云點歌系統的Python爬蟲設計和實現
2022-07-25 09:42:38羅可
現代計算機 2022年9期
羅 可
(邵陽學院圖書館,邵陽 422000)
0 引言
人們在家里聽音樂不外乎兩種方式:一種通過電腦打開音樂網站,再通過音箱來播放;另一種是通過藍牙設備連接手機來播放。現今,人們更偏向于追求簡單、方便、智能的播放方式,通過搜尋或者事先把歌曲下載才能播放音樂的傳統方式無法滿足用戶需求的便利性、簡單性。自2014 年亞馬遜公司上市了一款名叫“Echo”的智能音箱之后,許多科技龍頭企業都緊隨其后,紛紛推出天貓精靈、小愛音箱等智能音箱,使人們的聽覺習慣發生了根本性的變化。
當前,許多學者都在使用各種技術來研究點歌系統。王琴將C#技術與SQL Server 技術相結合,開發了一套以C/S 為核心的KTV 點歌系統。豆利以Delphi 和SQL Server 為開發工具,利用ADD 技術對KTV 音樂點歌管理進行了研究。陳 國 鋒結合MySQL 與PHP 技術,利 用Dream weaver 進行網頁的優化,開發出基于PHP的在線音樂點歌系統。在互聯網流媒體格式音樂和爬蟲技術興起的大背景下,本文提出了一種基于Python爬蟲技術的云點歌系統。
1 相關技術
1.1 網絡爬蟲
網絡爬蟲可以被稱作網絡蜘蛛、螞蟻、自動索引程序,或者FOAF 軟件中的網絡追逐者,是一種能夠自動瀏覽全球信息網絡的網絡機器人,已在因特網搜索引擎或其它相似的站點上廣泛使用。通過在網頁上的爬行將所有內容都收集起來,然后再由搜索引擎進行進一步的處理,這樣就可以讓使用者快速地找到自己想要的信息。網絡爬行的實質就是模仿用戶在網頁上打開的頁面,從而獲得用戶所需要的信息。
1.1.1 網絡爬蟲的構成及其工作原理
網絡爬蟲框架結構包括三部分:解析器、控制器和索引庫,其中解析器是網絡爬蟲的核心,它負責對網頁的下載、處理,處理JS腳本、HTML標簽、CSS代碼、空格符等內容。
網絡爬蟲工作過程如下:首先把網址放到爬蟲器里面;其次,把所有網址的程序代碼下載下來,因為并非全部都是所需要的數據,因此需要進一步篩選html 的元素,把所需結果加載到列表中,再把所有結果顯示出來。
1.1.2 網絡爬蟲搜索策略
網絡爬蟲策略可以分為深度優先策略、寬度優先策略、聚焦搜索策略三種。目前常見的網頁搜索策略為寬度優先和聚焦搜索策略。
