一種基于自注意力機制的深度學習側信道攻擊方法
2022-08-08 01:35:34周梓馨張功萱寇小勇
信息安全研究 2022年8期
周梓馨 張功萱 寇小勇 楊 威
(南京理工大學計算機科學與工程學院 南京 210094)
隨著信息技術的發展,嵌入式設備的數量日益增長,其安全性越來越受到重視,側信道攻擊是主要威脅之一[1].側信道攻擊的核心思想是利用密碼芯片運行過程中泄露的物理信息獲取密鑰信息(如功耗、電磁輻射等).根據對目標設備的訪問和控制級別,側信道分析可以分為2類:建模攻擊(如模板攻擊[2])和非建模攻擊(如差分能量攻擊[3]).側信道建模攻擊假設攻擊者擁有與目標設備相同類型的設備,并對其擁有充分的訪問控制權限,攻擊者通過對相同類型設備充分學習后將擁有對該設備的刻畫能力,并嘗試將這種刻畫應用到目標設備進行攻擊.機器學習的方法可以很容易地將非線性處理用于側信道攻擊[4-8]:Masure等人[9]通過信息論的研究證明了神經網絡在側信道攻擊中的效果;Valk等人[10]通過引入猜測熵偏差方差分解,進一步提高了神經網絡在側信道攻擊中的可解釋性.
隨著深度學習的興起,側信道攻擊研究者在監督學習下使用深度神經網絡構建攻擊模型進行側信道攻擊[11-13]:Maghrebi等人[11]證明了基于深度學習的側信道攻擊可以有效地攻擊未采用掩碼保護的AES算法實現.Timon[14]首次實現了在非監督學習下使用深度學習進行非建模攻擊,攻擊密鑰的一個字節時,針對密鑰空間的每一個猜測密鑰建立1個模型進行攻擊.Maghrebi等人和Cagli等人[11-12]通過構建卷積神經網絡攻擊模型成功地過濾了AES實現的失調對策;Carbone等人[13]成功地攻擊了采用失調對策的公鑰實現:多層感知機同樣可以很好地攻擊采取失調對策的加密措施[12,15].Perin等人[1]通過集成學習將多個簡單模型進行集成來達到強模型的攻擊效果,為深度學習側信道攻擊領域提供了一種新思路.Maghrebi[16]提出一種新的基于多標簽分類的方法,使得模型從8 b密鑰塊到更大的密鑰塊(16 b)的攻擊而不引入額外的開銷.Picek等人[17]深入研究了機器學習側信道攻擊中存在數據不平衡的優點與缺點,并使用各種數據平衡方法提高攻擊效果,攻擊所需能量跡數量減少7/8.Cagli等人[12]提出一種基于CNN的端到端的分析方法,在能量跡存在偏差的情況下可以簡化評估過程.Lu等人[18]提出一種基于注意力機制[19-23]端到端的處理原始能量跡的方法,構建了一個基于編碼器架構的模型,但該模型的循環層不能并行化,訓練時將耗費大量時間.Kwon等人[24]使用降噪標簽,通過真實數據中的噪聲訓練自編碼器,訓練好的自編碼器可以用于預處理,降低輸入數據中的噪聲.Prouff等人[25]提出了特定數據集的超參數選擇方法,但僅僅局限于特定的數據集.Zaid等人[26]提出了一種構建高效CNN架構的方法,依據可視化技術(如熱圖、梯度可視化、權重可視化)的結果選擇超參數.Rijsdijk[27]使用強化學習尋找最佳超參數,但該方法目前僅適用于可訓練超參數比較少的情況.
目前基于深度學習的側信道攻擊攻擊成功仍然需要大量能量跡,模型效率有待進一步提升;模型在訓練時存在快速過擬合[12,14,25,28]以及深度學習所具有的梯度消失、收斂速度慢等問題.通過使用數據增強[12]、添加噪聲到輸入能量跡[15]中、隨機移位[25,28]等方法可以緩解過擬合問題,但無法從根本上解決該問題.Vaswani等人[29]在2017年首次提出自注意力機制,并基于自注意力機制提出了可以并發訓練的新模型Transformer,使用全局視角對特征分配注意力,解決了卷積神經網絡的局部特征提取能力不足的問題,同時結合丟棄層和殘差網絡,解決了傳統神經網絡在模型訓練時存在的快速過擬合和梯度消失問題.然而,Transformer結構并不適用于側信道攻擊,因為其采用了多層編碼器解碼器架構用于解決NLP領域中文本前后的關聯性,而在側信道攻擊中,能量跡之間沒有時序關系.側信道攻擊模型屬于建模階段建立的一個分類模型,與攻擊階段獨立.本文借鑒了Transformer架構中的編碼器設計,將自注意力機制引入側信道攻擊中并提出一個基于自注意力機制的深度學習側信道攻擊模型SADLSCA,通過開展實驗驗證了SADLSCA的高效性.本文的主要貢獻有3個方面:
1) 引入自注意力機制用于側信道攻擊,使深度學習側信道攻擊有新的特征提取方式,并在公開數據集ASCAD(1)ASCAD數據集獲取地址為https://github.com/ANSSI-FR/ASCAD和CHES CTF 2018(2)CHES CTF 2018數據集獲取地址為https://chesctf.riscure.com/2018news上通過實驗驗證了自注意力機制在側信道攻擊中有良好的特征提取效果;
2) 基于自注意力機制構建一個深度學習側信道攻擊模型SADLSCA,解決了快速過擬合、梯度消失、收斂速度慢等問題,并在公開數據集上表現出良好的攻擊效果,驗證了SADLSCA在側信道攻擊時的可用性和高效性;
3) 通過對單層編碼器結構的模型進行實驗測試,給出了單層編碼器結構的模型達到最佳性能效果的常用超參數數值.
1 相關技術
1.1 符號定義
用T表示能量跡集合,T=(t1,t2,…,tN);N表示集合中能量跡的數量;P表示明文或密文集合;K表示密鑰集合;Y表示與P和K相關的中間值變量,分別由pi,j,ki,j,yi,j組成,其中i表示能量跡的取值范圍,j表示字節的索引.
1.2 深度學習側信道攻擊
深度學習側信道攻擊本質上屬于建模攻擊,模型由深度學習構建.在構建攻擊密鑰的第j個字節的模型時,使用一個大小為N的訓練集,ti,f為訓練集中的第i條能量跡的第f個特征值,與ti對應的中間值為yi,j=f(pi,j,ki,j).本文使用的泄露函數為
yi,j=Sbox(pi,j⊕ki,j),
(1)
其中,⊕為異或運算,Sbox對應S盒,是AES算法的字節替換運算.
在建模階段,使用泄露函數計算每條能量跡的中間值作為其標簽.隨機將數據pi和密鑰ki輸入到受控設備后,采集該設備泄露的物理信息得到能量跡.訓練完成后,從受控設備采集1個驗證集數據用于驗證模型的泛化能力.在攻擊階段,從擁有未知密鑰k*的待攻擊設備上收集攻擊集數據,將攻擊集數據輸入模型得到輸出.根據模型的輸出計算可能性最大的猜測密鑰概率pk,并認為它是真正的密鑰k*.其理論依據為貝葉斯公式與極大似然相關:
pk=P[k|T]=
(2)
其中,pk表示使用Na條能量跡攻擊的情況下,根據模型的輸出計算每個猜測密鑰的概率.在Na越小、正確密鑰k*對應的概率pk*越大的情況下,模型效果越好.
