基于決策樹模型的分布式存儲數據糾刪碼修復
2022-07-20 02:16:06沈洪敏周功建
計算機仿真 2022年6期
沈洪敏,周功建
(廈門大學嘉庚學院,福建 漳州 363105)
1 引言
隨著信息、網絡、電子技術的迅速發展,以及大數據時代的來臨,不斷催生信息數據越來越呈現爆炸性的增長,同時數據規模也呈現指數級上升的現象[1]。與此同時,使得當前信息技術的發展方向越來越變為以數據存儲為核心的計算機信息技術發展。基于分布式的數據存儲系統作為當前數據存儲的主要應用技術之一,充分結合了數據存儲系統、計算機技術、集成電路技術以及計算機網絡技術發展的結晶。同時,構建基于分布式的數據存儲系統其目的就在于充分利用當前相對廉價的數據存儲軟硬件資源、網絡軟硬件資源,從而構建超大規模、可靠性高以及具有強擴展性的數據存儲與應用系統。然而,當前隨著數據獲取方式不斷增多、數據類型日趨復雜、以及數據增長方式呈現前所未有的數據變化,從而造成數據在進行分布式存儲的過程中,呈現存儲節點數量逐步上升、節點的分散性高、異構性以及易失效性等問題,給傳統的數據存儲方式以及數據存儲過程中的可靠性帶來嚴峻的挑戰[2][3]。
因此,在進行分布式數據存儲系統研究的過程中,如何進一步提高系統的可靠性、容錯性以及數據恢復精度等內容,同時進一步降低軟硬件數據修復開銷成為當前分布式數據存儲系統的研究熱點。
通常來講,分布式存系統在進行提高數據容錯的方法主要從以下兩個方面進行研究,即多副本數據存儲技術以及數據存儲糾刪碼技術[4]。顧名思義,多副本數據存儲技術就是將需要保護的原始數據以多個數據副本存儲在不同的數據節點上,在進行數據恢復的過程中出現無效節點時,可以將其它未失效的節點副本數據復制覆蓋掉失效節點上,從而實現對失效節點上的數據進行恢復。很明顯,多副本數據存儲技術在進行數據存儲與恢復的過程中修復原理簡單直觀,而且更有利于實現,因此該方法是目前應用最為廣泛的數據存儲與容錯技術。很明顯可以看出,輕量級數據采用此方法極為有利[5]。但是,當遇到海量數據存儲與修復的過程中,為了保證數據的可靠性和容錯性,需要消耗大量存儲空間,會極大的耗費人力物力和財力。
為了解決多副本容錯技術帶來的缺點,數據糾刪碼技術應運而生,該方法通過將原始存儲數據按照一定編碼規則對原始數據進行編碼,將編碼得到的具有冗余信息的冗余數據按照一定規則一并存儲到對應的數據節點上,從而達到存儲數據容錯的目的[6]。在進行數據恢復的過程中,如果數據出現異常,通過對剩余有效數據進行讀取,然后按照數據存儲過程中的數據編碼規則,采用對應的譯碼算法完成對異常故障節點的數據進行恢復。