 GB的中文語料,滑動窗口設為20×120。
3 基于聚類的數據擴充方法
3.1 算法表示
基于以下兩個假設,使用基于聚類分析[18-19]的方法計算各課程評論的情感值,以實現課程評論的正負性標注:
(1)在文本向量空間中距離相近的2個文本正負性質相近;
(2)在文本向量空間中2個文本距離越近,其正負性質越相近。
借鑒半監督訓練的方法,通過標記少量的數據來對整個數據集進行情感值的計算,把標記的數據作為情感值計算的標桿,基于以上兩個假設對整個數據集進行聚類操作。
使用第2節中向量化后的課程評論數據作為數據集T,設ti∈T,使用Mi來表示ti的情感值。Mi為正則表示評論ti偏向正面,Mi越大表示正面性越強;Mi為負則表示評論ti偏向負面,Mi越小表示負面性越強。在T中選取適量課程評論數據作為初始數據集Tj,對任意tj∈Tj,對tj手工標記mj:若該評論為正面評論則標記mj=1,若該文本為中性評論則標記mj=0,若該文本為負面評論則標記mj=-1。設正整數常量Minit(經本文實驗,Minit=100為一個較合適的取值),用于對Mi進行初始化。對于每個ti,設置其Mi值:

設dij為評論ti與評論tj在向量空間的距離;設距離dfar,若dij≤dfar,則表示ti與tj的正負性質一樣(經本文實驗,dfar取除雜后向量空間中各評論數據平均距離的1/8為較合適的值);設距離dclose,若dij≤dclose, 則表示ti與tj非常接近 (經本文實驗,取為較合適的值)。在每一輪聚類中對于新標記的課程評論數據集Tk(初始時Tk=Tj)中的每一條評論tk,按下式更新其附近課程評論集合Tl中每一條評論tl的Ml值:

式(3)中表述了更新tl情感值的三種情況(見圖3):

圖3 三種更新情感值的情況


3.2 實際例子
設tk被手工標注為mk,t1、t2、t3、t4為tk附近的課程評論,對于算法中每一輪聚類過程及式(3)的更新過程,以下給出兩個實際例子進行說明。


表1 實際例子1


表2 實際例子2
3.3 情感值計算實驗結果
使用手工標注約800條課程評論數據進行正負性聚類用于課程評論的情感值計算,經主客觀聚類后提取的主觀課程評論數據通過PCA[20]降維操作可視化后的分布情況見圖4。

圖4 文本在正負性向量空間的分布情況
聚類后的部分評論及對應情感值Mi見表3。

表3 正負性分析部分結果
情感值計算的準確率使用基于古典概型[21]的方法推算得出:通過另外隨機手工標注課程評論數據并剔除Mi=0的評論,直到最終剩下n條課程評論,在n條課程評論中統計標注與聚類結果相符(即另外標注結果與實驗結果同為正面或同為負面)的數據量k,使用下式推算實驗準確率:

其中,P(A)為標注與聚類結果相符的事件A發生的概率,即推算出的準確率。本文實驗使用100條課程評論數據用作統計,即取n=100;統計出100條數據中標注與聚類結果相符的數據有86條,即k=86。基于上述計算,推算出準確率達86%。
在完成情感值計算的課程評論中,本文選取情感值最大的5萬條正面評論及情感值最小的5萬條負面評論共10萬條課程評論用于下文情感分析實驗。
4 基于聚類的主觀數據提取
使用3.1節中算法對向量化的569 970條課程評論數據進行聚類分析及主客觀性質計算,通過手工標注約1 000條課程評論數據進行主客觀聚類,由文本在向量空間[22]通過PCA降維操作后的分布情況(圖5)可知:主觀評論數據及客觀評論數據已經在幾個地方分別聚集成團,但由于手工標注的課程評論數量有所不足,使得部分數據不能參與聚類,從而造成圖中仍有部分中性數據。

