深度學(xué)習(xí)中的安全帽檢測(cè)算法應(yīng)用研究綜述
2022-08-19 08:19:36張立藝武文紅牛恒茂段凱博蘇晨陽(yáng)
計(jì)算機(jī)工程與應(yīng)用 2022年16期
張立藝,武文紅,牛恒茂,石 寶,段凱博,蘇晨陽(yáng)
1.內(nèi)蒙古工業(yè)大學(xué) 信息工程學(xué)院,呼和浩特 010080
2.內(nèi)蒙古建筑職業(yè)技術(shù)學(xué)院 建筑工程與測(cè)繪學(xué)院,呼和浩特 010020
建筑施工現(xiàn)場(chǎng)中因高空墜落、物體打擊導(dǎo)致作業(yè)人員死亡的事故占比達(dá)50%以上,安全帽是保證作業(yè)人員免受致命傷害的一種重要防護(hù)工具。因此在施工現(xiàn)場(chǎng)安全管理中,對(duì)施工人員進(jìn)行安全帽佩戴檢測(cè)是重要工作,同時(shí)也是未來(lái)智能建造平臺(tái)或智慧工地應(yīng)用的重要內(nèi)容。
目標(biāo)檢測(cè)作為計(jì)算機(jī)視覺(jué)領(lǐng)域的一個(gè)重要研究方向,是很多復(fù)雜計(jì)算機(jī)視覺(jué)任務(wù)的基礎(chǔ),其基本任務(wù)是找出圖像中感興趣的目標(biāo)并給出目標(biāo)的類別和位置信息。安全帽檢測(cè)作為目標(biāo)檢測(cè)的具體應(yīng)用領(lǐng)域,在施工現(xiàn)場(chǎng)智能化監(jiān)控系統(tǒng)中起關(guān)鍵作用。截至目前,安全帽檢測(cè)算法的研究主要分為兩類:一是基于傳感器的安全帽檢測(cè)算法;二是基于計(jì)算機(jī)視覺(jué)的安全帽檢測(cè)算法。其中,基于計(jì)算機(jī)視覺(jué)的安全帽檢測(cè)算法又分為傳統(tǒng)安全帽檢測(cè)算法和基于深度學(xué)習(xí)的安全帽檢測(cè)算法。
基于傳感器的安全帽檢測(cè)算法主要依靠定位技術(shù)來(lái)檢測(cè)工人和安全帽,現(xiàn)有的基于傳感器的檢測(cè)和跟蹤技術(shù)需要每個(gè)施工人員佩戴物理標(biāo)簽或傳感器,這就會(huì)對(duì)工人的正常作業(yè)造成干擾,跟蹤設(shè)備通常都會(huì)有距離限制,并且投資成本很高。因此,該方法具有一定的局限性。傳統(tǒng)安全帽檢測(cè)算法大致可以分為三個(gè)階段:首先通過(guò)活動(dòng)窗口提取出候選區(qū)域。其次對(duì)這些候選區(qū)域進(jìn)行手工的特征提取,特征提取的方法包括Haar-like特征[1]、方向梯度直方圖(histogram of oriented gradient,HOG)[2]和局部二值模式(local binary pattern,LBP)[3]。最后使用AdaBoost[4]、支持向量機(jī)(support vector machine,SVM)[5]等方法進(jìn)行分類識(shí)別,進(jìn)而判斷作業(yè)人員是否佩戴安全帽。傳統(tǒng)安全帽檢測(cè)算法主要有三種:背景差法[6]、圓霍夫變換法[7]和DPM(deformable part model)算法[8]。目前,安全帽檢測(cè)大多應(yīng)用于監(jiān)控視頻中,由于攝像機(jī)放置位置不同,會(huì)產(chǎn)生近場(chǎng)、遠(yuǎn)場(chǎng)以及光照強(qiáng)度、背景復(fù)雜多變的安全帽特征。傳統(tǒng)安全帽檢測(cè)算法提取的特征基本都是低層次、人工選定的特征,不能夠很好地表達(dá)大量、多類目標(biāo)。算法基于滑動(dòng)窗口的區(qū)域選擇沒(méi)有針對(duì)性,使得大量窗口冗余,造成算法的時(shí)間復(fù)雜度高。以上缺陷導(dǎo)致傳統(tǒng)安全帽檢測(cè)算法的準(zhǔn)確性差且無(wú)法滿足實(shí)時(shí)性要求。
隨著深度學(xué)習(xí)的發(fā)展,利用卷積神經(jīng)網(wǎng)絡(luò)能夠提取更高層、表達(dá)能力更好的安全帽特征,相比于用人工選定的特征,極大地提高了安全帽實(shí)時(shí)檢測(cè)的準(zhǔn)確性。基于深度學(xué)習(xí)的目標(biāo)檢測(cè)算法已經(jīng)廣泛應(yīng)用于安全帽檢測(cè)任務(wù)當(dāng)中,具有很大的應(yīng)用價(jià)值。本文首先簡(jiǎn)述了傳統(tǒng)安全帽檢測(cè)算法并分析其局限性,提出安全帽檢測(cè)面臨的問(wèn)題;之后簡(jiǎn)介了當(dāng)前常用的基于深度學(xué)習(xí)的安全帽檢測(cè)算法的應(yīng)用情況,說(shuō)明了各類算法的優(yōu)缺點(diǎn),重點(diǎn)闡述了基于深度學(xué)習(xí)的安全帽檢測(cè)算法的改進(jìn)、優(yōu)勢(shì)以及存在的問(wèn)題;最后對(duì)安全帽檢測(cè)未來(lái)的研究方向進(jìn)行了分析和討論。
1 基于深度學(xué)習(xí)的兩階段安全帽檢測(cè)算法
基于深度學(xué)習(xí)的兩階段安全帽檢測(cè)算法按照兩階段目標(biāo)檢測(cè)算法的原則進(jìn)行檢測(cè),其最大的優(yōu)點(diǎn)是可以充分提取圖像的特征,對(duì)安全帽實(shí)現(xiàn)精確的分類和定位,針對(duì)小目標(biāo)安全帽的檢測(cè)效果很好,但由于需要分兩步進(jìn)行檢測(cè),檢測(cè)效率偏低。目前,在安全帽檢測(cè)任務(wù)中用到的兩階段目標(biāo)檢測(cè)算法有Faster R-CNN 和Cascade R-CNN。
2015年Ren等[9]提出的Faster R-CNN算法是由生成候選框的區(qū)域建議網(wǎng)絡(luò)(region proposal network,RPN)和Fast R-CNN目標(biāo)檢測(cè)算法兩個(gè)模塊組成。Faster RCNN 采用RPN 來(lái)代替Fast R-CNN 中使用分割算法生成候選框的方式,節(jié)約計(jì)算成本,真正地實(shí)現(xiàn)了端到端訓(xùn)練,對(duì)安全帽的檢測(cè)準(zhǔn)確度和檢測(cè)速度比傳統(tǒng)的目標(biāo)檢測(cè)算法提高很多,但由于兩階段的算法特性,其檢測(cè)效率較低。Fang等[10]提出了一種基于Faster R-CNN的自動(dòng)非硬帽使用(non-hardhat-use,NHU)檢測(cè)方法,研究分析了建筑工人的各種視覺(jué)條件,并根據(jù)視覺(jué)條件對(duì)圖像幀進(jìn)行分類,根據(jù)不同的視覺(jué)類別,將圖像幀輸入到Faster R-CNN 模型中進(jìn)行訓(xùn)練,得到了比傳統(tǒng)安全帽檢測(cè)算法精度更高、速度更快、能有效檢測(cè)不同施工現(xiàn)場(chǎng)條件下施工人員NHU 的安全帽檢測(cè)算法,但由于采用最原始的FasterR-CNN算法,只能運(yùn)用于對(duì)實(shí)時(shí)性要求不高的安全帽檢測(cè)任務(wù)中。僅僅依靠Faster R-CNN算法不能很好地實(shí)現(xiàn)安全帽佩戴的圖像和視頻檢測(cè)。針對(duì)該問(wèn)題,2020 年鄧開(kāi)發(fā)等[11]通過(guò)將Faster R-CNN目標(biāo)檢測(cè)模型和深度特征流算法(deep feature flow)[12]相結(jié)合,實(shí)現(xiàn)了對(duì)施工現(xiàn)場(chǎng)攝像頭監(jiān)控的視頻中安全帽的檢測(cè),該方法可以較好地實(shí)現(xiàn)安全帽佩戴的圖像和視頻檢測(cè)。但是對(duì)圖像和視頻中目標(biāo)被遮擋和光線變化多樣的目標(biāo)檢測(cè)效果不好,需要進(jìn)一步通過(guò)改進(jìn)Faster R-CNN網(wǎng)絡(luò)來(lái)提高檢測(cè)的準(zhǔn)確度。
針對(duì)兩階段目標(biāo)檢測(cè)算法中單個(gè)的IOU 閾值設(shè)定使得正負(fù)樣本不均衡導(dǎo)致檢測(cè)準(zhǔn)確度低的問(wèn)題,2018年Cai等[13]提出了Cascade R-CNN算法。該算法將對(duì)樣本的單閾值采樣改為多閾值采樣,它的重采樣機(jī)制保證了算法的每一個(gè)R-CNN 階段的檢測(cè)器都不會(huì)過(guò)擬合,提高了檢測(cè)效果。Cascade R-CNN與Faster R-CNN網(wǎng)絡(luò)結(jié)構(gòu)對(duì)比圖如圖1所示,其中“I”表示輸入圖片,“Conv”表示骨干卷積神經(jīng)網(wǎng)絡(luò),“Pool”表示按區(qū)域提取特征,“H”表示檢測(cè)頭,“B”表示邊界框,“C”表示分類類別。相比于Faster R-CNN,Cascade R-CNN 很大程度上提高了檢測(cè)準(zhǔn)確度,但僅能應(yīng)用于對(duì)檢測(cè)速度要求較低的安全帽檢測(cè)任務(wù)中。

圖1 Cascade R-CNN與Faster R-CNN網(wǎng)絡(luò)結(jié)構(gòu)對(duì)比圖Fig.1 Comparison of network structures between Cascade R-CNN and Faster R-CNN
