一種基于用戶關(guān)系和用戶偏好的下一個(gè)興趣點(diǎn)推薦方法
2022-08-05 02:01:20方金鳳,孟祥福,2
地理與地理信息科學(xué) 2022年4期
方 金 鳳,孟 祥 福,2
(1.遼寧工程技術(shù)大學(xué)測繪與地理科學(xué)學(xué)院,遼寧 阜新 123000;2.遼寧工程技術(shù)大學(xué)電子與信息工程學(xué)院,遼寧 葫蘆島 125105)
0 引言
隨著無線通信設(shè)備的快速普及以及GPS定位技術(shù)的快速發(fā)展,海量基于位置服務(wù)數(shù)據(jù)能真實(shí)反映用戶的行為規(guī)律,使得對用戶行為模式的探索成為可能[1-4]。下一個(gè)興趣點(diǎn)推薦作為基于位置服務(wù)數(shù)據(jù)最典型的應(yīng)用之一,旨在根據(jù)用戶行為習(xí)慣準(zhǔn)確推測出用戶下一時(shí)刻將要訪問的興趣點(diǎn),為用戶的決策行為提供幫助,為商家的營銷活動(dòng)提供參考,因此,研究下一個(gè)興趣點(diǎn)推薦方法具有重要的現(xiàn)實(shí)意義和應(yīng)用價(jià)值。
與一般興趣點(diǎn)推薦不同,用戶的序列訪問行為對其要訪問的下一個(gè)興趣點(diǎn)具有重要影響,推薦列表會(huì)隨簽到信息時(shí)刻變化,且用戶的每次移動(dòng)均會(huì)導(dǎo)致推薦列表明顯變化,因此,下一個(gè)興趣點(diǎn)推薦本質(zhì)上是行為序列數(shù)據(jù)分析與推薦[5,6]。馬爾科夫鏈?zhǔn)墙鉀Q序列分析問題的有效手段,學(xué)者們最初常基于馬爾科夫鏈進(jìn)行用戶的下一個(gè)行為推薦[7-9],但隨著馬爾科夫階數(shù)(記憶步長)的增加,計(jì)算量會(huì)以指數(shù)形式增長,限制了該方法的應(yīng)用。詞嵌入模型可將詞的特征映射到低維空間中,從而縮短計(jì)算維度,有學(xué)者據(jù)此提出基于嵌入的下一個(gè)興趣點(diǎn)推薦方法[10,11],通過將興趣點(diǎn)嵌入低維空間中可捕獲興趣點(diǎn)間的相關(guān)性并減少計(jì)算量,但該方法無法有效獲取興趣點(diǎn)間的序列影響。為此,在采用嵌入方式進(jìn)行下一個(gè)興趣點(diǎn)推薦時(shí),通常結(jié)合其他能夠捕獲興趣點(diǎn)序列關(guān)系的方法,如Venue2Vec[12]基于用戶對興趣點(diǎn)的序列簽到信息與興趣點(diǎn)之間的距離構(gòu)建興趣點(diǎn)轉(zhuǎn)移圖,然后將興趣點(diǎn)的序列信息輸入詞嵌入模型中學(xué)習(xí),進(jìn)而獲得興趣點(diǎn)的向量表示。循環(huán)神經(jīng)網(wǎng)絡(luò)(Recurrent Neural Network,RNN)能在序列數(shù)據(jù)中自動(dòng)挖掘上下文信息之間的交互影響,在下一個(gè)興趣點(diǎn)推薦中也得到廣泛應(yīng)用,并成為當(dāng)前主流的推薦模型[13-15],但RNN模型在長序列建模中存在梯度爆炸和梯度消失問題,為此,提出長短時(shí)記憶(Long Short-Term Memory,LSTM)[16,17]和門控循環(huán)單元(Gated Recurrent Unit,GRU)[18,19]兩種RNN變體,形成了基于LSTM和GRU網(wǎng)絡(luò)的下一個(gè)興趣點(diǎn)推薦算法。
