高性能眾核處理器芯片時鐘網絡設計
2022-08-12 02:29:18馬永飛高成振黃金明
計算機工程 2022年8期
關鍵詞:設計
馬永飛,高成振,黃金明,李 研
(上海高性能集成電路設計中心,上海 201204)
0 概述
目前,主流高性能微處理器基于同步時鐘系統進行設計開發。時鐘信號為芯片內同步系統提供參考時間,是同步時序邏輯運行的基礎[1-3]。時鐘信號通常是芯片中扇出最大、負載最重、傳輸距離和覆蓋面最廣的信號。時鐘偏斜對時序邏輯電路正確運行性能具有重要的制約作用。在通常情況下,時鐘網絡的偏斜由設計及工藝與應用環境兩方面因素影響決定。設計因素包括各時鐘節點負載平衡性以及從時鐘源端輸出的傳輸距離、傳輸級數與布線方式。工藝與應用環境因素包括工藝角、片上工藝偏差、工作電壓與溫度[4-5]。為保證芯片內同步時序邏輯在各種不同的工藝角下均能正常穩定工作,在傳統的高性能處理器設計中,設計人員通常致力于開發時鐘偏斜更小、抗工藝偏差能力更強的平衡時鐘網絡,以獲得較高的工作頻率[6-8]。
高性能眾核處理器芯片中通常包含多個不同的時鐘域,且隨著系統對性能要求的日益提高,高性能眾核處理器芯片規模不斷提高,時鐘網絡規模越來越大,使得芯片時序收斂及功耗優化的壓力日益凸顯[9-11]。如何降低芯片時鐘網絡功耗并克服時鐘網絡分布受片上偏差(On-Chip Variation,OCV)影響而導致的時鐘偏斜(clock skew)問題,從而加速設計時序收斂,成為高性能眾核處理器芯片設計中的重要研究方向[12-13]。本文在傳統時鐘網絡結構及混合時鐘網絡結構的基礎上,構建一種新型的多源時鐘樹綜合(Multi-Root Clock Tree Synthesize,MRCTS)結構,并通過實驗探究MRCTS 設計對時鐘系統的功耗優化作用。
1 相關研究
1.1 傳統時鐘網絡結構
根據時鐘網絡的結構特點,傳統的時鐘網絡設計主要有樹狀和網狀兩種結構。
常見的時鐘樹結構包括:H-Tree,Fanout Balance Tree,Binary Tree 和Fishbone[14-16]。H-Tree 時鐘樹的skew 小,抗OCV 能力強,但設計要求嚴格,通常作為芯片核心高頻時鐘的全局互連[17]。基于EDA 工具時鐘樹綜合(Clock Tree Synthesis,CTS)的時鐘樹通常為Fanout Balance Tree 結構,其作為芯片內模塊級時鐘互連。Binary Tree 時鐘樹相比H-Tree 時鐘樹的設計要求低,但仍存在較為嚴格的負載平衡要求,通常作為芯片時鐘的全局互連。Fishbone 時鐘樹的長度短、延時小,受OCV影響小,通常作為芯片內模塊級時鐘互連。圖1為4 種常見的時鐘樹結構。
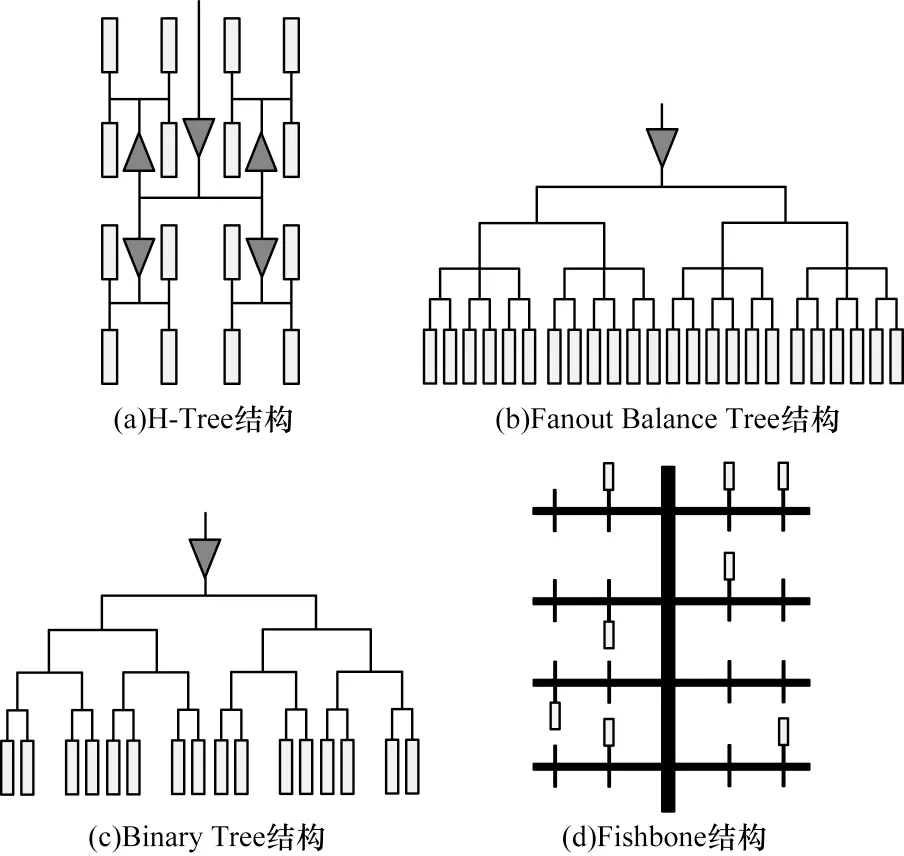
圖1 常見的時鐘樹結構Fig.1 Common clock tree structure
