皮膚腫瘤圖像自動分類的研究進展
2022-08-19 08:19:58戚倩倩孫衛(wèi)佳姚春麗
計算機工程與應用 2022年16期
王 慧,戚倩倩,李 雪,孫衛(wèi)佳,劉 瑩,姚春麗
1.長春工業(yè)大學 計算機科學與工程學院,長春 130012
2.吉林大學第二醫(yī)院 皮膚科,長春 130041
皮膚腫瘤是一種常見的皮膚增生性疾病,種類很多,臨床上分為良性腫瘤和惡性腫瘤[1]。皮膚惡性腫瘤有侵襲周圍組織器官及轉移的風險,早期診斷、及時治療可提高治愈率及生存率。圖1 列出了常見的皮膚良性腫瘤和惡性腫瘤,以及這些疾病患者的皮損圖像。良性腫瘤包括色素痣、脂溢性角化病、皮膚纖維瘤等;常見的皮膚惡性腫瘤包括基底細胞癌、鱗狀細胞癌、惡性黑色素瘤等[2]。
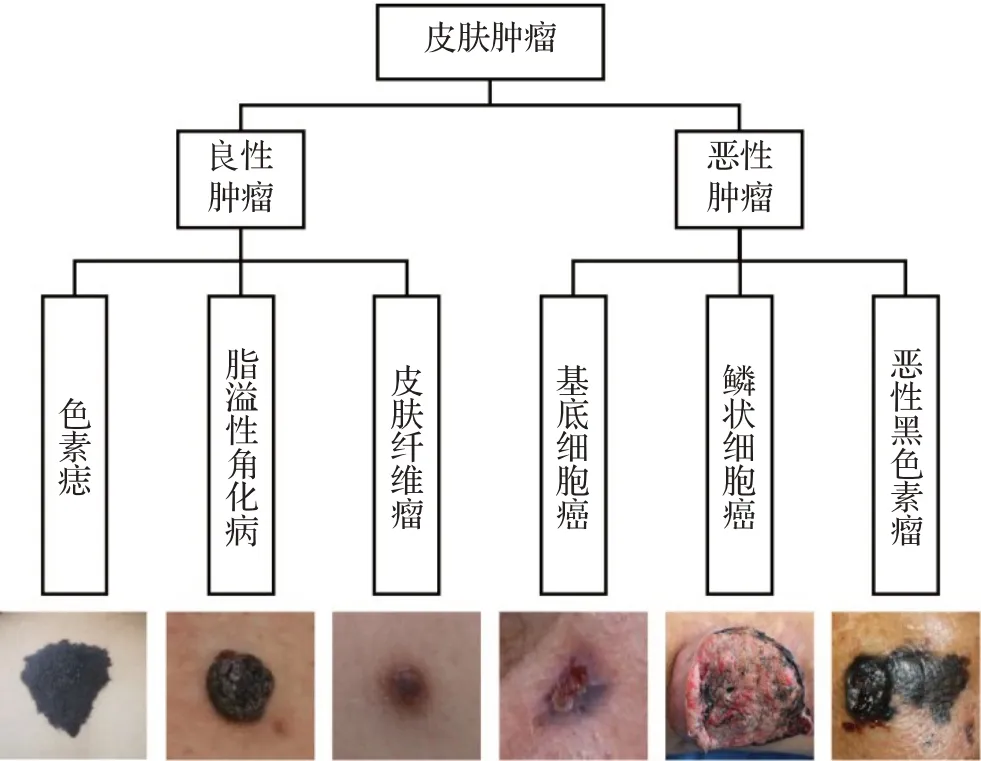
圖1 皮膚腫瘤分類及癥狀圖像Fig.1 Skin lesion classification and symptom images
在皮膚惡性腫瘤中基底細胞癌最為常見,其次為皮膚鱗狀細胞癌、惡性黑色素瘤。基底細胞癌生長緩慢,極少發(fā)生轉移,但具有侵襲性生長的特點[3]。鱗狀細胞癌具有轉移的風險,且高危型鱗狀細胞癌轉移有一定的致死率[4]。但絕大多數的皮膚惡性腫瘤致死病例都是惡性黑色素瘤造成的[5],早期診斷可極大提高生存率[6]。癌癥篩查和早期診斷是減輕癌癥疾病負擔的關鍵公共衛(wèi)生戰(zhàn)略措施[7],因此早期診斷、及時治療對改善皮膚惡性腫瘤的預后至關重要。但由于部分惡性腫瘤早期臨床表現與一些良性的皮膚腫瘤或皮膚疾病存在一定相似性,如早期惡性黑色素瘤、色素型基底細胞癌與色素痣,單從臨床表現較難鑒別,缺少經驗的醫(yī)生易誤診、漏診,導致皮膚惡性腫瘤的臨床診斷精度低,誤診率高,診療效率低下。應用皮膚鏡等輔助檢查措施可一定程度上提高確診率,具有無創(chuàng)、快速的優(yōu)點,但存在組織穿透性有限,結果判定主觀性強等缺點[8]。目前診斷的金標準仍是皮膚組織活檢病理檢查,但存在專業(yè)人員培養(yǎng)周期長、需要有創(chuàng)操作、耗時、花費高等局限性[9],因此對于早期的皮膚惡性腫瘤,尋找快速精準的診斷方法具有重要意義。
隨著人工智能的興起,計算機診斷皮膚疾病成為可能,我國多家醫(yī)院也開始著力于開展有關人工智能(artificial intelligence,AI)診斷皮膚疾病的研究[10-11]。計算機在提高皮膚科醫(yī)師診斷水平,促進學科建設和發(fā)展等方面擁有巨大潛能[12]。人工智能系統(tǒng)可以支持皮膚科醫(yī)生的日常臨床實踐,提高醫(yī)生的診斷效率[13],同時計算機可以給醫(yī)生提供診斷意見,醫(yī)生也可以結合臨床和組織病理特征,必要時為人工智能提供臨床信息用于訓練,提高系統(tǒng)的正確診斷率。但目前皮膚圖像分類領域內的綜述類文章對數據集的收集以及不同模型實驗效果整理不夠全面,因此本文針對近幾年的皮膚腫瘤圖像分類方法及相關數據集進行了詳細的歸納總結。
1 主要評價數據集
在皮膚圖像分類中,常用的公開數據集有ISIC數據集、PH2數據集、MED-NODE數據集、七點皮膚病數據集以及來源于搜索引擎各種公開的醫(yī)學圖像等。以下對皮膚疾病數據集進行總結。
(1)ISIC數據集
ISIC數據集由國際皮膚成像合作組織(The International Skin Imaging Collaboration)提供。從2016 年開始,該組織與領先的計算機視覺會議一起為計算機科學界贊助了年度挑戰(zhàn)賽,這些挑戰(zhàn)賽在規(guī)模、復雜性和參與度等方面都在不斷增長,因此ISIC 數據集是目前最大、使用頻率最高的公開皮膚疾病數據集。該數據集包含ISIC2016~ISIC2020共5個數據集,其中ISIC2016~ISIC2018 均包含分割、特征檢測、疾病分類三個挑戰(zhàn),ISIC2019 和ISIC2020 僅包含分類任務。該數據集的訓練集和測試集均為通過人工驗證、CC-0 許可的高質量圖像和元數據。
(2)ISIC2016數據集
ISIC2016 數據集[14]包含2 類疾病共1 279 張圖像以及類別標簽和GroundTruth,測試集包含379張圖像。皮膚疾病圖像顏色深度均為24 位,GroundTruth 顏色深度均為8位,圖像尺寸為722×542~4 288×2 848不等。類別標簽以表格形式存儲,使用該數據時需要進行預處理。
(3)ISIC2017數據集
ISIC2017 數據集[15]包含黑色素瘤、脂溢性角化病、良性痣3類疾病、2 750張圖像、GroundTruth以及類別標簽。其中訓練集圖像有2 000 張,驗證集和測試集分別有150 張圖像和600 張圖像,皮膚疾病圖像顏色深度均為24 位,圖像尺寸為767×576~6 621×4 441 不等。驗證集和測試集還包括未標注的超像素圖像。與ISIC2016相同,類別標簽為表格存儲,在訓練模型前需要對數據集進行預處理。