1.3 評價指標
Picek等人[17]提出精確率、召回率等常見的機器學習指標與成功率、猜測熵等常見的側信道攻擊指標之間存在不一致性,即機器學習常用指標并不適合作為側信道攻擊模型的評估指標.Standaert等人[30]指出側信道攻擊中的標準度量是成功率和猜測熵.Zhang等人[31]在數據不平衡的條件下使用交叉熵比指標比交叉熵指標更適用于評估側信道攻擊中深度學習模型的性能.Masure等人[9]證明了在深度學習側信道攻擊模型中選擇最小負對數似然損失函數(NLL)是有效的.Zaid等人[32]提出了排名損失函數,與交叉熵損失函數相比,估計誤差減少23%.在模型的訓練階段,由于排名損失函數會耗費極大的計算資源而得不償失,所以只要所選的損失函數可以保證模型在訓練過程中使得輸入所對應的輸出分類標簽的概率最大即可,最終選擇的損失函數為交叉熵損失函數:
(3)
其中,n為能量跡的個數,q(ti)為模型對第i條能量跡預測的概率分布,p(ti)為第i條能量跡的真實概率分布.在驗證和攻擊階段,使用成功率和猜測熵揭示正確的密鑰.攻擊階段中,給定Na條能量跡,以概率遞減的順序輸出猜測向量:g=(g1,g2,…,g|K|),其中,|K|為密鑰空間大小.成功率定義為g1等于真實密鑰k*的平均經驗概率;猜測熵定義為k*在猜測向量g中的平均位置.
1.4 自注意力機制
在側信道攻擊領域中, Lu等人[23]首次提出了一種基于注意力機制的端到端處理原始能量跡的方法.Vaswani等人[29]首次提出自注意力機制,并基于自注意力機制提出一種新的簡單的網絡結構Trasnformer,完全基于注意力機制,不需要任何卷積操作,具有更高的并行化能力,減少了訓練時間.2021年,Dosovitskiy等人[33]提出的模型Vision Transformer是基于Vaswani提出的自注意力機制構建的一種高效圖片分類模型.Vaswani和Dosovitskiy等人提出的自注意力機制和模型適用于圖像分類,不能用于側信道攻擊領域,本文對其作了優化使其適用于側信道攻擊.
注意力函數是將1個查詢Query(Q)和1個鍵值對集合(K,V)映射到1個輸出Output的函數(此處的K與上文的密鑰集合不同),其中Q,K,V和Output都是向量.輸出Output是由值的加權和計算得出,分配給每個值的權重由Q與相應的K計算出的矩陣決定.具體結構如圖1(a)所示:
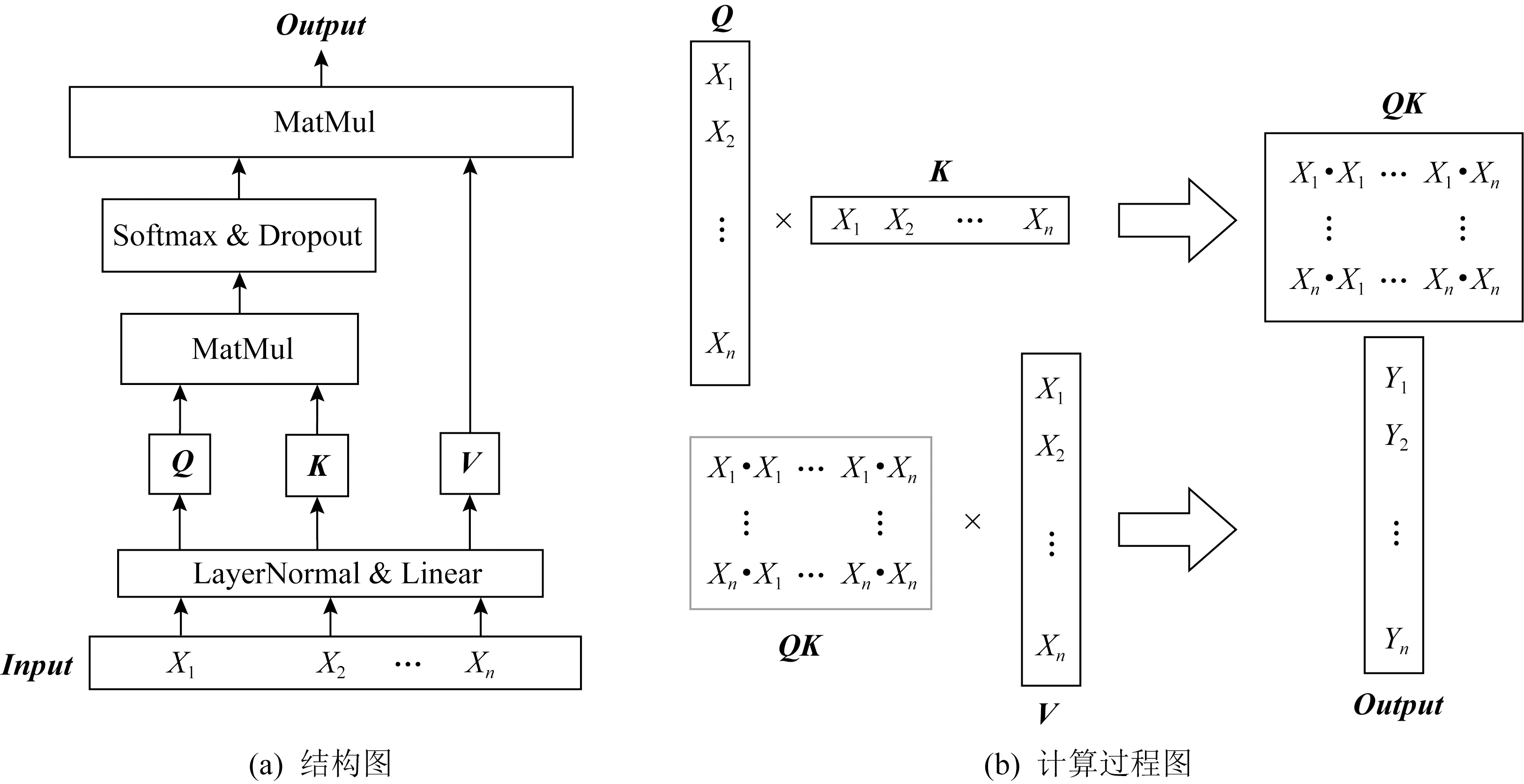
圖1 自注意力機制
對于能量跡集合T中的第i條能量跡ti,j,其有n個特征點,即j=1,2,…,n,為了簡潔表示,此處記ti,j為Xj,計算注意力的過程如圖1(b)所示.輸入的能量跡、變換后的Q,K,V以及輸出Output都是長度為n的向量.輸出Output是加權后得到的,重要的特征將會得到更大的值.本文使用的是縮放點積自注意力,公式為
(4)
其中,n為一條能量跡的特征數量,Dropout以概率p丟棄輸入的每一個特征,丟棄層可以對模型正則化,避免模型快速過擬合.文獻[29]證明了縮放點積自注意力機制將使模型更快地收斂并且空間效率更高.
