基于數據增強與集成學習的小樣本識別技術
2022-08-10 04:57:42王滿喜陸科宇王佳保林云
移動通信 2022年7期
王滿喜,陸科宇,王佳保,林云
(1.電子信息系統復雜電磁環境效應國家重點實驗室,河南 洛陽 471003;2.哈爾濱工程大學信息與通信工程學院,黑龍江 哈爾濱 150001)
0 引言
未來復雜電磁環境下的信息化戰爭是多軍種聯合作戰,各種武器平臺互聯、互通,構成了陸、海、空、天、網、電一體化作戰體系[1]。在復雜電磁環境下進行電磁個體識別是實現電磁頻譜管控的重要步驟,對未知威脅的用頻個體進行有效識別對提升復雜電磁頻譜環境下的實時感知能力具有關鍵的意義。而在實際工作場景中,電磁信號經常只能獲得少量有標簽樣本的數據,因此如何在小樣本環境下提高識別率成為了需要解決的難題。
面對復雜的電磁環境,各種設備依賴于電磁環境空間,因此深度學習也被用于處理物理層通信[2]。現代化信息戰中,電磁環境變得更加復雜,會對無線電的使用產生嚴重干擾,限制裝備的使用和作戰效能[3]。傳統的技術手段已經難以對電磁個體進行快速有效識別,而近幾年出現的深度學習方法[4],是一種快速發展、有前景的新型技術,在電磁信號識別領域得到了有效的應用[5]。其中基于深度學習的電磁個體識別技術主要有實數網絡、復數網絡、多模態融合以及注意力機制等技術[6]。
小樣本學習在近年來受到了廣泛的關注,被用于解決信號識別時樣本數不足導致模型識別率低的問題[7]。在小樣本信號識別中,數據增強是一種提升效果的方法,已經應用在圖像、文本和語音處理等方面,但是對時間序列尤其是電磁信號的數據增強方法研究較少[8]。數據增強是深度學習模型在時間序列數據上應用的關鍵。其中時序變換是時間序列數據最直接的數據增強方法,大多數對原始輸入數據進行處理,通過引入高斯噪聲或更復雜的噪聲模式來提高模型的魯棒性[9]。對時間序列在頻域的轉換,可以利用頻域中振幅和相位譜的擾動來增強卷積網絡對時序異常數據的識別能力[10],實驗證明該方法相較于原始序列有顯著提高。
深度學習生成對抗網絡(GAN,Generative Adversarial Networks)作為一種生成模型,可以有效地生成合成樣本,應用于小樣本識別的訓練。在GAN 中,需要為時間序列數據建立良好的通用生成模型。通過一種輔助分類器生成對抗網絡的智能編程數據增強方法,對等勢星球圖在統計圖域的特征進行數據增強,可以實現信號調制識別性能的提升[11]。利用循環生成對抗網絡的方法生成真實合成數據,還可以針對時間序列分類不平衡問題生成平衡的數據集[12]。研究人員還發現基于GAN 架構生成的合成時間序列數據,可能更接近測試數據。此外提出了一個在不同領域生成真實時間序列數據的自然框架,在嵌入式空間進行對抗和聯合性訓練,具有監督和非監督性損失[13]。
