基于深度特征字典學習和Largevis的遙感圖像檢索
2022-08-01 03:43:42侯峰,劉斌,卓政,卓力*,張菁
測控技術 2022年7期
侯 峰, 劉 斌, 卓 政, 卓 力*, 張 菁
(1.北京工業大學 北京計算智能與智能系統重點實驗室,北京 100124;2.北京工業大學 信息學部 微電子學院,北京 100124; 3.北京航空航天大學 計算機學院,北京 100191)
遙感技術在近些年發展迅速,遙感衛星對地觀測分辨率越來越高,遙感圖像數據量呈現出爆發式的增長。如何對海量的遙感圖像數據進行高效的檢索,是發揮其效應的關鍵所在[1]。
圖像檢索技術[2]的發展經歷了兩個階段。第一階段是20世紀70年代基于文本的圖像檢索技術 (Text-based Image Retrieval,TBIR),它采用關鍵字的方式來進行圖像檢索,雖然簡單快速,但是需要耗費大量人工成本進行標注,在海量圖像數據場景下難以適用。第二階段是20世紀90年代以來基于內容的圖像檢索(Content-based Image Retrieval,CBIR)。這一方法包含兩個核心技術,分別是圖像特征提取和相似性度量。首先,提取圖像的低層視覺特征用于描述圖像的內容,然后建立圖像特征描述符庫,將每一幅圖像與其特征描述符之間建立一一對應關系;在相似性度量階段,對查詢圖像以同樣的方式提取特征,然后與圖像特征描述符庫中所有特征描述符進行相似性度量,并按照相似性大小進行排序,將特征描述符最相似的若干幅圖像作為結果返回給用戶。對于CBIR來說,圖像檢索性能的優劣主要取決于圖像特征的表達能力。因此,如何提取更具有表達能力和區分性的圖像特征就成為研究重點。
早期的遙感圖像檢索基于CBIR框架加以實現,采用一些手工提取的特征,例如局部二值模式(LocalBinary Patter,LBP)、尺度不變特征變換(Scale-Invariant Feature Transformation,SIFT)、定向梯度直方圖(Histogram of Oriented Gradients,HOG)等,這些特征表征了圖像中一些局部點的統計特性,可以稱作局部描述子。由于這些局部描述子并不能描述整個圖像,因此需要將這些局部描述子使用一定的編碼方法構建出更加緊湊的全局圖像描述符。常用的編碼方法有詞袋(Bag of Words,BoW)[3]、改進的Fisher核(Improved Fisher Kernel,IFK)[4]和向量局部聚集描述符(Vector Locally Aggregated Descriptors,VLAD)[5]等。