與文獻[29]不同的是,能量跡輸入是一維數據.不考慮能量跡之間的關聯性,因為能量跡之間的關聯性體現在攻擊階段,建立模板階段只考慮分類問題,這是側信道模板攻擊和NLP的顯著區別.因此,放棄了多頭注意力和掩蔽多頭注意力機制以適應對1維能量跡分配注意力的場景.具體地,Input是1條維度為1×n的能量跡,Q,K,V由輸入的能量跡經過LayerNormal對其n個點進行正則化后分別進入3個全連接網絡學習得到,其中LayerNormal歸一化可以加速網絡收斂速度.然后Q和K進行矩陣點積運算進入匹配操作,緊接著Softmax層用于歸一化不同特征所分配到的注意力大小.Dropout可以對其正則化,這使得訓練出的網絡模型泛化能力更強.然后將最終注意力與V進行矩陣點積運算,將不重要的特征點賦予極小的權值,從而屏蔽能量跡中不重要的點集,賦予大的權值給重要的特征來提取出對模型分類重要的興趣點,完成特征提取操作.
2 SADLSCA模型結構
本節將詳細介紹SADLSCA模型.首先用實驗驗證自注意力機制在側信道攻擊領域是有效的.對輸入的能量跡進行1層全連接分類,如圖2所示,猜測熵沒有收斂到0.然后在輸入和含有256個神經元的全連接層之間放入圖1的注意力機制模塊,再次訓練模型,猜測熵可以收斂到0,至此驗證了自注意力模塊可以提取特征.
Transformer結構采用了多層編碼器解碼器架構用于解決NLP領域中文本前后的關聯性,而在側信道攻擊中,能量跡之間沒有時序關系.因此龐大的Transformer架構并不適用于側信道攻擊.本文采納了Transformer和Vision Transformer編碼器部分的優點,構建了輕量級的適用于側信道攻擊的模型SADLSCA,如圖3所示.模型分為3部分:輸入數據處理、編碼器、分類頭.
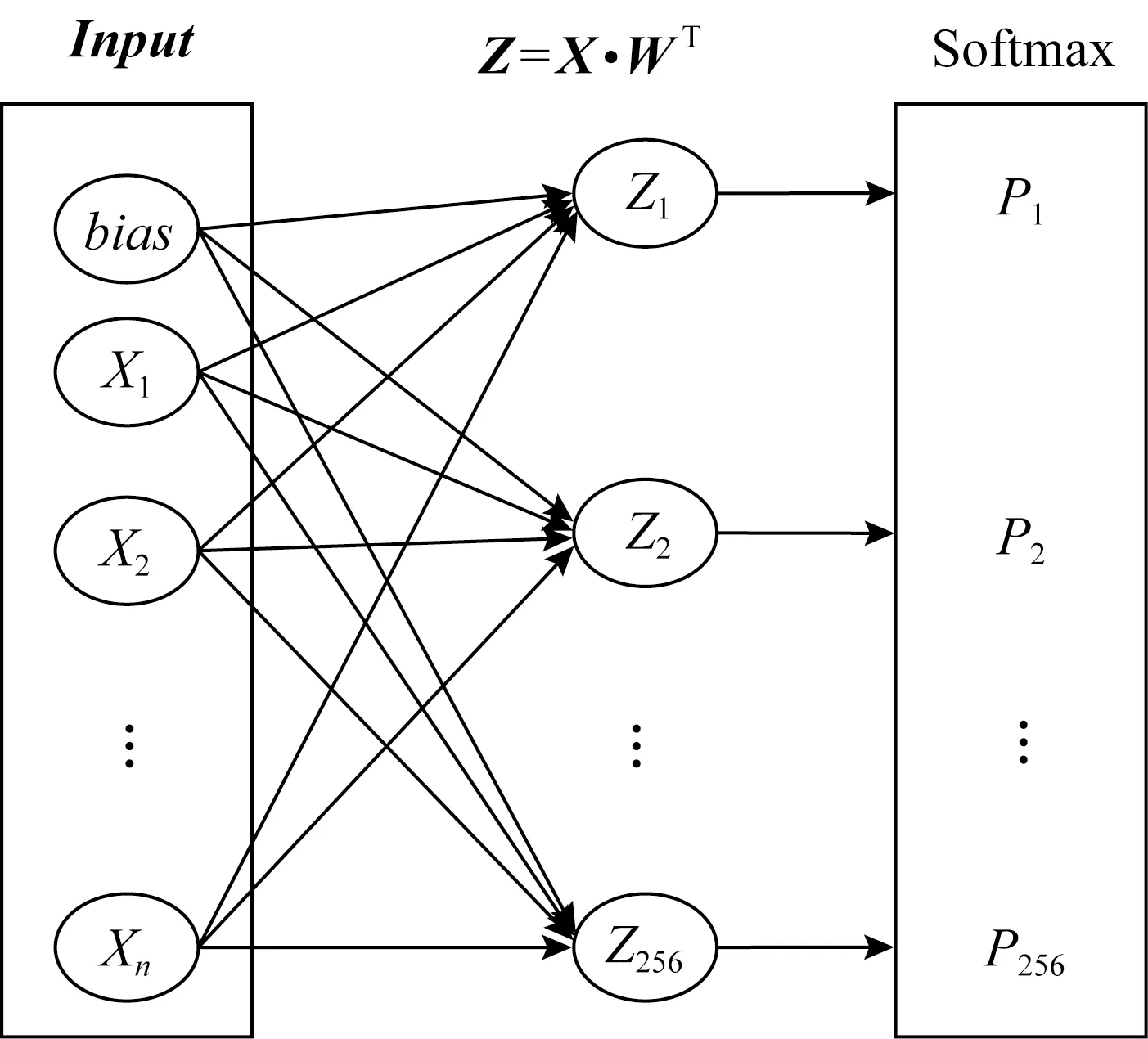
圖2 單層神經網絡
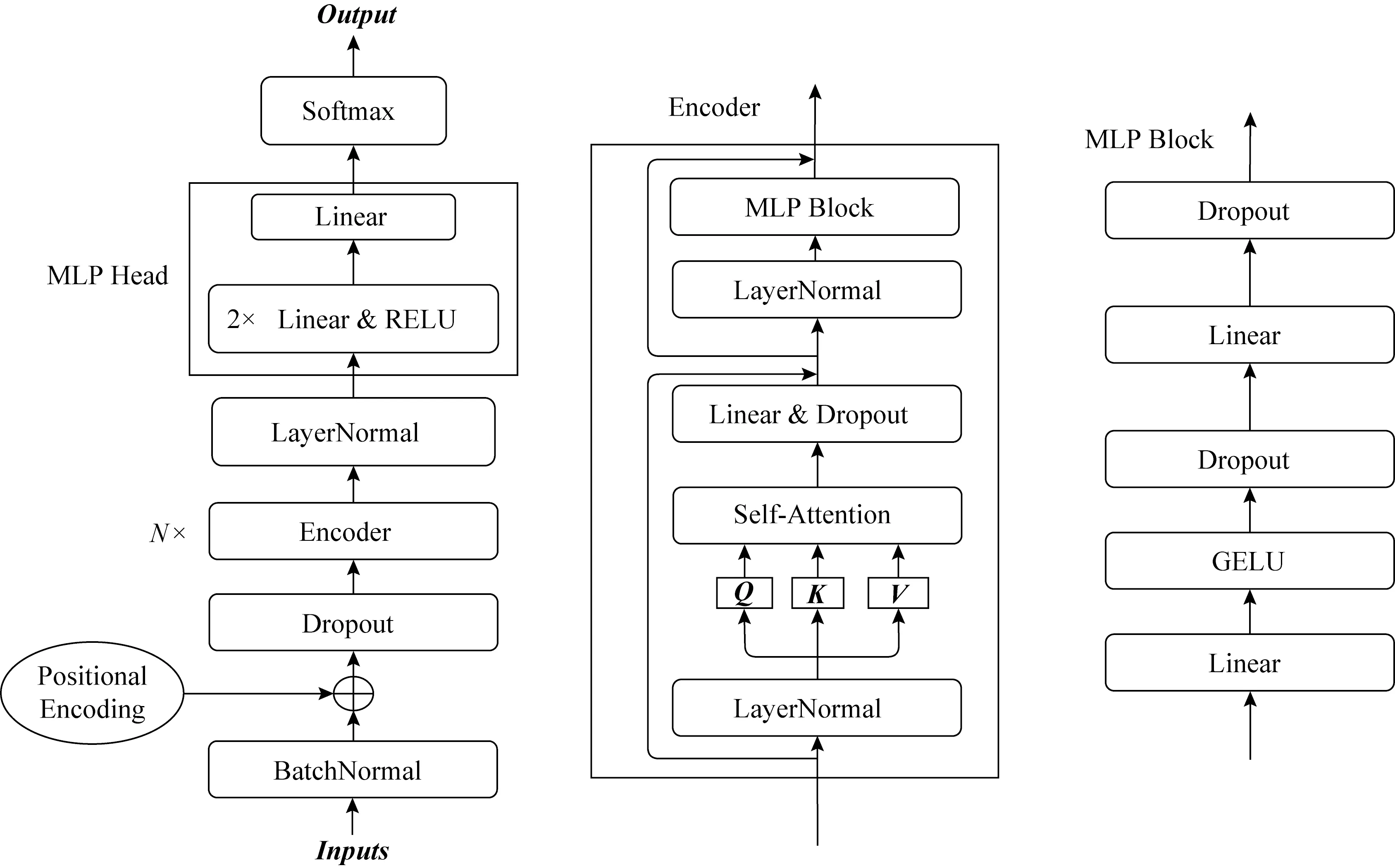
圖3 SADLSCA模型結構
2.1 輸入數據處理
輸入數據處理由BatchNormal[34],Positional Encoding[29]和Dropout[35]這3個模塊組成.BatchNormal用于對輸入數據進行歸一化,加速模型的訓練速度,使得模型更快地收斂.Positional Encoding用于對輸入數據進行位置編碼.Vaswani等人[29]指出自注意力機制的運算方式會丟失特征的時序關系,所以需要對能量跡的位置信息進行編碼,編碼后的每條能量跡特征之間的時序關系被唯一確定.位置編碼使得能量跡的每個特征都是獨一無二的,避免了打亂特征位置放入模型卻得到相同的輸出.在1條能量跡中,尤其是采用了防護措施的數據集上,能量跡中的特征點的位置關系極其重要,因為和能量泄露的時間點相關聯.Vaswani提出相應的位置編碼公式,由于能量跡的特征是1維數字,無法直接使用Vaswani提供的公式,所以選擇了文獻[33]中Dosovitskiy提出的位置編碼思想,直接對輸入的能量跡加上相同維度的可訓練參數即可.Dropout是丟棄層,以概率p丟棄輸入的每個特征,丟棄層可以對模型正則化,避免模型快速過擬合.
2.2 編碼器