(4)ISIC2018數據集
ISIC2018 數據集[16]中分類和分割包含有不同數量的疾病圖像,對于分割任務,共有2 594張圖像作為訓練集,驗證集和測試集分別有100 和1 000 張圖像。對于分類任務,共包含12 500 張圖像,其中訓練集共包含10 015 張圖像7 類疾病,分別為光化性角化病(327)、基底細胞癌(514)、良性角化病(1 099)、皮膚纖維瘤(115)、黑色素瘤(1 113)、黑色素細胞性痣(6 705)、血管性皮膚病變(142)。這些圖像由HAM10000[17]數據集提供,均為24位顏色深度,尺寸為600×450。驗證集和測試集分別為193 和1 512 張圖像。分類任務數據集中7 類圖像混合在同一個文件夾中,標簽以表格存儲,需要預處理。
(5)ISIC2019數據集
ISIC2019數據集共包含8類疾病,25 331張圖像,這些數據分別來自于HAM10000、BCN20000[18]和ISIC2017數據集。測試集共有8 238 張圖像。其中圖像深度均為24位,各個圖像尺寸不同。與ISIC2016~ISIC2018不同,ISIC2019 僅有分類任務,分別為使用元數據進行分類和不使用元數據進行分類。數據集標簽除了標明圖像的類別,同時還包括年齡、性別以及解剖部位的信息。同ISIC2018,這些數據以表格形式存儲,所有圖像在同一個文件夾中,需要預處理。
(6)ISIC2020數據集
ISIC2020 數據集[19]包含來自2 000 多個患者的共33 126例良性和惡性2類皮膚病變皮膚鏡訓練圖像。圖像來自巴塞羅那醫(yī)院、維也納醫(yī)科大學、斯隆·凱特琳紀念癌癥中心、澳大利亞黑素瘤研究所、昆士蘭大學和雅典大學醫(yī)學院。該數據集是針對2020年夏季在Kaggle舉辦的SIIM-ISIC黑色素瘤分類挑戰(zhàn)賽策劃的。所有圖像均為24位顏色深度,且尺寸不相同,所有圖像在同一個文件夾中,數據以表格形式存儲,需要預處理。
(7)PH2數據集
PH2數據集[20]是在葡萄牙馬托西諾斯Pedro Hispano醫(yī)院皮膚科服務處獲得的皮膚鏡圖像數據集。總共包含200例皮膚鏡檢查的黑素細胞病變,其中有80張普通痣、80張非典型痣和40例黑色素瘤。PH2數據集包括所有圖像的醫(yī)學注釋,即病變的醫(yī)學分割、臨床和組織學診斷以及幾種皮膚鏡檢查標準的評估。PH2數據集圖像尺寸介于760×560~770×580之間,顏色深度為24位,每張圖像都分別存儲在一個文件夾中,需要進行預處理。
(8)七點皮膚病數據集
七點皮膚病數據集[21]用于評估計算機對七點皮膚病變惡性程度的預測結果。該數據集包括20 類2 045張臨床和皮膚鏡彩色圖像,以及為訓練和評估計算機輔助診斷系統(tǒng)而定制的相應結構化元數據。這些圖像尺寸均為768×512,顏色深度為24位。數據集將疾病放在34個文件夾中,使用時需將圖像按類別分開。
(9)MED-NODE數據集
MED-NODE數據集[22]來自于格羅寧根大學醫(yī)學中心皮膚科,共包含2 類170 張圖像,分別為70 例黑色素瘤和100例良性痣。數據集包含各種尺寸圖像,顏色深度均為24位,這些疾病按類別分別放在兩個文件夾中,圖片和標簽可直接提取,不需要預處理。
(10)Dermofit Image Library數據集
Dermofit Image Library 數據集[23]來源于愛丁堡大學,該數據集包含了10 個不同類別的共1 300 張圖像,包括黑色素瘤、脂溢性角化病和基底細胞癌。每張圖像都有一個基于專家意見(包括皮膚科醫(yī)生和皮膚病理學家)的標準診斷。每個病變都對應一個GroundTruth。
(11)SNU數據集
SNU數據集[24]來自于首爾國立大學本當醫(yī)院、印加大學桑吉派克醫(yī)院和哈利姆大學東灘醫(yī)院,包含134類共2 201個不同尺寸圖像。數據集按照疾病類別存儲圖像,可直接讀取,不需要預處理。
(12)XiangyaDerm數據集
XiangyaDerm數據集[25]是一個大規(guī)模的以亞洲為主的帶有Bounding Box的皮膚病數據集。它包含107 565張臨床圖像,涵蓋541種皮膚病。該數據集中的每張圖片都是由專業(yè)醫(yī)生標注的,該數據集為非公開數據集。
(13)網站數據集
數據集除上述幾類外還可在各種皮膚疾病網站獲得。表1列出了一些公開的皮膚疾病相關網站如Derm-NetNZ、DermIS、Dermatology Atlas等,這些網站上的圖像主要為臨床圖像,在獲取時具有一定困難,且需要進行預處理。
皮膚疾病數據集總結如表1所示。

