基于SSD和光流法的煙火檢測
2022-07-25 09:42:28李宏
現代計算機 2022年9期
李 宏
(西南交通大學計算機與人工智能學院,成都 610000)
0 引言
世界各地每天都會發生數百起火災,嚴重影響到人類的生命和財產安全。因此,對煙火的實時監測變得尤其重要,及時檢測出煙火能在很大程度上減少火災帶來的損失。視頻相對靜態圖像包含更加豐富和復雜的信息,同時隨著監控攝像頭的普及,視頻數據也越來越容易獲取到。相對于靜態圖像的煙火檢測,我們能夠利用視頻里煙火的動態特性來降低煙火檢測的誤識別。
傳統的基于視頻的煙火檢測方法主要是利用一些運動檢測方法來提取出煙火的疑似區域,然后訓練一個機器學習分類器或者深度卷積神經網絡來判斷該候選區域中是否出現煙火。這類方法存在以下問題:①在復雜的場景中,通過運動檢測方法提取出來的區域會變得特別多,這導致如果對每一個候選區域都進行識別判斷,將很難做到實時處理;②跟煙火外形相似的物體很容易被誤識別成煙火,而這些對于火災防控尤其重要。在本文的工作中,使用SSD檢測模型和光流法來解決上述存在的問題。
SSD 在目標檢測中得到了廣泛的應用,多尺度和一階段的檢測框架使得其能夠實現高準確率和高效率。與傳統方法使用運動檢測方法得到煙火候選區域不同的是,本文首先通過SSD 檢測網絡檢測出煙火候選框,然后基于熱空氣向上流動的理論,利用相鄰幀的煙火候選框和光流法來進一步判斷該候選框是否存在煙火。與其他方法相比,本文提出的檢測框架能夠取得更好的效果,同時有著更快的檢測速度。
1 相關工作
1.1 煙火檢測
基于深度學習的煙火檢測算法最先是基于簡單的卷積網絡實現煙火的分類識別。Khan等權衡了檢測的準確性和效率,采用VGG-16卷積神經網絡作為Baseline 進行煙霧檢測,實驗表明即使輕量級的卷積神經網絡在煙火檢測上的表現也好于傳統方法。Yin 等將傳統的卷積網絡層替換為歸一化層和卷積層,加快模型收斂的速度,實驗表明卷積網絡并不需要特別復雜的處理,也能在煙火檢測上得到高準確率。Valikhujaev等將空洞卷積加入傳統的卷積神經網絡中,這可以在計算量相當的情況下提供更大的感受野,從而增加煙火檢測模型的泛化性。Khan 等為了消除含霧場景下的煙霧誤檢,使用EfficientNet 卷積網絡進行煙火識別,網絡模型訓練的數據類別共包含四類:smoke、non-smoke、smoke with fog 和non-smoke with fog,這能夠極大地減少含霧場景下的誤識別率。
直接將整個圖像輸入到分類網絡中會使得檢測準確率較低,尤其是在圖像分辨率很高的時候,而煙火只占圖像的小部分。面對這種情況,現有的方法大多是基于煙火的動態特性,使用運動檢測算法提取出候選區域,然后將候選區域輸入到CNN 網絡中進行分類。Gagliardi等提出了一個基于傳統的卡爾曼濾波的運動特征檢測器,通過生成移動物體的邊界框來自動選擇圖像中感興趣的特定區域,最后利用一個輕量級的淺層卷積網絡來驗證該區域中煙霧的實際存在。Cao等利用ViBe算法提取出煙火候選區域,然后通過卷積網絡和雙向的LSTM 網絡來提取煙火候選區域的時空特征,雙向即從前往后和從后往前,此外還采用注意力機制來強調時域的運動信息,找到對煙霧識別有更多貢獻的視頻幀。
1.2 目標檢測
基于深度學習的目標檢測方法主要可以分為兩類:一階段檢測器和兩階段檢測器。經典的一階段檢測器有SSD和Yolo 系列等,僅用一個深度卷積網絡完成候選區域的提取和識別檢測。相對兩階段檢測器,一階段檢測器通常更快。經典的兩階段檢測器有Faster RCNN和Cascade R-CNN等,這一類方法把檢測問題分為兩階段:候選區域提取階段和檢測階段,候選區域提取階段主要是生成目標可能存在的一些區域,然后在檢測階段,候選區域的位置和類別將被進一步細化。與一階段檢測器相比,二階段的檢測器能夠實現更好的檢測效果,然而檢測速度通常慢很多。
2 算法實現
本文通過在自己構建的數據集上分別測試了SSD,Yolov3,Faster R-CNN 的表現,最終權衡了檢測速度和精準度,選擇了效率更高的SSD作為本文的baseline,更多實驗細節見第3節實驗部分。通過采用SSD作為目標檢測網絡,得到煙火的候選框,然后提取相鄰幀的煙火候選框的光流,進一步判斷該候選框中是否存在煙火。
2.1 煙火候選框提取
本文采用SSD 檢測網絡進行煙火候選框的提取。不同于Faster R-CNN 只用最后一層進行檢測,SSD 使用了多層的特征圖進行檢測,能夠更好地捕獲到多尺度目標信息。因為錨點(anchor)被應用到不同尺度的特征圖上,所以SSD 在不同層的特征圖上設計了不同的錨點大小,能夠很好地處理同一個目標在各種場景下有著不同的大小尺寸問題,這也提升了檢測的召回率。此外,SSD 引入了一些額外的數據增強技術和困難負樣本挖掘技術,使得SSD 在一些基準數據集上能夠得到很好的檢測效果。
SSD 將總體的目標損失函數定義為置信度損失(conf)和定位損失(loc)的加權和,見公式(1):
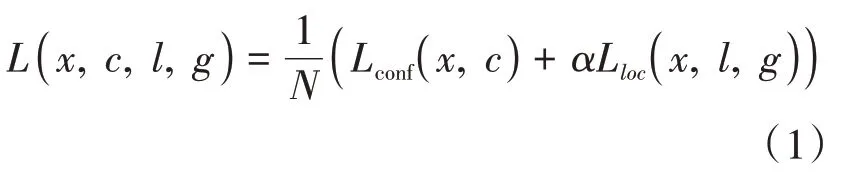
其中是匹配到真值框(ground truth)的先驗框數量,則用于調整置信度和定位損失之間的比例。