2012年,深度卷積神經網絡(Convolutional Neural Network,CNN)在大規模視覺識別挑戰賽中取得了當時最優的成績,且性能遙遙領先第二名。自此,以CNN為代表的深度學習技術在圖像處理、機器視覺等領域不斷突破,取得了遠超過傳統方法的性能。CNN通過多層卷積層來模仿人類大腦的學習機制,可以自動學習到從圖像細節紋理到局部塊再到高層語義的層次化遞進表達。與手工特征相比較,CNN不僅減少了手工設計圖像特征的復雜數學推導,而且學習到的深度特征相比手工特征更具魯棒性,區分性與表達能力也更強。
學者們將CNN應用于遙感圖像檢索中,取得了諸多成果。2015年,Babenko等[6]使用不同的CNN、卷積層池化和編碼方法進行了對比實驗。他們得出的結論是,基于聚合池化的方法可以獲得更優的性能。同年,Lin等[7]提出了一個深度學習框架,用于生成二進制哈希碼,實現圖像的快速檢索。該方法以一種逐點的方式學習哈希碼和圖像表示,比較適合于大規模數據集的檢索。實驗結果表明,在CIFAR-10和MNIST數據集上,該方法優于幾種最新的哈希算法。2019年,Ge等[8]將不同的卷積特征圖融合成一個更大的特征圖,以保留圖像的空間信息,將所有卷積層特征進行級聯后,采用maxpool方法進行壓縮,并采用PCA降維,得到了優于單一特征的檢索性能。同年,Xiong等[9]將注意力機制和新的注意模塊引入到CNN結構中,使得人們更加關注顯著特征,并對其他特征進行抑制,極大地提高了遙感圖像檢索的基線。2020年,彭晏飛等[10]提出了區域注意力網絡,該方法有效抑制了遙感圖像背景和不相關的圖像區域,在兩大遙感圖像數據集上取得了優異的效果。
本文以Google公司提出的Inception系列網絡的最新版本Inception v4[11]作為骨干網絡,提出了一種深度特征字典學習方法,該方法對Inception v4第一個Reduction Block輸出的卷積特征圖進行重組,然后使用重組特征學習深度特征字典,最后使用學習到的深度特征字典對卷積特征圖進行緊湊的表達,得到卷積層特征表示向量。該向量與全連接(Full Connection,FC)層特征級聯起來,形成圖像的特征表示向量。為了避免“維度災難”,采用Largevis方法對高維的特征表示向量進行降維,通過L2距離度量降維后的低維特征之間的相似度,實現圖像檢索。在多個遙感圖像數據集上的實驗表明,此方法可以有效地提升卷積層的特征表達能力,與現有的先進方法相比,可以獲得更好的檢索性能。