表1 相關數據集Table 1 Related datasets
2 主要評價指標
皮膚腫瘤圖像自動分類模型評估指標主要有準確率、精確度、靈敏度、特異度、F1值、ROC曲線、AUC值。計算這些指標需要分別計算真陽性(true positive,TP)、真陰性(true negative,TN)、假陽性(false positive,FP)和假陰性(false negative,FN),其概念如下:
真陽性:實為正例,分類器預測為正例的數目。
真陰性:實為反例,分類器預測為反例的數目。
假陽性:實為反例,分類器預測為正例的數目。
假陰性:實為正例,分類器預測為反例的數目。
(1)準確率(Accuracy)
準確率為預測正確的數量占總數量的百分比。其計算公式如下:

準確率衡量的是分類器的分類準確程度,準確率值越大表示分類器分類結果與真實確診結果越接近。
(2)精確度(Precision)
精確度為在所有被預測為正例的數目中實際為正例的概率。其計算公式如下:
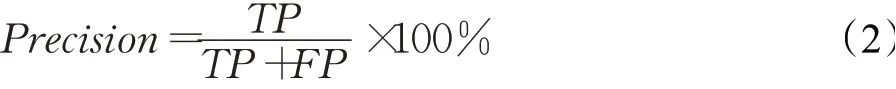
(3)靈敏度(Sensitivity)
靈敏度又叫召回率(recall)或真陽性率(true positive rate,TPR),為實際為正例的數目中被正確預測為正例的數目。其計算公式如下:
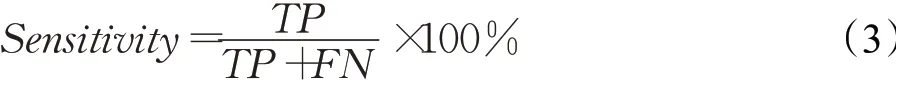
(4)特異度(Specificity)
特異度為實際為反例的數目中被正確預測為反例的數目。其計算公式如下:

(5)F1值(F-Measure)
F1 值是兼顧精確度和召回率的指標。F1 值越高,模型性能越好。其計算公式如下:

(6)ROC曲線(receiver operating characteristic)
ROC 曲線將誤判率(false positive rate,FPR)作為x軸,靈敏度作為y軸。靈敏度是所有實際為正例的樣本中,被正確判斷為正例的樣本比率。誤判率是所有實際為反例的樣本中,被錯誤判斷為正例的樣本比率。誤判率的計算公式如下:

(7)AUC值(area under curve)
AUC為ROC曲線下面積,表示處于ROC曲線下方的面積大小。AUC越大,模型分類效果越好,通常AUC值介于0.5 到1.0 之間。AUC 值是一個概率值,表示隨機挑選一個正樣本以及一個負樣本,分類器判定正樣本分值高于負樣本分值的概率就是AUC值。
3 計算機皮膚腫瘤圖像自動分類方法
皮膚腫瘤AI輔助診斷的核心為皮膚腫瘤圖像的計算機自動分類,常見分類流程如圖2所示。當前皮膚分類算法大體可以分成基于傳統(tǒng)機器學習的皮膚圖像自動分類方法和基于深度學習的皮膚圖像自動分類方法以及兩者結合等幾種方式。

圖2 皮膚腫瘤分類流程Fig.2 Flow chart of skin lesion classification
3.1 使用傳統(tǒng)機器學習算法
使用傳統(tǒng)機器學習算法對皮膚疾病分類主要通過對圖像的紋理、顏色、形狀等特征進行提取量化,之后使用分類算法對提取到的特征進行分類,最終得到分類結果。其主要流程如圖3所示。為準確提取到特征,在特征提取步驟之前通常會對圖像進行預處理,例如去掉噪聲干擾(如毛發(fā)、偽影等)或對病灶進行分割和邊界檢測,可以減少周圍健康皮膚對特征提取步驟的影響。對于傳統(tǒng)機器學習分類算法,則通常使用支持向量機(support vector machine,SVM)[26]和隨機森林(random forest,RF)[27]等方式。
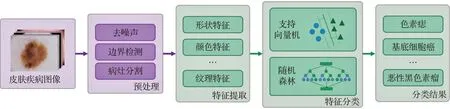
圖3 使用傳統(tǒng)機器學習算法分類流程圖Fig.3 Flow chart of traditional machine learning algorithm classification
支持向量機是一種小樣本學習方法,其泛化錯誤率低,具有良好的學習能力。Chatterjee等人[28]提出基于遞歸特征消除(recursive feature elimination,RFE)的技術來識別每種疾病。在分類之前,根據ABCDE 準則[29]分析皮膚病變的形狀、邊緣不規(guī)則性、紋理和顏色,使用不同的圖像處理工具提取不同的定量特征,之后使用SVM 進行分類,并采用分層結構分類模型對該框架的性能進行評估。但是經典的SVM 只適用于二分類算法,在皮膚多分類方面仍具有局限性。對于多分類問題,該團隊利用交叉相關技術,在類似視覺影響的基礎上,從皮膚疾病的明顯區(qū)域提取空間和光譜特征,選取適當的核心圖像塊進行分析,實現皮膚疾病的多類別分類[30],取得了較高的性能指標,但本質上是通過多次SVM進一步分出疾病亞類,最終只能區(qū)分4種不同疾病,對于更多種類的疾病則需要重新設計并訓練更多的分類器。
不同于SVM,隨機森林算法由多個決策樹組成,能有效地在大數據集上運行。Dhivyaa等人[31]首先使用區(qū)域生長法對病灶區(qū)域進行初步分割,再使用ABCDE 準則提取圖像特征,之后根據這些特征去設計不同的決策樹,最終使用隨機森林算法實現皮膚病變圖像分類,并用不同的數據集進行比較。與SVM 相比,該模型計算復雜度較低,設計靈活,可將皮膚疾病分為兩類或兩類以上。但是對于具有噪聲的圖像(例如被毛發(fā)遮擋的疾病)容易產生過擬合現象,且設計隨機森林時,可能存在多個相似的決策樹,對結果造成影響。Murugan 等人[32]則將SVM 與隨機森林結合起來,對不同特征提取方式提取到的特征進行分類,研究結果顯示使用灰度共生矩陣(grey-level co-occurrence matrix,GLCM)提取到的特征進行分類,其表現效果要優(yōu)于其他特征提取方式,在ISIC數據集上最高達到了89.31%的準確率。
盡管不同的機器學習方式在皮膚分類上取得了較大進展,有些優(yōu)秀的算法甚至超越了人類專家的水平[33],但傳統(tǒng)的機器學習算法是基于統(tǒng)計學原理的,不同的場景不同算法的表現也有很大差距,而且經典機器學習算法通常需要復雜的特征工程,適應性較差。
基于傳統(tǒng)機器學習的皮膚圖像自動分類代表性算法如表2所示。

