面向互聯(lián)網(wǎng)醫(yī)院的智能語音交互系統(tǒng)的設(shè)計
2022-08-23 05:04:00江蘇大學(xué)附屬醫(yī)院沈安娜
數(shù)字技術(shù)與應(yīng)用 2022年8期
江蘇大學(xué)附屬醫(yī)院 沈安娜
針對互聯(lián)網(wǎng)醫(yī)院線上診療服務(wù),緩解醫(yī)療機構(gòu)大量人力投入的壓力,解決線上診療過程中患者服務(wù)非標準化的問題。構(gòu)建醫(yī)療領(lǐng)域語料庫,采用語義識別、意圖識別、問答匹配等技術(shù),并對接業(yè)務(wù)數(shù)據(jù)庫,利用大數(shù)據(jù)相關(guān)技術(shù),搭建智能語音交互系統(tǒng),實現(xiàn)對患者基本問題的答復(fù),擴充線上診療的應(yīng)用場景。針對患者,在線上就診時可減少排隊時間,獲得標準化的實時反饋;針對醫(yī)護,在線上接診前減少無效對話,精準獲得更多患者信息。面向互聯(lián)網(wǎng)醫(yī)院的智能語音交互系統(tǒng)的應(yīng)用,可有效提高醫(yī)護患協(xié)同程度,提升醫(yī)院智慧服務(wù)水平。
1 面向互聯(lián)網(wǎng)醫(yī)院的智能語音交互系統(tǒng)的可行性
近年來,人工智能技術(shù)已在各行各業(yè)被廣泛應(yīng)用,其中智能語音技術(shù)作為人工智能應(yīng)用最成熟的技術(shù)之一,在家居、車載、可穿戴設(shè)備等領(lǐng)域有了迅猛的發(fā)展。反觀醫(yī)療行業(yè),智能語音技術(shù)的應(yīng)用起步較晚,還沒有具備醫(yī)療領(lǐng)域知識基礎(chǔ)和開發(fā)技術(shù)的智能語音產(chǎn)品。
根據(jù)國家衛(wèi)健委發(fā)布的《公立醫(yī)院高質(zhì)量發(fā)展促進行動(2021-2025年)》,要建設(shè)電子病歷、智慧服務(wù)、智慧管理“三位一體”的智慧醫(yī)院信息系統(tǒng),要提高醫(yī)療服務(wù)的智慧化、個性化水平。目前大部分三甲醫(yī)院已經(jīng)建設(shè)了互聯(lián)網(wǎng)醫(yī)院,打通覆蓋了診前、診中、診后的線上線下一體化醫(yī)療服務(wù)全流程,成為線下醫(yī)療的有效補充。在疫情防控期間,慢病復(fù)診、在線續(xù)方、藥師咨詢、護理咨詢等線上診療新功能的用戶使用量日趨增加,醫(yī)療機構(gòu)隨之投入的人力也成倍增加。而智能語音交互系統(tǒng)的應(yīng)用,能在線上就診全流程有效緩解人力投入,同時解決線上診療中患者服務(wù)非標準化的問題。
通過構(gòu)建面向互聯(lián)網(wǎng)醫(yī)院的醫(yī)療領(lǐng)域語料庫,利用語義識別、意圖識別、問答匹配等技術(shù),智能語音交互系統(tǒng)能夠快速學(xué)習(xí)相關(guān)內(nèi)容,并在短時間內(nèi)具備一線分診人員的業(yè)務(wù)素養(yǎng),實現(xiàn)對患者基本問題的答復(fù)。不僅如此,通過結(jié)合數(shù)據(jù)庫對接、查詢語句解析等技術(shù)和開源構(gòu)架,系統(tǒng)能夠擴充線上就診的應(yīng)用場景,提升整體醫(yī)護患協(xié)同水平,提高患者在互聯(lián)網(wǎng)醫(yī)院的就診滿意度。