1 深度特征提取
目前基于CNN的遙感圖像檢索方案提取的深度特征分別來自于卷積層和FC層,其中卷積層特征來自于CNN的低層,包含的大多是圖像局部細節信息,可以表征圖像的低層視覺特性[12];FC層通常位于CNN的最后幾層,用于表征圖像的高層語義信息[13]。
根據特征提取階段所利用的深度特征的不同,可以將基于CNN的遙感圖像檢索方案分為兩大類:基于卷積層特征的遙感圖像檢索和基于FC層特征的遙感圖像檢索,卷積層特征和FC層特征如圖1所示。
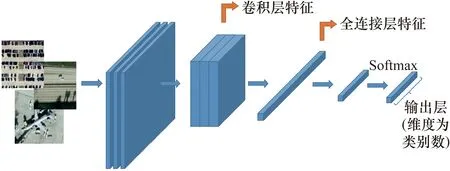
圖1 從卷積層和FC層提取的深度特征
Inception系列網絡是Google提出的面向圖像分類的卷積神經網絡結構,它們最大的特點是在同一個卷積層中使用不同大小的卷積核來提取深度特征。相比前面幾代的Inception系列網絡結構,Inception v4使用大量小尺度卷積核來代替大尺度卷積核,并多次使用1*1卷積核將特征圖通道數控制在一個合理的范圍內。這些操作使得網絡在保證性能不降低的情況下參數量更少,計算速度更快。除此之外,Inception v4進一步整合了前幾代的Inception網絡,引入了專門的Reduction Block,用于改變特征圖的寬度和高度。本文將采用Inception v4作為骨干網絡,來提取圖像的深度特征。
圖2是Inception v4的第一個Reduction Block結構,它將輸入的35*35大小的特征圖變成了17*17。Reduction Block結構包含3種操作,分別是3*3卷積、5*5卷積和maxpool操作。3種操作會得到3種不同類型的特征圖,這些特征圖無法直接作為描述符用于圖像檢索。為此,本文對這些特征圖進行了重組并對其進行量化編碼,得到一種緊湊的特征表示向量用于圖像檢索。
2 深度特征字典學習
提出了一種深度特征字典學習方法,該方法采用K均值聚類算法對重組后的卷積層特征進行訓練,得到深度特征字典。基于該字典對卷積層特征進行緊湊表達,得到卷積層的特征表示向量。
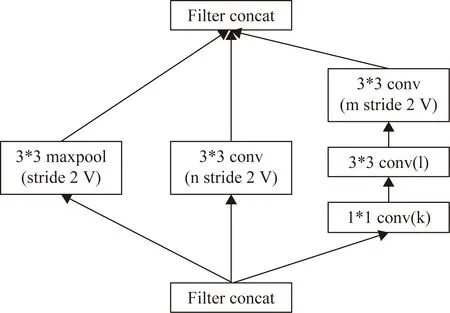
圖2 Inception v4中的Reduction Block結構
2.1 卷積層特征圖的重組