由于該方法無論在存儲資源消耗、數據存儲節點結構等方面很多優勢,因此該方法越來越成為當前分布式數據存儲與糾刪技術的研究熱點。其中比較典型的數據糾刪碼算法有,EvenOdd糾刪碼算法,Free Codes,RDP算法以及HRCSD等糾刪碼數據容錯算法。同時在此算法的基礎上,很多研究學者提出了新的數據糾刪容錯算法。其中,文獻[7]根據EvenOdd算法的特點,提出了同時針對多列誤碼的G-EvenOdd數據糾刪算法。與此同時,文獻[8]同樣基于EvenOdd基礎算法,提出了基于擴展EvenOdd的存儲數據糾刪模型,該模型描述了一種新的星形編碼方案,用于糾正三重存儲節點故障(擦除)。星型碼是雙糾擦偶奇碼的擴展,是廣義三糾擦偶奇碼的改進,然后詳細介紹了星型碼解碼算法,同時應用于糾正各種三節點故障。最后通過實驗表明,該方法在針對任意三點故障星型碼的有效性,驗證了該模型在應對需要更高可靠性的存儲系統具有很好的實際意義。文獻[9]在研究糾刪碼的過程中,作者將網絡編碼的思想引入其中,同時結合網絡中的信息流圖來進行對存儲數據的修復問題進行數學建模,通過分析沒此修復數據的修復帶寬的大小來進行評判該方法的優越性。文獻[10]提出采用建立在可用帶寬的存儲數據修復模型,這種模型通過分析優化對應的線性網絡編碼的數據修復速度。從實際使用角度可已看出,該方法的局限性主要在于除了要維護現有的數據,同時還可以有效維護大量的節點信息,很難解決整個系統的負載均衡問題。于此同時,文獻[11]于2005年經由IBM實驗室提出了關于針對多磁盤故障的糾刪算法,比如HoVer碼以及R5X0碼等方法。
綜合以上可以看出,在關于糾刪碼算法的研究過程中,主要集中于糾刪碼的以下的問題。首先,糾刪算法的冗余度問題,即系統在滿足一定糾刪性能的情況下產生多少冗余編碼才可以滿足整個系統的性能;其次,糾刪算法編碼的復雜度問題;因為糾刪算法的復雜度不僅直接影響文件的存儲時間,同時也是衡量糾刪算法優劣的一個性能指標;最后,糾刪算法的譯碼復雜度問題,該問題類似于是編碼算法逆,同時也直接影響整個數據塊文件重構的修復速度,因此在研究糾刪算法時,必須考慮以上三個問題。同時,還要關注整個糾刪算法的數據修復的成功率問題以及數據結構、節點的優化問題。
因此,本論文利用決策樹模型在數據決策時的優越性,建立了基于決策樹模型的分布式存儲數據糾刪碼修復算法。該方法通過采用決策樹模型對原始數據進行分類編碼,同時將得到的決策樹模型帶來的冗余數據存儲于模型中不同節點上,從而滿足超大規模數據并行存儲與修復的需求。
2 糾刪碼算法原理
