基于Logistic 回歸算法的疫情信息查詢及趨勢預測系統(tǒng)的實現(xiàn)
2022-08-13 06:32:52林仁華徐文品李涵通
無線互聯(lián)科技 2022年10期
林仁華,徐文品,李涵通,徐 卉
(南京審計大學 金審學院,江蘇 南京 210023)
0 引言
2020 年,歐洲和美國的新冠肺炎疫情暴發(fā)。 由于這些國家采取了消極的抗擊疫情政策——自然免疫法,病毒傳播速度極快,導致疫情在這些國家大規(guī)模暴發(fā)。 截至2020 年11 月27 日,美國新冠肺炎累計確診病例超過1 300 萬例,累計死亡264 624 例,是全球累計確診病例數(shù)和累計死亡病例數(shù)最多的國家。 隨著國際新冠病毒感染人數(shù)不斷增加,國內防疫壓力不斷增大,并且隨著秋冬季節(jié)的來臨,國內不斷有地區(qū)也出現(xiàn)或零星或聚集性病例。 目前查找密接人員的工作主要還是靠大數(shù)據篩查和各單位登記篩查。
本系統(tǒng)以美國新冠肺炎疫情發(fā)展為研究對象,分析美國各地區(qū)疫情病例發(fā)展現(xiàn)狀,并通過Logistic 模型建模,分析預測美國新冠肺炎發(fā)展趨勢[1]。
1 研究現(xiàn)狀
隨著2019 年國內疫情暴發(fā)到全球大規(guī)模暴發(fā),國內和國外許多學者都進行了預測分析。 匡征凌、匡遠鳳等人通過構建傳染病動力學SEIR 模型對日韓新型冠狀病毒肺炎疫情預測分析出日韓當前疫情發(fā)展情況和拐點日期。 