基于預訓練的惡意軟件分類方法
2022-07-25 09:42:38周安民
現代計算機 2022年9期
凌 祎,周安民,賈 鵬
(四川大學網絡空間安全學院,成都 610065)
0 引言
惡意軟件的規模和造成的經濟損失逐年上漲,并且惡意軟件的產業化現象明顯,攻擊方法變化多樣,攻擊的目的性越來越明顯。近年來,惡意軟件檢測主要使用傳統動靜態檢測方法提取惡意軟件特征,包括利用控制流圖及字節流等信息。隨著深度學習的發展以及在惡意軟件檢測上的應用,研究者能夠將更多維度的信息嵌入到代碼的特征向量中,能夠有效避免統計特征的局限性。受到近些年來自然語言處理發展的啟發,在處理匯編語言時可以將匯編文本看作自然文本來進行特征提取,而隨著經典的word2vec逐步向BERT等基于大量文本的預訓練模型發展,基于匯編語言的惡意軟件檢測方法也可以采用類似的方法。雖然匯編語言可以看作自然語言來處理,但是其語法結構和含義與實際的自然語言還是存在一定的區別,因此在預訓練部分需要自行進行訓練并重新定義新的語法結構。
常見的基于深度學習的惡意軟件檢測方法,大多利用了統計特征,近幾年逐步也有利用自然語言處理的特征提取方法出現,依據自身的上下文及語義信息來生成特征向量。針對傳統自然語言處理和匯編語言的差別,本文提出了一種新的檢測方法,該方法利用自建數據集WUFCG 對基礎BERT 模型進行預訓練,一定程度上彌補了自然語言和匯編語言在嵌入過程中的差別;針對程序運行的特點,不再僅僅把程序基本塊相連而是在基本塊的基礎上再以函數作為圖節點進行嵌入。
1 檢測模型概述
本章節將介紹檢測模型的整體概況和關鍵技術細節。
1.1 控制流圖及函數調用圖
基本塊是程序運行的基本單元,由基本塊構成的程序控制流圖能夠很準確地反映程序的特征,并且控制流圖天然形成圖結構=(,),基本塊本身作為圖頂點(),控制流關系形成邊()。但在程序實際運行時,由基本塊構成的函數結構也是客觀存在的,僅僅只考慮基本塊構成的圖結構會存在信息損失,本文在控制流圖(CFG)的基礎上引入了函數調用圖(FCG)結構,使得分類效果更加精確。
1.2 特征提取及BERT預訓練
傳統的基于深度學習的惡意軟件檢測特征提取大多基于指令數量的統計特征,例如統計常量代碼、比較指令、調用指令、算數指令、MOV 指令等,近期也有一些基于經典自然語言處理的特征提取方法取得了相較于統計特征更好的效果。該方法采用BERT對匯編文本進行特征提取,相較于經典自然語言處理方法,針對惡意軟件環境利用惡意軟件數據集WUFCG 對BERT 進行預訓練,并對BIG2015 數據集進行文本嵌入,如圖1所示。
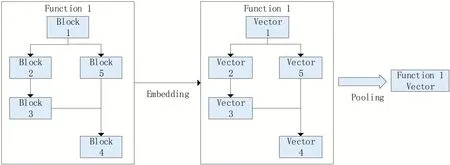
圖1 函數的嵌入框架
1.2.1 數據預處理
第一部分為預訓練階段的數據預處理,利用WUFCG 中的惡意樣本,首先將二進制文件進行逆向并對匯編文本預處理,在一個單獨的基本塊中,把基本塊中冗余信息剔除,每一行代碼內部使用短橫線連接,每行代碼之間使用空格隔開,每一行代碼看作一個單詞,一個基本塊看作一個句子,在單個函數中,相連的基本塊另起一行,函數與函數之間以空行間隔,這樣單個函數則可以看作一段,如圖2所示。

圖2 文本預處理示意圖
第二部分BIG2015 數據集的預處理,利用數據集中已逆向完成的匯編文本(.asm文件)。
1.2.2 預訓練
匯編文本處理以后,再利用BERT預訓練模型訓練參數,在預訓練環節中,使用WUFCG 來訓練BERT。在后續的訓練中,主要利用BERT的向量模式對BIG2015 數據集中的匯編文本進行嵌入,即將基本塊匯編文本(單句)嵌入。BERT 模型本身不含任何參數信息,GOOGLE 團隊在完成BERT算法后利用自身計算資源使用大量自然語言文本來預訓練,而匯編語言的單詞遠沒有自然語言豐富,直接利用官方參數不夠精確。BERT 的預訓練部分核心為兩個任務,第一個任務為Masked Language Model,第二個任務為Next Sentence Prediction。Masked Language Model 旨在一個句子中隨機選中若干token 用于在預訓練中對其進行預測,被選中的詞語有80%的概率被替換為[MASK],10%的概率被替換為其他token,10%的概率不被替換;Next Sentence Prediction(NSP)旨在預測兩個句子(基本塊)是否會相連,在本文的環境中即預測兩個基本塊是否會相連,在函數內部結構層面進行信息的提取,如圖3所示。

