基于LSTM的Linux系統下APT攻擊檢測研究
2022-08-08 01:35:06時紹森文偉平
信息安全研究 2022年8期
時 林 時紹森 文偉平
(北京大學軟件與微電子學院 北京 102600)
隨著網絡逐漸滲透到人們生活的方方面面,網絡空間的安全問題也逐漸被重視起來.網絡中的攻擊手段多種多樣,高級持續威脅(advanced persistent threat, APT)攻擊為其中較為復雜并且危害性較高的一種.APT攻擊過程貫穿系統外部與系統內部,且持續性很強,因此難以進行檢測與徹底防御,需要得到更多的關注.近年來,全球APT組織持續增多,攻擊涉及金融、政府、教育、科研等重點行業[1-2].到2021年上半年[3],APT攻擊整體形勢嚴峻,發現和披露的APT攻擊活動較2020年同期大幅增加.
APT攻擊周期一般較長,在長期且持續的攻擊下,攻擊者會將多種攻擊方式進行組合并調整,導致防護系統無法對經過精心處理的攻擊特征完成規則匹配,最終導致目標機器遭到入侵.目前,大多數IDS系統僅具有單步攻擊的檢測能力,并沒有將持續性的攻擊聯系起來,且檢測內容往往局限于網絡流量,如魚叉攻擊、XSS、SQL注入等.一些APT攻擊監控系統使用IDS的告警日志進行攻擊判定.報警日志往往具有一定比例的誤報,判定的攻擊行為并不準確.更重要的是,僅檢測流量往往會忽略完整的APT攻擊過程,APT攻擊攻入系統后,會進一步釋放控制機器的惡意代碼,導致主機系統發生大量攻擊.因此,將主機內的攻擊行為與網絡流量中的攻擊行為相結合,共同作為APT攻擊的判斷條件是十分必要的,并且對于APT攻擊檢測而言,主機內的惡意行為非常重要.
目前,針對Windows系統的入侵檢測系統與沙箱系統較多,而針對Linux系統攻擊的分析與防御措施較為薄弱.很多惡意代碼檢測分析工具與防火墻都是針對Windows系統的,側重于Linux系統的惡意文件檢測手段較少.例如,開源的Cuckoo沙箱、商用的騰訊微步沙箱、奇安信文件分析平臺等對Windows惡意文件的檢測較為成熟,但是對于Linux平臺上的惡意文件缺乏檢測能力.因此針對Linux系統的APT攻擊檢測亟待解決.此外,目前業內普遍用于研究的攻擊數據也只局限于網絡流量數據或某些APT攻擊釋放的惡意文件,并不具有很強的關聯性.APT攻擊持續時間長、攻擊步驟繁多的特點導致APT攻擊樣本并不豐富,目前還沒有形成一套科學的數據集供廣大安全從業人員進行研究.
針對以上問題和研究現狀,本文提出并實現了一種基于LSTM(long short-term memory)的Linux系統下APT攻擊檢測方案.該方案綜合了主機側與網絡側的雙側行為特征,將特征數據集依據APT攻擊的生命周期進行建模重構,進而使用LSTM進行訓練,得到了檢測效果良好的APT攻擊檢測模型.
本文主要貢獻如下:
1) 捕獲惡意Linux ELF文件行為的LAnalysis沙箱.
構建了一款能力較強的分析Linux ELF文件的LAnalysis沙箱,通過對相關內核函數以及系統調用函數的針對性內核插樁,LAnalysis可以獲取惡意代碼的持久化、隱藏與偽裝、權限提升、進程注入等10類共16種不同的惡意行為.
2) 符合APT攻擊生命周期的數據集.
使用LAnalyise沙箱分析了500個惡意家族的共4 101個惡意樣本.獲取了惡意樣本的主機側攻擊行為特征,構建了Linux主機側的攻擊數據集,并結合網絡側數據集NSL-KDD按照APT攻擊生命周期,構建了一套兼具主機行為和網絡行為特征的APT攻擊數據集.
3) 基于LSTM的APT攻擊檢測模型.
將符合APT生命周期的數據集放入注重時序性特征的LSTM進行訓練,其中包含網絡與主機雙側特征,得到了可以檢測APT攻擊的深度學習模型,并取得了良好的應用效果.
1 相關工作
APT攻擊生命周期較長,各種攻擊行為之間具有一定的關聯性,這給檢測帶來很大挑戰.目前的檢測手段主要分為側重于主機側APT攻擊部署的惡意代碼的檢測、側重于網絡側惡意流量分析的檢測以及將多步攻擊相結合的注重攻擊關聯性分析的檢測等.
主機側惡意代碼檢測主要是對APT攻擊釋放的木馬[4]或后門等文件進行檢測.當前針對可疑惡意程序的分析方法主要為動態分析與靜態分析[5].馮學偉等人[6]利用惡意代碼中使用的IP地址之間的聯系進行聚類;霍彥宇[7]將分析惡意代碼時產生的行為警報信息處理為特征,使用聚類的方法進行分類識別;Sharma等人[8]提出一種入侵檢測框架,使用6個監視器監視系統中的行為,統計4天中各個文件的更改情況以及進程數據作為正常情況后續進行狀態檢測,若文件與進程數據出現異常就會發出威脅告警;Moon等人[9]提出一種基于主機中發生行為的攻擊檢測方法,通過捕獲主機中39種特定行為的發生作為特征對APT攻擊進行檢測;孫增等人[10]提出基于沙箱回避對抗的相關檢測方法,統計了常見沙箱中使用系統的各種特征,在代碼運行前查找所運行系統的相關特征,進而判別當前軟件是否在沙箱中運行.
網絡側惡意流量分析檢測是對流量中的信息進行特征提取[11],利用這些特征通過規則匹配或機器學習與深度學習訓練模型等方式判定是否為異常流量.攻擊者通過系統中運行的Web服務進行入侵,或從已經完成入侵的系統中橫向移動至其他系統,在此期間都會產生大量的異常流量.因此檢測相關攻擊可以從異常流量入手.戴震等人[12]通過流量分析發現惡意軟件的遠端控制服務器對其進行指令發送的過程具有一致性,進而通過解析報文的通信特征對攻擊進行判定;Chuan等人[13]通過結合機器學習模型形成了一種集成學習器對URL中的特征進行分析與提取,對具有惡意風險的網站進行識別;Liu等人[14]通過對數據集NSL-KDD進行處理形成了一套新的網絡攻擊數據集,使用DBN網絡降維后通過SVD模型對可疑數據進行識別與分類.APT攻擊流量檢測中還有一部分是通過域名檢測來判定惡意流量的.Vinayakumar等人[15]收集了網上公開的惡意域名數據集,并在系統中收集了DNS日志,在合并處理后采用LSTM進行檢測;Niu等人[16]針對移動端的DNS日志進行C2域名檢測.