編碼器是模型最核心的部分,主要有Self-Attention和MLP Block 2部分.編碼器的設計使得輸入與輸出保持相同的形狀,因此可以疊加多層編碼器以適應大數據集的訓練,使得模型效果更佳.編碼器總體結構采用2層殘差結構便于梯度反向傳播,使得梯度有效回傳,加快模型收斂的速度,解決了梯度消失和模型收斂速度慢的問題.對于編碼器的輸入X和輸出Y滿足如下公式:
Z=X+W0(fDropout(SATTN(X)))+b0,
(5)
Y=Z+MB(LNORM(Z)),
(6)
MB(X)=fDropout(W2(fDropout(fGELU(W1Z+
b1)))+b2),
(7)
其中:SATTN函數為圖1對應的式(4),用于計算注意力W0,W1,W2為全連接網絡的矩陣;b0,b2,b2為其對應的偏置參數;MB(X)為MLP Block所對應的網絡;fDropout為丟棄層網絡.
在編碼器中,LayerNormal用于標準化每條能量跡的特征,加速模型的收斂速度.能量跡進入3個不同的全連接網絡得到3個相同形狀的向量Q,K,V,用于求自注意力.此處的LayerNormal,Q,K,V和自注意力模塊與圖1的結構完全相同,拆分出來僅僅是為了方便觀察殘差結構,該模塊可以并行化訓練,減少模型的訓練時間.編碼器中的線性層和丟棄層與輸入保持相同的形狀,其中丟棄層用于正則化以避免模型在訓練過程中快速過擬合的狀況.
編碼器中多層感知機塊(MLP Block)的設計借鑒了文獻[33]的結構和經驗,一共2層全連接,第1層全連接網絡的神經元個數是輸入特征個數的4倍;第2層全連接網絡的神經元個數與多層感知機輸入的特征數量相同,GELU激活函數避免了模型在輸入數值比較小的情況下梯度消失的問題,文獻[25]證明了在建模階段GELU激活函數會表現得更好.2個Dropout層對模型正則化,避免模型快速過擬合.
2.3 多層感知機分類頭(MLP Head)
MLP Head由3層全連接網絡和2層RELU激活函數層組成:第1層全連接網絡的神經元個數是輸入數據特征的一半;第2層全連接網絡用于分類,其神經元個數由泄露函數決定,取值9或256.第1層全連接網絡神經元個數減半是為了剔除一半不重要的特征,將重要的特征壓縮,從而提取出比較重要的特征.同理,第2層網絡在第1層網絡的基礎上再次減少一半的特征數量,最終使用第2層全連接網絡進行進一步分類達到更佳效果,這種神經網絡設計借鑒了卷積網絡中全連接網絡展開層的設計.RELU使模型在輸入數值大于0 的情況下梯度可以快速地反向傳播,模型會更加關注對正確分類起到決定性作用的特征.模型在訓練過程中不需要Softmax層,直接使用Pytorch集成的交叉熵損失函數可以獲得更好的數值穩定性.在攻擊階段需要先使用Softmax層輸出各個類別的所占權重的比例.
值得注意的是,當編碼器只有1個時SADLSCA屬于簡單模型,可以在小數據集上訓練出很好的效果.當數據集增大時,為了使得模型效果更好,有2個方法:第一,增加編碼器的個數,雖然模型中使用多個編碼器會訓練更長時間,編碼器并行化訓練加速模型收斂速度.同時,Vaswani等人[29]指出當數據集比較大時,編碼器的疊加效果將更好.第二,由于SADLSCA在編碼器個數為1的情況下仍然屬于簡單模型,并且可以收斂,Perin等人[1]證明了集成方法在機器學習側信道攻擊領域內仍然有效,SADLSCA單層編碼器模型是屬于簡單模型,可以使用集成的方法.