2 面向互聯(lián)網(wǎng)醫(yī)院的智能語音交互系統(tǒng)的總體設(shè)計
2.1 系統(tǒng)技術(shù)架構(gòu)
面向互聯(lián)網(wǎng)醫(yī)院的智能語音交互系統(tǒng)對多數(shù)據(jù)源進行數(shù)據(jù)處理和數(shù)據(jù)存儲,通過構(gòu)建醫(yī)療領(lǐng)域的對話規(guī)則和知識體系,將人機語音交互應(yīng)用于語音咨詢、語音分診、語音導(dǎo)醫(yī)等互聯(lián)網(wǎng)醫(yī)院線上診療場景,其技術(shù)架構(gòu)如圖1所示。

圖1 系統(tǒng)技術(shù)架構(gòu)圖Fig.1 System technical architecture
(1)數(shù)據(jù)源對接實時對話、HIS數(shù)據(jù)庫、LIS數(shù)據(jù)庫、EMR數(shù)據(jù)庫等獨立數(shù)據(jù)庫,支持實時數(shù)據(jù)、邊緣數(shù)據(jù)、設(shè)備數(shù)據(jù)、業(yè)務(wù)數(shù)據(jù)的獨立運行,并通過標準API開發(fā)兼容多種數(shù)據(jù)庫數(shù)據(jù)的交互與存儲。
(2)數(shù)據(jù)層首先將問答庫與語料庫分類,確保單句、節(jié)點、屬性、關(guān)系等資源的分布式存儲,在語料處理分析階段進行分詞、分類、詞性標注、詞法分析工作,同時經(jīng)過語料庫的不斷建立,提升數(shù)據(jù)的清洗能力,增強語音識別錯誤的檢查能力;數(shù)據(jù)處理時會通資源調(diào)度實現(xiàn)計算資源的統(tǒng)籌,并對語義識別及模糊匹配提供運算支持,保障并發(fā)量。
(3)技術(shù)層主要包含了規(guī)則體系、知識推理、知識體系、答案合成四大引擎。規(guī)則體系實現(xiàn)對患者數(shù)據(jù)訪問的隔離以及規(guī)則的分發(fā)服務(wù),并對現(xiàn)有規(guī)則進行邏輯校驗和學(xué)習(xí)補全;知識推理負責(zé)對患者提問的實體識別以及意圖識別;知識體系涵蓋了語料庫、規(guī)則庫、知識庫等多樣化知識數(shù)據(jù),通過每天的訓(xùn)練發(fā)現(xiàn)現(xiàn)有系統(tǒng)的不足,并通過人工審核后完成發(fā)布;答案合成負責(zé)大量數(shù)據(jù)的處理以及答案的語音合成,支持醫(yī)護與患者交互的最后一個環(huán)節(jié)。
(4)應(yīng)用層為患者提供包括語音咨詢、語音分診、語音導(dǎo)醫(yī)在內(nèi)的多類標準操作頁面、標準API接口及SDK,滿足患者對互聯(lián)網(wǎng)醫(yī)院線上診療的多樣化需求。