攻擊關聯性分析檢測更加注重對APT攻擊之間關聯性的分析與建模.Bahrami等人[17]利用殺傷鏈模型對APT攻擊場景進行建模,該模型將APT攻擊分解為40多項子活動,并確定了APT攻擊中的行為特征,進而進行攻擊檢測;Kim等人[18]對殺傷鏈模型進行了改進與細化,主要用于對IOT網絡的APT攻擊進行檢測;Zhou等人[19]通過對移動目標進行防護來處理APT攻擊中的路徑突變問題;Jasiul等人[20]和杜鎮宇等人[21]設計了不同的基于Petri網的攻擊檢測模型,文獻[20]使用主機內的系統特征與文件特征生成了有色Petri網,利用其對惡意軟件中的惡意行為進行建模,文獻[21]中的模型通過匹配攻擊路徑,并根據收集到的報警信息對攻擊行為進行預測;Ghafir等人[22]將屬于一個完整APT攻擊的不同子攻擊活動的檢測結果進行關聯,通過HMM對其解碼,確定最有可能的攻擊序列;Niu等人[23]使用動態步驟圖對APT攻擊進行映射,建立網絡攻擊模型捕獲APT攻擊因素;孫文新[24]提出了因果場景生成算法,將相關流量以及對應的攻擊步驟匹配至殺傷鏈模型中,發掘流量數據之間的相關性.
通過對以上APT攻擊檢測方法的研究發現,目前的檢測方法存在若干問題,包括對APT攻擊中單個攻擊之間的時序性結合關注度不高;針對Linux系統中惡意軟件的檢測與行為捕獲工具較少,且已有工具效果較差;由于APT攻擊周期過長導致業內對于APT攻擊的高質量數據集較少等.
2 Linux系統下APT攻擊原始數據集的構建
高質量的APT攻擊數據集是構建APT攻擊檢測模型的關鍵.本文構建的原始數據集融合了APT攻擊的主機側與網絡側雙側特征,為后續生成APT攻擊數據集提供了良好基礎.構建Linux主機攻擊行為捕獲沙箱LAnalysis,利用其分析Linux ELF惡意文件生成主機側初始數據集,對網絡公開數據集NSL-KDD進行處理,生成網絡側初始數據集.
2.1 沙箱LAnalysis
目前常用的開源沙箱以及眾多商用和在線文件分析平臺針對Linux ELF文件的惡意代碼樣本分析能力較弱,以致無法獲取惡意樣本的全部惡意行為.本文構建了一款能力較強的分析Linux ELF文件的沙箱LAnalysis,針對APT攻擊中使用的惡意代碼進行分析,進而構建APT攻擊中的主機行為數據集.
LAnalysis為C/S架構,分為服務端(監控端)與客戶端(被監控端)2部分.檢測方式為服務端將樣本發送至客戶端,對目標樣本進行檢測,檢測完后將檢測報告進行回傳,服務端將檢測報告進行分類處理,形成不同類惡意行為的特征文件.系統結構如圖1所示:
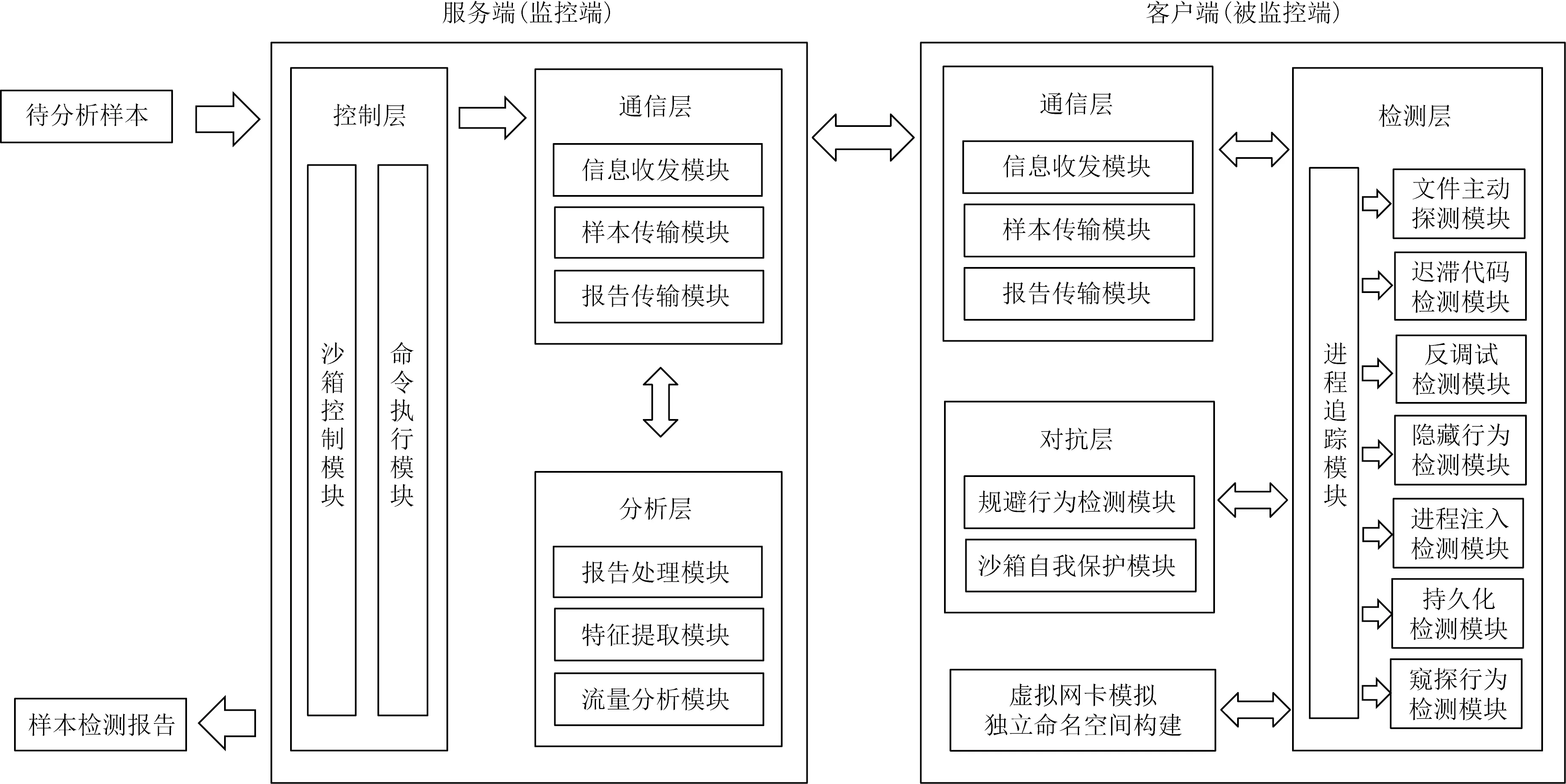
圖1 LAnalysis架構
服務端分為通信層、分析層、控制層共3層.控制層依據用戶傳遞過來的指令啟動沙箱工作,并且通過命令執行的方式對沙箱進行控制;通信層負責收集和處理另一端發來的消息并進行下一步流程的推進;分析層對客戶端發來的分析樣本的行為報告以及流量進行處理與分析,進一步提取出該樣本的惡意行為特征.
