基于i 向量和變分自編碼相對生成對抗網絡的語音轉換
2022-08-01 01:42:54李燕萍左宇濤
自動化學報 2022年7期
李燕萍 曹 盼 左宇濤 張 燕 錢 博
語音轉換是在保持語音內容不變的同時,改變一個人的聲音,使之聽起來像另一個人的聲音[1?2].根據訓練過程對語料的要求,分為平行文本條件下的語音轉換和非平行文本條件下的語音轉換.在實際應用中,預先采集大量平行訓練文本不僅耗時耗力,而且在跨語種轉換和醫療輔助系統中往往無法采集到平行文本,因此非平行文本條件下的語音轉換研究具有更大的應用背景和現實意義.
性能良好的語音轉換系統,既要保持重構語音的自然度,又要兼顧轉換語音的說話人個性信息是否準確.近年來,為了改善轉換后合成語音的自然度和說話人個性相似度,非平行文本條件下的語音轉換研究取得了很大進展,根據其研究思路的不同,大致可以分為3 類,第1 類思想是從語音重組的角度,在一定條件下將非平行文本轉化為平行文本進行處理[3?4],其代表算法包括兩種,一種是使用獨立于說話人的自動語音識別系統標記音素,另一種是借助文語轉換系統將小型語音單元拼接成平行語音.該類方法原理簡單,易于實現,然而這些方法很大程度上依賴于自動語音識別或文語轉換系統的性能;第2 類是從統計學角度,利用背景說話人的信息作為先驗知識,應用模型自適應技術,對已有的平行轉換模型進行更新,包括說話人自適應[5?6]和說話人歸一化等.但這類方法通常要求背景說話人的訓練數據是平行文本,因此并不能完全解除對平行訓練數據的依賴,還增加了系統的復雜性;前兩類通常只能為每個源?目標說話人對構建一個映射函數,即一對一轉換,當存在多個說話人對時,就需要構建多個映射函數,增加系統的復雜性和運算量;第3 類是解卷語義和說話人個性信息的思想,轉換過程可以理解為源說話人語義信息和目標說話人個性信息的重構,其代表算法包括基于條件變分自編碼器 (Conditional variational auto-Encoder,CVAE)[7]方法、基于變分自編碼生成對抗網絡(Variational autoencoding wasserstein generative adversarial network,VAWGAN)[8]方法和基于星型生成對抗網絡 (Star generative adversarial network,StarGAN)[9]方法.這類方法直接規避了非平行文本對齊的問題,實現將多個源?目標說話人對的轉換整合在一個轉換模型中,提供了多說話人向多說話人轉換的新框架,即多對多轉換,成為目前非平行文本條件下語音轉換的主流方法.
基于C-VAE 模型的語音轉換方法,其中的編碼器對語音實現語義和個性信息的解卷,解碼器通過語義和說話人身份標簽完成語音的重構,從而解除對平行文本的依賴,實現多說話人對多說話人的轉換.但是由于C-VAE 基于理想假設,認為觀察到的數據通常遵循高斯分布,導致解碼器的輸出語音過度平滑,轉換后的語音質量不高.基于循環一致生成對抗網絡的語音轉換方法[10]可以在一定程度上解決過平滑問題,但是該方法只能實現一對一的語音轉換.
Hsu 等[8]提出的VAWGAN 模型通過在CVAE 中引入Wasserstein 生成對抗網絡(Wasserstein generative adversarial network,WGAN)[11],將 VAE 的解碼器指定為WGAN 的生成器來優化目標函數,一定程度上提升轉換語音的質量,然而Wasserstein 生成對抗網絡仍存在一些不足之處,例如性能不穩定,收斂速度較慢等.同時,VAWGAN使用說話人身份標簽one-hot 向量建立語音轉換系統,而該指示標簽無法攜帶更為豐富的說話人個性信息,因此轉換后的語音在個性相似度上仍有待提升.
針對上述問題,本文從以下方面提出改進意見:1)通過改善生成對抗網絡[12]的性能,進一步提升語音轉換模型生成語音的清晰度和自然度;2)通過引入含有豐富說話人個性信息的表征向量,提高轉換語音的個性相似度.2019 年,Baby 等[13]通過實驗證明,相比于WGAN,相對生成對抗網絡(Relativistic standard generative adversarial networks,RSGAN) 生成的數據樣本更穩定且質量更高.此外,在說話人確認[14?16]和說話人識別[17]領域的相關實驗證明,i 向量(Identity-vector,i-vector)可以充分表征說話人個性信息.鑒于此,本文提出基于i 向量和變分自編碼相對生成對抗網絡的語音轉換模型(Variational autoencoding RSGAN and i-vector,VARSGAN+i-vector),該方法將RSGAN 應用在語音轉換領域,利用生成性能更好的相對生成對抗網絡替換VAWGAN 模型中的Wasserstein 生成對抗網絡,同時在解碼網絡引入含有豐富說話人個性信息的i 向量輔助語音的重構.充分的客觀和主觀實驗表明,本文方法在有效改善合成語音自然度的同時進一步提升了說話人個性相似度,實現了非平行文本條件下高質量的多對多語音轉換.
1 基于VAWGAN 的語音轉換基準方法
基于VAWGAN 語音轉換模型利用WGAN[11]提升了C-VAE 的性能,其中C-VAE 的解碼器部分由WGAN 中的生成器代替.VAWGAN 模型由編碼器、生成器和鑒別器3 部分構成.完整的語音轉換模型可表示為:

式中,fφ(·) 表示編碼過程,通過編碼過程將輸入語音x轉換為獨立于說話人的隱變量z,認為是與說話人個性特征無關的語義信息.fθ(·) 表示解碼過程,將說話人標簽y拼接至隱變量z上構成聯合特征 (z,y),在解碼過程中利用聯合特征 (z,y) 重構出特定說話人相關的語音,然后將真實語音x和生成語音送入鑒別器判別真假.同時,利用表征說話人身份的one-hot 標簽y,VAWGAN 模型可以根據y的數值對其表示的特定說話人進行語音轉換,從而實現多說話人對多說話人的語音轉換.
為實現語音轉換,WGAN 通過Wassertein目標函數[8]來代替生成對抗網絡中的JS(Jensen-Shannon)散度來衡量生成數據分布和真實數據分布之間的距離,在一定程度上改善了傳統生成對抗網絡[18]訓練不穩定的問題.
綜上分析可知,VAWGAN 利用潛在語義內容z和說話人標簽y重構任意目標說話人的語音,實現了非平行文本條件下多對多的語音轉換.該基準模型中WGAN 采用權重剪切操作來強化Lipschitz連續性限制條件,但仍存在訓練不易收斂,性能不穩定等問題,在數據生成能力上仍存在一定的改進空間.此外,VAWGAN 利用one-hot 標簽表征說話人身份,而one-hot 標簽只是用于指示不同說話人,無法攜帶更為豐富的說話人個性信息.通過提升WGAN 的性能或找到生成性能更加強大的生成對抗網絡,有望獲得更好自然度的語音,進一步引入含有豐富說話人個性信息的表征向量能夠有助于提升說話人個性相似度.
2 改進的基于VARSGAN+i-vector的語音轉換方法
2.1 RSGAN 的原理
為進一步提升VAWGAN 的性能,通過找到一個生成性能更加強大的GAN 替換WGAN 是本文的一個研究出發點.2019 年Baby 等[13]通過實驗證明相比于最小二乘GAN[19]和WGAN[11],RSGAN生成的數據樣本更穩定且質量更高.RSGAN 由標準生成對抗網絡發展而來,通過構造相對鑒別器的方式,使得鑒別器的輸出依賴于真實樣本和生成樣本間的相對值,在訓練生成器時真實樣本也能參與訓練.為了將鑒別器的輸出限制在[0,1]中,標準生成對抗網絡常常在鑒別器的最后一層使用sigmoid激活函數,因此標準生成對抗網絡鑒別器定義為:
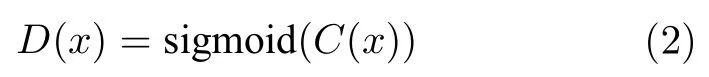
式中,C(x) 為未經過sigmoid 函數激勵的鑒別器輸出.由于鑒別器的輸出由真實樣本和生成樣本共同決定,因此可以使用下述的方法構造相對鑒別器:

式中,xr表示真實樣本,xr ∈P,xf表示生成樣本,xf ∈Q,表示真實樣本比生成樣本更真實的概率,表示生成樣本比真實樣本更真實的概率.經過如下推導:

可得

進而可得RSGAN 的鑒別器和生成器的目標函數:

式中,sigmoid 表示鑒別器最后一層使用sigmoid激活函數.
綜上分析可知,相比于WGAN,RSGAN 生成的數據樣本更穩定且質量更高,若將RSGAN 應用到語音轉換中,通過構造相對鑒別器的方式,使得鑒別器的輸出依賴于真實樣本和生成樣本間的相對值,在訓練生成器時真實樣本也能參與訓練,從而改善鑒別器中可能存在的偏置情況,使得訓練更加穩定,性能得到提升,并且把真實樣本引入到生成器的訓練中,可以加快GAN 的收斂速度.鑒于此,本文提出利用RSGAN 替換WGAN,構建基于變分自編碼相對生成對抗網絡(Variational autoencoding RSGAN,VARSGAN)的語音轉換模型,并引入可以充分表征說話人個性信息的i 向量特征,以期望在改善合成語音自然度的同時,進一步提升轉換語音的個性相似度.
2.2 i 向量的原理和提取
通過引入含有豐富說話人個性信息的表征向量,從而提升轉換語音的個性相似度是本文在上述研究基礎上進一步的探索.Dehak 等[14]提出的說話人身份i 向量,可以充分表征說話人的個性信息.i向量是在高斯混合模型?通用背景模型(Gaussian mixture model-universal background model,GMM-UBM)[15]超向量和信道分析的基礎上提出的一種低維定長特征向量.對于p維的輸入語音,GMM-UBM 模型采用最大后驗概率算法對高斯混合模型中的均值向量參數進行自適應可以得到GMM 超向量.其中,GMM-UBM 模型可以表征背景說話人整個聲學空間的內部結構,所有說話人的高斯混合模型具有相同的協方差矩陣和權重參數.由于說話人的語音中包含了個性差異信息和信道差異信息,因此全局GMM 的超向量可以定義為:

式中,S表示說話人的超向量,m表示與特定說話人和信道無關的均值超向量,即通用背景模型下的超向量,T是低維的全局差異空間矩陣,表示背景數據的說話人空間,包含了說話人信息和信道信息在空間上的統計分布,也稱為全局差異子空間.ω(ω1,ω2,···,ωq)是包含整段語音中的說話人信息和信道信息的全局變化因子,服從標準正態分布 N(0,I),稱之為i 向量,即身份特征i 向量.
首先,將經過預處理的訓練語料進行特征提取得到梅爾頻率倒譜系數,將梅爾頻率倒譜參數輸入高斯混合模型進行訓練,通過期望最大化算法得到基于高斯混合模型的通用背景模型,根據通用背景模型得到均值超向量m,通過最大后驗概率均值自適應得到說話人的超向量S.同時,根據訓練所得的通用背景模型提取其鮑姆?韋爾奇統計量,通過期望最大化算法估計獲得全局差異空間矩陣T.最終,通過上述求得的高斯混合模型的超向量S、通用背景模型的均值超向量m、全局差異空間矩陣T可以得到i 向量.由于上述得到的i 向量同時含有說話人信息和信道信息,本文采用線性判別分析和類協方差歸一化對i 向量進行信道補償,最終生成魯棒的低維i 向量.
2.3 基于VARSGAN+i-vector 的語音轉換方法
基于以上分析,本文提出VARSGAN+i-vector 的語音轉換模型,在解碼階段融入表征說話人個性信息的i 向量,將one-hot 標簽和i 向量拼接至語義特征上構成聯合特征重構出指定說話人相關的語音.其中,i 向量含有豐富的說話人個性信息,能夠與傳統編碼中的one-hot 標簽相互補充,互為輔助,前者為語音的合成提供豐富的說話人信息,后者作為精準的標簽能夠準確區分不同說話人,相輔相成有效提升轉換后語音的個性相似度,進一步實現高質量的語音轉換.基于VARSGAN+i-vector 模型的整體流程如圖1 所示,分為訓練階段和轉換階段.