置信度損失是在多類別置信度上的softmax損失,見公式(2),其中表示先驗框的序號,表示真值框的序號,表示類別的序號。

圖1 算法整體結構圖
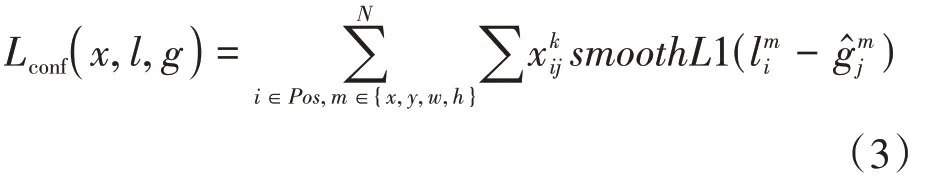
定位損失是典型的1 損失,見公式(3),其中為預測框,為真值框,使用1 損失是為了防止在訓練早期出現梯度爆炸。
2.2 煙火檢測識別
通過SSD 檢測網絡提取得到的煙火候選框通常存在一些誤檢情況,如車燈,紅色的物體,云霧等,這類物體跟煙火有著相似的外觀和形狀。為了盡可能消除這些誤檢,本文基于煙火的動態特性和熱空氣向上流動的理論,計算視頻中相鄰幀的煙火候選框的光流,統計候選框中每個像素點的位移向量,進而判斷該候選框中存在的物體是否為煙火。
光流法的輸入為連續兩張×的灰度圖像,輸出為一張××2 的光流場,其中每個像素值為輸入幀上該像素在方向和方向的位移。