客戶端由一個沙箱虛擬機組成,沙箱分為通信層、檢測層與對抗層共3層.檢測層負責部署沙箱檢測模塊,對目標樣本進行行為分析;通信層負責與服務端的溝通并將分析結果回傳給服務端;對抗層負責部署沙箱自我保護模塊與規避行為檢測模塊,對惡意樣本進行檢測并與破壞沙箱的行為進行對抗.
LAnalyisis獲取惡意代碼的10類共16種不同的惡意行為,在檢測與分析APT攻擊中部署的惡意Linux ELF文件的惡意行為上表現更為出色.
2.2 Linux ELF惡意文件行為捕獲與檢測
LAnalysis對惡意代碼的10類惡意行為進行捕獲,用于構建主機行為數據集.具體為反調試行為、遲滯代碼行為、持久化行為、文件隱藏行為、網絡隱藏行為、進程隱藏行為、網絡行為、權限提升行為、進程注入行為、對系統的窺探行為.捕獲行為的選擇來自攻擊框架ATT&CK中常用的攻擊行為.
惡意行為的捕獲與檢測主要依賴于LAnalysis的檢測層,它運行在沙箱內部,部署沙箱監控的各個模塊以檢測目標樣本的各類惡意行為,是整個沙箱系統的核心檢測層,由SystemTap編寫的8個惡意行為檢測模塊構成,分別為文件主動探測模塊、遲滯代碼檢測模塊、反調試檢測模塊、隱藏行為檢測模塊、進程注入檢測模塊、持久化檢測模塊、窺探行為檢測模塊、進程追蹤模塊. 除此之外還有為了防止沙箱被破壞所構建的沙箱自我保護模塊.另外,還有一些惡意行為的檢測不是通過SystemTap部署內核探針完成的,而是通過惡意代碼運行前后系統發生的變化進行檢測.
2.3 APT攻擊數據集構建
在APT攻擊中,主機攻擊指攻擊者通過各種方式入侵受害者的主機系統,在主機系統中植入惡意代碼,進而產生對受害者主機的控制與破壞行為.網絡側攻擊指在進入主機前在網絡空間中進行的流量攻擊或建立C2通道遠程操控進行攻擊的手段.
2.3.1 APT攻擊主機行為數據集的構建
通過對大量不同惡意家族中惡意樣本的分析,獲取其在Linux主機上產生的惡意行為,將其構建為APT攻擊的主機行為數據集.通過對無害良性樣本進行分析,提取與惡意樣本同樣的特征,作為正常主機行為特征,為構建非APT攻擊數據集提供原數據基礎.另外,為了方便生成APT攻擊樣本數據,需要將主機行為數據集進行標簽化處理.
2.3.2 APT攻擊流量數據集的處理
本文選用的流量數據集為NSL-KDD. NSL-KDD是入侵檢測領域的一個經典數據集,其每條數據均由41種特征組合而成,每個網絡連接被標記為normal或attack.本文使用NSL-KDD作為APT攻擊網絡攻擊數據集的原始數據集,其中attack表示攻擊數據,共有4大類,這4大類又被細分為22種不同的攻擊,共有125 973條數據.為了適應深度學習模型的訓練,通過one_hot對數據進行編碼.對數據集進行維度處理后,還需要將數據和標簽進行分離,同時將同一類標簽的數據進行歸類,以生成APT攻擊流量數據集.
3 基于LSTM的APT攻擊檢測方案
3.1 總體設計
APT攻擊檢測方案分為3個部分,分別為原始數據集生成模塊、APT攻擊數據集生成模塊、模型構建模塊.總體設計圖如圖2所示.
1) 原始數據集生成模塊.
在原始數據集生成模塊中,構建了沙箱LAnalysis并對采集的惡意樣本與良性樣本進行分析,形成APT攻擊的主機行為數據集;同時使用NSL-KDD作為APT攻擊的網絡流量初始數據集.
2) APT攻擊數據集生成模塊.
APT攻擊數據集生成模塊用于將網絡行為數據集與主機行為數據集根據APT攻擊的攻擊流程進行合并重構,將各種單獨的攻擊方式組合成具有前后上下文關聯的APT攻擊,生成APT攻擊數據集.同時,還需要生成非APT攻擊數據集作為深度學習模型訓練的負樣本.
3) LSTM模型構建模塊.
利用生成的APT攻擊數據集與非APT攻擊數據集構建基于LSTM的APT攻擊檢測模型.
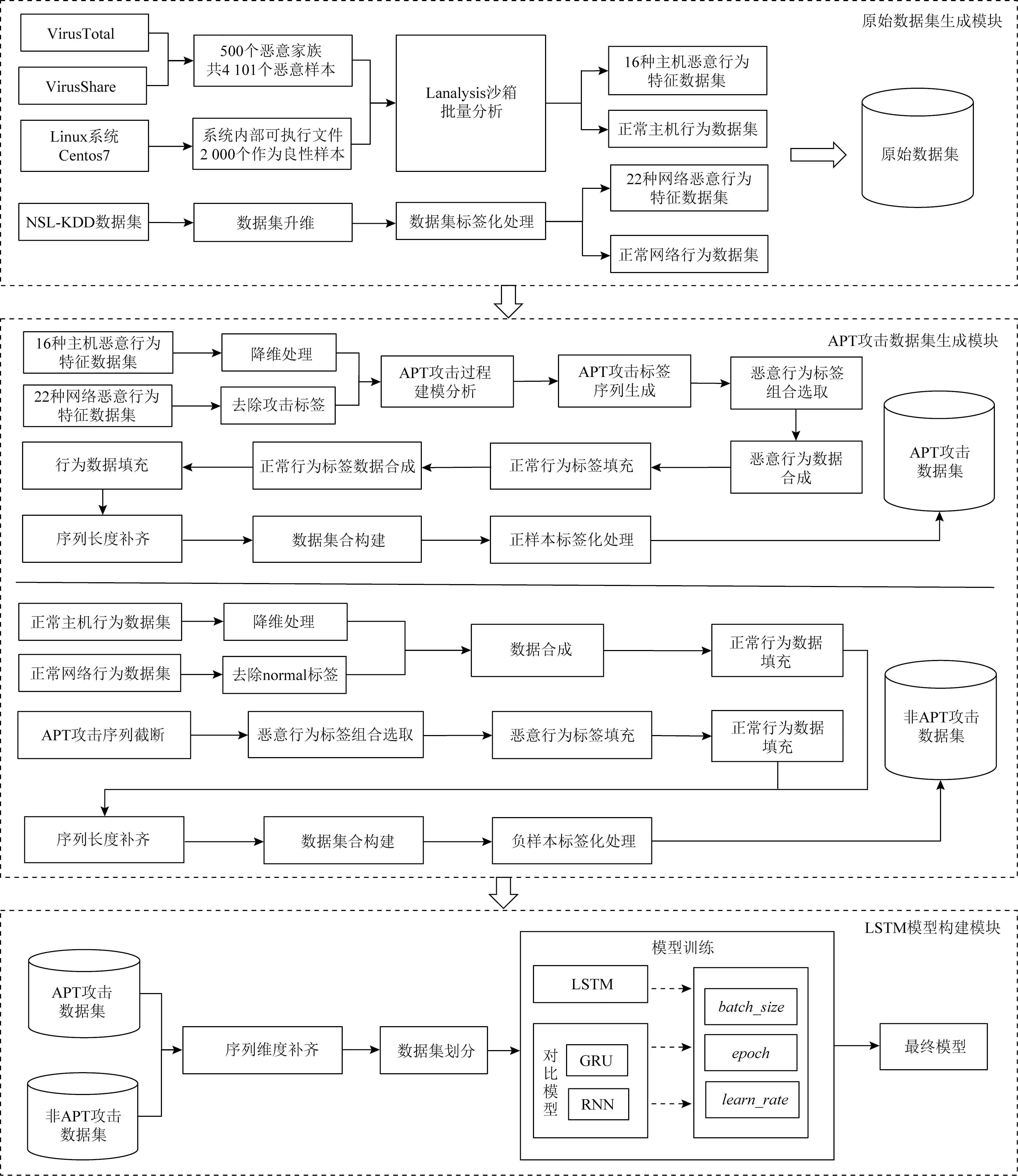
圖2 APT攻擊檢測方案總體設計圖
3.2 APT攻擊數據的生成
在APT攻擊數據生成前首先要針對APT攻擊過程進行攻擊步驟拆分與建模,之后使用網絡行為數據集與主機行為數據集中的子攻擊標簽組成APT攻擊標簽序列,形成符合APT攻擊生命周期的攻擊數據.
