網盤智能相冊系統研究與設計
2022-08-01 04:03:42鐘地秀丁小波蔡茂貞吳灼豪
現代計算機 2022年11期
鐘地秀,丁小波,蔡茂貞,彭 琨,吳灼豪
(中移互聯網有限公司云產品事業部,廣州 510000)
0 引言
隨著增強移動寬帶、低時延高可靠海量連接的5G 時代來臨,圖片、視頻、文本等個人數據也在不斷激增,個人數據的激增勢必讓個人網盤在未來成為強需求。據艾媒咨詢數據顯示,2020 年全球數據中心存儲容量將達到272 艾字節,不斷擴大的個人數據和云儲存需求加速了個人云服務市場的發展,預計2020 年中國個人云盤用戶規模有望超過4億人,未來個人網盤提供商的經營實力和服務能力將成為用戶關注的一大焦點。
國內個人網盤行業始于PC 時代,最初以網絡文件存儲、備份的功能為主。隨著互聯網技術的興起和智能手機的普及,個人手機上的數據(特別是照片和視頻)激增,個人網盤產品也不斷進化,照片和視頻的核心場景逐漸從個人網盤中獨立出來,從文件存儲分離出相冊產品。再到人工智能時代,大數據和圖像識別技術的引入為多媒體內容的識別和分析帶來諸多便利,孵化出如智能相冊、智能P 圖和自動視頻聚合等應用。本文重點關注基于圖像識別的網盤智能相冊系統。
1 網盤智能相冊功能
智能相冊基于AI 圖像識別技術,為網盤用戶提供良好的照片管理服務,包括人臉識別、物品分類以及場景理解、智能搜索等功能,通過理解圖片本身的視覺內容幫助用戶進行更多維度的分析管理。
(1)人臉識別。應用人臉檢測、人臉特征提取及聚類技術,自動識別出相冊圖片中包含哪些人,并將人物按照身份分組呈現給用戶,便于用戶瀏覽與查找。