陳茜茜等[2]用試驗試件鈉膜厚度與試驗試件表面粘鈉量、350℃鈉密度、試驗試件粘鈉表面積對意大利新型冠狀病毒肺炎疫情進行多次擬合預測分析。 王志心等[3]采用數(shù)學建模,通過機器學習,對國內各省預測分析,能夠準確預計各省最終確診人數(shù)所占比例。 丁中興等[4]考慮隔離措施之后構建SEIAQR 模型動力學模型對湖北省武漢市的發(fā)病人數(shù)及死亡人數(shù)進行預測分析,能夠準確地預測疫情趨勢。
2 疫情模擬仿真及其趨勢預測分析
2.1 數(shù)據來源
本系統(tǒng)所用數(shù)據來源于中國軟件杯a10 賽題提供的測試數(shù)據,將其經過一定規(guī)則的大數(shù)據清洗后存入數(shù)據庫中以供調用。
2.2 基于Logistic 函數(shù)的模型建立
Logistic 函數(shù)是一種常見的S 型曲線函數(shù)式。

本系統(tǒng)利用Logistic 函數(shù)建立美國新冠病毒感染人群的發(fā)展趨勢模型[5]。 如公式(1):t 表示時間;P0表示初始確診人數(shù);K 表示疫情峰值,即疫情最高峰累計確診人數(shù);r 表示增長率。 在傳統(tǒng)Logistic 函數(shù)曲線中,r 值可以衡量曲線變化的快慢,針對新冠疫情,該函數(shù)曲線中的r 值表示疫情到達峰值的速度。 如果r 值較大,疫情將很快到達峰值,表示一個國家在疫情期間采取強力有效的措施,比如醫(yī)院收治迅速、集中隔離等;反之,疫情到達峰值的時間較長。 