2.2 系統(tǒng)應(yīng)答邏輯
患者在互聯(lián)網(wǎng)醫(yī)院發(fā)起應(yīng)答需求后,系統(tǒng)需要經(jīng)過終端身份、語音處理、自然語言處理、對話管理、答案生成等5級計算引擎的循環(huán)才可完成應(yīng)答,如圖2所示。
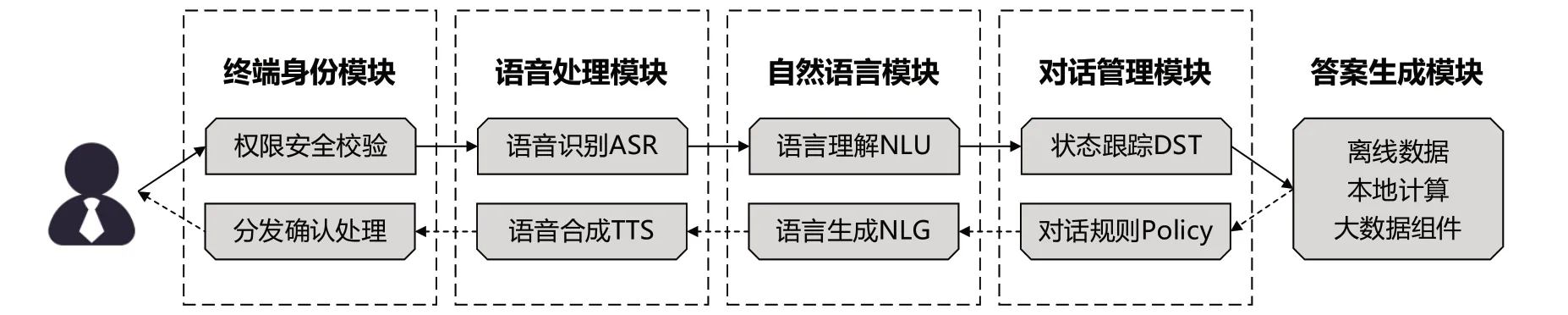
圖2 系統(tǒng)應(yīng)答邏輯圖Fig.2 System response logic diagram
其中終端身份模塊用以進行安全控制,語音處理模塊負責(zé)語音的分解與合成,自然語言處理模塊完成實體識別和意圖識別,對話管理模塊通過規(guī)則設(shè)置支持單輪/多輪兩類對話模式的切換,答案生成模塊集成大數(shù)據(jù)組件分析功能,并最大化優(yōu)化用戶使用性能,縮短應(yīng)答等待時間。
(1)權(quán)限安全校驗:識別患者身份,進行權(quán)限分配,指定連接數(shù)據(jù)庫對象、離線數(shù)據(jù)加載包、本地計算規(guī)則庫等。
(2)語音識別ASR:收集語音信息,完成分詞、向量轉(zhuǎn)化。
(3)語言理解NLU:完成實體和意圖識別,向量匹配。
(4)狀態(tài)跟蹤DST:在對話的每一輪次對患者的目標進行預(yù)估,管理每個回合的輸入和對話歷史,輸出當前對話狀態(tài)。
(5)分布式計算:對離線數(shù)據(jù)和離線規(guī)則的組合直接反饋;支持少量存儲資源占用的問答本地化,降低對傳輸、云計算的占用;對大數(shù)據(jù)分析組件進行調(diào)用,支持彈性存儲和計算。
(6)對話規(guī)則Policy:針對每一輪的場景以及綜合對話狀態(tài)設(shè)置不同的對話策略,從而提高系統(tǒng)的問答效果。
(7)語言生成NLG:將結(jié)構(gòu)化數(shù)據(jù)轉(zhuǎn)化為自然語言。
(8)語音合成TTS:將文本信息合成為可播放的語音內(nèi)容。
(9)分發(fā)確認處理:將語音內(nèi)容發(fā)送給對應(yīng)的患者,并等待患者下一次提問。
3 系統(tǒng)主要業(yè)務(wù)流程
面向互聯(lián)網(wǎng)醫(yī)院的智能語音交互系統(tǒng)在實現(xiàn)語音咨詢、語音分診、語音導(dǎo)醫(yī)等線上診療功能時,每一次人機對話都需經(jīng)過身份識別、語義理解、對話管理、答案生成、答案分發(fā)等五大主要業(yè)務(wù)流程。
3.1 身份識別
通過對患者的登錄名以及密碼進行初步校驗,向患者授權(quán)唯一Token值,確定患者所在的服務(wù)器集群,并依據(jù)賬戶類型分配不同類型的數(shù)據(jù)庫節(jié)點,將實時數(shù)據(jù)庫與離線數(shù)據(jù)庫剝離,增強對數(shù)據(jù)的利用能力。通過離線日志分析手段,依據(jù)患者歷史提問習(xí)慣,對每個患者形成一份知識庫,記錄患者常問問題以及使用習(xí)慣,從而為每個患者載入部分重要歷史數(shù)據(jù),減少應(yīng)答過程中產(chǎn)生的延遲以及計算損耗。身份識別流程如圖3所示。