在Inception v4的第一個Reduction Block模塊中,包含的3種操作可以表示為Fi_conv(.),i=1,2,3,分別表示3*3卷積、5*5卷積和maxpool操作,得到3組不同類型的卷積特征圖,分別為5*5 conv,3*3 conv和maxpool conv,如圖3所示。最終輸出的數據量大小為Si_conv=Bi_conv*Ci_conv*Hi_conv*Wi_conv。其中,Bi_conv為批數量;Ci_conv為特征通道數目;Hi_conv和Wi_conv分別為特征圖的高度和寬度。
對于CNN來說,特征圖中每個特征點是通過某一卷積核對圖像中的對應區域進行卷積得到。采用相同大小、不同參數的卷積核進行卷積,得到的是某一個感受野的不同響應輸出,可以看作是對該區域的不同特征表示。對3組卷積特征圖數據進行重新組織的過程如圖3所示。對于每組數據,將每個特征圖中相同位置處的特征值提取出來,形成一個一維向量xk,其中k的取值范圍是[1,2,… ,Hi_conv*Wi_conv],最終共獲得Hi_conv*Wi_conv個xk,這些向量共同構成了一個樣本集合X=[x1,x2,…,xHiconv*Wiconv]∈RHiconv*Wiconv。
2.2 深度特征字典學習
對于重組后的卷積層特征,通過K均值聚類算法訓練并構建深度特征字典,用于對X集合進行緊湊表示。K均值聚類算法是一種無監督方法,通過聚類算法可以將數據表示為n個簇,假設設置的聚類中心為n,每個簇的中心作為一個視覺單詞,集合起來構成一個n維字典。
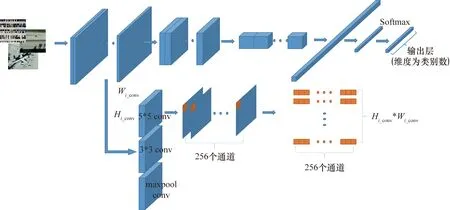
圖3 卷積層特征圖數據的組織過程示意圖

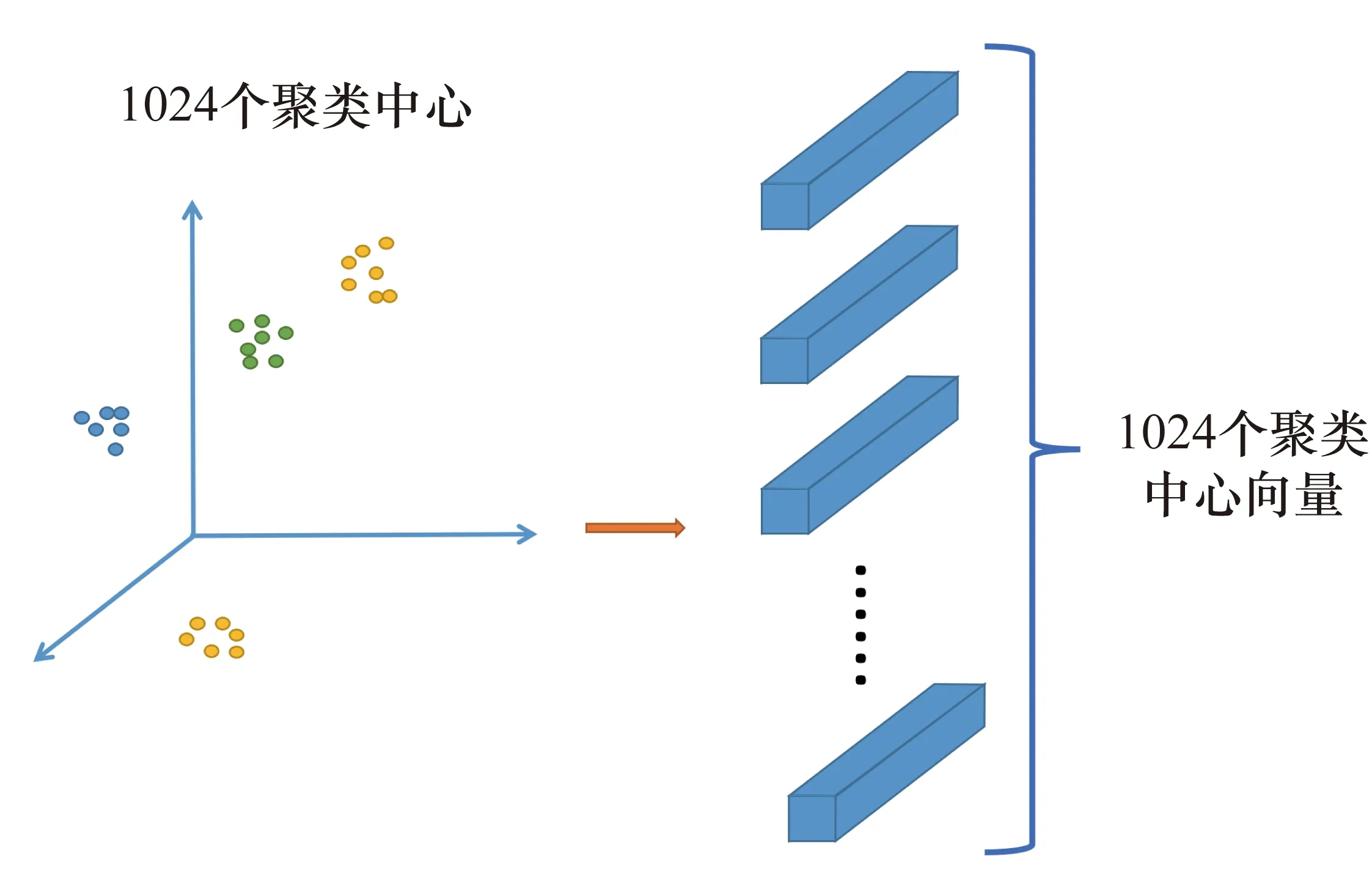
圖4 基于K均值聚類的深度特征字典學習
2.3 卷積特征圖的編碼表示
接下來,利用深度特征詞字典集合P,對卷積層特征圖進行量化,得到卷積層特征的緊湊表示。根據2.1節中所示的方法,每組卷積層特征圖可以看作是Hi_conv*Wi_conv個一維的特征列向量,向量維度為Ci_conv,i=1,2,3,分別表示其由3*3卷積、5*5卷積和maxpool等不同操作得到。每個列向量都可以用深度特征字典中的某個特征單詞近似代替,代替的依據是該列向量與某個特征單詞的L2距離最小。通過統計字典中每個特征單詞出現的次數,可以將每組卷積特征圖量化表示為一個L維的深度特征表示向量,L=1024。深度特征表示向量構建過程如圖5所示。
