基于FPGA的卷積神經網絡并行加速設計
2022-07-21 04:11:18龔豪杰馮水春
計算機工程與設計 2022年7期
龔豪杰,周 海,馮水春
(1.中國科學院國家空間科學中心 復雜航天系統電子信息技術重點實驗室,北京 101499; 2.中國科學院大學 計算機科學與技術學院,北京 101408)
0 引 言
隨著卷積神經網絡[1]算法在目標檢測、目標跟蹤[2]等領域的發展,卷積神經網絡算法正在逐步取代傳統算法。針對未來復雜多變的應用環境,空天領域也一直在推進智能化發展,發揮智能技術在空天領域建設中的引領作用[3],但由于衛星所處環境的特殊性,載荷在功耗、體積、材質等方面都有嚴格的限制,導致其存儲、計算資源的稀缺性,如何將卷積神經網絡模型部署到資源受限的嵌入式環境中成為了亟待解決的問題。
FPGA具有可重構、低功耗、可定制以及高性能等優勢[4],可以高度并行地執行卷積神經網絡模型中大量重復的乘加運算,并以較低的功耗完成高精度分類任務[5]。因此,FPGA在加速卷積神經網絡方面具有自己獨特的優勢[6]。
基于FPGA的卷積神經網絡優化加速是一個復雜的過程,設計方法也多種多樣。Wang D設計流水線卷積計算內核來加速卷積計算[7];Eyeriss團隊提出RS數據流以提高卷積計算的并行性[8];Liu等提出了一種大規模并行框架來提升卷積計算的吞吐量[9];張榜等通過雙緩沖和流水線技術對卷積進行優化[10];Suda等提出一種系統化的設計空間探索算法以最大化吞吐量[11]。目前的研究雖然提出了多種技術來加速卷積神經網絡,但都專注于某一方面的性能優化,并沒有完全發揮FPGA的并行計算潛能。
本研究提出了一種卷積并行加速系統,利用層融合、數據分片、緩存設計、并行設計等多種優化策略加速卷積計算,與CPU、GPU平臺以及其它FPGA平臺設計方案相比綜合性能有一定的提升。
1 卷積神經網絡與層融合
1.1 卷積神經網絡
為了提升卷積神經網絡的性能,處理更復雜的任務場景,卷積神經網絡的層級逐漸加深,結構也更加復雜。2012年,AlexNet奠定了卷積神經網絡在圖像處理領域的地位,網絡層數只有8層;2014年,GoogLeNet通過不斷復用inception結構來提升性能,卷積層數達22層;2016年,ResNet[12]利用殘差結構將網絡深度提升到152層。隨著網絡深度的增加,其特征表達能力會有一個實質性的突破。現如今,數千層的卷積神經網絡已非常常見。
然后,深層網絡也帶來新的問題,首當其沖的就是訓練難度加大,出現梯度消失和梯度爆炸,以及容易過擬合。因此,如今的深層網絡通常都會在卷積層后加一層BN層,BN層可以有效加快網絡的訓練過程,防止梯度消失和梯度爆炸以及過擬合問題。
圖1為ResNet(殘差網絡)的基礎殘差模塊,包含兩個主要部分:卷積層和BN層。卷積層是圖形特征有效的提取器,BN層則可以解決隱藏層協變量偏移問題,使得非線性變換函數的輸入值落入對輸入比較敏感的區域,以防止梯度消失,并加快訓練過程。
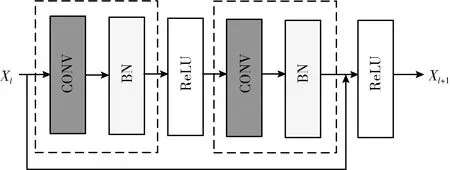
圖1 殘差模塊
圖2為卷積層的基本運算——卷積運算。卷積時將卷積核與輸入特征圖矩陣的局部做卷積運算得到輸出特征圖,局部大小取決于卷積核的大小,也即感受野的大小。其計算公式如下所示
(1)