圖3 身份識別流程Fig.3 Identification process
3.2 語義理解
通過對系統(tǒng)常用語料庫及醫(yī)療語料庫的深度學(xué)習(xí),實現(xiàn)啟發(fā)式規(guī)則算法的優(yōu)化以及用于快速檢索的字典樹搭建,將實體與規(guī)則及字典樹進行相關(guān)性檢驗并將初步檢驗結(jié)果作為模型匹配的輸入值,與現(xiàn)有模板進行比對從而判定本輪對話患者的真實意圖。當某種詞向量頻繁出現(xiàn)且無法匹配到規(guī)則/字典樹時,系統(tǒng)的機器學(xué)習(xí)函數(shù)會被激活,收集過去一段時間的詞向量與規(guī)則匹配的情況,并適當擴充當前規(guī)則及字典樹包含的模型庫,從而提升規(guī)則及字典樹的匹配能力。語義理解流程如圖4所示。
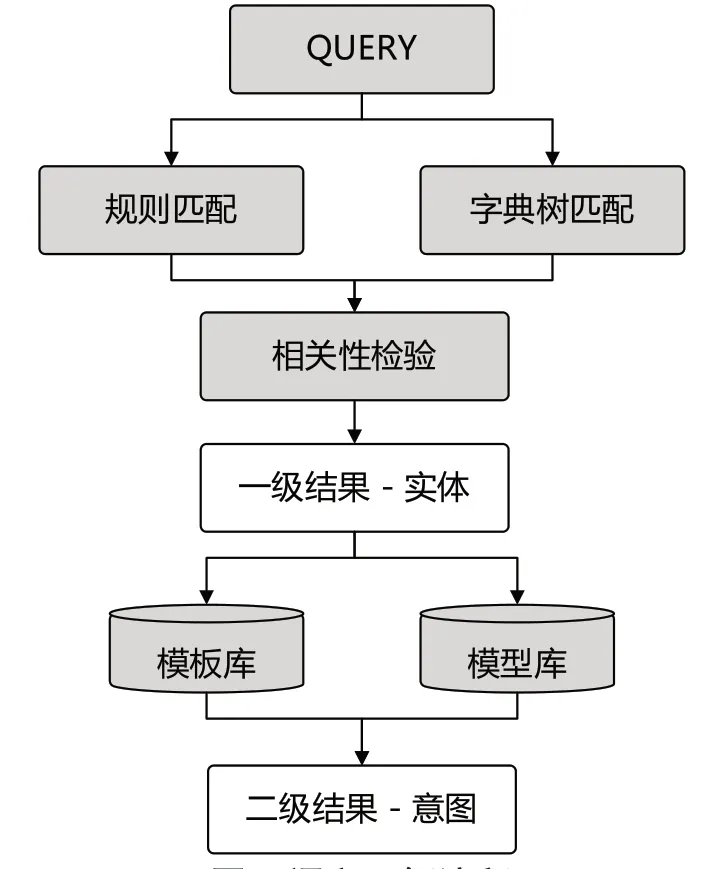
圖4 語義理解流程Fig.4 Semantic comprehension process
3.3 對話管理
通過系統(tǒng)的對話管理機制,幫助患者完善需求內(nèi)容,澄清/確認需求中不明確的內(nèi)容,實現(xiàn)對患者對話全生命周期的管理。當患者首次問題的實體識別、意圖識別結(jié)果能夠較好的匹配當前的答案庫模型,則標記當前對話狀態(tài)為結(jié)束,同時返回答案內(nèi)容。如果首輪提問無法匹配到合適的結(jié)果,則記錄當前對話狀態(tài)為進行中,結(jié)合當前場景與患者意圖自動生成引導(dǎo)性結(jié)果進入下一輪對話,直到系統(tǒng)發(fā)現(xiàn)答案結(jié)束當前會話。由于多輪對話可能存在某一輪患者口誤、表述有誤等導(dǎo)致的異常情況。為了保證系統(tǒng)不會直接結(jié)束對話過程,系統(tǒng)擁有自檢機制,對出現(xiàn)缺失等異常的對話進行場景恢復(fù)和患者意圖復(fù)盤,充分保證對話的有序流暢。對話管理流程如圖5所示。

圖5 對話管理流程Fig.5 Dialogue management process
3.4 答案生成
上級結(jié)果作為本級輸入,系統(tǒng)會對輸入進行分詞處理和意圖識別,通過知識庫轉(zhuǎn)化生成對應(yīng)查詢表達式并從本地數(shù)據(jù)優(yōu)先遴選資源,依據(jù)數(shù)據(jù)和表達式的相關(guān)性來決定是否調(diào)用大數(shù)據(jù)組件進行服務(wù)器端的計算。對計算結(jié)果進行有效性檢驗,無效答案則尋求臨近匹配問題,直至符合有效性目標,返回最優(yōu)解。答案生成流程如圖6所示。

圖6 答案生成流程Fig.6 Answer generating process
3.5 答案分發(fā)