一個完整的時鐘網狀結構(MESH)包含前驅層、短接層以及負載層,如圖2 所示。MESH 時鐘結構與時鐘樹結構的根本區別在于存在時鐘短接層。通過前驅層所有驅動單元的輸出短接以及大量冗余的時鐘連線,MESH 時鐘結構確保了負載層的各負載單元可以就近連接到短接層MESH 網,有效降低了時鐘網絡的延時偏差,消除了時鐘傳播的延時奇異點。然而,為了有效控制MESH 網的時鐘延時,必須提供充足甚至遠超負載規模需要的前驅層驅動器和驅動點,同時為保證短接層的時鐘MESH 網的平衡與完整,需要添加大量冗余的時鐘線,這會造成布線資源浪費的同時增加時鐘網絡的負載和時鐘功耗,此外前驅層驅動器間的延時偏差帶來的短路直通同樣會帶來大量的時鐘功耗損失。

圖2 MESH 時鐘結構Fig.2 MESH clock structure
1.2 H-Tree+MESH 混合時鐘網絡結構
隨著集成電路設計規模的不斷提高,片上時鐘網絡規模、時鐘類型和復雜的時鐘結構使得單一網絡結構的時鐘設計遇到了嚴峻挑戰,設計人員開始尋求在性能、功耗等方面進行折中,提出了混合結構的時鐘設計方法[18-19]。在借鑒樹狀和網狀兩種時鐘網絡結構特點的基礎上,根據芯片不同時鐘域的特點與設計需要,構建多種不同的混合時鐘網絡結構以應對特定的設計需求。以FINFET 工藝下,ChipA眾核處理器芯片為例,其運算核心SCORE(約含88 000 個觸發器)的時鐘網絡設計采用H-Tree+MESH 混合時鐘網絡結構。
在該芯片設計中,SCORE 采用層次化設計方案,包含3 個綜合子模塊(ES、MUX、EMDIS)及2 個定制SRAM 陣列(LDM、L1IC)。核心時鐘域SClk 分兩層實現:第一層是SCORE 上層的H-Tree 及類H-Tree 的多級時鐘樹;等二層是模塊內的MESH 時鐘網。采用MESH時鐘結構,保證了運算部件內的時鐘延時平衡,利用具有高度一致性的H-Tree及類H-Tree時鐘樹兼顧運算核心簇內和簇間的時鐘網絡偏斜,并最終確保SCORE 乃至芯片內SClk 時鐘域的整個時鐘網絡具有較高的抗工藝波動與片上工藝偏差的能力,為時序收斂設計及芯片穩定運行提供重要支撐。
在MESH 時鐘網絡設計中,針對相關時鐘驅動點(Tap)至時鐘驅動單元(Gater)輸入端以及Gater單元輸出至負載觸發器(或Latch)時鐘端的延時分別制定設計目標,并通過對時鐘網絡進行Hspice 仿真分析驗證時鐘樹設計是否達到預期指標要求。SCORE 最終設計結果顯示,雖然部分Tap 點至Gater 驅動的延時略有超標,但整個時鐘網絡的設計質量高于既定指標要求,Tap 點輸入至負載單元的最大延時僅為85.8 ps,時鐘延時偏差少于12 ps(僅占時鐘周期的2.5%)。
圖3 為SCORE 上層最后一級H-Tree 時鐘樹以及相關時鐘驅動點的分布情況。圖4 為SCORE 綜合子模塊內部門控時鐘的MESH 網絡分布情況。雖然基于MESH 的模塊級時鐘網絡設計可以實現極低的時鐘偏差,具有極高的抗工藝偏差的能力,但是各主流EDA 工具對于MESH 時鐘網絡的設計支持度不夠,需要精細的人工定制設計,耗費大量的人力和時間。定制化時鐘樹設計方法難以適應芯片設計周期的需要,更無法有效利用useful skew 實現對關鍵路徑的優化。此外,隨著集成電路設計工藝提高,為追求更高的性能,片上集成度進一步提升,芯片時鐘網絡規模進一步增加。仿真結果顯示,模塊級時鐘樹設計面臨布線資源需求大幅增加的嚴峻挑戰。為滿足項目進度、布線資源、時序及功耗優化等多方面的需求,亟需研究新型時鐘網絡結構。