綜上,下一個(gè)興趣點(diǎn)推薦方法已取得一定進(jìn)展,且多依據(jù)用戶偏好進(jìn)行推薦。研究表明,具有相似偏好的用戶往往具有相似的行為[20],可通過與某用戶具有相似偏好的用戶間接預(yù)測該用戶的行為,此外,朋友間的信息分享會(huì)影響用戶的決策[20-23],因此,對用戶關(guān)系(包括用戶偏好相似關(guān)系和用戶朋友關(guān)系)的挖掘和分析在下一個(gè)興趣點(diǎn)推薦中至關(guān)重要。K近鄰最初用于解決分類問題,后逐漸應(yīng)用于各類預(yù)測問題,在基于位置的服務(wù)、空間分析等領(lǐng)域應(yīng)用廣泛[24]。鑒于此,本文應(yīng)用K近鄰算法,基于用戶關(guān)系和歷史簽到記錄,由當(dāng)前序列的近鄰序列挖掘當(dāng)前序列的隱含信息,共同實(shí)現(xiàn)對用戶下一個(gè)興趣點(diǎn)的推薦。通過在真實(shí)數(shù)據(jù)集上展開實(shí)驗(yàn),對本文方法進(jìn)行效果與性能實(shí)驗(yàn)評價(jià),以驗(yàn)證方法的有效性和優(yōu)越性。
1 下一個(gè)興趣點(diǎn)推薦方法
本文下一個(gè)興趣點(diǎn)推薦方法(Relationships and Preferences-Gated Recurrent Unit,RP-GRU)的具體實(shí)現(xiàn)流程如圖1所示。首先,對用戶的訪問記錄進(jìn)行分段處理,由此獲取不同時(shí)段的用戶偏好;其次,將用戶關(guān)系引入下一個(gè)興趣點(diǎn)推薦中,通過構(gòu)建的用戶關(guān)系圖獲取用戶關(guān)系向量,并將用戶關(guān)系向量同當(dāng)前偏好向量與周期偏好向量進(jìn)行拼接,由此得到用戶向量,將用戶向量與興趣點(diǎn)向量相乘可獲得興趣點(diǎn)的近期得分;然后,采用用戶長期訪問序列的K近鄰序列獲取用戶的長期偏好,計(jì)算出興趣點(diǎn)的長期得分;最后,將興趣點(diǎn)的近期得分與長期得分相加得到興趣點(diǎn)的總得分,據(jù)此進(jìn)行下一個(gè)興趣點(diǎn)推薦。
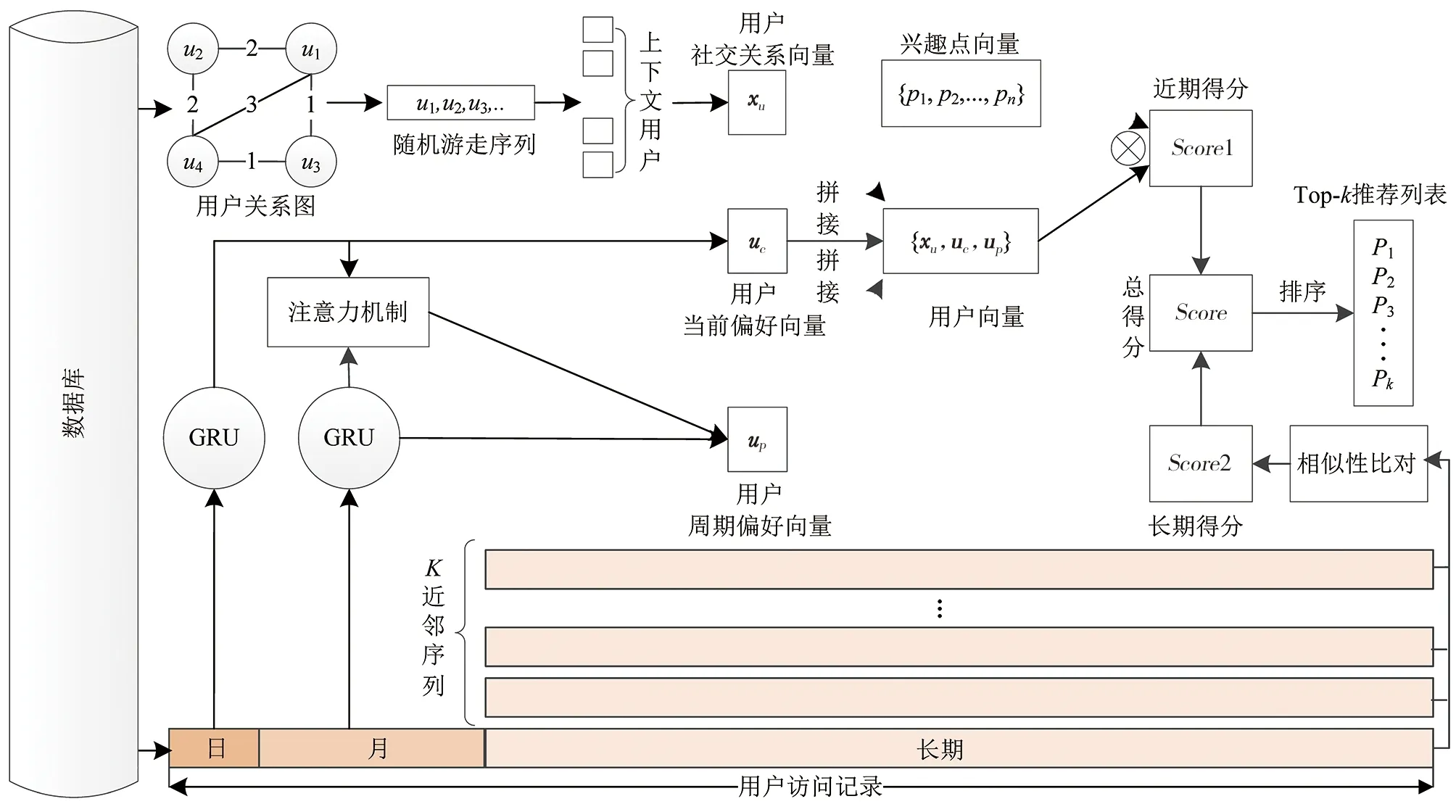
圖1 下一個(gè)興趣點(diǎn)推薦的解決方案Fig.1 Solutions for next POI recommendation
1.1 用戶關(guān)系向量
1.1.1 用戶關(guān)系圖構(gòu)建