(1)網絡爬蟲的寬度優先策略。從圖的某一節點開始探尋,探索該節點所有相鄰且未尋訪過的節點,根據探索過的節點繼續進行先廣后深的搜尋。如同樹形結構,即把同一深度的節點走訪完,再繼續向下一個深度搜尋,直到找到目的節點或遍尋全部節點。
要抓取一個網頁、分析一個網頁,是一件很容易的事情。那么對于搜尋引擎來說,要獲取的資源是網絡上的大量網頁,如何抓取就是一個策略問題。重要的網頁通常離種子比較近,比如當我們進入一個新聞站點時,通常會發現最熱的消息;而當我們繼續深入時,你所能看見的頁面就變得不那么重要了。互聯網的真實深度可以達到17 層,但到達某個網頁總存在一條很短的路徑,廣度優先瀏覽將會在最短時間內訪問到該頁面。廣度優先有助于多個爬行器之間的協作,而這種協作往往是先抓住站點內部的鏈路,并且具有很強的封閉性。
(2)網絡爬蟲的聚焦搜索策略。不同于深度優先和寬度優先,聚焦搜索策略采用了“匹配優先原則”的思想,利用特定的匹配算法,主動地選取與需求主題有關的數據文檔,并限定優先級,進而為后續的數據采集等工作做引導。按照“匹配優先原則”的方式訪問,可以快速有效地獲取更多與主題有關的網頁。聚焦爬蟲會為其下載的網頁打分,然后按分數順序將其加入到一個隊列中。接下來的最佳搜索將會在彈出隊列中的首頁上進行分析,這樣可以確保爬行器能夠對最有可能被鏈接到網頁的網頁進行排序。這個策略認為,頁面擁有許多的屬性,可以認為類似屬性的頁面其更新頻率也是類似的。如果要計算某個分類頁面的更新頻率,只需要對這一類網頁抽樣,以他們的更新周期作為整個類別的更新周期。
1.2 Python及網絡爬蟲第三方庫
Python 具備簡單、易用、功能強大、跨平臺、高開發效率、開源、移植性好、支持大量第三方資源庫等優點,目前已被廣泛地用于科學統計、人工智能開發、網絡爬蟲等領域。Beautiful Soup 是Python 的一個第三方庫,它的任務是從網頁中獲取數據,它能夠為用戶提供諸如瀏覽、查找、修改分析樹等簡單的Python功能。作為一個工具包,它可以為用戶分析文件所需的資料,因其簡單易于操作,編寫一個完整的應用程式并不需要太多的代碼。Beautiful Soup 可以把輸入的文件格式轉化為Unicode 編碼,而輸出的文件則會被轉化成UTF-8 編碼。