圖2 卷積運算
本文采用的卷積網絡參數見表1。該網絡結構包含6層卷積層,卷積核為3×3,移動步長為1。

表1 卷積網絡配置參數
1.2 層融合
使用BN層是為了解決網絡訓練過程中的梯度消失和梯度爆炸問題并提高泛化性能,然而在前向推理過程中,使用訓練后的數值固定的尺度因子γ和偏移因子β,以及每個通道的平均值μ與方差σ2的無偏估計計算BN層輸出。卷積層與BN層在FPGA實現時很難共用同一套處理資源,導致BN層帶來較大的額外資源開銷,為了提升網絡推理速度和降低資源消耗,可以將BN層與卷積層進行融合。BN層的計算公式如下
(2)
式中:μ表示輸入數據的均值,σ2表示輸入數據的方差。ε是分母添加的一個很小的值,防止分母為0。γ表示尺度因子,β表示偏移因子,是模型在訓練過程中自動學習到的兩個參數。將卷積式(3)帶入到BN層計算式(2)中并展開得到式(4)
Y=W·X+b
(3)
(4)
由于BN層本身帶有偏移因子,故卷積層的偏置b可以省略,因此融合后新卷積層的權重參數W′和偏置參數b′整理如下
(5)
(6)
融合卷積計算公式如下
Y′=W′X+b′
(7)
基于以上推理,將BN層在推理階段完全融入到卷積計算中,而沒有任何的精度損失,通過這種方式可以有效降低硬件計算量,減少資源消耗,加快推理過程。
2 基于FPGA的硬件設計
2.1 優化層級分析
隨著網絡的深度加深,結構更加復雜,將導致大量的特征圖輸入和權重輸入,而片上存儲器由于資源的限制不能存儲所有的輸入數據,因此需要較大的外部存儲。本系統涉及3個層級存儲模塊:外部存儲、片上緩存和寄存器級數據處理單元。外部存儲器存儲完整的網絡模型數據,數據傳輸延遲是該部分主要的性能瓶頸,通過數據復用減少數據傳輸;片上存儲器存儲當前網絡層的模型數據,存儲資源限制是該部分主要的性能瓶頸,通過數據分片降低資源消耗;寄存器級存儲單元存儲處于計算狀態的數據,計算并行性是該部分主要的性能瓶頸,通過循環展開提升計算并行性。系統數據調度如圖3所示。

圖3 數據流調度
輸入數據流經過處理器端的處理和預加載,將輸入圖像和權重存入外部存儲器DDR。PL端通過數據總線從外部存儲讀入當前卷積層和BN層的融合數據到片上緩存,然后輸入到硬件加速模塊,數據處理單元完成卷積運算,輸出數據返回到片上存儲,繼續返回到外部存儲器作為結果輸出或作為下一層網絡的輸入。
2.2 加速器總體架構設計
加速器架構如圖4所示,主要包括片上緩存、數據處理單元(PE)和控制器。片上緩存通過AXI總線與外部存儲交流。