糾刪碼算法作為當前比較典型的數據存儲與修復算法,由于其占用資源少、可靠性高以及修復速度快的優點引起了國內外眾多研究學者進行算法研究。在進行研究糾刪碼之前,首先對以下幾個基本概念進行解釋;首先,將數據塊定義為分布式數據存儲的過程中,將數據按照設定大小形式來進行存儲;其次,在進行編碼存儲的過程中將存儲冗余信息(校驗信息)所占用的存儲塊成為冗余塊,同時在進行糾刪碼存儲的過程中也將該內容稱為校驗塊;然后將存放數據塊的節點以及校驗數據的節點分別成為數據節點和校驗節點。典型糾刪碼技術的基本原理如圖1所示。
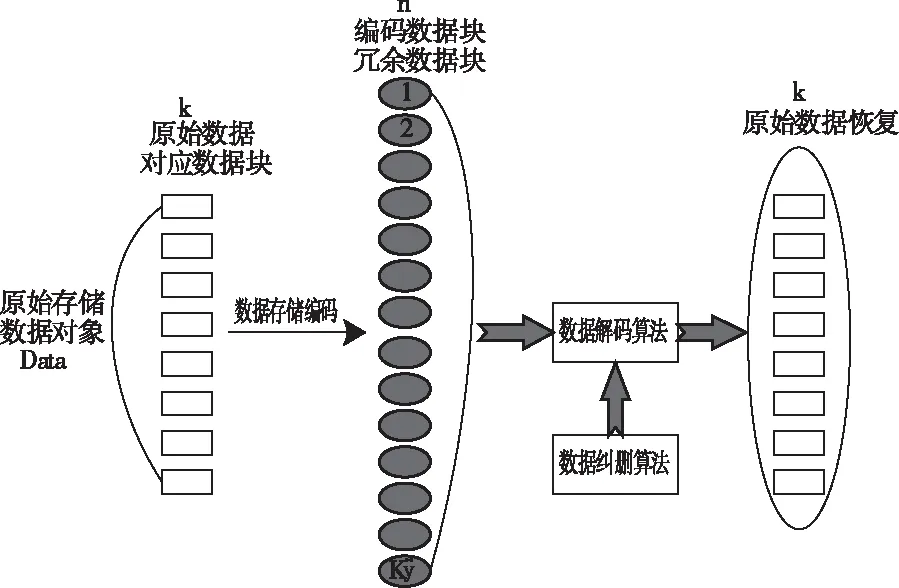
圖1 糾刪碼原理結構示意圖
如圖1所示可以看出,假設利用經典的三元組數據(n,k,k′)來表述糾刪碼。首先,將原始的存儲數據Data,分別存儲與對應的分解為大小恒定的k個數據塊中。因此,可以得到需要的數據塊個數為
Nblock=Size(Data)/k
(1)
在對原始數據進行編碼的過程中,一般都會采用特定的數據編碼算法,對所有k個數據塊進行編碼,然后可以得到Nblock數據塊。在對Nblock個編碼數據塊進行存儲的過程中,分別將Nblock數據塊存儲在N個不同的存儲節點上,這些節點之間相互獨立,在進行恢復數據的時候,如果其中某些節點出現問題或者丟失,可利用其它存活的節點來完成對數據的恢復。
由于本文主要描述糾刪碼在數據恢復中的作用,因此在進行數據恢復過程中,首先以4數據塊與2冗余數據塊為例,建立對應的數據編碼方法:
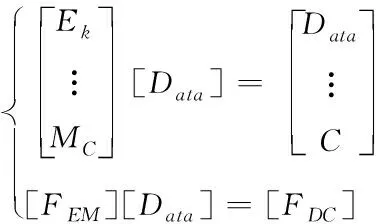
(2)
其中,MC表示編碼系數矩陣,C為編碼矩陣元素;Data需要存儲的編碼數據;Ek表示與存儲數據行列數大小對應的單位陣。利用公式(2)完成對數據編碼存儲。在進行解碼的過程中,如果對應的編碼塊節點出現錯誤,如公式(3)所示
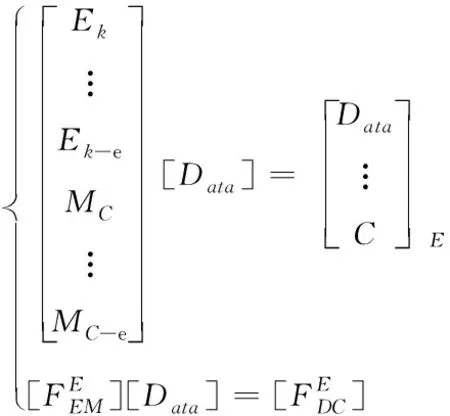
(3)
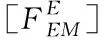
根據公式(2)和(3)可進行恢復損失的數據,在進行恢復的過程中首先構造對應的數據恢復矩陣
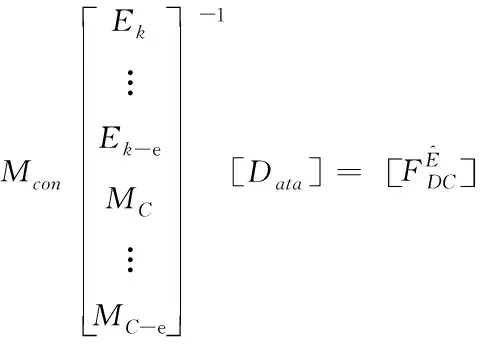
(4)
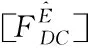
2.1 基于決策樹模型的糾刪碼數據恢復算法
在進行數據存儲恢復的過程中,雖然傳統經典的糾刪碼數據恢復算法已經得到廣泛的應用,但是依然存在數據恢復效率低,構建繁瑣等處理問題。為了解決以上問題,本文集合決策樹在數據處理中的應用,建立基于決策樹模型的糾刪碼數據恢復算法。