3.2.1 攻擊過程建模
根據Hutchins等人[25]提出的網絡攻擊殺傷鏈分析模型(Cyber Kill Chain)可知,1次APT攻擊分多個具體的攻擊步驟.因此將網絡側行為數據與主機側行為數據依據APT攻擊過程進行建模是生成APT攻擊數據的關鍵.由于APT攻擊方式多種多樣,每次攻擊都可能有不同的戰術變化,本文只選用最經典的3種APT攻擊方式進行模擬.
這3種最經典的APT攻擊方式是:釣魚攻擊、利用Web漏洞與操作系統漏洞入侵、利用線下移動設備入侵.3種攻擊方式都包含相似的必要攻擊步驟,但是在感染主機和感染后的行為上略有不同.例如,釣魚攻擊通常沒有針對Web的攻擊行為,但會有可疑的網絡流量出現,若被攻擊者成功執行釣魚程序,則其可以直接以被攻擊者的權限運行,有時不需要進一步提升權限.利用Web漏洞與操作系統漏洞的攻擊方式往往有較多的網絡攻擊流量,且攻入系統后有權限提升行為.利用線下移動設備入侵沒有任何網絡攻擊流量,直接利用U盤、移動硬盤等通過植入惡意代碼進行攻擊,但是在入侵后具有與控制服務器交互的行為,會產生網絡流量.
1) 通過網頁或郵件等進行釣魚攻擊.
由于被攻擊者安全意識不強,誤執行了攻擊者發送的郵件或網頁鏈接的不可信內容,以致主機被感染后遭受到一系列攻擊行為.該種攻擊方式的攻擊過程如表1所示.

表1 釣魚攻擊流程
2) 利用Web漏洞與操作系統漏洞進行入侵.
利用運行的Web漏洞或開放的高危端口對應的系統漏洞,通過網絡入侵進入主機后,進一步部署惡意代碼進行針對主機的攻擊.該種攻擊方式的攻擊過程如表2所示.

表2 利用Web漏洞與操作系統漏洞進行入侵
3) 利用線下移動設備入侵.
以便攜式的移動設備進行攻擊,如移動硬盤、U盤、手機等設備接入主機,可以直接進行植入式攻擊.該種攻擊方式的攻擊過程如表3所示:

表3 利用線下移動設備入侵
3.2.2 攻擊序列標簽生成
在對APT攻擊行為進行建模后,使用網絡行為數據標簽與主機行為數據標簽針對這3類攻擊的攻擊過程進行對應,形成APT攻擊的標簽序列可以通過變更標簽中的不同樣本,生成大量不同的APT攻擊樣本.表4~6分別為3種APT攻擊方式對應的攻擊標簽.
在生成APT攻擊數據時,由于真正的攻擊步驟在時間上不可能是完全連續的,各個步驟之間會有不可估計的時間間隔,因此需要在表4~6中的步驟之間穿插一系列的非攻擊操作.在實際生成APT攻擊數據集時,在表4~6中的各個步驟間,選擇在隨機位置插入隨機數量的標簽為normal的數據,表示網絡行為中的正常行為與主機行為中的正常行為.同時每個標簽都對應較多不同樣本,保證了APT攻擊數據集中數據的豐富性.

表4 釣魚攻擊流程的攻擊標簽

表5 利用Web漏洞與操作系統漏洞進行入侵的攻擊標簽

表6 利用線下移動設備入侵的攻擊標簽

圖3 1條APT攻擊數據構成
3.2.3 依據標簽生成APT攻擊數據
在生成的APT攻擊數據中每個步驟都會有主機行為和網絡行為與之對應,APT攻擊的每個時間步的數據由網絡行為與主機行為合并而成,表示當前步驟中的網絡狀態與主機狀態.特征處理方面,表示網絡狀態的特征為122維,即1個NSL-KDD數據標簽表示當前的網絡情況.主機行為特征由1個或多個當前步驟中的不同主機攻擊行為隨機組合而成.由于每種不同的主機攻擊行為在89維中都有自己固定的位置,因此組合后不會造成互相的覆蓋,而是會將各自的特征保留下來,沒有融合進來的其余位置都用0進行補齊,表示當前步驟中沒有類似的行為.因此1個或多個主機攻擊行為標簽最終會組合成89維的主機行為特征.1個步驟有網絡行為數據集的122維加上主機行為數據集的89維共211維特征.而1條APT攻擊數據就是由多個時間步的行為按照攻擊方式對應的標簽順序排列而成.
1條APT攻擊數據的生成過程如圖3所示,每條數據都由若干個時間步構成,表示每次攻擊中的攻擊步驟,而每個時間步有211維特征,由網絡側特征與主機側特征組合而成.利用線下移動設備入侵行為中的第7個攻擊步驟的1個時間步構成如圖4所示,其網絡行為數據標簽為rootkit,主機側特征由惡意行為特征集file_hide和process_inject中隨機選取1種組合而成.