圖4 加速器總體架構
由于卷積神經網絡參數量大,FPGA片上存儲資源有限,無法存儲所有的參數。數據緩存操作包括數據加載和數據處理兩部分,只有完成了數據加載之后才能對其中的數據進行后續處理。為了避免數據傳輸導致數據處理單元閑置的情況,本文采用雙緩存機制,以圖中權重緩存為例,當權重緩存1進行數據加載時,權重緩存2進行數據處理;當權重緩存2進行數據加載時,權重緩存1則進行數據處理。這種ping-pong RAM的工作模式可以保證在整個處理過程中,數據處理單元始終處于工作狀態。同理,輸入緩存也是如此,數據加載和數據處理完全并行操作,使數據處理模塊的計算能力得到最大化利用。
卷積計算主要是權重矩陣與輸入特征圖進行乘累加運算得到輸出特征圖。相比于所有通道的輸入卷積窗口參與卷積生成最終的輸出通道數據,本設計使用部分通道的輸入卷積窗口與所有的卷積核卷積生成中間結果,直到所有輸入通道計算完成并累加到輸出緩存生成最終輸出通道數據,可以有效增加輸入特征圖的數據復用,減少其在BRAM和外部存儲器之間的重復傳輸。
加速器處理流程如下,卷積層與BN層融合權重通過數據分片設計,輸入到權重緩存。輸入緩存生成多個通道的3×3卷積窗口,與權重同時輸入到PE單元進行卷積運算,N個PE單元完全并行處理,控制器計算輸出通道的索引值,通過索引值將運算結果輸出到相應的輸出緩存地址,由于輸入特征圖和權重進行了分片,計算結果是中間值,需要在輸出緩存上進行累加。當所有的輸入特征圖計算完畢,輸出緩存添加偏置,并通過控制器判斷是否進行激活處理,激活函數使用ReLU函數。
2.3 層融合分片設計
本文采用的層融合分片設計如圖5所示,矩陣代表完整的層融合輸入權重矩陣,其中列數表示輸入通道數,行數表示輸出通道數,每個灰色框圖表示一個3×3卷積核,實線框中矩陣即為數據分片后權重矩陣。本文在兩個維度上進行數據分片,分別是輸入通道N和輸出通道M。在后續的卷積并行計算中,N表示輸入通道并行度,M表示輸出通道并行度。輸入通道并行和輸出通道并行在不同程度上影響計算資源的開銷。在兩個維度上設置分片參數,提升了數據分片和計算并行度的靈活性,能更充分利用平臺的硬件資源。

圖5 層融合數據分片
2.4 數據處理單元設計
數據處理單元結構如圖6所示,每個虛線框代表一個數據處理單元,其內部為N個輸入通道之間并行運算,需要N個不同的卷積核。虛線框之間為M個輸出通道之間的并行運算,需要M組不同的卷積核。因此輸入通道N和輸出通道M決定了卷積計算的并行度。當N和M分別等于當前層的輸入特征圖數量和輸出特征圖數量時,卷積并行性達到理論最大值,但也會消耗大量的硬件資源。因此,可以利用設計空間探索,合理分配并行粒度以平衡計算性能和資源消耗。

圖6 數據處理單元結構
2.5 數據復用和卷積計算優化
數據復用與卷積優化方案如圖7所示,輸入特征圖按行順序一行一行輸入,每個像素值從第一次參與卷積計算到最后一次參與卷積計算,3×3卷積窗口會走過兩個輸入特征圖行尺寸的距離,為了最大化輸入特征值的復用機率,需要2倍特征圖行尺寸大小的線性緩存存儲訪問過的特征值,這樣當像素第二次進入卷積窗口時可以直接從線性緩存中順序讀取,降低了數據訪問延遲。

圖7 3×3卷積計算設計
本文采用3×3卷積核,卷積步長為1。卷積窗口向右滑動一個步長,只有最右邊的一列需要更新,復用第一列和第二列的輸入像素值,數據復用比例達66.7%。因此,本文采用兩個線性緩存,分別是線性緩存1和線性緩存2,每個線性緩存的大小為輸入特征圖行尺寸大小。每個讀數據階段線性緩存工作流程如下:
(1)輸入緩存輸入一個數據到卷積窗口;
(2)同時線性緩存1按從左到右順序存儲該輸入數據;
(3)如果線性緩存1數據存滿,則從左到右依次更新數據,并將原始數據存入線性緩存2;
(4)如果線性緩存2數據存滿,則從左到右依次更新數據,并丟棄原始數據。
如圖7所示,線性緩存2負責更新卷積窗口第一行,線性緩存1負責更新第二行,每次從輸入緩存讀取的數據則負責更新第三行。卷積窗口的三行數據同時更新,讀數據階段需要兩個時鐘周期,一個時鐘周期讀地址,一個時鐘周期讀取數據,通過完全流水線結構,可以在每個時鐘周期生成一個卷積窗口進行后續計算。
生成的卷積窗口與權重同時輸入到卷積計算單元,卷積計算單元的乘法運算完全展開,之后輸入到加法樹,通過乘法陣列-加法樹的模式最大化核卷積計算的并行性。
2.6 設計空間探索
由于不同的FPGA平臺有不同的資源限制,為了更好匹配平臺的資源限制,提升硬件資源利用率,本文提出了如表2所示的設計空間探索算法。