表2 基于傳統(tǒng)機器學習的皮膚圖像自動分類研究Table 2 Research on skin image classification based on machine learning
3.2 使用深度學習網絡模型
使用基于深度學習的方法對皮膚腫瘤圖像進行分類可以極大地提高準確性,且具有很強的適應性。同時深度學習網絡靈活性更強,可以從不同角度創(chuàng)新。圖4展示了當前深度學習網絡模型分類的基本流程,在訓練網絡前通常會對圖像進行數據增強(旋轉、拉伸、翻轉等)和歸一化等預處理操作,之后將圖像輸入到主干網絡進行特征提取,在主干網絡后接全連接層可以將提取到的特征轉換為分類結果。此外,也有學者使用分割-分類多階段模型對皮膚疾病進行分類,在分類前通常將圖像傳入分割網絡分割出病灶區(qū)域,之后將分割出的區(qū)域與疾病圖像點乘得到僅有病灶的圖像,這樣做可以排除病灶外皮膚區(qū)域對分類網絡的干擾,從而提高分類網絡的準確率。下面將對各種深度學習分類方式進行介紹。

圖4 使用深度學習算法分類流程圖Fig.4 Flow chart of deep learning algorithm classification
3.2.1 使用單個模型分類
ResNet[34],在皮膚分類領域中是一種主流的網絡模型[35-36],與人類專家相比具有較高的準確率[37]。基于ResNet50在皮膚分類任務上的分類能力,Han等人[38]在網絡結構基礎上增加注意力機制。該研究算法在F1值指標上表現出更好的效果,超越了非皮膚科醫(yī)生,準確率與皮膚科的醫(yī)生相當。Tschandl 等人[39]用ResNet34進行了皮膚惡性腫瘤的多分類任務和二分類任務。Han等人[40]使用ResNet152模型對12種皮膚病的臨床圖像進行分類。
盡管ResNet 具有強大的性能,但深層的網絡需要更長時間的訓練。不局限于ResNet,針對于皮膚分類任務,學者們提出了不同的網絡模型進行實驗。Jinnai 等人[41]提出了一種基于區(qū)域的卷積神經網絡,結果表明該模型分類的精度優(yōu)于皮膚科醫(yī)生,但是該研究的數據來源單一,可能存在偏差,并且提出的模型局部紋理識別能力較弱,難以識別低分辨率的圖像。Han等人[42]使用卷積神經網絡(convolutional neural networks,CNN)對多達134 種疾病進行分類,結果表明CNN 在分析模糊、難以辨別的圖像方面比皮膚科醫(yī)生更有效,然而訓練模型使用的圖像質量高,在實際應用中效果會因為圖像質量不佳而下降。Fujisawa 等人[43]使用GoogLeNet[44]進行圖像分類,但該模型在孔隙瘤和脂溢性角化病兩種疾病上的分類效果不佳。Liu 等人[45]則提出了一種多級關系捕獲網絡(multi-level relationship capture network,MRCN),使用區(qū)域相關學習模塊來模擬中心病變區(qū)域中不同重要區(qū)域之間的關系。同時,使用跨圖像學習模塊來模擬多幅圖像之間的深度語義相關性。該模型在三個具有挑戰(zhàn)性的數據集上進行了全面的實驗,實驗結果表明了MRCN優(yōu)越的性能。
隨著各種計算機視覺領域的模型提出,目前使用單個模型進行分類的技術已經趨于成熟,且易于實現,同時準確率較高。但對于不同的數據集,數據分布差異大,模型容易受到噪聲,如毛發(fā)、光線等多種因素影響,因此在多種數據集之間,單個模型表現可能相差較大,預測結果不具有穩(wěn)定性。
使用單個模型分類的代表性算法總結如表3所示。