(2)物品分類。應用物體檢測、物體分類技術,自動定位并識別出圖片中包含的主體位置和主體屬性標簽,如貓、狗、花、火車等,并基于圖片屬性標簽完成圖片分組展示。
(3)場景理解。應用圖像識別技術,分析圖片中出現的場景主題類別,如天空、海洋、草坪、婚禮等,以主題形式對用戶相冊進行分類管理,便于用戶記錄生活軌跡及美好瞬間。
2 網盤智能相冊系統架構
本文基于圖像識別及目標檢測等技術實現網盤智能相冊,實現的基本功能如圖1所示,針對用戶網盤相冊圖片集數據,系統可根據圖片視覺內容進行自動識別和自動分組,最后形成以人物個體或其它內容標簽為單位的圖片集,從而便于用戶更加快速高效地瀏覽及查找目標對象,實現智能高效管理相冊的目的。
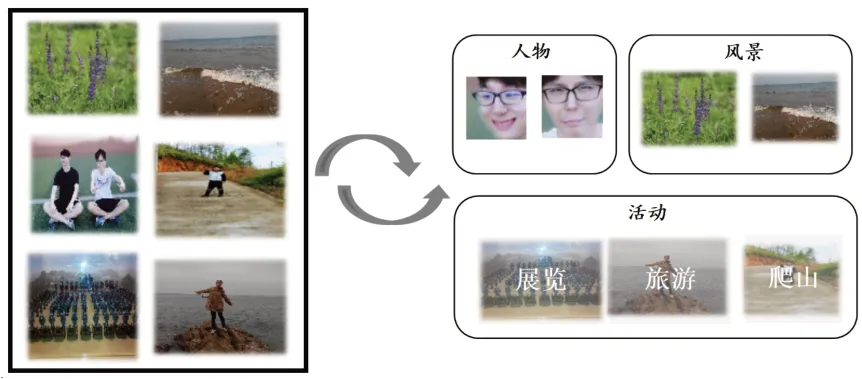
圖1 智能相冊功能示意圖
為實現上述基本功能,本文設計的智能相冊系統架構如圖2所示,整體架構分為模型訓練和服務應用兩大部分,模型訓練完成各類智能算法模型參數優化訓練,并為服務應用模塊提供算法技術支撐,實現相冊智能分類業務。本文網盤智能相冊具備人臉識別、物品分類、場景理解三大智能算法能力,基于基礎算法能力可為網盤用戶提供人像聚類及事物分類兩大智能相冊業務服務。
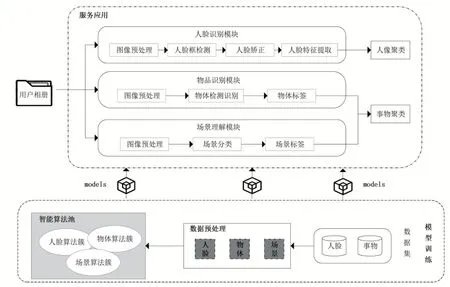
圖2 智能相冊系統框架圖
2.1 智能相冊算法模型訓練
模型訓練是整個系統框架的核心部分,智能相冊業務應用效果都依賴于模型訓練的高準確率,其基本組成部分如圖2 所示,包括用于模型優化訓練的圖片數據集、圖片數據預處理以及智能算法池三個模塊。本文智能相冊實現過程中需完成人臉識別、物體識別及場景理解三個模型訓練優化,具體詳情闡述如下。