表2 設計空間探索偽代碼
如偽代碼所示,Cout表示輸出特征圖數量,Cin表示輸入特征圖數量。算法的輸入是當前網絡的參數和硬件資源約束,輸出是網絡的并行度,包括輸入通道并行度N和輸出通道并行度M。首先,初始化參數N和M,根據當前網絡并行度參數運行網絡,如果資源開銷滿足硬件資源約束,則繼續判斷網絡的性能是否有提升,如果有提升則通過當前的并行度參數更新N和M,否則丟棄當前結果進入下一次迭代,直到找到最優的網絡并行度參數,N和M確定了計算資源的使用量。通常情況下,卷積網絡的通道數會隨著網絡加深而成倍增長,且本文卷積加速模塊在不同卷積層間是復用的,因此在充分利用硬件資源情況下確定的初始卷積層的并行粒度可以沿用到后續網絡層中。網絡的并行粒度即為N×M。
3 實驗結果
3.1 實驗環境
本次實驗使用Xilinx公司的ZCU104開發板作為實驗平臺,該芯片含有PL端1728個DSP48E單元,38 Mb RAM,以及PS端2 GB DDR4存儲器件,完全可以滿足本實驗的硬件要求。實驗數據位寬設定為浮點32位,FPGA主頻設定為100 MHz。
此外還在CPU和GPU平臺上進行計算性能測試,測試卷積網絡模型為表1的卷積層2,CPU采用的是Inter Core i5-4210H,主頻為2.90 GHz;GPU采用的是NVIDIA GTX1080ti,顯存容量為11 GB,核心頻率為1.582 GHz。
3.2 功能驗證
本實驗基于Vivado_hls 2020.1和Vivado 2020.1軟件進行開發和仿真,仿真波形如圖8所示。卷積的輸入、權值和偏置都為32位浮點數據,輸入時鐘頻率為100 MHz,時鐘波形如圖8中矩形框2所示。圖8所示波形包括待測加速器的波形信號和Test Bench Signals,為驗證加速器功能正確性,這里關注這兩個信號的輸出波形,即ofm波形。當輸出波形的寫使能信號ofm_we0和片選信號ofm_ce0置高位1時,輸出數據信號ofm_d0有效。矩形框1為待測加速器的輸出數據信號,矩形框3為理論輸出數據信號,可以看到,加速器的卷積輸出結果與理論輸出值完全相等,從而驗證了卷積加速器的功能的正確性。

圖8 卷積模塊仿真波形
3.3 資源使用
本次實驗設計經過綜合之后,Vivado HLS 2020.1給出了FPGA硬件資源使用情況。根據2.6節設計空間探索的結果,本文使用的輸入通道并行度參數N=8,輸出通道并行度參數M=4,卷積層在浮點32位運算下的資源使用情況見表3。FPGA工作在100 MHz下,由于輸出緩存需要存儲中間結果,分片后的部分權重和部分輸入數據也存儲在片上RAM,所以BRAM和URAM使用資源較高,分別達到53%和46%。乘法運算邏輯全部使用DSP資源,使用率達到83%;此外,LUT資源使用率也達到了93%,可以看出本文設計對資源的利用率已經很高。