3 實驗驗證
3.1 實驗環境
實驗環境為Python3.8+Pytorch1.8.1+cuda10.1;服務器內存為128 GB,顯卡為GM206GL;顯存為4 GB.
3.2 數據集介紹
使用的數據集為ASCAD和CHES CTF 2018,是采集電磁輻射的能量跡組成的數據集.本文的分析同樣可以擴展到其他側信道攻擊泄露數據集,如能耗泄露.
1) ASCAD數據集.
ASCAD數據集[25]是由Prouff發布的,由屏蔽AES-128在8位微控制器(ATmega8515)上軟件實現時被采集的測量值組成,算法實現采用了布爾掩蔽對策和隨機延遲對策.在第1輪加密中,與密鑰關聯的第1個字節和第2個字節未受到掩碼保護,即前2個字節的掩碼為0,其余14個密鑰字節掩碼都是隨機的.其中有2個數據集版本,第1版本數據集擁有5萬條能量跡用于訓練神經網絡,1萬條能量跡用于攻擊,且它們的密鑰是固定的,每條能量跡包含700個時間樣本點(特征).注意,這1萬條能量跡拆分成2份,各5 000條分別用于驗證和攻擊,記為ASCAD_fixed_key.第2版本數據集包含20萬條能量跡用于訓練神經網絡且密鑰可變,10萬條能量軌跡用于攻擊且密鑰固定,每條能量跡包含1 400個時間樣本點(特征).同樣將這1萬條能量跡拆分成2份用于驗證和攻擊,記為ASCAD_variable_key.
2) CHES CTF 2018數據集.
該數據集是2018年密碼硬件和嵌入式系統會議(the Conference on Cryptographic Hardware and Embedded Systems, CHES)發布的.該數據集由屏蔽AES-128運行在32位STM微控制器上的測量值組成.算法實現采用布爾掩蔽對策且16位掩碼隨機生成.訓練集包含4.5萬條能量跡且密鑰固定,驗證集和攻擊集各含2 500條能量跡且密鑰固定,攻擊集和驗證集密鑰相同但與訓練集的密鑰不同.每條能量跡由2 200個時間樣本(特征)組成,記為CHES_CTF_2018.
3.3 模型初始化設置
SADLSCA中網絡的權重分布初始化為均值為0、標準差為1的正態分布,位置編碼可學習參數初始化為0.
3.4 超參數選擇
在模型訓練時選擇了一些超參數,本文參考已有的參數選擇建議[1,25,29-30],以下的超參數取值是窮舉了參數部分取值得出的較好選擇.一些超參數的選擇如表1所示.
超參數的介紹和選擇理由如下:
1)batch_size設置為512,即每批次讀取512條能量跡放入模型進行訓練.
2)epochs用于控制模型訓練的次數.
3)learining_rate的設置一共3種:0.000 05,0.000 01和0.000 005.
4)leakage_model有很多可選項,模型在ASCAD數據集上訓練時設置為具有256個密鑰空間的中間值模型.在CHES_CTF_2018上訓練模型時,設置為漢明重量模型.
5)num_class數值由泄露模型決定,所以這個超參數設置為256和9(對應漢明重量模型).
6)target_byte是被攻擊密鑰的字節索引(從0開始),在攻擊ASCAD數據集時設置為2,即攻擊密鑰的第3個字節.在攻擊CHES_CTF_2018數據集時設置為0.
7)target_dataset有3個可選項,分別為ASCAD_v1_fixed_key, ASCAD_v1_variable_key, CHES_CTF_2018,用于加載不同數據集的參數信息.
8)dropout用于控制丟棄層丟棄神經元的概率,可以單獨為每個丟棄層設置不同的概率,避免快速過擬合的狀況.
9)num_features與數據集能量跡的特征數量保持一致.
10)depth用于設置編碼器的個數以適用于不同大小的數據集.
11)kr_step用于控制在攻擊階段中求取key rank的步長,可以使得攻擊效果穩定,采取Perin的實現源碼的數值[1],設置為10.
12)runs用于設置混洗次數,設置為100.在攻擊階段求猜測熵時會對模型的輸出混洗多次進行攻擊,然后取其平均值作為最終攻擊結果.
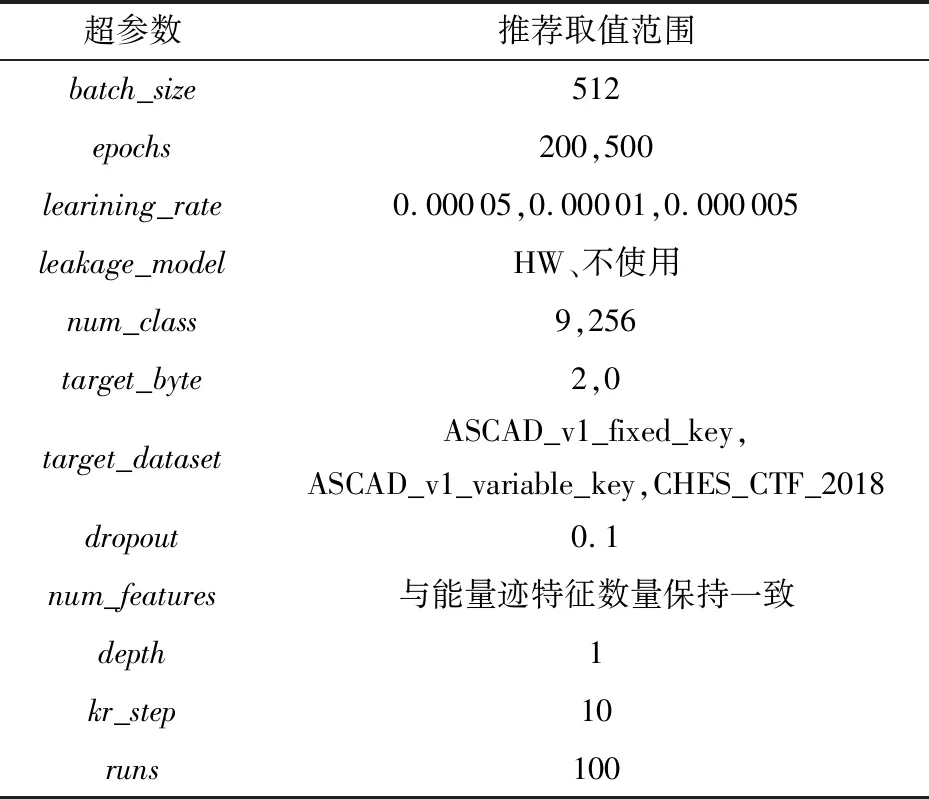
表1 超參數的選擇
3.5 模型效果分析
本節主要通過實驗證明SADLSCA對解決快速過擬合、梯度消失和收斂速度慢等問題的效果,實驗在數據集ASCAD_fixed_key上進行驗證,實驗參數與3.6節的ASCAD_fixed_key實驗中的設置相同,默認為3.4節中推薦的參數選擇.