圖5 文本在主客觀向量空間的分布情況
聚類后的部分評論及對應主客觀性質Mi見表4。

表4 主客觀分析部分結果
通過另外手工標注的100條課程評論數據中有81條標注與聚類結果相符(即另外標注結果與實驗結果同為主觀或同為客觀),即n=100,k=81,由式(4)可推算準確率達81%。
剔除干擾評論數據、中性評論數據及客觀評論數據后,本文最終篩選出23萬主觀課程評論用于情感值的計算及正負性標注。
5 情感預測分析
5.1 情感分析方法及參數設置
采用3.3節篩選出的10萬條課程評論數據進行情感預測分析實驗,隨機取其中90%作為訓練集,其余10%作為測試集,分別采用基于機器學習庫“sklearn”的SVM模型、RandomForest模型、AdaBoost模型、GradientBoost模型和基于TensorFlow的卷積神經網絡(CNN)模型進行情感預測分析。支持向量機(SVM)模型是一種在分類與回歸中分析數據的學習模型,SVM模型把數據映射為空間中的點,使每一類數據被盡可能寬地間隔分開;隨機森林(RandomForest)模型是一個包含多個決策樹的分類模型,其通過平均多個深決策樹以降低方差;AdaBoost模型是一種自適應的迭代模型,其在每一輪中加入一個新的弱分類器,以減少分類的錯誤率;梯度提升(GradientBoost)模型是一種用于回歸和分類問題的機器學習模型,其以分階段的方式構建模型,通過允許對任意可微分損失函數進行優化實現對一般提升方法的推廣;CNN模型是一種前饋神經網絡模型,它的人工神經元可以響應一部分覆蓋范圍內的周圍單元,近年來在圖像處理和語音處理上取得不少突破性進展,也有被應用于情感分析領域。
各模型參數設置見表5。

表5 模型訓練參數設置
本文實驗設備配置為Inter?CoreTMi7-9750H CPU和NVIDIA GeForce GTX 1650顯卡,系統環境為64位Windows 10系統,Python版本3.6.8。
5.2 模型訓練結果
對比sklearn的Label Spreading半監督學習算法,本文基于聚類分析的文本數據擴充算法在5個模型的情感分析準確率上均有明顯優勢,在SVM模型上準確率相差最大,在CNN模型上準確率相差最小。其中進行LabelSpreading實驗時,kernel選擇KNN,其他參數保持默認,使用標記為3.3節的手工標注,數據集為569 970條課程評論數據向量,最終隨機篩選出10萬條課程評論數據進行情感預測分析實驗。
在5個機器學習模型的準確率對比上,CNN模型的準確率最高(使用基于聚類分析的文本數據擴充算法時準確率達96.5%,使用LabelSpreading算法時準確率達84.47%);在使用基于聚類分析的文本數據擴充算法時,各模型準確率均高于89%。詳細對比見圖6。

圖6 本文方法與LabelSpreading在5種模型的準確率對比
準確率最高的CNN模型在訓練時的loss和準確率隨epoch的變化見圖7:隨著epoch的增加,loss逐漸減小,準確率逐漸提高,模型訓練在約第70個epoch收斂;loss最低值為0.012 6;準確率最高值為97.01%,最終準確率為96.50%。
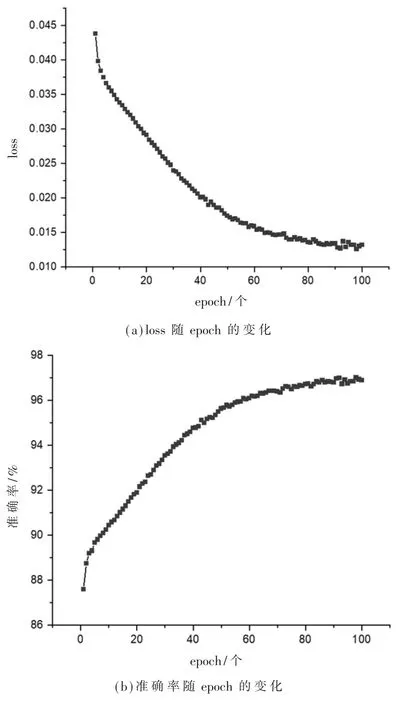
圖7 loss及準確率隨epoch變化圖
6 結論
本文針對情感分析應用在在線教育領域上的數據標注問題,提出了基于聚類分析的數據擴充方法,手工標注少量關鍵數據以擴充至大量標注數據。利用該方法擴充的數據,在多個主流機器學習模型和CNN模型上進行情感預測分析訓練,結果表明,經過擴充后的數據在各模型上的準確率均達89%以上,其中在CNN模型準確率達96.5%。使用本文方法擴充的數據在各模型上得到的準確率皆優于目前主流的LabelSpreading數據擴充算法的準確率。
猜你喜歡
民用飛機設計與研究(2020年4期)2021-01-21 09:15:02
中國生殖健康(2020年5期)2021-01-18 02:59:48
北極光(2019年12期)2020-01-18 06:22:10
小太陽畫報(2019年10期)2019-11-04 02:57:59
制造技術與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:24
電子制作(2018年18期)2018-11-14 01:48:06
中國生殖健康(2018年5期)2018-11-06 07:15:40
山東工業技術(2016年15期)2016-12-01 05:31:22
小學教學參考(2015年20期)2016-01-15 08:44:38