基于模型的時間序列增強方法通常會用統計模型對時間序列進行建模。通過一種稱為混合高斯樹的簡化版統計模型,對少數類時間序列數據進行建模,可以解決分類不平衡的問題,與不利用點間的過采樣相比有很大優勢[14]。此外使用局部和全局趨勢(LGT,Local and Global Trend)的統計方法來計算參數和預測路徑樣本,可以提高模型識別性能[15]。使用混合自回歸模型來模擬時間序列的集合,根據條件分布生成新的時間序列,同樣可以達到數據增強的效果[16]。
本文將針對電磁信號識別中的小樣本問題,在現有的識別方法的基礎上,分別使用切片處理、時間序列增強和對抗訓練增強這三種方法,在小樣本數據集上進行測試,并通過對不同數據增強場景下模型的集成學習,極大地提高信號的識別效果,同時對不同算法的性能進行探討。
1 實驗數據集的建立
1.1 數據采集系統
信號采集系統廣播式自動相關監視(ADS-B,Automatic Dependent Surveillance-Broadcast)遵循國際民航組織協議[17],系統的工作框架如圖1 所示。其中A 和B 飛機收到來自衛星導航發送的飛機位置消息后,與其自身的其他相關信息進行結合,比如飛機的速度、狀態、意圖等,由兩架飛機ADS-B 發送子系統的消息生成模塊生成合法的信號后,再通過消息發射模塊周期性地廣播出去,然后被地面工作站接收。
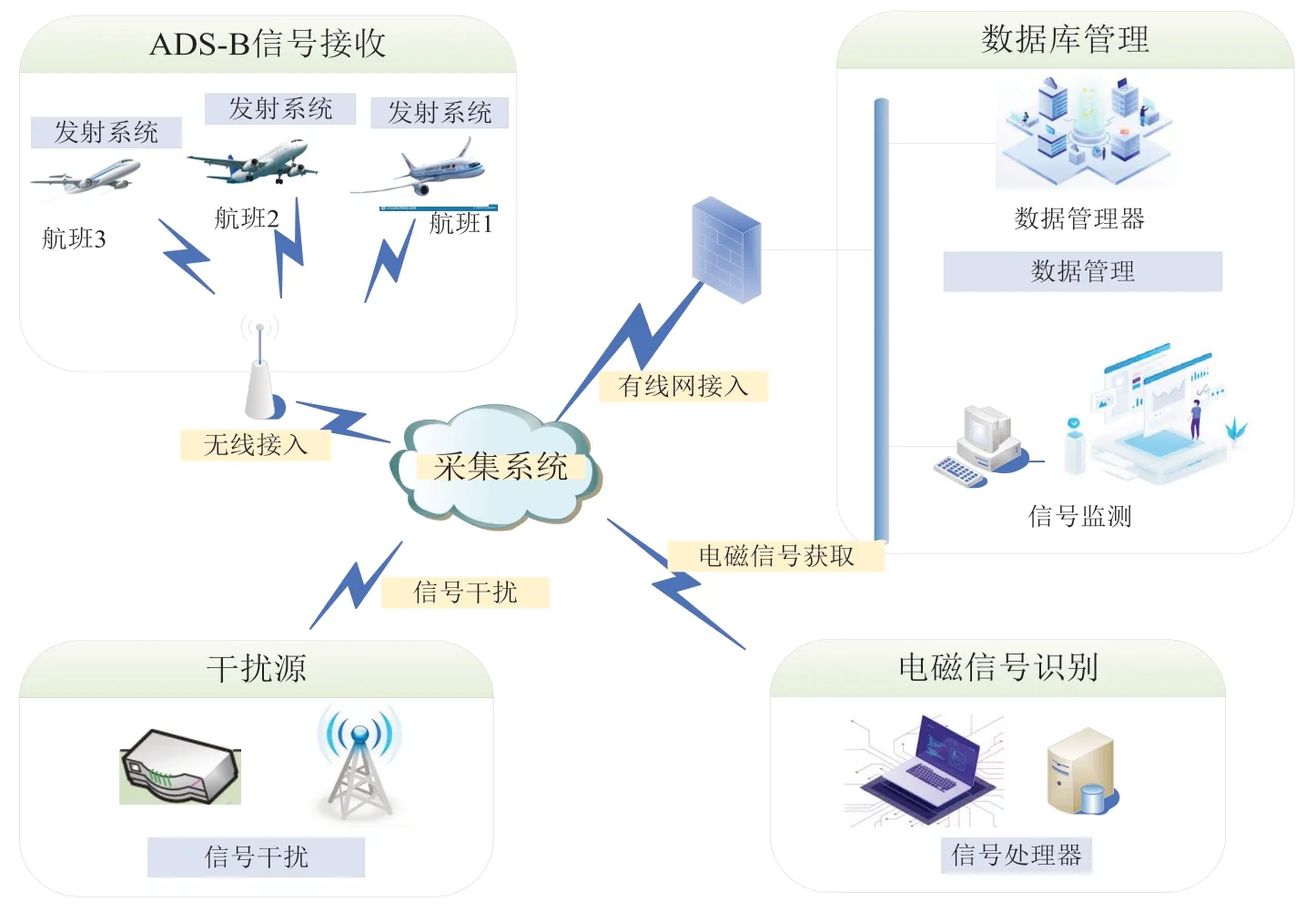
圖1 ADS-B系統工作框架
采用基于通用處理器的軟件無線電SM200B 接收設備采集信號,該設備的結構可以為開發提供很高的靈活性和簡便性,使用標準接口如以太網、通用串行總線等能夠對數字基帶或者低中頻的采樣數據進行處理,同時利用多核對數據進行處理以提高吞吐量。其結構包括天線、數模轉換模塊、緩沖模塊和常用處理器。這種架構十分靈活,能夠使用個人處理器進行算法的開發和測試。
1.2 數據采集與預處理
(1)數據集預處理
本文采集數據時自動聯合參數設置部分、信號解碼部分以及信道估計出的信號信息,進行消息組裝,并結合信號檢測部分的信號位置,提取出原始信號,完成自動標注過程。
1)利用統計學中的相關原理分別對I 路和Q 路兩路信號的二、四階統計量進行計算;
2)在同相和正交分量各自的二、四階統計特征的基礎上,得到對應的信號功率因子和噪聲功率因子,計算得到對應的信噪比;
3)根據同向和正交兩種分量的信噪比得到整體基帶通信信號的平均信噪比;
4)在上述工作的基礎上計算得到信號的參數化或非參數化功率譜;
5)在x-dB 的基礎上或根據其他方法對信號傳輸時的帶寬進行估計;
6)分別將信號的最低和最高截止頻率設置為fmin和fmax,對載波頻率偏移進行估計。
(2)實驗數據采集
實驗數據通過第1.1 節所述數據采集系統進行采集,并通過接收設備進行存儲。
電磁數據采集:圖2 展示了進行信號采集中的數據采集環境。采集地點選擇在航空器飛行航線上,避開架空導線等各種干擾源,降低到達采集點的反射雜波。采集到信號后將數據傳輸到控制臺并進行存儲。