因此,r 值的大小可以衡量一個國家面對疫情采取措施的效率,社會面對疫情的整體能力,群眾面對疫情的態(tài)度。 通過分析一段給定時間的美國某地疫情數(shù)據,得到一系列日期所對應的感染人數(shù),以Logistic 模型為基準擬合出一條曲線,通過sklearn 的誤差計算,調整參數(shù)來使擬合度提至最高,即得到一條最符合預測預期的疫情發(fā)展曲線。在曲線上通過Numpy 包計算出增長率開始降低的唯一點,確定其為拐點并提取拐點相關數(shù)據。
2.3 系統(tǒng)設計
2.3.1 系統(tǒng)具體設計
系統(tǒng)流程如圖1 所示。 本網頁搭建主要基于Python 語言的Django 框架,Django 是一個開放源代碼的Web 應用框架,由Python 寫成。 采用了MTV 的框架模式,即模型M,視圖V 和模板T。 其最初是用于管理勞倫斯出版集團旗下一些以新聞內容為主的網站,即CMS(內容管理系統(tǒng))軟件。 系統(tǒng)主頁面如圖2所示。
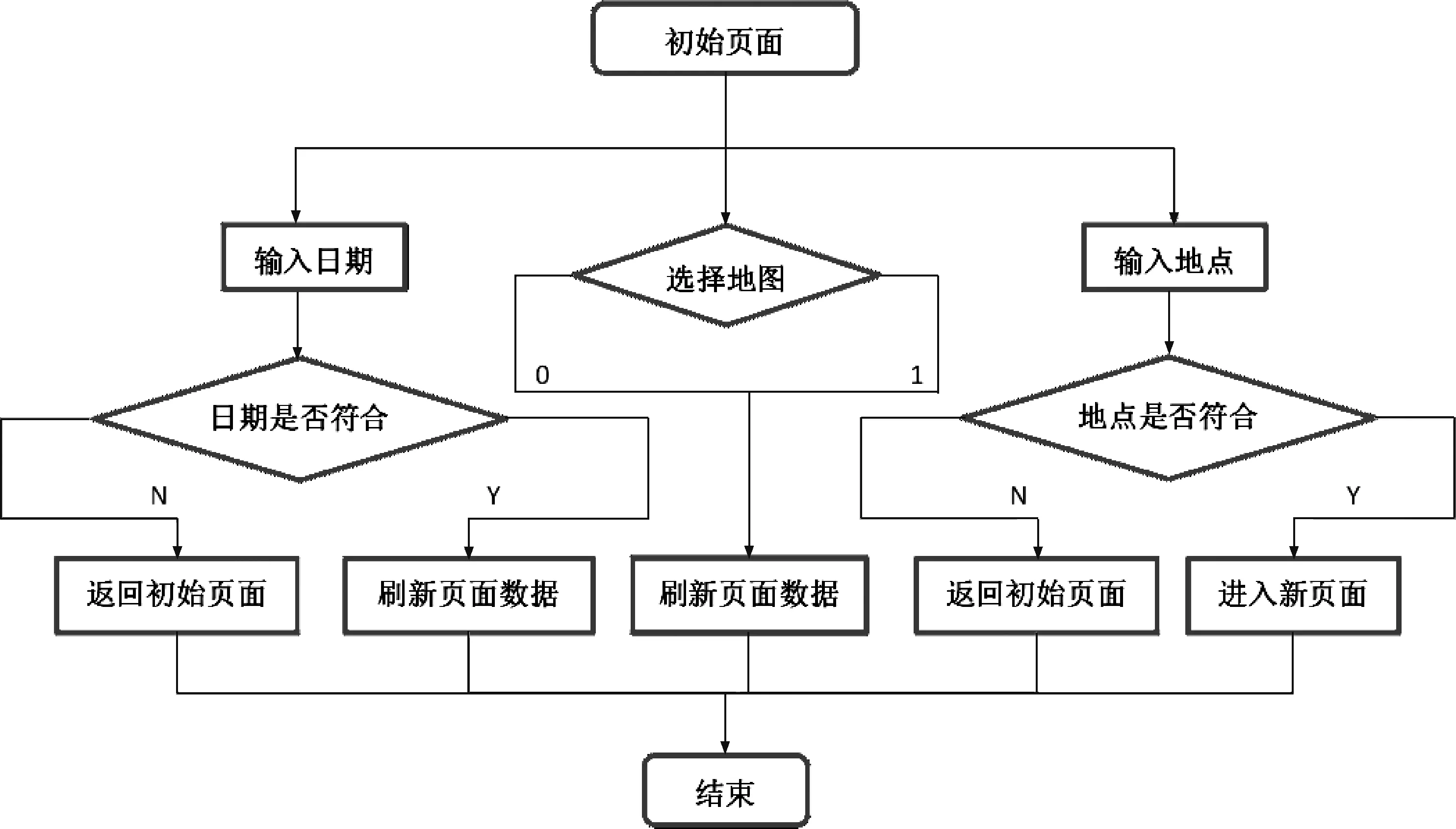
圖1 系統(tǒng)流程

圖2 系統(tǒng)主頁面
2.3.2 大數(shù)據清洗
本文所使用的大數(shù)據清洗技術為Pandas。 Pandas是一個開放源碼,BSD 許可的庫,提供高性能、易于使用的數(shù)據結構和數(shù)據分析工具。 Pandas 名字衍生自術語“panel data”(面板數(shù)據)和“Python data analysis”(Python 數(shù)據分析)。 