為完成智能相冊算法模型訓練,本文采用網絡爬蟲及開源數據融合方式獲取訓練圖片集。圖片訓練集獲取后進行圖片清洗、篩選標注等一系列工作,并可依據不同的訓練任務執行相應的數據預處理操作。圖片數據預處理包括通用預處理方法及特定預處理方法兩類,通用預處理方法通常為視覺任務共用的圖像預處理手段,特定預處理可根據任務模型需求而設定。
通用預處理方法:三個任務均采取均值消除,值域歸一化預處理訓練集數據。
特定預處理方法:采取數值標準化(normal?ize),并使用對比度、色調擴增預處理人臉圖片集;采取數值標準化(normalize),并使用隨機剪裁、隨機旋轉擴增預處理物體圖片集;針對場景圖片集,實驗對比發現數值標準化方法對場景色彩影響較大,易造成大面積色彩相近的場景圖混淆錯分,故本文不采用該方法預處理場景圖片,而是采用隨機灰度化來降低色彩對場景標簽的影響,同時采取亮度、對比度調整擴增場景圖片集。
2.1.1 人臉識別
人臉識別完成的任務是通過人物面部特征提取分析,實現人臉身份確認,本文系統中人臉識別流程主要由人臉檢測、人臉矯正和人臉特征比對三個部分完成。
(1)人臉檢測。人臉檢測完成從照片中檢測獲得人臉坐標框以及人臉關鍵點坐標的任務,文 本 系 統 采 用 基 于 開 源WIDERFACE和LFPW數據集訓練完成的MTCNN實現人臉框和人臉關鍵點生成工作,模型訓練完成后在網絡爬蟲數據集上進行測試,測試結果如表1 所示。測試圖片數目為1000 張,包含總人臉數目為2503張,測試人臉圖片具備不同光照、膚色、表情及部分遮擋等多種形態,模型作用于圖片預測輸出圖片中所有人臉框4個坐標點以及臉部5個關鍵點坐標。