(1)用戶關(guān)系圖由節(jié)點(diǎn)(代表用戶)、邊(代表用戶關(guān)系)和權(quán)重(代表用戶關(guān)系的緊密度)組成。用戶關(guān)系包括朋友關(guān)系和偏好相似關(guān)系,兩個(gè)用戶訪問的共同興趣點(diǎn)越多,說明其偏好越相似,如果兩個(gè)用戶存在朋友關(guān)系或兩者訪問過同一興趣點(diǎn),則兩者之間邊的權(quán)重加1。以4個(gè)用戶對3個(gè)興趣點(diǎn)的訪問情況及用戶之間的朋友關(guān)系為例(表1),可構(gòu)建出用戶關(guān)系圖(詳見圖1)。

表1 用戶對興趣點(diǎn)的訪問記錄及其朋友關(guān)系Table 1 Users′ check-in records for POIs and friend relationships
(2)重啟隨機(jī)游走算法通過迭代方式探索網(wǎng)絡(luò)圖的整體結(jié)構(gòu)以捕捉兩個(gè)節(jié)點(diǎn)之間的關(guān)系,進(jìn)而得到節(jié)點(diǎn)間的接近度[25]。本文根據(jù)用戶關(guān)系構(gòu)建用戶關(guān)系圖,將計(jì)算兩個(gè)用戶之間的相似性問題轉(zhuǎn)化為計(jì)算用戶關(guān)系圖中兩個(gè)節(jié)點(diǎn)之間的接近度問題,進(jìn)而通過重啟隨機(jī)游走算法評估兩個(gè)用戶之間的相關(guān)性。用戶關(guān)系圖中兩節(jié)點(diǎn)之間連線的權(quán)重代表從一個(gè)用戶到另一個(gè)用戶的轉(zhuǎn)移強(qiáng)度,如與u2相連邊的權(quán)重總和為4,u2與u4相連邊的權(quán)重為2,則從u2到u4的轉(zhuǎn)移概率為2/4(從u4到u2的轉(zhuǎn)移概率為2/6)。由此,用戶ui到uj隨機(jī)游走的概率可由式(1)計(jì)算。從用戶關(guān)系圖中的一個(gè)節(jié)點(diǎn)出發(fā),選取模型訓(xùn)練表現(xiàn)最優(yōu)對應(yīng)的步長和次數(shù)進(jìn)行隨機(jī)游走,并對圖中所有節(jié)點(diǎn)重復(fù)此操作即可獲得模型訓(xùn)練的序列輸入數(shù)據(jù)。本文中步長為20,次數(shù)為50次。由于不同數(shù)據(jù)集下參數(shù)的取值各異,對于較大的數(shù)據(jù)集需適量增加步長和隨機(jī)游走次數(shù)以提升模型性能,使得依賴短隨機(jī)游走得到的信息能夠在不需全局重新計(jì)算的情況下適應(yīng)網(wǎng)絡(luò)出現(xiàn)的小變化。
(1)
式中:f(ui,uj)為以ui和uj為頂點(diǎn)的邊的權(quán)重,f(ui,uj)與f(uj,ui)不一定相同;F(ui)為用戶關(guān)系圖中與ui有邊相連的節(jié)點(diǎn)集合。
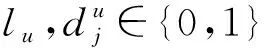
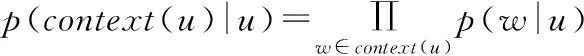
(2)
(3)
(4)
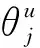