表3 使用單個模型分類研究總結Table 3 Research on classification using individual models
3.2.2 比較多種模型效果
在不同數據集上,不同的模型表現可能存在較大差異,通常學者會比較多種模型的效果最終選取效果較好的模型。Kimeswenger 等人[46]基于兩種方法實現神經網絡體系,分別是加入SELU 的Baseline 和多實例學習(multiple instance learning,MIL)體系結構,最終通過比較每種網絡的結果得出具有注意力機制的MIL 結構效果更好。通過使用四種不同的網絡模型,Huang 等人[47]實現了基底細胞癌和脂溢性角化病的分類。同樣,Singhal 等人[48]也比較了四種不同網絡模型在皮膚疾病七分類上的表現,之后選取表現最好的模型作為最終模型。上述Huang 與Singhal 等人的研究中,最終得出的結論都是Inception ResNet v2[49]在數據集上與其他模型相比的表現更好。在Huang等人[50]的研究中,通過比較多個模型最終得到DenseNet[51]在良惡性二分類任務中效果更好,EfficientNet[52]在多分類任務上綜合表現更好。Xie等人[53]在自己建立的湘雅數據集上比較了五種不同的模型,最終發(fā)現Xception[54]的表現最好。Mijwil[55]在其研究中使用三種不同體系結構,在ISIC2019 和ISIC2020 數據集上進行測試,最終實驗結果表明Inception v3的表現更好。
在上述實驗中,盡管都是皮膚疾病分類的任務,但學者們在不同數據集上得出了不同的結論,說明數據分布不同,不同網絡模型表現可能也存在差異。但上述各實驗結論中表現最好的模型都具有相同的特點——更寬的網絡。通常來說,加深網絡深度可以提升網絡的表達能力,增加感受野(如VGGNet[56]和ResNet 等),而更寬的網絡則能使網絡學習豐富的特征(如DenseNet、EfficientNet、InceptionNet 等),對于皮膚疾病圖像分類,病灶通常位于圖像中央,且各類疾病具有高度相似性,因此提取更豐富的特征辨別各類疾病間細微差距相比于增加感受野更能提高網絡的分類準確率。
通過使用多種不同深度學習網絡模型分別來完成分類任務,然后進行比較,得出最好的分類模型。這種方式通常用于篩選分類任務中的主干網絡,但本質上仍然屬于使用單個網絡進行分類,若通過多個網絡合作進行分類,其穩(wěn)定性相比于單個網絡會更高。
比較多種模型效果的代表性算法總結如表4所示。

表4 比較多種模型效果研究Table 4 Research on comparing effects of multiple models
3.2.3 分割-分類多階段模型
分割-分類多階段模型模擬了醫(yī)生診斷皮膚疾病時的流程,相比于單個分類網絡,往往能取得更好的效果。Al-Masni等人[57]提出了一種二階段診斷模型,首先使用全分辨率卷積神經網絡(full resolution convolutional network,FrCN)進行分割,再使用四種不同的分類網絡進行分類。但該研究使用兩個級聯網絡完成,因此需要為每個階段準備訓練數據。Jiang 等人[58]提出一種分類模型和后續(xù)語義分割模型組成的框架。但是研究使用的全視野數字切片(whole slide image,WSI)數據受系統(tǒng)成本、存儲等限制,在世界范圍的疾病診斷應用內進展緩慢。Khouloud 等人[59]則提出了一種檢測黑色素瘤的深度學習模型,該模型由分割網絡W-Net和分類網絡Inception ResNet 兩部分,實驗表明該模型的分割和分類能力表現優(yōu)秀,具有更高的準確性。Khan 等人[60]也提出了包括分割和分類兩個階段的深度學習框架,分別在不同的數據集上進行測試,獲得了良好的分類效果,但是該模型對紋理、顏色和背景等方面要求較高。除了分割模型,YOLO[61]作為目標檢測模型,也可以提取包含病灶在內的矩形區(qū)域,Nersisson 等人[62]融合YOLO 和CNN 提出了新的分類網絡,該網絡先使用YOLO 提取病灶區(qū)域,之后再使用CNN 完成皮膚疾病的分類。該研究在ISIC2016 數據集上達到了94%的準確率,并且在處理有毛發(fā)、汗液的圖像時基本不受影響,魯棒性強。Liu等人[63]模擬醫(yī)生學習和診斷過程提出了臨床啟發(fā)網絡(clinical-inspired network,CIN)。該網絡由病變區(qū)域分割模塊、病變特征注意模塊和病變區(qū)分模塊三部分組成,并在ISIC2016 和ISIC2017 數據集上測試,獲得了較高的準確率。
使用多個網絡共同完成分類任務具有更高的穩(wěn)定性,例如對病灶先進行分割,一定程度上減輕了數據分布差異對模型造成的影響,但多個網絡的訓練成本高,網絡參數大,對硬件要求高,難以普及。
分割-分類多階段模型的代表性算法總結如表5所示。

表5 分割-分類多階段模型研究總結Table 5 Summary of research on segmentation-classification multi-stage models
3.2.4 其他分類方式
從醫(yī)學數據集不足的角度出發(fā),使用生成對抗網絡(generative adversarial network,GAN)擴充數據集往往也能提升網絡預測效果。Zhao 等人[64]提出了基于Self-Attention-StyleGAN 的皮膚癌圖像生成分類網絡,該網絡使用生成對抗網絡生成圖像,之后進行分類。該模型的平衡多類精度在ISIC2019 數據集上達到了94.71%。Gao等人[65]設計了一種正則化的對抗訓練框架,在2D皮膚癌分類和3D 危及器官分割任務上,以較少的訓練開銷獲得了優(yōu)于最先進自動增強方法的性能。盡管GAN可以大幅擴充數據集,提高準確性,但與分割-分類模型相同,GAN增加了訓練的成本。
不局限于數據集,作為訓練時評估模型表現好壞的損失函數同樣對模型的訓練效果有著巨大影響。Lei等人[66]模擬醫(yī)學生比較疾病之間異同點來學習和識別一種疾病的方式,提出了一種三元組模型及三元組損失,該損失讓三元組的學習更加穩(wěn)定。Barata等人[67]模擬醫(yī)生看病時結合以往經驗的方式引入了基于內容的圖像檢索(content-based image retrieval,CBIR)技術,并提出由交叉熵損失、三重態(tài)損失、對比損失和蒸餾損失四部分組成的損失函數,取得了良好的結果。Zhu 等人[68]受小樣本學習(few-shot learning,FSL)的啟發(fā),將FSL 運用到皮膚疾病分類中,提出查詢相對(query-relative,QR)損失解決交叉熵損失與Episode Training 不兼容導致模型效果不佳的問題。修改損失函數雖然對模型的訓練不產生直接的時間消耗,但損失函數與網絡處理方式通常是相對應的,不具有泛化性。
開發(fā)輕量級的網絡模型進行皮膚疾病分類也是重要的研究方向之一,它可以嵌入到移動設備,使得患者在醫(yī)生診斷前獲得較為精確的檢測結果,之后醫(yī)生也可以參考該結果進行診斷。Toaar等人[69]提出了一種基于自動編碼器、脈沖神經網絡和卷積神經網絡的模型。該模型的分類網絡使用MobileNetv2[70],可以大大節(jié)省參數量,使其可以應用在智能手機上,同時自動編碼器和脈沖神經網絡彌補了MobileNetv2 準確率不高的問題。Srinivasu等人[71]在MobileNetv2的基礎上加入了LSTM[72]機制,在HAM10000 數據集上達到了85%的準確率,并將該模型應用到手機上。Iqbal 等人[73]設計了一種輕量級的皮膚分類網絡CSLNet,該網絡具有高效率和高性能。該研究中提出的算法在ISIC 數據集上的表現優(yōu)于最先進的算法。
輕量級模型訓練時間短,可以嵌入到移動設備,具有相當大的研究前景,但在設計輕量級模型時同時保證準確率與泛化能力具有一定的挑戰(zhàn)性。
其他分類方式的代表性算法總結如表6所示。