表1 MTCNN人臉檢測結果
(2)人臉矯正。為獲得更佳的人臉識別效果,在人臉檢測后需要對部分人臉圖片進行矯正,減小偏轉幅度過大的人臉傾斜角度。本文采用仿射變換完成人臉矯正,具體步驟如圖3左圖所示,通過調整人臉兩眼中心點連線的傾斜角度實現人臉旋轉角度矯正,矯正效果如圖3右圖所示。

圖3 人臉矯正方案(左)人臉矯正效果(右)
(3)人臉特征比對。人臉矯正完成后,應用人臉特征提取模型獲取人臉區域特征作為該人臉身份的表示向量,通過對比兩張人臉的表示向量判定人臉是否為同一人,從而確認人臉身份。本文采取insightface模型作為人臉特征提取模型,并應用歐式距離度量人臉特征表示。模型訓練集采用百度谷歌爬蟲獲得人物圖片集,包含1509 個人物ID,共94764 張圖片,模型主干網絡選擇Resnet50,損失函數采用基礎的softmax 損失,輸出人臉特征向量維度為512 維。模型訓練收斂后采用微博爬蟲圖片集進行測試,共包含1000 個微博人物ID,測試時隨機抽取3000 對相同人臉圖片及3000 對不同人臉圖片,測試結果如表2所示。

表2 人臉識別模型測試結果
2.1.2 物體識別