圖3 SCORE 上層H-Tree 及時鐘驅動點分布Fig.3 H-Tree and clock driver point distribution above SCORE

圖4 SCORE 中的MESH 時鐘網絡Fig.4 MESH clock network in SCORE
2 新型時鐘網絡設計
Synopsys 公司的布局布線工具ICC2 針對FINFET工藝下的時鐘網絡設計多源時鐘樹結構(Multi-Source Clock Tree Structure,MSCTS)[20-21],如圖5 所示。全局(Global)網絡包含全定制實現的H-Tree 時鐘樹、全局Tap 驅動器及其驅動的MESH 網,局部(Local)時鐘樹包含與MESH 相連的各子模塊的Tap 點及其驅動的標準CTS 時鐘樹。相比于傳統的CTS 時鐘樹結構,多源時鐘樹結構具有更高的抗片上工藝偏差能力并可實現更高的時鐘性能。
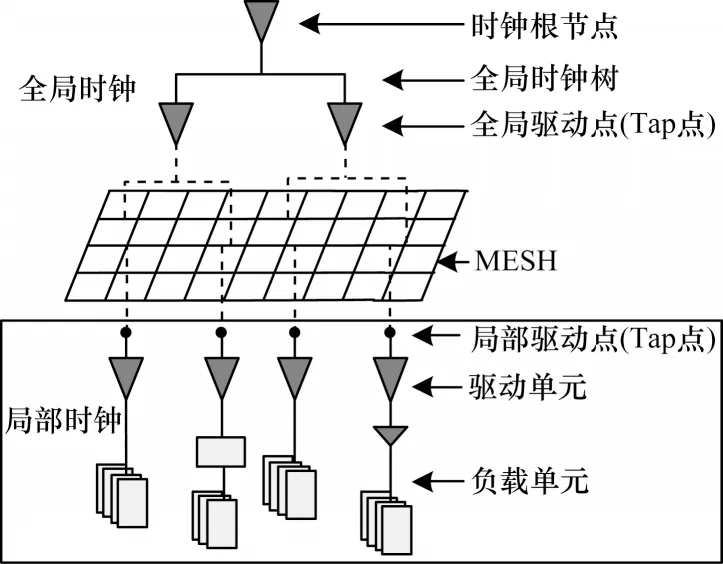
圖5 MSCTS 時鐘網絡結構Fig.5 MSCTS clock network structure
在MSCTS 中,以MESH 時鐘結構作為全局與各子模塊時鐘的互連通道,為提供較為充足與分布合理的Tap驅動點,全局時鐘上MESH結構的密集度要求較高,占用較多的高層金屬資源,大幅壓縮了各綜合子模塊的布線資源,降低了模塊的設計繞通性。同時,大量冗余的MESH 時鐘網絡極大地提高了時鐘網絡的負載,產生了較大的時鐘功耗。本文在H-Tree+MESH 混合時鐘網絡結構設計的基礎上,通過對標準多源時鐘樹設計策略的深入研究,結合新一代眾核處理器芯片面積大、核心時鐘網絡分布廣的特點,對多源時鐘樹結構進行改進,改進的時鐘網絡結構如圖6 所示。
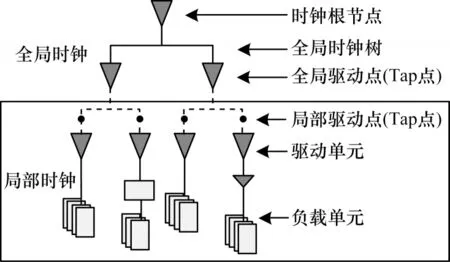
圖6 MRCTS 時鐘網絡結構Fig.6 MRCTS clock network structure
改進的時鐘網絡結構同樣分為全局和局部兩個部分:全局網絡包含全定制實現的H-Tree 時鐘樹及全局Tap 驅動器;局部時鐘樹基于MSCTS 流程以各子模塊Tap 點為時鐘輸入源進行多源時鐘樹綜合。將改進后的網絡結構稱為多源時鐘樹綜合(MRCTS)結構,其與MSCTS 的顯著區別在于取消了全局時鐘網絡末端的MESH 時鐘,局部時鐘與全局時鐘通過Tap 點直接相連。在設計時可以根據不同底層模塊的規模大小和各自特征,確定各自模塊Tap 點的數量和分布位置,從而達到控制局部時鐘樹的規模,實現各局部時鐘樹的延時基本相當,達到控制整個時鐘網絡skew 的目的。