隨著基于深度學(xué)習(xí)的目標(biāo)檢測(cè)算法的發(fā)展,施工現(xiàn)場(chǎng)安全帽檢測(cè)領(lǐng)域中所用到的算法也不斷地更新。由于兩階段安全帽檢測(cè)算法需要預(yù)先生成候選框,再對(duì)候選框進(jìn)行分類和回歸,邊界框經(jīng)過(guò)兩次微調(diào),檢測(cè)準(zhǔn)確度比單階段安全帽檢測(cè)算法要高,但損失了檢測(cè)速度。這就導(dǎo)致兩階段安全帽檢測(cè)算法不能夠適用于對(duì)速度要求極高的安全帽檢測(cè)任務(wù)。基于深度學(xué)習(xí)的兩階段安全帽檢測(cè)算法可以精準(zhǔn)地識(shí)別遠(yuǎn)處小目標(biāo)安全帽、遮擋的安全帽目標(biāo)以及處理光線變化等因素導(dǎo)致的檢測(cè)效果差的安全帽檢測(cè)問(wèn)題。然而面對(duì)復(fù)雜場(chǎng)景的施工現(xiàn)場(chǎng)中的安全帽檢測(cè)任務(wù),單階段安全帽檢測(cè)算法則體現(xiàn)了更高的應(yīng)用研究?jī)r(jià)值。
2 基于深度學(xué)習(xí)的單階段安全帽檢測(cè)算法
基于深度學(xué)習(xí)的單階段安全帽檢測(cè)算法模型結(jié)構(gòu)簡(jiǎn)單且檢測(cè)速度快,能夠很好地應(yīng)用于安全帽檢測(cè)任務(wù)中,與兩階段安全帽檢測(cè)算法相比,單階段安全帽檢測(cè)算法的檢測(cè)準(zhǔn)確度有所下降。目前,在安全帽檢測(cè)任務(wù)中常用的單階段目標(biāo)檢測(cè)算法包括YOLO 系列算法、SSD算法、RetinaNet和EfficientDet等。
2.1 YOLO系列安全帽檢測(cè)算法
用于安全帽檢測(cè)任務(wù)中的YOLO 系列算法包括YOLO、YOLOv2、YOLOv3、YOLOv4和YOLOv5算法。
2015 年Redmon 等[14]提出了YOLO(you only look once),該算法將對(duì)目標(biāo)的分類和定位問(wèn)題轉(zhuǎn)化為回歸問(wèn)題,YOLO網(wǎng)絡(luò)結(jié)構(gòu)由24個(gè)卷積層和2個(gè)全連接層構(gòu)成,通過(guò)整張圖訓(xùn)練網(wǎng)絡(luò)模型,能夠很好地區(qū)分檢測(cè)目標(biāo)和背景,通過(guò)劃分單元格的方式來(lái)檢測(cè)目標(biāo),大大提高了檢測(cè)速度。雖然YOLO 的檢測(cè)速度獲得了極大的提升,但是由于邊界框定位不準(zhǔn)確導(dǎo)致小目標(biāo)安全帽檢測(cè)效果差,存在小目標(biāo)安全帽漏檢的問(wèn)題。YOLOv2[15]采用YOLO劃分單元格的思想,使用由22個(gè)卷積層和5個(gè)池化層構(gòu)成的完全卷積網(wǎng)絡(luò)提取特征,與原始YOLO相比,去掉了dropout層,引入BN操作和錨機(jī)制,無(wú)全連接層,采用K-means聚類方法獲得錨框尺寸,在保持速度的同時(shí)提高了檢測(cè)準(zhǔn)確度。YOLOv2 較YOLO 對(duì)小目標(biāo)的檢測(cè)效果有所提升,但仍沒(méi)有解決小目標(biāo)安全帽漏檢、錯(cuò)檢的問(wèn)題。將YOLOv3 應(yīng)用于安全帽檢測(cè)任務(wù),極大地提高了對(duì)小目標(biāo)安全帽的檢測(cè)準(zhǔn)確度,同時(shí)檢測(cè)速度也有所提升。YOLOv3[16]相比于YOLOv2,采用基于殘差網(wǎng)絡(luò)的DarkNet-53來(lái)提取特征,無(wú)全連接層和池化層,對(duì)特征圖進(jìn)行8、16、32倍下采樣實(shí)現(xiàn)多尺度檢測(cè),使得網(wǎng)絡(luò)的檢測(cè)準(zhǔn)確度更高,同時(shí)加快了檢測(cè)速度。為了實(shí)現(xiàn)復(fù)雜場(chǎng)景下對(duì)工作人員是否佩戴安全帽的實(shí)時(shí)檢測(cè),2019年林俊等[17]提出將YOLOv3應(yīng)用于安全帽檢測(cè),針對(duì)未佩戴安全帽單類檢測(cè)問(wèn)題,修改分類器,將輸出修改為18維度的張量,將YOLOv3在ImageNet上進(jìn)行預(yù)訓(xùn)練得到預(yù)訓(xùn)練模型,然后再在自制數(shù)據(jù)集上進(jìn)行訓(xùn)練并優(yōu)化調(diào)參,最終得到的安全帽檢測(cè)模型檢測(cè)準(zhǔn)確率可達(dá)98.7%,平均檢測(cè)速度達(dá)到了35 frame/s,滿足實(shí)時(shí)性的檢測(cè)要求。總體來(lái)說(shuō)采用YOLOv3 算法作為安全帽檢測(cè)的基礎(chǔ),通過(guò)在自制數(shù)據(jù)集上進(jìn)行訓(xùn)練,獲得一個(gè)最優(yōu)的模型,并對(duì)作業(yè)人員安全帽佩戴情況進(jìn)行有效的檢測(cè),該方法的檢測(cè)準(zhǔn)確率大多超過(guò)了90%,滿足實(shí)際需求。雖然YOLOv3 提升了對(duì)小目標(biāo)安全帽的檢測(cè)效果,但對(duì)一些人員密集環(huán)境下重疊安全帽檢測(cè)仍然存在漏檢、錯(cuò)檢的問(wèn)題。2020 年Bochkovskiy 等[18]提出YOLOv4,該算法提高了對(duì)重疊安全帽檢測(cè)性能,并且在檢測(cè)速度和檢測(cè)準(zhǔn)確率平衡方面優(yōu)于之前的YOLO系列算法,更適用于安全帽檢測(cè)任務(wù)。與YOLOv3 相比,雖然平衡了模型的檢測(cè)精度和速度,但YOLOv4 的模型尺寸大,檢測(cè)速度要慢,且無(wú)法將其應(yīng)用于小型設(shè)備中。2021 年朱夏晗瀟[19]提出一種基于YOLOv4 的安全帽應(yīng)用檢測(cè)方法。先通過(guò)機(jī)器人進(jìn)行視頻數(shù)據(jù)采集,再經(jīng)過(guò)訓(xùn)練好的YOLOv4模型判斷頭部和安全帽位置,之后判斷出行為人是否佩戴安全帽。通過(guò)在自制的數(shù)據(jù)集上進(jìn)行訓(xùn)練測(cè)試,網(wǎng)絡(luò)模型的平均精度均值可達(dá)91.7%,分別比Faster R-CNN和YOLOv3提高了7.2%和4.1%。YOLOv5沿用了YOLOv4的網(wǎng)絡(luò)結(jié)構(gòu),同樣采用了Mosaic數(shù)據(jù)增強(qiáng)方法,采用自適應(yīng)錨框,檢測(cè)速度很快,集成了YOLOv3 和YOLOv4 的部分特性,檢測(cè)速度遠(yuǎn)超YOLOv4,有多種網(wǎng)絡(luò)結(jié)構(gòu),具有更高的靈活性。為了實(shí)時(shí)監(jiān)控相關(guān)人員是否佩戴安全帽,2021年Yi等[20]采用YOLOv5 目標(biāo)檢測(cè)算法檢測(cè)復(fù)雜場(chǎng)景中作業(yè)人員安全帽佩戴情況,可以準(zhǔn)確檢測(cè)處于運(yùn)動(dòng)狀態(tài)中的作業(yè)人員,對(duì)于遮擋的安全帽也有很好的檢測(cè)效果,檢測(cè)準(zhǔn)確度達(dá)到了92.4%。但將YOLOv5 模型應(yīng)用于小型的嵌入式安全帽檢測(cè)設(shè)備中,還需對(duì)YOLOv5模型的網(wǎng)絡(luò)結(jié)構(gòu)做進(jìn)一步改進(jìn)。目前,YOLO系列安全帽檢測(cè)算法的應(yīng)用比較廣泛,由于YOLO算法的更新,其中YOLOv3及YOLOv4在安全帽檢測(cè)領(lǐng)域最為常見(jiàn)。
由于單階段安全帽檢測(cè)算法不需要預(yù)先生成候選區(qū)域,直接對(duì)圖像的各個(gè)位置進(jìn)行分類和回歸,檢測(cè)速度較兩階段安全帽檢測(cè)算法有所提升,但同時(shí)也損失了檢測(cè)精度。雖然YOLO系列算法經(jīng)過(guò)一步步的更新,對(duì)小目標(biāo)安全帽檢測(cè)效果有所提升,尤其是在檢測(cè)速度方面有顯著的進(jìn)步,但是針對(duì)遮擋、光線變化環(huán)境中的小目標(biāo)安全帽的檢測(cè)準(zhǔn)確度還是不高。SSD 安全帽檢測(cè)算法則平衡了兩階段檢測(cè)算法檢測(cè)精度高但檢測(cè)速度慢,和YOLO系列算法檢測(cè)速度快但對(duì)小目標(biāo)安全帽檢測(cè)效果不佳的問(wèn)題。
2.2 SSD安全帽檢測(cè)算法