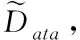
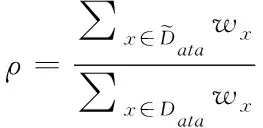
(5)
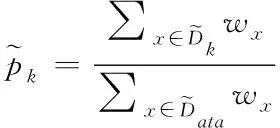
(6)
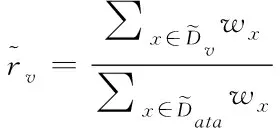
(7)
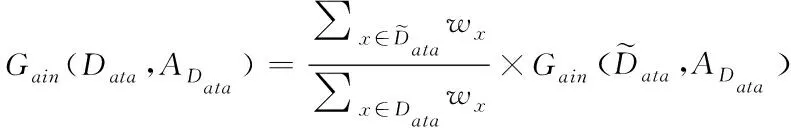
(8)
進一步得
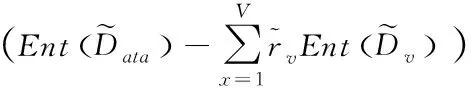
(9)
其次,為了描述確實節點數據的純度,文章采用決策樹模型中的基尼數值來進行描述。基尼值定義如下
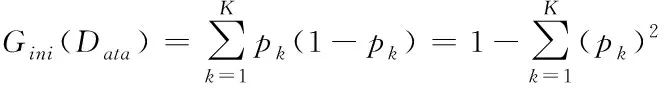
(10)
其中,K為描述存儲數據的分類級別數;pk表示數據中的樣本點屬于第K階分類的概率;可以清楚的發現,如果樣本點數據屬于上述定義的1類的概率p,這樣可以得到對應的概率密度的基尼指數為
Gini(Data)=2p(1-p)
(11)
同時,對于節點數據AData的基尼指數為
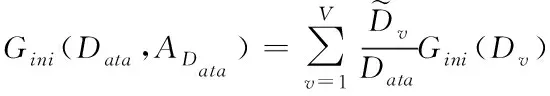
(12)
因此,結合公式(11)-(12)可以看出,在對確實數據進行分類的過程中Gini(Data)對的數值越小,則存儲數據缺失的節點數據越小。
在結合糾刪碼建模的過程中,具體結構流程示意圖如圖2所示。其中,首先將對應的原始數據進行數據遍歷,通過遍歷獲得對應的樣本點數據,以及樣本數據對應的存儲節點集。在進行數據恢復的過程中不斷去驗證對應恢復數據的基尼指數,看是否基尼指數到達滿意的程度。
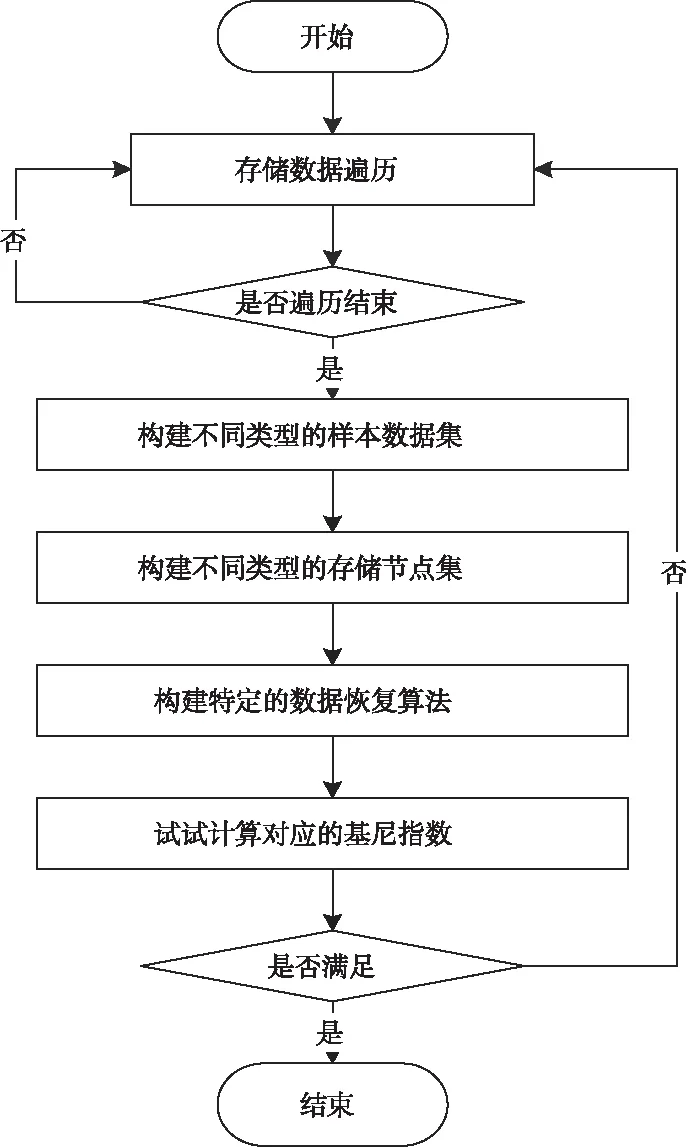
圖2 決策樹糾刪流程示意圖
3 數字仿真與數據分析
為了驗證本文提出算法在數據恢復過程中的有效性,分別采用不同的方法來進行對比,同時在不同角度來進行分析本文算法的優越性。
首先,分析存儲開銷方面。在進行數據存儲的過程中,數據存儲的開銷與數據效率通常定義為實際數據大小空間M與數據在存儲系統中所占有的實際存儲空間S的比值。為了說明本文有效性,本文將三副本技術、HRCSD碼、S2-RAID碼以及本文提出的方法分析存儲開銷。4種策略所占用的存儲空間開銷如圖3所示。
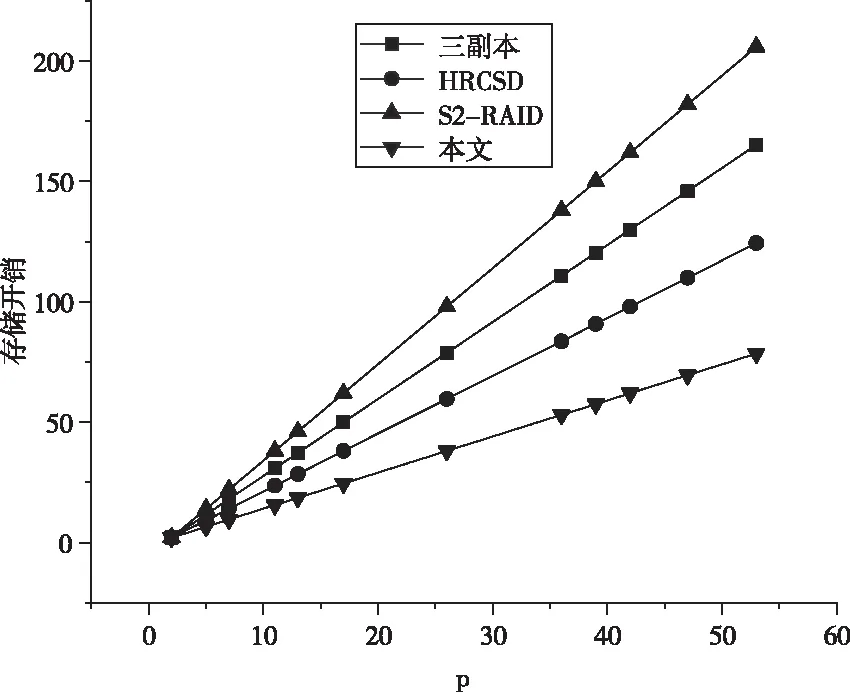
圖3 存儲數據開銷對比