采用改進的網絡結構可以降低中間的MESH 網帶來的大量時鐘功耗和對布線資源的額外占用,同時仍保有MSCTS 時鐘結構的優點:全局的H-Tree 時鐘樹保證了全芯片不同區域間clock skew 穩定可控,局部的CTS 時鐘樹可以合理利用useful skew 進行關鍵路徑的時序優化,實現時序收斂。全局和局部設計者的分工更加明確,在保證質量的同時,有利于縮短設計迭代周期,提高設計效率。
3 實驗設計與結果分析
3.1 基于MRCTS 時鐘結構的實驗設計
為探究MRCTS 時鐘結構的可行性及其對時鐘網絡的影響,基于SCORE 的設計代碼、布局規劃和Tap 點分布,采用MRCTS 時鐘樹設計策略,分別進行3 個子模塊的綜合實驗。在采用MRCTS 時鐘樹設計策略進行SCORE 的時鐘樹綜合設計時,首先設置時鐘樹的主體級數,然后根據模塊中利用useful skew 進行時序收斂的需要,對不同的時序分組分別調整時鐘樹的目標級數,在合理利用useful skew 的同時實現對時鐘樹延時和級數的有效控制。表1 為SCORE 中子模塊采用MRCTS 時鐘設計的基本數據。

表1 SCORE 時鐘網絡基本數據設置Table 1 Setting of basic data of SCORE clock network
圖7為SCORE中基于MRCTS的時鐘樹布線規劃,其中從每個Tap 點發出的放射狀線條表示每個Tap 點到對應負載端(包括觸發器、Latch、定制Latch 陣列時鐘端)的連接關系。圖8 為SCORE 中的MRCTS 時鐘網絡,可以看出與圖4中的MESH時鐘網絡相比,MRCTS時鐘網絡對布線資源的占用大幅減少。

圖7 SCORE 中基于MRCTS 的時鐘樹布線規劃Fig.7 Clock tree route planning based on MRCTS in SCORE

圖8 SCORE 中的MRCTS 時鐘網絡Fig.8 MRCTS clock network in SCORE
3.2 功耗分析結果
時鐘網絡的功耗由靜態功耗、短路功耗和翻轉功耗三部分組成[22],分別來自時鐘驅動單元、時鐘互連線以及時鐘負載三方面,而影響時鐘網絡功耗的因素包含電源電壓、時鐘頻率、時鐘信號的跳變時間、門控方案、門控單元插入位置、時鐘網絡負載等。表2 對比了SCORE signoff 版(MESH 結構)與綜合實驗版(MRCTS 結構)時鐘網絡負載情況。
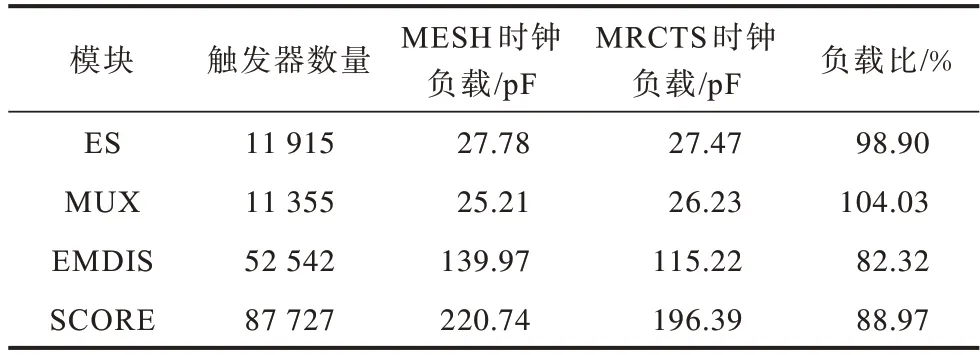
表2 時鐘網絡負載統計Table 2 Clock network load statistics
考慮到時鐘網絡功耗主要由動態功耗組成,而動態功耗的主體是開關功耗(Pswitch)。Pswitch計算公式如下:

其中:α為翻轉率;Cload為負載電容;VDD為電源電壓;f為時鐘頻率。開關功耗與時鐘網絡的負載電容、時鐘頻率成正比,與電源電壓的平方成正比,即在電源電壓和時鐘頻率相同時,時鐘網絡的功耗與時鐘網絡負載電容成正相關。