2016 年Liu 等[21]提出SSD(single-shot multibox detector)算法,該算法結(jié)合了Faster R-CNN和YOLO的思想,采用修改的VGG作為骨干網(wǎng)絡(luò),有效地運(yùn)用多尺度特征圖預(yù)測(cè)的思想,可以有效地檢測(cè)到相對(duì)較小的目標(biāo),檢測(cè)速度方面可以和YOLO 相媲美,檢測(cè)準(zhǔn)確度方面可以和Faster R-CNN相媲美。SSD算法可以很好地解決安全帽檢測(cè)中背景復(fù)雜且干擾性強(qiáng)和待檢測(cè)目標(biāo)較小的問(wèn)題。但隨著SSD算法復(fù)雜度增加,檢測(cè)速度也會(huì)大幅度下降,難以應(yīng)用于檢測(cè)速度要求較高的安全帽檢測(cè)任務(wù),并且算法模型難以應(yīng)用到儲(chǔ)存和計(jì)算能力有限的嵌入式設(shè)備中。在現(xiàn)有的SSD安全帽檢測(cè)算法中,研究人員大多是將改進(jìn)的SSD 算法應(yīng)用在安全帽檢測(cè)任務(wù)中。
2.3 新型的單階段安全帽檢測(cè)算法
除了上述單階段目標(biāo)檢測(cè)算法之外,一些新型的單階段目標(biāo)檢測(cè)算法也逐漸運(yùn)用到了安全帽檢測(cè)任務(wù)當(dāng)中。2017 年Lin 等[22]提出的RetinaNet 指出了正負(fù)樣本不平衡的問(wèn)題是導(dǎo)致單階段目標(biāo)檢測(cè)算法的檢測(cè)準(zhǔn)確度普遍低于兩階段目標(biāo)檢測(cè)算法的原因,采用加權(quán)的交叉熵?fù)p失函數(shù),稱為焦點(diǎn)損失(focal loss,F(xiàn)L),可以減少正確檢測(cè)框的損失。該算法基于ResNet和特征金字塔網(wǎng)絡(luò)(feature pyramid networks,F(xiàn)PN)[23]構(gòu)建特征提取網(wǎng)絡(luò),實(shí)現(xiàn)了多尺度檢測(cè),達(dá)到了與兩階段目標(biāo)檢測(cè)算法相當(dāng)?shù)臋z測(cè)準(zhǔn)確度,同時(shí)保持了檢測(cè)速度。2021年王雨生等[24]提出一種基于姿態(tài)估計(jì)的安全帽佩戴檢測(cè)方法。使用RetinaNet 檢測(cè)頭部區(qū)域安全帽的佩戴情況,解決了安全帽與復(fù)雜施工場(chǎng)景類極不平衡的問(wèn)題,網(wǎng)絡(luò)模型的平均精度均值可達(dá)97.1%,分別比Faster RCNN 和YOLOv3 提高了9.53%和2.8%,但檢測(cè)速度要遜于YOLOv3。2019年Duan等[25]提出的CenterNet針對(duì)CornerNet[26]不能很好地參考被檢測(cè)對(duì)象全局信息而產(chǎn)生部分誤檢的問(wèn)題,在CornerNet 的基礎(chǔ)上增加了感知視覺(jué)模式,通過(guò)中心點(diǎn)池化來(lái)預(yù)測(cè)對(duì)象的中心點(diǎn),通過(guò)判斷檢測(cè)框的中心區(qū)域是否有預(yù)測(cè)的中心點(diǎn)來(lái)消除錯(cuò)誤的檢測(cè)框,提高了檢測(cè)準(zhǔn)確度,但難以解決兩個(gè)不同的重合中心點(diǎn)的問(wèn)題,對(duì)重合安全帽檢測(cè)效果差。2020年Tan 等[27]提出了EfficientDet,該算法由特征提取網(wǎng)絡(luò)EfficientNet 和面向多目標(biāo)檢測(cè)的加權(quán)雙向特征金字塔網(wǎng)絡(luò)構(gòu)成,解決了網(wǎng)絡(luò)的深度、寬度和分辨率值檢測(cè)不平衡問(wèn)題,提高了生成模型的泛化能力。該算法的網(wǎng)絡(luò)結(jié)構(gòu)可以實(shí)現(xiàn)多尺度的特征融合,對(duì)小目標(biāo)安全帽的檢測(cè)起到了顯著作用,但由于網(wǎng)絡(luò)模型的復(fù)雜度增大,使得檢測(cè)速度有所降低。2020 年梅國(guó)新等[28]提出了基于EfficientDet 的用于檢測(cè)邊緣環(huán)境下面向復(fù)雜監(jiān)控視頻背景的安全帽檢測(cè)算法。通過(guò)在SHWD公開(kāi)數(shù)據(jù)集上進(jìn)行訓(xùn)練測(cè)試,網(wǎng)絡(luò)模型檢測(cè)平均精度均值最高可達(dá)92%,比YOLOv3提高了20%,檢測(cè)速度達(dá)到15 frame/s,但檢測(cè)速度比YOLOv3 要低。EfficientDet 模型克服了檢測(cè)目標(biāo)存在明顯遮擋、重疊度高和圖像分辨率低的問(wèn)題,取得了比較好的檢測(cè)效果,同時(shí)模型所占空間較小,為模型部署在邊緣計(jì)算環(huán)境上提供了可能,但在檢測(cè)速度方面還有較大的提升空間。其他未改進(jìn)的單階段安全帽檢測(cè)算法的具體應(yīng)用見(jiàn)表1。
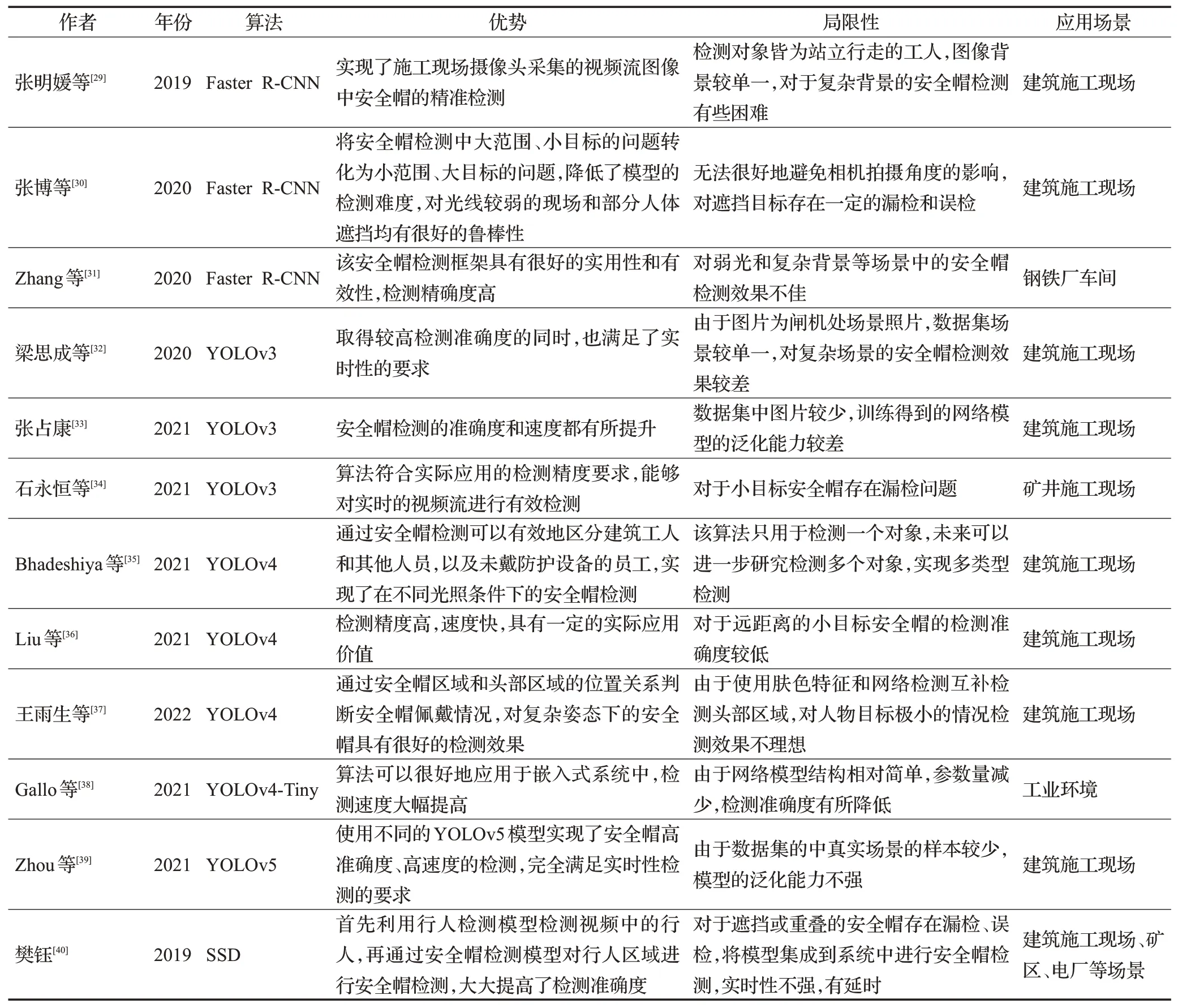
表1 無(wú)改進(jìn)的基于深度學(xué)習(xí)的安全帽檢測(cè)算法Table 1 No improved helmet detection algorithm based on deep learning
3 基于深度學(xué)習(xí)的安全帽檢測(cè)算法的改進(jìn)及應(yīng)用
僅僅將原始的基于深度學(xué)習(xí)的目標(biāo)檢測(cè)算法應(yīng)用于安全帽檢測(cè)任務(wù)中具有一定的局限性,研究人員提出了一系列的改進(jìn)方法。具體方法包括:優(yōu)化Anchor Box、優(yōu)化骨干網(wǎng)絡(luò)、特征融合、引入注意力機(jī)制、優(yōu)化非極大值抑制算法、引入在線困難樣本挖掘策略和優(yōu)化損失函數(shù)等。
3.1 優(yōu)化Anchor Box
優(yōu)化Anchor Box[41]也就是對(duì)錨點(diǎn)數(shù)量或錨點(diǎn)尺寸的調(diào)整,在基于深度學(xué)習(xí)的兩階段安全帽檢測(cè)算法和單階段安全帽檢測(cè)算法中都使用了優(yōu)化Anchor Box的改進(jìn)方法。兩階段安全帽檢測(cè)算法中RPN的錨點(diǎn)數(shù)量是網(wǎng)絡(luò)中的一個(gè)超參數(shù),直接影響后續(xù)候選區(qū)域的生成。由于在安全帽檢測(cè)任務(wù)中,需要檢測(cè)安全帽、人員等多個(gè)目標(biāo),尤其是向安全帽這種局部的目標(biāo)檢測(cè),小目標(biāo)是無(wú)法避免的,網(wǎng)絡(luò)默認(rèn)的錨點(diǎn)參數(shù)較大,無(wú)法對(duì)小目標(biāo)安全帽進(jìn)行很好的識(shí)別,因此需要對(duì)網(wǎng)絡(luò)默認(rèn)的參數(shù)進(jìn)行修改或增加。通過(guò)優(yōu)化Anchor Box的改進(jìn)方式可以有效地解決安全帽檢測(cè)算法對(duì)部分遮擋、尺寸不一和小目標(biāo)存在檢測(cè)難度大的問(wèn)題。2020 年徐守坤等[42]提出了一種改進(jìn)的Faster R-CNN安全帽檢測(cè)算法。針對(duì)施工現(xiàn)場(chǎng)安全帽檢測(cè)任務(wù)中的小目標(biāo),在網(wǎng)絡(luò)默認(rèn)錨點(diǎn)數(shù)量的基礎(chǔ)上,加入了一組64×64 錨點(diǎn),使得網(wǎng)絡(luò)可以檢測(cè)到更多的小目標(biāo)安全帽。原始的Faster R-CNN使用9 個(gè)錨點(diǎn),而改進(jìn)之后錨點(diǎn)數(shù)量增加到了12 個(gè),分別對(duì)應(yīng)64×64、128×128、256×256 和512×512 這四個(gè)尺度大小。通過(guò)在自制的數(shù)據(jù)集上進(jìn)行訓(xùn)練測(cè)試,檢測(cè)精確度提升了0.79%。該改進(jìn)方法增強(qiáng)了網(wǎng)絡(luò)檢測(cè)不同尺寸目標(biāo)的魯棒性,通過(guò)增加錨點(diǎn)數(shù)量和修改錨框的尺寸,使RPN 得到可以覆蓋安全帽佩戴檢測(cè)所有尺寸的目標(biāo)框,提高了安全帽的佩戴檢測(cè)精度,對(duì)多尺寸目標(biāo)和小目標(biāo)均有較好的檢測(cè)效果,但由于人員的姿態(tài)有所不同,此模型只能粗略地選取安全帽的相對(duì)位置,泛化性不高。在單階段安全帽檢測(cè)算法中采用的是K-means聚類算法[43]對(duì)安全帽數(shù)據(jù)集進(jìn)行聚類分析,對(duì)目標(biāo)框的大小進(jìn)行分類,輸出先驗(yàn)框的尺寸,從而達(dá)到優(yōu)化網(wǎng)絡(luò)內(nèi)部初始錨框的目的。由于在安全帽檢測(cè)任務(wù)中收集的安全帽數(shù)據(jù)集有所不同,原網(wǎng)絡(luò)結(jié)構(gòu)中的錨框尺寸參數(shù)不能滿足安全帽數(shù)據(jù)集的檢測(cè)要求,這就需要對(duì)安全帽數(shù)據(jù)集重新進(jìn)行聚類,選擇合適的先驗(yàn)框。針對(duì)施工現(xiàn)場(chǎng)遠(yuǎn)景視野下安全帽目標(biāo)較小的特點(diǎn),常增加特征圖尺度個(gè)數(shù),再進(jìn)行聚類得到先驗(yàn)框的尺寸。2021 年鄭曉等[44]設(shè)計(jì)實(shí)現(xiàn)了一種基于深度學(xué)習(xí)的安全帽檢測(cè)智能監(jiān)管系統(tǒng),系統(tǒng)采用YOLOv4 目標(biāo)檢測(cè)模型,在數(shù)據(jù)集上使用K-means算法聚類分析生成新的先驗(yàn)框,并使用新的先驗(yàn)框進(jìn)行訓(xùn)練。該模型的檢測(cè)精度可達(dá)92%,大大提高了工程現(xiàn)場(chǎng)的生產(chǎn)安全系數(shù)和監(jiān)管效率,但在實(shí)際應(yīng)用當(dāng)中,對(duì)數(shù)據(jù)集進(jìn)行聚類分析得到的先驗(yàn)框尺寸不滿足待檢測(cè)的安全帽的大小,導(dǎo)致對(duì)小目標(biāo)安全帽的檢測(cè)效果較差。