圖1 基于VARSGAN+i-vector 模型的整體流程圖Fig.1 Framework of voice conversion based on VARSGAN+i-vector network
2.3.1 訓練階段
獲取訓練語料,訓練語料由多名說話人的語料組成,包含源說話人和目標說話人;將所述的訓練語料通過WORLD[20]語音分析模型,提取出各說話人語句的頻譜包絡、基頻和非周期性特征;利用第2.2 節的i 向量提取方法獲得表征各個說話人個性信息的i 向量i;將頻譜包絡特征x、說話人標簽y、i 向量i一同輸入VARSGAN+i-vector 模型進行訓練,VARSGAN+i-vector 模型是由C-VAE 和RSGAN 結合而成,將變分自編碼器的解碼器指定為RSGAN 的生成器來優化目標函數.原理如圖2所示.

圖2 VARSGAN+i-vector 模型原理示意圖Fig.2 Schematic diagram of VARSGAN+i-vector network
該模型完整的目標損失函數為:

式中,L(x;φ,θ) 為C-VAE 部分的目標函數:

式中,DKL表示KL(Kullback-Leibler) 散度,qφ(z|x)表示編碼網絡,該網絡將頻譜特征x編碼成潛在變量z.pθ(x|z,y,i) 表示解碼網絡,將聯合特征向量盡可能重構x就可以使式(11)的期望盡可能大.pθ(z)為潛在變量z的先驗分布,該分布為標準多維高斯分布.使用隨機梯度下降法來更新C-VAE中的網絡模型參數,其目標是 max{L(x;φ,θ)}.
式(10)中,α是調節RSGAN 損失的系數,JRSGAN表示RSGAN 部分的目標函數,由生成器和鑒別器的損失函數構成,其中RSGAN 的生成器中結合了表征各說話人個性信息的i 向量i.由式(7)和式(8)可知,生成器網絡的損失函數用LG來表示:

式中,Gθ表示生成器,Dψ表示鑒別器,θ和ψ分別是生成器和鑒別器的相關參數,Gθ(z,y,i) 表示重構的頻譜特征,Dψ(Gθ(z,y,i))表示鑒別器對重構的頻譜特征判別真假.
鑒別器網絡的損失函數用LD表示:

添加梯度懲罰項后,鑒別器的損失函數更新為:

構建從源說話人語音對數基頻 lnf0到目標說話人對數基頻的轉換函數:

式中,μ和σ分別表示源說話人的基頻在對數域的均值和標準差,μ′和σ′分別表示目標說話人的基頻在對數域的均值和標準差.
2.3.2 轉換階段
將待轉換語料中源說話人的語音通過WORLD[20]語音分析模型提取出不同語句的頻譜包絡特征x、基頻和非周期性特征;將頻譜包絡特征x、說話人標簽y、i 向量i輸入訓練好的VARSGAN+i-vector 模型,從而重構出目標說話人頻譜包絡特征;通過式(15)表示的基頻轉換函數,將源說話人對數基頻lnf0轉換為目標說話人的對數基頻lnf0′;非周期性特征保持不變.將重構的目標說話人頻譜包絡特征、目標說話人的對數基頻lnf0′和源說話人的非周期性特征通過WORLD 語音合成模型,合成得到轉換后的說話人語音.
3 實驗與分析
本實驗采用VCC2018[22]語料庫,該語料庫是由國際行業內挑戰賽提供的標準數據庫,為評估不同科研團隊的語音轉換系統的性能提供一個通用標準.鏈接為http://www.vc-challenge.org/vcc2018/index.html,其中的非平行文本語料庫包括4 名源說話人(包括2 名男性和2 名女性),分別是VCC2SF3、VCC2SF4、VCC2SM3 和VCC2SM4;4 名目標說話人(包括2 名男性和2 名女性),分別是VCC2TF1、VCC2TF2、VCC2TM1 和VCC2-TM2.每個說話人在訓練時均選取81 句訓練語音,在轉換時選取35 句測試語音進行轉換,一共有16種轉換情形.將上述8 個說話人的訓練語料輸入Kaldi 語音識別工具中預訓練好的模型來提取i 向量特征,分別得到表征上述8 個人個性信息的各自100 維的i 向量.
實驗系統在Python 平臺環境下實現.在Intel(R) Xeon(R) CPU E5-2660v4@2.00GHz,NVIDIA Tesla V100 (reva1)的Linux 服務器上運行,對語料庫中的8 個說話人的語音基于5 種模型進行客觀和主觀評測,將VAWGAN[8]作為本文的基準模型與本文提出的改進模型VARSGAN、VAWGAN+i-vector 和VARSGAN+i-vector 進行縱向對比,并進一步與StarGAN 模型[9]進行橫向對比,這5 種模型都是實現非平行文本條件下的多對多轉換.
本文使用WORLD 分析/合成模型提取語音參數,包括頻譜包絡特征、非周期性特征和基頻,由于FFT 長度設置為1 024,因此得到的頻譜包絡和非周期性特征均為1 024/2+1=513 維.使用VARSGAN+i-vector 模型轉換頻譜包絡特征,使用傳統的高斯歸一化的轉換方法轉換對數基頻,非周期性特征保持不變.在VARSGAN+i-vector 模型中,所述編碼器、生成器、鑒別器均采用二維卷積神經網絡,激活函數采用LReLU 函數[23].圖3 為VARSGAN+i-vector 模型網絡結構圖,其中編碼器由5 個卷積層構成,生成器由4 個反卷積層構成,鑒別器由3 個卷積層和1 個全連接層構成.

圖3 VARSGAN+i-vector 模型網絡結構示意圖Fig.3 Structure of VARSGAN+i-vector network
圖3 中,h、w、c分別表示高度、寬度和通道數,k、c、s分別表示卷積層的內核大小、輸出通道數和步長,Input 表示輸入,Output 表示輸出,Real/Fake 表示鑒別器判定為真或假,Conv 表示卷積,Deconv 表示反卷積 (轉置卷積),Fully Connected 表示全連接層,Batch Norm 表示批歸一化.實驗中隱變量z的維度,在借鑒基于變分自編碼器模型的相關文獻基礎上結合實驗調參,設置為128.實驗中RSGAN 的損失系數α設置為50,梯度懲罰參數λ設置為10,訓練批次大小設置為16,訓練周期為200,學習率為0.000 1,最大迭代次數為200 000.本文模型VARSGAN+i-vector 訓練約120 000 輪損失函數收斂,能達到穩定的訓練效果,而基準模型耗時相對較長,并且得到的轉換性能不夠穩定.
3.1 客觀評價
本文選用梅爾倒譜失真距離(Mel-cepstral distortion,MCD)作為客觀評價標準,通過MCD 值來衡量轉換后的語音與目標語音的頻譜距離[1?2],MCD 計算公式如下:

式中,cd和分別是目標說話人語音和轉換后語音的第d維梅爾倒譜系數,D是梅爾倒譜系數的維數.計算MCD 值時對16 組轉換情形分別選取35 句轉換語音進行統計.圖4 為16 種轉換情形下5 種模型的轉換語音的MCD 值對比.