表6 其他分類方式研究Table 6 Research on other classification methods
3.3 深度學習模型與傳統(tǒng)機器學習算法結合
除了上述提到的深度學習的方式與傳統(tǒng)機器學習算法的方式,也有學者嘗試將兩種方法結合起來對皮膚疾病圖像進行分類。在傳統(tǒng)機器學習分類流程的基礎上使用深度學習網絡替代特征提取部分,而預處理部分也需要換成深度學習方式中的預處理。將深度學習模型與傳統(tǒng)機器學習算法結合的方式包含了兩種分類方式的優(yōu)點,不僅省略了傳統(tǒng)機器學習算法中復雜的特征工程的操作,而且將深度學習中全連接層換成傳統(tǒng)機器學習中的算法也可以進一步提高算法的分類速度。使用兩種方式分類的流程圖如圖5所示。

圖5 結合深度學習與傳統(tǒng)機器學習算法分類流程圖Fig.5 Flow chart of combining deep learning with traditional machine learning algorithm classification
Dorj 等人[74]利用經過預訓練的卷積神經網絡模型進行特征提取,利用ECOC-SVM 分類器對皮膚惡性腫瘤進行分類。該模型準確率、靈敏度、特異度均超過90%,表現優(yōu)于其他模型。Minagawa等人[75]使用灰度算法對亮度和顏色平衡進行標準化,之后將預處理后的圖像使用深度神經網絡進行分類。Tyagi等人[76]將卷積神經網絡結構與粒子群算法相結合,提出一種基于皮膚鏡圖像的疾病預測與分類智能預測模型,該模型在ISIC2016 上的分類準確率高達99.46%,其他指標也均在97%以上。Khan 等人[77]提出一種使用深度學習特征和改進的飛蛾火焰優(yōu)化(improved moth-flame optimization,IMFO)算法進行皮膚病變分割和分類,該方法融合了多種機器學習算法和特征分析方式,實現了分割-分類兩階段的模型,在ISIC2016~ISIC2018 數據集上的準確率均超過90%。由于該模型使用了較多的技術,整個分類流程需要花費較長的計算時間。在Adla 等人[78]的研究中,首先使用深度學習的方式提取圖像的特征,然后使用基于燕子群算法的卷積稀疏自動編碼器(convolutional sparse auto-encoder,CSAE)進行分類,取得了優(yōu)良的結果,該算法在ISIC2017上的準確率高達98.5%。
使用傳統(tǒng)機器學習算法與深度學習網絡模型進行結合的方式適用于各種不同情況的疾病分類,傳統(tǒng)機器學習算法與深度學習的結合保證了模型的預測速度以及較高的準確率,同時可以通過深度學習提取特征的方式解決復雜的特征工程問題。但是將兩種方式結合仍然存在一定困難,如何通過深度學習網絡生成適用于機器學習處理的特征是一項挑戰(zhàn)。同時該方向也一直是學術界積極探索的問題,目前相關的研究較少,具有很高的研究價值。
深度學習與傳統(tǒng)機器學習算法結合分類的代表性算法總結如表7所示。
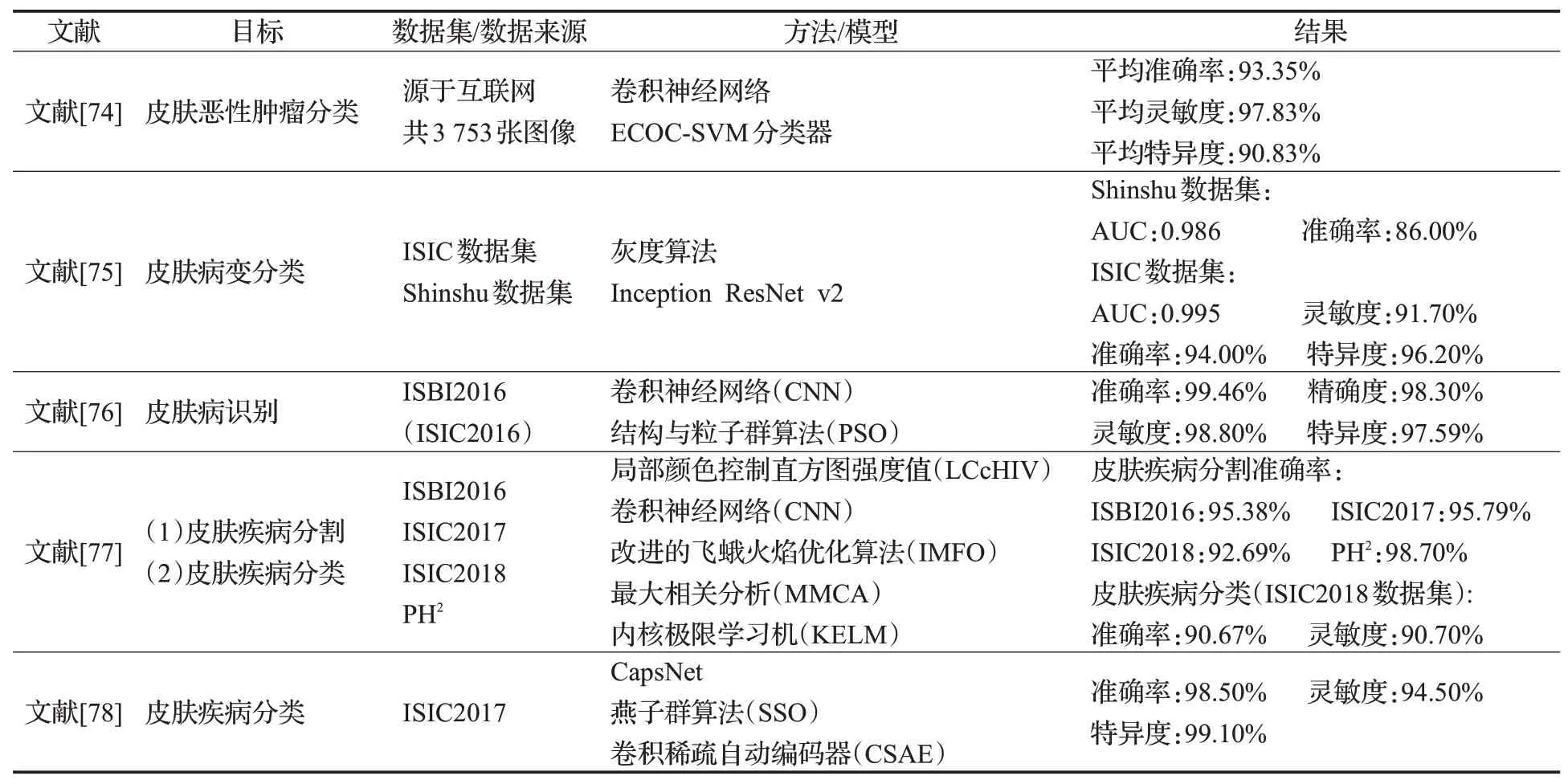
表7 深度學習與傳統(tǒng)機器學習算法結合分類研究Table 7 Research on combination of deep learning and machine learning algorithms for classification
4 總結
4.1 不同模型在典型數據集上的表現
本文總結了許多學者提出的不同模型,下面選取四個不同的典型數據集,分別是ISBI2016(ISIC2016)、ISIC2017、ISIC2018(HAM10000)和ISIC2019數據集,評估指標選取準確率、精確度、靈敏度、特異度進行分析。
不同實驗中數據集的訓練集和測試集劃分不同,因此相同的模型在同一數據集上也可能產生不同結果。此外訓練輪數、Batchsize、學習率等超參數的設置對網絡訓練結果也會產生較大影響。圖6~圖9 展示了不同模型在數據集的表現。