圖2 電磁數據采集環境
2 基于時間和對抗序列的數據增強
2.1 切片預處理
通過窗口滑動將每個小樣本數據集中的信號處理成序列長度相等的切片,并且使用原有信號的標簽對設備進行標記[18]。對數據進行切片的流程如圖3 所示,Mk是第k個序列的長度,L為對應子幀的序列長度,當設置窗口滑動步長為1 時,第k幀傳輸共生成Mk-L+1 個子幀切片。
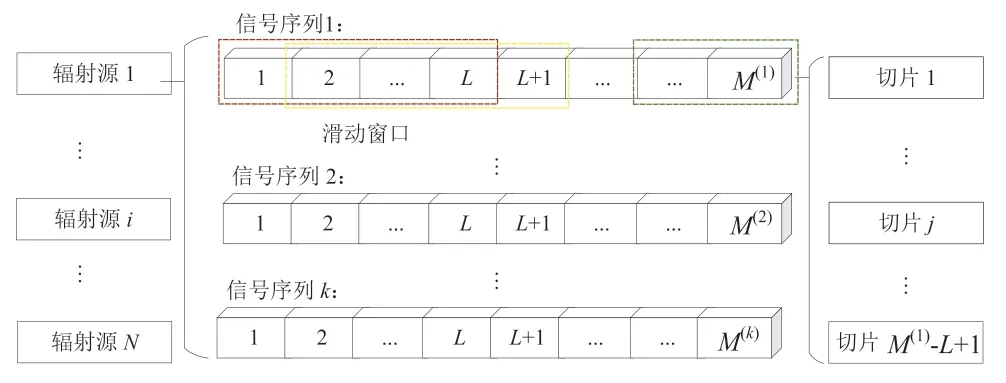
圖3 切片處理示意圖
為了提高模型的訓練速度并降低訓練數據特征的冗余,不需要將所有子幀的切片都輸入至網絡進行訓練,因此在本文中,均勻地隨機選擇一部分切片作為識別模型的輸入樣本,每個傳輸k最終得到的實際切片數由式(1)得出:

其中,λ為超參數,控制最終的實際切片數,其物理意義為在[1,L]區間內每個訓練樣本出現的次數的期望值,選擇合適的期望值可以降低模型過擬合的風險并節約計算成本。
2.2 時間序列數據增強
(1)頻率偏移數據增強
接收設備與發射設備之間的相對運動或信號發生反射的現象,會對信號傳輸產生影響,即多普勒效應[19]。在模型進行訓練時對數據加入頻偏,可以提高魯棒性。信號從發射端X 處產生并且向Y 處運動,接收設備在s的位置接收到電磁信號,則信號傳輸的長度存在路徑差:

式中,Δt表示發射端從X 處運動到Y 處的時間;θ代表X、Y 發射與信號接收位置產生的夾角。實際采集情況中,接收設備一般距離發射端20 km 以上,因此可以假設在兩處有相同的θ,從而可以計算出接收電磁信號的相位變化Δφ:

采集數據過程中飛機速度相對過快,接收數據會受到多普勒效應的干擾[20],偏移頻率是數據的重要特征,進行頻偏變換需要傅里葉變換。
(2)信道損傷數據增強
在地空信號的傳輸過程中易受如山體、大霧等的環境干擾而造成信號的反射、衍射和繞射[21],從而導致衰落,本文利用該特性對數據進行增強。
接收端信號可以表示為:

其中α代表信號衰減;f0代表頻率偏移;θ0代表相位偏移;ω(t) 代表均值為零的復高斯加性白噪聲;s(t) 為信道傳輸信號,其分布服從:

在地與空通信中傳輸鏈路一直保持“通視”效果,即存在信號直射路徑,但因為傳輸的多普勒效應和多徑效應的影響,使接收得到的信號包含多徑分量,而且信號的包絡服從萊斯分布。
2.3 對抗樣本數據增強
對抗樣本攻擊指通過對數據集樣本引入擾動,使其產生具有高置信度的錯誤輸出[22]。對于學習系統M(·) 和正常的輸入a,如果有另一個樣本是幾乎與a相同,但被系統錯誤地分類為,可以稱其為對抗樣本。本文利用對抗樣本對模型進行訓練以提升模型的泛化能力及魯棒性。
分類器對輸入a及其擾動版本做出不同的響應是不合理的,即。為了實現有效的分類器設計,只要,分類器就應該將a和分類為同一類。假設激活函數是線性的,那么對的分類器的輸入為:
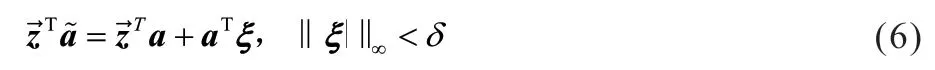
3 基于集成學習的信號分類
3.1 集成學習算法原理
本算法主要包括小樣本信號預處理、網絡識別和投票集成幾個部分。在數據輸入分類器之前,將采集得到的原始小樣本數據進行處理,然后使用不同網絡提取出信號特征進行投票,利用集成學習算法進行信號識別的流程如圖4 所示。
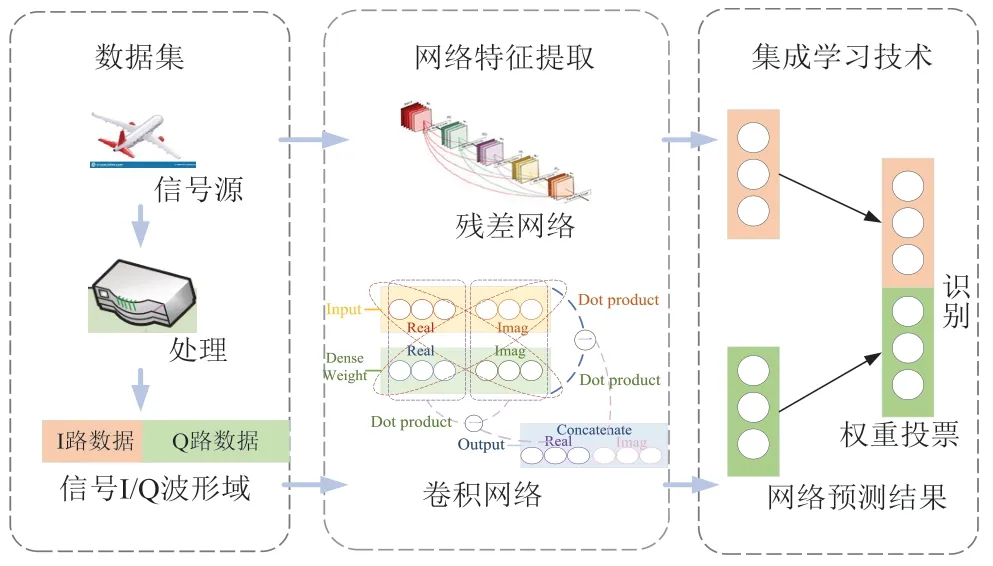
圖4 集成學習算法流程
集成學習包含以下三種常用方法:1)直接平均法,這種集成方法具有高效性,預測結果為不同網絡產生的分類置信度的平均;2)加權平均法,在直接平均的基礎上引入權重進而調節不同網絡分類置信度的重要性,從而提高識別率;3)投票法,常見的方法,其中使用最多的是多數表決法,投票之前分別將網絡得到的分類置信度轉變為預測類別[24],將最高分類置信度相應的類別作為該網絡的輸出對結果進行預測。
3.2 卷積神經網絡
卷積神經網絡具有較強的識別數據特征的能力,進而獲得更具擬合性的模型,是在監督下學習的分類模型[25],可以進行局部連接、權值共享和下采樣的操作。卷積神經網絡一般由輸入層、卷積層、池化層、全連接層及輸出層構成。分類識別中常用的卷積神經網絡的結構如圖5 所示:

圖5 卷積神經網絡結構
卷積層包含多個濾波器,以對輸入信號的特征進行學習[26],不同尺寸的卷積核提取得到的特征包含不同信息,而且權值的共享可以減少模型的復雜度并提高魯棒性[27]。除Alexnet 外,本文引入了ResNet[28]、VGG 和Inception[29]進行信號識別。
4 實驗及分析
本文設計并構建了小樣本下的電磁信號識別任務,并在不同的數據增強方法和基于集成學習的小樣本電磁信號識別方法下進行對比驗證。
4.1 實驗設置
實驗所采用的數據為數據采集系統得到的ADS-B 信號數據集,信號長度為4 800。分別對數據進行切片處理和數據增強獲得數據集,將增強后的數據集與原始數據集進行混合訓練,設置80% 數據為訓練集,20% 數據用于測試,然后使用4 種卷積神經網絡進行訓練與測試。在基于集成學習的小樣本識別中,對4 種模型進行集成學習。
本文中神經網絡訓練均基于Windows 10 操作系統上的Keras 與Tensorflow 深度學習框架構建,CPU 處理器為i7 -11370,GPU 使用NVIDIAGeForce 3060。
4.2 基于數據增強的識別性能分析
(1)切片處理后性能分析
為了對比不同樣本數目下切片處理對信號識別結果的影響,分別在類別樣本數目N為5、10、15、20 的情況下進行切片處理,通過這種方式對樣本數目進行擴增。切片處理后,在得到的數據集上分別對4 種神經網絡模型進行測試。在該實驗中,每個數據集包含20 個類別,對樣本切片時設置單幀長度為4 799,即將數據擴增一倍。
從圖6 中的結果可以看出,經過切片處理的信號識別效果與未經處理的效果相差很大,基于切片處理的小樣本識別準確率有了大幅度的提高。在單個類別樣本數目為5時,識別率最高的VGG13 僅為35%,殘差網絡的識別率為10%,這表明在小樣本下,模型的分類識別能力面對很大考驗。但是經過切片處理后,4 種模型的識別率均有了大幅提高,其中網絡的識別率最高達到了92.5%。
隨著樣本的數目越多,不同的網絡的識別率會隨之上升,這表明樣本數目的大小對模型的識別能力有著較大的影響。在樣本數目較小時,網絡缺少足夠的特征來提高魯棒性;當樣本數目提高到20 時,4 種模型的識別率均超過了90%。實驗結果證明了切片處理的有效性,在接下來的實驗中設置每個類別樣本數均為20。但是該方法得到的數據并不包含新的特征,沒有對模型進行新的訓練。且切片處理在模型的實際部署應用中存在約束,無法對信號進行實時的識別。且在識別前首先對信號進行切片處理,這樣會占用大量的時間和資源,因此本文接下來對時序增強方法進行研究。
(2)時序增強方法性能分析
為了通過增加樣本特征的方式提高小樣本識別率,需驗證時序增強方式在信號樣本較少時能否提高模型的性能。選用頻偏增強和損傷增強兩種信號增強方法對樣本特征進行擴增,樣本類別與每類樣本數目均為20,訓練得到的結果如表1 所示,對不同網絡結構和增強方式的識別效果進行研究。在訓練時為保障訓練的一致性和公平性,將學習率等超參數保持一致。設置頻偏增強的載波頻率偏移為4 kHz,萊斯多徑信道損傷的時延τ為0.1 個符號時間,增強后的數據與原始數據等比例混合訓練。從結果中可以看出,兩種數據增強方式均可以在一定程度上提高識別準確率。對于不同的模型,數據增強的效果相差較大。網絡VGG13 的識別率提高到了90.6%,而殘差網絡的識別率僅提高到了68.75%,這與網絡結構的不同有關。
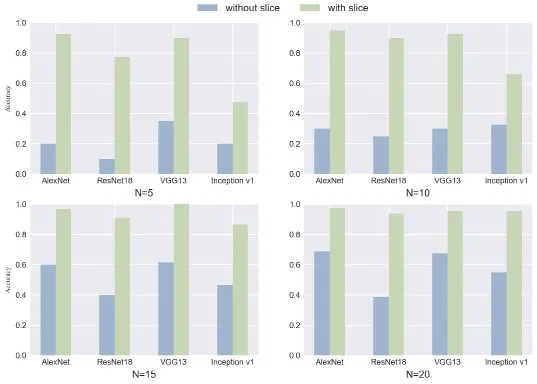
圖6 切片下不同模型性能對比