為保證并發(fā)情況下的系統(tǒng)效能,患者提問得到的結(jié)果會通過分發(fā)器分發(fā)到用戶終端,如果分發(fā)失敗則間隔一段時間進行輪詢并檢測患者當前狀態(tài),若患者存在設(shè)備/賬戶/網(wǎng)絡(luò)等各種異常情況,則將問題以及結(jié)果數(shù)據(jù)緩存至本地或云端,當患者下一次登錄時恢復(fù),避免了異常情況導(dǎo)致的數(shù)據(jù)丟失。若任意一輪詢檢測患者狀態(tài)恢復(fù)正常,則開始斷點續(xù)傳,保證結(jié)果的送達率。答案分發(fā)流程如圖7所示。
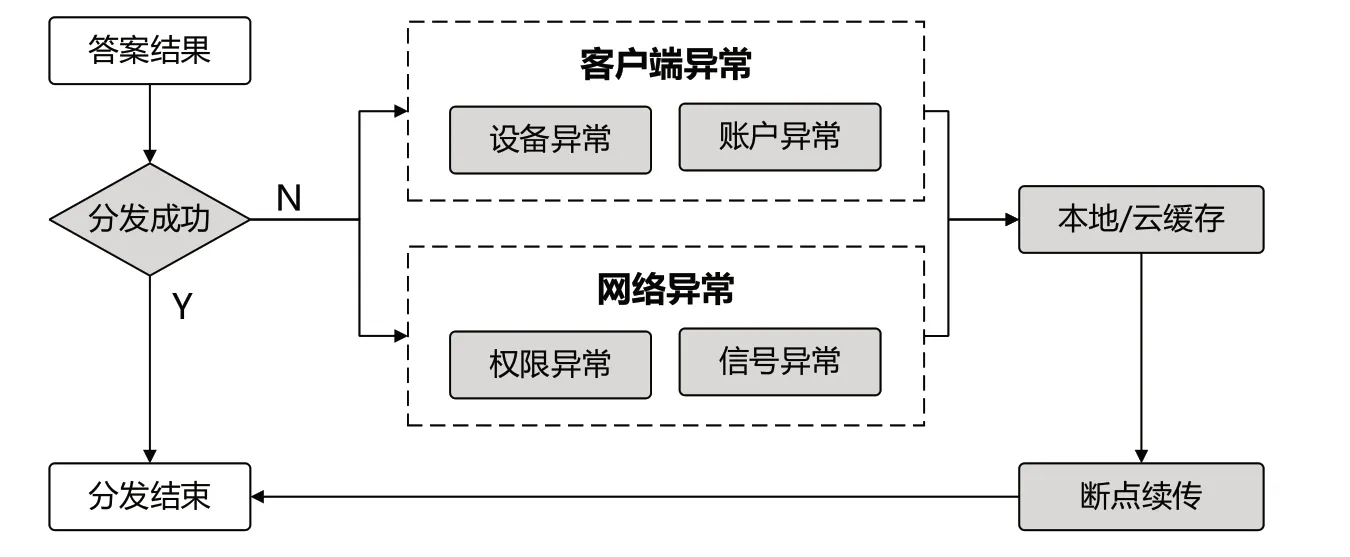
圖7 答案分發(fā)流程Fig.7 Answer distribution process
4 系統(tǒng)關(guān)鍵技術(shù)
4.1 有醫(yī)療特征的語料庫學(xué)習(xí)模型
傳統(tǒng)語料庫具有無特定語料收集規(guī)則、原生語料資源多等特征,單個語料庫的大小均在1GB以上,包含上百萬中文字符和數(shù)十萬種語句,能夠充分發(fā)揮機器學(xué)習(xí)、深度學(xué)習(xí)模型的可擴展能力,大規(guī)模訓(xùn)練結(jié)果可靠性更高。
相比于傳統(tǒng)語料庫,面向互聯(lián)網(wǎng)醫(yī)院的語料庫具有明顯的醫(yī)療特征,且缺乏開源、廣泛的資源基礎(chǔ),無法實現(xiàn)海量數(shù)據(jù)訓(xùn)練的算法要求,需要找到一種適合小型語料庫的預(yù)處理學(xué)習(xí)模型。醫(yī)療語料庫的學(xué)習(xí)模型集成了語音識別和學(xué)習(xí)領(lǐng)域現(xiàn)有的處理框架和模型,從意圖識別和知識理解兩個角度出發(fā),完成了對NLP領(lǐng)域Word2vec/GloVe/ELMo/BERT等工具技術(shù)的集成應(yīng)用。建立對話樣本集,并在樣本集中通過新建、標注、導(dǎo)入等操作來完成對話樣本的管理。
4.2 大數(shù)據(jù)分析模型的嵌入技術(shù)
為了提高互聯(lián)網(wǎng)醫(yī)院患者端的交互體驗,智能語音交互系統(tǒng)將“反應(yīng)速度”作為最核心的指標之一,由底層大數(shù)據(jù)處理能力支撐,通過服務(wù)分段,從讀取、計算、轉(zhuǎn)換、渠道、環(huán)境等角度提高綜合效能。
(1)在讀取層,使用行業(yè)領(lǐng)先的語音轉(zhuǎn)化和分詞技術(shù),達到5字每秒的語音轉(zhuǎn)化速度和50ms每次的分詞效能。
(2)在計算層,除了應(yīng)用Hadoop中MapReduce模型提高計算性能等大數(shù)據(jù)領(lǐng)域措施外,系統(tǒng)還對常見計算的處理結(jié)果做本地化,達到500MB的離線模型、數(shù)據(jù)、計算結(jié)果緩存。
(3)在轉(zhuǎn)換層,對常用語料庫進行本地化,在互聯(lián)網(wǎng)醫(yī)院的不同患者端,通過不同節(jié)點對常用語料的節(jié)點分布式存儲,提高答案的組合效率。