除非該文件未指定編碼方式,否則你不必去思考如何進行編碼,只需簡單地解釋最初的編碼方法。Beautiful Soup 不但為Python標準庫提供HTML解析器,而且也為某些第三方提供解析工具,比如xml HTML、lxml XML、html5lib 等。Beautiful Soup 的 解 析 器 對比如表1所示。
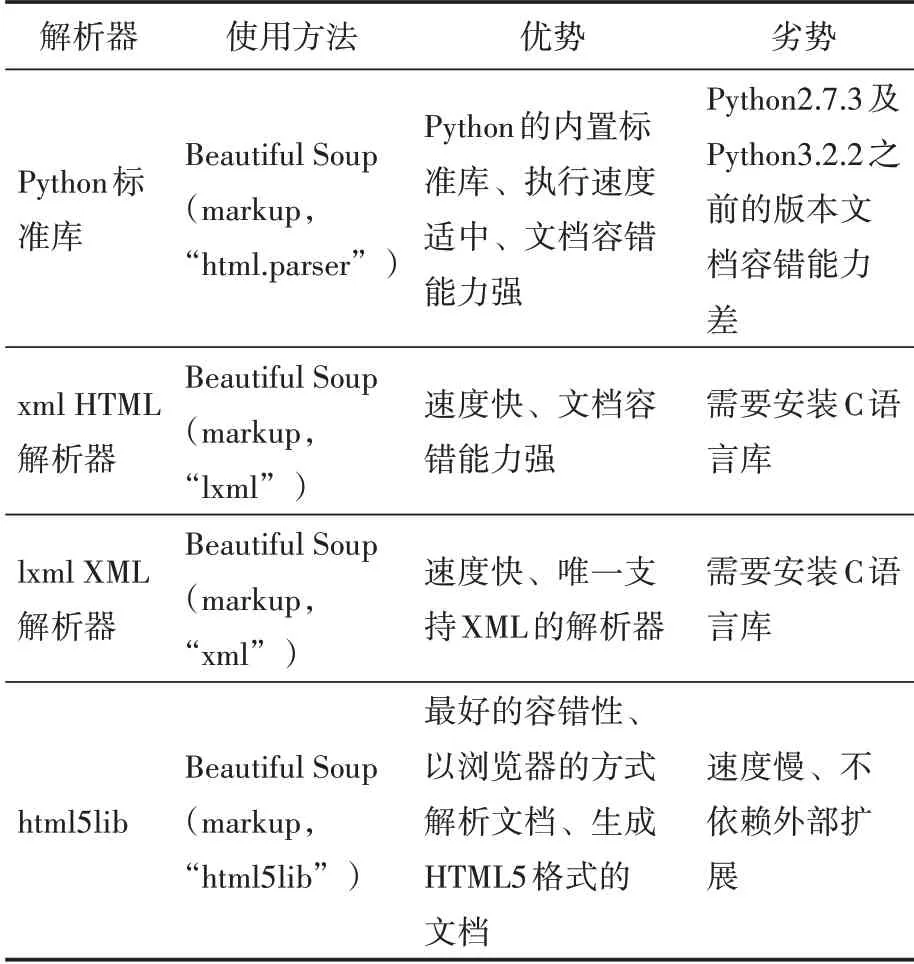
表1 Beautiful Soup解析器對比
2 云點歌系統總體框架及其功能
2.1 云點歌系統主體框架及流程
云點歌系統主要由三部分組成:主程序模塊,爬蟲模塊和語音識別模塊。主程序模塊負責視頻格式轉換和音頻播放輸出;爬蟲模塊負責根據語音識別的文字信息實時搜索音樂平臺的視頻資源,獲取相關資源信息反饋給主程序;語音識別模塊負責實時監聽外部指令,例如“開始點歌”、“我要切歌”等關鍵詞語,將指令回傳給爬蟲程序進行網絡搜索。

圖1 云點歌系統架構流程圖
2.2 功能介紹
2.2.1 點歌功能
用戶要點歌時,只需說出“開始點歌”四個字,系統就進入用戶點歌進程,然后彈出“請點歌”的語音,等待用戶說出自己喜歡的歌曲,系統會根據歌曲名,通過爬蟲程序到音樂平臺獲取網址回傳,處理好后會有語音提示“發現歌曲”,再過幾秒就可以聽到音樂。
2.2.2 切歌功能
歌曲在播放過程中,用戶只需講出“我要切歌”,就可以中止正在進行播放的歌曲,回到點歌的進程中。
2.3 模塊設計
2.3.1 主程序模塊
系統的初始運行是由主程序模塊啟動的,主程序模塊包含主線程、播放線程和切歌線程三個線程,如圖2所示。
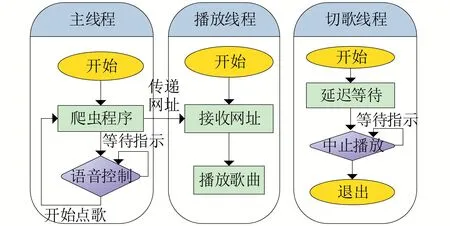
圖2 主模塊線程流程圖
主線程會先執行爬蟲程序,然后進行語音控制;播放線程根據網絡資源地址播放音樂;切歌線程負責實時監聽切歌指令、執行中止播放操作,切歌線程一開始要等待2秒,因為播放線程要進行網址轉換的過程大約需要2 至3 秒,這樣歌曲播放的時候才能做切歌的操作。
2.3.2 語音控制模塊
執行此程序時,程序實時監聽外部語音信息,如果獲取到用戶說出的關鍵詞“我要切歌”,音樂播放程序就會執行中斷歌曲,或者在歌曲結束時隨便講一句話也可以將語音控制程序退出,如圖3所示。由于外部環境噪聲可能造成聲音干擾,為了提高語音的辨識度,語音程序需連續識別兩至三次切歌指令,才可以切歌。