由此可以看出,基于相同代碼與布局規劃進行MRCTS 時鐘樹設計后,SCORE 時鐘網絡的總負載下降約11%,根據式(1)可以簡單推算出,SClk 時鐘域的模塊級時鐘網絡功耗可以獲得約11%的優化。
3.3 功耗實測結果
新一代ChipB 芯片設計采用更先進的第二代FINFET 工藝,同時為獲得更優的能效,在SCORE 的設計中應用了MRCTS 時鐘結構。相比于ChipA,SCORE的有效晶體管數由2.58×107增至3.33×107,增長了約28.9%,觸發器數由8.77×104增至10.80×104,增長了約23.3%。為驗證新型時鐘網絡設計對功耗優化的效果,分別選取5 顆ChipA 和ChipB 芯片進行時鐘功耗測試,并將電源電壓與時鐘頻率進行一致性折算,對比結果如表3 所示。從表3 數據分析結果可以看出,在觸發器總量增加23.3%的情況下,采用MRCTS 時鐘結構,SCORE 時鐘網絡功耗約降低了22.15%(折算相同電源電壓和時鐘頻率)。

表3 ChipA 與ChipB 的SCORE 時鐘網絡功耗對比Table 3 Comparison of clock network power consumption of SCORE between ChipA and ChipB
4 結束語
本文分析高性能眾核處理器芯片設計中的H-Tree+MESH 混合時鐘網絡結構,構建新型多源時鐘樹綜合(MRCTS)結構并研究其對模塊時鐘網絡功耗的優化作用。兩款處理器芯片實測功耗的對比結果顯示,在相同電源電壓和時鐘頻率條件下,基于MRCTS的ChipB運算部件SCORE 的時鐘網絡功耗較ChipA 下降約22.15%。但由于新型MRCTS 時鐘樹結構中Tap 點的位置受限于H-Tree 時鐘樹結構,分布一般比較均勻且位置相對固定,Tap點位置調整對全局布線的影響較大,然而在實際設計中時序單元的分布不均勻,受邏輯設計和物理布局規劃影響,相對分布均勻的Tap 點會導致各Tap 點驅動的Local 時鐘網絡負載不均衡,在部分情況下可能會嚴重影響最終的時鐘樹設計及模塊時序收斂,因此后續將通過實時分析與調整Tap 點的分布和數量進一步優化時鐘網絡設計。
猜你喜歡
河北畫報(2020年8期)2020-10-27 02:54:06
現代裝飾(2020年7期)2020-07-27 01:27:42
流行色(2020年1期)2020-04-28 11:16:38
電子制作(2019年19期)2019-11-23 08:41:36
電子制作(2019年15期)2019-08-27 01:11:50
電子制作(2019年7期)2019-04-25 13:18:16
藝術啟蒙(2018年7期)2018-08-23 09:14:18
海峽姐妹(2017年7期)2017-07-31 19:08:17
Coco薇(2017年5期)2017-06-05 08:53:16
商周刊(2017年26期)2017-04-25 08:13:04
