整車大數據存儲與計算優化實現
2022-08-17 10:04:36韋統邊司帥鋒溫麗梅唐瑩蘇德
電子測試 2022年14期
韋統邊,司帥鋒,溫麗梅,唐瑩,蘇德
(上汽通用五菱汽車股份有限公司廣西汽車新四化重點實驗室,廣西柳州,545007)
1 整車大數據存儲與計算
當前汽車成為大部分家庭生活必須品。電動化、網聯化、智能化和共享化成為新一代汽車的基本要求,汽車上數百個傳感器在不間斷的采集數據,這些數據的傳輸和利用蘊藏著巨大的價值,在2030年我國汽車保有量將增長到4.3億輛,每輛智能網聯汽車每秒可產生8.6MB數據[1]。海量數據的傳輸、存儲和計算成本之間的均衡成為當前最急需解決的問題之一。
本文將基于整車大數據目前狀況,簡要說明常用的數據存儲格式優缺點,選擇Parquet數據格式原由,并結合數據歸類和歸檔策略,總體上實現存儲壓縮和計算性能提升的目標。總體上實現存儲壓縮和計算性能提升的目標。
2 數據存儲格式
2.1 Txt數據格式
Txt是微軟在操作系統上附帶的一種文本格式,主要是用于存儲文本信息,此處我們利用txt格式文件按行存儲車輛上傳的加密數據,所有車輛信號項以及對應的值都以十六進制進行傳輸,需要使用時再用制定好的規則把十六進制數據解析為明文數據。
優點:沒有對應的解密規則無法將數據解密,數據的安全性高。壓縮比高,節省網絡帶寬,因為同樣位數的十六進制能比十進制和二進制表達的信息更多。
缺點:當使用數據時必須先解析為明文數據,再進行數據分析,若需要分別實現多個算法,會多次讀取源數據,導致數據解析工作重復進行,即使讀取一個信號項的值,也必須遍歷所有數據后再解析出指定信號項的值,重復解析工作耗費大量的集群計算資源。
應用場景:低頻歸檔數據。
2.2 Json數據格式
一種按行存儲的輕量級的數據交換格式,采用完全獨立于語言的文本格式,包含對象(鍵值對)和數組(包含多個對象)這兩種結構[2]。由字符串、數字、對象和數組組成的數據結構都可以通過Json來表示,其中對象是有一對大括號{}包裹起來的內容,數據結構為多個{key1:value1,key2:value2,…}形式的鍵值對,key為對象的屬性,value為對象的值,key一般用整數和字符串表示,value可以是Json支持的任意數據類型;而數組是由中括號[]包裹起來的內容,數據結構為 [“java”, 123, “vb”, ...] 的索引結構,同樣數組的值也可以是任意數據類型。整車數據解析后轉為JSON數據格式再按行存儲,文件格式可以是json和txt等。
優點:數據讀取速度快,一次解析多次使用,大量節省數據重復解析的時間;按需讀取信號項值,省去逐個遍歷信號項的時間。
缺點:占用存儲空間大,因為每一行數據都重復存儲相同的key值,以及大量的冒號、雙引號、大括號和逗號等,數據冗余問題較為嚴重。
應用場景:數據量低于百萬級別系統。
2.3 ORC數據格式
一種非單純的列式存儲格式,ORC數據格式遵循“先對行分組,再按列存儲”的理念,首先會按行組去分割整個數據表,每一個行組內再進行按列存儲,以strip為邏輯單位分為行組,每一個邏輯單位的大小一般與HDFS的block大小一致,保存了每一列的索引和數據,這可以保證邏輯單位內所有行都能保存在一個集群節點上;邏輯單位內的數據再按列存儲。這樣可以保證讀取多列數據時不會出現跨節點通信組裝元組的情況[3]。
ORC數據格式讀取是從文件的尾部開始,第一次讀取16KB大小的數據,盡可能將元數據信息和文件結構信息讀入內存,至此數據讀取初始化完畢。之后就可以通過元數據信息指定需要讀取的列編號,如果不指定列編號則默認讀取全部列。同時ORC文件是自描述的,它的元數據使用Protocol Buffers序列化,使用兩級壓縮機制,首先將一個數據流使用流式編碼器進行編碼,然后使用可選的壓縮器對編碼后的數據進一步壓縮,達到降低存儲空間的目的。
優點:具有極高的壓縮比,并且文件是可分割的,可支持更高的任務并行度。
缺點:對多層數據嵌套結構支持不夠友好,在使用多層數據嵌套結構時性能和空間損失較大。
應用場景:數據結構較為簡單的大數據集群。
2.4 Parquet數據格式
一種以二進制方式存儲的列式存儲格式,對多層數據嵌套結構支持比較友好,它的文件不可直接讀取和修改,它的文件也是自解析的[4]。Parquet數據格式主要分為三層,遵守自下而上的交互方式,最上層為數據存儲層,這層定義Parquet的文件格式/類型,包括原始類型定義、page類型、編碼類型和壓縮類型等;中間層為對象轉換層,這層作用是完成其他對象模型與Parquet內部數據模型的映射和轉換;最底層為對象模型層,該層定義如何讀取Parquet文件的內容,并對外提供接口,實現java對象和Parquet文件的轉換。Parquet的存儲模型主要由行組(Row Group)、列塊(Column Chuck)、頁(Page)組成,Row Group:將數據水平分割劃分為行組,默認行組大小與HDFS block塊大小一致,保證一個行組會被一個Mapper處理,Column Chuck:行組中的每一列保存在一個列塊中,每一個列塊只包含一種數據類型的數據,并且不同列塊可以使用不同的壓縮算法,Page:Parquet是按照塊頁方式去存儲數據,每個列塊包含多個頁,頁是最小的編碼單位,同樣不同的頁可以用不同的編碼方式。同時在ORC的基礎上采用Striping/Assembly壓縮算法,通過該算法,Parquet可使用較少的存儲空間表示復雜的嵌套格式。
優點:支持的系統多,數據壓縮比高,數據使用復雜的嵌套格式時占用存儲空間較少。
缺點:壓縮比沒有ORC數據格式高。
應用場景:數據為復雜嵌套格式的大數據集群。
2.5 數據格式對比
列舉的數據格式各項指標對比結果如下[5]:

數據格式指標 Text Json ORC Parquet壓縮比 低 極低 高 較高ACID 不支持 不支持 支持 不支持UPDATE操作 不支持 不支持 支持 不支持索引 不支持 不支持 粗粒度索引 粗粒度索引Impala、Drill、Spark、Hive單表查詢耗時 — — 9t 10t支持平臺 Hdfs Hdfs Spark、Hive
綜合以上對比結果,Parquet更適合我們當前大數據業務場景,因為ORC和Parquet查詢性能接近,但是Parquet支持更多的平臺,方便后續引入其他大數據組件。
3 基于Parquet數據格式存儲與計算優化實現
3.1 整車大數據數據流
利用kafka作為消息緩存隊列,加密數據全都暫存HDFS,一天數據存入一個文件中,凌晨時解析數據并轉為Parquet數據格式,Parquet格式數據用于數據分析,不常使用的加密數據轉存備用HDFS中,詳情請看圖1。
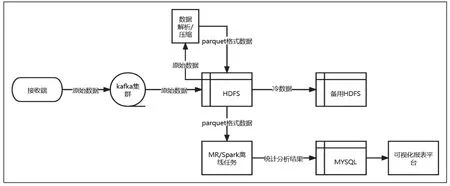
圖1 整車大數據數據流
3.2 Parquet文件存儲規則
為提高Parquet格式數據計算并行度,每一天數據將劃分為多個文件進行存儲,對文件存儲結構制定如下規則:
(1)解析后數據分類存儲:解析后的數據按/車型/采集日期/壓縮算法_時段_from_數據接收日期/Parquet文件目錄結構進行存儲,無法區分車型的車輛統一存儲到車型為UNKNOWN的文件夾下。
(2)清洗異常數據:過濾采集時間異常的數據,例如:過濾掉年份不屬于2019年至當年年份的數據 ,過濾掉月份不屬于1月至12月的數據,過濾掉日期不屬于1日至31日的數據,過濾掉時段不屬于0時至23時的數據,過濾掉分和秒不屬于0至59的數據。
(3)文件大小限制單個Parquet文件大小不允許超過512M,并且同一個文件夾下不允許有多個名稱相同,且文件大小都小于256M的文件出現,如果有要求把小文件合并為大文件。
3.3 數據壓縮算法實現
整車大數據Text轉Parquet壓縮算法實現如下:
(1)按行讀取Text文件,講數據轉為便于計算的RDD數據集。
(2)將數據解析為key-value形式,key為采集的信號項名稱,value為信號項值。
(3)過濾采集時間異常的數據。
(4)對過濾后的RDD數據集分組,分組key為車型和數據采集日期拼接的字符串,例如:SUV20211111,表示該條數據于2021年11月11日采集的SUV車型數據,value為過濾后的RDD數據集。
(5)遍歷分組后RDD數據集,根據key生成數據文件存儲路徑,將RDD數據集轉為DataFrame數據集,通過控制每個文件數據條數來控制每個文件的大小,最后通過DataFrame的coalesce方法控制此次分組生成的Parquet文件個數。
3.4 基于Spark數據分析優化
基于現有的Parquet格式數據,我們要實現一個統計功能,統計晚高峰期(18時-19時)每一個時段數據上傳的條數,通過同比每個時段數據量可分析出集群是否發生過數據延遲問題。現有的樣例數據8451條,樣例數據如圖2和圖3所示。
圖2 樣例數據

圖3 輸出結果圖
用于統計的代碼如下:
(1)初始化 spark 環境
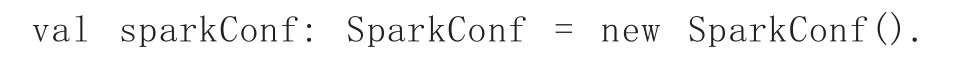

(2)讀取Parquet格式文件數據

(3)將DataFrame數據緩存,防止后續多次Action操作導致多次加載DataFrame數據
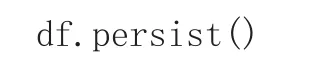
(4)利用列式存儲優勢,按需選擇需要統計的字段

(5)根據條件過濾掉非高峰期時段的數據

(6)統計每個日期每個時間段數據條數

(7)釋放緩存的DataFrame

最終輸出結果如圖3所示。相比傳統的按行分析數據,列式存儲Parquet可按需篩選字段,極大減少用于讀取數據的資源開銷,而且可使用近似Sql語法去分析數據,極大減少數據分析的工作量,
4 結束語
本文介紹一種基于Parquet數據格式實現整車大數據存儲與計算優化,減少了數據存儲成本,同時數據分析速度提升,為企業實現降本增效的根本目的。