物體識別分辨出圖片中存在哪些物體,預測輸出圖片中包含的所有物體類別標簽。本文物體識別應用yolov5目標檢測模型實現,選擇日常生活中常見標簽(見表3),訓練圖片集由從開源coco數據集中抽取的部分標簽樣本集以及網頁爬蟲獲取的部分圖片集組成,訓練模型結構選用yolov5l 模型,并載入release 預訓練權重完成模型參數初始化。測試數據集由網頁爬蟲獲取,每類測試圖片為100張,測試僅計算物體識別結果,測試結果如表3所示。
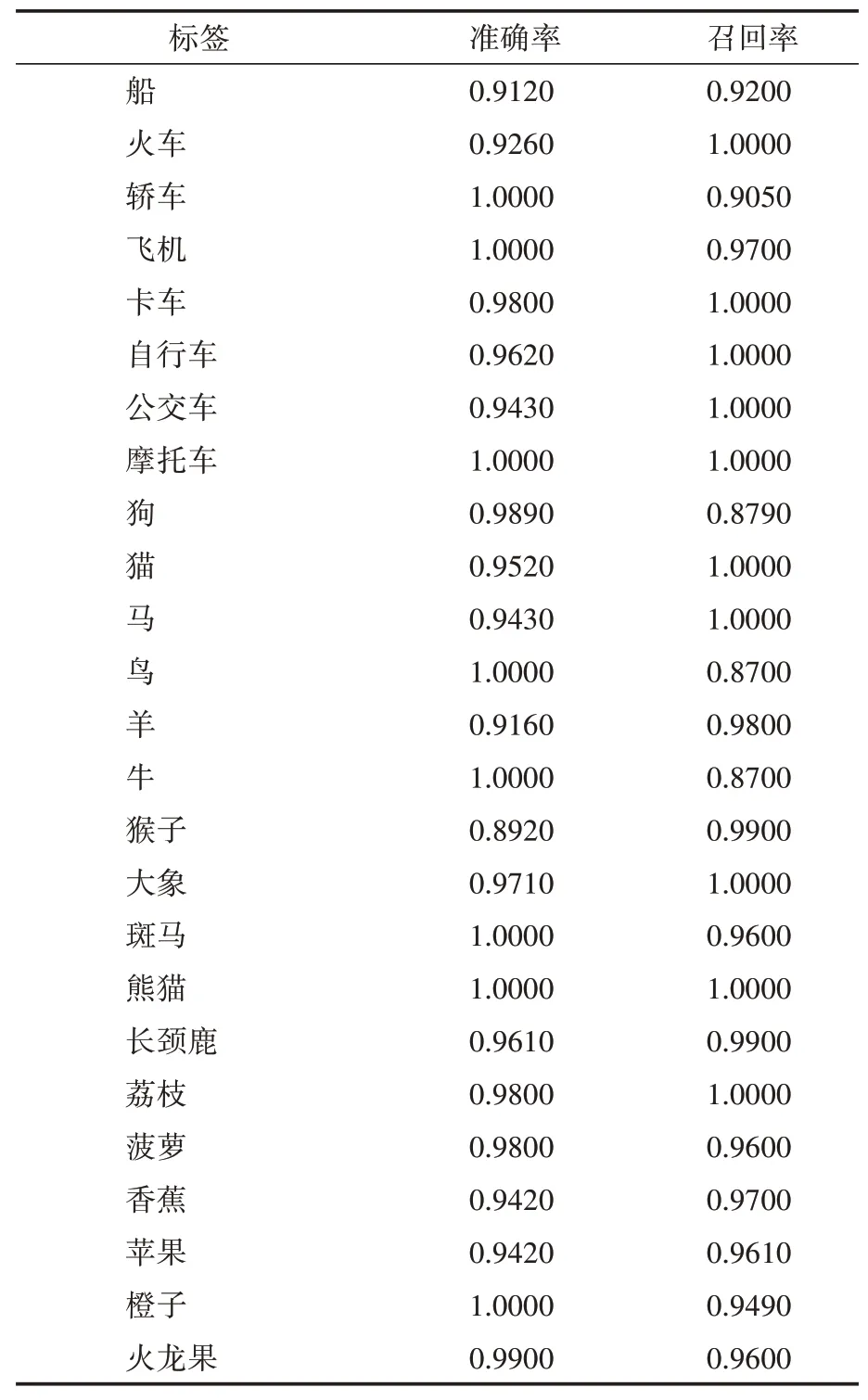
表3 物體識別測試結果
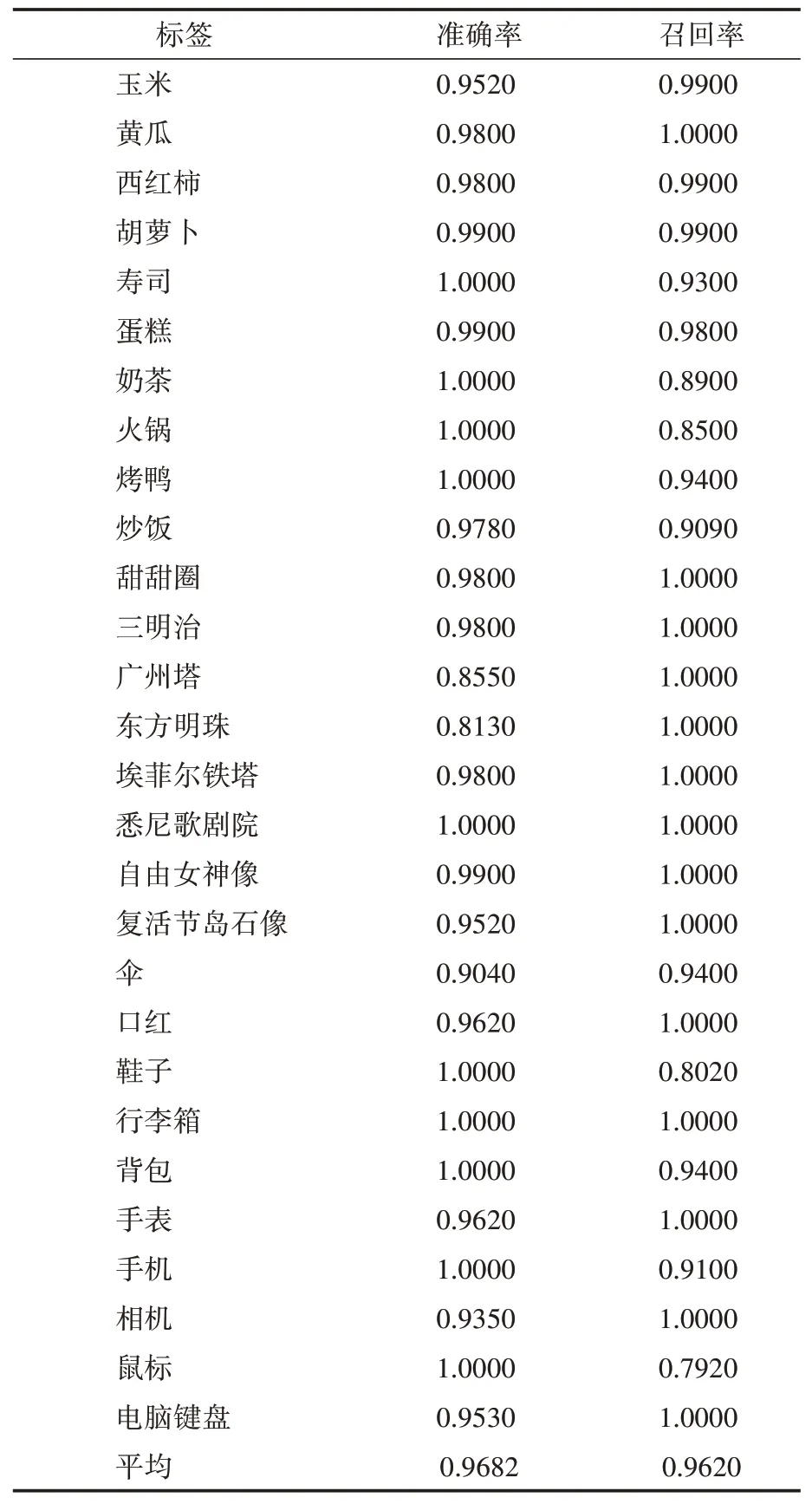
續表3
2.1.3 場景理解
場景理解解析圖像所處的場景環境,如天空、草地等,與物體識別結合使用,完成網盤相冊事物分類服務,為網盤用戶提供照片的智能自動分組及管理。場景理解預測輸出圖片所屬場景類別標簽,屬于圖片多標簽識別任務,本文采用經典resNet50卷積模型完成場景分類任務。為實現場景多標簽預測,本文替換原resNet 模型中的softmax 激活分類層為sigmoid 激活,同時考慮到樣本不均衡問題,本文采用非對稱損失ASL 進行分類模型優化。場景標簽選擇常見的26 類生活場景標簽,通過網頁爬蟲獲得訓練樣本集和測試樣本集,訓練集每類圖片數目3000~5000 張,測試集圖片每類100 張,模型訓練測試結果如表4所示。
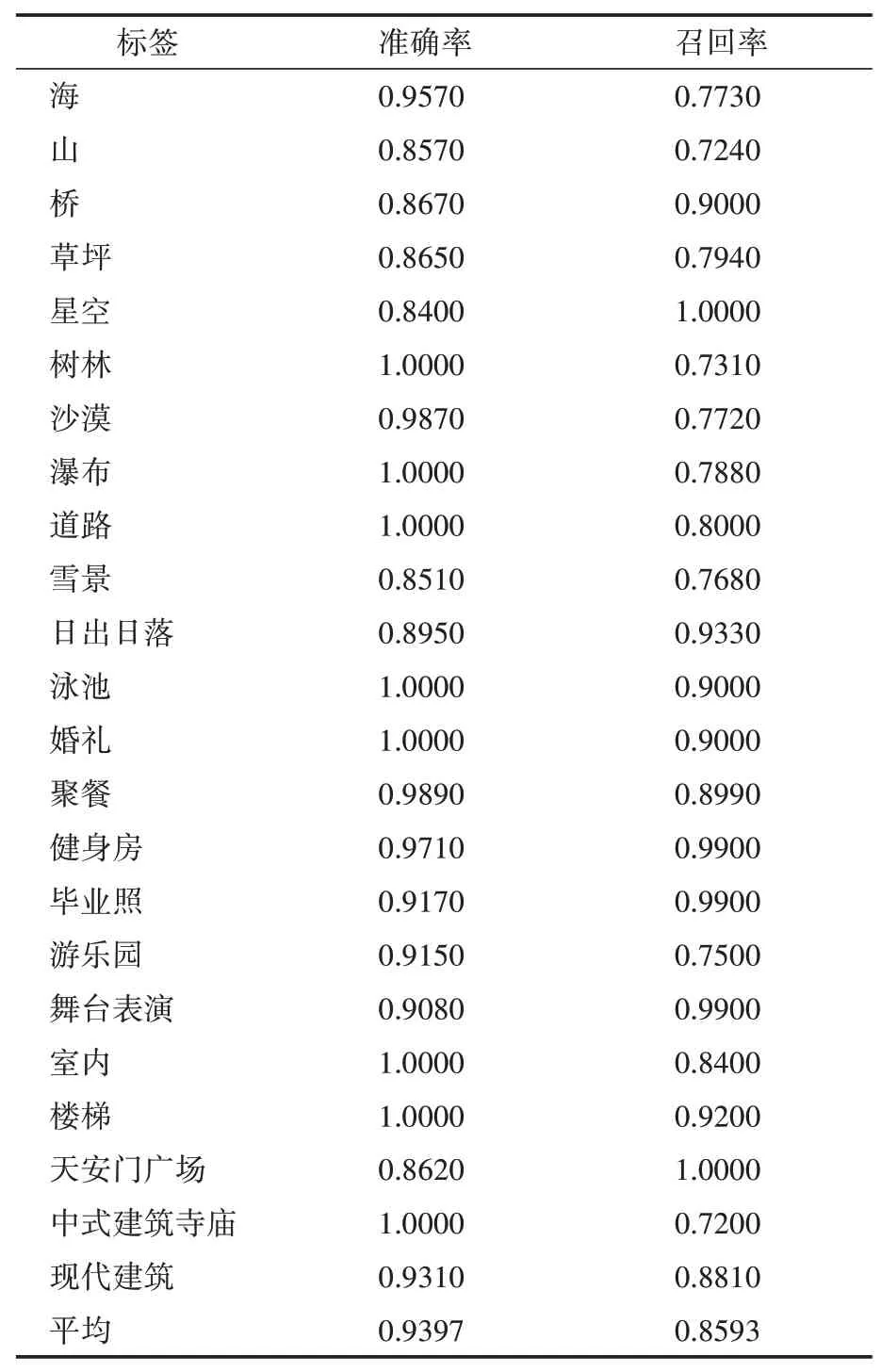
表4 場景理解測試結果
2.2 智能相冊算法服務應用
網盤智能相冊基于人臉識別、物體識別及場景理解基礎算法技術形成人像聚類及事物聚類兩大類應用,可以根據圖片標簽屬性將相冊圖片進行分組劃分,例如將相同人物照片劃分為同一組,將事物圖片聚合分為風景、美食、建筑等類別,也可以將人物場景事件分為聚餐、運動、演出等類別。