圖6 不同模型在ISIC2016數據集上的比較Fig.6 Comparison of different models on ISIC2016 dataset

圖7 不同模型在ISIC2017數據集上的比較Fig.7 Comparison of different models on ISIC2017 dataset

圖8 不同模型在ISIC2018數據集上的比較Fig.8 Comparison of different models on ISIC2018 dataset
從圖6~圖9中可以看出,使用多種網絡共同合作的方式準確率和靈敏度高于使用單個模型,說明多個網絡合作更適用于圖像分類任務。對于ISIC2018數據集,其相關研究的文獻更多,說明目前的皮膚疾病分類任務數據集主要以ISIC2018(HAM10000)為主。而ISIC2019相關的研究不多,作為較新的數據集,其數據量比ISIC2018 更大,可能會在今后的研究中成為主要數據集。此外,從ISIC2016到ISIC2019數據集,模型的綜合效果逐年下降,這是因為ISIC2016數據集的圖像和種類較少,分類相對簡單。而ISIC2019 數據集共有8 類,數據集總量為ISIC2016的20倍左右,因此挑戰(zhàn)性更大。

圖9 不同模型在ISIC2019數據集上的比較Fig.9 Comparison of different models on ISIC2019 dataset
4.2 不同方法的適用范圍
表8總結了不同方法/機制的優(yōu)點、局限性以及適用范圍。當前皮膚疾病分類任務更傾向于使用深度學習的方式。對于使用深度學習框架,單個分類網絡的框架已經較為成熟,易于實現,但是這種方式受輸入圖像影響較大,例如臨床圖像中的病灶小,不在中心等位置,可能導致網絡訓練時受到較大噪聲的干擾,影響分類結果。使用多個網絡比較更適用于篩選出合適的網絡模型作為Backbone 或Baseline,并在此基礎上進行創(chuàng)新。而使用網絡類似于分割-分類多階段的模型完成圖像分類保證了更高的穩(wěn)定性,同時修改更具有靈活性。使用GAN對數據集擴充可以有效解決醫(yī)學領域皮膚疾病數據集少的問題,但是生成圖像的質量難以保證。損失函數的創(chuàng)新可能為模型帶來不錯的提升,但設計起來相對困難,泛化能力比交叉熵損失弱。輕量級的模型具有更強的實用性,但同時保證較少的參數量和較強的泛化能力仍是一項巨大挑戰(zhàn)。知識蒸餾(knowledge distillation)作為當前研究熱點,可以結合上述所有深度學習模型進行創(chuàng)新,具有相當大的潛力。結合深度學習與機器學習的方式雖然也是學術界積極研究的問題,但該方向仍然存在一定困難。