圖4 1個時間步構成示例
3.3 非APT攻擊數據的生成
APT攻擊數據集在最終模型的數據集中使用標簽1進行對應,表示正樣本集,還需生成非APT攻擊數據作為負樣本集,用標簽0與之對應.網絡特征部分使用NSL-KDD中標簽normal的樣本,總共為122維特征.主機行為的正常行為樣本在創建時就沒有按攻擊行為進行拆分,整個89維的標簽normal的樣本就是當前時刻正常的主機行為,因此從中隨機選取進行利用即可.將主機行為數據和網絡行為數據進行組合形成211維的當前步驟下的單步非APT攻擊數據.
使用單步非APT攻擊數據生成1條完整的非APT攻擊數據的方式共有2種:第1種由標簽為normal的網絡單步數據與主機單步數據組成,這樣得到的數據為完全正常的行為序列;第2種是在APT攻擊的3種入侵方式中只生成某步驟之前的攻擊序列,代表攻擊的中止與失敗,該條數據也為非APT攻擊數據,為了與攻擊數據有一定的區分度,截取的步驟為整體步驟的前2/3處,不會從接近攻擊結束的地方進行截取.
3.4 基于LSTM的APT攻擊檢測模型構建
基于構建出的APT攻擊數據集與非APT攻擊數據集,使用LSTM進行訓練,訓練過程分為以下幾個步驟:數據集劃分與處理、模型初步訓練、調參優化.生成參數最優的APT攻擊檢測模型.整體流程如圖5所示:
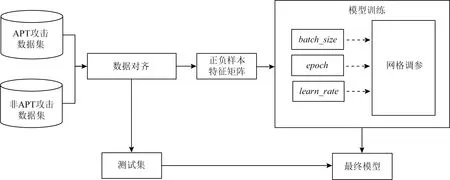
圖5 APT攻擊檢測模型訓練過程
1) 數據集劃分與處理.
首先對輸入模型的數據進行時序劃分處理,使用LSTM進行模型訓練時,3個較為關鍵的可以體現時序特征的參數為單個數據維度、時間步長度與最大數據長度.本文單個數據維度為122+89=211維,表示當前步驟的網絡狀態與主機狀態,最長數據由40個時間步構成,因此最大數據長度為40×211=8 440.為了輸入數據的長短一致,將所有數據的長度補齊至8 440.
本文共生成16 000條APT攻擊數據與16 000條非APT攻擊數據,將訓練集與測試集按照3∶1進行劃分,則訓練集共有12 000條正樣本數據與12 000條負樣本數據,測試集共有4 000條正樣本數據與4 000條負樣本數據.
2) 模型的調參優化.
針對LSTM的learn_rate,batch_size以及epoch這3個參數進行優化,比較取何值時模型的表現最好.batch_size是單批次訓練數據的大小,影響訓練時間與訓練速度.epoch為訓練的輪數,值越大訓練的時間就越長,隨著epoch的增大損失函數會逐漸收斂,此時模型趨于穩定,因此需要找到合適的epoch值.learn_rate是1個相對重要的超參數,其取值會影響模型最終的準確率.
3) 模型評價標準.
APT攻擊檢測是一個二分類問題,模型的預測出的結果只有1和0這2種取值.本文采用準確率、精確率、召回率和F1值這4個深度學習與機器學習中較為常用的指標衡量模型的優劣程度.
4 測試與結果分析
4.1 測試環境
4.1.1 LAnalysis實現環境
LAnalysis分為服務端與客戶端,都是基于Python3進行開發,同時還使用了shell腳本、SystemTap腳本進行相關功能的實現.服務端與客戶端采用虛擬機嵌套的方式運行,服務端使用主機系統中的VMware創建,客戶端使用服務端系統中的VirtualBox創建.具體環境參數如表7所示:
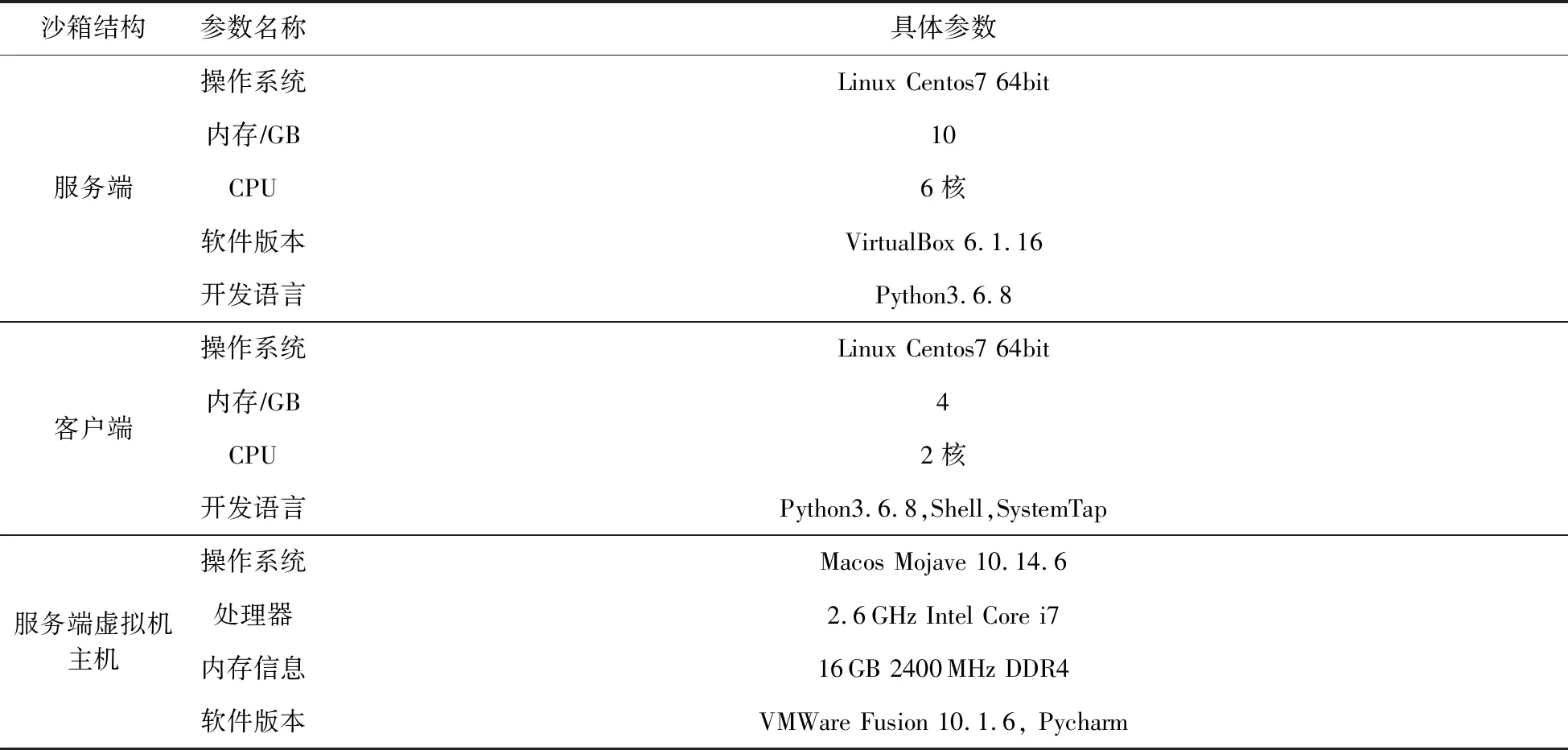
表7 LAnalysis環境參數
4.1.2 LSTM構建環境
LSTM的構建環境為Linux操作系統,主要使用Python進行開發.神經網絡模型開發框架使用開源的Keras框架.具體環境參數如表8所示.