表3 FPGA資源利用率
3.4 性能比較
由于不同文獻使用的FPGA器件和網絡結構不同,如果僅采用前向推理的時延和平臺功耗,無法有效和公正地對比不同設計架構的優劣。此外,考慮到不同方法的資源利用效率存在差異,卷積運算過程主要是乘加運算。因此,本文提出DSP效率作為性能評估依據。DSP是卷積計算中使用的主要資源,通常情況下加速器的吞吐量與硬件平臺的DSP數量呈正相關趨勢,DSP效率表示單位DSP所能提供的GFLOPS,可以避免不同硬件平臺DSP數量差異帶來的影響,從而更有效比較不同設計方案的性能優劣。本文同時增加能效比參數以便全面對比不同方法的加速效果。
各卷積層的時延和性能見表4。時間延遲主要包括數據傳輸和卷積計算的延時。網絡整體的平均性能為35.45 GFLOPS。

表4 各卷積層的性能對比
通過本次設計的板級測試,得到系統的性能和功耗等數據與其它文獻的對比見表5。文獻[13]使用循環展開并行處理和多級流水線加速卷積神經網絡,但沒有設計片上緩存結構來提升數據訪問效率,在DSP效率和能效比上遠低于本設計。文獻[11]利用設計空間探索尋找最優的計算并行性來最大化系統吞吐量,但沒有充分設計片上緩存的數據復用方案,DSP效率雖然高于本文,但是本文的能耗比更高,是其1.5倍,且本文使用32位浮點數表示,計算精度高于其16位定點數。綜上所述,本文設計的加速方案在利用了緩存設計、并行設計、數據復用以及設計空間探索等多種優化設計的基礎上,具有更高的綜合性能。在硬件資源和功耗嚴格受限的嵌入式平臺中,本設計相比表中其它方案,在單位能量上貢獻更高的計算量。

表5 與其它文獻方法的對比
在100 MHz的工作頻率下,數據處理單元處理一次8×56×56的輸入特征圖,通過4×8×3×3的卷積核生成4×56×56的輸出特征圖的卷積計算,計算量為1 806 336 FLOPS,數據處理單元的運行時間為34.37 μs,卷積計算的峰值性能為52.56 GFLOPS。
表6為本文設計的卷積峰值計算性能與CPU、GPU以及文獻[14]的對比,計算性能是CPU的4.1倍,功耗僅為GPU的9.9%。相比文獻[14],本文利用設計空間探索充分挖掘卷積計算的并行性,本文設計的卷積計算性能是其1.4倍。

表6 卷積計算性能的比較
4 結束語
針對如何提升運行在嵌入式平臺的深度卷積神經網絡的速度和能效,本文提出了一種卷積并行加速架構。該架構首先利用卷積層和BN層融合算法降低計算復雜度,通過層融合的分片設計,降低片上存儲的資源消耗。為了優化內存,本文提出了一種雙線性緩存設計,有效提高了數據復用效率,并利用ping-pong RAM的緩存方式和數據并行計算提高數據吞吐量。同時,利用設計空間探索尋找最優的計算并行度,從而最大化資源利用率。
實驗結果表明,與CPU、GPU和其它FPGA平臺的實現對比,本文提出的方法在性能、能耗以及資源利用率方面具有更高的綜合性能,對于在資源和功耗嚴格受限的嵌入式環境中部署深度卷積網絡,實現航天電子系統的智能化處理具有意義。
猜你喜歡
江蘇安全生產(2023年1期)2023-02-08 05:58:38
吉林廣播電視大學學報(2021年4期)2022-01-14 02:35:48
現代裝飾(2020年7期)2020-07-27 01:27:42
作文成功之路·小學版(2020年5期)2020-06-11 12:48:26
流行色(2020年1期)2020-04-28 11:16:38
小天使·一年級語數英綜合(2018年11期)2018-11-23 09:47:26
藝術啟蒙(2018年7期)2018-08-23 09:14:18
海峽姐妹(2017年7期)2017-07-31 19:08:17
Coco薇(2017年5期)2017-06-05 08:53:16
資源再生(2017年3期)2017-06-01 12:20:59