由于使用的安全帽檢測(cè)數(shù)據(jù)集有較大差異,除了采用原模型中K-means聚類算法在新數(shù)據(jù)集上重新聚類得到先驗(yàn)框的尺寸之外,還可以對(duì)聚類算法進(jìn)行優(yōu)化改進(jìn),應(yīng)用到安全帽檢測(cè)算法中,得到更加精確的先驗(yàn)框的尺寸大小,進(jìn)而達(dá)到優(yōu)化Anchor Box的目的,提高模型的檢測(cè)效果,優(yōu)化聚類算法是優(yōu)化Anchor Box 的一種有效方式。然而對(duì)于密度不均勻的安全帽檢測(cè)數(shù)據(jù)集,聚類效果不是很好。原始的K-means聚類算法,是隨機(jī)選取數(shù)據(jù)集中K個(gè)點(diǎn)作為聚類中心,這種隨機(jī)選取的方式導(dǎo)致聚類得到的先驗(yàn)框的尺寸不夠準(zhǔn)確。2021年孫世丹等[45]對(duì)網(wǎng)絡(luò)模型中的聚類算法進(jìn)行優(yōu)化,使用加權(quán)核K-means聚類算法對(duì)訓(xùn)練數(shù)據(jù)集聚類分析,選取更適合小目標(biāo)檢測(cè)的Anchor Box,提高了檢測(cè)的平均精度和速度。改進(jìn)之后的網(wǎng)絡(luò)模型檢測(cè)的平均準(zhǔn)確率可達(dá)到93.5%,比原YOLOv3 提高了7.6%,檢測(cè)速度達(dá)到45 frame/s,但該算法的改進(jìn)同樣是針對(duì)安全帽檢測(cè)數(shù)據(jù)集的聚類分析,對(duì)于現(xiàn)實(shí)中的安全帽并不完全適用,對(duì)極端大小的安全帽存在漏檢、誤檢問(wèn)題。
優(yōu)化Anchor Box的改進(jìn)方式僅僅是通過(guò)對(duì)安全帽圖像中的目標(biāo)框進(jìn)行尺寸判斷,進(jìn)而細(xì)化特征圖中的錨框,從而提高了對(duì)安全帽的檢測(cè)效果,但對(duì)小目標(biāo)的檢測(cè)效果有限,要想真正地提高檢測(cè)性能,需對(duì)骨干網(wǎng)絡(luò)進(jìn)行改進(jìn)或替換,提高模型的特征提取能力,使小目標(biāo)在特征圖上更好地表達(dá)出來(lái),從而提升模型的檢測(cè)準(zhǔn)確率。
3.2 優(yōu)化骨干網(wǎng)絡(luò)
骨干網(wǎng)絡(luò)(backbone)作為目標(biāo)檢測(cè)模型中的特征提取器,特征提取的效果往往直接影響目標(biāo)檢測(cè)的性能。兩階段目標(biāo)檢測(cè)中常見(jiàn)的骨干網(wǎng)絡(luò)有SPPNet[46]、VGG-Net[47]和ResNet[48]等。原始Faster R-CNN 算法的骨干網(wǎng)絡(luò)為VGG,它采用頂層特征做預(yù)測(cè)會(huì)導(dǎo)致底層的位置信息丟失,對(duì)深層次的特征信息學(xué)習(xí)能力不足,降低模型對(duì)小目標(biāo)安全帽的檢測(cè)準(zhǔn)確度,提高特征提取能力需要更多的網(wǎng)絡(luò)層數(shù),但增加網(wǎng)絡(luò)層數(shù)會(huì)加大模型損耗。RestNet網(wǎng)絡(luò)可以很好地解決由于卷積層加深而導(dǎo)致的模型退化的問(wèn)題。在安全帽檢測(cè)任務(wù)當(dāng)中,研究人員通過(guò)優(yōu)化骨干網(wǎng)絡(luò),采用ResNet代替原來(lái)的VGG-Net,從而達(dá)到很好的檢測(cè)效果。為了解決Faster R-CNN算法在對(duì)小物體檢測(cè)性能方面魯棒性差的問(wèn)題,2019年周展博[49]摒棄了原始的VGG-16 基礎(chǔ)網(wǎng)絡(luò),提出將101 層堆疊的殘差學(xué)習(xí)模塊組成的ResNet-101 網(wǎng)絡(luò)作為新的基礎(chǔ)網(wǎng)絡(luò)。該改進(jìn)方法提升了安全帽佩戴的檢測(cè)精度,但由于采用更深網(wǎng)絡(luò)結(jié)構(gòu)的ResNet以達(dá)到更好的檢測(cè)準(zhǔn)確度,網(wǎng)絡(luò)模型的復(fù)雜性更高,在檢測(cè)速度上未達(dá)到實(shí)時(shí)性級(jí)別。
除了兩階段目標(biāo)檢測(cè)算法中常用的VGG、ResNet和SPPNet 骨干網(wǎng)絡(luò)之外,單階段目標(biāo)檢測(cè)算法還用到了MobileNet[50]、DenseNet[51]等。YOLO系列算法采用層數(shù)結(jié)構(gòu)不同的DarkNet 來(lái)提取特征,網(wǎng)絡(luò)結(jié)構(gòu)變得復(fù)雜,參數(shù)量也會(huì)隨之增加,導(dǎo)致檢測(cè)速度慢,內(nèi)存消耗大且對(duì)硬件性能要求很高的問(wèn)題,不利于安全帽的實(shí)時(shí)性檢測(cè)。深度可分離卷積網(wǎng)絡(luò)將區(qū)域和通道分開(kāi)計(jì)算,并且對(duì)不同的通道進(jìn)行獨(dú)立卷積操作,可以大大減小模型的參數(shù)量和運(yùn)算量,得到一個(gè)輕量化的模型。2020年朱曉春等[52]提出了改進(jìn)的基于YOLOv3 的安全帽檢測(cè)算法,通過(guò)深度可分離卷積對(duì)DarkNet 網(wǎng)絡(luò)結(jié)構(gòu)進(jìn)行改進(jìn),優(yōu)化了骨干網(wǎng)絡(luò),減少了模型的參數(shù)量,相對(duì)于標(biāo)準(zhǔn)卷積運(yùn)算,降低了模型的計(jì)算量,網(wǎng)絡(luò)結(jié)構(gòu)如圖2 所示。該改進(jìn)算法的檢測(cè)準(zhǔn)確率可達(dá)89.67%,檢測(cè)速度為105 frame/s,檢測(cè)速度提高了兩倍,但由于模型參數(shù)量的減少,網(wǎng)絡(luò)結(jié)構(gòu)相對(duì)簡(jiǎn)單,并沒(méi)有提高模型的檢測(cè)準(zhǔn)確率。
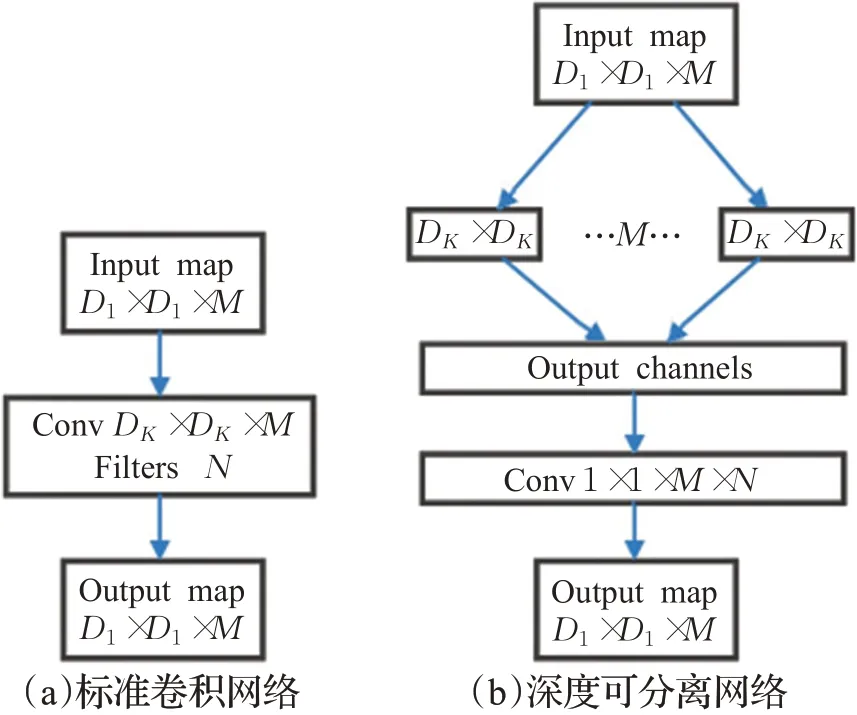
圖2 網(wǎng)絡(luò)結(jié)構(gòu)Fig.2 Network structure
實(shí)際安全帽檢測(cè)環(huán)境下需要把網(wǎng)絡(luò)模型部署在算力有限的移動(dòng)端或嵌入式設(shè)備中,但將體積偏大的原YOLOv5模型嵌入到設(shè)備中,會(huì)導(dǎo)致設(shè)備無(wú)法支持復(fù)雜的計(jì)算量的問(wèn)題。2021 年蔣潤(rùn)熙等[53]提出了一種適合部署在移動(dòng)設(shè)備上的輕量級(jí)目標(biāo)檢測(cè)網(wǎng)絡(luò)HourGlass-YOLO(HG-YOLO)。該算法以YOLOv5 為基礎(chǔ)模型,重構(gòu)了新的骨干網(wǎng)絡(luò)來(lái)替換原骨干網(wǎng)絡(luò),并使用了通道剪枝技術(shù),在保證精度的情況下,減少了模型的參數(shù)。通過(guò)在公開(kāi)數(shù)據(jù)集SHWD 上進(jìn)行訓(xùn)練測(cè)試,網(wǎng)絡(luò)模型的平均精度均值可達(dá)94.4%,雖然檢測(cè)準(zhǔn)確度不如原YOLOv5模型,但檢測(cè)速度達(dá)到9.5 frame/s,參數(shù)量達(dá)到了最少,可以更好地將算法部署在低端設(shè)備,然而由于融合卷積層與批量歸一化層,減少了網(wǎng)絡(luò)層數(shù)和參數(shù)量,使得模型對(duì)小目標(biāo)安全帽的檢測(cè)會(huì)出現(xiàn)漏檢情況。VGG作為SSD的基礎(chǔ)網(wǎng)絡(luò)對(duì)SSD算法的檢測(cè)性能有重要影響,MobileNet網(wǎng)絡(luò)在參數(shù)量、計(jì)算量和訪存量上都要比VGG 小得多,因此在一些特別的安全帽檢測(cè)任務(wù)中,MobileNet 更加適合。針對(duì)在安全帽檢測(cè)任務(wù)中SSD 模型在不使用GPU 加速時(shí)檢測(cè)速度緩慢、內(nèi)存消耗大以及計(jì)算復(fù)雜度高的問(wèn)題,2020年張麗[54]引入輕量型MobileNet來(lái)替換SSD中的VGG網(wǎng)絡(luò),網(wǎng)絡(luò)模型檢測(cè)速度比原SSD 提高了兩倍。改進(jìn)的SSD 安全帽檢測(cè)算法大幅度提高了檢測(cè)速度,但其精度卻有所損失,因此,在檢測(cè)速度加快的同時(shí)保持檢測(cè)精度還需要進(jìn)一步的研究。