(5)
式中:η為學(xué)習(xí)率,根據(jù)文獻(xiàn)[26]取值為0.025。
1.2 周期偏好與當(dāng)前偏好
按照用戶對興趣點(diǎn)的簽到時(shí)間將用戶偏好劃分為長期偏好(用戶所有簽到記錄)、周期偏好(包括當(dāng)前偏好和月偏好)和當(dāng)前偏好。
1.2.1 當(dāng)前偏好與月偏好 當(dāng)前偏好指用戶最后一次簽到1天之內(nèi)的簽到記錄(日偏好),月偏好指與用戶最后一次簽到相距1個(gè)月內(nèi)的簽到記錄,兩者均用GRU模型建模,以簽到興趣點(diǎn)和簽到時(shí)間為輸入,區(qū)別在于輸入數(shù)據(jù)的時(shí)間間隔不同。簽到時(shí)間包括簽到星期和簽到時(shí)刻,分別用獨(dú)熱編碼(one-hot encoding)表示,簽到星期分為7 d,如周一表示為[1,0,0,0,0,0,0],簽到時(shí)刻分為24 h,如0點(diǎn)表示為[1,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0]。模型在t時(shí)刻的輸入St由當(dāng)前時(shí)刻簽到興趣點(diǎn)向量pt、簽到星期向量Weekt與簽到時(shí)刻向量Hourt組成,記做St=[pt:Weekt:Hourt]。通過GRU模型對月偏好和當(dāng)前偏好建模(圖2),其計(jì)算方法為:
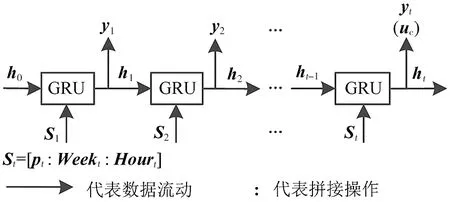
圖2 當(dāng)前偏好建模Fig.2 Current preference modeling
ht=f(St,Wht-1,b)
(6)
uc=σ(Wo·ht+bo)
(7)
式中:ht為GRU模型的輸出;uc為當(dāng)前偏好向量;ht-1為GRU模型上一時(shí)刻的輸出;W、Wo和b、bo分別為神經(jīng)網(wǎng)絡(luò)的權(quán)重和偏置。
1.2.2 周期偏好 受DeepMove模型[18]的啟發(fā),用戶的周期偏好對其訪問下一個(gè)興趣點(diǎn)存在一定影響。DeepMove模型以日為單位對用戶的簽到記錄進(jìn)行劃分,以用戶每日簽到興趣點(diǎn)向量的平均值表示用戶當(dāng)日的信息。本文利用分層注意力機(jī)制通過用戶的月偏好和當(dāng)前偏好得到用戶的周期偏好(式(8)-式(10))。通過用戶的當(dāng)前偏好uc與向量ot得到月偏好模型每一時(shí)刻對用戶周期偏好貢獻(xiàn)的注意力權(quán)重αt,將ht與其對應(yīng)注意力權(quán)重αt相乘作為月偏好每一時(shí)刻對用戶周期偏好的貢獻(xiàn),月偏好所有時(shí)刻的貢獻(xiàn)之和up即為用戶的周期偏好(圖3)。
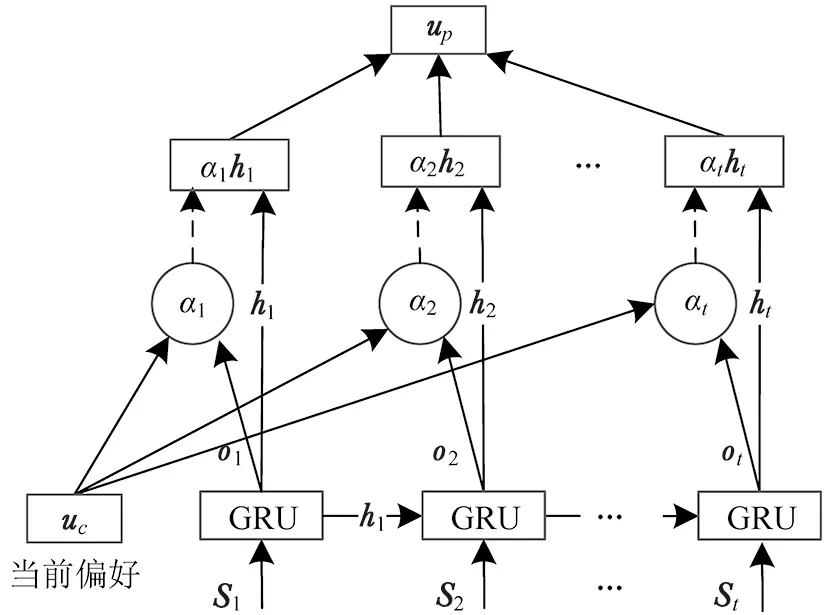
圖3 周期偏好建模Fig.3 Periodic preference modeling
ot=tanh(Wht+bw)
(8)
(9)
(10)