一個強大的分析結構化數(shù)據的工具集,基礎是Numpy(提供高性能的矩陣運算)。 可以從CSV,JSON,SQL,Microsoft Excel 等各種文件格式導入數(shù)據;可以對各種數(shù)據進行運算操作,比如歸并、再成形、選擇等,還有數(shù)據清洗和數(shù)據加工特征。
詳細清洗規(guī)則如圖3 所示:(1)用戶選擇具體日期,系統(tǒng)反饋出該日美國的整體疫情信息數(shù)據以及數(shù)據分析。 (2)用戶選擇地圖類型,系統(tǒng)反饋出其所選的美國疫情地圖信息。 (3)用戶選擇美國具體城市,系統(tǒng)反饋出該地點的疫情信息及預測疫情走向。
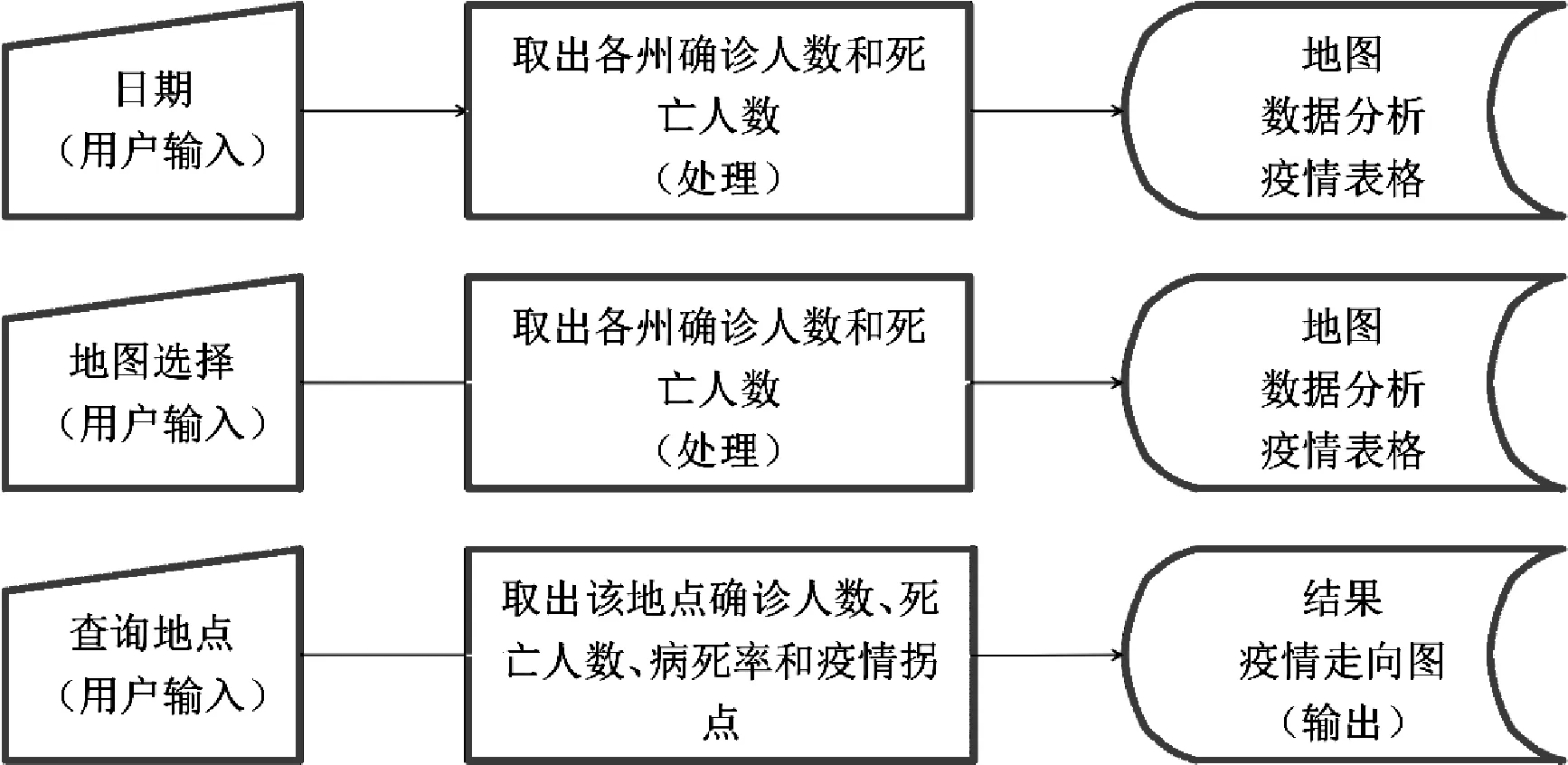
圖3 清洗規(guī)則
2.4 預測結果分析
查詢結果如圖4 所示,根據預測結果可以看出,對紐約疫情的確診人數(shù)數(shù)據預測大致與實際相同。 確診人數(shù)大致呈上升趨勢,自2020 年3 月1 日至5 月18 日紐約疫情確診人數(shù)在4 月11 日達到拐點,并在此日之后上升曲線開始趨于平緩,但還是在不斷上升。 在疫情暴發(fā)的25 天后,預測曲線逐漸與現(xiàn)有確診人數(shù)重合,說明Logistic 回歸函數(shù)適合對于該疫情的合理預測,而在5 月18 日紐約疫情達到峰值,有將近2.1 萬人確診新冠病毒。
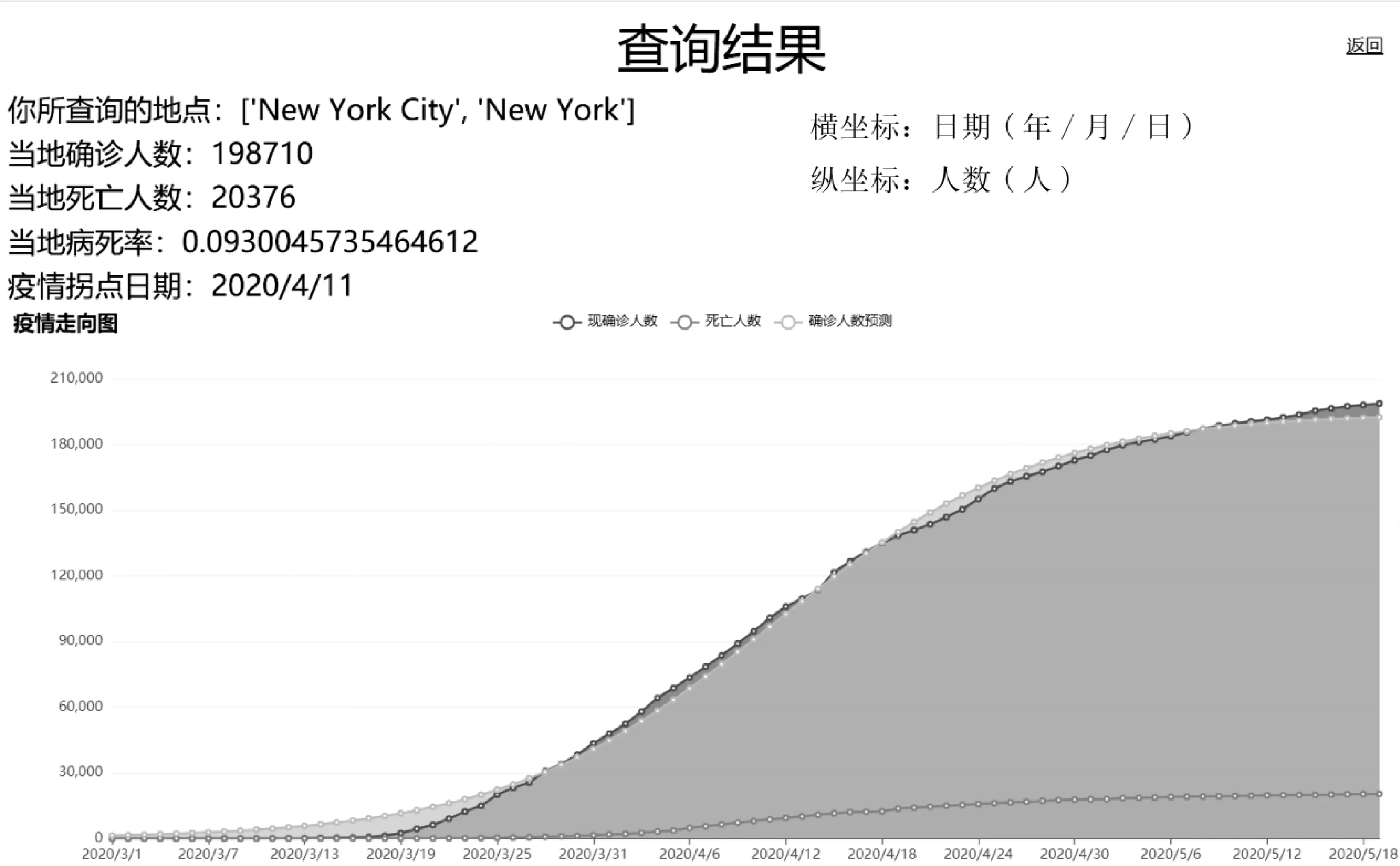