雖然優(yōu)化骨干網(wǎng)絡(luò)后的檢測(cè)精度得到了大幅提升,但目前骨干網(wǎng)絡(luò)仍存在模型復(fù)雜等問(wèn)題,施工現(xiàn)場(chǎng)安全帽檢測(cè)大多面臨復(fù)雜背景環(huán)境,僅僅替換骨干網(wǎng)絡(luò)對(duì)安全帽小目標(biāo)的特征提取能力還是不足。如果說(shuō)優(yōu)化骨干網(wǎng)絡(luò)屬于從大結(jié)構(gòu)上來(lái)改進(jìn)網(wǎng)絡(luò)模型,從而提高特征提取效果,那么特征融合則屬于從細(xì)節(jié)上進(jìn)一步提高模型的特征提取性能。
3.3 特征融合
基于深度學(xué)習(xí)的目標(biāo)檢測(cè)算法一般關(guān)注的是中、大目標(biāo),利用卷積神經(jīng)網(wǎng)絡(luò)提取深層次的特征,具有很好的檢測(cè)性能。但對(duì)于安全帽檢測(cè)任務(wù)中的小目標(biāo),深層卷積神經(jīng)網(wǎng)絡(luò)的尺寸小且感受野較大,使得小目標(biāo)會(huì)被漏檢,淺層卷積神經(jīng)網(wǎng)絡(luò)雖然感受野小,但目標(biāo)特征不強(qiáng),置信度較低,在檢測(cè)過(guò)程中也會(huì)被舍棄。特征融合就是將深層和淺層的卷積特征進(jìn)行融合,使得產(chǎn)生的候選區(qū)域特征同時(shí)具有高分辨率特征圖的位置信息和低分辨率特征圖的語(yǔ)義信息,再由RPN 網(wǎng)絡(luò)分別預(yù)測(cè)達(dá)到多尺度檢測(cè)的目的,從而提高網(wǎng)絡(luò)對(duì)小目標(biāo)的檢測(cè)能力。但是僅僅采用特征融合的方法都會(huì)損失一定的檢測(cè)速度,研究人員有時(shí)會(huì)將特征融合方法與其他改進(jìn)方法配合使用以達(dá)到最好的檢測(cè)效果。2020年吳冬梅等[55]提出了一種基于改進(jìn)的Faster R-CNN的安全帽佩戴檢測(cè)及身份識(shí)別方法,通過(guò)將骨干網(wǎng)絡(luò)中的5個(gè)網(wǎng)絡(luò)階段的特征圖進(jìn)行融合,如圖3 所示,并將多尺寸的特征圖分別輸入到RPN網(wǎng)絡(luò)中,完成特征融合和多尺度檢測(cè),改進(jìn)之后的網(wǎng)絡(luò)的平均精度均值比原模型提高了16.8%。該改進(jìn)方法在安全帽特征提取時(shí)能充分利用所有特征層信息,大大提升了安全帽檢測(cè)效果,但由于進(jìn)行了5個(gè)階段的特征融合,增加了模型的復(fù)雜度,使得模型的檢測(cè)速度有所降低。針對(duì)施工現(xiàn)場(chǎng)作業(yè)場(chǎng)景的復(fù)雜環(huán)境,由于工人所佩戴的安全帽在圖像中所占的像素較少,導(dǎo)致使用卷積神經(jīng)網(wǎng)絡(luò)提取的特征質(zhì)量不高,極大地影響了檢測(cè)模型的檢測(cè)精度。2021年Jin等[56]采用基于特征融合的Faster R-CNN 算法實(shí)現(xiàn)了工人安全帽佩戴檢測(cè),利用特征映射融合方法獲得特征信息更豐富的特征映射,然后利用特征映射對(duì)檢測(cè)模型進(jìn)行訓(xùn)練,檢測(cè)準(zhǔn)確率可達(dá)96%,能有效地檢測(cè)出工人安全帽佩戴情況。

圖3 特征融合金字塔Fig.3 Feature fusion pyramid
在單階段安全帽檢測(cè)算法中,采用特征融合使得網(wǎng)絡(luò)可以得到包含豐富位置信息和語(yǔ)義信息的特征,獲得不同尺度的特征圖,從而提高網(wǎng)絡(luò)模型對(duì)小目標(biāo)的檢測(cè)準(zhǔn)確度,增強(qiáng)網(wǎng)絡(luò)的魯棒性。針對(duì)安全帽檢測(cè)場(chǎng)景中環(huán)境復(fù)雜、光照不均勻等各類環(huán)境問(wèn)題,2019 年何超[57]通過(guò)對(duì)YOLOv3算法進(jìn)行改進(jìn),提出了一種新的特征融合算法,其主要網(wǎng)絡(luò)結(jié)構(gòu)是深度殘差網(wǎng)絡(luò),在YOLOv3 的主網(wǎng)絡(luò)之后又增加了1個(gè)卷積層,并同淺層的殘差網(wǎng)絡(luò)做特征融合,從而將網(wǎng)絡(luò)從3 個(gè)尺度擴(kuò)展為4 個(gè)尺度卷積層的特征金字塔,然后對(duì)特征金字塔進(jìn)行2 倍上采樣,與前面的深度殘差網(wǎng)絡(luò)進(jìn)行融合,形成深度融合的快速安全帽檢測(cè)模型。該網(wǎng)絡(luò)模型的平均精度均值可達(dá)93.61%,比原網(wǎng)絡(luò)提升了4.51%。但由于有些安全帽檢測(cè)中的背景較復(fù)雜,多尺度檢測(cè)利用高分辨率特征會(huì)引入過(guò)多的背景噪聲,容易造成模型收斂速度緩慢的結(jié)果。2021年肖體剛等[58]提出一種基于改進(jìn)SSD的安全帽佩戴快速檢測(cè)算法。通過(guò)將SSD中的骨干網(wǎng)絡(luò)VGG-16替換為輕量型卷積神經(jīng)網(wǎng)絡(luò)MobileNetV3-small,減少了模型的參數(shù),同時(shí)使用特征金字塔結(jié)構(gòu)將深層特征與淺層特征進(jìn)行融合,提升了檢測(cè)精度,網(wǎng)絡(luò)模型的平均精確率可達(dá)91.1%,基于GPU的檢測(cè)速度為108 frame/s,該改進(jìn)方法不論是檢測(cè)速度還是精度都優(yōu)于原SSD算法。
采用特征融合的方式進(jìn)行安全帽檢測(cè)能夠?qū)踩碧卣鲌D中的深層特征和淺層特征結(jié)合起來(lái),得到多尺度的特征,但特征融合使得特征之間的信息交互不完全,提取特征的相關(guān)性不強(qiáng)。而注意力機(jī)制通過(guò)分配不同的權(quán)重來(lái)獲得安全帽特征信息,具有很好的特征表達(dá)效果,使得提取的特征的相關(guān)性更強(qiáng),更大程度地提高安全帽檢測(cè)性能。
3.4 引入注意力機(jī)制
安全帽檢測(cè)算法的特征提取環(huán)節(jié)尤為重要,在神經(jīng)網(wǎng)絡(luò)中,注意力機(jī)制[59]是根據(jù)關(guān)注對(duì)象的重要程度進(jìn)行不同的資源分配,注意力分配的資源也就是權(quán)重。在卷積神經(jīng)網(wǎng)絡(luò)當(dāng)中,卷積核是局部的,為了增大感受野,采用堆疊卷積層的方式將卷積核和原始特征進(jìn)行線性組合得到輸出特征,但是這種方式的效率很低。引入注意力機(jī)制可以獲得全局信息并選擇出對(duì)當(dāng)前任務(wù)目標(biāo)更關(guān)鍵的信息,具有很好的特征表達(dá)效果,這就使得提取的特征的相關(guān)性更強(qiáng),捕獲到更豐富的高級(jí)語(yǔ)義信息,進(jìn)而提高檢測(cè)性能,但引入注意力機(jī)制后模型的參數(shù)量也會(huì)隨之增加,加大網(wǎng)絡(luò)的計(jì)算量,進(jìn)而降低模型的收斂速度。2022 年孫國(guó)棟等[60]提出了一種基于Faster RCNN的融合注意力機(jī)制的安全帽檢測(cè)算法。該算法通過(guò)自注意力層來(lái)捕獲多個(gè)尺度上的全局信息,得到更豐富的高層特征并將更大的感受野范圍引入模型,采用ResNet-101 代替原來(lái)的VGG-16 骨干網(wǎng)絡(luò),同時(shí)采用錨點(diǎn)補(bǔ)選增強(qiáng)的方法,強(qiáng)化了網(wǎng)絡(luò)對(duì)小尺度目標(biāo)的表達(dá)能力。改進(jìn)之后的網(wǎng)絡(luò)模型的平均精度均值可達(dá)94.3%,比傳統(tǒng)的Faster R-CNN提高了6.4%。引入注意力機(jī)制的改進(jìn)方法對(duì)不同施工現(xiàn)場(chǎng)的安全帽檢測(cè)任務(wù)有著較好的檢測(cè)效果,但采用注意力機(jī)制需要矩陣來(lái)存儲(chǔ)注意力權(quán)重,增大模型的參數(shù)量,檢測(cè)速度有所降低。引入注意力機(jī)制的改進(jìn)方法同樣適用于單階段目標(biāo)檢測(cè)算法,自注意力模塊通過(guò)計(jì)算輸出特征圖每個(gè)像素點(diǎn)之間的相互影響,改變每個(gè)網(wǎng)絡(luò)層之間的感受野,從而讓網(wǎng)絡(luò)在向前傳播的過(guò)程中感受野不斷增加,使得檢測(cè)算法具有全局性和可靠性。施工現(xiàn)場(chǎng)的復(fù)雜環(huán)境中存在的弱小目標(biāo)與遮擋目標(biāo)大多難以得到有效檢測(cè),針對(duì)該問(wèn)題,2021年李天宇等[61]在YOLOv3的基礎(chǔ)上建立了一種基于注意力機(jī)制的雙向特征金字塔的安全帽檢測(cè)卷積神經(jīng)網(wǎng)絡(luò)。為了準(zhǔn)確檢測(cè)戴安全帽的工人,減少網(wǎng)絡(luò)特征損失,引入了雙向特征融合的特征金字塔網(wǎng)絡(luò)PANet,提高了對(duì)弱小目標(biāo)的定位準(zhǔn)確性;為了減少遮擋目標(biāo)被誤檢,在特征金字塔網(wǎng)絡(luò)的輸出部分引入了注意力模塊,網(wǎng)絡(luò)模型的平均精度均值可達(dá)91.96%,比原YOLOv3 提升了0.82%,檢測(cè)速度可達(dá)21 frame/s,能夠?qū)崿F(xiàn)復(fù)雜環(huán)境下的安全帽精確檢測(cè)且滿足實(shí)時(shí)性要求,但由于模型的復(fù)雜度提高,影響了檢測(cè)速度。2020年黃勇[62]提出了融入自注意力的SSD 改進(jìn)算法。通過(guò)Self-Attention模塊擴(kuò)大了SSD算法的感受野,增強(qiáng)了算法的識(shí)別能力。通過(guò)在自制的數(shù)據(jù)集上進(jìn)行訓(xùn)練測(cè)試,網(wǎng)絡(luò)模型的檢測(cè)準(zhǔn)確率可達(dá)71.7%,比原SSD提升了2.37%。該方法對(duì)安全帽的目標(biāo)小、易形變以及堆疊的情況有很好的檢測(cè)效果。