4.2 LAnalysis行為檢測效果與分析
將本文自主構建的沙箱LAnalysis與開源沙箱Cuckoo、業內較常用的微步云沙箱和騰訊哈勃沙箱以及奇安信文件分析平臺進行對比,從Virustotal與VirusShare 2019—2020 ELF樣本集中隨機選取20個惡意樣本,對比統計分析出的惡意行為種類及個數.
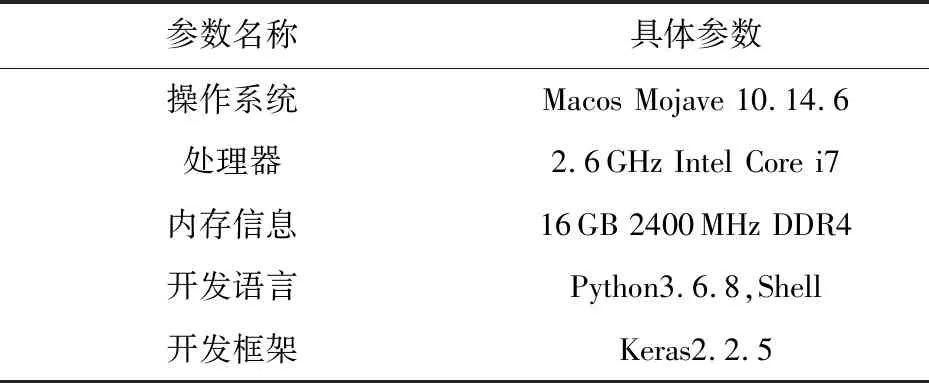
表8 LSTM環境參數
20個惡意樣本的用例編號如表9所示,根據惡意樣本用例編號可以直接在Virustotal和VirusShare中找到該惡意樣本,這是每個惡意樣本的唯一性標識.

表9 20個惡意樣本的用例編號
由于20個惡意樣本并不能完全覆蓋10類的16種惡意行為,因此將惡意行為概括為對抗行為、隱藏行為、持久化行為、窺探行為以及其他惡意行為5種.由于20個樣本一一列舉篇幅占用過多,因此只列出其中2個樣本的詳細對比結果與20個樣本的總體分析結果.
1) 0dbcc464a0dc0463bc9969f755e853d8.
該樣本為蓋茨家族的惡意樣本,各沙箱分析結果如表10所示.

表10 0dbcc464a0dc0463bc9969f755e853d8的沙箱分析結果對比
2) 0A9BBC90CAB339F37D5BDD0B906F1A9C.
該樣本為Skeeyah家族的惡意樣本,各沙箱分析結果如表11所示.

表11 0A9BBC90CAB339F37D5BDD0B906F1A9C的沙箱分析結果對比
3) 20個樣本.
各沙箱所檢測出來的20個惡意樣本的惡意行為總量如表12所示.
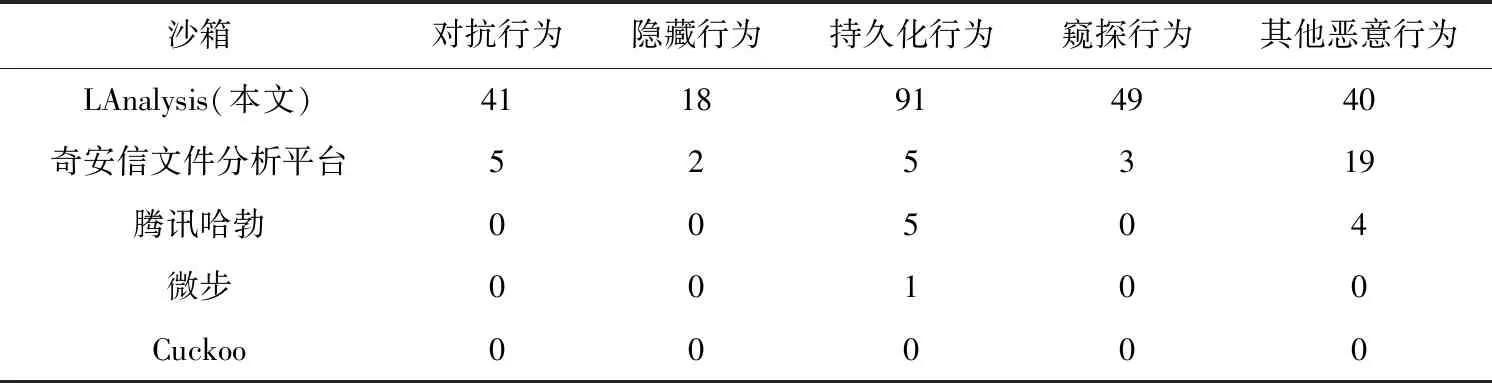
表12 20個惡意樣本的沙箱分析結果對比 項
由對比結果可知,雖然Cuckoo、騰訊哈勃、奇安信文件分析平臺以及微步在Windows文件分析上較為成熟,在業內也較為常用,但是對Linux ELF文件的分析能力十分薄弱.
以上結果證明了本文構建Linux ELF文件分析沙箱的合理性,同時也證明了LAnalysis在分析Linux ELF文件上的功能十分強大.LAnalysis較好地分析了眾多惡意家族的惡意樣本,因此基于LAnalysis構建的APT攻擊主機行為數據集較為全面,利用這些數據構成的APT攻擊樣本的合理性與豐富性也因此得到了保障.
4.3 模型檢測效果實驗及對比分析
4.3.1 LSTM模型訓練與優化
將3.4節所給出的訓練集與測試集的正樣本與負樣本形成2維數組輸入模型,標簽為x_train,y_train與x_test,y_test.
首先設置batch_size=32,learn_rate=0.000 1,epoch=10.將初始參數設定為較小的值可以提高調參優化的效率.此時的評價指標如表13所示:

表13 初始狀態的評價指標
1) 改變batch_size.
batch_size是訓練1次所使用數據量的大小,對訓練速度與時間具有較大影響,因此先對batch_size進行調整有利于為后續epoch和learn_rate的調整節省時間.batch_size受總內存值的影響,取值從32開始翻倍增長,當batch_size增大到256時程序會明顯變慢,出現卡頓,因此batch_size最合適的大小應設置為128.后續的調參過程中batch_size均設定為128,此時訓練速度是最快的.