圖3 預訓練框架
1.3 訓練模型
本節將介紹整體的惡意軟件分類模型。在上一節中獲得了基本塊的嵌入形式,為了利用FCG 進行圖分類,還需要將整個函數中的基本塊圖池化,我們利用鄰接矩陣將函數內部的信息進行兩次傳播,再通過平均池化獲得函數的嵌入表達形式即帶屬性的FCG,公式(1)如下。


在圖神經網絡訓練階段,我們采用SAGPool來完成最終的圖分類。在圖神經網絡中,圖的節點的特征信息和圖的結構信息都會對最后的分類結果產生影響,僅僅只關注某一方面的信息是不準確的,經典圖的池化方法Set2Set、SortPool、DiffPool 均在考慮結構與節點信息方面有所欠缺,因此本文選用綜合考慮了節點特征信息和圖拓撲結構信息的SAGPool 來對最終的FCG進行池化分類。
SAGPool 采用了Self-Attention 機制,改寫了GCN 經典結構,增加了自注意力參數,獲得用于 池 化 的 自 注 意 力 得 分∈R,公 式(2)如下。



其中idx 為前「」 個節點索引,為特征注意力mask,更多細節請參考原文。
SAGPool有兩種經典模型,全局池化結構和分層池化結構,全局池化結構相較于分層而言在小圖上表現更加優異,而我們的樣本以小圖為主,因此選用全局池化結構,圖神經網絡結構如圖4 所示,左為全局池化,右為分層池化,圖中Graph Convolution層為標準的圖卷積層。
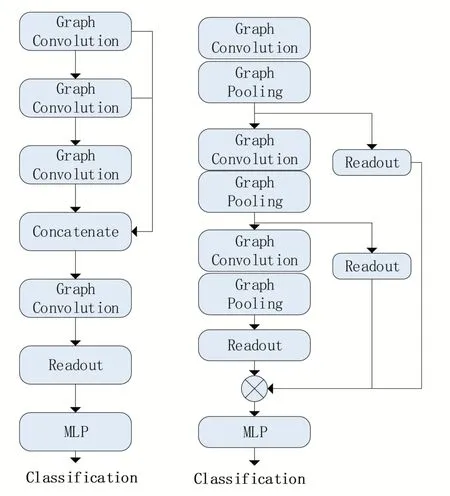
圖4 SAGPool池化框架
2 實驗及分析
本節將評估我們的惡意軟件分類效果,實驗所使用深度學習框架為pytorch,服務器操作系統為Ubuntu16.04,CPU 為Intel Core E5-2630 2.60 GHz,GPU為GTX 2080Ti,顯存48 G。
2.1 數據集
實驗部分使用了兩個數據集,第一個數據集為自建數據集,是只含惡意樣本的WUFCG,共含惡意樣本33554 個,均為x86/i386 結構,惡意樣本來自安全網站、安全廠商以及相關論壇,經過預處理后形成了60G 訓練文本;第二個數據集為2015 年Kaggle 主辦的微軟惡意軟件分類比賽中所使用的惡意軟件數據集BIG2015,共包含9 個惡意軟件家族,共10868 個樣本,包含十六進制文件(不含PE 頭)和IDA PRO 生產的匯編文件,但匯編文件中包含一些無效的文件(因加殼導致.asm 文件為亂碼),數據集詳情如表1所示。

表1 BIG2015樣本
2.2 實驗結果及分析
實驗部分采用十折交叉驗證,主要關注準確率、精確率、召回率以及1 值,實驗結果如表2所示。

表2 實驗結果對比
由于設備原因,實驗部分BERT采用的參數為最小模式BERT-TINY。實驗結果表明,在參數量最小的BERT模式下,其分類結果已明顯優于傳統方法。
3 結語
該方法基于BERT 和SAGPool 實現了對惡意軟件家族分類,并取得了理想的效果。該方法不僅可以用在惡意軟件家族分類上,在惡意軟件檢測、漏洞檢測方面亦可有一定的拓展,具有實際意義,在后續的工作中可以考慮修改SAGPool 中的部分圖卷積細節、增加BERT 參數量來提高最終的效果。
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
制造技術與機床(2019年10期)2019-10-26 02:48:08
電子制作(2019年15期)2019-08-27 01:12:00
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
電子制作(2018年18期)2018-11-14 01:48:06
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
中國生物醫學工程學報(2017年6期)2017-02-10 05:11:45
小學教學參考(2015年20期)2016-01-15 08:44:38
噪聲與振動控制(2015年4期)2015-01-01 07:08:21