通過(guò)優(yōu)化Anchor Box、優(yōu)化骨干網(wǎng)絡(luò)、特征融合和引入注意力機(jī)制的改進(jìn)方法,一定程度上可以提升對(duì)安全帽小目標(biāo)的檢測(cè)能力,但還是解決不了候選框被錯(cuò)誤剔除的問(wèn)題,對(duì)一些密集目標(biāo)還是存在漏檢、錯(cuò)檢。
3.5 優(yōu)化非極大值抑制算法
非極大值抑制算法(non-maximum suppression,NMS)[63]的作用是在目標(biāo)框篩選階段剔除部分冗余框,解決一個(gè)目標(biāo)被多次檢測(cè)的問(wèn)題。但NMS算法始終存在兩個(gè)問(wèn)題:一是對(duì)于一些目標(biāo)比較密集的檢測(cè)任務(wù),在剔除部分冗余框的同時(shí)去掉了部分正樣本的檢測(cè)框,如圖4所示。二是NMS算法是將大于閾值的目標(biāo)框直接剔除,但是一個(gè)合適的閾值是很難找到的。

圖4 NMS的缺陷Fig.4 Defects of NMS
因此,在一些安全帽檢測(cè)任務(wù)中,研究人員通過(guò)優(yōu)化非極大值抑制算法來(lái)解決上述問(wèn)題,進(jìn)而提高安全帽檢測(cè)算法的檢測(cè)效果。具體優(yōu)化算法包括Soft-NMS和DIOU-NMS等,該方法皆適合于解決較密集的安全帽檢測(cè)場(chǎng)景下因NMS過(guò)程中刪除高度重疊目標(biāo)而造成安全帽漏檢的問(wèn)題。2019 年金肖瑩[64]針對(duì)分布比較密集的安全帽目標(biāo),使用Soft-NMS[65]來(lái)替換后處理過(guò)程中的NMS,在不重新訓(xùn)練模型的情況下提高了檢測(cè)的準(zhǔn)確性。改進(jìn)之后的網(wǎng)絡(luò)的精確度可達(dá)88.1%,比傳統(tǒng)的Faster R-CNN模型提高了9.5%。通過(guò)優(yōu)化非極大值抑制算法之后的安全帽檢測(cè)算法在準(zhǔn)確率和泛化能力上表現(xiàn)出了很好的性能,但由于本身是兩階段的算法,即使提高了檢測(cè)準(zhǔn)確度,其檢測(cè)速度還是較低,仍無(wú)法解決檢測(cè)速度要求較高的安全帽檢測(cè)問(wèn)題。針對(duì)YOLOv5算法檢測(cè)小目標(biāo)時(shí)存在的漏檢和模型收斂速度慢的問(wèn)題,2021 年Tan 等[66]增加檢測(cè)規(guī)模,并使用DIOU-NMS代替NMS,利用DIOU-NMS 在對(duì)候選框進(jìn)行剔除的同時(shí)考慮了重疊區(qū)域和兩個(gè)目標(biāo)框的中心距離的優(yōu)點(diǎn),提高了模型對(duì)小目標(biāo)的檢測(cè)準(zhǔn)確度,模型的檢測(cè)準(zhǔn)確度可達(dá)95.68%,檢測(cè)速度達(dá)到98 frame/s,但由于YOLO系列算法網(wǎng)絡(luò)檢測(cè)目標(biāo)的局限性,對(duì)嚴(yán)重遮擋安全帽仍存在一定程度的漏檢、錯(cuò)檢。2020 年邱浩然[67]針對(duì)安全帽位置中存在的遮擋和重疊情況,使用Soft-NMS 代替YOLOv3中的NMS算法,提高了模型的檢測(cè)效果。
以上五種改進(jìn)方法在兩階段安全帽檢測(cè)算法和單階段安全帽檢測(cè)算法中都比較常見(jiàn),為了達(dá)到最好的檢測(cè)效果,研究人員常常把多種改進(jìn)方法結(jié)合起來(lái)使用,從而在最大程度上提高對(duì)安全帽佩戴的檢測(cè)效果。除了上述改進(jìn)方法,兩種基于深度學(xué)習(xí)的安全帽檢測(cè)算法還有各自的改進(jìn)方法,進(jìn)一步提升了安全帽檢測(cè)算法的檢測(cè)性能。更多相關(guān)改進(jìn)的安全帽檢測(cè)算法見(jiàn)表2。

表2 (續(xù))
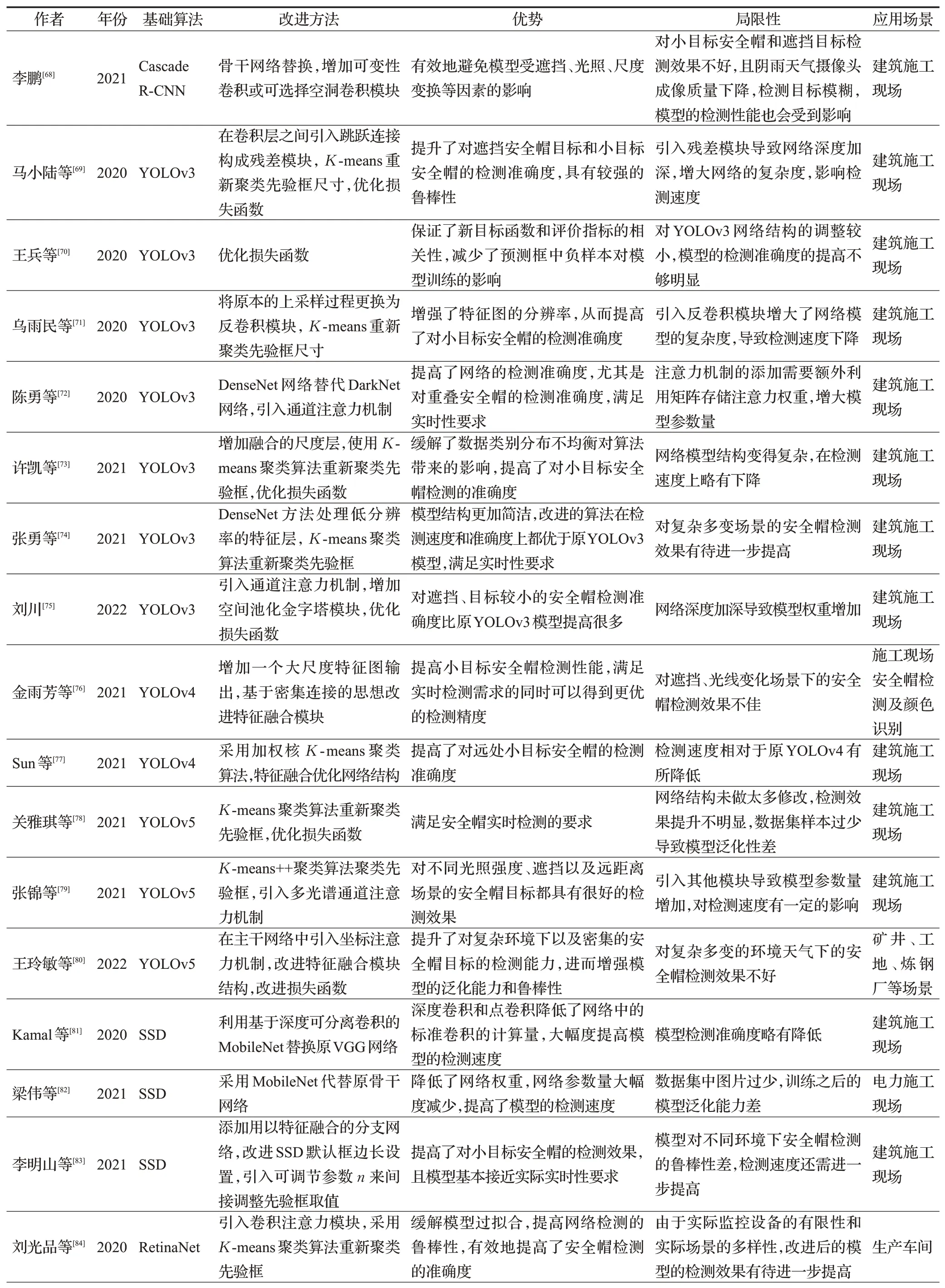
表2 改進(jìn)的基于深度學(xué)習(xí)的安全帽檢測(cè)算法Table 2 Improved helmet detection algorithm based on deep learning
3.6 引入在線困難樣本挖掘策略、優(yōu)化損失函數(shù)
在兩階段安全帽檢測(cè)算法中,通過(guò)引入在線困難樣本挖掘策略,解決了兩階段安全帽檢測(cè)算法隨機(jī)挑選正負(fù)樣本并設(shè)置比例導(dǎo)致樣本存在大量無(wú)效樣本,以及模型參數(shù)更新緩慢導(dǎo)致檢測(cè)效率低的問(wèn)題。在線困難樣本挖掘策略[88]通過(guò)自動(dòng)挖掘損失較高的樣本而不需要人為設(shè)定正負(fù)樣本比例,這樣有針對(duì)性地學(xué)習(xí)訓(xùn)練,提高了模型的訓(xùn)練速度和檢測(cè)準(zhǔn)確度,但在安全帽檢測(cè)中由于安全帽檢測(cè)數(shù)據(jù)集本身的問(wèn)題,無(wú)法覆蓋各種場(chǎng)景的安全帽樣本。2020 年王慧[89]針對(duì)安全帽數(shù)據(jù)集中難易樣本、正負(fù)樣本不均衡使得網(wǎng)絡(luò)后期損失較高的問(wèn)題,將在線困難樣本挖掘機(jī)制引入到特征融合后的FasterR-CNN。改進(jìn)之后的網(wǎng)絡(luò)模型的平均精度均值可達(dá)93.3%,比原模型提高了1.8%,在線困難樣本挖掘策略能夠挖掘損失較大的困難樣本,進(jìn)行針對(duì)性的訓(xùn)練,增強(qiáng)模型背景分辨能力的同時(shí)降低了漏檢率,但只是基本滿足實(shí)際應(yīng)用中的精度要求,對(duì)小目標(biāo)安全帽和遮擋安全帽的檢測(cè)準(zhǔn)確度還有待提高。2020 年徐守坤等[90]在原始Faster R-CNN的基礎(chǔ)上使用多層特征融合技術(shù)優(yōu)化區(qū)域建議網(wǎng)絡(luò)產(chǎn)生首選區(qū)域特征圖,使用在線困難樣本挖掘技術(shù)訓(xùn)練ROI網(wǎng)絡(luò),自動(dòng)挑選出困難樣本使訓(xùn)練更加有效,提高了對(duì)部分遮擋和小尺寸目標(biāo)的檢測(cè)效果,對(duì)環(huán)境變化也有很強(qiáng)的適應(yīng)性。引入在線困難樣本挖掘策略提高了檢測(cè)效率,但采用多特征融合技術(shù)增加了模型的復(fù)雜程度和參數(shù)量,最終導(dǎo)致檢測(cè)速度有所降低。
在單階段安全帽檢測(cè)算法中,YOLOv3利用均方誤差(mean squared error,MSE)作為損失函數(shù)來(lái)進(jìn)行目標(biāo)框的回歸,利用均方誤差評(píng)價(jià)指標(biāo)有時(shí)候并不能把不同質(zhì)量的預(yù)測(cè)結(jié)果區(qū)分開(kāi)來(lái)。比如說(shuō),在YOLOv3中采用交并比(intersection over union,IOU)來(lái)判斷模型是否檢測(cè)到目標(biāo),模型設(shè)定一個(gè)IOU 閾值,如果檢測(cè)目標(biāo)的IOU 大于設(shè)定閾值,則會(huì)判斷為檢測(cè)到目標(biāo),反之則反。YOLOv3中回歸質(zhì)量的評(píng)價(jià)采用IOU指標(biāo),但是對(duì)于IOU 值不同的檢測(cè)目標(biāo)可能得到相同的MSE 損失值,如圖5所示。

圖5 相同MSE下的IOU值Fig.5 IOU value under same MSE