2) 改變epoch.
epoch為訓練的輪數,初始狀態epoch=10,此時損失函數的變化曲線如圖6所示.通過圖6可知損失函數尚未收斂,說明模型仍在優化的過程中,因此應該增大epoch的值進行再次訓練.
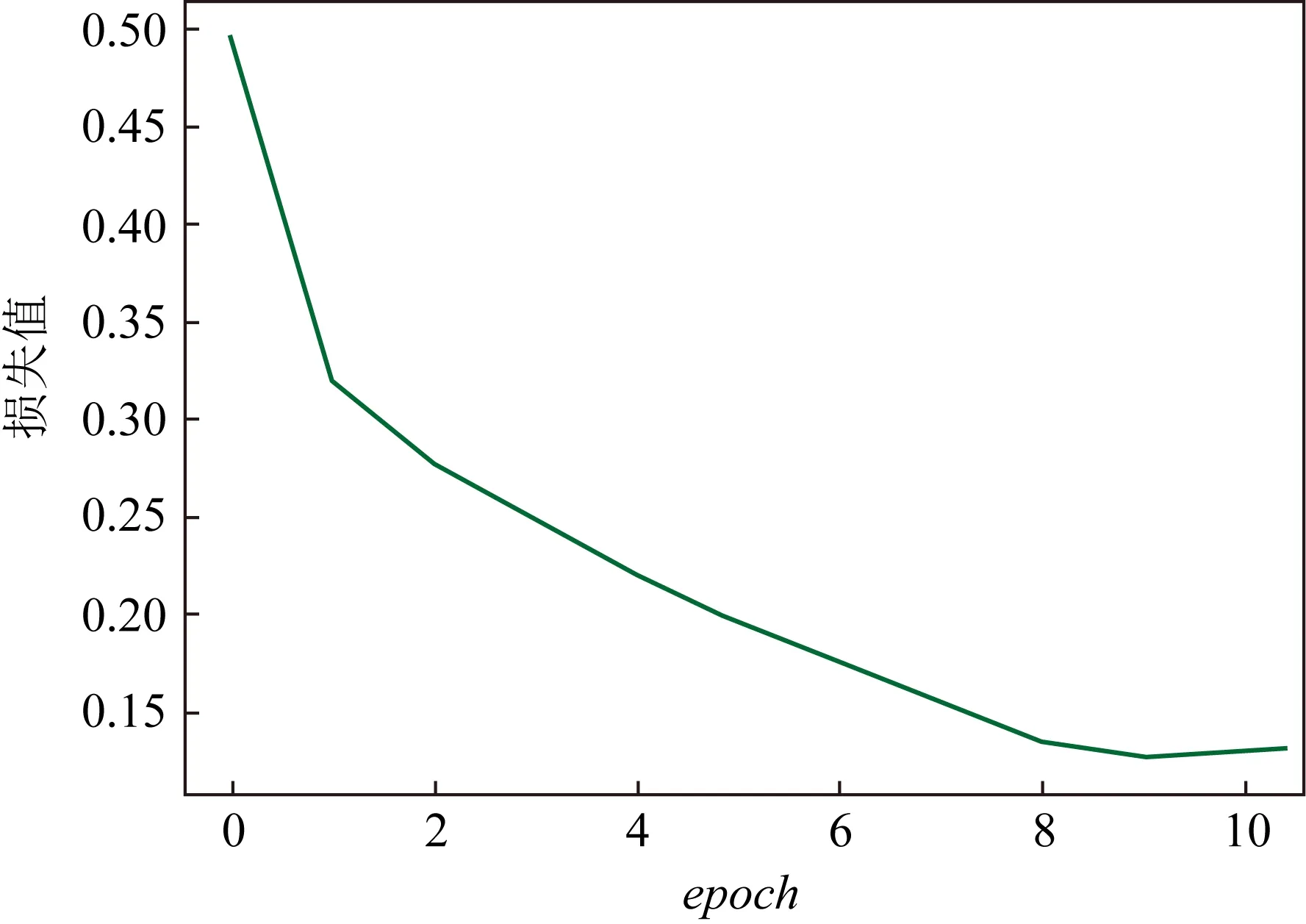
圖6 epoch=10時的損失函數曲線
當epoch=50時,損失函數變化曲線如圖7所示,此時可以看到模型隨著訓練輪數的增多逐漸收斂,當epoch=40時可以看到模型基本收斂,因此后續的調參過程將epoch設定為40.
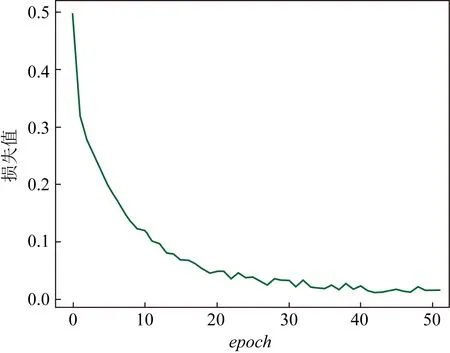
圖7 epoch=50時的損失函數曲線
3) 改變learn_rate.
通常learn_rate的取值范圍為[0.000 1,1],但是若直接取值,大概率會選擇到[0.1,1]的范圍內,此時learn_rate的值難以在較大范圍內變化.因此采用對數取值的方式,先選定4個區間,即[0.000 1,0.001],[0.001,0.01],[0.01,0.1],[0.1,1],在這4個區間內再進行平均取值.本文在batch_size=128,epoch=40的情況下不斷改變learn_rate進行訓練,不同learn_rate下的評價指標對比情況如表14所示.
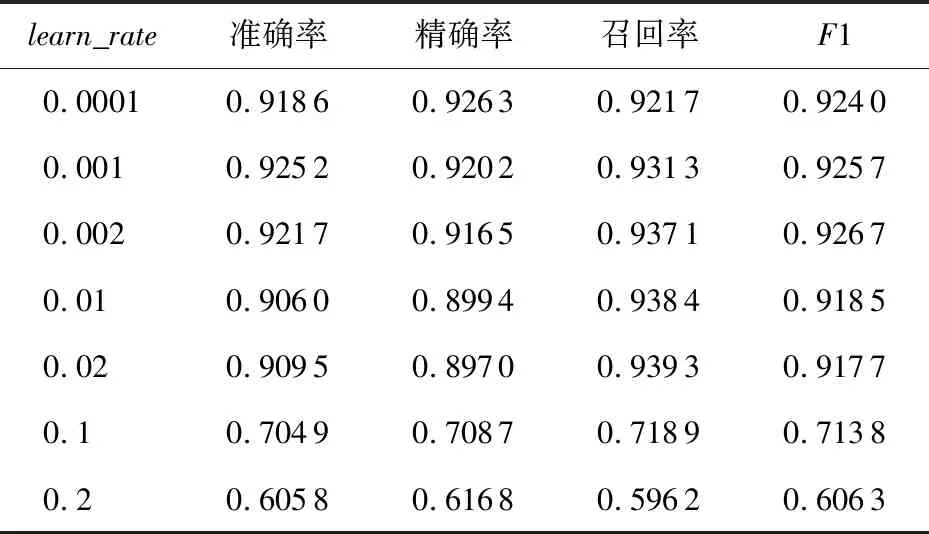
表14 不同learn_rate下的評價指標對比情況
由表14可知,learn_rate=0.002時模型的F1值是最好的,因此模型的最終指標于batch_size=128,epoch=40,learn_rate=0.002時取得,如表15所示.