圖4 16 種轉換情形下5 種模型的轉換語音的MCD 值對比Fig.4 Average MCD of five models for 16 conversion cases
由圖4 可知,16 種轉換情形下VAWGAN、VARSGAN、VAWGAN+i-vector、VARSGAN+i-vector 和StarGAN 模型的轉換語音的平均MCD 值分別為5.690、5.442、5.507、5.417 和5.583.本文提出的3 種模型相比基準模型,分別相對降低了4.36%、3.22%和4.80%.VARSGAN+i-vector 模型相比StarGAN 模型相對降低了2.97%.表明相對生成對抗網絡的結合和i 向量的引入能夠顯著改善轉換語音的合成自然度,有助于提升轉換語音的質量.
進一步將上述16 種轉換情形按照源?目標說話人性別劃分為具有統計性的4 大類,即同性別轉換女?女、男?男和跨性別轉換男?女、女?男.4 大類轉換情形下不同模型的MCD 值對比如圖5 所示.

圖5 4 大類轉換情形下不同模型的MCD 值對比Fig.5 Comparison of MCD of different models for four conversion cases
進一步分析實驗結果可得,本文提出的方法VARSGAN+i-vector 在跨性別轉換下,女?男類別下的平均MCD 值比男?女類別下的平均MCD值相對低4.58%,表明女性向男性的轉換性能稍好于男性向女性的轉換.而這一現象在基準系統VAWGAN、VARSGAN、VAWGAN+i-vector 和StarGAN 中也不同程度地存在.原因主要是,語音的發音主要由基頻和豐富的諧波分量構成,即使同一語句,由于不同性別說話人之間的基頻和諧波結構存在差異較大[24?25],會導致不同性別說話人之間的轉換存在一定的性能差異.
3.2 主觀評價
本文采用反映語音質量的平均意見得分(Mean opinion score,MOS)值和反映說話人個性相似度的ABX 值來評測轉換后語音.主觀評測人員為20名有語音信號處理研究背景的老師及碩士研究生,為了避免主觀傾向以及減少評測人員的工作量,從5 種模型的各16 種轉換情形的35 句轉換語音里面為每個人隨機抽取一句,并將語句順序進行系統置亂.其中在ABX 測試中,評測人員還需同時測聽轉換語音相對應的源和目標說話人的語音.
在MOS 測試中,評測人員根據聽到的轉換語音的質量對語音進行打分,評分分為5 個等級:1 分表示完全不能接受,2 分表示較差,3 分表示可接受,4 分表示較好,5 分表示非常樂意接受.本文將16種轉換情形劃分為4 類:男?男,男?女,女?男,女?女,4 類轉換情形下5 種模型的轉換語音MOS值對比如圖6 所示.

圖6 5 種模型在不同轉換類別下的MOS 值對比Fig.6 Comparison of MOS for different conversion categories in five models
通過分析實驗結果可得,VAWGAN、VARSGAN、VAWGAN+i-vector、VARSGAN+i-vector 和StarGAN 的平均MOS 值分別為3.382、3.535、3.471、3.555 和3.446.相比基準模型,本文3 種模型的MOS 值分別相對提高了4.52%、2.63%和5.12%,VARSGAN+i-vector 相比StarGAN 提高了3.16%,表明本文提出的相對生成對抗網絡和i 向量的引入能夠有效地改善合成語音的自然度,提高聽覺質量.
在ABX 測試中,評測人員測評A、B 和X 共3 組語音,其中A 代表源說話人語音,B 代表目標說話人語音,X 為轉換后得到的語音,評測人員判斷轉換后的語音更加接近源語音還是目標語音.一般將16 種轉換情形劃分為同性轉換和異性轉換.5種模型在同性轉換下的ABX 測試結果如圖7 所示,異性轉換下的ABX 測試結果如圖8 所示.