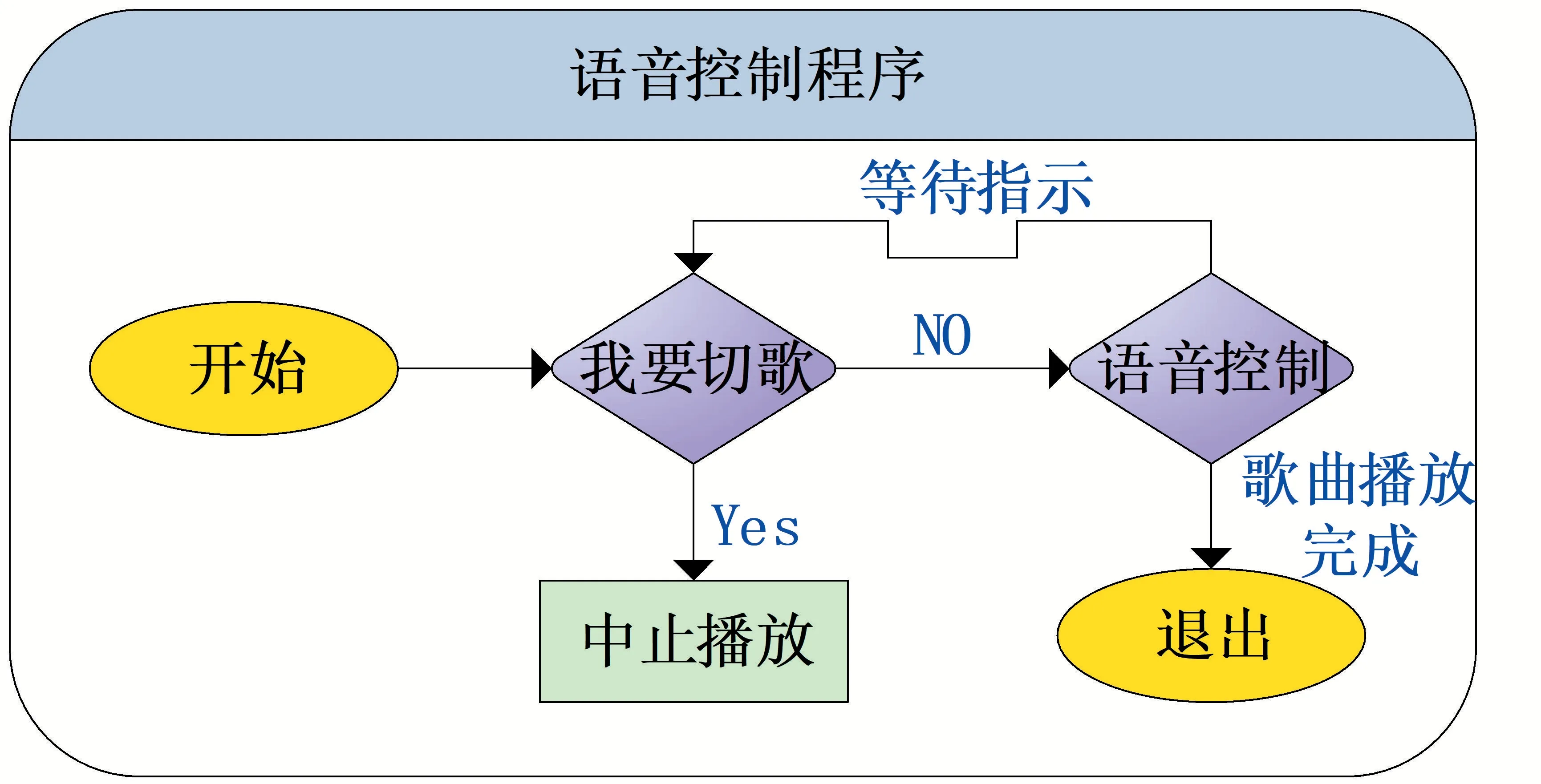
圖3 語音控制流程圖
2.4 音樂平臺Python爬蟲實現
2.4.1 獲取歌曲ID號
首先從音樂平臺搜索頁面開始,使用的是chrome 瀏覽器,并設置打開瀏覽器開發模式,可以查看相關頁面的加載信息。在XHR 里面的內容中可以找到JSON 格式的歌曲詳細信息,其中包含了所需的歌曲ID,然后調用BeautifulSoup 的庫函數解析抓取功能,拿到返回的JSON進行解析,這樣就可以得到想要的所有數據。在很多動態裝載站點中,將JSON 數據封裝成response,然后由爬行器調用loads函數將返回的JSON 數據轉化成python 的dictionary 數據,這樣可以更好地進行數據分析。有了歌曲的ID 號,可以方便以后的播放源地址進行拼接。
2.4.2 獲取音源鏈接地址
根據歌曲ID 號找到播放音樂的網頁,利用requests 庫的post 方式發送一個請求,對頁面的文字進行分析,然后尋找包含mp4 的視頻源地址,再把結果返回到主程序上進行播放。
3 結語
本文是以Python 的爬蟲技術為基礎,完成了一款云音樂點歌系統的架構設計。利用python 第三方庫爬取歌曲的源鏈接,只需說出想聽的歌曲名,就可以免費聽到音樂平臺的歌曲。這種智能化聽歌方式,給人們的生活增添更多歡樂。
猜你喜歡
文萃報·周五版(2025年2期)2025-02-14 00:00:00
大灰狼畫報·益智版(2024年3期)2024-12-09 00:00:00
保健醫苑(2022年1期)2022-08-30 08:39:14
小天使·一年級語數英綜合(2020年3期)2020-12-16 02:56:12
藝術啟蒙(2018年7期)2018-08-23 09:14:16
兒童繪本(2017年24期)2018-01-07 15:51:37
東方藝術·大家(2016年6期)2016-09-05 07:30:56
電腦愛好者(2011年11期)2011-06-22 08:20:18
河北軟件職業技術學院學報(2010年3期)2010-06-06 07:18:42
數位時尚·環球生活(2009年8期)2009-11-19 09:16:12