(4)在渠道層,側(cè)重在微信開發(fā)平臺上搭載后的性能優(yōu)化和App端的優(yōu)化。互聯(lián)網(wǎng)醫(yī)院小程序端部分功能采用組件化的開發(fā)方式,通過對常規(guī)功能的組件化開發(fā),優(yōu)化小程序的響應(yīng)參數(shù);H5頁面的加載速度是影響整體響應(yīng)速度的關(guān)鍵因素,該系統(tǒng)利用預(yù)加載的技術(shù),在用戶點擊進入頁面前提前加載下一個頁面的內(nèi)容,減少頁面響應(yīng)時間。互聯(lián)網(wǎng)醫(yī)院App端采用數(shù)據(jù)包壓縮技術(shù),減少與服務(wù)器通信所占用的帶寬,提高App性能。
(5)在環(huán)境層,系統(tǒng)可以自動監(jiān)測當前用戶的網(wǎng)絡(luò)狀況,對輸出數(shù)據(jù)采用不同的壓縮選項和格式,當用戶所處網(wǎng)絡(luò)信號較弱時,系統(tǒng)支持2種以上的緩存方式,在網(wǎng)絡(luò)恢復(fù)時完成斷點續(xù)傳。
4.3 服務(wù)的組件化開發(fā)技術(shù)
為進一步提升本系統(tǒng)的遷移能力,拓展智能語音交互系統(tǒng)在醫(yī)療行業(yè)的更多應(yīng)用場景。系統(tǒng)可兼容多種數(shù)據(jù)來源,如不同數(shù)據(jù)庫類型、不同結(jié)構(gòu)數(shù)據(jù)等,同時對不同用戶終端進行適配測試,保證對市面上80%的設(shè)備兼容。
系統(tǒng)將開源公有語料庫作為主庫,各獨立語料庫如醫(yī)療語料庫的臨時性內(nèi)容擴充并不會直接影響到主庫,而是采用系統(tǒng)自動化檢驗顯著性的方式,對各獨立語料庫中的新增語料進行顯著性校驗,只有具備明顯普適性特征的語料才會更新并同步到主庫,采用自動審核、定時發(fā)布的形式對外提供公有語料庫最新內(nèi)容。
為保證各服務(wù)組件的穩(wěn)定性,系統(tǒng)將搭載安全態(tài)勢感知平臺,對高頻次、非常規(guī)IP地址的請求進行隔離,并觸發(fā)報警機制,防止異常請求對系統(tǒng)穩(wěn)定性的影響。
4.4 分布式存儲提升應(yīng)用效能方面
通過對不同問題的類型進行分類,將無需調(diào)用數(shù)據(jù)庫并經(jīng)過大數(shù)據(jù)計算的常規(guī)問答類資源存儲到離線數(shù)據(jù)庫中,將需要調(diào)用數(shù)據(jù)庫經(jīng)過計算并給出答案的數(shù)據(jù)問答類資源存儲到實時計算資源庫中。通過對數(shù)據(jù)問答類資源的實時計算與維護,降低患者提出數(shù)據(jù)類問題的響應(yīng)時間,保證并發(fā)時的用戶體驗以及整個系統(tǒng)的計算能力不受到嚴重影響。
5 系統(tǒng)推廣及應(yīng)用
5.1 打造醫(yī)護患協(xié)同的語音交互入口級產(chǎn)品