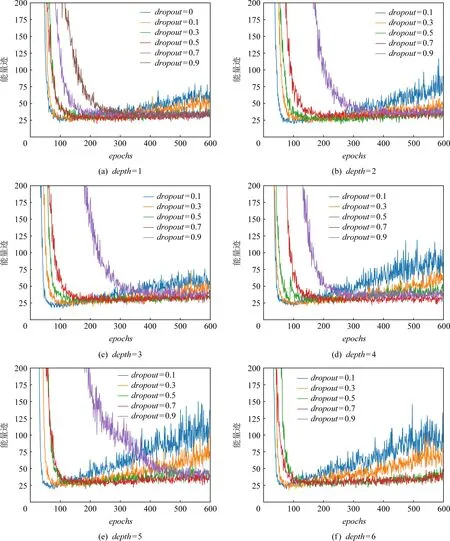
圖4 dropout的不同取值對depth不同模型攻擊時的正則化效果
ASCAD_fixed_key是1個小數據集,在訓練的過程中最容易發生快速過擬合的狀況,本文在該數據集上通過實驗探究SADLSCA中的dropout層是否能解決機器學習側信道攻擊領域中快速過擬合的問題.隨著網絡層數的加深,模型在訓練過程中梯度反向傳播會出現減弱甚至消失的情況,SADLSCA收斂速度會變慢,針對該數據集使網絡模型采用不同depth值進行實驗,并分析SADLSCA是否能解決梯度消失和收斂速度慢的問題.其中dropout設置為0~0.9,步長為0.1;depth設置為1~6,步長為1;其余超參數與3.6節的ASCAD_fixed_key實驗中設置相同,保持固定.
圖4示出depth為1~6,dropout分別為0.1,0.3,0.5,0.7和0.9,迭代1~600次時模型攻擊成功所需要的能量跡數量.當depth=1時,為了對比效果,將dropout=0時的結果也進行了繪圖,即圖5(a)中depth=1的藍色曲線,可以很明顯觀察到,其和dropout=0.1時相似,很快可以達到最佳攻擊效果,SADLSCA僅僅需要迭代100次便可以使用25條能量跡攻擊成功,并且比dropout=0.1時收斂更快,但也很快出現過擬合的狀況,隨著迭代次數的增加,其攻擊成功所需要的能量跡數量逐漸增加.然而dropout為0.5,0.7和0.9時就相對平緩很多,沒有出現過擬合的狀況,但隨著dropout的增大,模型的收斂速度會變慢,這是預料之中的,因為丟棄的概率越大,模型擬合的效果就被削弱得更大,在減少過擬合的同時也減少了模型正常擬合的效果.
隨著depth增加,過擬合狀況會增強,以dropout為0.1為例,當depth增加到3,4,5時,SADLSCA在迭代600次時想要攻擊成功需要100條左右能量跡數量,過擬合極其嚴重,這也反向說明了編碼器塊數的增加(即模型深度增加)會加速模型擬合效果,網絡收斂所需要的迭代次數也明顯減少(depth為1時需要100次迭代,depth為5時僅僅需要50次左右),這也側面驗證了SADLSCA縱向擴展(增加網絡深度)是有效的.同時也驗證了SADLSCA在網絡層數加深的情況下不會出現梯度消失和收斂速度慢的問題,這個效果來源于殘差網絡結構.
depth增加的同時,增加dropout同樣可以抑制過擬合,直觀地看,在該數據集上dropout為0.5和0.7時較好,SADLSCA整體表現得較為平緩.若繼續增加dropout,模型收斂速度太慢,反而丟失了性能,花費太多時間訓練模型得不償失,比如在depth為6,dropout為0.9時,圖5中甚至沒有紫色的曲線,這是因為模型在訓練600次依舊沒有收斂到很好的攻擊效果,其攻擊成功所需能量跡超過200條,所以不在圖中顯示,事實上其攻擊成功所需要的能量跡已經超過500條.
雖然模型攻擊效果的評價指標是猜測熵,但模型在訓練時采用的交叉熵損失函數,兩者雖然不是絕對的同步關系,但相關性依然很大,否則也不會在模型訓練階段采用交叉熵損失函數.為了驗證droput取值對模型最終猜測熵的影響是否與模型訓練時損失值有關,給出了模型depth分別為1,3和5以及各個dropout數值對模型訓練時在驗證集上的損失指標變化情況,如圖6所示:
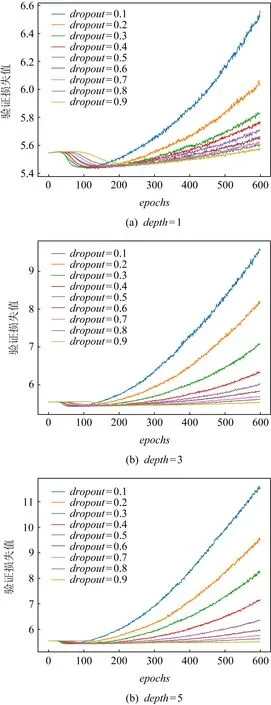
圖5 dropout的不同取值對depth不同模型訓練時的正則化效果
圖5說明了當dropout增加時會緩解快速過擬合的狀況,不考慮圖中dropout為0.9的情況(因為由圖4和之前的分析,這種情況下模型沒有很好地收斂),即使在depth增加的情況下,dropout的增加依然可以很好地緩解過擬合,這也驗證了dropout可以緩解模型訓練時的過擬合狀況.
3.6 實驗結果與分析
本文通過公開的數據集驗證了SADLSCA用于側信道攻擊是有效的,這3個數據集為ASCAD_fixed_key,ASCAD_variable_key,CHES_CTF_2018.如無特別說明,超參數默認為3.4節中給出的數值.
1) ASCAD_fixed_key.
訓練集包含5萬條能量跡,驗證集和攻擊集合各500條能量跡用于驗證和攻擊,且密鑰都是固定且相同的,每條能量跡包含700個時間樣本點.設置學習率learining_rate為0.000 01,epochs為200,depth為1,target_byte為2(第3個字節),runs為100,圖6展示了SADLSCA(黃色和綠色)以及現有的方法模型在訓練迭代次數為134和216情況下150條能量跡對該數據集進行攻擊的猜測熵(圖6(a))和成功率(圖6(b))的具體變化情況;圖6(a)中紅色曲線所對應的模型是由文獻[25]針對ASCAD數據集提供的開源的并訓練好的最佳CNN模型,模型迭代訓練75次,由6層CNN網絡組成,每層200個神經元個數,batch_size=200,num_class=256;圖6(a)中藍色曲線對應的Ensemble模型是由文獻[1]提供的開源集成學習模型,且集成的是MLP模型,使用漢明重量泄露模型,num_class為9,按照其最佳參數設置模型,一共50個模型,每個模型迭代50次,每個模型的模型超級參數由給定范圍的數值區間中取得.
圖6(a)示出SADLSCA在迭代134和216次情況下的猜測熵變化,SADLSCA猜測熵很快就降到0(為了直觀地通過結果對比得出結論,對猜測熵取對數并繪圖),比最佳CNN模型和集成學習模型效果更好.圖6(a)中紅色曲線的震蕩展示了最佳CNN模型攻擊效果的不穩定性,這種不穩定性一方面來自CNN只能提取局部空間信息的特性,而SADLSCA以全局視角提取特征信息;另一方面來源其runs為1,求得的是單次結果,中間出現震蕩意味著并沒有真正收斂,而SADLSCA和集成模型的結果runs為100,求的是平均值,而且自注意機制擅長以全局視角提取特征,因此SADLSCA的數值曲線更加穩定平滑.藍色曲線表示的集成學習雖然比較穩定,但其收斂速度顯然沒有SADLSCA快,甚至在使用了150條能量跡攻擊下猜測熵沒有收斂到0,其最終在數值350時收斂,這是因為集成學習模型的效果比較穩定.圖6(b)展示了SADLSCA的成功率,數值大約在25可以攻擊成功,與最佳CNN模型需要數值在55附近才能穩定相比,減少了54.5%的能量跡數量,SADLSCA更加穩定,整體曲線平滑;與集成學習模型需要數值在350附近才能收斂的結果相比,減少了91%的能量跡數量,SADLSCA攻擊效果更好.同時注意到,迭代次數為134和216的攻擊結果卻相近,這是由于模型中Dropout模塊起到了正則化的作用,避免了模型快速擬合.