因此,以均方誤差作為衡量預(yù)測(cè)邊界框的回歸效果的損失值,不能與IOU 很好地聯(lián)系起來(lái),從而影響了模型的檢測(cè)性能。2021 年韓錕等[91]針對(duì)損失函數(shù)與模型檢測(cè)效果不匹配的問(wèn)題,使用基于GIOU的損失函數(shù)代替均方誤差損失函數(shù),更好地匹配了算法損失函數(shù)與目標(biāo)檢測(cè)評(píng)價(jià)之間的關(guān)系,網(wǎng)絡(luò)模型檢測(cè)的平均精度均值可達(dá)93.84%,比未改進(jìn)損失函數(shù)的模型提高了2.57%。改進(jìn)的模型對(duì)多樣化場(chǎng)景、多尺度目標(biāo)具有很好的魯棒性,但沒(méi)有考慮到天氣對(duì)圖像成像質(zhì)量的影響,雨雪、霧霾天氣會(huì)造成攝像頭成像質(zhì)量下降,檢測(cè)目標(biāo)模糊,模型的檢測(cè)性能也會(huì)受到影響。在安全帽檢測(cè)的實(shí)際應(yīng)用場(chǎng)景中,輕量級(jí)算法YOLOv3-Tiny 由于參數(shù)數(shù)量較少,易于在嵌入式設(shè)備中部署,但其檢測(cè)精度較低,不適合檢測(cè)小目標(biāo)安全帽。2021 年Cheng 等[92]構(gòu)造了一種基于深度可卷積和通道注意機(jī)制的輕量級(jí)模塊來(lái)代替原有的卷積層,在減少參數(shù)和計(jì)算量的同時(shí),獲得了更多的特征信息,采用CIOU 損失函數(shù)代替原損失函數(shù),提高了對(duì)小目標(biāo)的檢測(cè)效果,與原模型相比,提高了檢測(cè)精度,檢測(cè)準(zhǔn)確率可達(dá)81.6%,但損失了檢測(cè)速度。為了解決基于深度學(xué)習(xí)的安全帽檢測(cè)方法因結(jié)構(gòu)復(fù)雜和計(jì)算量大而難以應(yīng)用到嵌入式設(shè)備中的問(wèn)題,2022年農(nóng)元君等[93]以YOLOv3-Tiny檢測(cè)網(wǎng)絡(luò)為基礎(chǔ),通過(guò)優(yōu)化網(wǎng)絡(luò)結(jié)構(gòu),引入空間金字塔池化模塊豐富特征圖的多尺度信息,采用K-means聚類算法重新優(yōu)化錨框,最后引入了CIOU 邊界框回歸損失函數(shù)提高了檢測(cè)精度。該改進(jìn)方法在光線不佳、小目標(biāo)、密集目標(biāo)等復(fù)雜施工環(huán)境下具有良好的適應(yīng)性和泛化能力,但該改進(jìn)方法為了滿足嵌入式平臺(tái)的需要,降低了網(wǎng)絡(luò)參數(shù),減少了運(yùn)算量,使得檢測(cè)準(zhǔn)確度比YOLOv3要低。
優(yōu)化損失函數(shù)的改進(jìn)方法彌補(bǔ)了IOU 損失函數(shù)的不足,解決了當(dāng)檢測(cè)框與真實(shí)框沒(méi)有重合部分時(shí),梯度不存在而無(wú)法進(jìn)行梯度下降優(yōu)化的問(wèn)題。但優(yōu)化損失函數(shù)并不是每次都能達(dá)到最好的訓(xùn)練結(jié)果,損失函數(shù)的選擇還得依安全帽檢測(cè)的實(shí)際情況而定。
3.7 改進(jìn)算法模型適應(yīng)能力的其他方法
在對(duì)基于深度學(xué)習(xí)的安全帽檢測(cè)算法研究中,除了上述的改進(jìn)方法之外,研究人員還通過(guò)引入其他網(wǎng)絡(luò)、模型壓縮、遷移學(xué)習(xí)、數(shù)據(jù)增強(qiáng)以及選擇合適的優(yōu)化器的方法,進(jìn)一步提高模型的適應(yīng)能力。
3.7.1 引入其他網(wǎng)絡(luò)——提高安全帽檢測(cè)準(zhǔn)確度
在將單階段目標(biāo)檢測(cè)算法運(yùn)用到具體應(yīng)用中時(shí),通常也采用與其他網(wǎng)絡(luò)相結(jié)合來(lái)改進(jìn)網(wǎng)絡(luò)模型的方法。這種改進(jìn)方式使得原網(wǎng)絡(luò)融合了其他網(wǎng)絡(luò)結(jié)構(gòu)的優(yōu)勢(shì),提高模型的泛化能力。2021 年鐘鑫豪等[94]提出了一種基于改進(jìn)Tiny-YOLOv3 算法的安全帽佩戴檢測(cè)模型,在該算法的原網(wǎng)絡(luò)中加入殘差網(wǎng)絡(luò)模塊,避免了小目標(biāo)的特征隨著網(wǎng)絡(luò)的加深而導(dǎo)致梯度消失的問(wèn)題,提高了小目標(biāo)的檢測(cè)準(zhǔn)確率。網(wǎng)絡(luò)模型檢測(cè)的平均精度均值比原模型提高了4.1%,檢測(cè)速度基本與原模型相當(dāng)。雖然檢測(cè)精度和速度得到了均衡,但與YOLOv3等大型檢測(cè)網(wǎng)絡(luò)相比,小目標(biāo)安全帽的檢測(cè)準(zhǔn)確度還有待提高,且增加殘差網(wǎng)絡(luò)模塊影響檢測(cè)的實(shí)時(shí)性。在安全帽檢測(cè)中,有些檢測(cè)對(duì)象較小,由于其在圖片中所占的像素較小,使得在特征提取時(shí)會(huì)造成特征信息的丟失。針對(duì)該問(wèn)題,2021 年曹燕等[95]將Conv-LSTM 引入到SSD 模型中,改進(jìn)后的模型可以將高特征信息層與低特征信息層分開(kāi),使得小目標(biāo)信息特征可以充分利用,提高了對(duì)小目標(biāo)檢測(cè)的檢測(cè)效果,但由于在SSD網(wǎng)絡(luò)的基礎(chǔ)上增加了Conv-LSTM模塊,網(wǎng)絡(luò)的復(fù)雜度提升,降低了檢測(cè)速度。
3.7.2 模型壓縮——提升安全帽檢測(cè)速度
模型壓縮主要是在保持網(wǎng)絡(luò)精度的前提下,減少模型參數(shù),從而實(shí)現(xiàn)模型的壓縮,提高模型的檢測(cè)速度。模型壓縮最常用的三種方法是參數(shù)量化[96]、模型蒸餾[97]、模型裁剪[98]。為了增加模型的可用性,2019年方明等[99]以YOLOv2 目標(biāo)檢測(cè)方法為基礎(chǔ),借鑒了密集連接網(wǎng)絡(luò)思想,在原網(wǎng)絡(luò)中加入密集快實(shí)現(xiàn)特征融合,利用MobileNet 中的輕量化網(wǎng)絡(luò)結(jié)構(gòu)對(duì)網(wǎng)絡(luò)進(jìn)行壓縮,縮減了網(wǎng)絡(luò),大大提高了檢測(cè)速度,改進(jìn)之后的網(wǎng)絡(luò)模型的檢測(cè)速度可達(dá)148 frame/s,檢測(cè)精度達(dá)到87.42%。該改進(jìn)方法減少了模型的參數(shù)量,增加了模型的可用性,但由于縮減了網(wǎng)絡(luò)結(jié)構(gòu),模型對(duì)安全帽檢測(cè)的準(zhǔn)確度有待提高。2021年趙紅成等[100]提出了一種新型輕量的安全帽佩戴檢測(cè)模型,通過(guò)優(yōu)化骨干網(wǎng)絡(luò),將原始YOLOv5s主干網(wǎng)絡(luò)更改為MobileNetV2,通過(guò)對(duì)模型進(jìn)行壓縮,在BN層引入縮放因子進(jìn)行稀疏化訓(xùn)練,采取模型裁剪方法進(jìn)一步減少模型推理計(jì)算量,最后通過(guò)模型蒸餾進(jìn)行微調(diào)得到了YOLO-S。改進(jìn)的網(wǎng)絡(luò)模型的檢測(cè)平均精度可達(dá)92.1%,比原模型提高了1.4%,浮點(diǎn)數(shù)為YOLOv5s 的1/3,推理速度比其他模型快,可移植性高。模型壓縮降低了模型的參數(shù)量,顯著提升了檢測(cè)速度,為將安全帽檢測(cè)算法模型應(yīng)用于嵌入設(shè)備提供了可能,但是損失了一定的檢測(cè)準(zhǔn)確度。該方法需要和其他方法結(jié)合使用,從而平衡檢測(cè)速度和檢測(cè)準(zhǔn)確度。
3.7.3 遷移學(xué)習(xí)和數(shù)據(jù)增強(qiáng)——解決安全帽數(shù)據(jù)集規(guī)模小的問(wèn)題
在安全帽檢測(cè)任務(wù)中,往往在自制的數(shù)據(jù)集上進(jìn)行模型訓(xùn)練,為了克服數(shù)據(jù)不足造成的缺陷,通常也采用遷移學(xué)習(xí)和數(shù)據(jù)增強(qiáng)。遷移學(xué)習(xí)[101]是將網(wǎng)絡(luò)中每個(gè)節(jié)點(diǎn)的權(quán)重從一個(gè)訓(xùn)練好的網(wǎng)絡(luò)遷移到另一個(gè)全新的網(wǎng)絡(luò)。在安全帽檢測(cè)任務(wù)中,安全帽數(shù)據(jù)集的樣本數(shù)量是訓(xùn)練網(wǎng)絡(luò)性能的限制因素,神經(jīng)網(wǎng)絡(luò)訓(xùn)練的數(shù)據(jù)集數(shù)量往往需要達(dá)到如ImageNet[102]的量級(jí)才能有效地避免網(wǎng)絡(luò)過(guò)擬合。針對(duì)安全帽數(shù)據(jù)集規(guī)模小的問(wèn)題,使用遷移學(xué)習(xí)策略能夠加快安全帽檢測(cè)模型的訓(xùn)練速度,增強(qiáng)模型的泛化能力。為了解決安全帽數(shù)據(jù)集規(guī)模小導(dǎo)致網(wǎng)絡(luò)難以充分?jǐn)M合特征的問(wèn)題,文獻(xiàn)[103-104]采用遷移學(xué)習(xí)策略克服模型訓(xùn)練困難問(wèn)題,加快了安全帽檢測(cè)模型的訓(xùn)練速度。在網(wǎng)絡(luò)的訓(xùn)練階段,改進(jìn)數(shù)據(jù)增強(qiáng)的方法在擴(kuò)充數(shù)據(jù)集的同時(shí)還可以增加樣本中小目標(biāo)的數(shù)量。