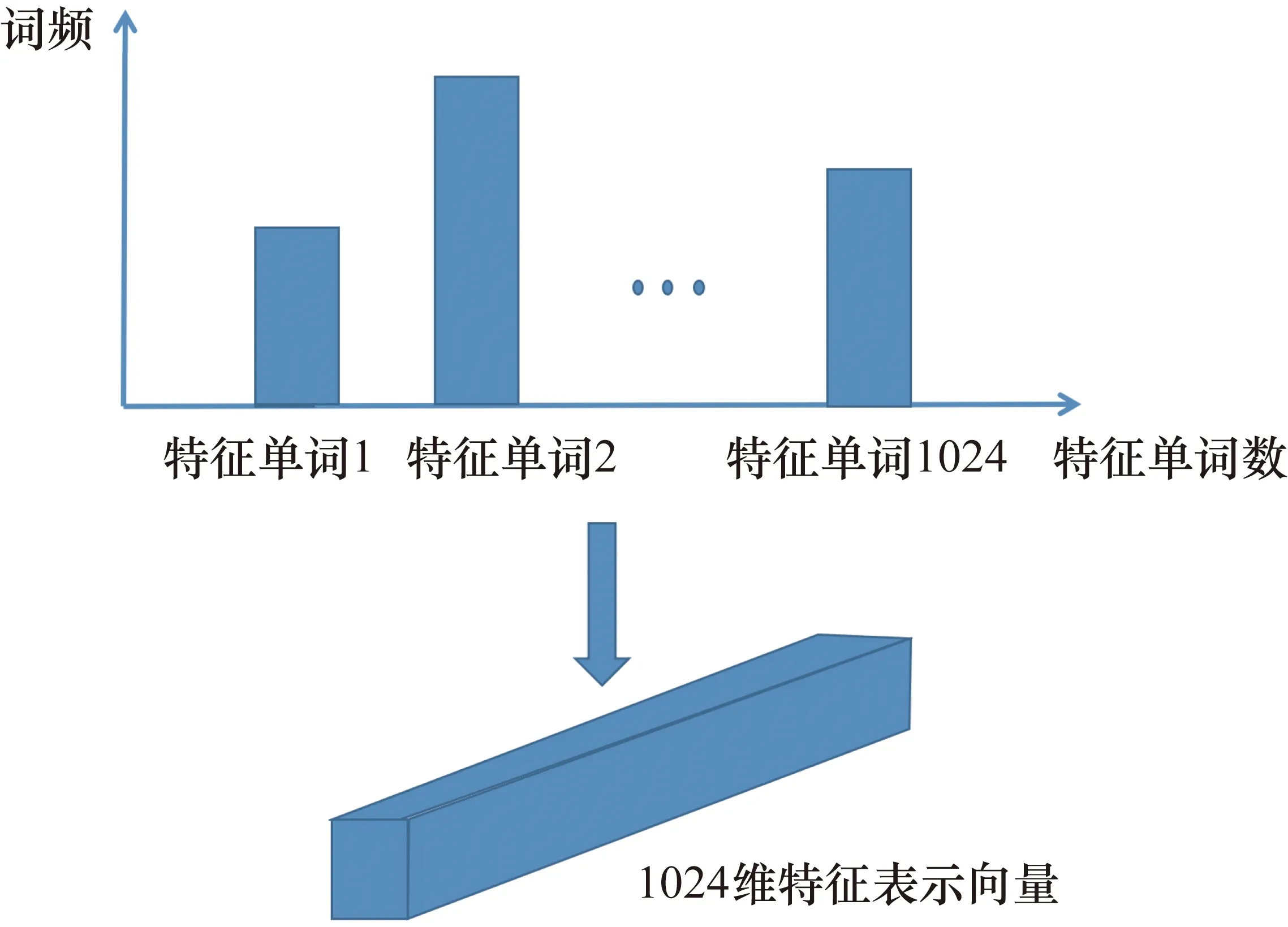
圖5 卷積特征圖的編碼表示
2.4 圖像特征表示向量
利用深度特征字典對卷積特征圖進行編碼,得到了一個1024維的深度特征表示向量Fi_conv,i=1,2,3,分別表示其由3*3卷積、5*5卷積和maxpool等不同操作得到。Fi_conv與FC層的特征向量Ffc進行級聯后,得到圖像特征表示向量F,F的維度為1024+1536=2560,如圖6所示。
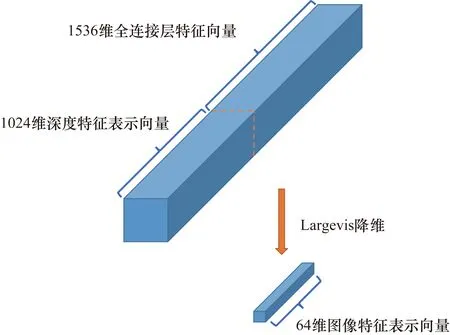
圖6 特征級聯與Largevis降維
為了降低計算量,節約存儲空間,對于得到的圖像特征表示向量,使用Largevis降維方法對其進行降維。Largevis是唐建等[14]于2016年提出的降維方法,該方法被用于大規模超高維數據的可視化。它由t-SNE進一步發展得到,采用了高效的 KNN圖來構建算法,并采用最近鄰搜索方法進行優化。Largevis算法相對于t-SNE不僅極大地降低了訓練的時間復雜度,而且在數據由高維空間向低維空間映射的過程中拉大了類間距離,縮小了類內距離。
采用Largevis對深度特征進行降維以后的特征向量為64維,作為最終的圖像特征表示。
3 相似性度量
本文采用L2距離度量特征之間的相似性。n維空間中兩個特征x1(x11,x12,…,x1n)與x2(x21,x22,…,x2n)間的L2距離定義如下:
(1)
4 實驗結果與分析
為了驗證筆者提出的遙感圖像檢索方法的有效性,分別在UCM、RS19和RSSCN三個數據集上進行了實驗,并與現有的各種先進方法進行了對比。
4.1 數據集與評價標準
目前最常用的遙感圖像檢索數據集有UCM、RS19和RSSCN等。其中RS19[15]是武漢大學發布的一個高分辨率衛星場景數據集,一共包括19個地物類別,每個類別有50張左右的圖像,每幅圖像大小是600像素×600像素,一共有1005張圖像。UCM數據集[16]由加州大學摩賽德分校發布,一共包含了21類地物,每個類別100張圖像,每張圖像大小是256像素×256像素。RSSCN7數據集[17]稱為遙感場景數據集,一共有7個類別,每個類別包含400張圖像,圖像大小是400像素×400像素。
使用平均準確率(mean Average Precision,mAP)作為檢索性能評價指標[18],平均準確率是遙感圖像檢索最常用的評價指標,定義如下:
(2)
式中:Q為類別數目;AveP的定義為
(3)
式中:P(k)為準確率;rel(k)是一個分段函數,當第k張圖像為相關圖像時,其值為1,否則為0。
4.2 參數設置
采用“預訓練+微調”的策略對Inception v4網絡進行訓練,解決無法在小規模的數據集上訓練深層網絡的問題。首先利用ImageNet數據集對Inception v4網絡進行預訓練,得到初始的網絡參數。然后利用遙感圖像數據集對初始網絡參數進行微調,得到面向遙感圖像檢索任務的網絡參數。接下來,提取網絡卷積層和FC層特征,按照第2節中所述的方法處理后得到圖像特征表示向量。
對于遙感圖像數據集,按照80%訓練集,20%測試集的比例進行劃分。單次實驗中對數據集隨機劃分,進行3次重復實驗,對3次的結果取平均作為最終的實驗結果。
實驗采用PyTorch開源框架進行搭建。計算硬件平臺使用單張Titan Xp 12GB的顯卡進行訓練和測試。訓練迭代次數設置為100輪,batch大小設置為16,學習率為0.001。
4.3 實驗結果
4.3.1 不同卷積特征表示向量對檢索性能的影響
通過使用深度特征字典對由Inception v4的第一個Reduction Block模塊輸出的3組卷積特征進行量化,可以獲得相應的卷積特征表示向量,表示為F3*3_conv、F5*5_conv和Fmaxpool。這些特征表示向量分別與FC特征級聯,形成用于圖像檢索的圖像特征表示向量,分別為F3*3_conv+FC、F5*5_conv+FC和Fmaxpool_conv+FC,維度均為2560,相似性度量采用的是式(1)所示的L2距離度量準則。在UCM、RS19和RSSCN7數據集使用3種特征表示向量得到的檢索性能如表1所示。

表1 不同卷積特征表示向量對檢索性能的影響
可以看出,卷積核的大小對檢索性能有很大的影響。綜合來看,采用5*5的卷積核得到的卷積特征表示向量可以獲得更好的檢索性能。因此可以選擇5*5卷積核得到的特征表示向量與FC層特征級聯,作為圖像的特征表示向量。
4.3.2 不同降維算法對檢索性能的影響