表1 小樣本在時序增強時的性能比較
從結果中可以看出,網絡的結構對時序數據增強的效果有著較大的影響。傳統的卷積神經網絡有較多的參數,在面對小樣本時,識別率較高且具有較高的魯棒性。經時序數據增強后,識別率得到了大幅提升。而對于殘差網絡,主要由殘差塊組成且參數較少,在面對新的特征時,因其魯棒性不強,所以無法對新的樣本進行有效識別。
(3)對抗訓練增強方法性能分析
為了驗證對抗訓練增強方法對于小樣本信號識別是否有作用,選用4 種對抗樣本方法生成對抗性樣本數據。采用上述實驗中的原始數據集,首先對測試集數據進行對抗樣本攻擊,并將不同模型在不同攻擊方式下的識別效果展示在圖7。從圖中可以看出,不同的攻擊方式均會造成網絡識別率的下降,且隨著樣本擾動程度的增加,對識別性能的損傷越嚴重,同時模型的結構對攻擊的效果有著一定的影響。這表明接下來可以利用對抗樣本攻擊對模型進行訓練,使其具備對精心設計的擾動的識別能力,提高模型在進行小樣本識別時的魯棒性。

圖7 對抗樣本攻擊下模型性能對比
經過上述研究,為了得到不同網絡結構和對抗攻擊訓練方法對識別的提高效果,將不同網絡在樣本擾動為0.01 的情況下產生的訓練集對抗樣本與原始數據進行混合訓練。從表2 可以看出,對抗訓練增強可以提高網絡小樣本識別性能。

表2 小樣本在對抗增強時的性能比較
4.3 基于集成學習的識別方法性能分析
為了研究集成學習在小樣本下的識別性能,從模型角度對識別性能進行分析,對上文中使用到的數據集和模型進行集成訓練。首先在不同的信噪比下進行分析,然后在不同數據增強方法下進行集成學習,驗證本文提出的方法。
(1)集成學習算法性能分析
對網絡在沒有數據增強下的識別效果進行研究,并將結果呈現在圖8 中:

圖8 集成學習與非集成模型性能對比
從結果可以看出,集成學習和單一模型的識別性能隨著信噪比的增加而逐步提高,在低信噪比下均無法取得很高的識別效果。在信噪比為-5 dB 時,集成學習的識別率超過了其余模型,并且在20 dB 信噪比下達到了71.3%的識別準確率,其分類結果的混淆矩陣如圖9 所示,這表明集成學習對小樣本識別有效,可以為接下來數據增強下集成學習提供參考。

圖9 集成學習,SNR=20 dB
從結果可以看出,集成學習并未對小樣本的識別準確率帶來大幅的提升,這并不表明集成學習不適用于小樣本識別場景,而是因為其中一些模型在小樣本下的原始識別率無法達到很好的效果,導致進行集成學習后無法產生正面的效果。
(2)數據增強下集成學習性能分析
數據增強下,4 種模型均能取得較高的識別準確率,因此考慮在數據增強下對模型進行集成學習訓練,研究是否能通過數據維度與模型維度對小樣本識別率的提升產生積極的影響。測試在對抗訓練增強和時序數據增強下進行,并將結果展示在圖10 中:
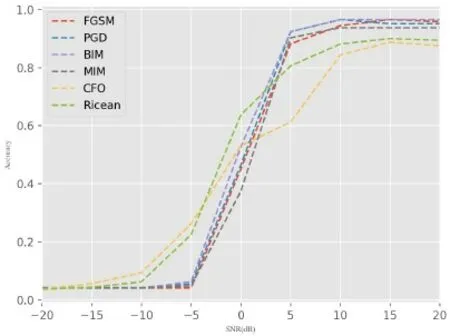
圖10 數據增強下集成性能對比
從結果可以看出,本文提出的基于數據增強和集成學習的小樣本識別方法取得了很好的效果,在BIM 對抗訓練下的識別率最高可以達到96.5%,其分類結果的混淆矩陣如圖11 所示:

圖11 BIM對抗訓練下集成學習
從結果中還可以看出,基于時序增強和集成學習的小樣本識別方法并沒有提高識別準確率,這同樣是因為在時序增強下,有些模型的識別性能不強從而對其他模型的識別產生了負面的影響。
5 結束語
小樣本電磁信號識別在民用和軍用領域具有重要的戰略意義。隨著通信領域和電磁空間領域相關技術的不斷發展,只有通過領先的電磁信號識別技術才能定位對方的電臺、飛機等設備,在未來的復雜電磁環境中掌握主動權。在設備的實際工作中,建立一個高質量標注數據集是很難實現的工作。為了利用少量的有標簽數據訓練得到具有泛化能力的模型,本文提出了基于數據增強和集成學習的小樣本識別方法。通過數據增強的方式,擴展信號樣本的特征,使模型能夠獲得較多的特征來提高泛化能力,同時從模型角度來探討如何提高小樣本識別率。
對于小樣本識別中存在的樣本和特征不足問題,本文分別從切片處理、時序增強和對抗訓練增強等角度對其進行了探討。從結果發現,該3 種方法均能有效提高小樣本信號識別率,其中時序增強對模型的提升效果不同,而對抗訓練增強能對模型識別性能普遍產生正向效果。最后在數據增強下利用集成學習進行識別,識別率最高達到了96.5%,證明了該方法的有效性,在后續工作中,可以從特征維度研究如何提高小樣本識別效果。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
鴨綠江(2021年35期)2021-04-19 12:24:18
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
考試與評價·高一版(2020年6期)2020-11-02 02:45:24
數學物理學報(2020年2期)2020-06-02 11:29:24
中國生殖健康(2019年3期)2019-02-01 06:12:26
光學精密工程(2016年6期)2016-11-07 09:07:19
鑿巖機械氣動工具(2016年3期)2016-03-01 04:00:25
海軍航空大學學報(2015年3期)2015-11-11 17:20:00
核科學與工程(2015年4期)2015-09-26 11:59:03