互聯(lián)網(wǎng)醫(yī)院現(xiàn)存的人工分診模式存在患者服務(wù)水平參差不齊、單人培養(yǎng)成本高、處理效率低等固有缺陷。以一次存在糾紛的患者投訴為例,傳統(tǒng)患者投訴服務(wù)流程需要經(jīng)過患者電話投訴→患者識別→查找患者就診記錄/來院監(jiān)控→查找接診醫(yī)護記錄→識別患者意圖→尋找解決方案等多個環(huán)節(jié),其中患者識別、就診記錄定位以及患者意圖識別會耗費投訴處理人員大量的時間,一方面由于手機號碼和固定號碼的可變性,導(dǎo)致識別患者身份的準確率很低;另一方面,對于一個成熟的公立醫(yī)療機構(gòu),面向患者的投訴解決方案可能存在成百上千種,投訴處理人員在識別患者身份、患者意圖的同時還需要找到最佳的解決方案,存在較大難度。
通過搭建面向互聯(lián)網(wǎng)醫(yī)院的智能語音交互系統(tǒng),不僅降低了醫(yī)療機構(gòu)人工客服在識別用戶身份、意圖以及找尋解決方案的難度,還可以通過標準的QA庫提升患者服務(wù)水平。借助于大數(shù)據(jù)技術(shù)以及機器學(xué)習(xí)算法,讓智能語音交互系統(tǒng)擁有一線人工客服的業(yè)務(wù)素養(yǎng)的同時,還可以不斷學(xué)習(xí),并且具備數(shù)據(jù)分析與計算的能力。
5.2 通過服務(wù)封裝提高語音交互系統(tǒng)的可復(fù)用能力
經(jīng)過系統(tǒng)的不斷學(xué)習(xí)和語料庫的擴充,將不同類別的問題進行歸類總結(jié),利用統(tǒng)一的封裝技術(shù)與標準,編寫成為各自獨立的語料庫,并提供標準的API接口對外開放,讓該系統(tǒng)的能力不僅適用于醫(yī)療機構(gòu)內(nèi)部,還能夠輻射到醫(yī)聯(lián)體內(nèi)的更多成員,借助大用戶量的使用,系統(tǒng)可供分析的問題也會變得越來越多,從而達到對接-收集-反饋的開源生態(tài)系統(tǒng),為患者提供更多的服務(wù)場景。以患者咨詢問診為例,在患者向語音系統(tǒng)提問的過程中,可以讓系統(tǒng)捕捉到患者意圖,并適當?shù)淖鲋敢僮鳎缇€上預(yù)約、掛號、繳費、送藥到家、用藥指導(dǎo)等均可在語音交互中完成,提升患者問題的解決效率,從而提高患者就診滿意度。
猜你喜歡
工業(yè)設(shè)計(2022年8期)2022-09-09 07:43:20
軍民兩用技術(shù)與產(chǎn)品(2021年10期)2021-03-16 06:05:30
北京測繪(2020年12期)2020-12-29 01:33:58
兒童繪本(2018年10期)2018-07-04 16:39:12
家庭影院技術(shù)(2017年9期)2017-09-26 03:41:45
財經(jīng)(2017年2期)2017-03-10 14:35:35
財經(jīng)(2016年15期)2016-06-03 07:38:02
小朋友·快樂手工(2016年5期)2016-05-14 17:18:34
財經(jīng)(2016年3期)2016-03-07 07:44:46
財經(jīng)(2016年6期)2016-02-24 07:41:51