圖7 同性轉換情形下5 種模型轉換語音的ABX 圖Fig.7 ABX test results of five models for intra-gender

圖8 異性轉換情形下5 種模型轉換語音的ABX 圖Fig.8 ABX test results of five models for inter-gender
圖8 中,A (sure)表示轉換語音完全確定是源說話人,A (not sure)表示轉換語音像源說話人但不完全確定,B (not sure)表示轉換語音像目標說話人但不完全確定,B (sure)表示轉換語音像目標說話人且完全確定.在5 種模型中,沒有評測人員認為轉換后的語音確定是源說話人,因此A (sure)沒有得分,即在圖中沒有比例顯示.在評測結果分析中,將B (not sure)和B (sure)的比例之和作為轉換語音更像目標說話人的衡量指標.
如圖7 和圖8 所示,5 種模型在異性轉換下的說話人個性相似度均優于同性轉換下的說話人個性相似度,其中在同性轉換情形下,VAWGAN、VARSGAN、VAWGAN+i-vector、VARSGAN+i-vector 和StarGAN 的ABX 值的比例分別為70.3%、74.1%、78.4%、79.7%和73.5%,相比基準模型,本文3 種模型分別提升了3.8%、8.1% 和6.2%,VARSGAN+i-vector 相比StarGAN 模型提升了4.4%.在異性轉換情形下5 種模型的ABX值的比例分別為82.8%、86.2%、89.4%、90.6%和83.8%,相比基準模型,本文3 種模型分別提升了3.4%、6.6%和7.8%,VARSGAN+i-vector 相比StarGAN 提升了6.8%.在同性和異性2 種情形下,本文提出的3 種模型相比基準模型,平均ABX 值分別提升了3.6%、7.35%和8.6%,VARSGAN+i-vector模型相比StarGAN 模型提升了5.6%,由分析可以看出,相對生成對抗網絡的改進不僅有效地改善了合成語音的自然度,而且也有助于說話人個性相似度的提高;結合傳統說話人編碼one-hot 實現多對多語音轉換的同時,在解碼階段融入含有豐富說話人個性信息的特征i 向量,能夠有效增強目標說話人的個性信息,顯著提升說話人的個性相似度.因此,本文方法能夠顯著改善模型的性能.
綜上所述,VARSGAN+i-vector 模型相比基準模型 VAWGAN 和StarGAN,平均MOS 值相對提高了5.12% 和3.16%,平均ABX 值提升了8.6%和5.6%,表明本文提出的相對生成對抗網絡和i 向量的引入,能夠顯著提高合成語音的自然度和個性相似度.
4 結束語
本文提出一種基于VARSGAN+i-vector 的語音轉換模型,該方法利用RSGAN 替代基準模型中的WGAN,改進了語音轉換模型中生成對抗網絡的性能,從而生成語音自然度更好的轉換語音.進一步將i 向量引入基于VARSGAN 的語音轉換模型,在模型訓練和轉換過程中利用i 向量表征說話人的個性信息,有效提升轉換語音的個性相似度.充分的客觀和主觀實驗結果表明,相比于基準模型VAWGAN 和 StarGAN,本文提出的方法在有效改善轉換語音的合成質量的同時,也顯著提升了說話人個性相似度,實現了高質量的語音轉換.今后工作將研究序列到序列的語音轉換,進一步考慮韻律特征的建模和轉換,此外,降低對訓練數據量的需求以實現小樣本語音轉換[26]也是課題組后續進一步研究的關注點和探索方向,這也是該技術真正進入工業領域需要接受的挑戰之一.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
中華手工(2017年2期)2017-06-06 23:00:31
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
中外會展(2014年4期)2014-11-27 07:46:46
中學數學雜志(初中版)(2006年1期)2006-12-29 00:00:00
建筑創作(2001年3期)2001-08-22 18:48:14
祝您健康(1987年3期)1987-12-30 09:52:32