表15 模型最終指標
4.3.2 不同檢測模型和方案的對比與分析
1) 不同時序處理模型的比較.
本文方案的模型準確率為92.17%,F1值為0.926 7.為確定最優的時序處理模型,訓練了RNN模型、GRU模型與LSTM模型進行對比,實驗結果如圖8所示.從圖8可以看出LSTM在處理APT攻擊時序數據時效果要好于RNN與GRU模型.
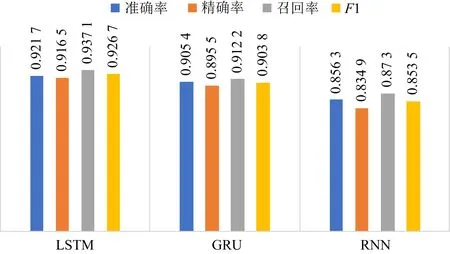
圖8 不同時序處理模型的比對情況
2) 不同APT攻擊檢測方案的比較與分析.
目前業內有眾多利用機器學習與深度學習進行APT攻擊檢測的方法.本文選擇了較有代表性的4種[9,14,22,26]與本文構建的模型從模型準確率、特征全面度以及APT攻擊建模等方面進行比較,結果如表16所示:
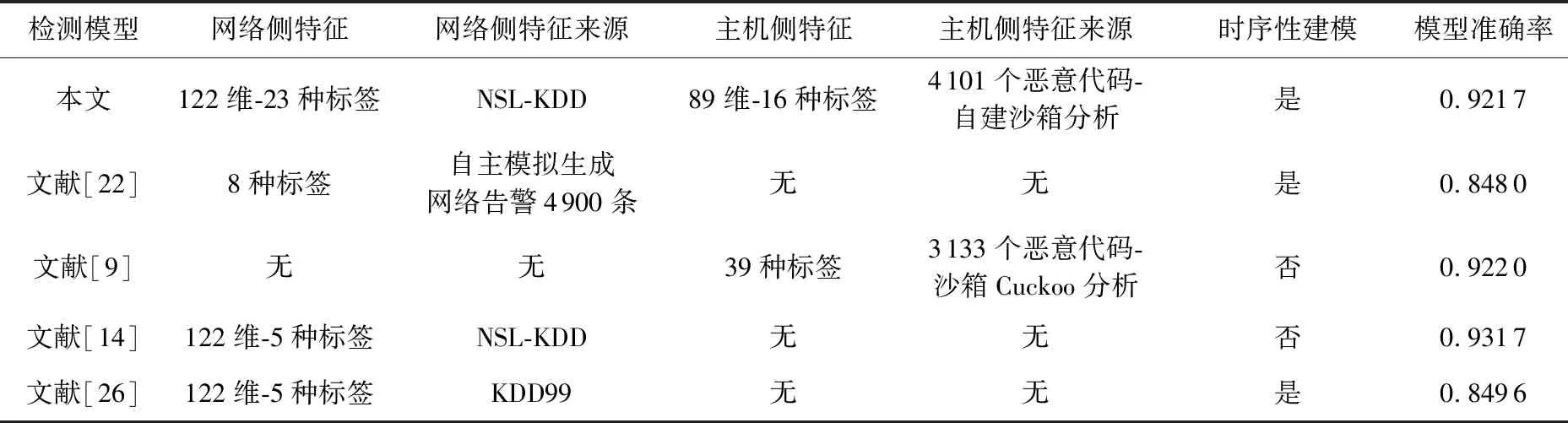
表16 APT攻擊檢測模型對比
由表16可知,對比的4種方法沒有完全兼顧網絡側特征、主機側特征以及APT攻擊的時序性建模這3個APT攻擊檢測的重要方面,模型都存在不足之處.
文獻[22]使用自主構建的網絡告警數據進行模型訓練,沒有在大量網絡數據集中進行驗證與復現,具有一定的片面性.此外,雖然其考慮到了APT攻擊中對子攻擊的時序性建模,但是沒有將主機側的行為數據放入模型,對APT攻擊的檢測具有片面性與不合理性.
文獻[9]使用沙箱Cuckoo對惡意代碼進行分析,由4.2節可知Cuckoo對惡意代碼的分析能力并不出色,因此基于Cuckoo進行惡意樣本分析以檢測APT攻擊具有很大的提升空間.另外文獻[9]并沒有考慮APT攻擊的時序性,仍局限于單種惡意代碼的檢測,并不能作為有效的APT攻擊檢測模型.
文獻[14]在數據處理時沒有使用NSL-KDD中的惡意行為細分標簽,而是將攻擊行為局限于大類,導致對攻擊的刻畫不夠具體.另外其沒有將APT攻擊與普通的入侵檢測進行區別,仍是針對單種攻擊進行檢測,沒有將APT攻擊的時序性特征考慮在內.雖然其準確率為93.7%,但卻不能視為較好的APT攻擊檢測效果.
文獻[26]在實驗中使用的數據集為KDD99,該數據集相較于NSL-KDD有明顯不足,存在大量冗余數據,目前已很少被業內使用.同時文獻[26]也沒有使用KDD99中更為細分的攻擊小類,而是使用大類進行檢測,對攻擊的刻畫不夠具體.另外,文獻[26]沒有使用任何主機數據構建APT攻擊數據集,僅用KDD99中包含的網絡側特征數據,而僅依據KDD99構建的APT攻擊數據集與APT攻擊檢測模型是不合理的.
5 總 結
針對業內檢測方案對APT攻擊中單個攻擊之間的時序性結合關注度不高、對于Linux系統中的惡意代碼攻擊檢測工具較少、APT攻擊周期過長導致APT攻擊研究樣本較少等問題,本文提出一種基于LSTM的Linux系統下APT攻擊檢測方案,并與其他方案進行了對比.實驗證明,本文方案能夠較好地對APT攻擊進行檢測,并且能夠構建一套兼具主機行為和網絡行為特征的APT攻擊數據集,較好解決了當前業內缺乏高質量的APT攻擊數據集的問題,為后續研究工作打下了良好的基礎.
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
民用飛機設計與研究(2020年4期)2021-01-21 09:15:02
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
電子制作(2018年18期)2018-11-14 01:48:24
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
山東工業技術(2016年15期)2016-12-01 05:31:22
海峽科技與產業(2016年3期)2016-05-17 04:32:12