式中:ht為月偏好模型每一時(shí)刻的輸出;W和bw分別為神經(jīng)網(wǎng)絡(luò)的權(quán)重和偏置;ot為ht經(jīng)過一層全連接神經(jīng)網(wǎng)絡(luò)后的向量;uc為周期偏好的輸入,文獻(xiàn)[27]中uc向量被隨機(jī)初始化,然而本文以當(dāng)前偏好模型在最后一個(gè)時(shí)刻得到的輸出向量作為uc。
1.3 興趣點(diǎn)近期得分
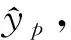
wi=eiW
(11)
式中:ei為嵌入之前的向量;wi為嵌入之后的向量;W∈Rm×d為模型需要訓(xùn)練的權(quán)重矩陣。
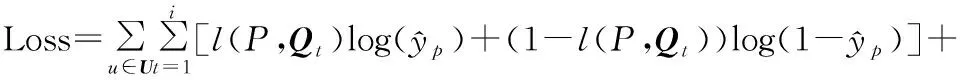
(12)
式中:l(P,Qt)用于判斷在輸入序列為Qt的條件下模型能否正確預(yù)測興趣點(diǎn)P,能正確預(yù)測,l(P,Qt)=1,否則l(P,Qt)=0;θ為模型所有可訓(xùn)練的參數(shù);λ為正則化系數(shù)。
1.4 興趣點(diǎn)長期得分
現(xiàn)有下一個(gè)興趣點(diǎn)推薦算法通常只利用用戶自身的偏好信息進(jìn)行推薦,忽略了相鄰序列(指與該用戶的歷史簽到序列相似的序列)中的潛在協(xié)作信息(即兩序列之間的共性),相鄰序列存在類似的行為模式,反映與當(dāng)前序列相似的用戶意圖。例如,當(dāng)前用戶的歷史訪問序列為[公園1,公園2,博物館1,公園3],序列1為[公園1,公園2,博物館2,公園3,賓館],序列2為[動(dòng)物園1,公園2,動(dòng)物園2,公園3,飯店],相比序列2,序列1與當(dāng)前用戶的歷史訪問序列更接近,由此可以推斷當(dāng)前用戶的意圖與序列1較相似,該用戶離開公園3后,要訪問的興趣點(diǎn)大概率是序列1中的賓館,而非序列2中的飯店。
采用K近鄰序列對用戶長期偏好進(jìn)行挖掘,主要通過當(dāng)前用戶歷史訪問序列的相似序列探索該用戶可能訪問的下一個(gè)興趣點(diǎn)。序列之間的相似性由兩個(gè)序列共同訪問過興趣點(diǎn)的數(shù)量與兩個(gè)序列分別訪問過興趣點(diǎn)的總數(shù)量的比值表示。首先,通過式(13)計(jì)算當(dāng)前序列s與數(shù)據(jù)集中其他序列n之間的相似性,根據(jù)相似性結(jié)果在數(shù)據(jù)集中找出與當(dāng)前序列最相似的K個(gè)序列,構(gòu)成當(dāng)前序列的K近鄰序列集合Ns;然后,通過每個(gè)興趣點(diǎn)在K個(gè)近鄰序列中的存在情況為興趣點(diǎn)賦分值,作為興趣點(diǎn)的長期得分Score2(i)(式(14)),由此可得興趣點(diǎn)的總分值Score(i)=Score1(i)+Score2(i);最后,對Score(i)進(jìn)行排序,將分值較大的前K個(gè)興趣點(diǎn)推薦給用戶。
sim(s,n)=|s∩n|/|s∪n|
(13)
(14)