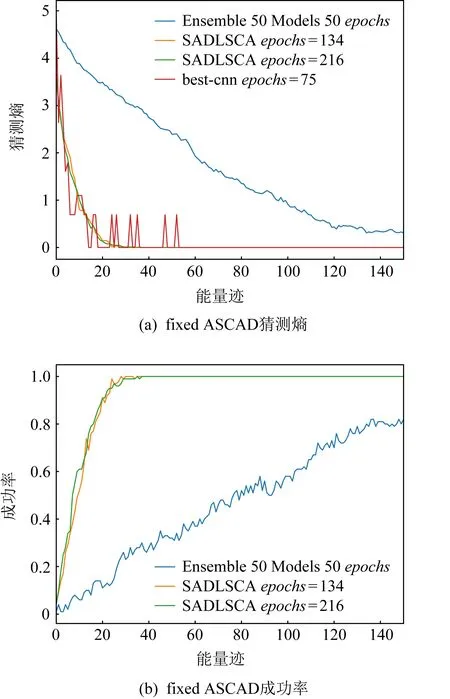
圖6 學習率為0.000 01、epochs為134和216的猜測熵和成功率
2) ASCAD_variable_key.
訓練集包含20萬條能量跡且密鑰隨機,驗證集和攻擊集各5 000條能量跡用于驗證和攻擊并且密鑰固定,每條能量跡包含1 400個時間樣本點,該數據集合比較大.
設置學習率learining_rate為0.000 01,epochs為200,target_byte為2(第3個字節),runs為100,圖7(a)展示了SADLSCA(黃色和綠色)以及現有的方法模型訓練迭代次數為67和78情況下150條能量跡對該數據集進行攻擊的猜測熵(圖7(a))和成功率(圖7(b))的具體變化情況.其中紅色曲線所對應的模型是最佳CNN模型[25],藍色曲線所對應的Ensemble曲線是集成學習模型[1].
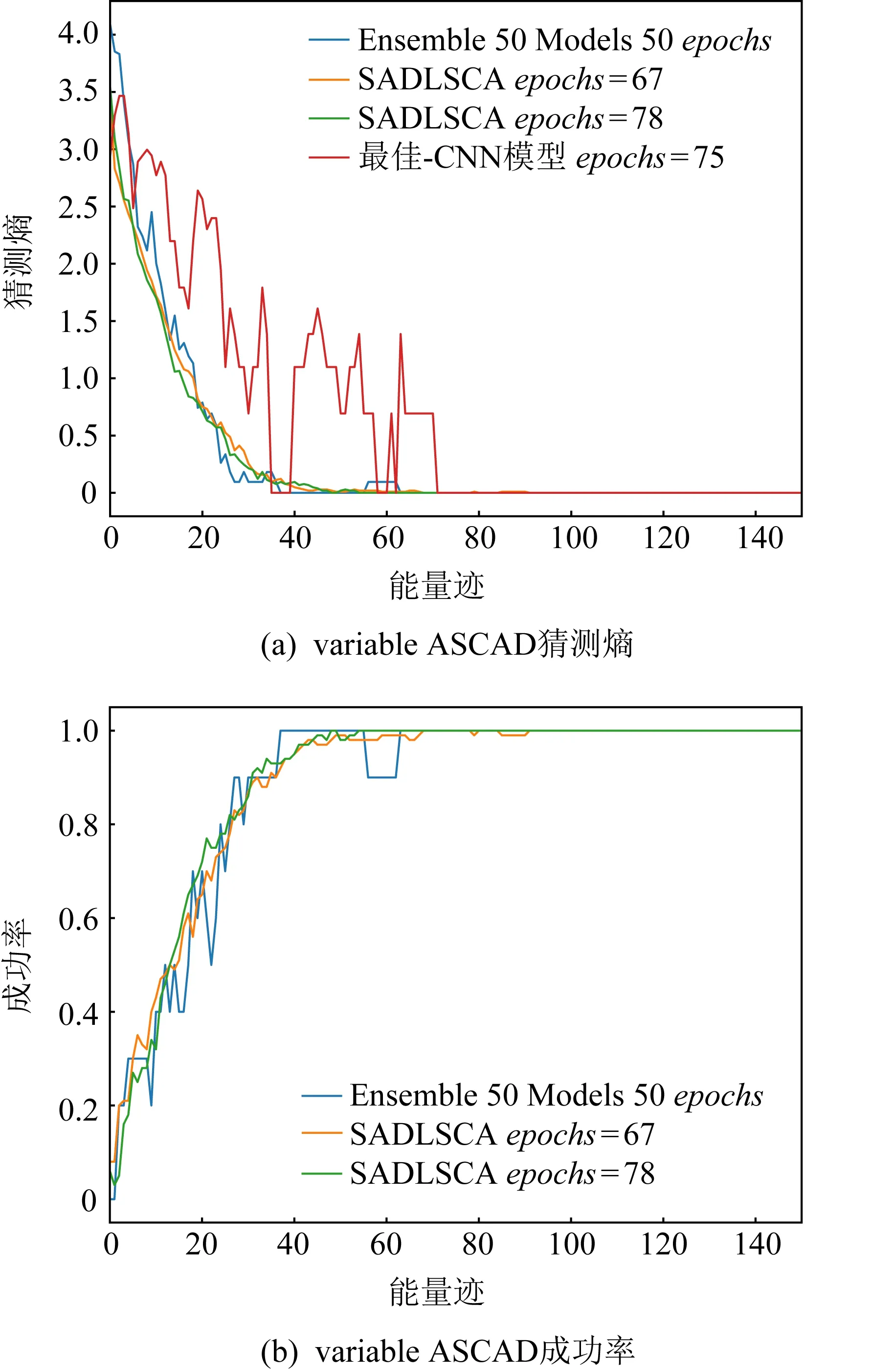
圖7 學習率為0.000 01、epochs為67和78的猜測熵和成功率
圖7(a)的結果展示了SADLSCA在迭代67和78次情況下猜測熵的變化,圖7(a)中黃色和綠色曲線是SADLSCA分別在迭代67,78次下的攻擊結果,最終收斂于數值50左右.圖7(a)中紅色曲線的震蕩原因與3.4節ASCAD_fixed_key中的原因相同,最佳CNN模型最終收斂于數值70左右.同時藍色曲線表示的集成學習收斂速度顯然沒有SADLSCA快,其最終在數值65左右收斂.圖7(b)同樣清晰展示了SADLSCA的成功率,綠色曲線是SADLSCA迭代78時的攻擊成功率,數值大約在50~60之間可以攻擊成功,與最佳CNN模型需要數值在70附近才能穩定相比,減少了28.6%的能量跡數量,SADLSCA更加穩定,整體曲線平滑;與集成學習模型需要數值在65附近才能收斂的結果相比,減少了23.1%的能量跡數量,同樣彰顯了SADLSCA的高效性.