表8 不同方法/機制的特點和適用范圍Table 8 Features and application scope of different methods/mechanisms
4.3 研究趨勢
對于數據集來說,當前研究的數據集主要傾向于ISIC2018 數據集,而關于ISIC2019 和ISIC2020 的實驗相關研究較少。此外,Wang 等人[79]認為當前的皮膚圖像分類都采用標注好類型的數據集,這無疑需要消耗大量的人工和精力去制作精良的數據集,因此他們提出了一種基于自監(jiān)督拓撲聚類網絡的未標記皮膚損傷分類。該方法可以在沒有先驗分類結果的情況下自動對未標記的醫(yī)學圖像進行分類,并且充分的實驗證明了他們提出的STCN 模型能夠有效地解決未標記的醫(yī)學圖像分類任務。
從分類模型來看,傳統(tǒng)的機器學習和單個網絡模型的研究在近年來較少,因為這兩種方法的發(fā)展已經較為成熟,此外這兩種方法在分類準確性上具有一定的局限性。在未來發(fā)展上,皮膚分類模型將趨向于準確率更高,模型更輕量。對于更高的準確率,使用遷移學習往往能帶來更好的效果,除了載入預訓練權重,領域自適應(domain adaptation)作為遷移學習中的一部分,旨在把分布不同的源域和目標域的數據,映射到一個特征空間中,使其在該空間中的距離盡可能近,這也是目前研究的熱點之一。但是在領域遷移時,域內和域間類別不平衡的問題成為一項挑戰(zhàn),Yoon等人[80]則提出一種分類和對比語義對齊(classification and contrastive semantic alignment,CCSA)的方式來解決域內與域間數據不平衡的問題,為了鼓勵從少數類中學習,損失使用采樣的類概率來加權分類和對齊損失。Bayasi 等人[81]提出了一種用于多域學習(multi-domain learning,MDL)的持續(xù)學習(continual learning,CL)方法,即一種新的剪枝策略,該策略會檢測每個域中造成錯誤分類的相關單元,并釋放這些單元,以便它們專門用于新域的后續(xù)學習。此外,作者有效地將剪枝和訓練階段合并為一個步驟,從而減少與重新訓練網絡后對于網絡剪枝的相關計算成本。
此外,也有不少學者結合當前熱點技術等對皮膚疾病圖像進行分類。強化學習是一類學習、預測、決策的框架,它與環(huán)境交互,是一種針對序列問題的算法,相比于監(jiān)督學習,強化學習考慮的是長期回報,這種長遠的眼光對于找到最優(yōu)解非常關鍵。例如Akrout 等人[82]引入強化學習技術,將其與CNN結合提出一種問答(question answering,QA)模型,該模型提高了視覺癥狀檢查器的分類置信度和準確性,同時減少了提出的平均問題數。聯邦學習能夠在滿足用戶隱私保護、數據安全和政府法規(guī)的要求下,在多參與方或多計算結點之間開展高效率的機器學習框架。Bdair等人[83]提出一種半監(jiān)督的聯邦學習方法,并提出了對等匿名化(peer anonymization,PA)技術來改善隱私,在提高性能的同時降低了通信成本。知識蒸餾是一種壓縮模型的方法,由教師網絡和學生網絡組成,通過精簡、參數量小的學生網絡學習復雜、泛化能力強的教師網絡的輸出,使得學生網絡能夠有效地學習教師網絡的泛化能力。Van Molle等人[84]使用知識蒸餾技術訓練深度學習網絡,并將其運用到皮膚疾病分類上,取得了良好的效果。Transformer是一種利用注意力機制來提高訓練速度的模型,被廣泛應用于自然語言處理中,最近有研究證實其在計算機視覺領域也有巨大潛力。Shamshad 等人[85]對Transformer 在醫(yī)學領域中的應用進行了詳細的總結。Wu等人[86]引用自然語言分析中的Transformer 技術與分類網絡結合,在全視野數字切片上進行分類,實驗結果表示該方法優(yōu)于其他全視野數字切片方法。
除了模型和技術上的創(chuàng)新,結合醫(yī)學知識去分析疾病類別同樣也是一種新的方向。例如Kinyanjui 等人[87]提出了一種估計皮膚病基準數據集中膚色的方法,并研究模型性能是否依賴于該度量。Pacheco等人[88]使用元數據(例如病人的年齡、性別等)進行輔助分類,他們使用了五種不同的網絡,并加入他們提出的元數據處理塊,使得網絡的分類結果有所提升。
盡管深度學習在皮膚腫瘤圖像分類領域取得巨大進展,許多模型與方法已經較為成熟甚至投入實際使用,但目前的研究仍然存在以下問題或改進方向:
(1)在醫(yī)學領域,數據集缺乏仍然是一項重要的問題,而制作一份精良的醫(yī)學數據集不僅需要專業(yè)的人員操作,同時需要消耗巨大的成本。使用自監(jiān)督技術標注數據集能大大降低時間和人工的消耗。此外,使用生成對抗網絡可以生成逼真的圖像,也可以解決醫(yī)學圖像數據少的問題。
(2)現有的分類模型大部分都局限于單一模型對單張圖像直接進行分析,若結合其他信息,如患者年齡、膚色、性別、各類別圖像之間的異同點、其他模型的軟預測結果等,可能會對模型的提升有更大幫助。不局限于計算機視覺領域,引入其他領域的技術如Transformer、強化學習、聯邦學習進行皮膚疾病分類也是當前的研究熱點之一,且目前相關研究較少,值得深入探索。
(3)隨著深度學習的發(fā)展,會有越來越多性能優(yōu)異的模型被提出,相比于追求高的準確率,輕量級的模型在醫(yī)學領域的實用價值更大,不管是嵌入在移動設備端,或是在云端計算機上運算,輕量級模型能在保證不降低過多準確率的情況下大幅提升效率。領域自適應、知識蒸餾、網絡剪枝、輕量級模型等技術具有巨大的研究價值。
5 結束語
皮膚惡性腫瘤對患者的生活質量及生命健康威脅巨大,但是惡性腫瘤又與一些良性腫瘤臨床表現相似,容易導致醫(yī)生的誤診,使用AI 輔助醫(yī)生的方式可以提高醫(yī)生的診斷效率和精確度,可在醫(yī)療領域中發(fā)揮重大作用。基于皮膚腫瘤圖像自動分類的臨床輔助診斷模型,可有效提高皮膚科醫(yī)生的臨床診斷效率和準確率,縮短診斷周期,達到各級醫(yī)院的診斷均質化,具有重要的實用價值。
本文對國內外皮膚腫瘤圖像自動分類方法進行了歸納總結,在有關人機的對比實驗中,無論傳統(tǒng)機器學習算法還是深度學習算法對皮膚腫瘤分類效果都比一般醫(yī)生要好,和專家水平相當。且計算機具有很強的計算能力,因此使用計算機輔助醫(yī)學診斷是未來醫(yī)療的趨勢。相比于傳統(tǒng)機器學習算法,深度學習方法在提取圖像特征中具有較強優(yōu)勢,準確率更高,因此多數的皮膚圖像分類任務都是使用基于深度學習的方法實現的。而深度學習算法有很多種模型,不同的模型各有優(yōu)勢,在不同任務中表現的效果不同,因此使用多種網絡模型組合完成任務也是實現圖像分類任務的方法之一。同時,隨著算力的不斷提升,也會有更多新的模型被提出,這些網絡模型在醫(yī)學圖像分類領域中也會有較好的表現。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