2.2.1 人像聚類
基于人臉特征向量間歐式距離設置兩層閾值完成相同照片人臉聚合,第一層閾值用于進行相似圖像的聚類組合,可存在一張圖片屬于多種聚類組合中;第二層閾值對于存在聚類組合的圖像進行過濾與整合,輸出結果保證每張圖像只存在一種聚類組合。聚類流程如圖4 所示。人臉特征向量由人臉識別模型獲得,以特征向量間的歐式距離作為人臉相似度度量。
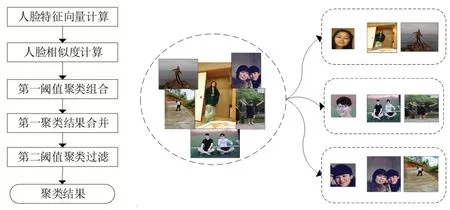
圖4 人像聚類方案(左)和人像聚類示例(右)
第一層閾值聚類:第一層閾值聚類組合將相似度大于所設定的第一閾值人臉圖片劃分為同一類別;
第一聚類結果合并:第一層聚類完成后對沒有聚類結果的圖片進行過濾,并對存在共同人臉圖片的聚類組合進行合并;
第二層閾值聚類:遍歷合并后的第一聚類結果,計算聚類結果類別中人臉平均相似度,并基于相似度對聚類結果進行二重篩選。具體做法是,若一張圖片與類別中的其他圖片最小相似度和平均相似度都不符合設定的第二閾值,則將此圖片剔除出此類別的聚類結果。
2.2.2 事物聚類
通過圖片物體及場景輸出標簽聚合形成網盤照片事物聚類應用,為便于用戶瀏覽與查找,可根據圖片細分標簽將圖片聚合為多個主題大類,如表5所示。

表5 事物聚類主題列表
可將物體標簽與場景標簽聚合為交通、動物、美食、建筑等大類,實現網盤智能相冊事物圖片智能分組應用,實現效果如圖5所示。
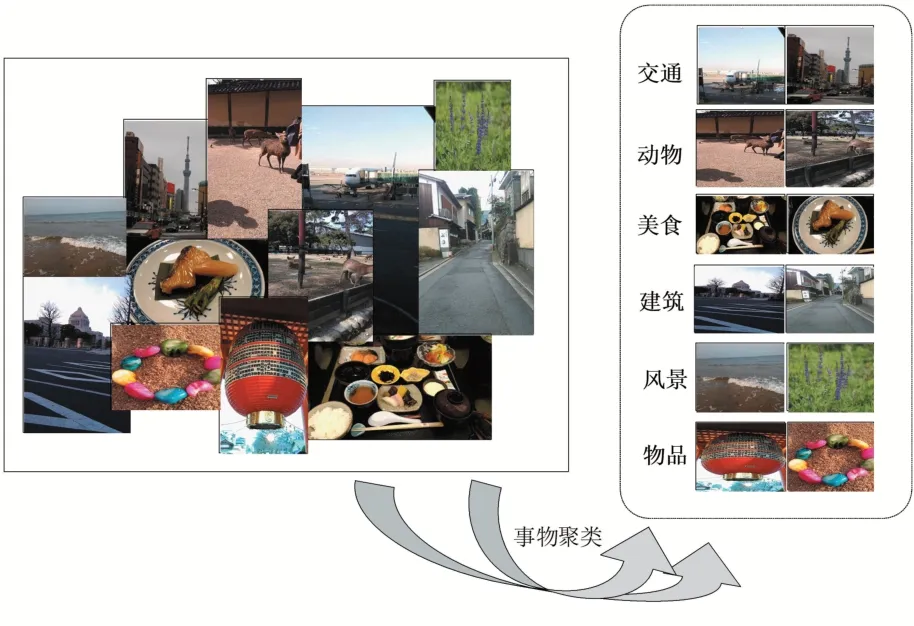
圖5 事物聚類示例