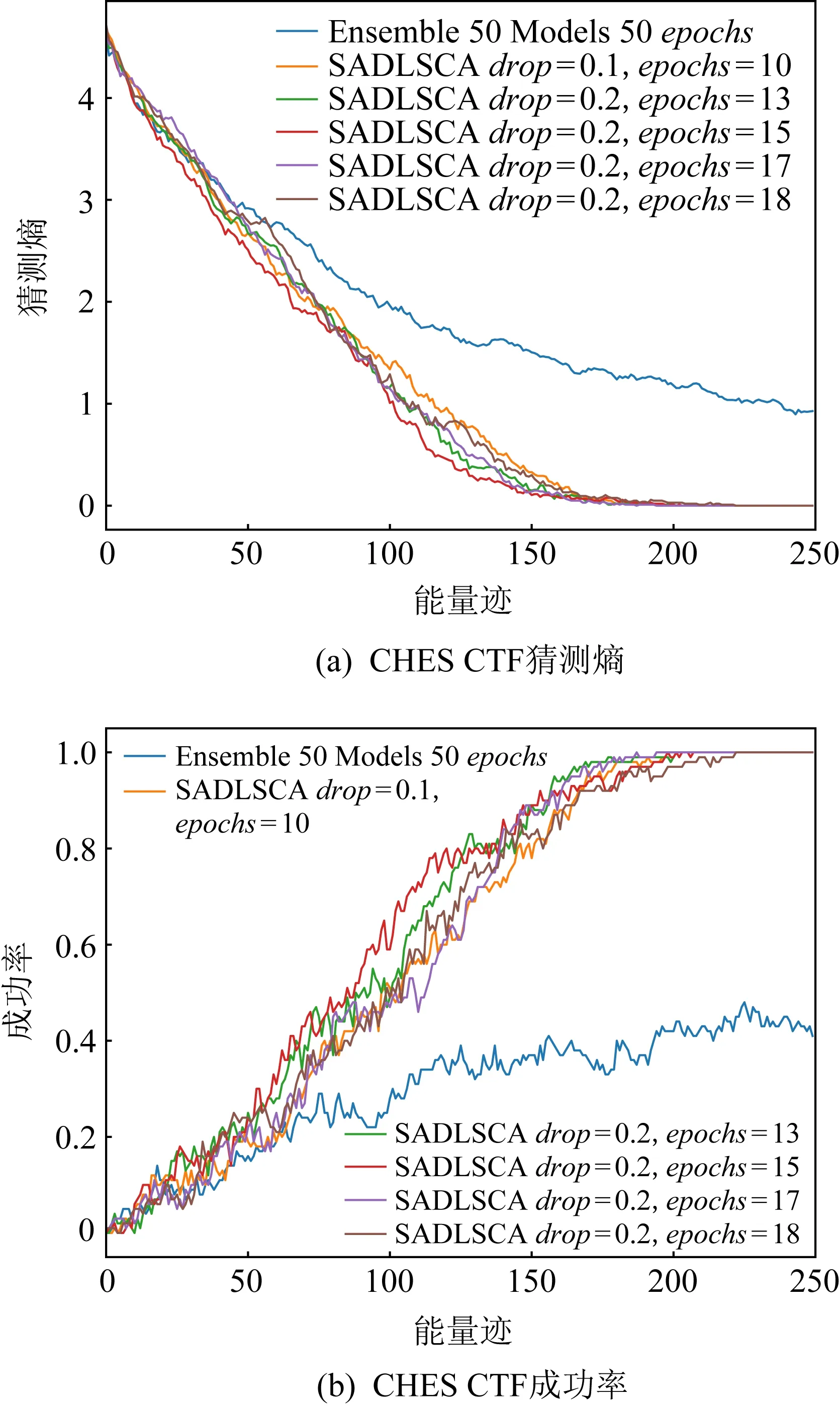
圖8 epochs為10,13,15,17,18的猜測熵和成功率
3) CHES _CTF_2018.
因為該數據集已經進行過預處理,所以模型中的BatchNormal對于該數據集而言是多余的模塊.訓練集包含4.5萬條能量跡且密鑰固定,驗證集和攻擊集各250條能量跡用于驗證和攻擊,密鑰固定且與訓練集密鑰不同,每條能量跡包含2 200個時間樣本點.設置學習率learining_rate為0.000 05,epochs為100,depth為1,target_byte為0(第1個字節),runs為100,dropout為0.1和0.2,leakage_model為HW(漢明重量模型),圖8展示了模型以及使用集成學習模型在訓練次數分別為10,13,15,17,18的情況下進行攻擊求得的猜測熵(圖8(a))和成功率(圖8(b))的具體變化情況,圖8(a)中藍色曲線對應的Ensemble模型是由文獻[1]提供的開源集成學習模型,其余曲線都是SADLSCA在不同迭代次數下的攻擊效果,具體見圖例.
圖8(a)展示了集成MLP網絡的方式在處理CHES_CT_2018數據集時不能收斂,與文獻[1]結論相同,這是由于該數據集生成的過程中使用了隨機掩碼,而MLP網絡空間平移不變性較差,導致MLP模型攻擊效果較差.圖8(b)展示了SADLSCA在數值大約為175時可以攻擊成功,此時成功率為1.與文獻[1]中使用集成學習對50個CNN模型分別訓練50次進行集成的方法需要300條能量跡攻擊才能收斂相比,攻擊所需能量跡數量減少了41.7%,同時SADLSCA是單層編碼器且僅需10~20次訓練就達到這個攻擊效果,收斂速度很快并且攻擊效果更好.
4 總結和未來的工作
本文主要的研究工作是在深度學習側信道攻擊中引入了自注意力機制,對自注意力機制作了詳細介紹并使其適用于深度學習側信道攻擊.基于自注意力機制構建了一個深度學習側信道攻擊模型SADLSCA,解決了基于深度學習的側信道攻擊模型在訓練時存在的快速過擬合、梯度消失和收斂速度慢等問題,并在ASCAD_v1_fixed_key,ASCAD_v1_variable_key,CHES_CTF_2018這3個公開數據集上進行實驗,實驗結果驗證了SADLSCA的可用性和高效性,同時本文給出了SADLSCA可以達到很好攻擊效果的常用超參數數值.
攻擊階段中,猜測熵的計算所耗費的內存空間與攻擊集中能量跡的數量成正比,計算猜測熵會極大地消耗存儲資源和計算資源.Transformer架構[29]的輸出是狀態的疊加,攻擊過程中猜測熵的求解也是狀態的疊加,兩者有著天然的關聯.因此,下一步我們將主要研究使用Transformer解碼器架構構建模型取代模板攻擊中的攻擊階段,避免攻擊階段中猜測熵的計算,提升攻擊效率.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中老年保健(2021年12期)2021-11-30 02:58:01
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
攝影之友(影像視覺)(2019年2期)2019-03-05 08:27:14
中華詩詞(2018年11期)2018-03-26 06:41:34
光學精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年8期)2016-10-09 02:11:50
核科學與工程(2015年4期)2015-09-26 11:59:03
中國醫藥科學(2015年19期)2015-02-27 12:33:11