如圖3所示,可以看出在對同類數據進行存儲的過程中,本文提出的算法的存儲開銷相對較低,同時采用S2-RAID方法所占用的存儲空間最大,另外兩種方法分別處于兩種方法的中間。所以采用本文提出的方法相對來說更好一些。
其次,在進行數據恢復過程中,數據恢復的效率是考核所有數據恢復算法重要的衡量指標。接下來通過不同的方法來對比數據恢復效率,恢復效率對比表格如表1所示。

表1 不同方法的數據恢復效率
如表1中的數據可以看,由于在進行建模的過程中引入了對應的決策樹模型以及算法流程在基尼指數的介入,大大提高了數據修復的準確性。因此可以看出,在進行數據恢復的過程中,采用本文提出的數據恢復的方法數據恢復效率更高,這也就意味著在進行數據恢復的過程中恢復的數據精確度更高。
最后,分析采用不同方法進行數據恢復過程中修復時間變化。同樣采用不同方法來對相同的存儲數據量進行修復,修復時間曲線如圖4所示。
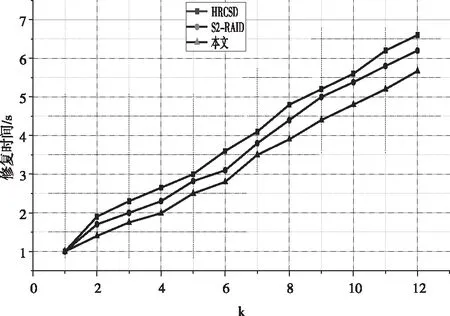
圖4 不同方法下的數據修復時間
如圖4所示,可以看出采用本文提出的方法在數據修復時所需要的修復時間相對較低,側面反映出本文提出的方法可以有效縮短對應的數據修復時間。
4 結論
由于分布式數據存儲系統作為經典數據容錯技術,因此基于分布式存儲數據糾刪碼技術研究一直是近些年數據修復過程中的研究熱點。在進行數據備份與修復的過程中,糾刪碼技術以其數據存儲過程中資源消耗低、可靠性高等優點在數據糾刪存儲領域得到了廣泛應用。但是,隨著應用數據的深入,以及大量數據在不斷地更新產生,傳統糾刪碼數據修復技術依然存在數據修復速度低、修復率低等缺點。因此,本文結合數據決策模型提出基于決策樹模型的分布式數據糾刪碼修復算法,該算法通過引入決策樹模型在數據決策上的優勢,建立的基于決策樹的分布式存儲數據糾刪碼算法。最后,為了驗證本文算法在存儲效率,數據恢復效率以及對應的修復時間方面的優越性,本文給出了對應的數據仿真。通過對比仿真可以看出本文提出的方法在修復速度、數據修復率等方面有很好的提升。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
兒童故事畫報(2019年5期)2019-05-26 14:26:14
光學精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年2期)2016-03-22 02:42:52
核科學與工程(2015年4期)2015-09-26 11:59:03
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