式中:ln(i)為檢驗(yàn)興趣點(diǎn)i是否存在于當(dāng)前序列的K近鄰序列中的標(biāo)記,如果序列n包含興趣點(diǎn)i,則ln(i)=1,否則ln(i)=0。
2 實(shí)驗(yàn)結(jié)果與分析
2.1 實(shí)驗(yàn)設(shè)置
選取真實(shí)的CA數(shù)據(jù)集和Gowalla數(shù)據(jù)集進(jìn)行算法驗(yàn)證:CA數(shù)據(jù)集采用Fousquare點(diǎn)評網(wǎng)站(https://foursquare.com/about)上2010年1月至2011年8月4 163名加利福尼亞用戶的483 813條簽到信息,興趣點(diǎn)的緯度范圍為[-33.94°,52.31°],經(jīng)度范圍為[-159.35°,151.17°];Gowalla數(shù)據(jù)集是興趣點(diǎn)推薦廣泛使用的公開數(shù)據(jù)集(http://snap.stanford.edu/data/loc-gowalla.html),包括2009年2月至2010年10月196 591名用戶的6 442 890條簽到信息,興趣點(diǎn)的緯度范圍為[32.65°,40.59°],經(jīng)度范圍為[-122.87°,-114.04°]。為緩解數(shù)據(jù)的稀疏性,移除簽到次數(shù)少于10的用戶和興趣點(diǎn)。用戶簽到數(shù)據(jù)集的格式如表2所示,選擇用戶歷史簽到數(shù)據(jù)集的最后一次簽到記錄作為測試集,其余為訓(xùn)練集。
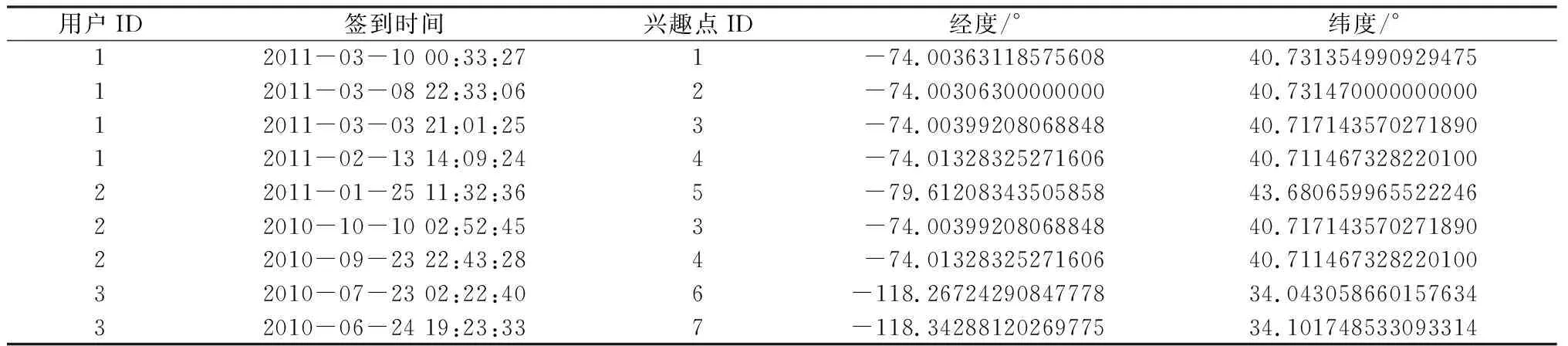
表2 實(shí)驗(yàn)數(shù)據(jù)集格式Table 2 Format of experimental datasets
選擇常用的Accuracy@k(ACC@k(式(15)))和MRR@k(式(16))作為實(shí)驗(yàn)評價(jià)指標(biāo):ACC@k可衡量推薦列表中興趣點(diǎn)的準(zhǔn)確程度,如果用戶訪問的下一個(gè)興趣點(diǎn)真實(shí)出現(xiàn)在推薦列表中,則認(rèn)為預(yù)測正確,其值為1,否則為0,ACC@k取所有測試實(shí)例的平均值,值越高表示模型的推薦效果越好;MRR@k可衡量推薦列表中興趣點(diǎn)的排名,用戶訪問下一個(gè)興趣點(diǎn)在推薦列表的位置越靠前,則MRR@k的得分越高。
(15)
(16)
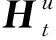
2.2 實(shí)驗(yàn)結(jié)果
為驗(yàn)證本文模型引入用戶關(guān)系的有效性,分別在CA和Gowalla數(shù)據(jù)集上將未引入用戶關(guān)系和引入用戶關(guān)系后得到的推薦結(jié)果進(jìn)行對比,結(jié)果如表3所示。由表3可以看出,引入用戶關(guān)系的算法要顯著優(yōu)于未引入用戶關(guān)系的算法,這是因?yàn)榕笥阎g會(huì)分享相關(guān)信息,也會(huì)結(jié)伴訪問相同的興趣點(diǎn);同時(shí),歷史訪問行為相似的用戶很可能未來也會(huì)訪問相似的興趣點(diǎn)。