圖4 查詢結果
3 結語
本預測系統(tǒng)在疫情暴發(fā)初期能有很好的預測分析能力,通過擬合累計確診病例和累計死亡人數(shù),能夠得到較好的擬合結果。 為了方便觀察美國各地疫情信息,本系統(tǒng)將各個地區(qū)的人數(shù)疫情信息和預測數(shù)據分別展現(xiàn)出來。 實際工作過程中,因部分感染者不能被及時發(fā)現(xiàn)、上報等各種因素會導致預測誤差,所以預測結果會呈現(xiàn)“先高后低”的現(xiàn)象。 這也反映出美國政府措施不夠落實到位,美國人民對待疫情的不夠重視。為了預防疫情的進一步暴發(fā),我們應該提前做好防疫措施,正視疫情。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
音樂天地(音樂創(chuàng)作版)(2022年1期)2022-04-26 13:51:10
民用飛機設計與研究(2020年4期)2021-01-21 09:15:02
中學生數(shù)理化·七年級數(shù)學人教版(2020年10期)2020-11-26 08:24:50
人大建設(2020年5期)2020-09-25 08:56:22
快樂作文(1.2年級)(2020年8期)2020-09-10 07:22:44
數(shù)學物理學報(2020年2期)2020-06-02 11:29:24
電子制作(2018年18期)2018-11-14 01:48:24
山東工業(yè)技術(2016年15期)2016-12-01 05:31:22