2021年趙春暉等[105]提出基于改進(jìn)YOLOv3的安全帽檢測(cè)算法,在訓(xùn)練階段利用目標(biāo)可占比數(shù)據(jù)增強(qiáng)方法,增加了小目標(biāo)的數(shù)量,同時(shí)在網(wǎng)絡(luò)中引入了多尺度特征池化模塊,使得網(wǎng)絡(luò)對(duì)不同尺度的目標(biāo)更加敏感。該改進(jìn)方法的平均精度可達(dá)88.63%,比原YOLOv3 提升了1.54%,但改進(jìn)方法僅提高了對(duì)小目標(biāo)安全帽的檢測(cè)精度,對(duì)于遮擋的安全帽目標(biāo)檢測(cè)有待進(jìn)一步研究,并且模型引入多尺度模塊,使得網(wǎng)絡(luò)參數(shù)量增加,影響了模型的檢測(cè)速度。針對(duì)不平衡數(shù)據(jù)集導(dǎo)致模型檢測(cè)精度下降的問(wèn)題,2021 年Geng 等[106]在YOLOv3 目標(biāo)檢測(cè)算法的基礎(chǔ)上,采用基于加權(quán)的高斯模糊數(shù)據(jù)增強(qiáng)方法對(duì)不平衡數(shù)據(jù)集進(jìn)行預(yù)處理,對(duì)YOLOv3 算法進(jìn)行改進(jìn),檢測(cè)準(zhǔn)確度可達(dá)98.2%。但由于通過(guò)高斯模糊數(shù)據(jù)增強(qiáng)方法對(duì)圖像進(jìn)行處理時(shí),圖像離被處理對(duì)象越近,其對(duì)該像素的影響就越大,然而使用加權(quán)平均之后,每個(gè)像素使用周圍像素的平均值,這就導(dǎo)致了圖像中點(diǎn)丟失特征細(xì)節(jié),影響了之后模型的檢測(cè)準(zhǔn)確度。
3.7.4 選擇合適的優(yōu)化器——優(yōu)化檢測(cè)效果
神經(jīng)網(wǎng)絡(luò)中的優(yōu)化器是用來(lái)更新和計(jì)算影響模型訓(xùn)練和模型輸出的網(wǎng)絡(luò)參數(shù),使其達(dá)到最優(yōu)值。一個(gè)合適的優(yōu)化器可以加快網(wǎng)絡(luò)模型的收斂速度,減少訓(xùn)練時(shí)間。2020年張業(yè)寶等[107]提出基于改進(jìn)SSD的安全帽檢測(cè)方法。采用Adam 優(yōu)化器實(shí)現(xiàn)訓(xùn)練過(guò)程中神經(jīng)網(wǎng)絡(luò)的快速收斂,同時(shí)對(duì)網(wǎng)絡(luò)進(jìn)行遷移學(xué)習(xí),加快了訓(xùn)練過(guò)程并減少了對(duì)數(shù)據(jù)量的需求,提高了網(wǎng)絡(luò)模型的檢測(cè)準(zhǔn)確度,但檢測(cè)速度較原SSD 算法提升不夠明顯,有待進(jìn)一步研究。在基于深度學(xué)習(xí)的目標(biāo)檢測(cè)算法中,都會(huì)有符合算法的優(yōu)化器,但是在安全帽檢測(cè)任務(wù)中,有時(shí)候通過(guò)更換優(yōu)化器會(huì)有意想不到的效果。
以上對(duì)提升安全帽檢測(cè)模型適應(yīng)能力的有關(guān)方法進(jìn)行了總結(jié),更多采用提高模型適應(yīng)能力方法的安全帽檢測(cè)算法見(jiàn)表3。
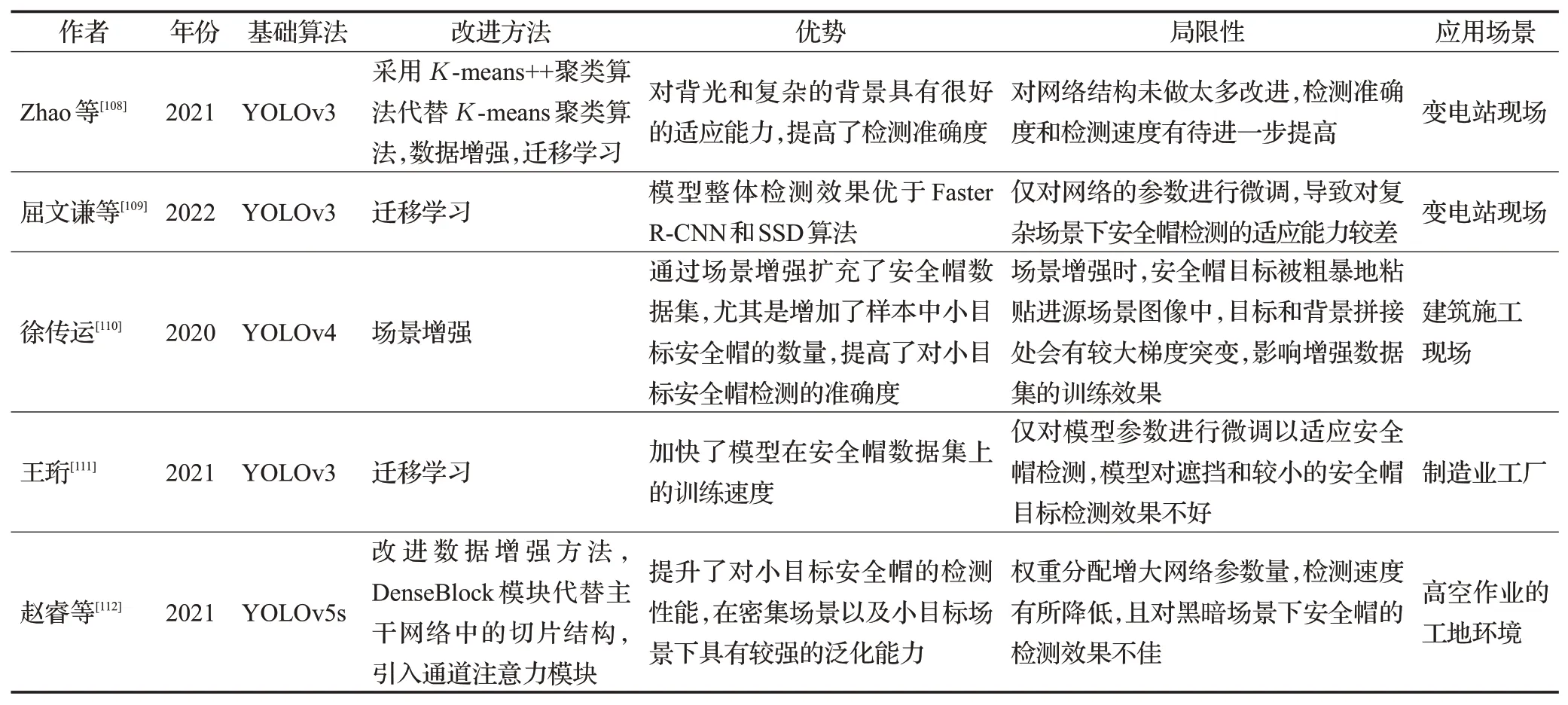
表3 改進(jìn)的增強(qiáng)模型適應(yīng)能力的安全帽檢測(cè)算法Table 3 Improved helmet detection algorithm to enhance adaptability of model
4 總結(jié)與展望
本文深入分析了近年來(lái)基于深度學(xué)習(xí)的目標(biāo)檢測(cè)算法在安全帽檢測(cè)領(lǐng)域的研究,總結(jié)了安全帽檢測(cè)方法的種類,詳細(xì)闡述了兩階段安全帽檢測(cè)算法和單階段安全帽檢測(cè)算法及其具體改進(jìn)方法,為智能建造技術(shù)領(lǐng)域相關(guān)科研人員提供借鑒與思路。當(dāng)前安全帽檢測(cè)算法雖然已取得了一定的成果,但將其使用在未來(lái)智能建造平臺(tái)或智慧工地的應(yīng)用維度上還需繼續(xù)努力研究。以下提出當(dāng)前研究過(guò)程中的一些問(wèn)題或建議,同時(shí)給出未來(lái)發(fā)展方向,供大家借鑒。
(1)目前安全帽檢測(cè)數(shù)據(jù)集還是太少,難以適應(yīng)各種復(fù)雜場(chǎng)景下網(wǎng)絡(luò)模型的訓(xùn)練要求。目前,大多數(shù)研究人員都是根據(jù)安全帽檢測(cè)的具體應(yīng)用場(chǎng)景自行構(gòu)建數(shù)據(jù)集。綜合分析施工現(xiàn)場(chǎng)安全帽數(shù)據(jù)集的圖片來(lái)源主要包括以下三個(gè)途徑:利用搜索引擎從互聯(lián)網(wǎng)上爬取圖片;從施工現(xiàn)場(chǎng)的監(jiān)控視頻中截取視頻幀;通過(guò)攝像機(jī)在施工現(xiàn)場(chǎng)進(jìn)行手工拍攝。未來(lái),還需要研究人員針對(duì)安全帽檢測(cè)任務(wù)構(gòu)建一套完備的數(shù)據(jù)集。
(2)安全帽檢測(cè)數(shù)據(jù)集中的小目標(biāo)還是存在一定的誤檢、漏檢,這是安全帽檢測(cè)領(lǐng)域普遍存在的問(wèn)題。針對(duì)該問(wèn)題,除了本文提到的改進(jìn)方法,還需在對(duì)安全帽的檢測(cè)當(dāng)中充分利用小目標(biāo)的區(qū)域特征,結(jié)合上下文信息增強(qiáng)對(duì)小目標(biāo)的檢測(cè)。Transformer 已經(jīng)在計(jì)算機(jī)視覺(jué)領(lǐng)域表現(xiàn)出很好的性能,主要運(yùn)用了自注意力機(jī)制,Transformer應(yīng)用于安全帽檢測(cè)任務(wù)可能會(huì)有很好的效果。
(3)安全帽檢測(cè)算法應(yīng)用于嵌入式設(shè)備中還是有些困難。針對(duì)該問(wèn)題,未來(lái)可以對(duì)輕量級(jí)網(wǎng)絡(luò)展開(kāi)研究,采用模型壓縮、參數(shù)量化等方法減少模型參數(shù)量,使其可以應(yīng)用于嵌入式設(shè)備中。
(4)由于攝像機(jī)位置角度不同使得數(shù)據(jù)集中存在遮擋目標(biāo),對(duì)這種情況同樣存在誤檢、漏檢。未來(lái),隨著5G 網(wǎng)絡(luò)時(shí)代的發(fā)展和硬件技術(shù)的更新,智慧工地也會(huì)針對(duì)性地設(shè)計(jì)多樣化的視頻設(shè)備來(lái)降低誤檢、漏檢概率。
(5)人與安全帽的位置關(guān)系不好判斷的問(wèn)題,模型不能很好判斷出作業(yè)人員是否正確佩戴安全帽。目前,智能建造技術(shù)領(lǐng)域已經(jīng)將基于姿勢(shì)估計(jì)算法的工人關(guān)鍵點(diǎn)提取和基于多目標(biāo)跟蹤算法的工人關(guān)鍵點(diǎn)跟蹤應(yīng)用于工人施工狀態(tài)識(shí)別當(dāng)中,盡管還不成熟,但是可以預(yù)計(jì)未來(lái)人與安全帽位置關(guān)系不好判斷的問(wèn)題,可以通過(guò)關(guān)鍵點(diǎn)檢測(cè)算法和目標(biāo)檢測(cè)算法相結(jié)合的方式來(lái)解決。
利用智能的方法實(shí)現(xiàn)施工現(xiàn)場(chǎng)實(shí)時(shí)監(jiān)控,既節(jié)省人力成本,又提高施工現(xiàn)場(chǎng)安全性,更為我國(guó)智能建造平臺(tái)或智慧工地的發(fā)展奠定了良好的基礎(chǔ)。在安全帽檢測(cè)任務(wù)中,由于考慮角度不同,有的針對(duì)遮擋和小目標(biāo)安全帽的問(wèn)題,有的需要應(yīng)用于嵌入式設(shè)備中,有的針對(duì)數(shù)據(jù)集中檢測(cè)目標(biāo)不足的問(wèn)題,有的則更注重模型的收斂速度,因此改進(jìn)方法有所不同,將基于深度學(xué)習(xí)的目標(biāo)檢測(cè)算法應(yīng)用于安全帽檢測(cè)任務(wù)中,還需具體問(wèn)題具體分析。未來(lái),隨著深度學(xué)習(xí)的發(fā)展,將會(huì)有更多的研究成果應(yīng)用于安全帽檢測(cè)領(lǐng)域中。
猜你喜歡
童話王國(guó)·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(bào)(2020年2期)2020-06-02 11:29:24
瘋狂英語(yǔ)·新策略(2019年10期)2019-12-13 08:43:28
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
數(shù)學(xué)小靈通·3-4年級(jí)(2017年9期)2017-10-13 08:10:54
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