圖2 光流場的表現形式
本文采用的光流計算方法來自OpenCV SDK提供的的DeepFlow,該方法能夠很好地計算相鄰幀的光流信息。使用該方法計算出相鄰幀的煙火候選框的光流運動方向來進行輔助檢測,能夠極大減少一些誤檢情況的發生,如車燈、旗子、云霧等。
3 實驗設置與結果分析
3.1 數據集
由于公開的煙火數據集并沒有進行目標框的標注,所以本文將構建一個能夠用于目標檢測網絡訓練測試的數據集,其中數據來源于互聯網和一些公開數據集。本文的數據集共分為兩類:圖像和視頻,其中圖像用于目標檢測網絡的訓練和測試,視頻則用于本文算法檢測效果的驗證分析。圖像數據集共包含19532 張圖片,將這些圖片使用標注工具進行煙火兩類目標框標注后按照8∶2 的比例劃分為訓練集和測試集。視頻數據集有6 個視頻,包含2 個煙火視頻和4個容易被誤識別成煙火的非煙火視頻。
3.2 評價指標
在本文的實驗中采用平均精度均值(mean average precision,mAP)作為評價標準,的定義首先是被PASCAL VOC 數據集提出的。針對目標檢測,本文使用交互比(intersection over union,IoU)來判斷預測候選框的準確性,通過設定閾值為0.5 來判斷正負樣本。精準度()是預測結果中正確預測的比例,召回率()是所有正樣本中預測對的比例。在不同的recall之下的precision得到一條曲線,即曲線,根據這個曲線得到各個類別的,然后對所有的類別取平均得到。此外,模型的推理速度也是一個很重要的平均指標,即每秒能夠檢測多少張圖片。
3.3 實驗設置
本實驗在Linux 16.04系統上進行,使用了4塊TITAN XP 顯卡進行目標檢測的訓練和測試。在目標檢測網絡對比實驗中,SSD,Yolov3,Faster R-CNN 設置相同的參數,批尺寸取32,初始學習率取0.02,權重衰減因子取0.0001,都是用SGD 訓練策略。而對于主干網絡,SSD 采用VGG-16,Yolov3 采用DarkNet-53,Faster RCNN 采用ResNet-101。三者的主干網絡都加載在ImageNet上已經預訓練的模型參數進行微調。
3.4 結果分析
本文將SSD,Yolov3,Faster R-CNN 在構建的圖像測試集上進行了實驗對比,實驗結果如表1所示。其中加粗表示效果最好,加下劃線表示效果次之。通過實驗結果可以看出,SSD 跟Faster RCNN 有著幾乎相近的檢測精準度,同時還有著三者最快的檢測速度。這可能與本文的檢測目標和SSD 的檢測網絡有關,因為煙火在不同場景下有著不同大小的尺度, 而SSD 專為檢測多尺度特征而生。同時,SSD采用輕量級的VGG-16作為主干網絡也帶來了更快的檢測速度。
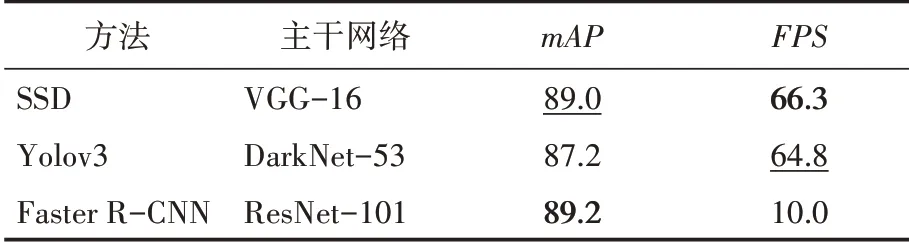
表1 不同檢測網絡的實驗結果對比
權衡檢測模型的精準度和速度,本文選用SSD 檢測網絡繼續在視頻數據集上進行測試。對視頻進行抽幀,使用SSD 檢測模型檢測視頻的每一幀,從檢測結果可以看出,SSD 仍存在不少誤檢,尤其是外形跟煙火相似的物體。如圖3,車燈或者一些光照很強的物體容易被誤識別為煙或火,為了消除這類誤檢,本文使用光流法計算相鄰幀的光流。通過觀察煙火的光流運動方向和非煙火的光流運動方向,本文得出煙火的光流運動方向通常是向上,而其他容易被誤識別成煙火的物體的光流方向通常是向下或者運動緩慢。結合光流法,本文在視頻數據集上繼續測試,實驗結果見表2。從表2 可以看出,利用光流法可以極大地消除誤檢。

圖3 測試結果實例(從左至右分別為誤檢情況和其對應的光流場)

表2 煙火檢測算法在視頻上的表現
4 結語
本文提出了基于目標檢測網絡SSD 和光流法的煙火檢測方法,并在構建的圖像和視頻數據集上進行該方法的實驗,實驗表明該方法可以實現高準確率和高效率,同時能夠極大減少誤檢數量。該方法可用做實際火災防控工作的智能化解決方式,能夠實時識別出煙火并且定位到其發生的具體位置。
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
中學生數理化·中考版(2022年11期)2022-02-16 07:01:20
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