3 結語
隨著5G 技術的發展及人們生活品質的不斷提高,用戶對網盤存儲有了更高的要求,即要保證速度與容量,還要足夠智能。本文基于深度學習算法技術設計實現了網盤智能相冊系統,包含模型訓練及服務應用兩大模塊,模型訓練模塊訓練輸出人臉識別、物體識別及場景理解系列算法模型用以支撐服務應用模塊的網盤人像聚類及事物聚類業務應用,該應用服務可根據圖片視覺內容進行自動識別和自動分組,形成以人物個體或其它內容主題為單位的圖片集,便于用戶更加快速、高效地瀏覽及查找網盤相冊圖片,實現智能高效的相冊管理。本系統架構后續還可進行擴展以支撐更多網盤智能應用,如擴增智能算法池算法類型以支撐網盤文本、視頻智能分類處理,也可基于基礎算法模型擴展服務應用類型,如可實現基于人臉識別及事物識別的智能搜索應用服務。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
作文中學版(2022年1期)2022-04-14 08:00:34
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
學生天地(2020年31期)2020-06-01 02:32:06
文苑(2018年23期)2018-12-14 01:06:06
文苑(2018年19期)2018-11-09 01:30:14
文苑(2018年17期)2018-11-09 01:29:26
文苑(2018年21期)2018-11-09 01:22:32
光學精密工程(2016年6期)2016-11-07 09:07:19