為了驗證不同降維算法對檢索性能的影響,在UCM、RS19和RSSCN7三個數據集上使用FICA( Fast Independent Component Analysis)、PCA(Principal component analysis)以及Largevis三種降維算法對4.3.1節中的F5*5_conv+FC進行降維,并進行了對比,對比結果見表2。為了達到速度與精度的均衡,設置降維的維度為64。可以看出,使用Largevis降維算法所得到的降維向量的檢索準確率在3個數據集上均遠超另外兩種降維算法,甚至高于4.3.1節中未降維之前的檢索準確率。這是因為Largevis可以將高維數據投影到低維空間,在減少高維數據冗余的同時,能有效地拉大原來在高維空間中不同類別數據之間的距離,減小相同類別數據之間的距離,從而提升特征的區分能力。
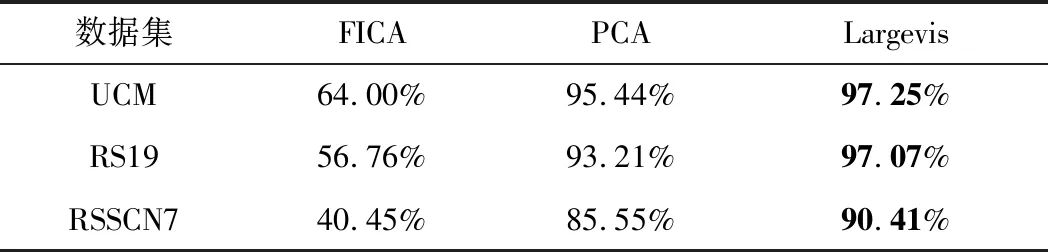
表2 采用Largevis降維對檢索性能的影響
4.3.3 與其他方法的對比結果
為了驗證筆者提出的圖像檢索方法的有效性,將其與現有的7種遙感圖像檢索方法進行對比。在3個數據集上和其他方法所得到的檢索性能對比結果如表3所示,表中的“—”表示原文中未進行該數據集的準確率測試實驗。
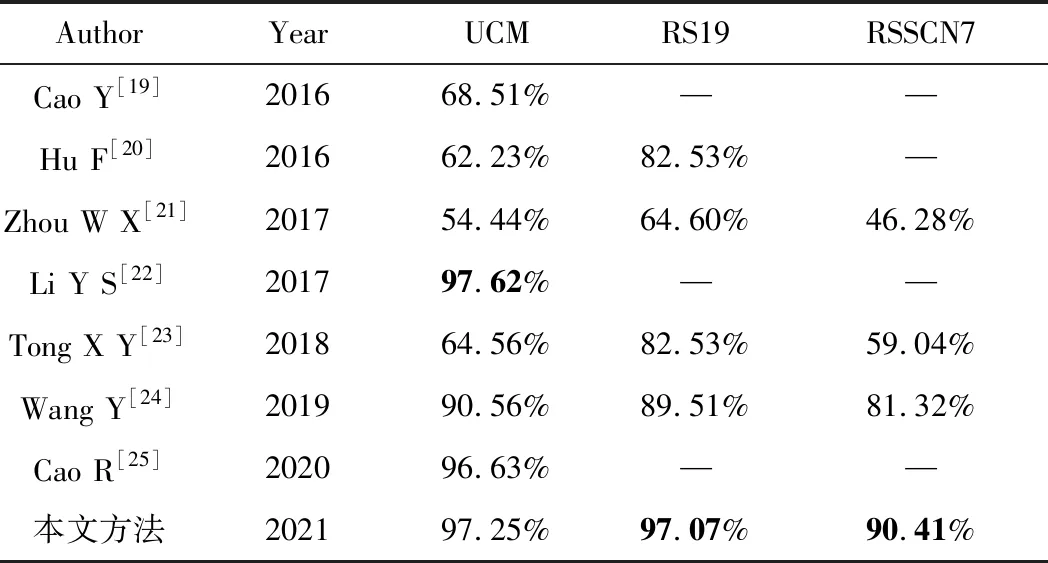
表3 mAP與現有檢索方法對比
由表3可以看出,與現有方法相比,筆者提出的方法在RS19和RSSCN7數據集上都能達到較好的檢索性能。而在UCM數據集上,mAP值僅比性能最好的方法低0.37%。采用Inception v4網絡架構,可以獲得描述性好、表達能力強的深度特征。采用深度特征進行字典學習以后對圖像細節表達更加充分,更加有利于遙感圖像檢索性能的提升。而采用Largevis對深度特征進行降維,不但可以降低計算復雜度,節約存儲空間,還可以進一步提升深度特征的區分能力,從而獲得最優的檢索性能。
5 結束語
本文基于Inception v4網絡結構,提出了一種遙感圖像檢索方法。該方法對卷積特征圖數據進行了重組,利用K均值聚類算法建立深度特征字典,對卷積層特征進行緊湊表示。然后將卷積層特征表示向量與FC層特征進行級聯,得到圖像特征表示向量。對其采用Largevis進行降維,進一步提升特征的區分能力。最后,利用L2距離度量準則進行特征相似性比對,實現遙感圖像檢索。在RS19、RSSCN7和UCM數據集上的實驗結果表明,與現有方法相比,該方法能獲得更好的檢索性能。在今后的工作中,將努力學習更深層次的視覺字典,以進一步提高檢索性能。
猜你喜歡
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