以ACC@10評價(jià)指標(biāo)為例,引入用戶關(guān)系的算法在CA和Gowalla數(shù)據(jù)集上分別比未引入用戶關(guān)系的算法準(zhǔn)確度提升了25.17%和18.13%,說明用戶關(guān)系對預(yù)測用戶的決策行為至關(guān)重要,引入用戶關(guān)系的算法可顯著提升推薦結(jié)果的準(zhǔn)確性。

表3 用戶關(guān)系對推薦性能的影響Table 3 Impact of user relationship on recommendation performance
為驗(yàn)證本文采用K近鄰方法分析用戶長期序列偏好的有效性,分別在CA和Gowalla數(shù)據(jù)集上將未采用K近鄰方法和采用K近鄰方法得到的推薦結(jié)果進(jìn)行對比,通過測試K不同取值的實(shí)驗(yàn)得出,在CA和Gowalla數(shù)據(jù)集上K分別取100和300。由表4可知,無論是推薦準(zhǔn)確性指標(biāo)ACC@k還是索引值指標(biāo)MRR@10,采用K近鄰序列挖掘用戶的長期興趣點(diǎn)偏好均優(yōu)于未采用K近鄰算法,表明K近鄰序列對挖掘當(dāng)前序列的隱含信息具有積極作用,由此可以證明本文添加K近鄰序列的有效性,但添加K近鄰長期序列分析法對實(shí)驗(yàn)結(jié)果的提升不明顯。以ACC@10指標(biāo)為例,采用K近鄰算法后的模型比未采用K近鄰的模型在CA和Gowalla兩數(shù)據(jù)集上分別高出4.20%和1.27%,這是因?yàn)橛脩舻南乱粋€(gè)行為主要受當(dāng)前偏好和周期偏好的影響較大,長期偏好對用戶決策的影響力較小。

表4 K近鄰序列對推薦性能的影響Table 4 Impact of K-nearest neighbor sequences on recommendation performance
為進(jìn)一步驗(yàn)證本文算法的有效性,分別與5種經(jīng)典的下一個(gè)興趣點(diǎn)推薦算法進(jìn)行對比,結(jié)果如表5所示。1)FPMC-LR[9]:基于馬爾科夫鏈并結(jié)合矩陣分解對序列建模獲取用戶偏好,進(jìn)而實(shí)現(xiàn)下一個(gè)興趣點(diǎn)的推薦;2)PRME-G[10]:采用個(gè)性化度量嵌入的方法進(jìn)行下一個(gè)興趣點(diǎn)推薦,將空間距離作為權(quán)重控制用戶的距離偏好,同時(shí)整合用戶偏好信息、序列信息和地理位置信息;3)POI2Vec[11]:典型的基于嵌入模型的方法,將Word2Vec應(yīng)用于興趣點(diǎn)預(yù)測,將每個(gè)興趣點(diǎn)看作Word2Vec中的一個(gè)word,實(shí)現(xiàn)下一個(gè)興趣點(diǎn)的預(yù)測;4)Distance2Pre[19]:利用GRU模型獲取用戶簽到歷史序列信息和距離偏好進(jìn)行推薦,提出線性和非線性兩種整合模型,本文使用效果更好的非線性模型進(jìn)行對比;5)CSRM[15]:一種新穎的興趣點(diǎn)推薦方法,不僅對用戶的簽到信息進(jìn)行建模,還考慮相似用戶的會(huì)話簽到信息。

表5 不同算法推薦性能對比Table 5 Comparison of different algorithms in recommendation performance
由表5可知,基于GRU對用戶歷史簽到數(shù)據(jù)建模的Distance2Pre和RP-GRU模型顯著優(yōu)于只基于當(dāng)前興趣點(diǎn)進(jìn)行推薦的FPMC-LR和PRME-G模型,從側(cè)面說明GRU模型對于序列建模的有效性,同時(shí)也反映出當(dāng)前簽到興趣點(diǎn)序列較短,無法有效預(yù)測用戶偏好信息,應(yīng)考慮更長期的序列信息,以免誤解用戶的訪問意圖。整體看,與5種對比算法相比,兼顧用戶關(guān)系以及用戶不同階段偏好的RP-GRU模型在兩數(shù)據(jù)集上的效果均最好,證明該方法有效。
3 結(jié)論
本文對用戶的訪問記錄進(jìn)行分段處理,根據(jù)簽到時(shí)間劃分為長期偏好、周期偏好和當(dāng)前偏好,通過GRU模型對用戶的周期偏好和當(dāng)前偏好建模,采用用戶歷史簽到序列的K近鄰序列挖掘用戶的長期偏好,同時(shí)引入用戶關(guān)系,為下一個(gè)興趣點(diǎn)推薦提供了新的解決方案,并通過在真實(shí)數(shù)據(jù)集上進(jìn)行實(shí)驗(yàn)以及與現(xiàn)階段主流的下一個(gè)興趣點(diǎn)推薦方法進(jìn)行對比,驗(yàn)證了本文方法的有效性。
下一個(gè)興趣點(diǎn)推薦是基于位置服務(wù)的典型應(yīng)用,具有重要的研究價(jià)值和良好的發(fā)展前景,未來將從以下兩方面進(jìn)行研究:1)K近鄰算法中K值的確定,雖然本文方法可應(yīng)用于不同數(shù)據(jù)集中,但K近鄰的取值需依據(jù)不同數(shù)據(jù)集而定,下一步將考慮在更多的數(shù)據(jù)集上進(jìn)行實(shí)驗(yàn),尋找K近鄰取值與數(shù)據(jù)集之間的關(guān)聯(lián)性,爭取自適應(yīng)確定K近鄰數(shù)量;2)用戶關(guān)系的界定,需重點(diǎn)探索朋友關(guān)系和偏好相似關(guān)系建模的側(cè)重點(diǎn)。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(bào)(2020年2期)2020-06-02 11:29:24
中華手工(2017年2期)2017-06-06 23:00:31
商用汽車(2016年11期)2016-12-19 01:20:16
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
創(chuàng)業(yè)家(2015年5期)2015-02-27 07:53:25
中外會(huì)展(2014年4期)2014-11-27 07:46:46
